AI独角兽Glean揭秘如何构建上下文图谱? 企业AI自动化的万亿美元机遇
上下文图谱通过连接企业实体与行为轨迹,让AI理解工作真实流程而非仅知晓数据状态,成为企业智能化的核心基础设施,投资者称其为万亿美元机遇。
文章摘要
上下文图谱通过连接企业实体与行为轨迹,让AI理解工作真实流程而非仅知晓数据状态,成为企业智能化的核心基础设施,投资者称其为万亿美元机遇。
往期推荐
揭秘生成式AI与知识图谱的未来:海外企业级大模型知识管理独角兽Glean如何用GraphRAG为企业节省数百万美元
企业级AI独角兽Glean揭秘知识图谱增强大模型:企业AI的关键基石,重新定义智能系统的上下文理解
加速迈向超级智能企业:Glean 全新企业图谱、第三代助手与智能体超能力
基于知识图谱增强大模型的企业级智能知识库独角兽Glean获1.5亿美元F轮融资,估值72亿美元
企业智能知识库企业Glean利用GraphRAG融资2.6亿美元
企业级知识库为什么要用GraphRAG - 硅谷企业级ChatGPT独角兽Glean系列之二
GraphRAG从研发到上线的挑战-硅谷企业级大模型知识库独角兽Glean系列之三
GraphRAG产业化应用落地挑战和探索:知易行难 - 企业大模型独角兽Glean实践之四
引言:上下文图谱的时代价值
在AI技术飞速发展的今天,尽管大语言模型已经能够使用各种工具,但它们依然缺乏一个关键能力——理解企业内部工作流程的知识。投资者将上下文图谱(Context Graph)称为"万亿美元的机遇",这并非夸张之词 。
传统的记录系统虽然能捕捉决策结果,但真正的工作却发生在会议、聊天、邮件和文档中。如果没有一个结构化的视角来理解工作实际如何完成,AI就无法可靠地实现工作自动化 。本文将详细阐述Glean公司在构建上下文图谱方面的方法论,以及我们选择这条路径的深层原因。
一、什么是上下文图谱?
1.1 核心定义
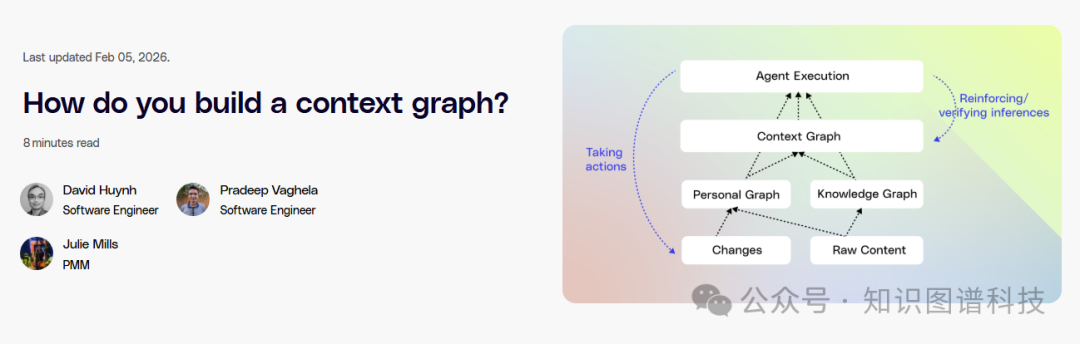
上下文图谱是一种将企业实体(人员、文档、工单、系统)与它们之间的行为和事件的时间轨迹连接起来的模型。它能从这些轨迹中提取可操作的洞察,让AI真正理解工作是如何完成的 。
1.2 上下文图谱能回答的关键问题
上下文图谱帮助AI回答以下类型的问题 :
-
"P1级事故通常如何解决?"
-
"关于产品X最常见的升级问题是什么?"
-
"从'试点创建'到'交易完成'之间通常会发生什么?"
-
"对于这个团队,'入职完成'实际意味着什么?"
-
"典型的部署需要多长时间,为什么?"
1.3 为什么需要上下文图谱?
