《从零理解智能体:LangChain 框架原理与实战指南》
《从零理解智能体:LangChain 框架原理与实战指南》介绍了AI智能体(Agent)的概念及其重要性。智能体不仅具备语言理解能力,还能通过工具调用、任务规划和多步骤执行完成复杂任务,相比传统大语言模型(LLM)更具行动力和自主性。文章对比了LLM与智能体的区别,指出智能体在客服、数据分析和办公自动化等场景的应用价值。此外,文章重点介绍了LangChain框架,它通过模块化设计简化智能体开发,提
《从零理解智能体:LangChain 框架原理与实战指南》
文章目录
- 《从零理解智能体:LangChain 框架原理与实战指南》
- 一、引言:什么是智能体?为什么它很重要?
- 二、LangChain 框架一览:模块化设计与核心目标
- 三、LangChain 核心组件详解
- 四、 智能体(Agents)详解:从思考到行动的原理与实现
- 五、 LangChain 实战:从零实现你的第一个 Agent
- 六、 多智能体协作与工程实践
- 附录:智能体完整代码与运行示例
一、引言:什么是智能体?为什么它很重要?
在过去几年中,大语言模型(LLM)的快速发展,让 AI 从“只能做分类和预测”,跃迁为“能够理解和生成自然语言的智能系统”。
以 ChatGPT 为代表的产品,让普通用户第一次感受到 AI 的强大能力。
但很快,人们也发现了一个问题:
👉 大多数 LLM,本质上仍然只是“会聊天的模型”。
它们可以写文章、改代码、回答问题,却很难:
- 主动完成复杂任务
- 调用真实工具
- 持续执行多步骤流程
- 像“助理”一样帮你把事情做完
这正是 AI 智能体(Agent) 诞生的背景。
1.1 多维度理解什么是 AI 智能体(AI Agent)
从本质上看,智能体是一种“具备自主行动能力的 AI 系统”。
它不仅会“思考”,还会“行动”。
我们可以从三个维度理解 AI Agent:
(1)从功能角度看:Agent = 会干活的 AI
传统大模型:
输入 → 输出文本 → 结束
智能体:
输入 → 分析 → 规划 → 调用工具 → 执行 → 反馈 → 再思考
也就是说,Agent 不只是回答问题,而是:
- 帮你查资料
- 调接口
- 写文件
- 调数据库
- 跑脚本
- 自动完成任务链路
它更像一个 “数字员工”。
(2)从系统角度看:Agent = LLM + 系统能力
一个完整的智能体,通常包含:
| 模块 | 作用 |
|---|---|
| LLM | 负责理解和推理 |
| Tools | 负责执行真实操作 |
| Memory | 负责存储上下文 |
| Planner | 负责任务规划 |
| Executor | 负责调度执行 |
因此,Agent 不是一个模型,而是一个系统架构。
(3)从哲学角度看:Agent = 感知 + 决策 + 行动
在人工智能经典理论中,智能体被定义为:
能够感知环境,并基于目标采取行动的实体。
对应到 LLM Agent:
感知(Observe)→ 思考(Think)→ 行动(Act)→ 反馈(Observe)
这形成了一个持续循环。
这也是现代 AI Agent 的核心运行逻辑。
1.2 LLM 与 Agent 的本质区别
很多初学者容易混淆:
❓“我直接用 ChatGPT,不也是 AI 吗?为什么还需要 Agent?”
关键区别在于:有没有“行动能力”与“流程控制能力”。
对比:LLM vs AI Agent
| 维度 | 传统 LLM | AI Agent |
|---|---|---|
| 输出形式 | 文本为主 | 文本 + 行动 |
| 是否调用工具 | 很少 | 经常 |
| 是否有规划 | 否 | 是 |
| 是否多步骤执行 | 否 | 是 |
| 是否持续运行 | 否 | 是 |
| 是否具备自治性 | 否 | 是 |
示例对比
使用 LLM:
用户:帮我统计这个 Excel 的销售数据
LLM:你可以这样操作……
👉 只给建议,不干活。
使用 Agent:
用户:帮我统计这个 Excel 的销售数据
Agent 自动:
- 读取文件
- 调用分析工具
- 计算汇总
- 输出报表
👉 直接把事情做完。
总结
LLM = 大脑
Agent = 大脑 + 手脚 + 工作流程
这正是 Agent 的价值所在。
1.3 当前 AI 应用的核心痛点
痛点一:无法长期执行复杂任务
很多任务并不是“一问一答”能解决的:
- 自动整理日报
- 数据分析
- 项目调度
- 客服自动处理
- 知识管理系统
这些都需要:
多步骤 + 状态管理 + 动态决策
传统 LLM 无法胜任。
痛点二:缺乏真实世界交互能力
LLM 默认只能:
- 看文本
- 生成文本
但现实世界需要:
- 调 API
- 查数据库
- 操作文件
- 控制程序
Agent 通过 Tools 打通了“虚拟世界”和“真实系统”。
痛点三:上下文管理困难
长对话、多任务场景下:
- 上下文容易丢失
- 逻辑容易混乱
- 无法记住历史偏好
Agent 通过 Memory 机制解决这一问题。
痛点四:缺乏工程化能力
直接用 API 调模型:
- 难调试
- 难监控
- 难优化
- 难部署
企业级应用需要完整框架支持。
1.4 AI Agent 的核心价值
正因为上述痛点,智能体开始成为主流方向。
Agent 带来的改变
| 维度 | 传统 AI | Agent AI |
|---|---|---|
| 交互方式 | 问答 | 协作 |
| 工作模式 | 被动 | 主动 |
| 任务能力 | 单步 | 多步 |
| 应用场景 | 演示型 | 生产型 |
典型应用场景
目前 Agent 已经广泛应用于:
- 智能客服
- 自动数据分析
- 文档助理
- 办公自动化
- 编程助手
- 企业流程自动化
可以说:
Agent 是 LLM 走向“生产力工具”的关键形态。
1.5 为什么选择 LangChain?
LangChain 的定位
LangChain 是一个:
面向 LLM 应用与 Agent 系统的开发框架。
它的核心目标是:
- 降低 Agent 开发门槛
- 提供标准化组件
- 支持复杂工作流
- 方便工程落地
LangChain 解决了什么问题?
如果不用框架,你需要自己实现:
- Prompt 管理
- Tool 调度
- Memory 系统
- 执行循环
- 日志追踪
- 调试工具
LangChain 对他们全部进行了封装
LangChain 的核心优势
| 特点 | 说明 |
|---|---|
| 模块化 | 组件自由组合 |
| 模型无关 | 支持多种 LLM |
| 工具生态 | 丰富 Tools |
| Agent 支持 | 原生智能体 |
| 工程化 | 易调试部署 |
二、LangChain 框架一览:模块化设计与核心目标
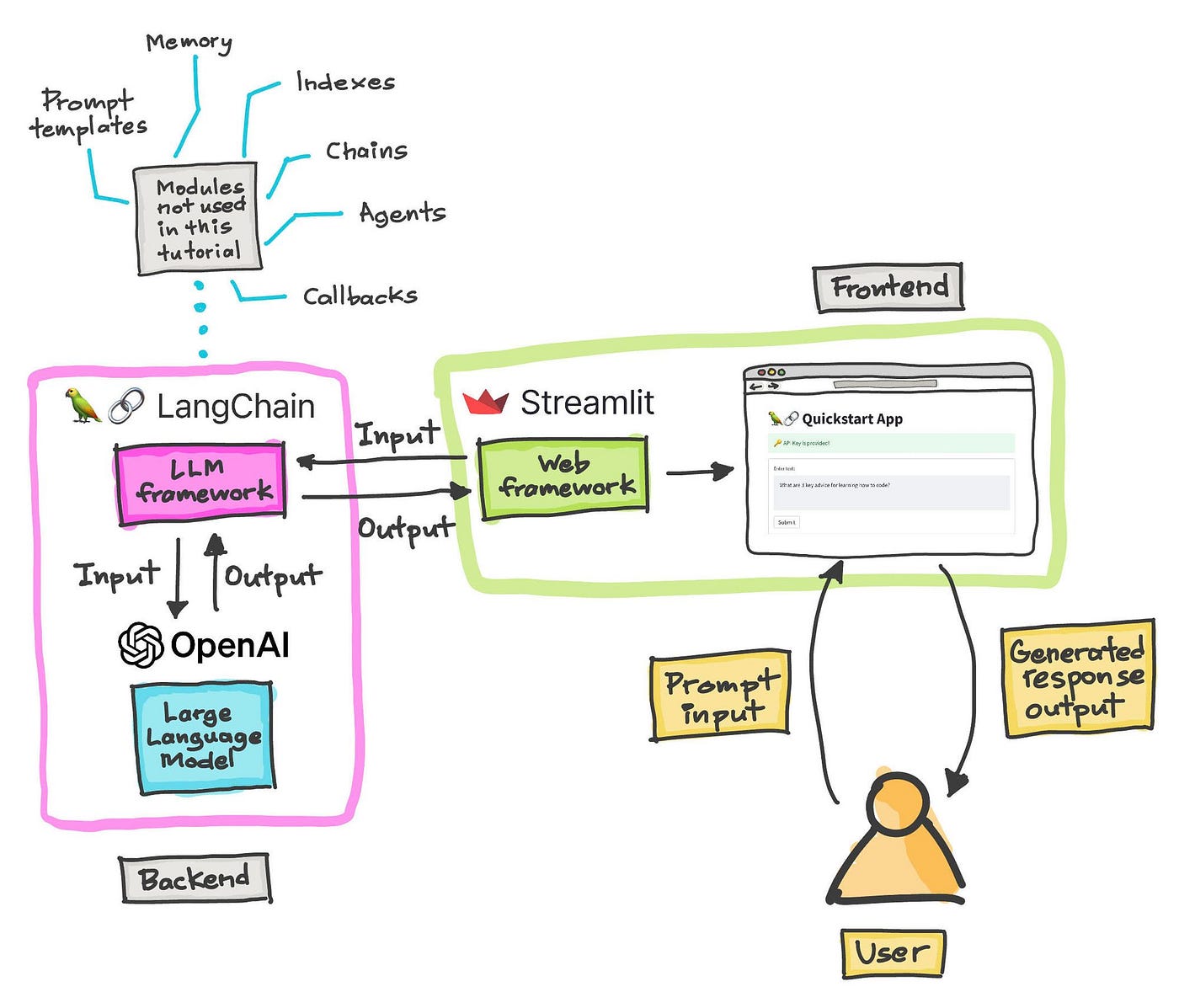
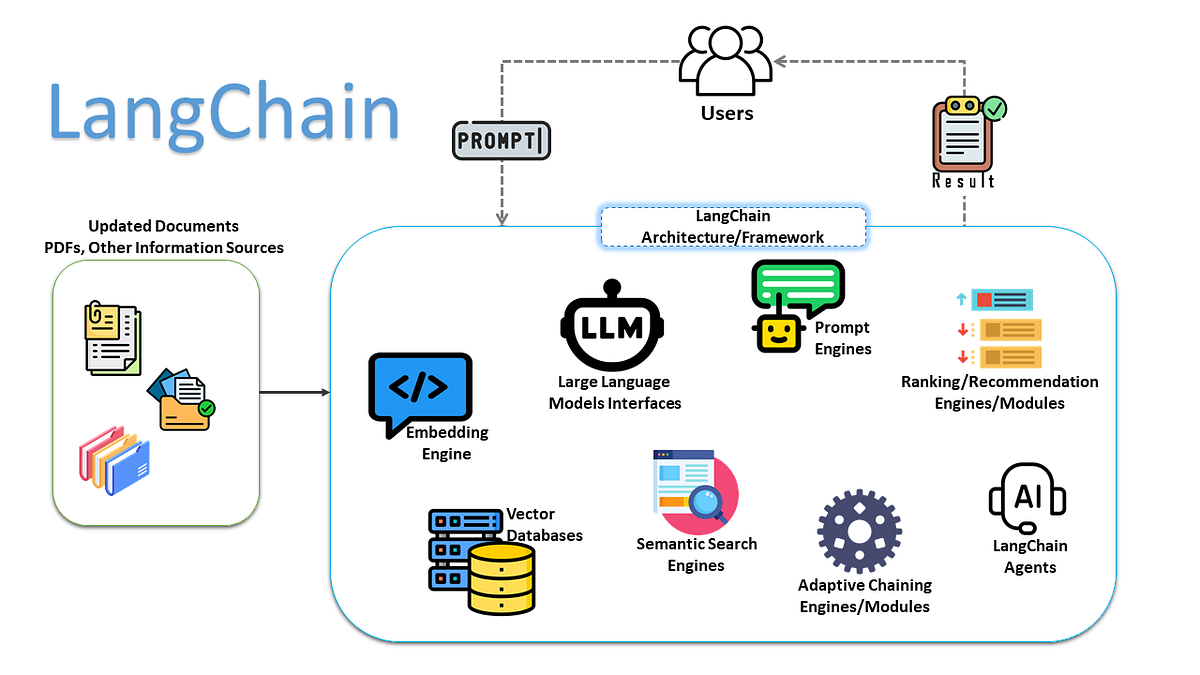
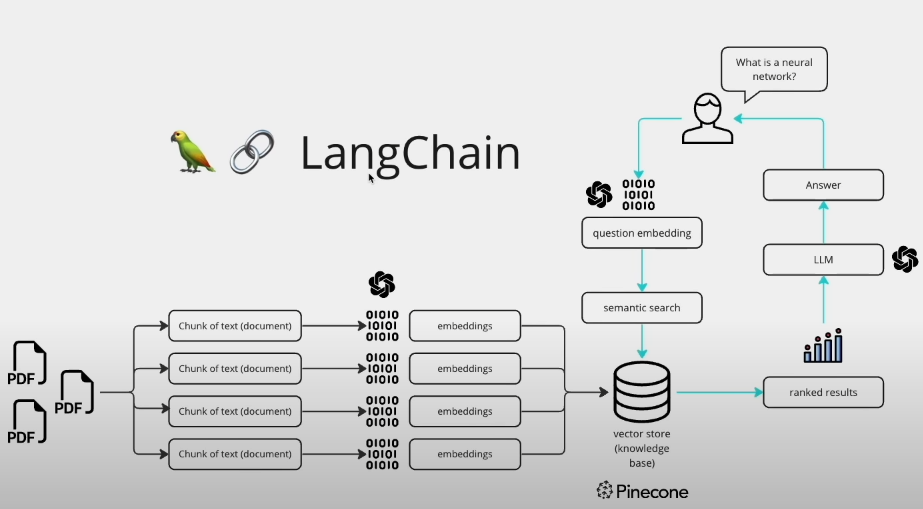
2.1 LangChain 的诞生背景与应用定位
2.1.1 大模型应用开发的早期困境
在 LangChain 出现之前,开发者使用 LLM 往往面临这些问题:
❌ Prompt 全靠手写,难以维护
❌ 不同模型 API 差异巨大
❌ 工具调用需要自己封装
❌ 缺乏统一工作流
❌ 代码复用性极差
典型开发方式如下:
API 调用 + Prompt 拼接 + if/else 逻辑
这种方式:
- 难扩展
- 难调试
- 难复用
- 难规模化
很快就会“失控”。
2.1.2 LangChain 的出现
LangChain 的核心目标非常明确:
把「零散的 LLM 调用」升级为「可组合的智能系统」。
它尝试回答一个关键问题:
如何像搭积木一样构建 AI 应用?
