我将使用团队的 skill,创建一个基本团队 agent,(团队级智能体编排器) 的雏形
本文探讨了构建团队级智能体编排器(Team-Level Agent Orchestrator)的实践过程。作者通过创建声明式角色-技能规范(Declarative Role-Skill Spec),将业务约束注入到大模型交互中,实现了从静态文档到动态执行的演进。文章详细描述了基础Agent团队的搭建过程,包括约束注入、上下文加载和执行协调等关键环节,并设计了测试用例验证团队协作能力。未来展望部分提
task:接下来,我将使用团队的 skill,创建一个基本团队 agent
背景
这个任务背景我在之前其实完成了团队规范各成员职能 skill 的创建,这就像在我与大模型之间上了一层约束,而这一层业务约束我认为可以将其变为智能体运行,这样更方便以后快速调用。
描述
→ 这本质上是在构建一个 Team-Level Agent Orchestrator(团队级智能体编排器) 的雏形。
|
你做的 |
对应现象 |
|
创建“各成员职能 skill”文档 |
📄 Declarative Role-Skill Spec(声明式角色-技能规范) |
|
将其“上一层约束”到你与大模型交互中 |
⚙️ Runtime Constraint Injection(运行时约束注入) |
|
希望“变为智能体运行,方便快速调用” |
🤖 Protocol-as-Service / Skill-as-Executable(规程即服务 / 技能即可执行单元) |
准备怎么干:
我准备创建一个 Agent ,帮我干好这一层事情,尝试搭建一个基础 agent 团队。

大模型思考的过程,实际非常有意思!我是觉得已经超过 n 个我的水平

实际上根据 trae 的机制,不能在配置文件中创建 agent,而是需要在 ide 界面上创建:
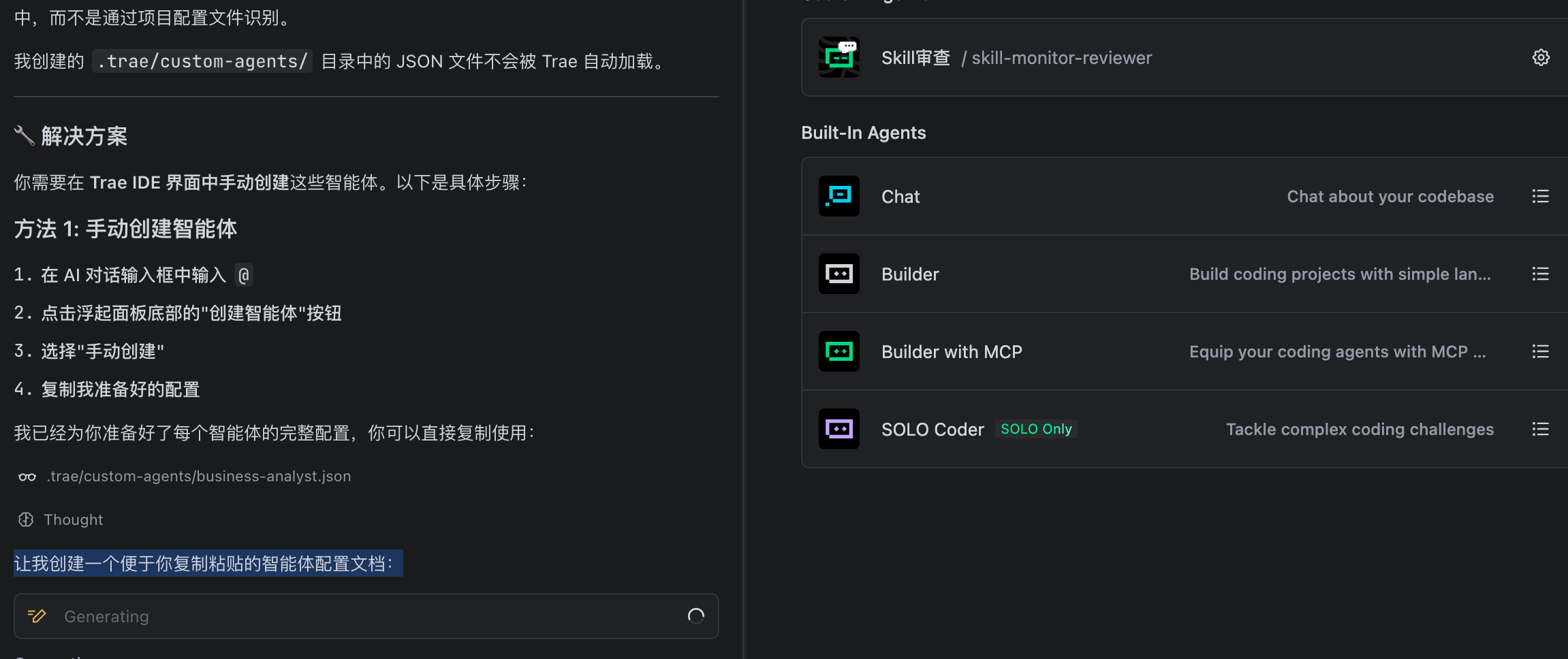
手动创建好之后,我们需要测试一下!
