图书管理系统(7)完善强制登录功能
综合案例1:图书管理系统(7)完善强制登录功能
观前提醒:
这个图书管理系统,非常的简陋,仅作为练习使用。不建议大家使用我介绍的 图书管理系统 ,去作为 课程设计。
如果你是第一次点击这篇博客的,需要你将我 图书管理系统 的博客列表中,从这篇开始看:
图书管理系统(1)项目准备,用户登录接口,添加图书接口
还需要把拦截器的博客看了,这里的部分代码,是在这篇博客中写的:
统一功能处理(1)拦截器
无Mybatis版本获取:
这个 图书管理系统 的实现,需要你从我的 gitee上,将 无Mybatis版本 的图书管理系统源代码下载下来。
gitee链接:https://gitee.com/mrbgvhbhjv/java-ee-course/tree/master/%E5%90%8E%E7%AB%AF%E4%BB%A3%E7%A0%81/springboot_bookManage_System
基于 Mybatis版本 的获取:
如果你想直接获取 基于 Mybatis 完全实现了增删查改功能的图书管理系统,就从我的 gitee 上面获取,下载源代码。
gitee链接:https://gitee.com/mrbgvhbhjv/java-ee-course/tree/master/%E5%90%8E%E7%AB%AF%E4%BB%A3%E7%A0%81/Book_System_20251107
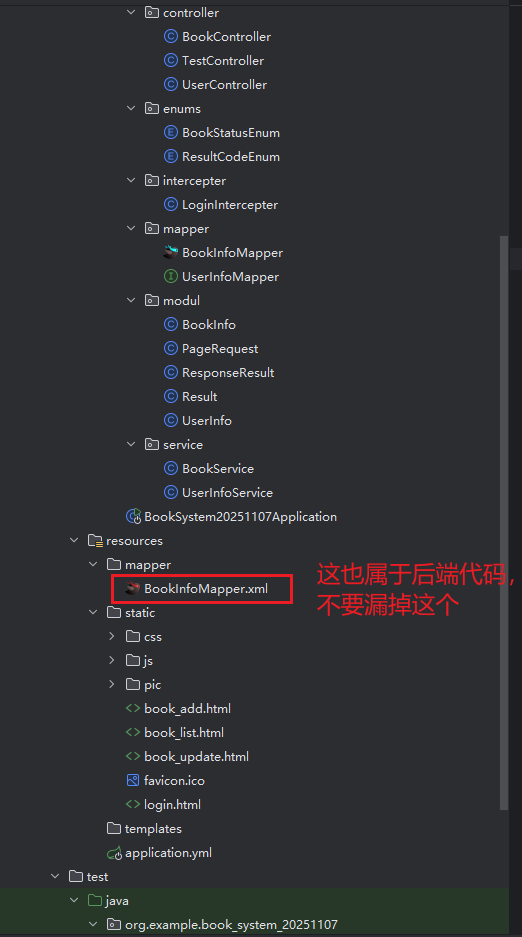
目录结构:
以防大家会乱,或者我博客写的不详细,各种类的存放位置,我放个目录结构在这里: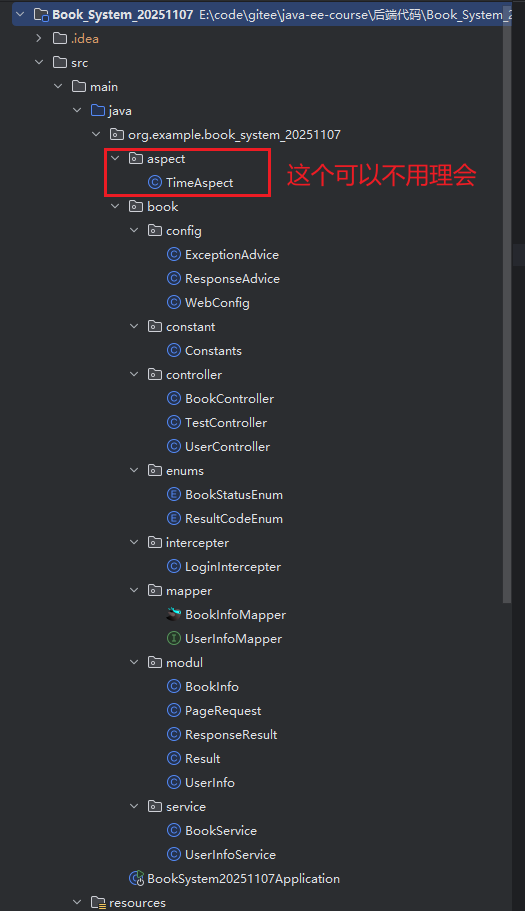
个人建议:
这篇博客的代码,建议自己敲一下。
跟着我的步骤,使用 无Mybatis版本 的图书管理系统源代码 ,一步一步的将代码实现出来。
这里使用的数据库是 MySQL。
图形化工具:Navicat
虽然,截止到 2026年,cursor,TRAE等 AI工具,能够一键编写代码,甚至一个系统。
但是,如果你不会基础知识,只会让 ai 生成代码,不会看代码,不会修改代码,代码运行报错,你不会解决问题等等。其实,你都不算是一个 Java开发者。
如果我们将 AI工具,对我们的工作效率提升,有巨大的帮助,它一定是一个乘法结算的结果。
你的基础开发能力 × AI工具效率 == 工作效率。
如果你的基础开发能力不行,约等于 0,那么,无论 AI工具效率多高,99倍也好,0 * 99 == 0
所以,只有将我们自己的基础开发能力提升了,使用 AI工具提升效率,才是事半功倍的效果。
1. 拦截器,完善强制登录功能
拦截器是 Spring 框架提供的核心功能之一,主要用来拦截用户的请求,在指定方法执行前后,根据业务需要执行预先设定的代码。
我们通过拦截器实现如下逻辑:在访问所有图书接口之前,都会先执行拦截器中的代码,判断用户是否已登录本系统。