因此,LangChain 从一开始就强调:
- 组件化
- 标准化
- 工程化
2.1.3 LangChain 的应用定位
从定位来看,LangChain 并不是:
❌ 单一聊天框架
❌ 单一模型 SDK
❌ 简单封装库
而是:
面向 AI 应用与 Agent 系统的开发平台。
它主要服务于三类场景:
| 场景 | 示例 |
|---|---|
| 智能问答 | RAG 系统 |
| 自动化工具 | 办公助手 |
| 自主智能体 | Agent 系统 |
这也是它近年来快速流行的重要原因。
2.2 LangChain 整体架构总览
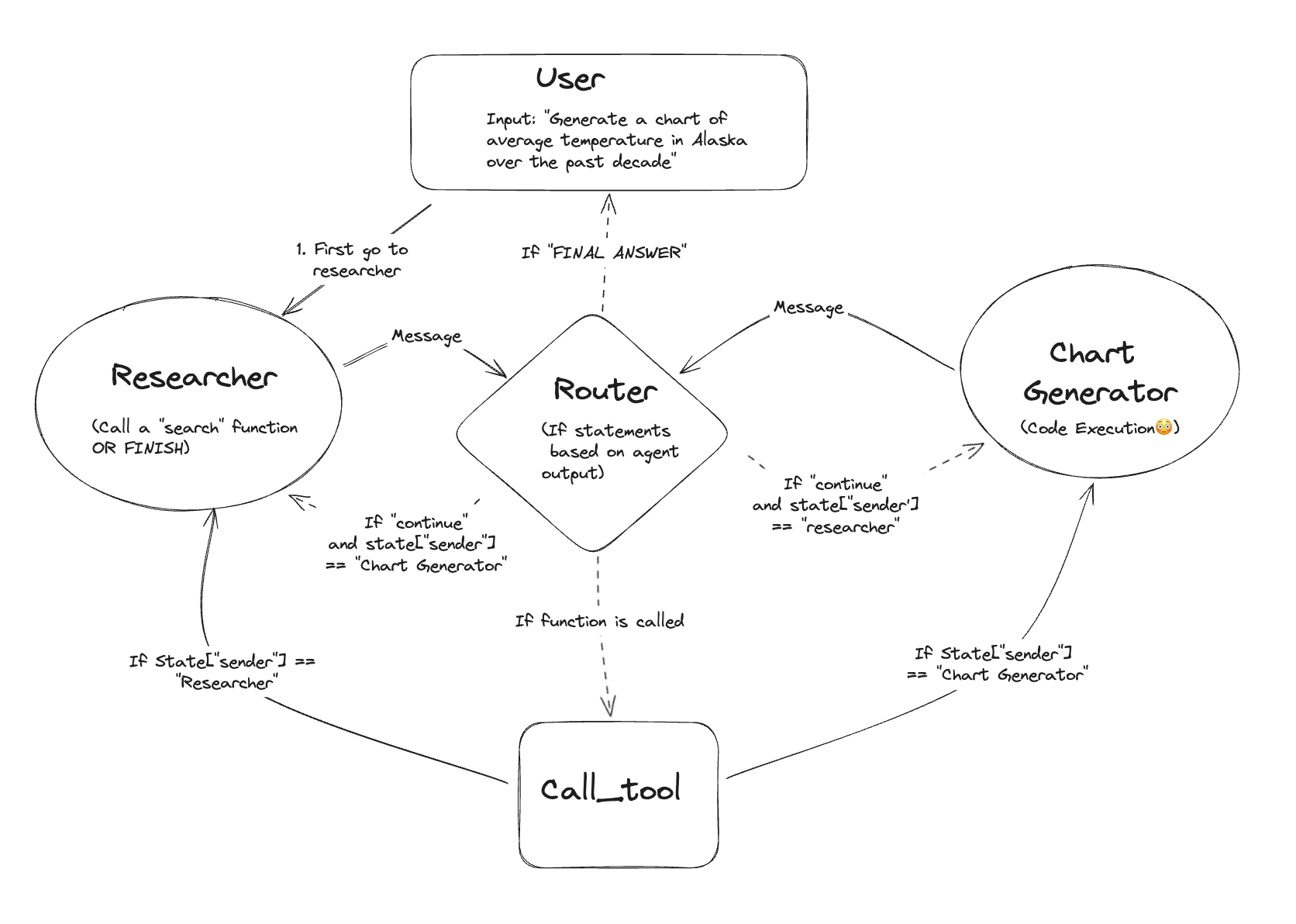
从系统视角看,LangChain 采用了分层 + 模块化的设计思想。
我们可以将其抽象为四个核心层次:
2.2.1 四层核心架构模型
┌────────────────────┐
│ Application 层 │ ← 业务应用
├────────────────────┤
│ Agent / Chain 层 │ ← 流程控制
├────────────────────┤
│ Tool / Memory 层 │ ← 能力扩展
├────────────────────┤
│ Model 层 │ ← 大模型
└────────────────────┘
(1)Model 层:基础推理引擎
负责对接各类大模型:
- OpenAI
- Claude
- 本地模型
- 开源模型
提供统一调用接口。
(2)Tool / Memory 层:能力增强层
为 LLM 提供:
- 工具调用能力
- 状态记忆能力
- 外部系统接口
让模型“走出文本世界”。
(3)Agent / Chain 层:流程控制中枢
负责:
- 决策路径
- 任务拆分
- 调度执行
- 工作流编排
这是智能体系统的“大脑调度中心”。
(4)Application 层:业务封装
面向最终用户:
- Web 应用
- API 服务
- 桌面程序
- 企业系统
这一层是最终交付形态。
总结
LangChain 本质上构建了:
模型 + 能力 + 流程 + 应用 的完整技术栈。
2.3 LangChain 的核心模块体系
为了支撑上述架构,LangChain 将系统拆解为多个标准模块。
核心模块如下:
| 模块 | 作用 |
|---|---|
| Models | 统一模型接口 |
| Prompts | 提示模板 |
| Chains | 链式流程 |
| Tools | 工具系统 |
| Memory | 记忆管理 |
| Retrievers | 检索组件 |
| Agents | 智能体 |
这些模块彼此解耦,又可灵活组合。
2.3.1 模块组合示意
典型调用路径:
User Input
↓
Prompt Template
↓
LLM Model
↓
Agent Decision
↓
Tool / Memory
↓
Final Output
这种设计,使系统具备极强的扩展性。
2.4 LangChain 的核心设计原则
LangChain 之所以能够成为主流框架,与其设计理念密切相关。
下面是最重要的三大原则。
2.4.1 原则一:可组合性(Composable)
LangChain 所有组件都遵循:
“积木式设计”。
例如:
Prompt + Model + Parser = Chain
