Transformer之注意力机制中QKV原理解读
本文深入解析了自注意力机制中的QKV(Query-Key-Value)机制。在单头注意力中,QKV通过线性变换将输入序列转换为查询、键和值向量,计算注意力分数并进行加权求和,最终输出融合上下文信息的特征表示。文章通过狗狗照片分类的实例,展示了自注意力如何强化同类特征。同时对比了交叉注意力机制,指出其使用外部查询与另一序列交互的特点。QKV机制是Transformer模型捕捉长距离依赖的关键,其权重
引言
在自注意力(Self-Attention)机制里,查询(Query,简称Q)、键(Key,简称K)和值(Value,简称V)这三个是核心中的核心,它们仨一起参与计算,才能得出序列的加权表示。
之前的文章我其实简单提过一嘴QKV,但说实话,那点介绍远远不够深入。毕竟它们在注意力机制里,那可是占了“半壁江山”的存在。现在前沿的大模型研究,一大半都是围着QKV矩阵打转的,比如注意力优化、量化、低秩压缩这些方向,全和它有关。
之所以这么重要,核心原因就一个:QKV的权重,占了大语言模型总权重的50%以上。而且在推理的时候,QKV的存储量会跟着上下文长度的增加而线性增长,计算量更是会平方级往上翻。
这么一来,问题就来了:
QKV机制到底是干啥的?它们各自输出的是什么东西?最终得到的注意力输出,又到底代表着什么?
还有,QKV到底在哪个地方?我们为啥非得要有QKV不可?
01、单头注意力机制下的QKV机制
我们来读一段话:
“小明昨天去了学校,他今天也去了学校。”
当你看到后半句里的“他”,心里会想:这个“他”到底是谁?
这时候,“他”就是你的 Query。
然后你会往前看:“小明昨天去了学校”。
这句话里能回答“他是谁”的关键词,就是小明,这就是 Key。
而整句话“小明昨天去了学校”,就是对应的 Value。
所以说,注意力机制其实就在干这件事:
给你一个 Query,让你找到跟它匹配的 Key,再从里面拿出对应的 Value。
放到 Transformer 里,注意力机制的核心就是靠三个向量来干活:
Query、Key、Value,用来算出哪些信息更重要、更值得关注。
我们先把整体流程理一理:
假设我们有一串序列,里面有 n 个元素,每个元素用一个 d 维向量表示,
那这一整串就可以写成一个 n×d 的矩阵 X。
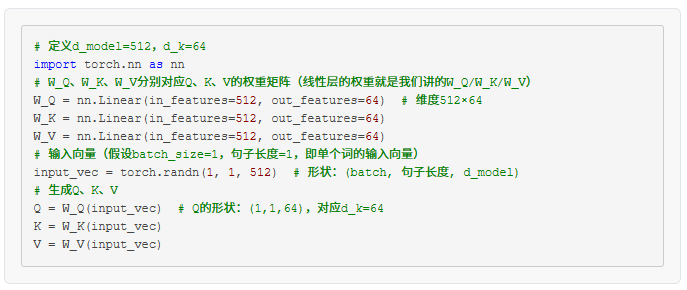
接下来,我们用三组不同的线性变换矩阵,把 X 分别变成 Q、K、V:
Q = X * W_Q
K = X * W_K
V = X * W_V
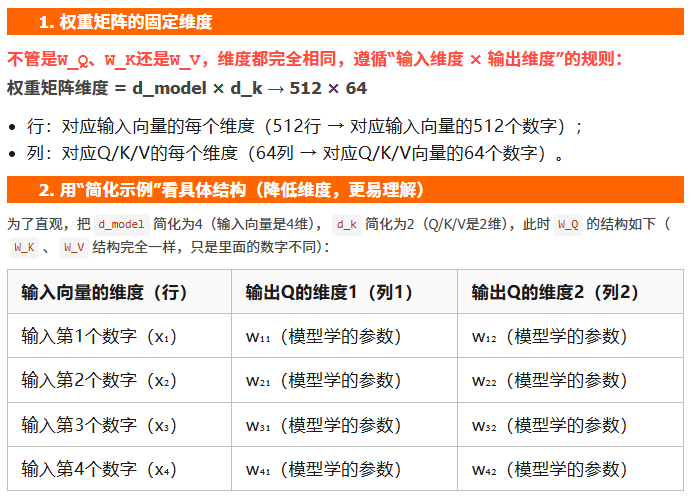
这里的 W_Q、W_K、W_V 都是模型在训练里可以学习的参数矩阵,