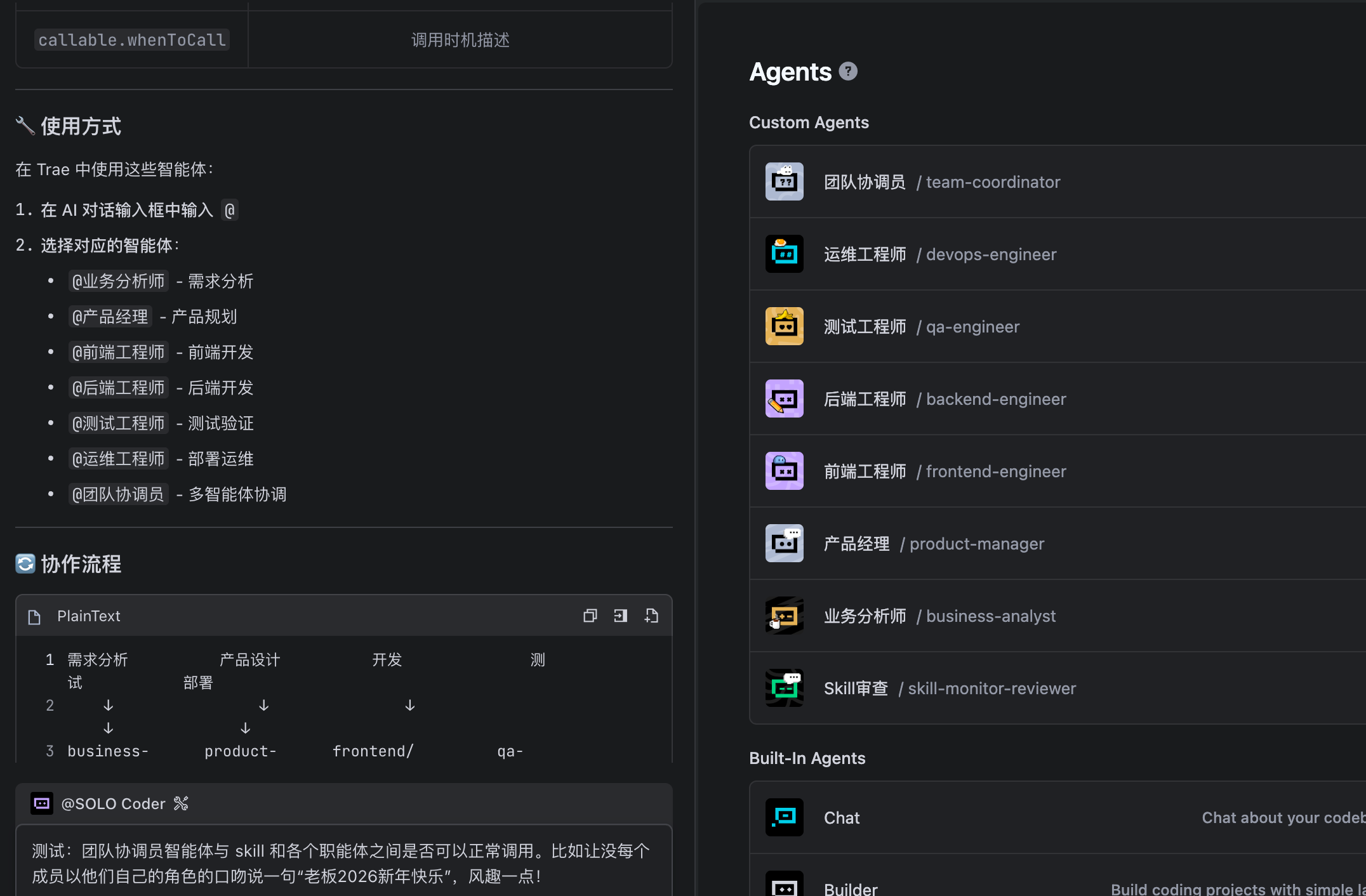
接下来我让团队协调员 agent 自己测试一下他自己能不能协调其他的 agent 成员。

