AI Agent 开源软件txtai的RAG实践之一
引言及背景知识
想了解AI Agent具体是如何工作的,并且想实际体验一下RAG的效果,所以想获取一个简单的开源AI Agent来入门,询问DeepSeek推荐了txtai开源软件。
AI Agent(智能体)可以被理解为一个能够自主理解、决策并执行任务的智能程序。
一个典型的AI Agent系统主要由以下几个模块构成:
- 大脑(核心控制器):对应大语言模型
- 感知系统:接收来自外部的输入,如文本、图像、语音、屏幕截图等。
- 记忆模块:包含短期记忆,记录当前对话上下文或任务执行过程中的信息,类似于浏览器的缓存。长期记忆:使用向量数据库存储过去的经验、用户偏好或领域知识,以便在未来任务中调用。RAG 是实现 AI Agent 长期记忆的核心技术方案之一,它通过向量数据库检索历史知识来增强当前生成。
- 工具包:Agent可以调用的外部工具集合。例如:搜索引擎API、计算器、代码解释器、公司的内部API(如CRM系统)、第三方应用(如Gmail、飞书、Slack)等。
- 行动模块:执行最终决定的动作,与外部世界进行交互。
一个简单的RAG系统大概如下图所示: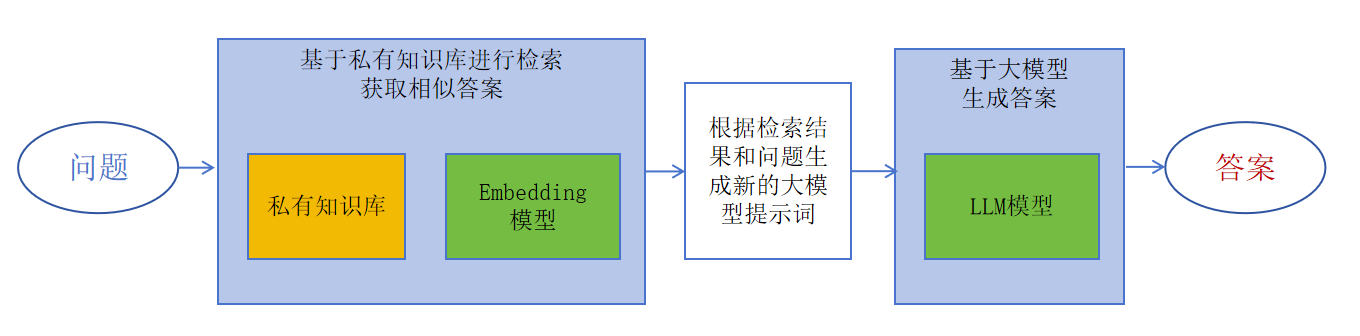
参考下图理解2个模型的差异:
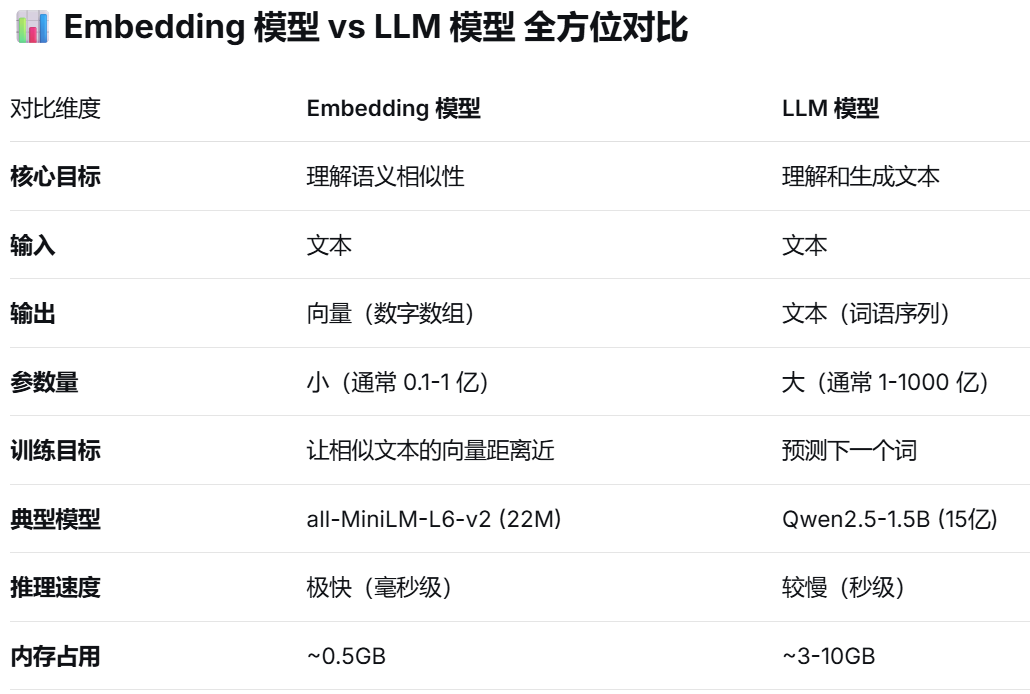
下面开始实践内容:
Txtai软件安装
首先需要创建一个干净的环境,我比较习惯用Anaconda,这个电脑安装好的是miniconda,已经可以运行。
Anaconda有2种命令行,左边的是Powershell,右边的是标准cmd。

先在miniconda中为本次实践测试创建一个新环境:
(base) C:\Users\37995>conda create --name myRAG1 python=3.10
【注意】一定要写明python版本,否则创建的是一个空壳环境
(base) C:\Users\37995>conda activate myRAG1
在创建的conda环境中安装txtai
(myRAG1) C:\Users\37995>pip install txtai
软件包比较多,有的比较大,需要下载比较长的时间
确保这些软件包安装
pip install transformers torch txtai accelerate
最终可以在GPU正常运行RAG测试代码的环境我放到文档的最后,如果运行中遇到问题,可以对照查看软件包的各个版本。
离线下载模型
由于模型很大,加上网络限制问题,推荐使用离线模型,有多种下载模型的方法,我比较习惯用命令行cli方式。
选择cli的方式下载:
先设置hugging face的镜像:
如果是标准cmd界面,用下面的命令设置
set HF_ENDPOINT=https://hf-mirror.com
如果是powershell界面,用下面的命令设置hugging face的镜像
