【专题之MARL】 A Multi-Agent Reinforcement Learning Approach to Prescriptive Process Monitoring
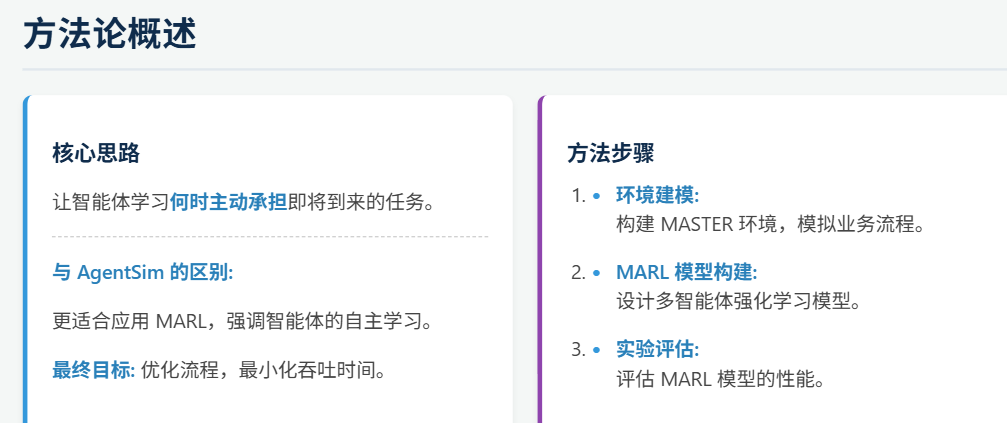
本文提出了一种基于多智能体强化学习(MARL)的处方过程监控方法,重点研究了MAPPO和QMIX算法在业务流程优化(BPO)中的应用。通过构建MASTER模拟平台,将资源建模为自主智能体,支持部分可观测性和事件日志驱动的任务分配。研究探讨了MARL在BPO中的适用性,比较了不同算法在数据集上的性能差异,并提出了一种结合集中训练与分散执行的框架。实验结果表明,该方法能有效优化任务分配策略,提高流程效
文章目录
文章: A Multi-Agent Reinforcement Learning Approach to Prescriptive Process Monitoring
MSc 项目论文 多智能体强化学习方法在处方过程监控中的应用
Markdown将文本转换为 HTML。
Business Process Optimization :BPO 业务流程优化

研究内容: 多智能体系统,使用强化学习方法,研究程序检测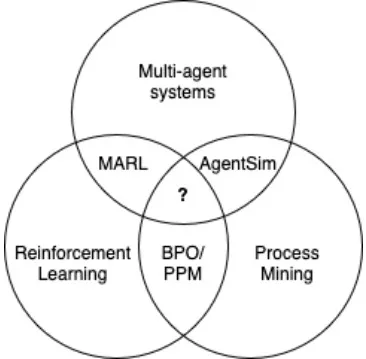
本论文的目标是探索和评估是否以及如何将多智能体强化学习应用于BPO。研究问题是:“如何将多智能体强化学习应用于 BPO / PPM,并且它在不同的数据集上表现如何?”
定义子问题
- 多代理强化学习是否可以应用于 BPO ?
- 哪些MARL算法适用于这种应用?
- 数据集之间的性能差异如何?
一、多代理系统和强化学习
MAS由许多相互作用的代理组成,它们在一个共享的环境中独立学习。MARL 环境可以通过多种不同的方式建模,这些方法在奖励的返回方式和每个代理可观察的信息方面有所不同。
- 多代理MDP,其中有一个中央学习者为所有代理学习动作,奖励在代理之间共享[13]。
- 单代理环境类型是一种POMDP,它将MDP推广到部分可观测环境中[13, 14]。
1.1 MAPPO
🐸 MAPPO
- 全称: Multi-Agent Proximal Policy Optimization
- 基于PPO算法的多智能体扩展 (On-policy)。
- CTDE: Centralized Training with Decentralized Execution。
- 稳定性高,训练效率好。
PPO 是一种通过代理目标函数实现策略稳定性和训练效率的最优策略梯度算法,该目标函数惩罚与当前策略的较大偏差。它使用剪切的目标来限制策略更新,避免极端的策略更新影响其学习能力并导致稳定性问题。
主要思想是最大化剪切后的代理目标:
MAPPO 建立在 PPO 的基础上。它使用集中式训练和分散执行(CTDE)。环境中的每个代理都分配了一个 actor(或策略)网络,该网络通过其观察结果和行动进行训练。
在集中式训练期间,批评网络可以访问全局状态,包括来自所有代理的观察和行动。训练完成后,批评网络被丢弃,实现去中心化执行;每个代理仅根据其本地观察选择自己的行动。
1.2 QMIX
QMIX
- 类型: Value-based, off-policy RL算法。
- 专为完全合作的多智能体场景设计。
- 同样采用 CTDE 框架。
- 通过混合网络聚合局部 Q i Q_i Qi 值,得到全局 Q t o t a l Q_{total} Qtotal 值。
- 支持去中心化执行
QMIX 的核心思想是通过集中式训练与分散式执行(CTDE)框架,实现多智能体系统的均衡稳态 。其核心创新在于通过混合网络将各个智能体的局部 Q 值组合成全局 Q 值,并通过单调性约束确保全局 Q 值随局部 Q 值增加而增加,从而实现策略一致性 。QMIX 在多智能体任务中表现出色,特别是在需要合作的任务中,能够有效协调各个智能体的行为,提高整体系统的性能。