说白了就是模型“自己慢慢学出来的一组数字”——一开始是随机值,
训练时会跟着任务(比如翻译、理解文本)不断调整,
直到 Q/K/V 能精准算出“词和词之间到底有多相关”。
然后就开始算注意力分数:
对每一个查询向量 qᵢ(对应第 i 个元素),
先算它和所有键向量 kⱼ 的点积,
再除以 √dₖ(目的是让梯度更稳定),
最后过一下 softmax 做归一化,得到权重 αᵢⱼ。
这些权重 αᵢⱼ 就是注意力分数,
代表第 i 个元素和第 j 个元素的关联程度。
最后,对第 i 个元素来说,
我们就用这些权重 αᵢⱼ,把所有值向量 vⱼ 做一次加权求和,
得到的结果 zᵢ,就是这一步的输出。
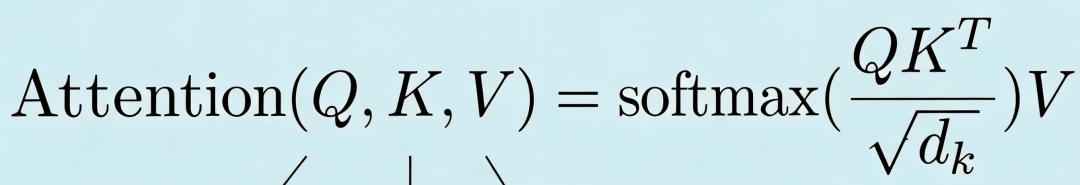
咱们可以把 Q 理解成查询,就是你想查什么内容。
K 可以看成索引标签,就像书前面的目录,专门标记内容在哪。
V 就是每个位置对应的真实内容,也就是你最终想拿到的信息。
这么一说是不是就清晰多了?下面我再举个实际例子,你会更容易理解。
我会用单头注意力机制和交叉注意力机制两种来讲,其中交叉注意力是多模态模型 Transformer 架构里的机制,后面我会单独写一篇文章细讲。
举个例子:
假设我们有一组狗狗的照片(每张照片都已经用特征提取器处理过,变成了一组向量),让模型在这组狗狗照片内部做自注意力计算,用来强化每张照片的特征表达。
具体场景:
我们就拿三张狗狗照片来说,每张都已经通过 CNN 这类特征提取器转成了特征向量,把这三张照片的特征向量当作输入序列。
我们的目的就是:用自注意力机制,让每张照片的特征都能“参考”其他照片的特征,从而更准确地表示出照片里狗狗的种类特征。
比如三张里有两张是金毛,那模型就会自动强化金毛相关的特征。
具体步骤:
输入序列:三张照片的特征向量,假设每个向量维度是 512(也就是 d_model=512)。
照片1:金毛A(金色长毛,面带微笑)
照片2:哈士奇(蓝眼睛、立耳朵,黑白毛色)
照片3:金毛B(金色长毛,张嘴吐舌头)
# 3张照片的原始特征(每张512维)
photo_features = [
# 照片1: 金毛A
[0.9, 0.8, 0.2, 0.7, 0.1, ...], # 金色=0.9, 长毛=0.8, 立耳=0.2, 微笑=0.7, 背景=0.1...
# 照片2: 哈士奇
[0.1, 0.3, 0.9, 0.3, 0.8, ...], # 金色=0.1, 长毛=0.3, 立耳=0.9, 微笑=0.3, 背景=0.8...
# 照片3: 金毛B
[0.8, 0.9, 0.1, 0.6, 0.2, ...] # 金色=0.8, 长毛=0.9, 立耳=0.1, 微笑=0.6, 背景=0.2...