- 如果用户已登录,且身份校验通过,则放行请求,允许用户正常访问系统功能。
- 如果用户未登录(或 Session 信息已失效),则拦截本次请求,并提示用户需先完成登录操作。
1.1 preHandle方法:
LoginIntercepter类中的 preHandle方法,是 HandlerInterceptor接口 提供的方法。
是访问图书接口之前,必须先执行的方法,用于判断:用户是否登录。
代码:
/**
*
* @param request
* @param response
* @param handler
* @return
* true:对目标方法放行,不会拦截
* false:拦截目标方法,通过验证之后,才能访问
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
log.info("preHandle方法,目标方法执行前。。。");
// 判断用户是否登录过该系统,进行拦截
// 通过 Session 的 key,获取 Session中的UserInfo对象
HttpSession httpSession = request.getSession();
UserInfo userInfo = (UserInfo)httpSession.getAttribute(Constants.SESSION_USER_KEY);
// 判断 UserInfo对象,是否为空,是否因为后端原因,导致 UserInfo对象的 id 出现异常,<=0 的情况
if (userInfo == null || userInfo.getId() <= 0){
//用户未登录
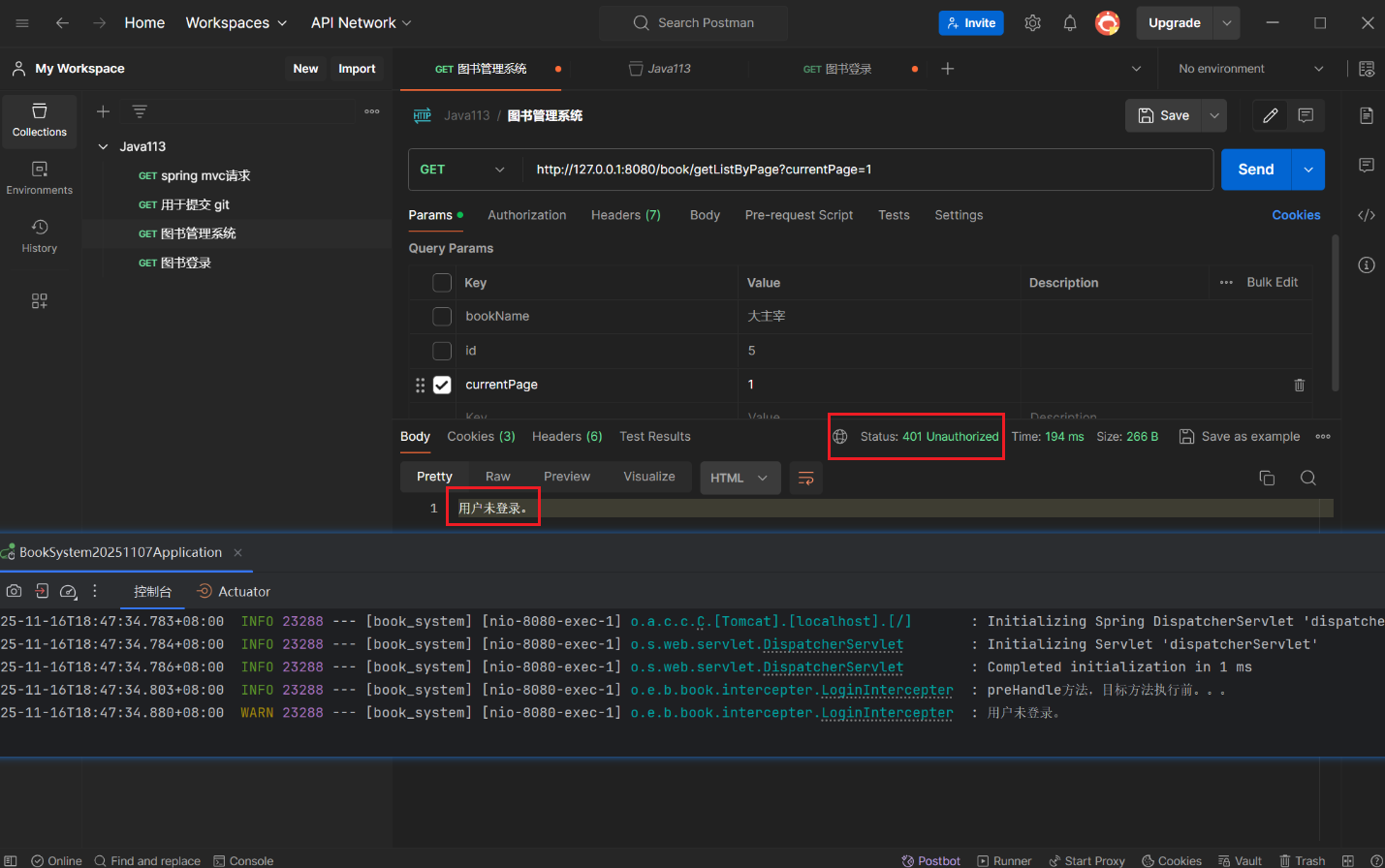
log.warn("用户未登录。");
// 设置相应的状态码,响应信息
response.setContentType("text/html;charset=utf-8");
response.setStatus(401);// 401表示用户未登录
String msg = "用户未登录。";
response.getOutputStream().write(msg.getBytes("utf-8"));
// 用户未登录,拦截请求
return false;
}
log.info("用户已登录。");
return true;
}
1.2 WebConfig类:
代码:
import lombok.extern.slf4j.Slf4j;
import org.example.book_system_20251107.book.intercepter.LoginIntercepter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Slf4j
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private LoginIntercepter loginIntercepter;