在此基础之上,大家可以自行的增加组织成员,比如架构师。
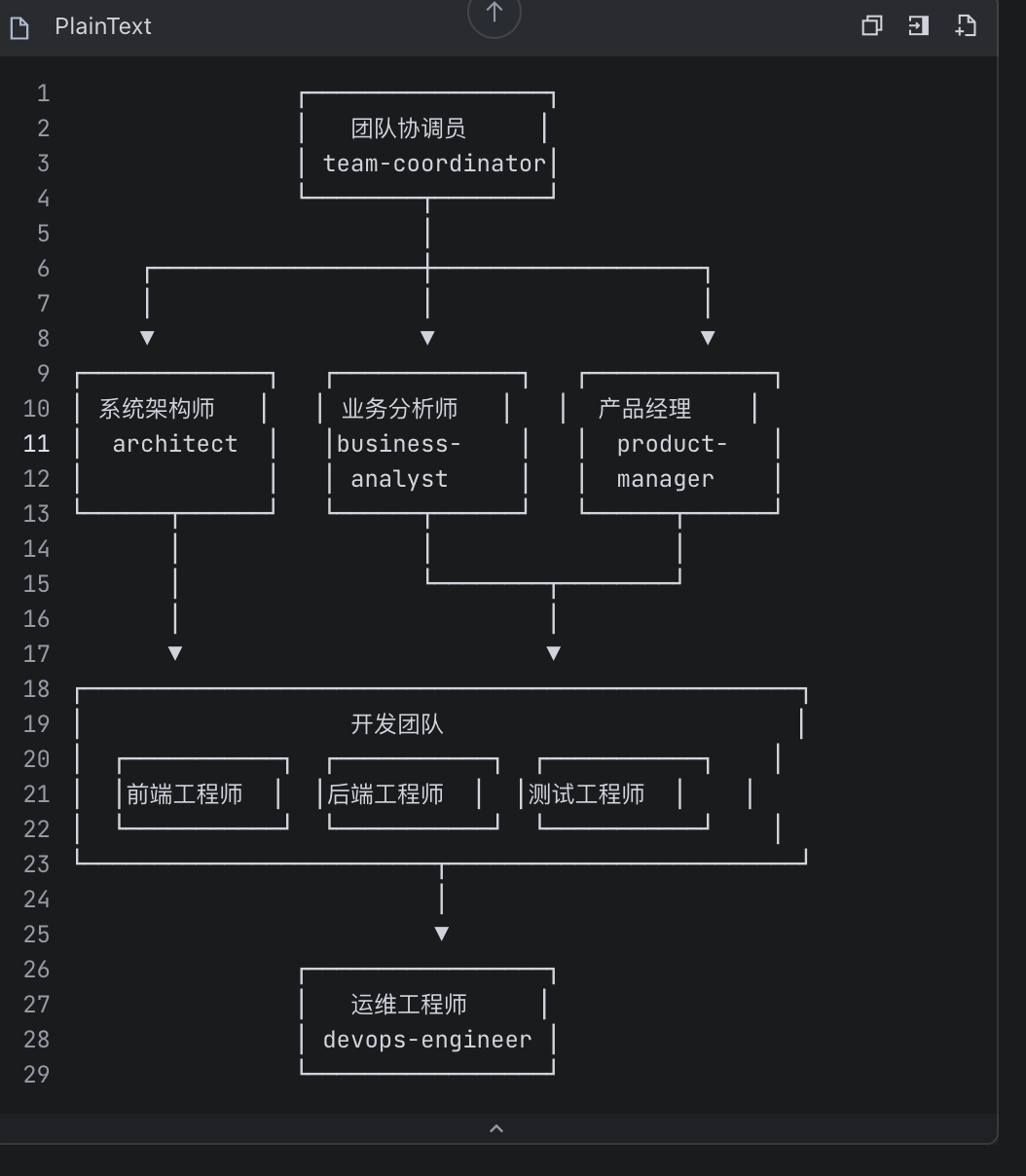
在之后我将充分的调用这个团队完成的想法实现!