]
# 形状: [3, 512] - 3张照片,每张512维特征

过程:
对于每一张图像,我们通过对应的权重矩阵,分别生成查询向量 Q、键向量 K、值向量 V。
以图像1为例:
- 查询向量 Q₁ = 图像1特征 × W_Q
- 键向量 K₁ = 图像1特征 × W_K
- 值向量 V₁ = 图像1特征 × W_V
同理,我们可以得到图像2的 Q₂、K₂、V₂,以及图像3的 Q₃、K₃、V₃。
接下来,仍以图像1为例,计算它在自注意力机制中的最终输出。
Q1 = [0.9, 0.2, 0.8, 0.1] * W_Q = [0.9*0.5+0.2*0.1+0.8*0.4+0.1*(-0.1), 0.9*(-0.2)+0.2*0.3+0.8*0.1+0.1*0.2] = [0.45+0.02+0.32-0.01, -0.18+0.06+0.08+0.02] = [0.78, -0.02]
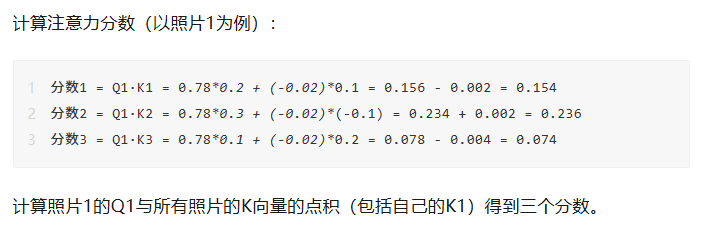
自注意力计算(金毛A的视角)



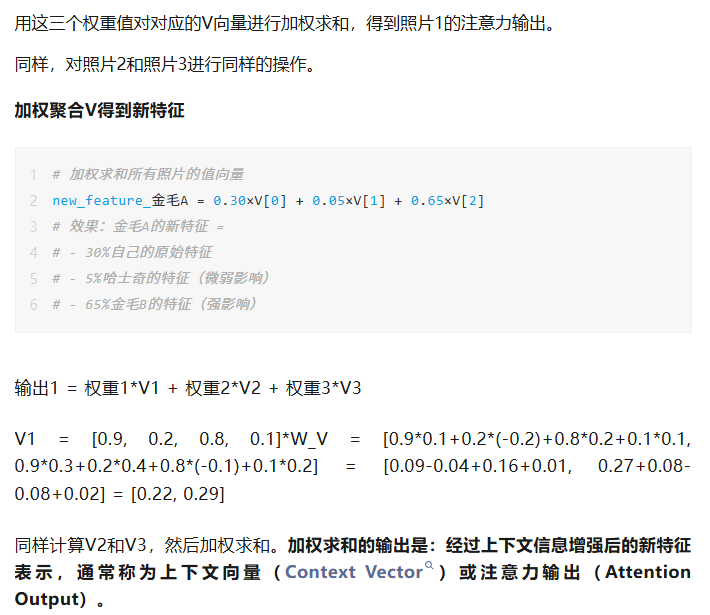

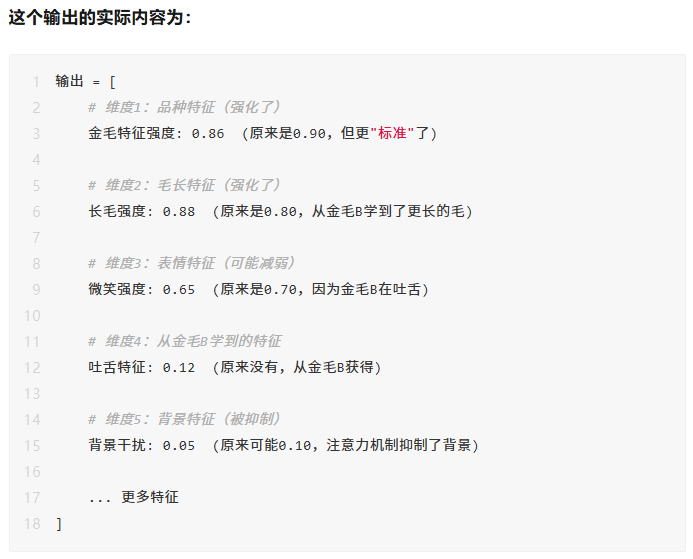
经过公式计算后,最终输出的是一个经过加权的 Value 向量,本质是一个多维矩阵,里面包含了词汇之间的上下文关系与语义信息。
在不同任务里,这个特征的作用也不一样:
- 对于分类任务:输出特征更擅长区分不同类别
- 对于检索任务:输出特征更利于精准匹配查询内容
- 对于生成任务:输出特征会携带更丰富的上下文信息
前面我们提到,注意力机制的核心流程可以概括为两步:
\1. 用 Query 和 Key 做运算,得到注意力分数
\2. 用这个分数对 Value 做加权求和,得到最终输出
所以,注意力机制的本质,就是输出一个融合了上下文信息的 Value 向量。
这也是 Transformer 能轻松捕捉长距离依赖关系的关键:
它能让当前词的表示,直接受到句子中远距离相关词汇的影响,最终生成一个融合上下文、能代表当前词真实含义的新向量。
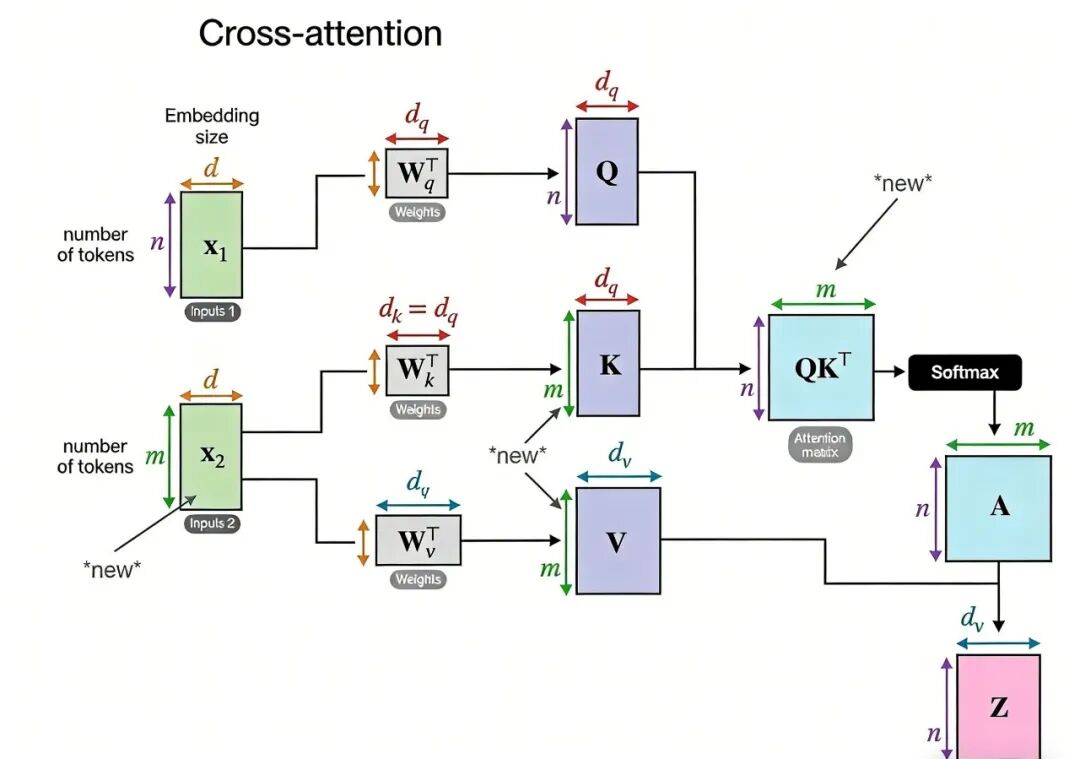
02、交叉注意力下的QKV机制