@Override
public void addInterceptors(InterceptorRegistry registry) {
log.info("拦截器启动拦截");
registry.addInterceptor(loginIntercepter).addPathPatterns("/**");
// 这句代码做了两件事情:
// 1. 添加拦截器对象,指定使用的拦截器
// 2. 设置拦截器拦截的请求路径( /** 表⽰拦截所有请求)
}
}
WebConfig类 的代码,需要修改:/** 表示拦截所有请求,包括:前端的请求,用户登录接口的请求
这两个请求,不应该被拦截,而是正常放行。
拦截的请求,应该是访问 图书的增删查改接口 的请求,需要判断是否登录,不能直接访问。
1.3 排除请求(三种写法):
所以,我们需要通过代码,排除这两个请求。
排除请求的方式,有三种写法:
excludePathPatterns方法(包含两种)
excludePathPatterns方法,排除指定路径下,文件的请求。
第一种:指定路径:
import lombok.extern.slf4j.Slf4j;
import org.example.book_system_20251107.book.intercepter.LoginIntercepter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.Arrays;
import java.util.List;
@Slf4j
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private LoginIntercepter loginIntercepter;
@Override
public void addInterceptors(InterceptorRegistry registry) {
log.info("拦截器启动拦截");
registry.addInterceptor(loginIntercepter)
.addPathPatterns("/**")
//设置拦截器排除拦截的路径
// 第一种:指定路径
.excludePathPatterns("/user/login")
//排除前端静态资源
.excludePathPatterns("/**/*.js")
.excludePathPatterns("/**/*.css")
.excludePathPatterns("/**/*.png")
.excludePathPatterns("/**/*.html");
//registry.addInterceptor(loginIntercepter).addPathPatterns("/**")
// 这句代码做了两件事情:
// 1. 添加拦截器对象,指定使用的拦截器
// 2. 设置拦截器拦截的请求路径( /** 表⽰拦截所有请求)