当前的AI智能体在处理端到端流程或需要数周、数月的长期任务时面临困难,这些任务需要综合来自多个分散系统的知识 。
当你连接跨越不同事件的多个任务时,需要整合来自各种来源的信息,以及许多人的工作方式——每个人执行工作的方式都略有不同,他们的流程中融入了本地例外情况和特殊边界案例。但记录系统通常只显示当前状态,很少捕捉执行的变化性或完整的历史背景,因此依赖这种不完整的视图可能导致盲点和次优结果 。
相反,拥有一个关于组织真实流程的内部模型——从实际行为轨迹构建的上下文图谱——成为学习要遵循的结构和工作背后意图的最佳代理 。
二、从"是什么"到"如何做":上下文图谱的范式转变
2.1 传统系统 vs 上下文图谱
上下文图谱通过从描述"是什么"转变为描述"如何"变化来描述工作流程 :
- "是什么"
: 传统数据和知识系统对事物建模:客户、工单、文档、人员、系统
- "如何做"
: 上下文图谱对行为建模:谁做了什么、在哪些应用中、以什么顺序、产生了什么效果
2.2 将行为转化为一级实体
"如何做"是通过将行为转化为图谱中的一级实体来描述的 :
节点(即用户和智能体的行为及丰富的数据轨迹):
-
"创建"、"查看"、"批准"、"升级"、"评论"、"解决"
-
每个节点都带有时间戳和关于变化的丰富元数据
边:
-
边代表因果关系和相关性
-
"消息A"以概率P触发了"更新B"
2.3 预测能力与推理洞察
Glean选择这种建模方式是为了给一系列活动附加预测能力,这样我们可以建议下一步可能发生什么,而无需硬编码流程。最终得到的是可能路径的分布,使智能体能够自主选择场景中最可能的路径 。
在这些流程路径之上,还有衍生的洞察——解释"路径A"为何不同于"路径B"的原因。这使我们不仅能编码"如何做",还能编码可能的"为什么",这些可以在运行时输入智能体 。
智能体运行后,其行为成为上下文图谱的新轨迹。然后通过强化学习评估所选路径是否最优,并识别智能体未来可以采取的替代路径 。
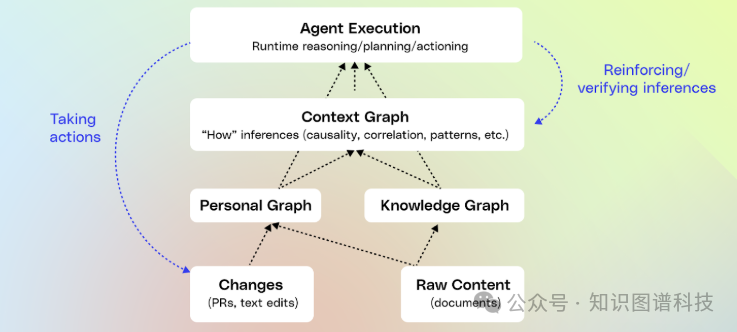
三、如何构建上下文图谱?Glean的五步方法论
第一步:投资深度连接器和可观测性
上下文图谱需要深度连接器和可观测性的基础。如果看不到工作如何发生,就无法对其建模。这意味着需要在文档级别与实际工作发生的应用集成,以及结构化数据:CRM和工单系统、聊天、文档、电子邮件、日历、代码、仪表板和内部应用 。
我们深入理解每个应用的实际使用方式。例如,Jira评论会快速过时,而Jira描述中的链接通常是规范的(即文档、设计等) 。我们在集中式数据模型中捕获这些模式,然后将其放入搜索索引中。
难点在于长期保持模型的健康:追踪不一致的API、协调不同工具间的身份差异,并持续实施内容权限,以确保每个结果既相关又安全 。
几年前,我们开始捕获的不仅是文档数据,还有应用中的所有变更事件。然后将它们标准化并作为轨迹公开,目标是构建上下文图谱 。
[Glean深度连接器集成的企业应用生态系统]
第二步:构建统一知识图谱
爬取和索引数据后,我们通过运行机器学习管道来构建知识图谱,以推断更高级的实体,如项目、客户、产品、团队和人员。我们还识别它们之间的关系——确定哪些文档、工单、通话和仪表板属于给定的产品或账户 。
我们持续输入活动信号(浏览、编辑、评论等),以理解信息实际如何使用以及人们如何协作。这就是Glean如何理解CRM中的"ACME Inc"和支持工单中的"ACME"是同一个客户 。