$env:HF_ENDPOINT = "https://hf-mirror.com"
后续的命令都是基于Powershell。
安装
pip install huggingface_hub
网速不好可以额外设置一些环境变量,如下,已经验证OK:
# 1. 设置镜像源(确保走国内加速)
$env:HF_ENDPOINT = "https://hf-mirror.com"
# 2. 设置超时时间为60秒(默认只有10秒)[citation:1][citation:4]
$env:HF_HUB_TIMEOUT = 60
# 3. 设置下载失败后的最大重试次数 [citation:1]
$env:HF_HUB_MAX_RETRIES = 5
# 4. 关闭高速传输模式,因为它虽然快,但极不稳定,是超时的常见元凶 [citation:4][citation:10]
$env:HF_HUB_ENABLE_HF_TRANSFER = 0
# 5. 最后,重新执行你的下载命令
下载Embedding模型:
Txtai默认使用的模型:
hf download sentence-transformers/all-MiniLM-L6-v2 --local-dir D:\nxk\ai_models\all-MiniLM-L6-v2
下载LLM模型
下载txtai默认使用的LLM模型:
hf download google/flan-t5-base --local-dir D:\nxk\ai_models\flan-t5-base
之前下载很慢,中途停止后,重新执行,会断点续传。
【注意】这个模型中文支持很差,不建议使用。
推荐下载千问模型
hf download Qwen/Qwen2.5-1.5B-Instruct --local-dir D:\nxk\ai_models\Qwen2.5-1.5B-Instruct
测试过程
flan-t5-base模型
采用google/flan-t5-base模型遇到的主要问题是:
google/flan-t5-base模型是text2text-generation类型,而txtai软件不支持text2text-generation类型,只支持text-generation类型,或者说是因为transformers新版本对task名称进行了重组/限制,txtai未适配新版transformers的task注册机制,最终原因我也就不纠结了
加载LLM的代码大概是这样:
llm = LLM(LLM_MODEL_PATH) # 直接使用你的本地路径
解决方案是:
方案1,基于txtai软件和google/flan-t5-base模型,放弃txtai的LLM类,直接用Hugging Face加载;
方案2,放弃google/flan-t5-base模型,采用qwen模型。
采用方案一可以解决问题,程序可以完整运行,大概代码如下:
tokenizer = AutoTokenizer.from_pretrained(LLM_MODEL_PATH)
model = AutoModelForSeq2SeqLM.from_pretrained(
LLM_MODEL_PATH,
torch_dtype=torch.float32,
low_cpu_mem_usage=True
)
但是这个模型对中文的支持很差,基本上生成的结果都不可用
放弃
千问模型Qwen2.5-1.5B-Instruct
改为千问模型后,执行效果较好
加载模型代码为
tokenizer = AutoTokenizer.from_pretrained
model = AutoModelForCausalLM.from_pretrained
测试结果展示:
要求代码增加了调试信息,可以看到每一步的步骤,更清楚RAG与LLM是如何配套的。
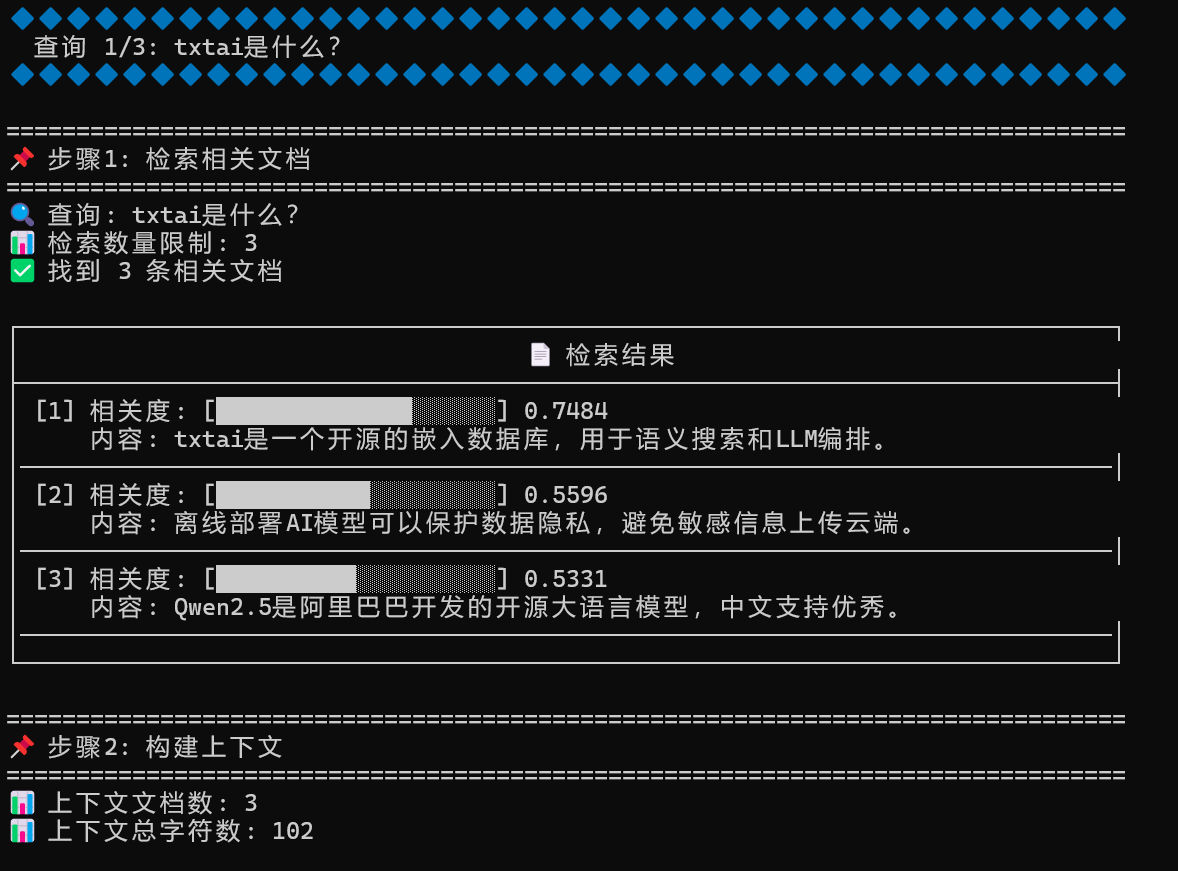
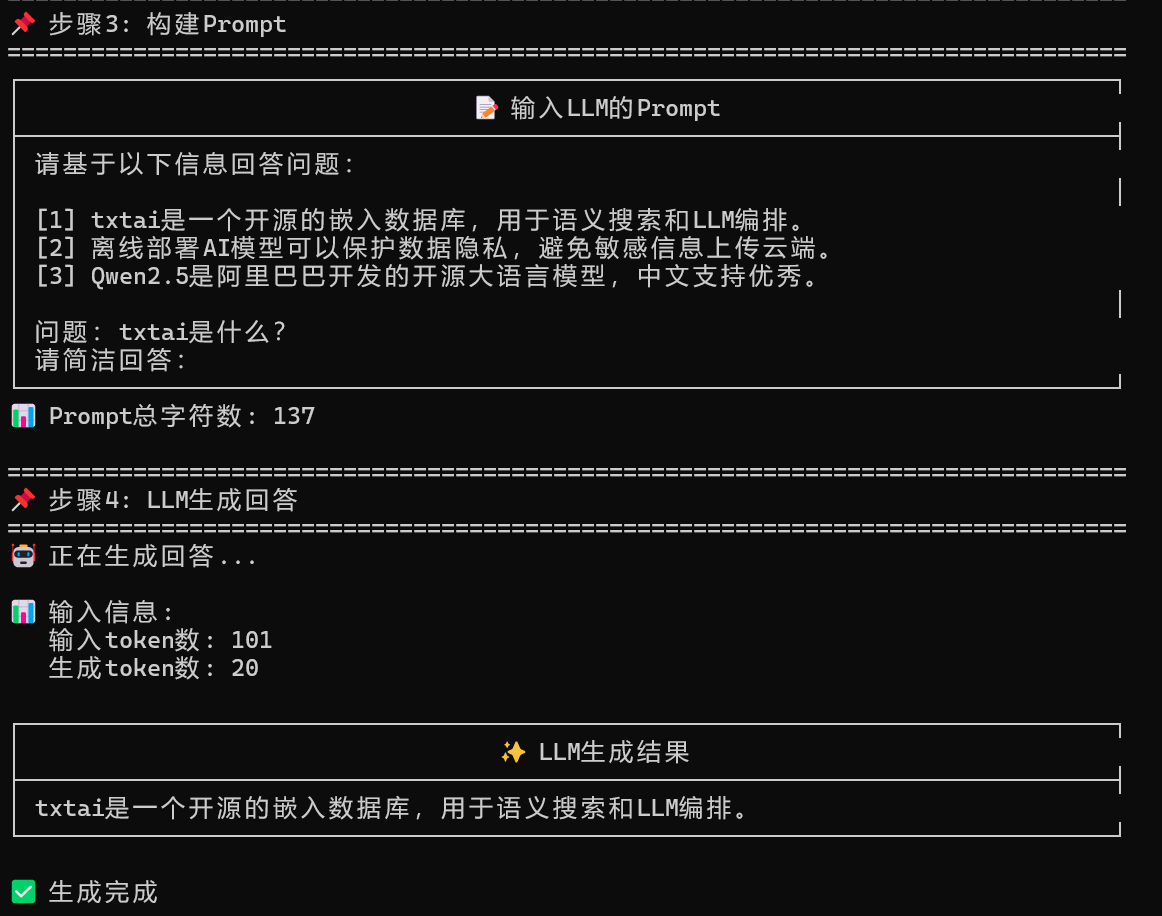
基于千问模型把加载方式改回LLM加载
最早用google/flan-t5-base模型是text2text-generation类型,加载有问题,放弃txtai的LLM类,直接用Hugging Face加载;现在改用千问模型了,就想退回LLM加载的方式。
用DeepSeek修改后的代码在使用qwen模型生成答案的时候,明显速度很慢,风扇转速明显提高,询问DeepSeek的原因是加载模型的参数设置不同,但是也很难一下子改回之前的状态,询问多次也没有效果,感觉是DeepSeek自己找不到根本原因。
后来对比了千问生成的代码,感觉核心原因是加载LLM时的参数不对。
llm = LLM(LLM_MODEL_PATH, trust_remote_code=True)中trust_remote_code=True导致的,去掉之后,改为llm = LLM(LLM_MODEL_PATH),速度明显很快,且听不到风扇声。
【注意】这是当前实践的测试结果,根本原因是什么还不确定。不同AI给出的答案不一样,所以可能后续还需要自己了解一些知识。
使能GPU
我的电脑是联想拯救者,带有GPU RTX4060,所以需要先把GPU用起来。
先运行下面的命令确认GPU是否识别:
python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"
提示 "Torch not compiled with CUDA enabled",说明GPU相关的软件未支持。
解决方案:
步骤1:卸载当前的CPU版本
pip uninstall torch torchvision torchaudio -y
步骤2:安装支持GPU的版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
安装之后执行下面的命令,显示成功
python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"