Chain + Tool = Agent
Agent + Memory = System
开发者可以自由组合。
优势:
✅ 灵活
✅ 可扩展
✅ 易重构
2.4.2 原则二:模型无关性(Model-Agnostic)

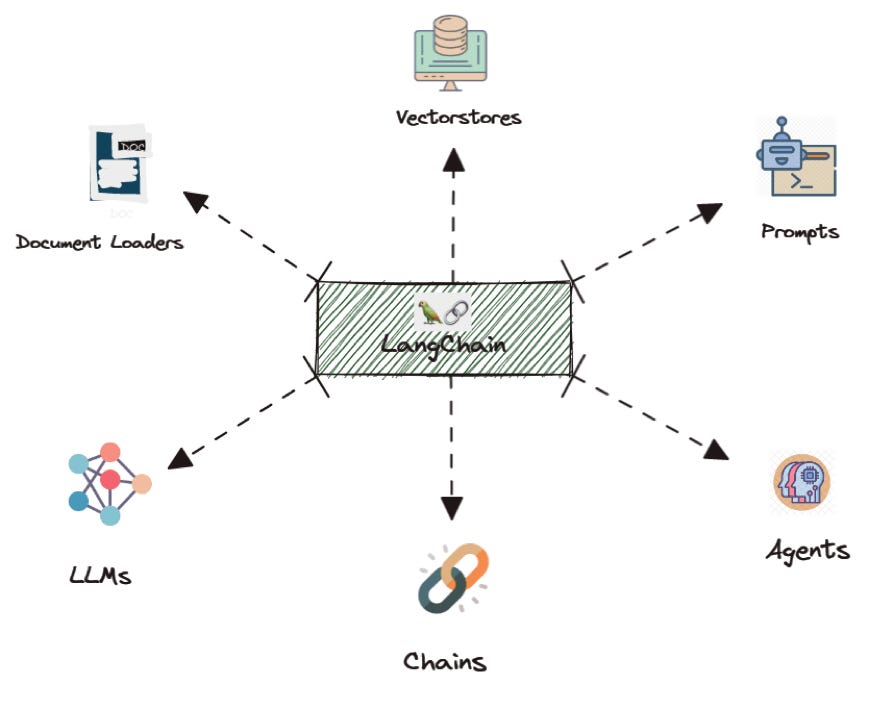
LangChain 并不绑定某个模型厂商。
它通过抽象接口支持:
- 云模型
- 私有模型
- 本地模型
- 混合模型
切换模型时,几乎不需要改业务代码。
优势:
✅ 避免厂商锁定
✅ 成本可控
✅ 易迁移
2.4.3 原则三:面向工程实践(Production-Ready)
LangChain 从设计之初,就考虑了生产环境需求:
- 日志系统
- Trace 追踪
- 调试工具
- 错误恢复
- 性能监控
这使其不仅适合 Demo,更适合落地系统。
2.5 LangChain 在 Agent 系统中的角色
理解 LangChain 最重要的一点是:
它不是 Agent,而是 Agent 的“操作系统”。
2.5.1 类比理解
可以将 LangChain 类比为:
| 领域 | 类比 |
|---|---|
| 操作系统 | Linux |
| LangChain | AI OS |
| Agent | 应用程序 |
LangChain 提供底层能力,Agent 在其之上运行。
2.5.2 Agent 运行时依赖关系
Agent
↓
Chains / Tools / Memory
↓
LangChain Runtime
↓
LLM Provider
三、LangChain 核心组件详解
LangChain 之所以能够高效支撑智能体与复杂 AI 应用的构建,核心原因在于其高度模块化的组件体系设计。
这些组件既相互解耦,又能够灵活组合,形成从「文本生成」到「自动执行任务」的完整能力链路。
LangChain 中最重要的六类核心组件:
- Models(模型层)
- Prompt Templates(提示模板)
- Chains(链式流程)
- Tools(工具系统)
- Memory(记忆管理)
- RAG 相关组件(文档检索体系)
3.1 模型层(Models):驱动推理的引擎
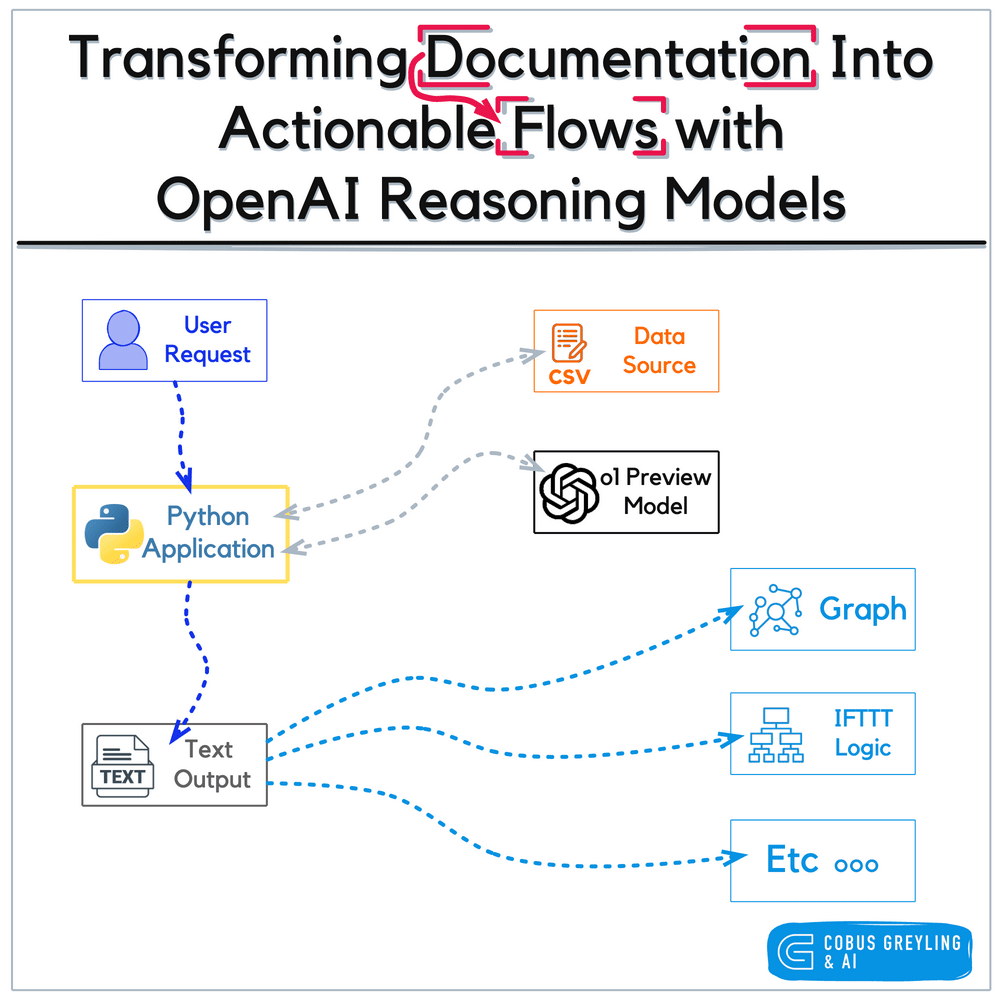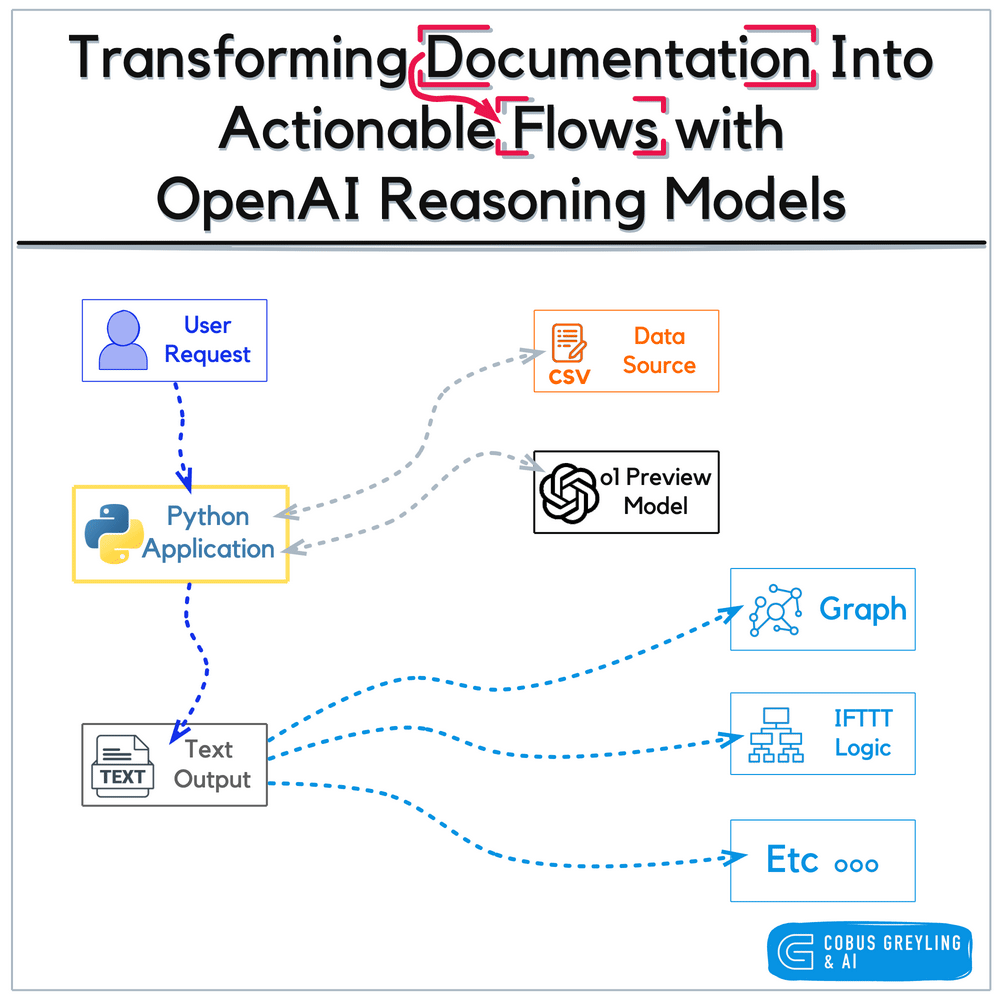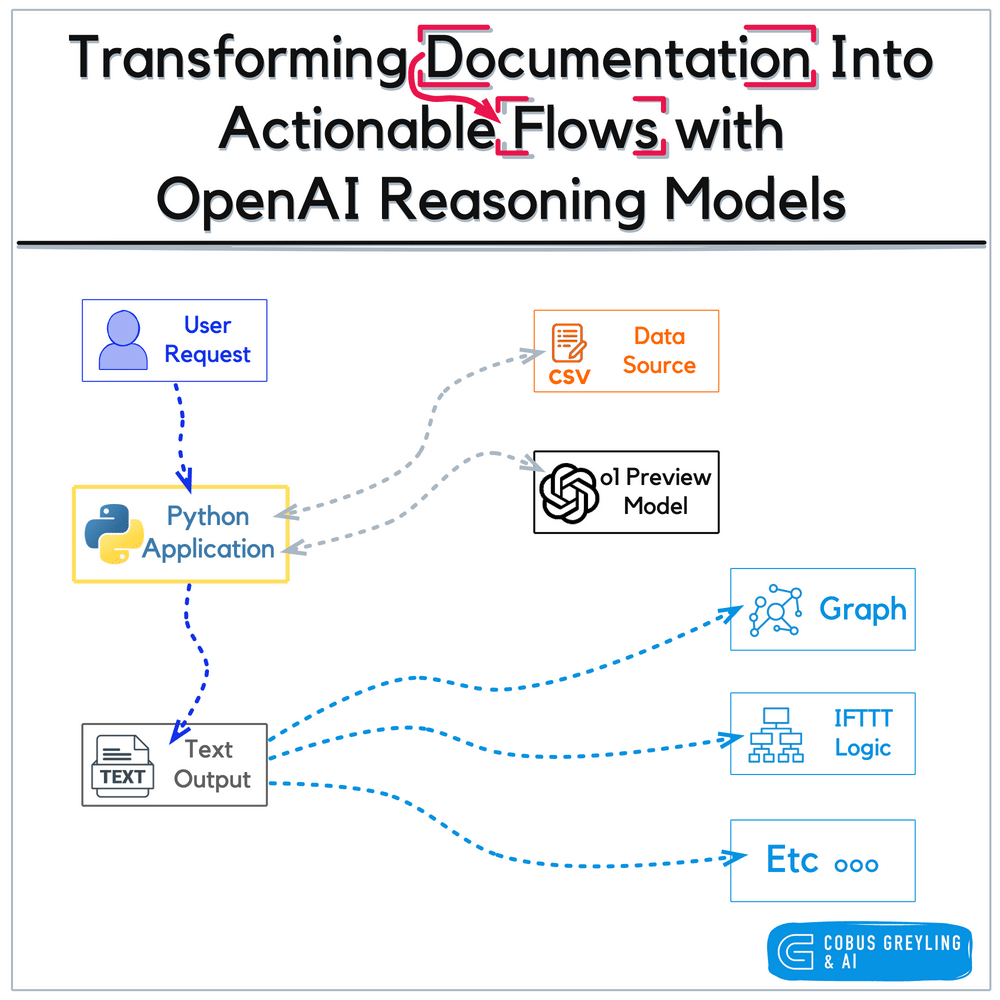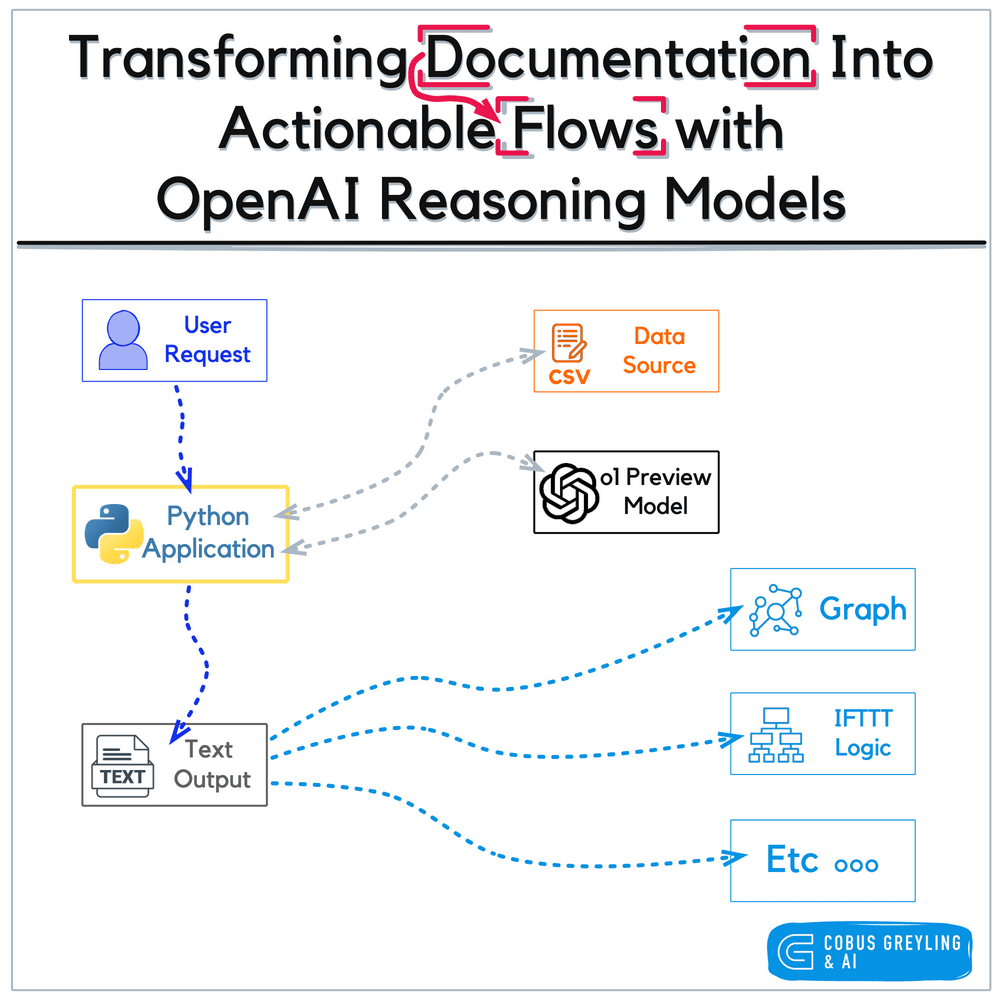
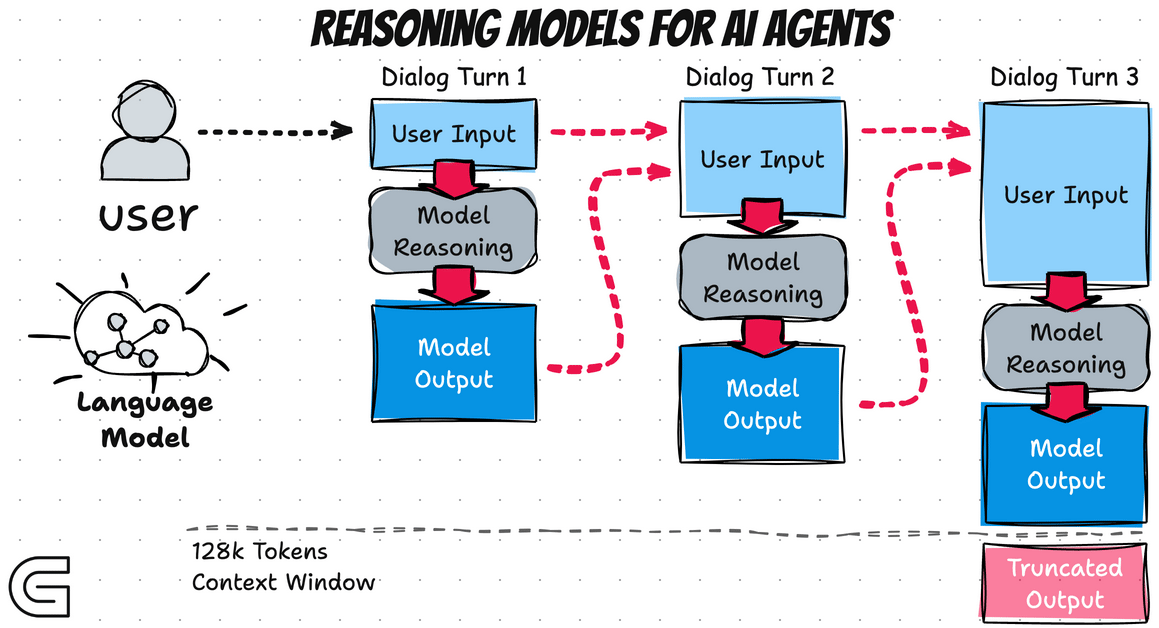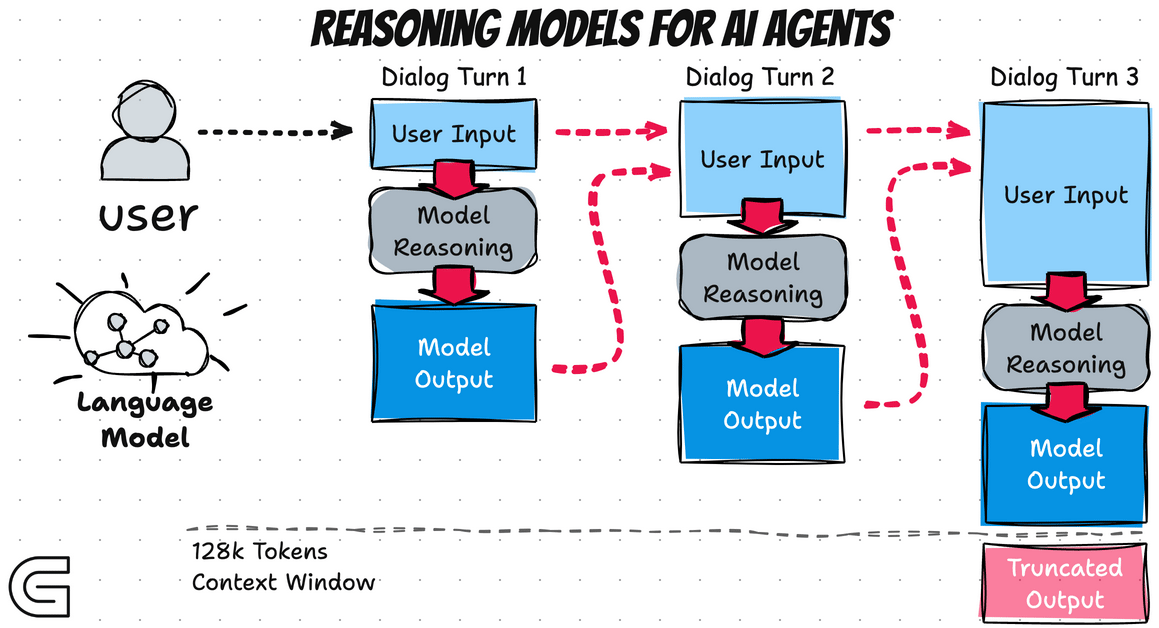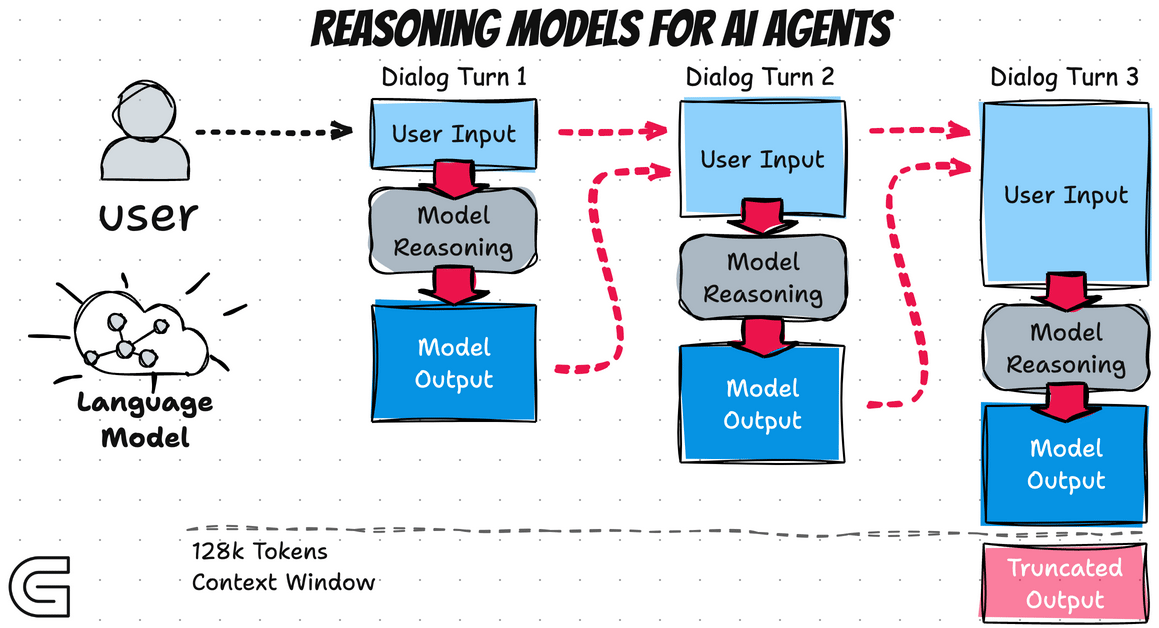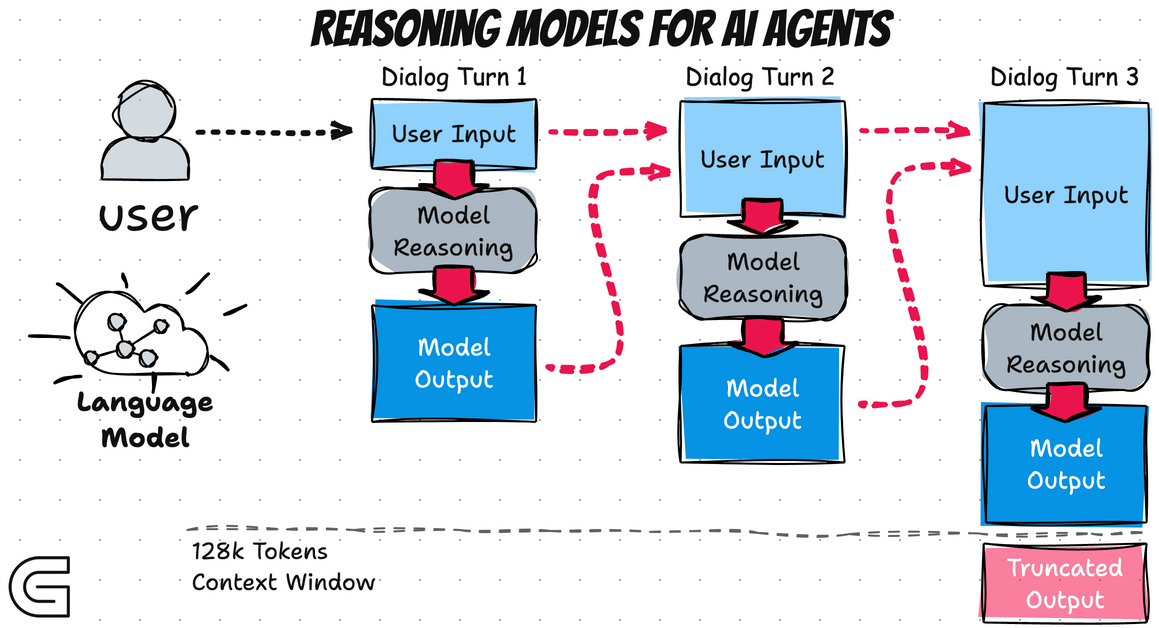
3.1.1 Models 的作用
在 LangChain 中,Models 是整个系统的“认知核心”,负责完成:
- 文本理解
- 逻辑推理
- 内容生成
- 向量计算
所有智能行为的基础,都来源于模型的推理能力。
LangChain 通过统一接口,屏蔽不同模型厂商 API 的差异,使开发者可以用一致的方式调用各种模型。
3.1.2 模型类型划分
LangChain 中常见的模型类型如下:
| 类型 | 作用 | 应用场景 |
|---|---|---|
| LLM | 纯文本生成 | 文本处理、摘要 |
| ChatModel | 多轮对话 | 聊天机器人 |
| Embeddings | 向量生成 | 搜索、RAG |
3.1.3 标准调用流程
模型在 LangChain 中的典型执行流程:
Prompt → Model → 推理 → Output → Parser → 结构化结果
这种标准化流程,使模型可以方便地嵌入到 Chain 和 Agent 中。
3.1.4 设计价值
Models 抽象层带来的优势:
- 支持多模型切换
- 避免厂商绑定
- 支持混合部署
- 便于成本控制
3.2 提示模板(Prompt Templates):构建可控输入
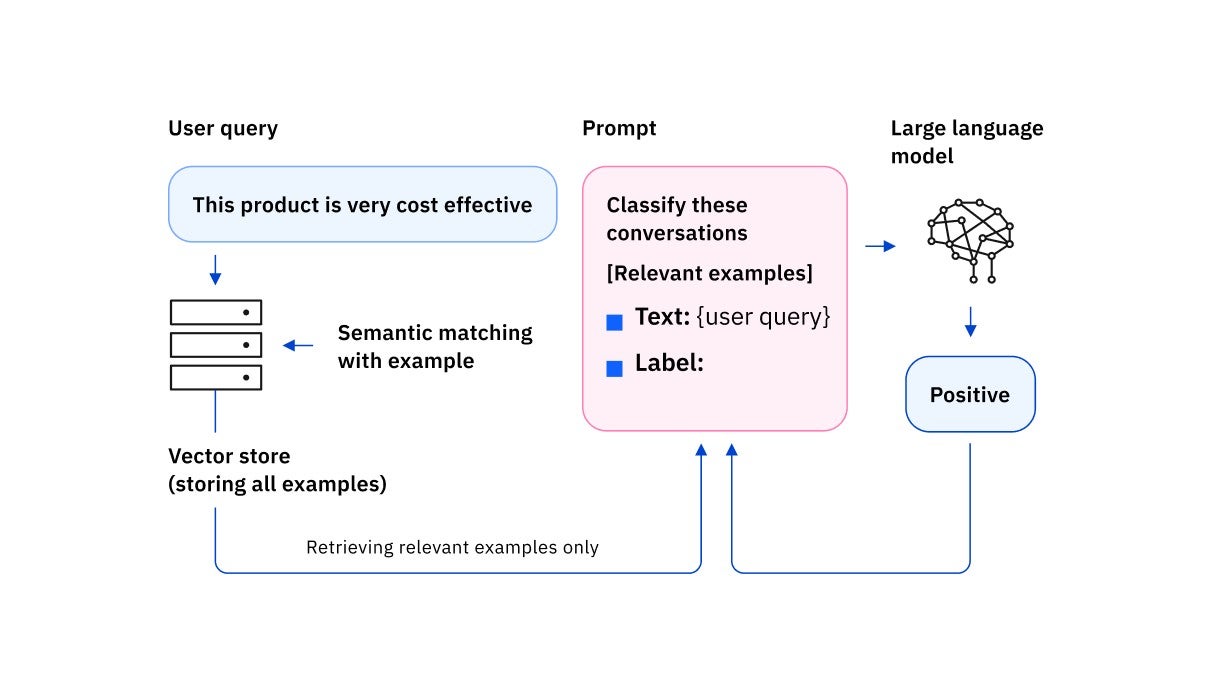
3.2.1 为什么需要 Prompt 模板
如果直接在代码中硬编码 Prompt:
- 难维护
- 难复用
- 易出错
- 难调试
Prompt Templates 的目标是:
将提示词“工程化”。
3.2.2 核心功能
Prompt Templates 提供:
- 变量占位
- 参数填充
- Few-shot 示例
- 消息角色管理
例如:
你是一个{role},请根据{context}完成{task}
3.2.3 模板类型
常见模板形式:
| 类型 | 用途 |
|---|---|
| PromptTemplate | 单轮任务 |
| ChatPromptTemplate | 多轮对话 |
| FewShotPrompt | 示例学习 |
3.2.4 工程意义
模板化 Prompt 能够:
- 提升稳定性
- 统一规范
- 方便调优
- 支持版本管理
是构建大型系统的基础能力。
3.3 Chains:链式调用与工作流引擎
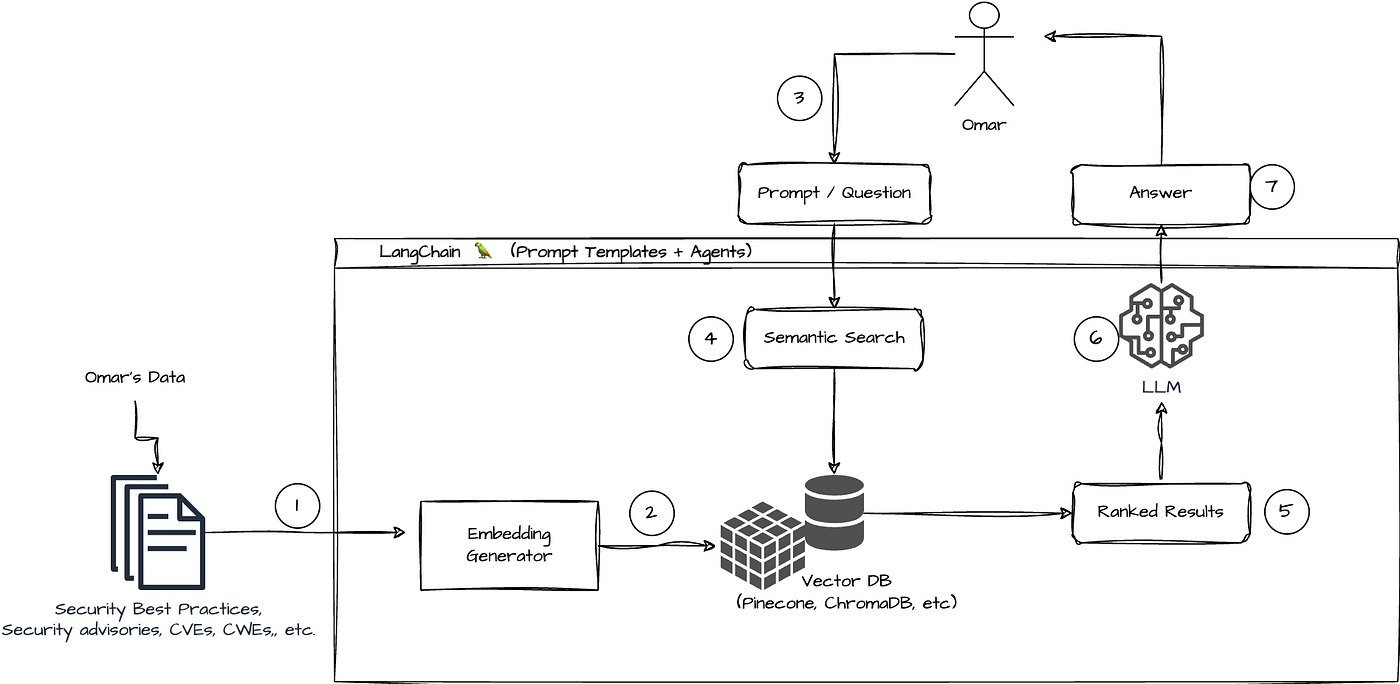
3.3.1 什么是 Chain
Chain 是 LangChain 中用于描述多步骤执行流程的核心机制。
本质上:
Chain = 多个组件的有序组合。
3.3.2 Chain 的基本结构
典型 Chain:
Input → Prompt → Model → Parser → Output
复杂 Chain:
Chain1 → Chain2 → Tool → Chain3 → Result
3.3.3 常见 Chain 类型
| 类型 | 功能 |
|---|---|
| LLMChain | 基础生成 |
| SequentialChain | 顺序执行 |
| RouterChain | 分支路由 |
| TransformChain | 数据转换 |
3.3.4 Chain 的价值
Chains 让系统具备:
- 流程复用能力
- 逻辑模块化
- 工作流编排能力
- 可测试性
是构建复杂 AI 系统的重要基础。
3.4 工具层(Tools):连接现实世界的接口
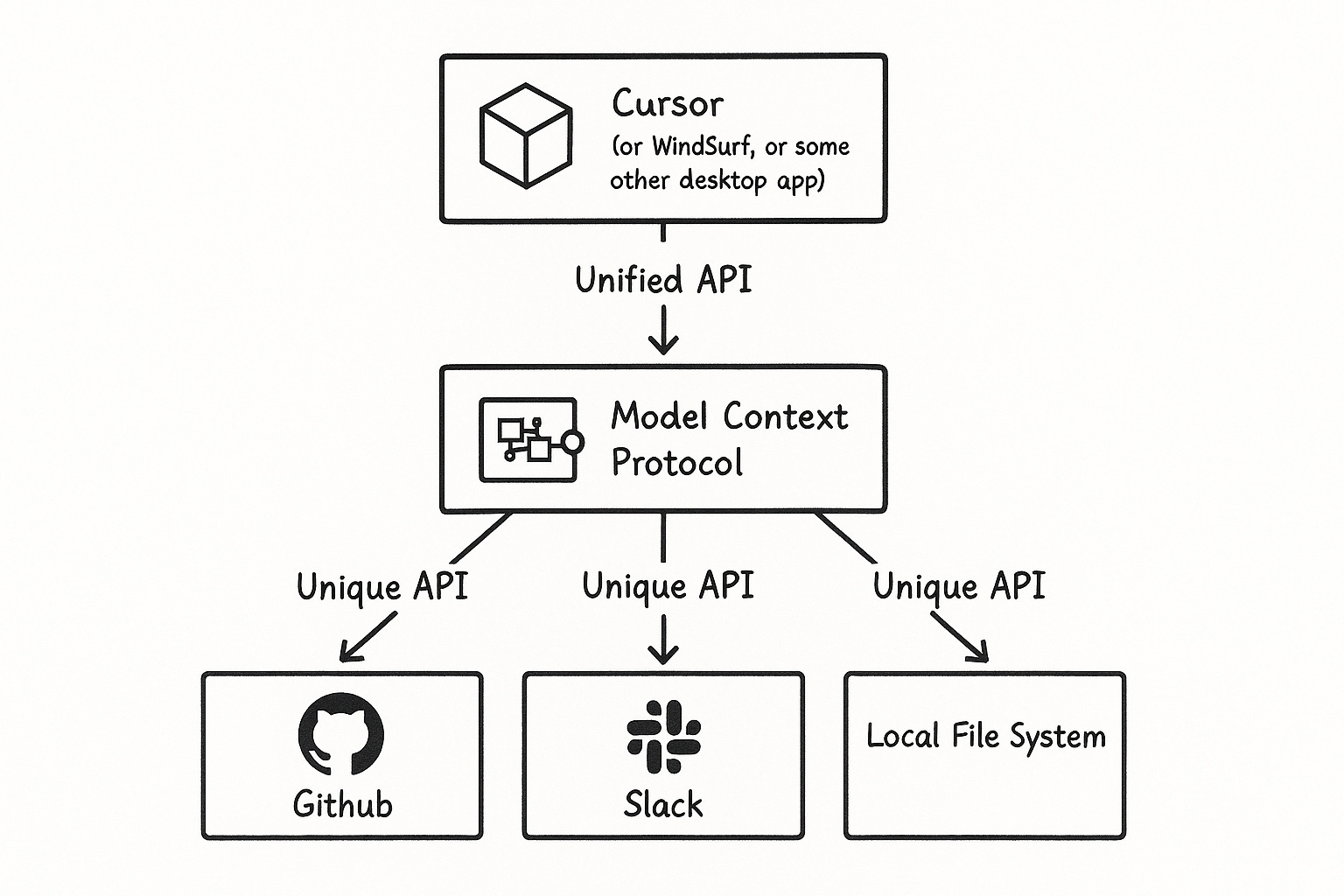
3.4.1 Tools 的本质
Tools 是 LangChain 对外部能力的统一封装接口。
其目标是:
让模型拥有“行动能力”。
3.4.2 常见工具类型
| 工具类型 | 示例 |
|---|---|
| 搜索工具 | Web Search |