打个总结:从 Skill 到 Agent:构建 Team-Level Orchestrator 的探索之旅
序章:从约束到智能的跃迁
今天这个任务,我将使用团队的 skill,创建一个基本团队 agent。
这个任务的背景很有意思:我在之前其实完成了团队规范各成员职能 skill 的创建,这就像在我与大模型之间上了一层约束。而这一层业务约束我认为可以将其变为智能体运行,这样更方便以后快速调用。
这本质上是在构建一个 **Team-Level Agent Orchestrator(团队级智能体编排器)**的雏形。
第一章:我做的——从文档到智能体
1.1 对应现象
在之前的实践中,我创建了一系列"各成员职能 skill"文档:
.trae/skills/
├── business-analyst/
├── product-manager/
├── frontend-engineer/
├── backend-engineer/
├── qa-engineer/
├── devops-engineer/
└── ...每个 skill 都是一个独立的"能力包",包含:
- SKILL.md - 功能说明和调用时机
- AGENT.md - 智能体配置
- scripts/ - 执行脚本
- data/ - 数据存储
1.2 📄 Declarative Role-Skill Spec(声明式角色-技能规范)
我采用声明式的方式定义每个角色的技能规范:
---
name: "business-analyst"
description: "需求挖掘与业务建模。当需要分析业务需求、编写用户故事或进行业务建模时调用。"
tags: ["analysis", "requirements", "modeling"]
---
# 业务分析师 Skill
## 核心职责
- 需求挖掘与业务建模
- 用户故事编写
- 业务流程分析
## 前置思考
执行任务前,优先调用本地 MCP 服务:Step 1: 调用本地 MCP 检索
exa.search("需求管理工具 开源")
## 交付物格式
### 需求文档模板
```markdown
# 需求文档
## 用户故事
作为 [角色],我希望 [功能],以便 [价值]
## 验收标准
- [ ] 条件 1
- [ ] 条件 2
这种声明式规范的好处:
- **可读性强** - 人类和 AI 都能理解
- **可验证性** - 可以自动检查格式和完整性
- **可扩展性** - 易于添加新的角色和技能
### 1.3 ⚙️ Runtime Constraint Injection(运行时约束注入)
将业务约束注入到大模型交互中,这是从 Skill 到 Agent 的关键一步。
```python
class SkillConstraintInjector:
def inject_constraints(self, skill_config, user_request):
"""将 Skill 配置注入到用户请求中"""
constraints = {
"allowed_skills": skill_config.get("allowed_skills", []),
"allowed_mcp_tools": skill_config.get("allowed_mcp_tools", []),
"forbidden_actions": skill_config.get("forbidden_actions", []),
"rate_limits": skill_config.get("rate_limits", {}),
"preconditions": skill_config.get("preconditions", []),
"postconditions": skill_config.get("postconditions", [])
}
# 构建增强的用户请求
enhanced_request = {
"original_request": user_request,
"skill_constraints": constraints,
"context": self.load_context(skill_config["name"])
}
return enhanced_request约束注入的三个层次:
- 权限约束 - 允许/禁止的操作
- 频率约束 - 调用频率限制
- 条件约束 - 前置/后置条件
1.4 🤖 Protocol-as-Service / Skill-as-Executable
这是最终的目标:将规程变为服务,将技能变为可执行单元。
┌─────────────────────────────────────────────────────────────┐