True
NVIDIA GeForce RTX 4060 Laptop GPU
实际运行GPU测试代码时,仍然遇到问题,软件包还是没有安装完全。
至少需要以下软件包:
cat .\requirements.txt
# requirements.txt
sentence-transformers>=3.0.0
transformers>=4.36.0
torch>=2.0.0
torchvision>=0.15.0
torchaudio>=2.0.0
scikit-learn>=1.0.0
psutil>=5.8.0
numpy>=1.24.0
下面的命令可以自动安装上述软件包。
pip install -r requirements.txt
这些安装成功之后,执行DeepSeek自动生成的测试代码,执行成功
小错误返回DeepSeek修改后即可
第一次成功的代码执行时,仍然听到明显的风扇声音,所以要求DeepSeek重新生成LLM最简配置代码,速度提升较多,生成质量也可以接受。
执行效果参考下图,可以看到
第一个问题(测试1/4)的回答,主要是从索引结果1获取的答案,忽略了索引结果2;
第二个问题(测试2/4)的回答:同时吸取了索引结果1和2,并从大模型LLM中获取了新内容进行了补充;
也就是综合了RAG和LLM的结果。

主要的简化优化项参考:
- do_sample=False - 从概率抽样变成确定性的贪心搜索,直接取最大概率的词,跳过复杂的概率计算
- num_beams=1 - 束搜索本质上是同时探索多个可能性,每个可能性都要完整计算,关闭后计算量直接除以束宽
- max_new_tokens - Transformer的生成是自回归的,每生成一个token都要重新计算,长度直接影响总时间
- 禁用tokenizer并行
- 改用CausalLM方式
本次测试加载LLM的代码大概如下:
self.tokenizer = AutoTokenizer.from_pretrained
self.model = AutoModelForCausalLM.from_pretrained
后来对比千问后,感觉应该还是用llm = LLM(LLM_MODEL_PATH)方式更为合理。但是这样生成的答案效果是否好,还不太确定。
【心得】不同AI生成的代码风格也不同,多问几次同一个AI可能也会每次修改代码,所以需要提示AI尽可能少修改已有代码,只修改必要部分。
加载LLM模型时有很多参数可以设置,应该也会对生成的实际效果有影响,还有待继续观察。
下一步要做的事情
当前测试代码是直接硬编码写入了一些document内容作为私有知识库,后续需要有一个系统来读取各种word文档、pdf文档、图片等,来创建自己的私有知识库,这样才能构建一个完整的系统。
LLM模型的参数影响还有待深入了解。
软件包版本参考:
参考一
