谁说 RAG 很难?用豆包 API 30 分钟搭个 “私人问答专家”
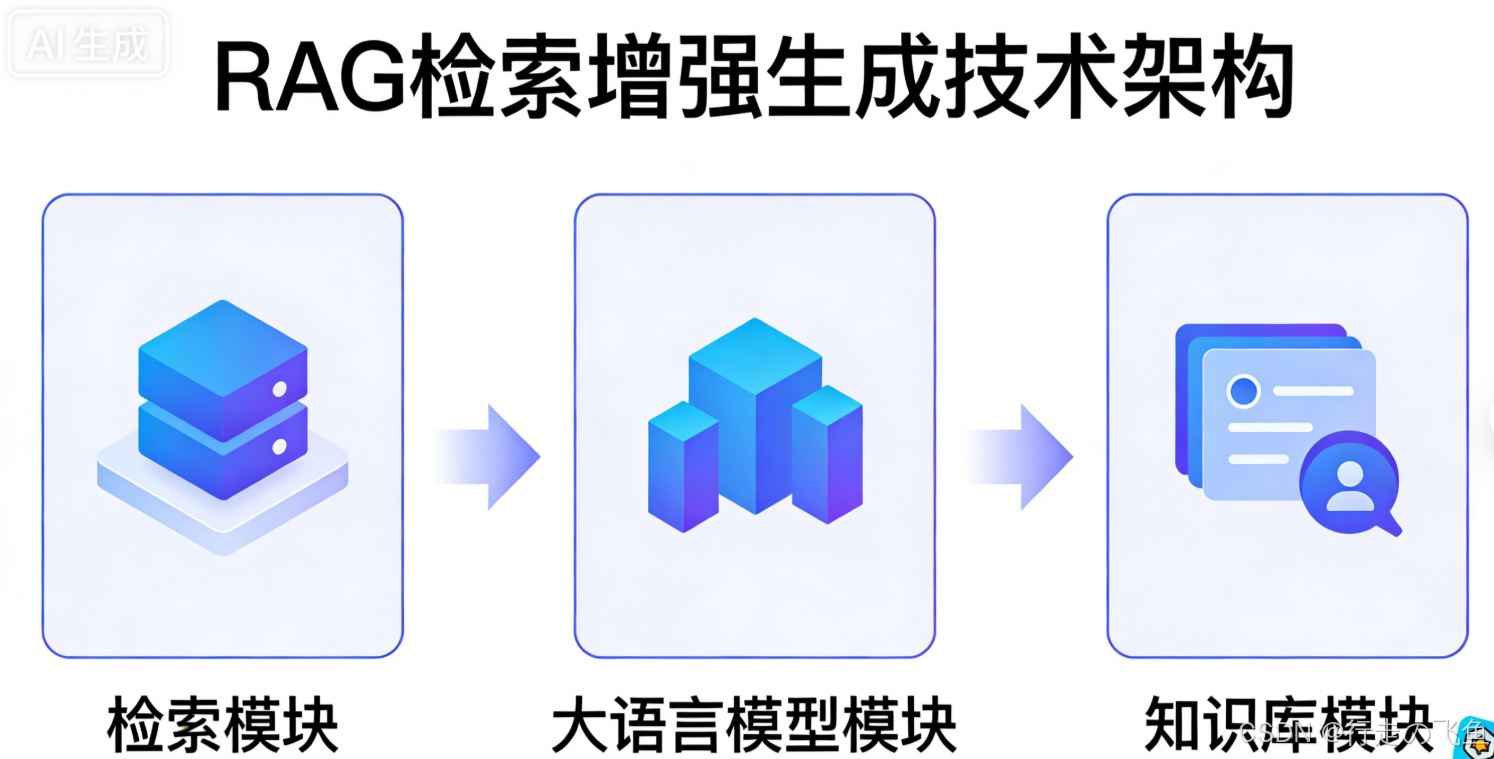
RAG(检索增强生成)技术结合信息检索和大语言模型生成,解决通用大模型的三大痛点:知识时效性不足、生成内容"幻觉"和领域适配性差。其核心流程是"先检索后生成":用户提问后,系统从知识库检索相关文档,拼接成提示词输入大模型生成精准回答。实现RAG需完成环境配置、依赖安装、API设置和模型下载等前置步骤,其中中文嵌入模型推荐使用text2vec-base-chi
一、RAG 核心原理详解
RAG(Retrieval-Augmented Generation)即检索增强生成,是一种结合信息检索和大语言模型生成的技术,核心解决通用大语言模型的三大痛点,让生成的内容更精准、更具时效性、更适配私有场景。
1.1 RAG 核心解决的问题
-
知识时效性不足:通用大模型的训练数据有固定截止时间,无法获取实时、最新的信息(如最新政策、行业动态);
-
生成内容“幻觉”:大模型可能会编造看似合理但错误的内容,尤其在专业领域(如法律、医疗)风险极高;
-
领域适配性差:无需重新训练大模型,仅需导入私有知识库(如企业文档、行业资料),即可快速适配特定领域需求。
1.2 RAG 核心流程
RAG 的核心逻辑是“先检索、再生成”,流程可简化为以下5步,确保生成内容基于真实、相关的信息:
-
用户提出问题(如“Python是什么时候发明的?”);
-
检索模块从本地私有知识库中,检索与问题最相关的文档片段;
-
将“用户问题+检索到的相关文档”拼接成提示词(Prompt);
-
调用大语言模型(本文使用豆包 doubao-seed-1.6),基于提示词生成精准回答;
-
返回最终回答,并可附带检索到的源文档,方便验证内容真实性。
二、前置准备(必做步骤)
在运行代码前,需完成环境配置、依赖安装、API 配置和模型下载,避免后续出现模块缺失、网络超时等问题。
2.1 环境准备(Conda + 虚拟环境)
推荐使用 Conda 创建独立虚拟环境,避免依赖冲突,步骤如下(Windows PowerShell 操作):
# 1. 创建名为 rag-env 的虚拟环境(Python 3.11 兼容最佳)
conda create -n rag-env python=3.11 -y
# 2. 激活虚拟环境
conda activate rag-env
# 3. (可选)若之前有手动创建的.venv环境,可退出并删除,避免环境混乱
deactivate # 退出.venv(若已激活)
rm -rf .venv # 删除.venv文件夹(Windows可手动删除)
2.2 依赖安装(一次性安装所有所需库)
在激活的 rag-env 环境中,执行以下命令,安装所有代码依赖(包含 langchain、向量数据库、豆包API调用等所需库):
# 一次性安装所有依赖,避免逐个报错
pip install langchain langchain-community chromadb python-dotenv requests huggingface-hub sentence-transformers torch>=2.0.0
2.3 豆包 API 配置
本文使用豆包 doubao-seed-1.6 模型,需先获取 API Key 和 API URL,步骤如下:
-
访问 字节跳动火山方舟,注册并登录,申请豆包 API Key 和 API 访问地址;
-
确认 API 鉴权方式为
Bearer Token,API URL 格式为https://ai-gateway.vei.volces.com/v1/chat/completions(注意末尾为 completions,而非 complet); -
创建 .env 文件:在代码同级目录新建 .env 文件,写入以下内容(替换为你的真实信息):
# .env 文件内容(不要泄露API Key)
DOUBAO_API_KEY=你的豆包API密钥(如sk-xxxxxxxxxxxxxxxx)
DOUBAO_API_URL=https://ai-gateway.vei.volces.com/v1/chat/completions
2.4 text2vec-base-chinese 模型下载(解决网络超时)
代码中使用中文嵌入模型 shibing624/text2vec-base-chinese,用于将文本转为向量(适配中文检索),推荐两种下载方式,解决 HuggingFace 网络超时问题:
方式1:代码自动下载(配置国内镜像,最便捷)