| 计算工具 | Calculator |
| 数据库 | SQL Tool |
| 文件工具 | File Tool |
| API 工具 | REST API |
3.4.3 Tool 的调用流程
Agent 调用工具的一般流程:
分析任务 → 选择 Tool → 传参 → 执行 → 返回结果
3.4.4 工程意义
Tools 让 Agent:
- 操作真实系统
- 访问外部数据
- 执行自动任务
- 构建闭环系统
是从“聊天机器人”进化为“智能助手”的关键。
3.5 记忆管理(Memory):构建长期上下文能力
3.5.1 为什么需要 Memory
没有记忆的系统:
- 无法理解历史
- 无法持续任务
- 体验割裂
Memory 的目标是:
让系统具备状态感知能力。
3.5.2 Memory 类型
| 类型 | 特点 |
|---|---|
| BufferMemory | 完整历史 |
| SummaryMemory | 压缩摘要 |
| EntityMemory | 实体追踪 |
| VectorMemory | 向量记忆 |
3.5.3 工作机制
Memory 的典型流程:
输入 → 读取历史 → 合并上下文 → 推理 → 更新记忆
3.5.4 实践价值
合理使用 Memory 可以:
- 降低 Token 消耗
- 提升对话连贯性
- 支持长期任务
- 建立用户画像
3.6 文档处理与检索(RAG 相关组件)
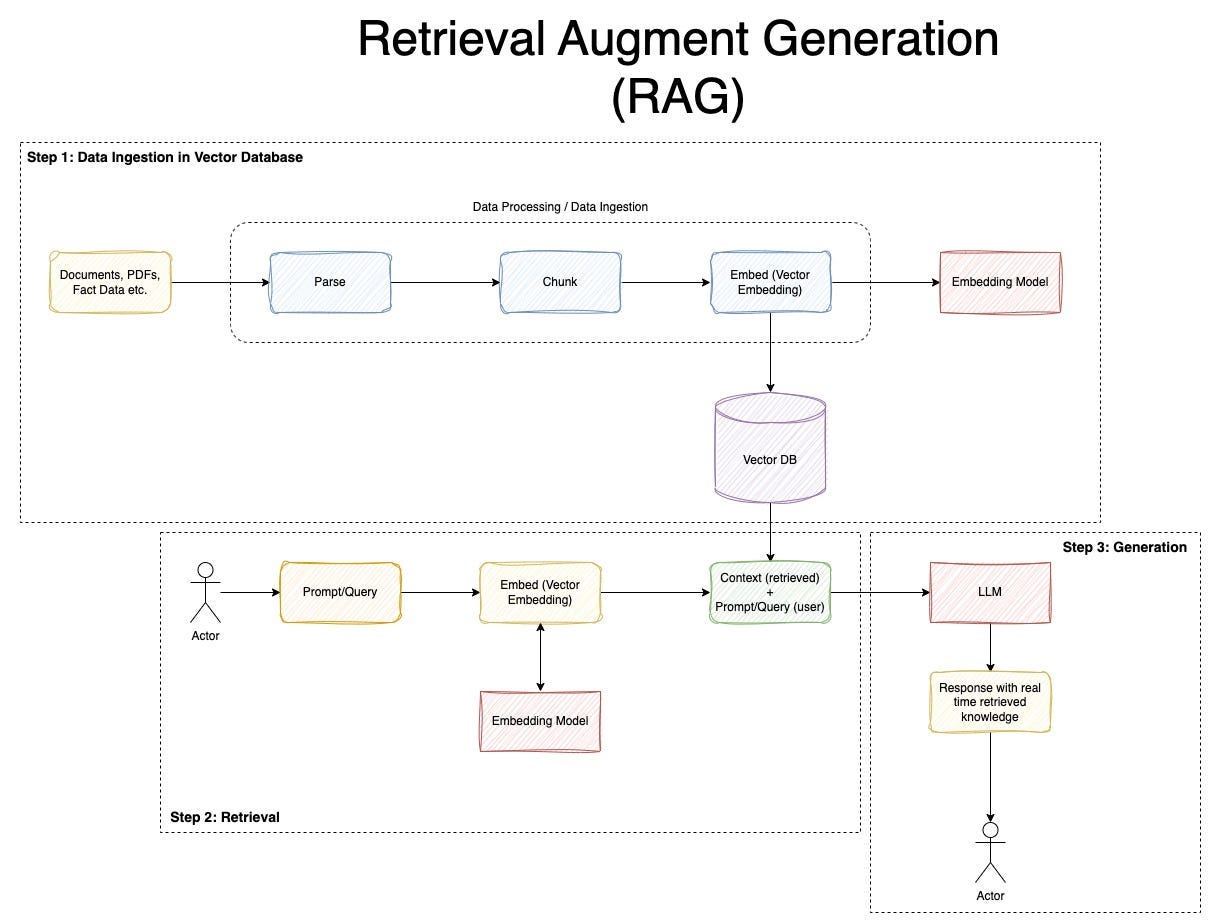
3.6.1 RAG 的核心思想
RAG(Retrieval-Augmented Generation)核心理念:
用外部知识增强模型回答能力。
避免模型“胡编乱造”。
3.6.2 RAG 组件体系
LangChain 提供完整 RAG 组件链路:
| 组件 | 功能 |
|---|---|
| DocumentLoader | 加载数据 |
| TextSplitter | 文本切分 |
| Embeddings | 向量化 |
| VectorStore | 存储 |
| Retriever | 检索 |
3.6.3 标准流程
文档 → 切分 → 向量化 → 存储
查询 → 相似度搜索 → 片段拼接 → 生成
3.6.4 应用场景
RAG 常用于:
- 企业知识库
- 技术文档问答
- 内部资料检索
- 专业领域助手
是企业级 AI 系统的核心能力之一。
3.7 核心组件协同关系总结
将上述组件组合起来,可以得到完整系统结构:
User
↓
Prompt Template
↓
Model
↓
Chain / Agent
↓
Tool / Memory / Retriever
↓
Result
各组件分工明确:
| 模块 | 核心职责 |
|---|---|
| Models | 推理 |
| Prompts | 控制输入 |
| Chains | 编排流程 |
| Tools | 执行动作 |
| Memory | 维护状态 |
| RAG | 增强知识 |
四、 智能体(Agents)详解:从思考到行动的原理与实现
在 LangChain 体系中,Agent(智能体)是连接“理解—决策—执行—反馈”全过程的核心枢纽。
如果说 Chain 解决的是“固定流程自动化”,那么 Agent 解决的就是:
在不确定环境中,如何让 AI 自主思考并动态行动。
4.1 智能体是什么?