}
}
第二种:指定路径,整合为集合的方式
import lombok.extern.slf4j.Slf4j;
import org.example.book_system_20251107.book.intercepter.LoginIntercepter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.Arrays;
import java.util.List;
@Slf4j
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private LoginIntercepter loginIntercepter;
private List<String> excludePaths = Arrays.asList(
"/user/login",
"/**/*.js",
"/**/*.css",
"/**/*.png",
"/**/*.html"
);
@Override
public void addInterceptors(InterceptorRegistry registry) {
log.info("拦截器启动拦截");
registry.addInterceptor(loginIntercepter)
.addPathPatterns("/**")
// 第二种:指定路径,包装为集合的方式:
.excludePathPatterns(excludePaths);
//registry.addInterceptor(loginIntercepter).addPathPatterns("/**")
// 这句代码做了两件事情:
// 1. 添加拦截器对象,指定使用的拦截器
// 2. 设置拦截器拦截的请求路径( /** 表⽰拦截所有请求)
}
}
明确需要拦截的请求(一种):
前端的请求,用户登录接口的请求,这两个请求,不应该被拦截,而是正常放行。
拦截的请求,应该是访问 图书的增删查改接口 的请求,需要判断是否登录,不能直接访问。
第三种方式:明确需要拦截的请求
代码:
import lombok.extern.slf4j.Slf4j;
import org.example.book_system_20251107.book.intercepter.LoginIntercepter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.Arrays;
import java.util.List;
@Slf4j
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private LoginIntercepter loginIntercepter;
@Override
public void addInterceptors(InterceptorRegistry registry) {