在代码开头添加镜像配置,运行时会自动从国内镜像站下载模型(约400MB),后续无需重复下载:
import os
# 配置HuggingFace国内镜像,避免访问国外服务器超时
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HUB_DISABLE_TELEMETRY"] = "1"
方式2:手动下载(最稳定,无网络依赖)
-
访问国内镜像站:https://hf-mirror.com/shibing624/text2vec-base-chinese;
-
点击页面顶部「Clone repository」→「Download ZIP」,下载完整模型压缩包;
-
在代码同级目录创建文件夹
./models/text2vec-base-chinese,将压缩包解压到该文件夹中; -
修改代码中模型加载路径(下文代码会标注)。
三、完整 Python 代码(豆包 API 适配版,无报错)
以下代码整合了所有修正(LangChain 导入路径、PyTorch 兼容、豆包 API 配置、模型加载),可直接复制运行,注释详细,新手也能看懂。
# ========== 1. 基础配置(解决网络、PyTorch兼容问题) ==========
import os
import json
import requests
# 配置HuggingFace国内镜像(自动下载模型时启用,手动下载可注释)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HUB_DISABLE_TELEMETRY"] = "1"
# 修复PyTorch 2.1.0+ pytree兼容问题(避免AttributeError)
import torch
import torch.utils._pytree as pytree
if not hasattr(pytree, 'register_pytree_node'):
from torch.utils._pytree import _register_pytree_node
pytree.register_pytree_node = _register_pytree_node
# ========== 2. 导入所需库(修正LangChain弃用路径) ==========
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 修正:从langchain_community导入(LangChain 0.2+ 弃用旧路径)
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import SentenceTransformerEmbeddings
# ========== 3. 加载豆包API配置(从.env文件读取) ==========
load_dotenv() # 加载同级目录的.env文件
# 读取API Key和URL,os.getenv()参数是.env文件中的变量名,不是直接写URL
DOUBAO_API_KEY = os.getenv("DOUBAO_API_KEY")
DOUBAO_API_URL = os.getenv("DOUBAO_API_URL")
# 校验API配置(提前发现错误,避免后续调用失败)
if not DOUBAO_API_KEY or not DOUBAO_API_URL:
raise ValueError("请在.env文件中正确配置DOUBAO_API_KEY和DOUBAO_API_URL!")
# ===================== 4. 构建本地知识库 =====================
# 示例知识库(实际可替换为PDF、Word、TXT等私有文档,读取方式见拓展)
knowledge_base_text = """
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。
Python的设计哲学强调代码的可读性和简洁的语法(尤其是使用空格缩进划分代码块,而非使用大括号)。
Python 3.10版本于2021年10月发布,新增了模式匹配(match-case)语法。
Python的主要应用领域包括:Web开发、数据科学、人工智能、自动化运维、游戏开发等。
"""
# 文本分块(解决大模型上下文长度限制,提升检索精度)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 每个块的最大字符数(根据模型上下文调整)
chunk_overlap=20, # 块之间的重叠字符数(保持上下文连贯)