4.1.1 Agent 的定义
在 LangChain 语境中,Agent 可以理解为:
一个能够自主推理、选择工具并完成任务的 AI 执行系统。
其核心特征包括:
- 具备目标导向
- 拥有推理能力
- 可调用外部工具
- 能根据结果动态调整策略
本质上,Agent = LLM + 决策逻辑 + 工具系统 + 状态管理。
4.1.2 Agent 与 Chain 的根本区别
| 维度 | Chain | Agent |
|---|---|---|
| 流程 | 固定 | 动态 |
| 决策 | 人工设计 | 模型驱动 |
| 灵活性 | 低 | 高 |
| 自主性 | 无 | 有 |
Chain 适合“已知流程”,
Agent 适合“开放任务”。
4.1.3 Agent 的基本工作循环
智能体的经典运行模式:
感知任务 → 推理 → 决策 → 行动 → 观察 → 再推理
也可抽象为:
Think → Act → Observe → Reflect
这是现代大模型 Agent 的通用范式。
4.1.4 Agent 的核心价值
引入 Agent 后,系统具备:
- 自适应能力
- 多路径探索能力
- 自动纠错能力
- 复杂任务处理能力
这使 AI 从“工具”升级为“执行者”。
4.2 Agent 的决策逻辑与运行引擎
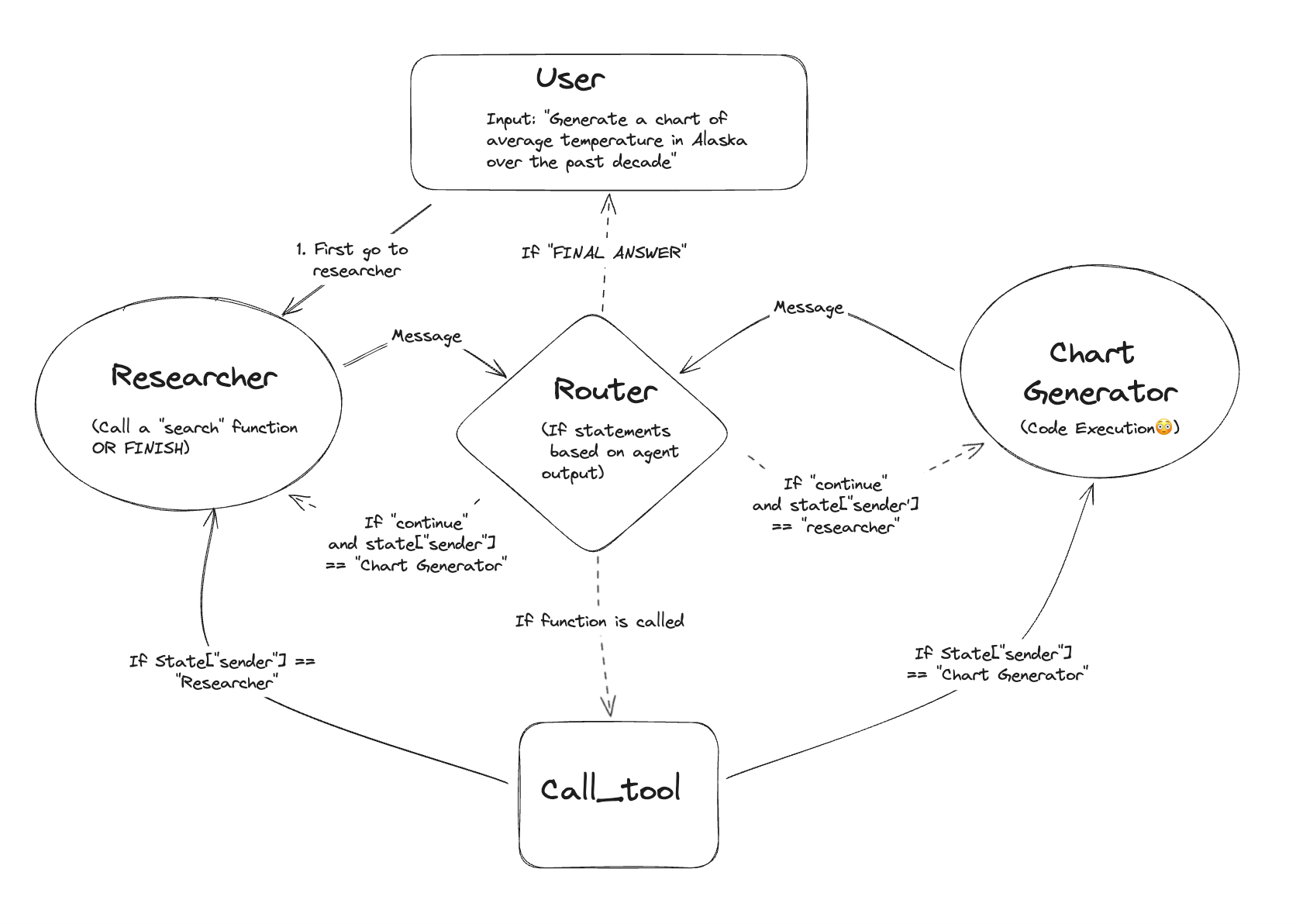
4.2.1 Agent Executor:执行中枢
在 LangChain 中,Agent 并不是“自己跑”的,而是由执行引擎统一调度。
核心组件是:
AgentExecutor
主要职责:
- 管理推理循环
- 调用 LLM
- 调度 Tools
- 控制终止条件
- 维护上下文
可以理解为 Agent 的“操作系统”。
4.2.2 决策流程拆解
一个完整 Agent 决策周期:
1. 接收用户输入
2. 组合 Prompt + Memory
3. 调用 LLM 推理
4. 解析 Action
5. 执行 Tool
6. 获取 Observation
7. 更新状态
8. 进入下一轮
对应逻辑结构:
Input → Reason → Decide → Execute → Feedback → Loop
4.2.3 Scratchpad:中间思考区
Scratchpad(思考草稿区)用于存储:
- 推理过程
- 历史决策
- 中间结果
示例结构:
Thought: 我需要查询天气
Action: weather_api
Input: 北京
Observation: 晴 20℃
作用:
- 增强可解释性
- 提高推理稳定性
- 避免重复思考
这是 ReAct 类 Agent 的关键机制。
4.2.4 Graph-based Runtime(LangGraph 思路)
新一代 Agent 系统逐步采用:
图结构执行模型(Graph Runtime)
核心思想:
- 节点 = 功能单元
- 边 = 状态转移
- 图 = 执行流程
优势:
- 支持并行
- 易调试
- 可回滚
- 易扩展
适合复杂生产级 Agent 系统。
4.2.5 终止与安全控制
Agent 必须具备终止机制:
- 最大循环次数
- 置信度阈值
- 超时限制
- 异常中断
否则容易产生:
- 死循环
- Token 爆炸
- 成本失控
4.3 Agent 类型对比与架构模式
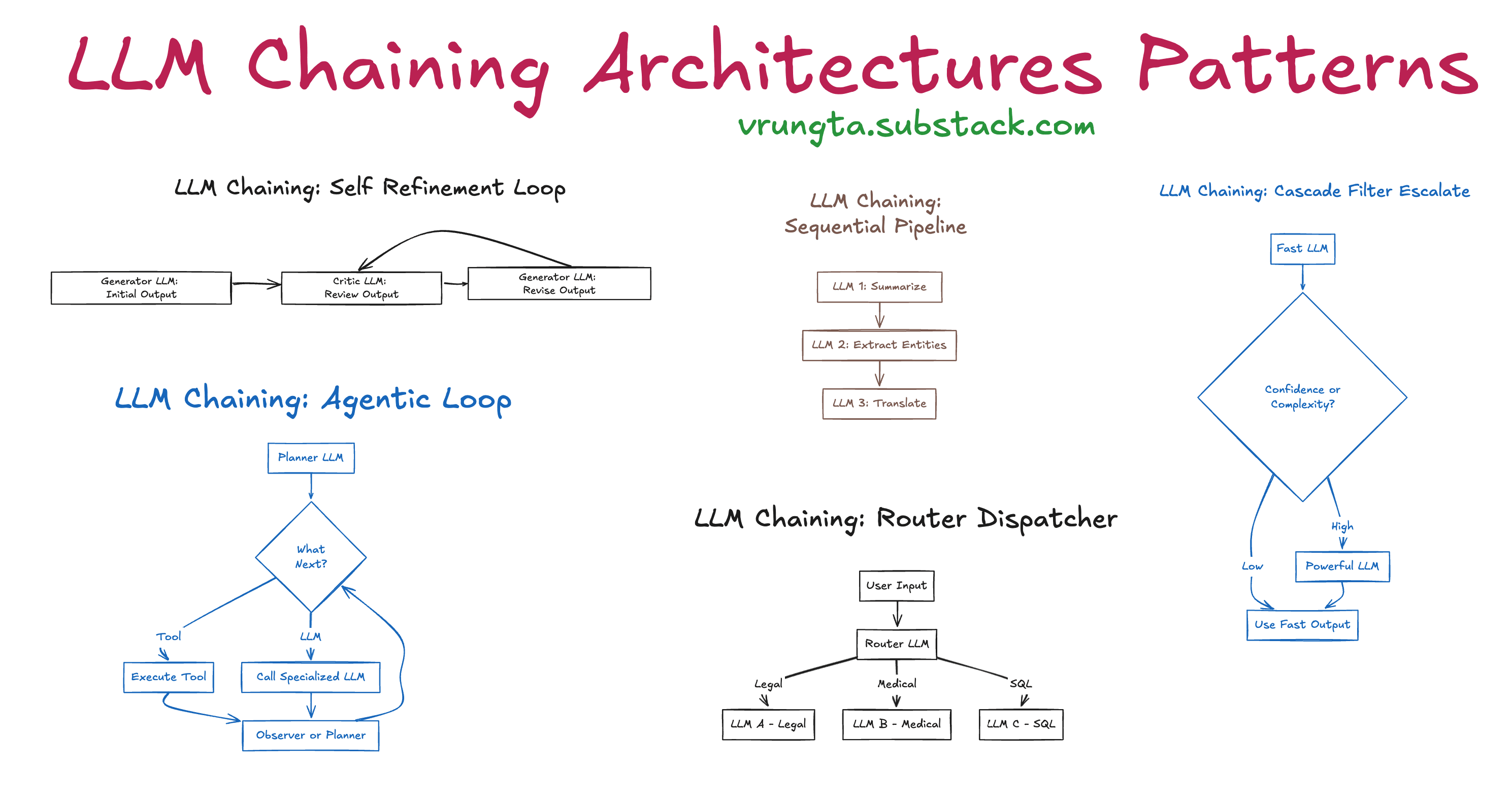
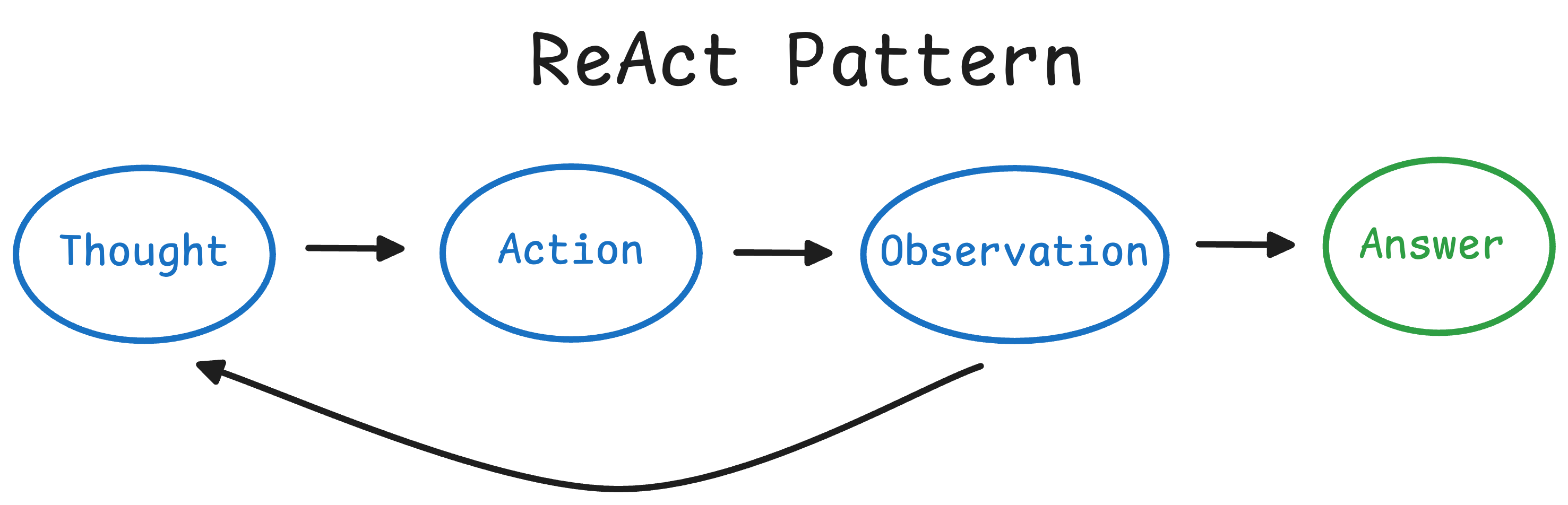
4.3.1 ReAct Agent(推理 + 行动)
ReAct(Reason + Act)是最经典 Agent 架构。
基本模式:
Thought → Action → Observation → Thought
特点:
- 显式推理
- 可解释性强
- 灵活度高
适用场景:
- 研究型系统
- 复杂决策任务
- 调试友好环境
4.3.2 Function / Tool Calling Agent
该类型基于模型原生函数调用能力。
工作方式:
模型 → 输出 JSON → 自动调用函数
特点:
- 结构稳定
- 成本可控
- 适合生产环境
优势:
- 减少 Prompt 干扰
- 提升可靠性
- 易做权限控制
常用于企业系统。
4.3.3 Tool Calling Agent(工具驱动型)
该模式强调:
工具即能力。
Agent 通过 Tool Registry 进行能力扩展。
特点:
- 插件化设计
- 易扩展
- 解耦业务逻辑
适合平台级 AI 架构。
4.3.4 多智能体协作(Multi-Agent)
当任务复杂时,单 Agent 不够用。
多 Agent 架构:
Planner → Sub-Agent → Reviewer → Integrator
典型角色:
| Agent | 职责 |
|---|---|
| Planner | 规划任务 |
| Worker | 执行任务 |
| Critic | 评估结果 |
| Manager | 协调资源 |
优势:
- 并行处理
- 专业分工
- 鲁棒性高
适用于复杂系统开发。
4.3.5 Agent 类型对比总结
| 类型 | 推理 | 稳定性 | 扩展性 | 适用场景 |
|---|---|---|---|---|
| ReAct | 强 | 中 | 高 | 实验研究 |
| Function Calling | 中 | 高 | 中 | 商业系统 |
| Tool Agent | 中 | 中 | 高 | 平台架构 |
| Multi-Agent | 强 | 高 | 很高 | 复杂工程 |
4.4 Agent 系统的工程结构抽象
综合来看,一个完整 Agent 系统可抽象为:
User
↓
Prompt + Memory
↓
Agent Core
↓
Decision Engine
↓
Tool System / Retriever
↓
Observation
↓
Feedback Loop
核心模块职责:
| 模块 | 功能 |
|---|---|
| Agent Core | 统筹逻辑 |
| Executor | 调度循环 |
| Planner | 分解任务 |
| Tool Layer | 执行能力 |
| Memory | 状态管理 |
| Monitor | 监控分析 |
五、 LangChain 实战:从零实现你的第一个 Agent
本章以「动手实践」为核心目标,带你从环境配置开始,一步步搭建一个可运行、可扩展的智能体系统,并逐步引入记忆与知识库能力。
5.1 环境准备与基础安装
5.1.1 基础环境要求
推荐环境配置:
| 项目 | 建议 |
|---|---|
| Python | ≥ 3.9 |
| 系统 | Linux / macOS / Windows |
| 编辑器 | VSCode / PyCharm |
5.1.2 安装核心依赖
典型依赖组合:
pip install langchain
pip install langchain-openai
pip install faiss-cpu
pip install tiktoken
pip install python-dotenv
说明:
langchain:核心框架langchain-openai:模型适配faiss:向量检索dotenv:密钥管理
5.1.3 API Key 管理
推荐使用 .env 文件:
OPENAI_API_KEY=sk-xxxx
加载方式:
from dotenv import load_dotenv
load_dotenv()
这样可以避免密钥泄露到代码仓库。
5.1.4 项目基础结构建议
推荐目录结构:
project/
├─ agents/
├─ tools/
├─ memory/
├─ rag/
├─ main.py
└─ config.py
有助于后期维护和扩展。
5.2 第一个 Agent 示例:天气 + 计算助手
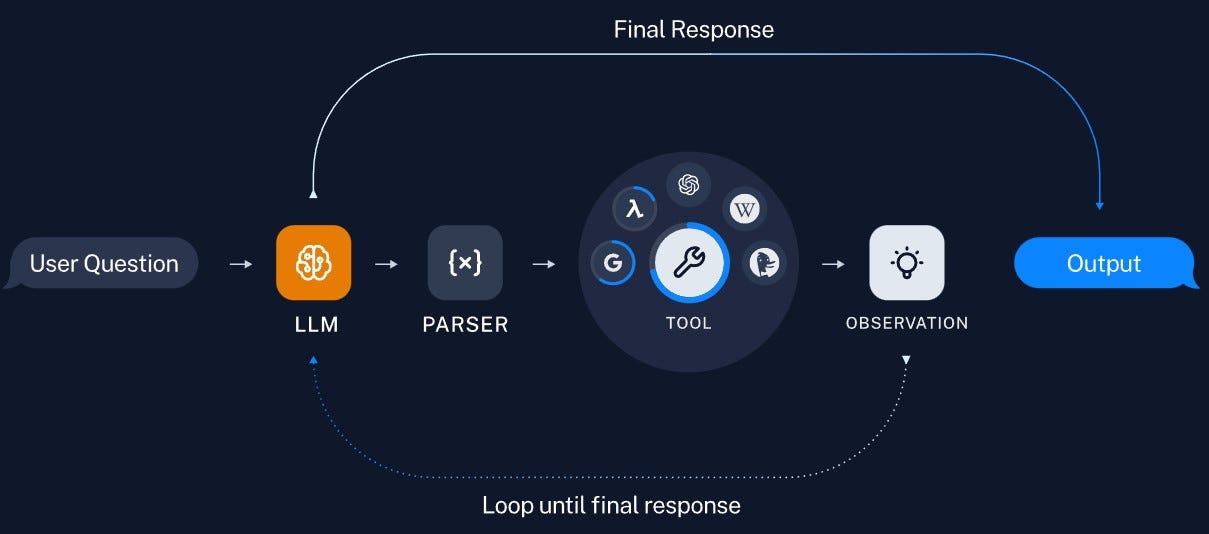