log.info("拦截器启动拦截");
registry.addInterceptor(loginIntercepter)
// /book/** :表示请求路径中,包含 book 这个字符的所有请求,都会被拦截
// 拦截后,执行 preHandle方法
.addPathPatterns("/book/**");
//registry.addInterceptor(loginIntercepter).addPathPatterns("/book/**")
// 这句代码做了两件事情:
// 1. 添加拦截器对象,指定使用的拦截器
// 2. 设置拦截器拦截的请求路径( /book/** :表示请求路径中,包含 book 这个字符的所有请求,都会被拦截)
}
}
1.4 拦截器代码:
package org.example.book_system_20251107.book.config;
import lombok.extern.slf4j.Slf4j;
import org.example.book_system_20251107.book.intercepter.LoginIntercepter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.Arrays;
import java.util.List;
@Slf4j
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private LoginIntercepter loginIntercepter;
private List<String> excludePaths = Arrays.asList(
"/user/login",
"/**/*.js",
"/**/*.css",
"/**/*.png",
"/**/*.html"
);
@Override
public void addInterceptors(InterceptorRegistry registry) {
log.info("拦截器启动拦截");
registry.addInterceptor(loginIntercepter)
// /book/** :表示请求路径中,包含 book 这个字符的所有请求,都会被拦截
// 拦截后,执行 preHandle
.addPathPatterns("/book/**");
//设置拦截器排除拦截的路径
// 第一种:指定路径
// .excludePathPatterns("/user/login")
// //排除前端静态资源
// .excludePathPatterns("/**/*.js")
// .excludePathPatterns("/**/*.css")
// .excludePathPatterns("/**/*.png")
// .excludePathPatterns("/**/*.html");