这使我们能够将活动汇总到同一个规范项目或客户中,从而高度确信实际发生的情况。这就是为什么知识图谱是上下文图谱的关键基础,因为活动信号本身是嘈杂的,你需要下面的知识图谱才能使活动变得有意义 。
第三步:创建个人图谱
与知识图谱并行,我们构建个人图谱,了解你的任务和项目,以提供主动的、个性化的帮助 。
要构建个人图谱,我们收集和综合活动流和轨迹,将这些原始信号拼接成时间线,并用知识图谱中的实体丰富它们:
-
对每个人,跨工具的按时间顺序的行为序列,以及更丰富的元数据
-
从那里,我们开始将低级事件分组为语义任务
这是棘手的部分。真实工作是混乱的:人们不断切换上下文,在不同工作中重复使用相同文档,并在几天后放弃并重新拾起线程。单个"编辑文档"事件可能属于多个并行工作流 。
为了理解这一点,我们结合使用:
-
简单信号,如共享标题、工单与文档之间的链接、会议邀请、频道名称和时间窗口
-
查看事件序列并推断的LLM:"这个集群看起来像在调查警报",或"这些行为一起看起来像在起草和社交化规范"
目标是将流程划分为连贯的工作单元——系统可以推理的任务和更高级别的项目 。
由于我们维护用户隐私,这些数据只对他们自己可见。但当我们开始聚合分析时,我们可以看到主题 。
第四步:创建上下文图谱
当我们聚合分析流程时,我们将每个个人图谱标准化为一系列匿名化的"步骤",带有粗略标签 :
-
行为类型(查看、编辑、评论、升级)
-
工具系列(文档、聊天、工单、代码)
-
涉及的知识图谱实体(事故类型、产品、服务、客户细分)
-
从LLM或启发式方法派生的流程标签(例如"investigate_alert"、"draft_spec"、"negotiate_contract"、"onboard_customer")
-
轻量级时间特征和结果(例如"已解决P1,MTTR < 30分钟"或"交易已赢得")
我们不会将原始文本(文档正文、消息文本)、用户标识符或客户特定机密带入抽象轨迹中。然后我们计算抽象轨迹之间的相似性,以确定哪些可能涉及相同流程 。
此外,我们只将至少在k个不同用户和n个独立轨迹中出现的模式视为可行,任何过于罕见的模式都会被丢弃以保护匿名性 。
当我们这样做时,我们正在构建"通常会发生什么"、"以什么顺序"以及"为什么这条路径偏离其他类似路径"的概率视图。然后我们使用时间来确定流程的价值。如果类似用户组完成一个流程需要大量时间,那很可能是一个高价值流程。这成为系统的上下文图谱——智能体在看到类似情况时可以依赖的手册 。
我们使用混合模型来存储事件数据:纯图结构是刚性的;原始文本灵活但难以导航。因此我们采用混合模型:取自由格式文本,将其分解为更小的块,并嵌入实体ID。例如,一个事故变成标记转换的短片段——从"调查"到"缓解"——通过用incident_id=INC-123、channel_id=#p1-incidents或action_type=escalated等ID标记它们。这让智能体能够一步步走过流程,有明确的路标,权衡是它没有针对一次推理数千个事故进行优化 。
第五步:从智能体轨迹中学习
最后一个主要步骤是与智能体执行形成闭环。如果智能体在系统外运行,图谱永远无法从中学习。如果它们在系统内运行,每次智能体运行都会成为另一条轨迹 :
-
它调用了哪些工具、以什么顺序、带什么输入和输出
-
运行是否成功完成、运行效率如何,以及用户是否投了反对票或赞成票
-
所有这些学习都在每个企业范围内,专注于智能体如何使用工具,而不是存储底层内容
离线时,我们会回放并尝试替代路线。我们根据正确性、完整性、指令遵循和效率对替代方案进行评分。我们对待智能体轨迹的方式与对待人类轨迹相同 :
-