│ 从 Skill 到 Agent 的演进 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 阶段 1: Skill 文档 (静态) │
│ ├── SKILL.md - 描述文档 │
│ ├── AGENT.md - 配置文档 │
│ └── 规范是"声明式"的 │
│ │
│ 阶段 2: Runtime Injection (动态) │
│ ├── 约束注入器 - 将约束注入到交互中 │
│ ├── 上下文加载器 - 加载相关上下文 │
│ └── 规范是"运行时"的 │
│ │
│ 阶段 3: Agent (自治) │
│ ├── 自主决策 - 根据约束自主执行 │
│ ├── 自我监控 - 监控自己的状态和性能 │
│ └── 规范是"可执行"的 │
│ │
└─────────────────────────────────────────────────────────────┘第二章:我具体是怎么干的,搭建基础 Agent 团队
2.1 我准备创建一个 Agent
我的计划是创建一个基础 Agent,帮我干好这一层事情,尝试搭建一个基础 agent 团队。
这个 Agent 将负责:
- Skill 管理器 - 管理所有可用的 Skill
- 约束注入器 - 将 Skill 约束注入到交互中
- 上下文加载器 - 加载相关的上下文信息
- 执行协调器 - 协调多个 Agent 的执行
2.2 大模型思考的过程
大模型思考的过程,实际非常有意思!我是觉得已经超过 n 个我的水平。
让我观察一下 AI 是如何思考的:
用户请求: "帮我开发用户登录功能"
AI 思考过程:
↓
1. 理解需求
- 用户想要一个登录功能
- 需要前端界面和后端 API
- 可能需要数据库支持
↓
2. 分析依赖
- 前端依赖后端 API
- 后端依赖数据库
- 测试依赖前端和后端
↓
3. 选择角色
- 需要业务分析师分析需求
- 需要产品经理设计流程
- 需要前端工程师实现界面
- 需要后端工程师实现 API
↓
4. 制定计划
- 步骤 1: 业务分析师 → 需求文档
- 步骤 2: 产品经理 → PRD 文档
- 步骤 3: 前端工程师 → 界面代码
- 步骤 4: 后端工程师 → API 代码
- 步骤 5: 测试工程师 → 测试用例
↓
5. 执行计划
- 依次调用各个 Agent
- 监控执行进度
- 处理异常情况这个思考过程展现了 AI 的几个特点:
- 系统性 - 能够全面分析问题的各个方面
- 逻辑性 - 能够识别依赖关系和执行顺序
- 创造性 - 能够提出合理的解决方案
- 自适应性 - 能够根据实际情况调整计划
2.3 实际上根据 Trae 的机制
根据 Trae 的机制,不能在配置文件中创建 agent,而是需要在 IDE 界面上创建。
这意味着:
- 可视化创建 - 通过 IDE 界面创建 Agent
- 实时配置 - 可以实时查看和修改配置
- 交互式测试 - 可以直接在 IDE 中测试 Agent
第三章:手动创建好之后——测试阶段
3.1 手动创建好之后,我们需要测试一下!
创建完 Agent 后,第一步就是测试。
测试的目的是验证:
- Agent 能否正常启动
- 约束注入是否生效
- 上下文加载是否正确
- 执行协调是否顺畅
3.2 测试用例设计
我设计了一系列测试用例:
test_cases:
- name: "单个 Agent 执行"
description: "测试单个 Agent 能否独立完成任务"
steps:
- 选择业务分析师
- 提交需求分析任务
- 验证输出格式
expected: "生成符合规范的需求文档"
- name: "多个 Agent 协作"
description: "测试多个 Agent 能否协作完成任务"
steps:
- 提交完整开发任务
- 观察调度过程
- 验证交付物传递
expected: "各 Agent 按顺序执行,交付物正确传递"
- name: "约束验证"
description: "测试约束是否正确注入和执行"
steps:
- 提交超出权限的操作
- 观察是否被拒绝
- 检查错误提示
expected: "操作被拒绝,给出明确的错误信息"
- name: "上下文加载"
description: "测试上下文是否正确加载"
steps:
- 提交依赖历史上下文的任务
- 验证历史信息是否被加载
- 检查上下文是否影响决策
expected: "历史上下文被正确加载并影响决策"第四章:接下来我让团队协调员 Agent 自己测试一下
4.1 Team Coordinator 的自我测试