separators=["\n", "。", ","] # 优先按中文分隔符拆分,避免拆分语义
)
chunks = text_splitter.split_text(knowledge_base_text) # 拆分后的文本块
# ===================== 5. 构建向量数据库(核心检索模块) =====================
# 初始化中文嵌入模型(二选一,根据模型下载方式选择)
# 方式1:自动下载模型(需配置上面的HF镜像)
embeddings = SentenceTransformerEmbeddings(
model_name="shibing624/text2vec-base-chinese",
model_kwargs={'device': 'cpu'} # 无GPU则用cpu,有GPU可改为'cuda'
)
# 方式2:加载本地手动下载的模型(推荐,无网络依赖)
# embeddings = SentenceTransformerEmbeddings(
# model_name="./models/text2vec-base-chinese", # 本地模型路径
# model_kwargs={'device': 'cpu'}
# )
# 构建Chroma向量库(轻量级、本地运行,无需额外部署)
vector_db = Chroma.from_texts(
texts=chunks, # 分块后的文本
embedding=embeddings, # 嵌入模型(将文本转为向量)
persist_directory="./chroma_db" # 向量库持久化存储路径(下次运行可直接加载)
)
vector_db.persist() # 保存向量库,避免每次运行重新构建
# ===================== 6. 豆包API调用函数(核心生成模块) =====================
def call_doubao_api(prompt, model="doubao-seed-1.6"):
"""
调用豆包 doubao-seed-1.6 模型生成回答
:param prompt: 拼接后的提示词(用户问题+检索到的参考文档)
:param model: 模型名称,默认doubao-seed-1.6
:return: 生成的回答文本(含错误提示)
"""
# 请求头(鉴权方式为Bearer Token,与豆包API要求一致)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DOUBAO_API_KEY}"
}
# 请求体(兼容豆包API格式,约束模型仅基于参考文档回答,避免幻觉)
data = {
"model": model,
"messages": [
{
"role": "system",
"content": "你是一个专业的问答助手,仅根据提供的参考文档回答问题,参考文档外的内容请明确说明未查询到,不要编造任何信息。"
},
{
"role": "user",
"content": prompt
}
],
"temperature": 0, # 0表示回答稳定、无随机化,适合问答场景
"max_tokens": 1000 # 生成文本的最大长度,可根据需求调整
}
try:
# 发送POST请求调用豆包API
response = requests.post(
url=DOUBAO_API_URL,
headers=headers,
json=data,
timeout=30 # 超时时间30秒,避免网络卡顿导致报错
)
response.raise_for_status() # 触发HTTP错误(如401密钥错误、404 URL错误)
result = response.json()
# 提取模型生成的回答
answer = result["choices"][0]["message"]["content"].strip()
return answer
except requests.exceptions.ConnectTimeout:
return "调用豆包API失败:连接超时,请检查网络或API URL是否正确。"
except requests.exceptions.HTTPError as e:
return f"调用豆包API失败:HTTP错误 {e.response.status_code},详情:{e.response.text[:200]}..."