成功的运行强化你希望系统偏好的模式,成为自然语言手册
-
需要干预的运行突出需要更多上下文或更好工具使用的反模式
随着时间推移,上下文图谱成为人类和智能体行为的联合模型。它不仅描述工作过去如何发生;它反映了现在工作如何展开,因为人类和智能体共享更多工作 。
这就是为什么上下文图谱必须由数据层和编排层共同拥有。对于高价值流程——事故响应、销售交易、产品开发——你需要两者:一个捕获企业结构化、流程感知模型的上下文层,以及一个可以计划、迭代和生成轨迹的执行层。将它们分开会产生漂移:图谱以一种方式演化,智能体执行以另一种方式演化,你最终会得到两个不同的现实版本 。
将图谱和编排保持在一个系统中,确保智能体始终基于企业实际工作方式的实时演化模型 。
四、Glean的实践之路:从内部测试到产品化
4.1 内部验证先行
构建上下文图谱是一项重大投资,我们在构建之前实际上在内部测试了这个概念。我们通过依赖已经构建的技术——个人图谱——为Glean手动创建了一个上下文图谱 。
我们邀请Glean的员工选择加入共享他们的个人图谱数据,这些数据捕获了他们从事的项目、遵循的步骤序列以及花费的时间。通过时间元素,我们能够区分低价值和高价值流程。然后我们查看哪些团队具有相同的、重复的高价值流程,如"AE中端市场交易周期"、"SE概念验证"、"值班事故响应"、"PM功能发布"等 。
我们获取这些工作的事件序列,并与主题专家验证完成工作的A路径与D路径,何时存在偏差以及原因。我们还查看了我们的盲点,或因为没有爬取正确数据或缺乏支持给定步骤的行为而缺失的步骤。然后,我们投入资源将这些高价值流程(经Glean和客户需求验证)转化为在Glean中实际运作的智能体 。
4.2 从静态到动态:持续演化的目标
虽然这些智能体成为当前状态的静态表示,但这不是我们的最终目标。我们想要上下文图谱。这是因为最优路径会演化,所有权会变化,新工具会出现等等 。
我们使用上下文图谱的目标不仅仅是铸造一套静态的智能体,而是持续为智能体提供来自图谱的新流程洞察,并将更多逻辑推入该学习层,而不是不断依赖手动指令。这就是我们认为如何获得自主运行的长期智能体的方法 。
在Glean,我们即将将其变为现实 。
五、结语:上下文图谱的战略意义
上下文图谱不仅仅是一个技术创新,它代表了企业AI应用的根本性转变——从理解"是什么"到理解"如何做",从静态知识库到动态流程模型,从人工操作到智能自动化。
对于企业、机构和投资者而言,上下文图谱的价值在于:
- 真实流程洞察
: 捕获工作实际如何完成,而非理想状态
- 智能自动化基础
: 为AI智能体提供可靠的流程知识
- 持续学习能力
: 从人类和智能体的行为中不断优化
- 隐私与安全
: 在保护用户隐私的前提下提取集体智慧
- 长期价值
: 随着使用而不断改进,形成企业独特的流程资产
正如投资者所预见的,这确实是一个万亿美元的机遇。上下文图谱将成为企业数字化转型的下一个核心基础设施,就像数据库、云计算一样不可或缺 。
相关标签
#ContextGraph #EnterpriseAI #上下文图谱 #企业智能化 #流程自动化 #知识图谱
原文链接
想了解更多关于上下文图谱的信息?请访问Glean官网查看原文,或注册免费演示
关于Glean
Glean是企业AI搜索和知识管理领域的领导者,致力于构建能够真正理解企业工作流程的智能系统。通过深度集成、知识图谱和上下文图谱技术,Glean帮助全球企业实现工作的智能化和自动化 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)