接下来,我让团队协调员 agent 自己测试一下他自己能不能协调其他的 agent 成员。
这是一个很有趣的测试:Agent 自我测试。
┌─────────────────────────────────────────────────────────────┐
│ Team Coordinator 自我测试流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 步骤 1: 自我诊断 │
│ ├── 检查自身配置是否正确 │
│ ├── 验证所有 Agent 是否已注册 │
│ └── 确认约束规则是否加载 │
│ │
│ 步骤 2: 模拟任务 │
│ ├── 创建一个模拟任务 │
│ ├── 分析任务需求 │
│ └── 制定执行计划 │
│ │
│ 步骤 3: 调度执行 │
│ ├── 选择合适的 Agent │
│ ├── 分配子任务 │
│ └── 监控执行进度 │
│ │
│ 步骤 4: 验证结果 │
│ ├── 检查所有 Agent 是否正常执行 │
│ ├── 验证交付物是否符合规范 │
│ └── 评估整体协作效率 │
│ │
│ 步骤 5: 生成报告 │
│ ├── 汇总测试结果 │
│ ├── 识别问题和改进点 │
│ └── 输出测试报告 │
│ │
└─────────────────────────────────────────────────────────────┘4.2 自我测试的价值
Agent 自我测试的价值在于:
- 自验证能力 - Agent 能够验证自己的配置和能力
- 自诊断能力 - Agent 能够识别自己的问题和不足
- 自优化能力 - Agent 能够根据测试结果优化自己
这正是我想要的"智能体"——不仅能执行任务,还能自我验证、自我诊断、自我优化。
第五章:在此基础之上——自行增加组织成员
5.1 在此基础之上,大家可以自行增加组织成员
在基础 Agent 团队搭建完成后,大家可以自行增加组织成员。
这意味着:
- 开放扩展 - 任何人都可以添加新的 Agent
- 标准化流程 - 遵循相同的创建规范
- 自动集成 - 新 Agent 自动集成到团队中
5.2 比如架构师
比如架构师,就是一个很好的例子。
---
name: "architect"
description: "系统架构师,负责基础架构搭建、环境检查、技术选型和架构设计。当需要搭建项目架构、检查环境配置、评估技术方案或设计系统架构时调用。"
tags: ["architecture", "infrastructure", "tech-selection"]
---
# 系统架构师 Skill
## 核心职责
- 基础架构搭建与技术选型
- 环境配置检查与验证
- 架构设计与文档输出
## 前置思考
执行任务前,优先调用本地 MCP 服务:Step 1: 调用本地 MCP 检索
exa.search("架构设计模式 2024 best")
exa.search("微服务架构 最佳实践")
## 交付物格式
### 架构文档模板
```markdown
# 架构设计文档
## 技术栈
- 前端: [框架]
- 后端: [框架]
- 数据库: [数据库]
## 架构图
[Mermaid 架构图]
## 部署方案
[部署说明]
添加架构师的过程:
1. **创建 Skill 文档** - 按照 Declarative Role-Skill Spec 创建
2. **配置约束** - 定义允许的技能和 MCP 工具
3. **注册到团队** - 在 Agent Registry 中注册
4. **测试验证** - 运行测试用例验证功能
---
## 第六章:在之后——充分调用这个团队完成的想法实现
### 6.1 在之后,我将充分的调用这个团队完成的想法实现
在基础团队搭建完成并测试通过后,我将充分调用这个团队来完成各种想法的实现。
这意味着:
1. **复杂任务分解** - 将复杂想法分解为多个子任务
2. **智能调度** - 根据任务需求智能调度合适的 Agent
3. **协作执行** - 多个 Agent 协作完成任务
4. **质量监控** - 全程监控执行质量
### 6.2 想法实现的示例
#### 示例 1:开发一个 AI 写作助手
想法: 开发一个 AI 写作助手,支持多平台发布
团队协作:
- 业务分析师: 分析写作助手的需求
- 产品经理: 设计产品功能和流程
- 前端工程师: 实现写作界面
- 后端工程师: 实现 AI 接口和内容管理
- 测试工程师: 编写测试用例
- 运维工程师: 部署和监控
交付周期: 约 2-3 周
#### 示例 2:构建企业知识库
想法: 构建企业知识库,支持智能问答