Conda环境中,用pip安装时通常会考虑到软件版本的配套性,但是新功能也会额外安装新的软件包,各个软件包的版本配套是个大问题,如下已经成功运行的可供参考:
(myRAG1) PS C:\Users\37995\miniconda3\envs\myRAG1> conda list
# packages in environment at C:\Users\37995\miniconda3\envs\myRAG1:
#
# Name Version Build Channel
accelerate 1.12.0 pypi_0 pypi
annotated-doc 0.0.4 pypi_0 pypi
anyio 4.12.1 pypi_0 pypi
bzip2 1.0.8 h2bbff1b_6
ca-certificates 2025.12.2 haa95532_0
certifi 2026.1.4 pypi_0 pypi
click 8.3.1 pypi_0 pypi
colorama 0.4.6 pypi_0 pypi
exceptiongroup 1.3.1 pypi_0 pypi
expat 2.7.4 hd7fb8db_0
faiss-cpu 1.13.2 pypi_0 pypi
filelock 3.24.3 pypi_0 pypi
fsspec 2026.2.0 pypi_0 pypi
h11 0.16.0 pypi_0 pypi
hf-xet 1.2.0 pypi_0 pypi
httpcore 1.0.9 pypi_0 pypi
httpx 0.28.1 pypi_0 pypi
huggingface-hub 1.4.1 pypi_0 pypi
idna 3.11 pypi_0 pypi
jinja2 3.1.6 pypi_0 pypi
joblib 1.5.3 pypi_0 pypi
libexpat 2.7.4 hd7fb8db_0
libffi 3.4.4 hd77b12b_1
libzlib 1.3.1 h02ab6af_0
markdown-it-py 4.0.0 pypi_0 pypi
markupsafe 3.0.3 pypi_0 pypi
mdurl 0.1.2 pypi_0 pypi
mpmath 1.3.0 pypi_0 pypi
msgpack 1.1.2 pypi_0 pypi
networkx 3.4.2 pypi_0 pypi
numpy 2.2.6 pypi_0 pypi
openssl 3.0.19 hbb43b14_0
packaging 25.0 py310haa95532_1
pillow 12.0.0 pypi_0 pypi
pip 26.0.1 pyhc872135_0
psutil 7.2.2 pypi_0 pypi
pygments 2.19.2 pypi_0 pypi
python 3.10.19 h981015d_0
pyyaml 6.0.3 pypi_0 pypi
