LangChain 结构化输出:让大模型输出 “对机器友好” 的结构化数据
本文介绍了 LangChain 的 .with_structured_output() 方法,它能让大模型直接输出 Pydantic 对象、TypedDict 或 JSON 等结构化数据,避免了繁琐的字符串解析。文章详细讲解了该方法的核心使用步骤、不同输出格式的实现方式,以及在信息提取、工具结合等场景中的应用。通过示例代码,展示了如何将大模型的自然语言输出转化为对程序友好的结构化数据,从而提升开发
目录
在与大模型交互时,我们常常会遇到一个痛点:模型返回的自然语言虽然对人类友好,但对程序却极不友好。如果我们想从文本中提取关键信息,就需要编写复杂且易出错的解析代码。
LangChain 的 .with_structured_output() 方法正是为了解决这个问题。它允许我们预先定义一个期望的数据结构,并要求大模型必须按照这个结构返回信息,从而实现从 “字符串” 到 “对象” 的范式转换。
一、什么是结构化输出?
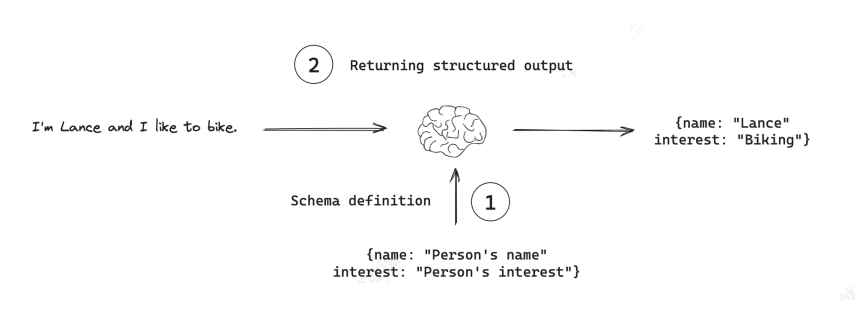
结构化输出是一种聊天模型技术,它可以指示模型使用特定的输出结构(例如 JSON)进行响应。这种需求源于我们希望将模型输出存储在数据库中,并确保其符合数据库模式。
在没有这个功能之前,我们调用聊天模型得到的是一个 AIMessage,其内容是一个字符串。例如:
response = model.invoke("告诉我关于苹果公司的最新消息。")
print(response.content)
# 输出: "苹果公司将于昨日发布了新款iPhone...其股价上涨了26..."
这个字符串对人类阅读很友好,但对程序不友好。我们需要编写复杂的解析代码(如正则表达式)来提取 “公司名” 和 “股价变化”,这不仅繁琐,还容易出错。
而 .with_structured_output() 方法则允许我们预先定义一个期望的数据结构,并要求大模型必须按照这个结构返回信息。
二、核心使用方法
使用 .with_structured_output() 的步骤非常清晰:
- 定义输出结构:可以是 Pydantic 模型、TypedDict 或 JSON Schema。
- 绑定结构到模型:通过
model.with_structured_output(schema)得到一个新的可运行实例。 - 调用新模型:使用新实例进行推理,返回的将是结构化对象,而非字符串。
1. 返回 Pydantic 对象
Pydantic 是最常用的方式,它提供了强大的数据验证功能。我们可以定义一个 Pydantic 模型,然后将其作为 schema 传入。
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# 1. 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 定义输出结构: Pydantic 类
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
# 3. 绑定结构并执行
structured_model = model.with_structured_output(Joke)
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result)
打印结果:
Joke(setup='为什么歌手总是喜欢在洗手间唱歌?', punchline='因为那里有很好的回音壁啊!', rating=9)
我们还可以返回一个 Pydantic 对象的列表:
class Data(BaseModel):
"""获取关于笑话的数据。"""
jokes: List[Joke]
structured_model = model.with_structured_output(Data)
result = structured_model.invoke("分别讲一个关于唱歌和跳舞的笑话")
print(result)
打印结果
Data(
jokes=[
Joke(setup='为什么唱歌的人总是很有 punch?', punchline='因为他们总是“乐”在其中!', rating=8),
Joke(setup='一个跳舞的牛走进俱乐部,为什么大家都不理它?', punchline='因为它总“跳”错门!', rating=7)
]
)
2. 返回 TypedDict
TypedDict 为字典对象提供精确的、结构化的类型提示,在 Python 3.8+ 中非常实用。
from typing import TypedDict, Annotated
class Joke(TypedDict):
"""给用户讲一个笑话。"""
setup: Annotated[str, ..., "这个笑话的开头"]
punchline: Annotated[str, ..., "这个笑话的妙语"]
rating: Annotated[Optional[int], None, "从1到10分,给这个笑话评分"]
structured_model = model.with_structured_output(Joke)
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result)
打印结果:
{'setup': '为什么歌手总是喜欢在洗手间唱歌?', 'punchline': '因为他们有很好的回音壁!', 'rating': 7}
如果设置 include_raw=True,返回的将是一个包含原始消息和解析结果的字典:
structured_model = model.with_structured_output(Joke, include_raw=True)
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result)
打印结果:
{
'raw': AIMessage(content='...', ...),
'parsed': {'setup': '...', 'punchline': '...', 'rating': 7},
'parsing_error': None
}
3. 返回 JSON
我们也可以让大模型直接返回 JSON,这需要我们定义一个 JSON Schema。
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
# 定义 JSON Schema
json_schema = {
"title": "Joke",
"description": "给用户讲一个笑话。",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "这个笑话的开头"
},
"punchline": {
"type": "string",
"description": "这个笑话的妙语"
},
"rating": {
"type": "integer",
"description": "从1到10分,给这个笑话评分",
"default": None
}
},
"required": ["setup", "punchline"]
}
structured_model = model.with_structured_output(json_schema)
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result)