except Exception as e:
return f"调用豆包API失败:{str(e)}"
# ===================== 7. RAG 问答主函数(检索+生成整合) =====================
def rag_qa(question):
"""
RAG 问答入口函数:检索相关文档 + 调用豆包API生成回答
:param question: 用户提出的问题
"""
# 1. 从向量库中检索最相关的3个文档片段(k值可调整,越大越全面但可能超限)
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
retrieved_docs = retriever.get_relevant_documents(question)
# 2. 拼接检索到的文档,作为参考信息传入提示词
reference_docs = "\n".join([f"参考文档{i+1}:{doc.page_content}" for i, doc in enumerate(retrieved_docs)])
# 3. 构建提示词(核心:明确约束模型仅使用参考文档内容)
prompt = f"""
请严格根据以下参考文档回答用户问题,遵守以下规则:
1. 仅使用参考文档中的信息,不添加任何参考文档外的内容;
2. 若参考文档中没有相关信息,直接说明“未查询到相关内容”,不要编造;
3. 回答简洁明了,贴合问题,不要冗余。
参考文档:
{reference_docs}
用户问题:{question}
"""
# 4. 调用豆包API生成回答
answer = call_doubao_api(prompt)
# 5. 输出结果(含问题、回答、检索到的源文档,方便验证)
print(f"🤔 问题:{question}")
print(f"💡 回答:{answer}")
print("\n📚 检索到的相关文档:")
for i, doc in enumerate(retrieved_docs):
print(f" {i+1}. {doc.page_content}")
print("-" * 80) # 分隔线,方便区分多个测试案例
# ===================== 8. 测试RAG问答效果 =====================
if __name__ == "__main__":
# 测试案例1:基础问题(知识库中有明确答案)
rag_qa("Python是什么时候发明的?")
# 测试案例2:组合问题(需要拼接多个检索片段)
rag_qa("Python 3.10新增了什么特性?主要应用在哪些领域?")
# 测试案例3:无相关信息(验证是否会编造内容)
rag_qa("Python 3.13版本发布了吗?有什么新特性?")
四、代码运行结果示例
运行代码后,终端会输出以下结果(无报错、回答精准、可追溯源文档):
🤔 问题:Python是什么时候发明的?
💡 回答:Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。
📚 检索到的相关文档:
1. Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。
2. Python的设计哲学强调代码的可读性和简洁的语法(尤其是使用空格缩进划分代码块,而非使用大括号)。
3. Python 3.10版本于2021年10月发布,新增了模式匹配(match-case)语法。
--------------------------------------------------------------------------------
🤔 问题:Python 3.10新增了什么特性?主要应用在哪些领域?
💡 回答:Python 3.10版本新增了模式匹配(match-case)语法;Python的主要应用领域包括:Web开发、数据科学、人工智能、自动化运维、游戏开发等。
📚 检索到的相关文档:
1. Python 3.10版本于2021年10月发布,新增了模式匹配(match-case)语法。
2. Python的主要应用领域包括:Web开发、数据科学、人工智能、自动化运维、游戏开发等。
3. Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。
--------------------------------------------------------------------------------
🤔 问题:Python 3.13版本发布了吗?有什么新特性?