regex 2026.2.19 pypi_0 pypi
rich 14.3.3 pypi_0 pypi
safetensors 0.7.0 pypi_0 pypi
scikit-learn 1.7.2 pypi_0 pypi
scipy 1.15.3 pypi_0 pypi
sentence-transformers 5.2.3 pypi_0 pypi
setuptools 80.10.2 py310haa95532_0
shellingham 1.5.4 pypi_0 pypi
sqlite 3.51.1 hda9a48d_0
sympy 1.13.1 pypi_0 pypi
threadpoolctl 3.6.0 pypi_0 pypi
tk 8.6.15 hf199647_0
tokenizers 0.22.2 pypi_0 pypi
torch 2.6.0+cu124 pypi_0 pypi
torchaudio 2.6.0+cu124 pypi_0 pypi
torchvision 0.21.0+cu124 pypi_0 pypi
tqdm 4.67.3 pypi_0 pypi
transformers 5.2.0 pypi_0 pypi
txtai 9.5.0 pypi_0 pypi
typer 0.24.0 pypi_0 pypi
typer-slim 0.24.0 pypi_0 pypi
typing-extensions 4.15.0 pypi_0 pypi
tzdata 2025c he532380_0
ucrt 10.0.22621.0 haa95532_0
vc 14.3 h2df5915_10
vc14_runtime 14.44.35208 h4927774_10
vs2015_runtime 14.44.35208 ha6b5a95_10
wheel 0.46.3 py310haa95532_0
xz 5.6.4 h4754444_1
zlib 1.3.1 h02ab6af_0
(myRAG1) PS C:\Users\37995\miniconda3\envs\myRAG1>
参考二
GPU的相关信息如下:
.\python.exe .\gputest1.py
Python版本: 3.10.19 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 16:41:31) [MSC v.1929 64 bit (AMD64)]
PyTorch版本: 2.6.0+cu124
CUDA是否可用: True
PyTorch编译时的CUDA版本: 12.4
GPU数量: 1
当前GPU: 0
GPU型号: NVIDIA GeForce RTX 4060 Laptop GPU
GPU显存: 8.0 GB
证明GPU的torch软件配套是OK的。
结尾

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)