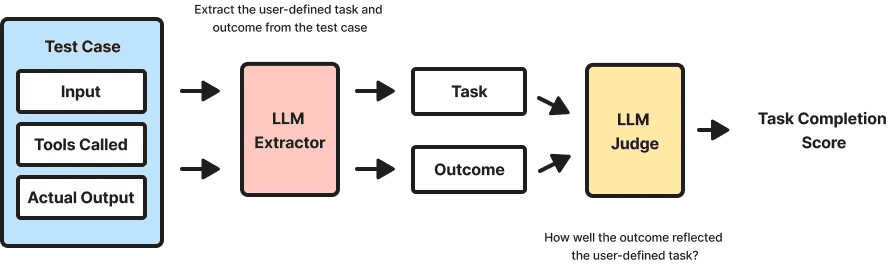
本节实现一个基础智能体,具备:
- 查询天气
- 数学计算
- 多轮对话
- 自动工具选择
5.2.1 定义工具(Tools)
示例工具结构:
from langchain.tools import tool
@tool
def calculator(expression: str) -> str:
return str(eval(expression))
工具本质是:
带有语义描述的可调用函数。
5.2.2 注册工具
tools = [
calculator,
weather_tool
]
注册后,Agent 即可感知这些能力。
5.2.3 配置 Memory
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
用于保存历史对话。
5.2.4 构建 AgentExecutor
from langchain.agents import initialize_agent
agent = initialize_agent(
tools=tools,
llm=llm,
memory=memory,
agent="zero-shot-react-description"
)
该组件负责:
- 控制推理循环
- 调度工具
- 管理状态
5.2.5 执行流程示意
用户问题
↓
Agent 推理
↓
选择工具
↓
执行工具
↓
整合结果
↓
输出答案
示例调用:
agent.run("帮我算一下 12 * 35,再查一下北京天气")
5.2.6 中间过程可视化
典型推理过程:
Thought: 需要先计算,再查天气
Action: calculator
Input: 12*35
Observation: 420
Action: weather_tool
Input: 北京
Observation: 晴
这体现了 Agent 的“思考—行动”机制。
5.3 加入文档检索 + 记忆增强
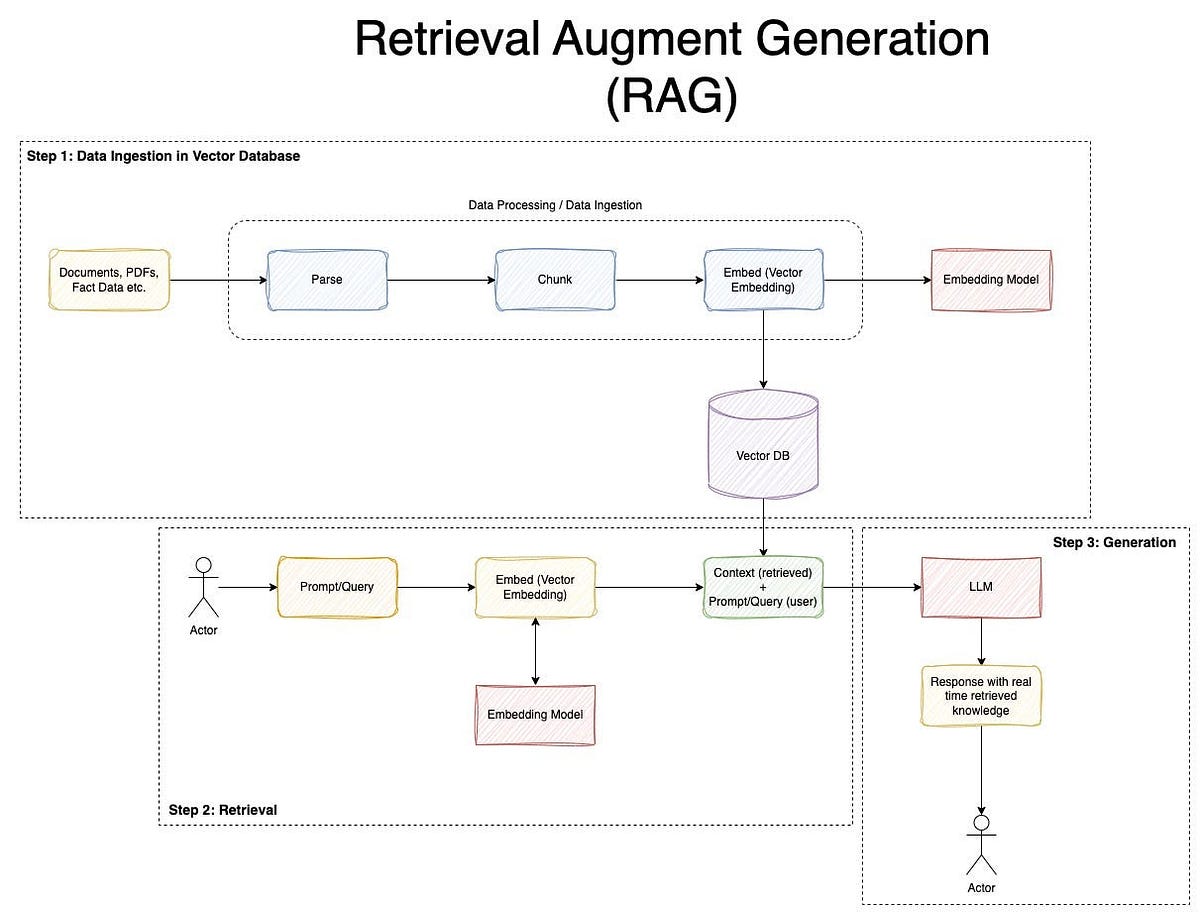
5.3.1 构建本地知识库
加载文档:
from langchain.document_loaders import TextLoader
loader = TextLoader("docs.txt")
docs = loader.load()
5.3.2 文本切分
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = splitter.split_documents(docs)
5.3.3 向量化与存储
from langchain.vectorstores import FAISS
db = FAISS.from_documents(chunks, embeddings)
5.3.4 构建 Retriever Tool
retriever = db.as_retriever()
并注册为 Agent Tool。
5.3.5 增强后工作流程
用户问题
↓
Agent 判断是否检索
↓
Retriever 查询
↓
拼接上下文
↓
LLM 生成
5.3.6 长期记忆应用场景
结合 Vector Memory 后,可实现:
- 用户偏好存储
- 项目状态跟踪
- 长期任务管理
形成“长期智能助手”。
六、 多智能体协作与工程实践
6.1 多 Agent 编排与协作模式
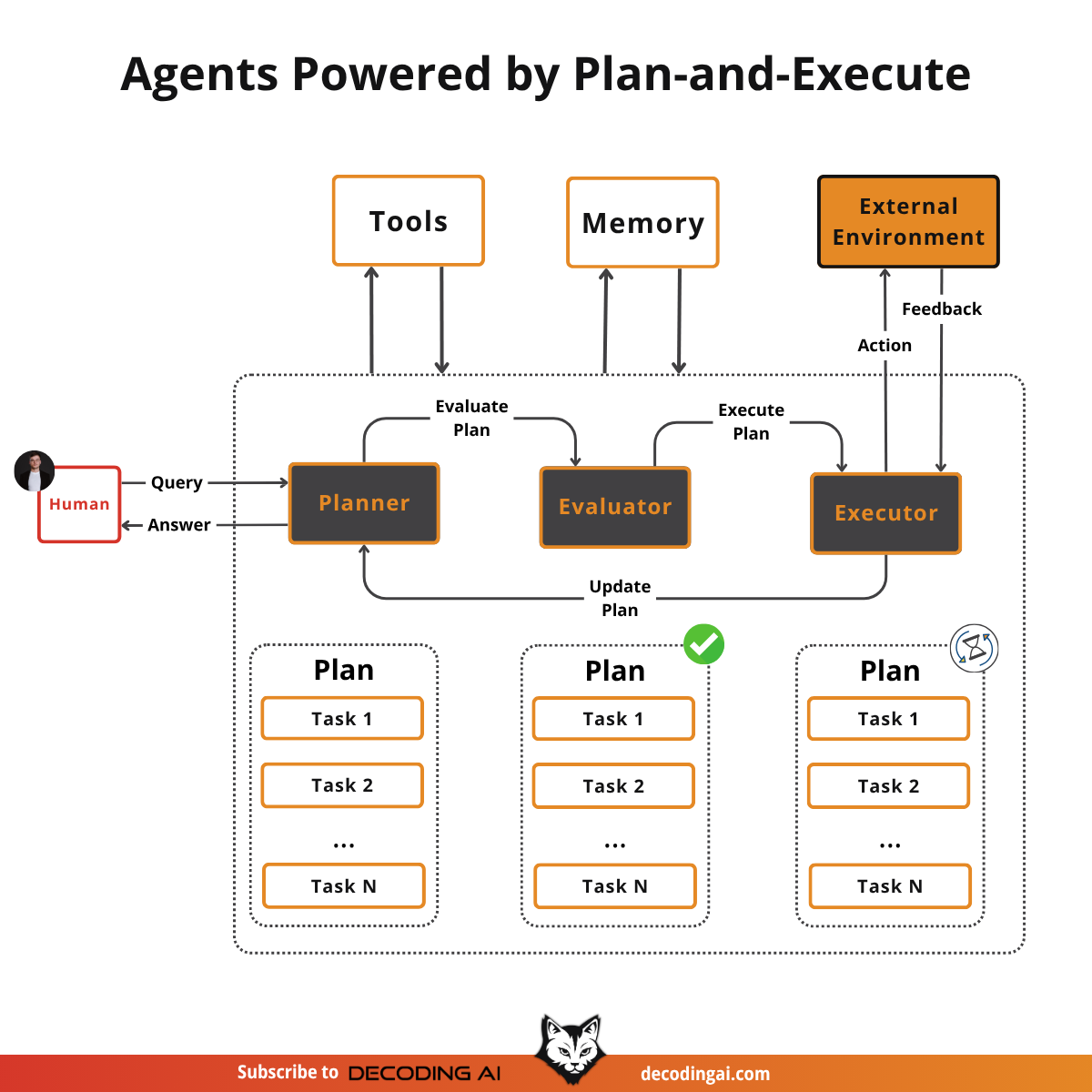
6.1.1 为什么需要多 Agent
复杂任务通常具备:
- 多阶段
- 多领域
- 多目标
单 Agent 易出现:
- 推理过载
- 错误累积
- 上下文爆炸
6.1.2 经典架构:Planner–Executor
典型模式:
Planner → Executor → Reviewer → Integrator
职责划分:
| Agent | 职能 |
|---|---|
| Planner | 任务拆分 |
| Executor | 执行子任务 |
| Reviewer | 校验结果 |
| Manager | 资源调度 |
6.1.3 协作通信机制
多 Agent 通信方式:
- 消息队列
- 共享 Memory
- Graph 状态传递
- API 调用
示意流程:
任务 → 拆分 → 并行执行 → 汇总 → 输出
6.1.4 多 Agent 的优势
- 并行处理
- 错误隔离
- 专业分工
- 可扩展性强
适合大型系统。
6.2 调试与可观测性(Tracing & Monitoring)
生产环境中,Agent 系统必须具备完整的可观测能力。
6.2.1 为什么需要可观测性
缺乏监控的 Agent 系统容易出现:
- 隐性死循环
- 成本失控
- 输出异常
- 性能退化
6.2.2 核心监控维度
| 维度 | 说明 |
|---|---|
| 调用链路 | 推理路径 |
| Token | 成本控制 |
| 延迟 | 性能评估 |
| 工具成功率 | 稳定性 |
| 错误率 | 可靠性 |
6.2.3 Trace 机制原理
Trace 记录完整执行过程:
User Input
↓
Prompt
↓
LLM Call
↓
Tool Call
↓
Observation
↓
Output
可回放每一步。
6.2.4 调试方法论
推荐实践:
- 开启全链路日志
- 保留中间推理
- 标准化异常码
- 建立回归测试集
6.2.5 性能优化方向
| 方向 | 手段 |
|---|---|
| 成本 | Prompt 压缩 |
| 速度 | 并行化 |
| 稳定性 | Cache |
| 质量 | 多模型投票 |
附录:智能体完整代码与运行示例
说明:
本附录演示了一个基于 本地 Ollama 的 Agent 测试示例,支持 RAG、计算器、天气查询和多轮对话。无需 OpenAI API Key 或其他在线模型密钥。
项目目录
project/
├─ agents/
│ └─ agent_executor.py
├─ tools/
│ ├─ calculator.py
│ └─ weather_tool.py
├─ memory/
│ └─ conversation_memory.py
├─ rag/
│ ├─ loader.py
│ ├─ splitter.py
│ └─ vectorstore.py
├─ main.py
├─ docs.txt
└─ config.py
代码模块
config.py
import os
from dotenv import load_dotenv
load_dotenv()
# Ollama 配置
OLLAMA_BASE_URL = os.getenv("OLLAMA_BASE_URL", "http://localhost:1314")
OLLAMA_MODEL = os.getenv("OLLAMA_MODEL", "qwen2.5:3b")
tools/calculator.py
from langchain.tools import tool
@tool
def calculator(expression: str) -> str:
try:
expression = expression.strip().strip('"').strip("'")
result = eval(expression)
return str(result)
except Exception as e:
return f"计算错误: {e}"
tools/weather_tool.py
from langchain.tools import tool
@tool
def weather_tool(city: str) -> str:
city = city.strip().strip('"').strip("'")
fake_weather = {
"北京": "晴 20°C",