在自注意力机制中,我们核心是让序列中的每张照片(或每个输入元素),主动去“关注”序列内的其他所有照片,通过这种内部交互,不断更新每张照片自身的特征表示。
关键在于,自注意力机制中的查询(Q)、键(K)、值(V),均来源于同一组输入序列,不存在外部输入的参与。
我们可以通过一个具体例子,更直观地区分自注意力与另一种常见的注意力机制——交叉注意力(cross-attention)。假设我们有一组狗的照片,并且已经通过特征提取器,将每张照片转化为了可计算的特征向量。
此时如果我们有一个明确的查询,比如“金毛狗”的特征向量,想要从这组照片中筛选出与之最匹配的照片,这本质上是一个检索任务,而这类场景恰好可以用交叉注意力机制来实现——但需要注意,这已经不再是自注意力了。
两者的核心差异的在于输入来源:交叉注意力中,查询(Q)来自一个序列(比如这里的用户查询“金毛狗”),而键(K)和值(V)则来自另一个完全不同的序列(比如这组狗的照片特征),二者属于“跨序列交互”;而自注意力则是“同序列内部交互”。
具体来说,在自注意力机制中,序列中的每个元素(比如每一张狗的照片)都会独立生成属于自己的Q、K、V三个向量。我们可以用通俗的方式理解:对于其中某一张照片而言,它的查询向量(Q)就相当于它提出的“疑问”——“序列中还有哪些照片和我相关?”。
键向量(K)则是每张照片的“身份标识”,用于响应其他元素的查询、完成匹配;值向量(V)则是每张照片的核心内容,是最终用于更新特征表示的关键信息。
而交叉注意力的核心特点,是存在一个明确的“外部查询”(比如用户提出的“金毛狗”需求):我们会将这个外部查询编码为查询向量(Q),而将另一组序列(比如狗的照片特征)作为键(K)和值(V)。
简单来说,就是用一个外部的“疑问”,去检索另一组序列中的相关信息,这就是交叉注意力的核心逻辑。
进一步延伸来看,交叉注意力的应用场景十分广泛。比如在图像描述生成任务中,我们通常会将图像提取的特征作为键(K)和值(V),将文本生成过程中的隐藏状态作为查询(Q),通过这种跨模态的交叉注意力,让文本生成能够精准贴合图像内容。
而在我们之前的例子中,用户查询“金毛狗”编码后的向量就是Q,狗的照片特征序列就是K和V,二者通过交叉注意力完成匹配检索。

QKV的权重矩阵W




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)