// 第二种:指定路径,整合为集合的方式:
// .excludePathPatterns(excludePaths);
//registry.addInterceptor(loginIntercepter).addPathPatterns("/**")
// 这句代码做了两件事情:
// 1. 添加拦截器对象,指定使用的拦截器
// 2. 设置拦截器拦截的请求路径( /** 表⽰拦截所 有请求)
}
}
1.5 删除之前强制登陆的代码:
现在,我们强制登录的功能,是由拦截器完成的。
之前我们写的一系列判断代码,可以删除了。
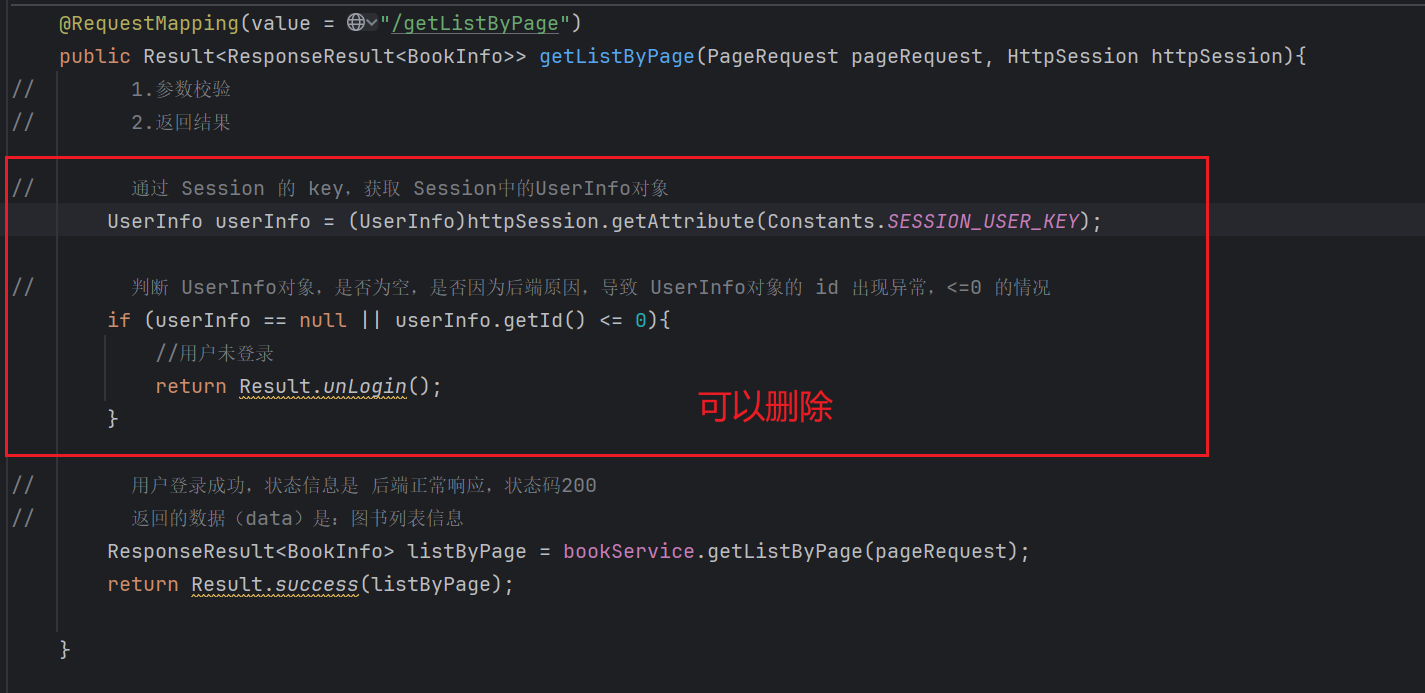
代码:
@RequestMapping(value = "/getListByPage")
public Result<ResponseResult<BookInfo>> getListByPage(PageRequest pageRequest, HttpSession httpSession){
// 1.参数校验
// 2.返回结果
// 强制登录功能,由 拦截器 实现,这里的代码可以删除
//// 通过 Session 的 key,获取 Session中的UserInfo对象
// UserInfo userInfo = (UserInfo)httpSession.getAttribute(Constants.SESSION_USER_KEY);
//
//// 判断 UserInfo对象,是否为空,是否因为后端原因,导致 UserInfo对象的 id 出现异常,<=0 的情况
// if (userInfo == null || userInfo.getId() <= 0){
// //用户未登录
// return Result.unLogin();
// }
// 用户登录成功,状态信息是 后端正常响应,状态码200
// 返回的数据(data)是:图书列表信息
ResponseResult<BookInfo> listByPage = bookService.getListByPage(pageRequest);
return Result.success(listByPage);
}
1.6 测试:
使用 Postman 测试拦截器是否除了 前端的请求,用户登录接口的请求 这两个接口不拦截,其他的所有接口请求,是否都拦截。
用户未登录:
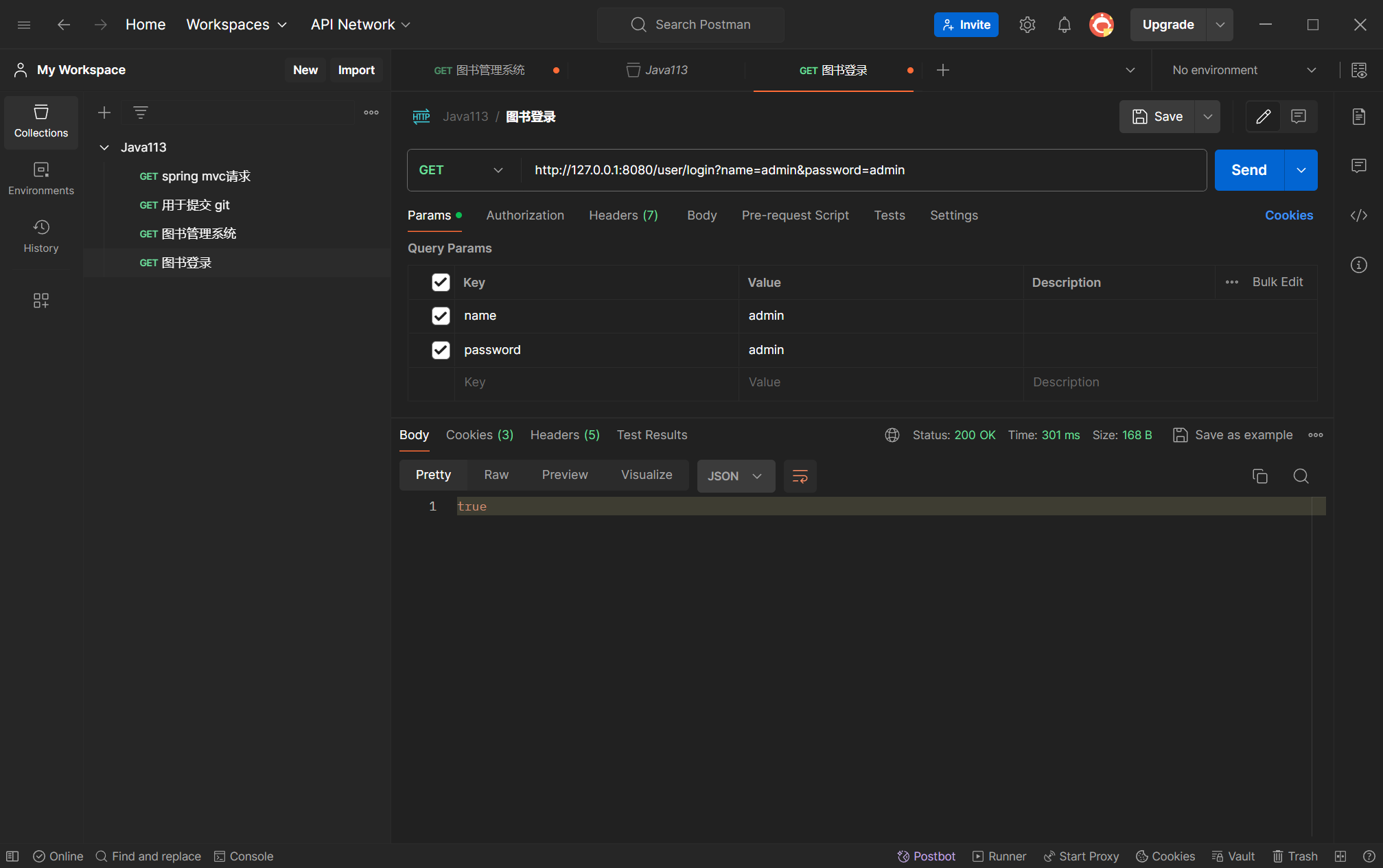
用户登录接口的请求:
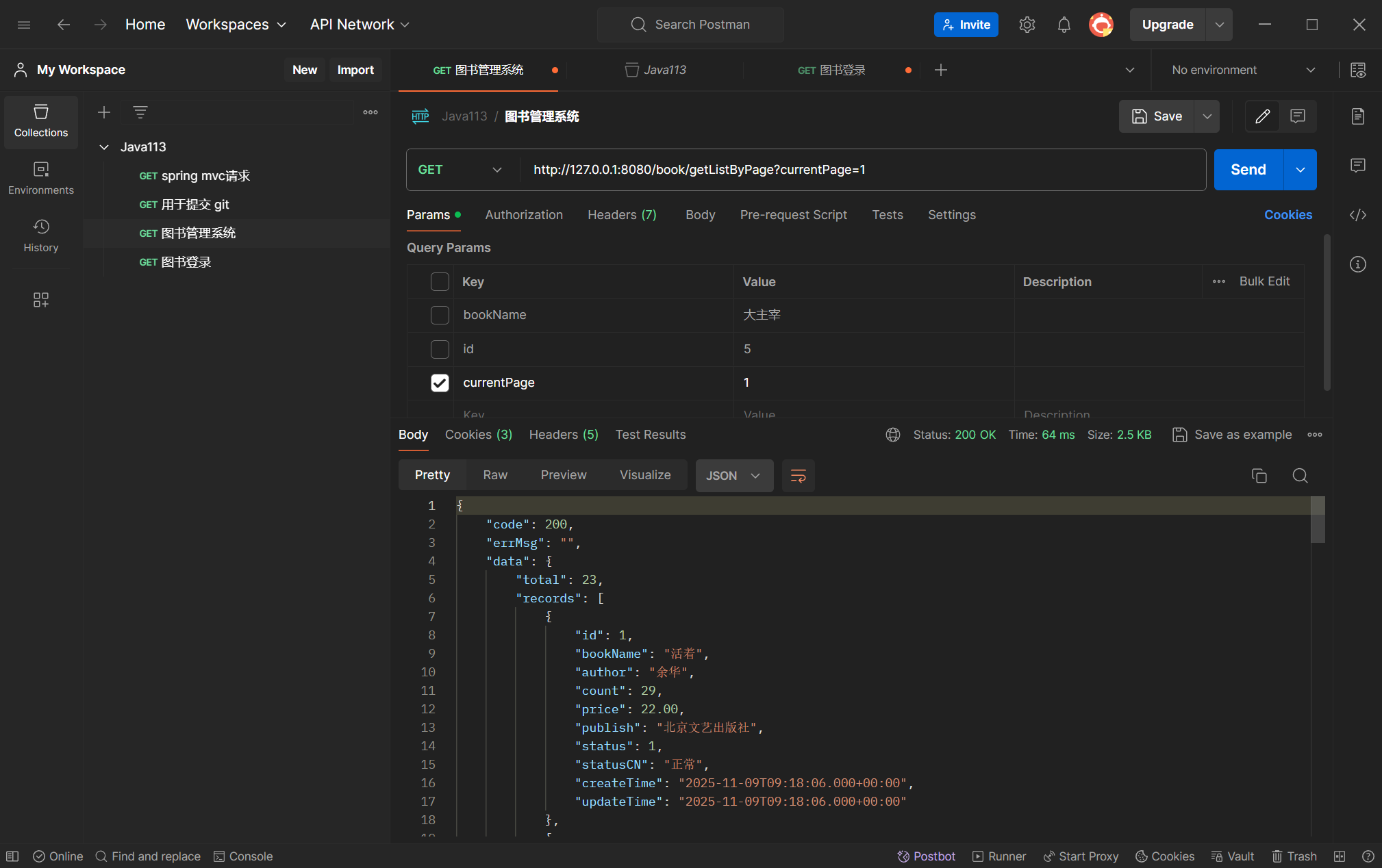
登录之后,再次访问图书列表:
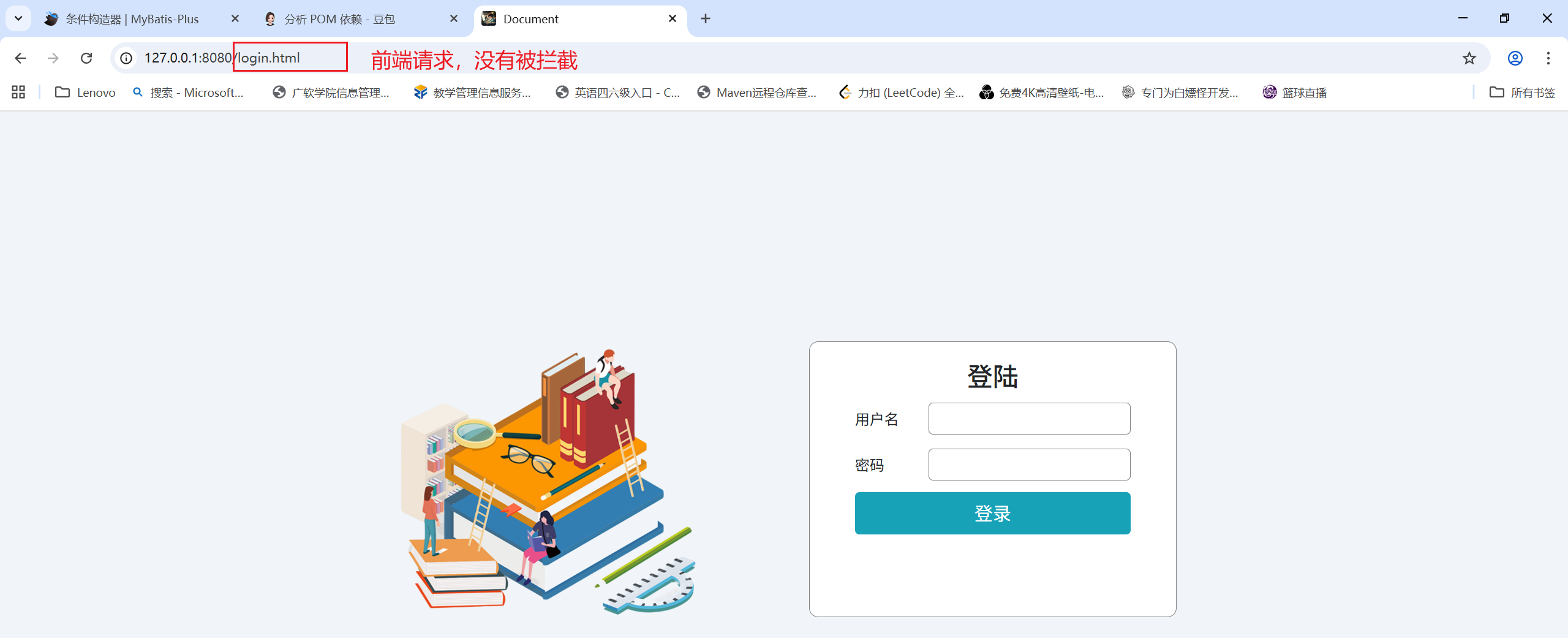
测试前端:
前端的请求,需要通过访问 login.html 这个页面来验证:
测试没有登录,访问图书列表:
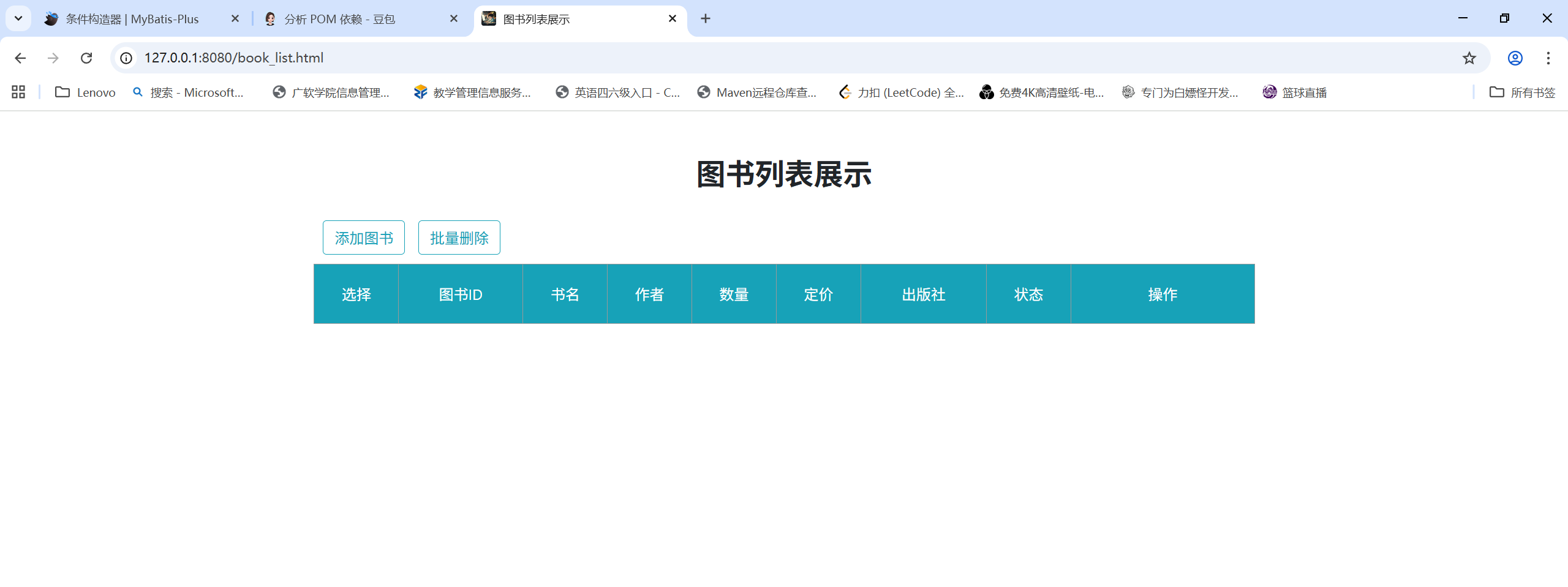