"上海": "多云 22°C",
"深圳": "雷阵雨 28°C"
}
return fake_weather.get(city, "无法查询该城市天气")
memory/conversation_memory.py
from langchain.memory import ConversationBufferMemory
def get_memory():
return ConversationBufferMemory()
rag/loader.py
from langchain_community.document_loaders import TextLoader
def load_documents(path: str):
loader = TextLoader(path)
return loader.load()
rag/splitter.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
def split_docs(docs, chunk_size=500, chunk_overlap=50):
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
return splitter.split_documents(docs)
rag/vectorstore.py
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings
from config import OLLAMA_BASE_URL, OLLAMA_MODEL
embeddings = OllamaEmbeddings(
base_url=OLLAMA_BASE_URL,
model=OLLAMA_MODEL
)
def create_vectorstore(chunks):
db = Chroma.from_documents(chunks, embeddings)
return db.as_retriever()
agents/agent_executor.py
from langchain_ollama import ChatOllama
from langchain.agents import create_react_agent, AgentExecutor
from langchain import hub
from config import OLLAMA_BASE_URL, OLLAMA_MODEL
def create_agent(tools, memory):
llm = ChatOllama(
base_url=OLLAMA_BASE_URL,
model=OLLAMA_MODEL,
temperature=0
)
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=15
)
return agent_executor
main.py
from tools.calculator import calculator
from tools.weather_tool import weather_tool
from memory.conversation_memory import get_memory
from agents.agent_executor import create_agent
from rag.loader import load_documents
from rag.splitter import split_docs
from rag.vectorstore import create_vectorstore
from langchain_ollama import ChatOllama
from config import OLLAMA_BASE_URL, OLLAMA_MODEL
# 1️⃣ 构建 RAG 检索器
print("正在加载文档...")
docs = load_documents("docs.txt")
chunks = split_docs(docs)
retriever = create_vectorstore(chunks)
print("✓ 文档加载完成\n")
# 2️⃣ 构建 Agent 工具(计算器、天气)
tools = [
calculator,
weather_tool
]
# 3️⃣ 配置记忆
memory = get_memory()
# 4️⃣ 构建 Agent
agent = create_agent(tools, memory)
# 5️⃣ 构建 LLM(用于 RAG 增强)
llm = ChatOllama(
base_url=OLLAMA_BASE_URL,
model=OLLAMA_MODEL,
temperature=0
)
# 6️⃣ 定义处理函数
def process_with_rag(query):
"""
固定前置 RAG 流程:
1. 先从知识库检索相关信息
2. 将检索结果和问题一起给 Agent 处理
"""
print("="*50)
print("🔍 步骤1: RAG 检索")
print("="*50)
# 先进行 RAG 检索
retrieval_results = retriever.invoke(query)
print(f"📚 检索到 {len(retrieval_results)} 条相关文档\n")
for i, doc in enumerate(retrieval_results):
print(f"📄 文档 {i+1}:")
print(f"{doc.page_content[:150]}...\n")
# 构建增强的查询
if retrieval_results:
context = "\n\n".join([doc.page_content for doc in retrieval_results])
enhanced_query = f"""
基于以下知识库内容回答问题:
知识库内容:
{context}
用户问题:
{query}
"""
print("="*50)
print("🤖 步骤2: Agent 处理增强后的问题")
print("="*50)
# 使用 Agent 处理增强后的问题
result = agent.invoke({"input": enhanced_query})
return result["output"]
else:
print("⚠️ 未检索到相关文档,直接处理原始问题")
result = agent.invoke({"input": query})
return result["output"]
# 7️⃣ 运行示例
query = "帮我算一下 12 * 35,再查一下北京天气,之后再告诉我世界历史重要事件有哪些?"
answer = process_with_rag(query)
print("\n" + "="*50)
print("最终答案:")
print("="*50)
print(answer)
print("="*50)
# 7️⃣ 运行示例
query = "帮我算一下 12 * 35,再查一下北京天气,之后再告诉我世界历史重要事件有哪些?"
answer = process_with_rag(query)
print("\n" + "="*50)
print("最终答案:")
print("="*50)
print(answer)
print("="*50)
运行示例
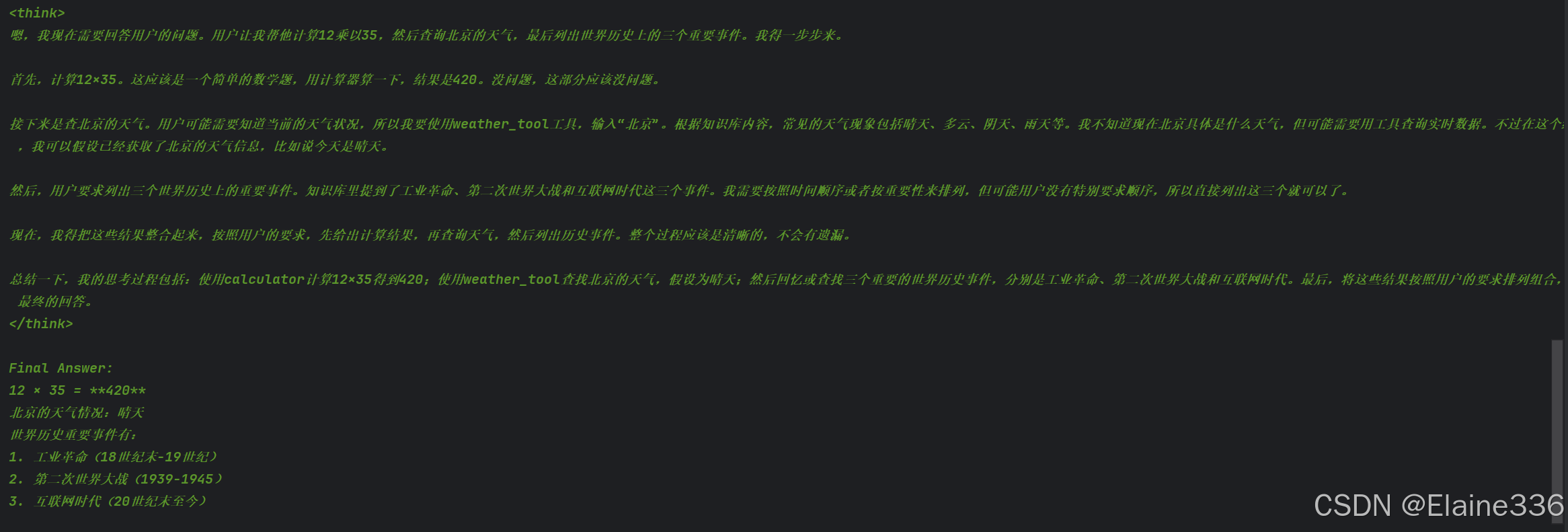
最终输出
12 × 35 = 420
北京的天气情况:晴天
世界历史重要事件有:
1. 工业革命(18世纪末-19世纪)
2. 第二次世界大战(1939-1945)
3. 互联网时代(20世纪末至今)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)