打印结果:
{'setup': '为什么唱歌的人总是很开心?', 'punchline': '因为他们总有很多音(因)可选啊!', 'rating': 7}
4. 选择输出格式
我们还可以创建具有联合类型属性的输出模式,以支持多种输出格式。
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Optional, Union
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
class ConversationalResponse(BaseModel):
"""以对话的方式回应,例如:你好,乐于助人。"""
response: str = Field(description="对用户咨询的会话响应")
class FinalResponse(BaseModel):
final_output: Union[Joke, ConversationalResponse]
structured_model = model.with_structured_output(FinalResponse)
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result)
result = structured_model.invoke("你好")
print(result)
打印结果:
FinalOutput(final_output=Joke(setup='为什么歌手总是带着梯子?', punchline='因为他们想要达到更高的音高!', rating=8))
FinalOutput(final_output=ConversationalResponse(response='你好啊!有什么我可以帮助你的吗?'))
三、实用场景
结构化输出的应用场景非常广泛,以下是几个典型的例子:
场景 1:作为信息提取器
我们可以利用结构化输出从非结构化的文本中精准提取关键信息。
from langchain_openai import ChatOpenAI
from typing import Optional
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, SystemMessage
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出结构
class Person(BaseModel):
"""一个人的信息。"""
name: Optional[str] = Field(default=None, description="这个人的姓名")
hair_color: Optional[str] = Field(default=None, description="如果知道这个人头发的颜色")
skin_color: Optional[str] = Field(default=None, description="如果知道这个人的肤色")
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的身高")
structured_model = model.with_structured_output(schema=Person)
messages = [
SystemMessage(content="你是一个提取信息的专家,只从文本中提取相关信息。如果某些不知道需要提取的值,请留空。"),
HumanMessage(content="Anna 是一个 26 岁的金发女孩,身高 1.63 米。")
]
result = structured_model.invoke(messages)
print(result)
打印结果:
Person(name='Anna', hair_color='金发', skin_color=None, height_in_meters='1.63')
场景 3:与工具结合使用(分步拆解版)
当需要同时使用结构化输出和其他工具时,我们需要注意顺序,不要弄反。下面是更清晰的分步拆解方式:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 1. 定义结构化输出结果
class SearchResult(BaseModel):
"""结构化搜索结果。"""
query: str = Field(description="搜索查询")
findings: str = Field(description="调查结果摘要")
# 2. 定义工具
@tool
def web_search(query: str) -> str:
"""在网上搜索信息。"""
# 模拟搜索结果
return f"西安今天多云转小雨,气温18-23度,东南风2级,空气质量良好"
# 3. 先将工具绑定到原始模型
model_with_tools = model.bind_tools([web_search])
# 4. 构造消息
messages = [
HumanMessage("搜索当前最新的西安的天气")
]
# 5. 第一次调用:让模型决定是否调用工具
ai_msg = model_with_tools.invoke(messages)
# 6. 检查并执行工具调用
if ai_msg.tool_calls:
tool_call = ai_msg.tool_calls[0]
tool_msg = web_search.invoke(tool_call)
messages.append(ai_msg)
messages.append(tool_msg)
# 7. 第二次调用:使用结构化输出模型,处理包含工具结果的消息列表
structured_search_model = model_with_tools.with_structured_output(SearchResult)
result = structured_search_model.invoke(messages)
print(result)
打印结果:
SearchResult(query='西安天气', findings='西安今天多云转小雨,气温18-23度,东南风2级,空气质量良好')
这次的结果符合我们的预期,但依旧略显麻烦,因为我们实际上调用了两次模型:
- 第一次调用模型:模型返回了工具调用,然后我们执行工具,将工具结果加入消息列表。
- 第二次调用:我们使用结构化输出
SearchResult的模型,来处理整个消息列表(包含工具调用的结果),然后输出结构化结果。
有没有只手动调用一次(实际上允许调用两次模型)就能获取到结构化输出的结果呢?将来在学习 LangChain 部分的 Agent 就可以做到这件事。
四、总结
LangChain 的 .with_structured_output() 方法是一个强大的工具,它彻底改变了我们与大模型交互的方式。通过将输出结构化,我们可以:
- 消除解析代码:不再需要编写复杂的字符串解析逻辑。
- 保证数据质量:利用 Pydantic 等库进行严格的数据验证。
- 提升开发效率:直接将模型输出用于下游任务,如数据库存储、API 响应等。
无论是信息提取、工具调用还是构建复杂的 AI 应用,结构化输出都能让你的代码更加健壮、清晰和高效。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)