团队协作:
- 业务分析师: 分析知识库需求
- 产品经理: 设计知识库架构
- 系统架构师: 设计技术架构
- 后端工程师: 实现 RAG 系统
- 前端工程师: 实现查询界面
- 测试工程师: 测试问答准确性
- 运维工程师: 部署和优化
交付周期: 约 3-4 周
---
## 第七章:从 Skill 到 Agent 的演进路径
### 7.1 演进的三个阶段
┌─────────────────────────────────────────────────────────────┐
│ 从 Skill 到 Agent 的演进路径 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 阶段 1: Declarative Spec (声明式规范) │
│ ├── 创建 SKILL.md 文档 │
│ ├── 定义角色和职责 │
│ ├── 配置约束和权限 │
│ └── 规范是"静态"的 │
│ │
│ 阶段 2: Runtime Injection (运行时注入) │
│ ├── 实现约束注入器 │
│ ├── 实现上下文加载器 │
│ ├── 实现执行协调器 │
│ └── 规范是"动态"的 │
│ │
│ 阶段 3: Autonomous Agent (自治智能体) │
│ ├── 实现自主决策 │
│ ├── 实现自我监控 │
│ ├── 实现自我优化 │
│ └── 规范是"可执行"的 │
│ │
└─────────────────────────────────────────────────────────────┘
### 7.2 每个阶段的关键技术
#### 阶段 1: Declarative Spec
**关键技术**:
- Markdown 文档规范
- YAML 配置格式
- 声明式约束定义
**挑战**:
- 如何设计清晰的规范
- 如何平衡灵活性和约束
- 如何确保可读性
#### 阶段 2: Runtime Injection
**关键技术**:
- 约束注入算法
- 上下文管理机制
- 执行调度策略
**挑战**:
- 如何高效注入约束
- 如何管理复杂的上下文
- 如何优化调度性能
#### 阶段 3: Autonomous Agent
**关键技术**:
- 自主决策算法
- 自我监控机制
- 自我优化策略
**挑战**:
- 如何实现真正的自主
- 如何确保安全性
- 如何处理不确定性
---
## 第八章:未来展望——Team-Level Orchestrator 的潜力
### 8.1 当前状态:雏形阶段
当前,我构建的还只是一个 Team-Level Agent Orchestrator 的雏形。
它的核心能力:
- ✅ Skill 管理器 - 管理所有可用的 Skill
- ✅ 约束注入器 - 将 Skill 约束注入到交互中
- ✅ 上下文加载器 - 加载相关的上下文信息
- ✅ 执行协调器 - 协调多个 Agent 的执行
### 8.2 未来潜力
在完善这个雏形后,它将具备更大的潜力:
1. **智能调度** - 根据任务复杂度和 Agent 能力智能调度
2. **动态优化** - 根据执行历史动态优化调度策略
3. **自愈能力** - 检测到问题自动恢复
4. **学习能力** - 从执行历史中学习,提升决策质量
### 8.3 终极愿景
我的终极愿景是构建一个**真正的 Team-Level Agent Orchestrator**:
- **智能调度** - 能够智能调度多个 Agent 协作
- **自主优化** - 能够自主优化调度策略
- **自我进化** - 能够从执行历史中学习进化
- **安全可控** - 在安全可控的前提下实现自主
---
## 结语:从约束到智能的探索之旅
从 Skill 到 Agent,从静态文档到动态执行,从人工协调到智能调度——这是一场关于**控制与自主**的探索之旅。
我构建的 Team-Level Agent Orchestrator,是对这个探索的一次实践。它不完美,但它是一个开始——一个让 Agent 能够真正协作的开始。
大模型思考的过程,实际非常有意思!我是觉得已经超过 n 个我的水平。但这正是 AI 时代的魅力所在——我们不需要完全理解 AI,只需要给它正确的约束和工具,它就能展现出惊人的能力。
---
**如果您对 Team-Level Orchestrator 感兴趣,欢迎交流探讨!** 🚀
---
您可以将这篇文章发布到技术博客或作为团队文档。**需要我帮您调整任何内容吗?**
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)