页面没有数据展示,说明请求被拦截了,没有数据返回给前端并进行展示。
后端日志: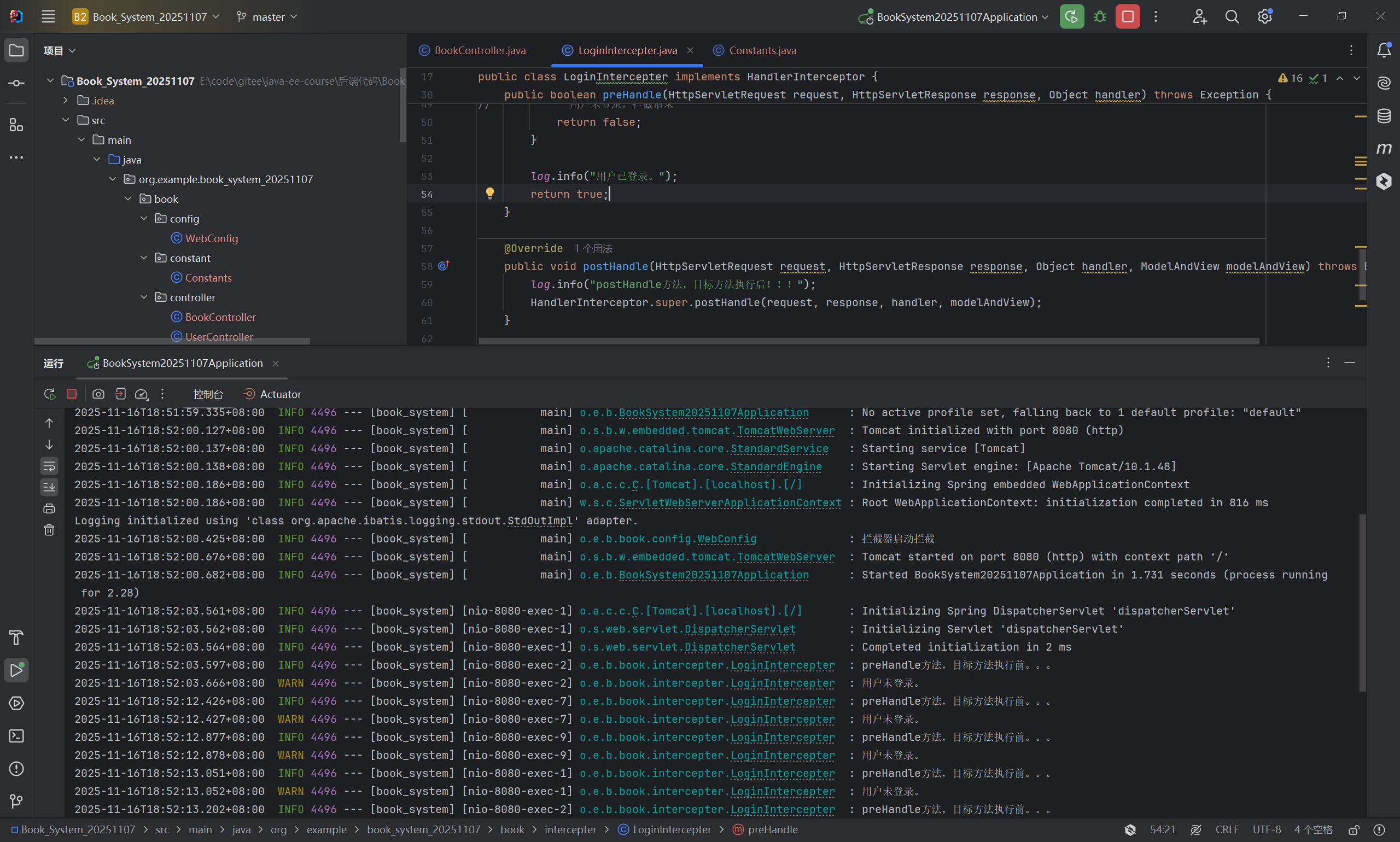
2. 前端代码:
前端页面,如果后端的请求被拦截器拦截了,没有数据展示,不能干巴巴的这么显示啊。
后端的请求被拦截器拦截了,是因为用户没有登录。
所以,因为用户没有登录,后端的请求被拦截器拦截,没有数据返回给前端并进行展示。
前端应该根据后端设置的状态码(401),跳转到 登陆页面,让用户进行登录,而不是 显示空白 列表。
book_list.html
function getBookList ()
{
$.ajax({
type: "get",
url: "/book/getListByPage" + location.search,
success: function (result)
{
if (result == null || result.code == -1) {
alert("用户未登录,请先登录");
location.href = "login.html";
}
// 其他情况判断,此处省略
if (result == null || result.data == null){
return;
}
var data = result.data;
var books = data.records;
var wholeHtml = "";
for (var book of books) {
// 拼接列表
wholeHtml += '<tr>';
wholeHtml += '<td><input type="checkbox" name="selectBook" value="' + book.id + '" id="selectBook" class="book-select"></td>';
wholeHtml += '<td>' + book.id + '</td>';
wholeHtml += '<td>' + book.bookName + '</td>';
wholeHtml += '<td>' + book.author + '</td>';
wholeHtml += '<td>' + book.count + '</td>';
wholeHtml += '<td>' + book.price + '</td>';
wholeHtml += '<td>' + book.publish + '</td>';
wholeHtml += '<td>' + book.statusCN + '</td>';
wholeHtml += '<td><div class="op">';
wholeHtml += '<a href="book_update.html?bookId=' + book.id + '">修改</a>';
wholeHtml += '<a href="javascript:void(0)" onclick="deleteBook(' + book.id + ')">删除</a>';