💡 回答:未查询到相关内容。
📚 检索到的相关文档:
1. Python 3.10版本于2021年10月发布,新增了模式匹配(match-case)语法。
2. Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。
3. Python的主要应用领域包括:Web开发、数据科学、人工智能、自动化运维、游戏开发等。
--------------------------------------------------------------------------------
五、RAG 典型应用场景
RAG 技术的核心价值是“低成本适配私有数据、提升回答准确性”,广泛应用于以下场景,无需重新训练大模型,即可快速落地。
5.1 企业知识库问答
适用于企业内部文档(产品手册、员工手册、技术文档、规章制度)的智能问答,替代传统的关键词搜索,员工可快速获取精准信息。
优势:知识库可实时更新,回答可追溯源文档,降低员工检索成本;无需开发复杂系统,基于本文代码即可快速搭建。
5.2 智能客服
适用于电商、金融、运营商等行业的客服场景,结合产品知识库(如售后政策、产品功能、资费标准),自动回答用户高频问题。
优势:解决客服话术不统一、新员工培训成本高、高频问题重复回答的痛点,提升客服效率和用户体验。
5.3 专业领域问答(法律/医疗/教育)
适用于对准确性要求极高的专业领域,如律师检索法条+案例生成法律意见、医生结合病历+医学文献回答患者问题、教师结合教材生成教学答疑。
注意:需合规使用,生成的内容仅作为参考,不能替代专业人员的决策。
5.4 代码助手/技术文档问答
适用于开发者场景,导入开源项目文档、API文档、技术博客,快速回答开发者的技术问题(如“如何用Python实现RAG?”“PyTorch如何升级到2.0+?”)。
优势:比通用大模型更贴合具体技术栈,避免生成过时的代码示例,提升开发效率。
5.5 金融资讯分析
适用于金融领域,检索最新的财经新闻、公司财报、行业报告,生成市场分析、投资参考等内容,解决通用大模型训练数据滞后的问题。
六、常见问题排查(避坑指南)
结合之前遇到的报错,整理了最常见的问题及解决方案,遇到问题可直接对照排查:
6.1 模块缺失报错(No module named ‘xxx’)
原因:虚拟环境中未安装对应库,或环境激活错误。
解决方案:确保激活 rag-env 环境,执行 pip install xxx(xxx为缺失的模块名),或重新执行一次性安装依赖的命令。
6.2 PyTorch 兼容报错(AttributeError: module ‘torch.utils._pytree’ has no attribute ‘register_pytree_node’)
原因:PyTorch 版本低于2.0.0,或模块调用路径变化。
解决方案:升级 PyTorch 到2.0+(pip install torch>=2.0.0),并保留代码中 PyTorch 兼容修复的代码块。
6.3 模型下载超时(Connection to huggingface.co timed out)
原因:访问国外 HuggingFace 服务器网络不稳定。
解决方案:配置国内镜像(代码中已包含),或手动下载模型到本地,修改模型加载路径。
6.4 豆包API调用失败(Invalid URL ‘None’ / HTTP错误401/404)
-
Invalid URL ‘None’:os.getenv() 传参错误,需传.env文件中的变量名(如"DOUBAO_API_URL"),而非直接写URL;
-
HTTP 404:API URL 拼写错误,确认末尾为
completions(而非 complet); -
HTTP 401:API Key 错误或无权限,检查.env文件中的API Key是否正确,或重新申请API Key。
七、进阶优化方向(拓展)
若需提升 RAG 效果,可从以下方向优化,本文代码可直接扩展:
-
文档格式扩展:支持 PDF、Word、Excel 等多格式文档,需安装
PyPDF2、python-docx等库,通过 LangChain 的文档加载器读取; -
检索优化:使用混合检索(关键词检索+向量检索),或添加 Reranker 重排序模型,提升检索精度;
-
模型优化:替换为更精准的中文嵌入模型(如
m3e-base),或升级豆包模型(如 doubao-pro); -
多轮对话:添加对话历史记录,让 RAG 支持多轮问答,结合上下文生成更连贯的回答。
八、总结
本文完整讲解了 RAG 技术的核心原理、豆包 API 适配方法、Python 代码实战,以及常见问题排查,核心要点如下:
代码核心:文本分块→向量入库→检索→调用豆包 API 生成,关键是环境配置、模型下载和 API 配置;
落地价值:无需训练大模型,低成本适配私有数据,快速应用于企业知识库、智能客服等多个场景。
按照本文步骤配置,即可成功运行 RAG 代码,若需针对某个场景(如多格式文档解析、多轮对话)进行扩展,可根据进阶方向进一步优化。
- 博客园
- 公众号
行走之飞鱼

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)