wholeHtml += '</div></td></tr>';
}
$("tbody").html(wholeHtml);
//翻页信息
$("#pageContainer").jqPaginator({
totalCounts: data.total, //总记录数
pageSize: 10, //每页的个数
visiblePages: 5, //可视页数
currentPage: data.pageRequest.currentPage, //当前页码
first: '<li class="page-item"><a class="page-link">首页</a></li>',
prev: '<li class="page-item"><a class="page-link" href="javascript:void(0);">上一页<\/a><\/li>',
next: '<li class="page-item"><a class="page-link" href="javascript:void(0);">下一页<\/a><\/li>',
last: '<li class="page-item"><a class="page-link" href="javascript:void(0);">最后一页<\/a><\/li>',
page: '<li class="page-item"><a class="page-link" href="javascript:void(0);">{{page}}<\/a><\/li>',
//页面初始化和页码点击时都会执行
onPageChange: function (page, type)
{
if (type == "change") {
location.href = "book_list.html?currentPage=" + page;
}
}
});
},
// 用户未登录时,跳转到登陆页面
error:function (error) {
if (error.status == 401){
alert("用户未登录,请先登录");
location.href = "login.html";
}
}
});
}
运行效果:
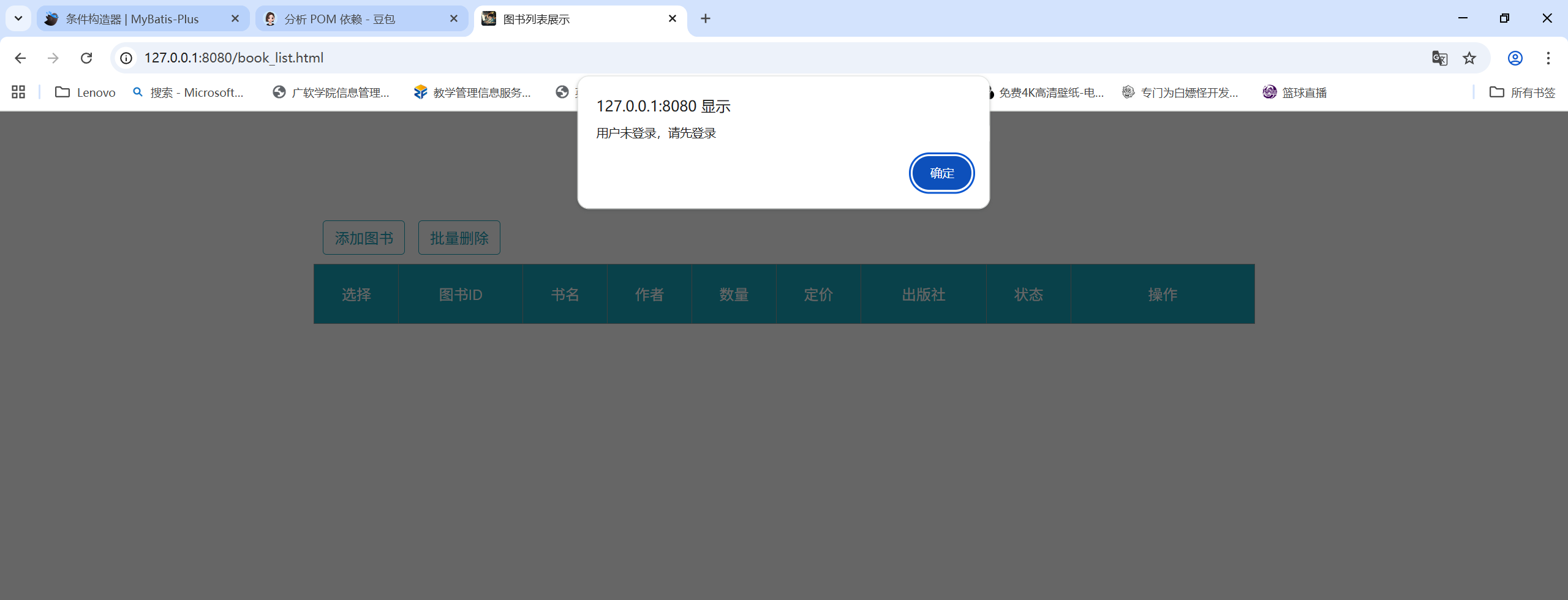
3. 总结:
第一次将 拦截器 运用在简单的项目中,实现 强制登陆 的功能。
强制登陆 的功能。在很多网站上,都由应用,有拦截器实现,是主流方式,需要多理解,吃透这个实现的方式。
以上代码的意思,通过注释,你应该能看懂,看不懂的,使用 ai工具(deepseek,豆包……)
最后,如果这篇博客能帮到你的,请你点点赞,有写错了,写的不好的,欢迎评论指出,谢谢!
下一篇博客:图书管理系统(8)统一管理返回结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)