混合网络在实现去中心化执行中起着重要作用。它被设计为一个约束,确保全局Q值是每个代理的局部Q值的单调函数。这种单调性约束通过使用非负权重在混合网络中得到保证,这确保了单个代理的Q值的改进不会降低全局Q值。这一结构允许根据代理的局部Q值贪婪地提取策略,并且仍然优化在训练期间学到的联合策略。重要的是,混合网络在训练期间依赖于完整的全局状态,从而能够捕捉到代理之间的依赖关系并改进信用分配。
QMIX 的价值分解框架特别适合于所有代理共享共同奖励信号并旨在集体提高过程性能的合作任务。通过将全局价值函数分解为每个代理的组件,QMIX 避免了显式建模大量代理的联合行动空间的需求,这在具有许多代理的环境中是计算上不可行的[20]。这使得它对于资源被视为自治代理的中等数量代理设置来说是一个可扩展且实用的算法
二、工作基础
2.1 系统
建立了一个系统,其中包含一组代理和模拟参数。这些被表示为一个概率密度函数(probability density function)(PDF)上的到达时间间隔和一组外在延迟的 PDF 。
- “间断时间PDF”(PDF)用于对新病例到达系统所需的时间进行建模.该系统使用了一个概率密度函数(PDF)来表示病例到达时间的间隔时间。该PDF用于建模新病例进入系统的到达时间。
- “外源性延迟的PDF集合”则用于描述病例在系统中延迟开始处理的情况。 “用于考虑延迟因素的外源性延迟的PDF集合”用于计算病例在被转交给其他资源后不会立即开始的情况
2.2 Agents
每个代理模拟器中的代理有4个属性:
- 类型t指的是特定类型代理可以执行的活动的相似特征
- 计划s,即一个时间间隔的集合,在这些时间间隔内代理可以执行活动。
- 功能c,即代理可以执行的一系列活动的集合,以及一组PDFs来表示每个活动的处理时间。
- 行为b描述了代理在完成一个活动后如何移交案件
2.3 simulation
模拟使用离散时间步长,并且在每个时间步长中,它检查是否有新的病例到达并将其添加到流中。之后,对每个病例进行处理。这是通过检查当前时间步长是否可以处理该病例以及最近的活动是否已完成来完成的。如果可以在当前时间步长处理该病例,则选择一个新活动执行。这通过从活动转移概率中采样来实现。
在选择下一个活动后,负责的代理必须确定。这可以通过两种方式完成:直接分配给具有适当能力的任何代理,或者通过询问其他代理来接管任务,由移交概率决定
三、Method
现有的基于MAS的RL和MARL工作主要在并行进行,MAS提供了现实过程模拟但缺乏自适应学习能力,而基于RL的BPO/PPM方法依赖于具有全面可见性的集中控制。MARL在其他领域展示了作为分散式优化的潜力,但尚未系统地应用于事件日志驱动的企业流程。本论文试图通过结合基于MAS的模拟与MARL,在事件日志数据直接实现分散式、自适应决策,并评估其在多个数据集上的性能。

3.1 Modeling the environment
核心思想
智能体通过与环境交互,学习最优的任务分配和交接策略。
平台定义
MASTER: Multi-Agent System for Task Execution and Resource management
目标: 为MARL在BPO/PPM中的应用提供可复用的模拟平台。
特点:
- 资源建模为自主智能体;
- 部分可观测性;
- 事件日志驱动;
- 支持MARL
环境构成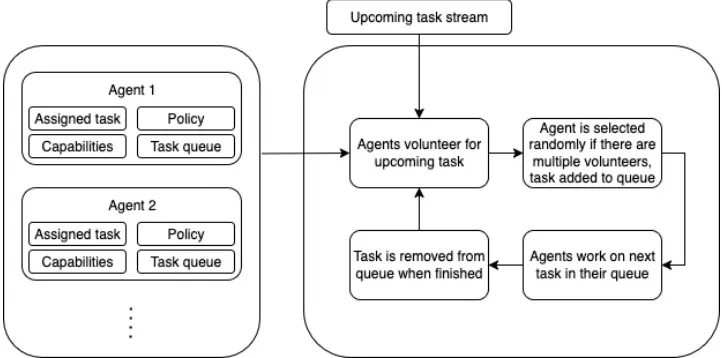
图4:环境模型的概览。在每个时间步,一组代理自愿接受来自任务流的任务。如果没有任何志愿者或有多个志愿者,则随机选择一个代理。代理继续工作直到完成其任务
该环境被分解为三个主要组件。
- 智能体 (Agents): 执行任务的主体。
- 任务流 (Task Stream): 待处理的任务序列。
- 任务处理循环: 控制任务分配和完成的流程。
在这个特定的模型实现中,代理可以访问以下信息:
- 下一个任务是什么
- 他们在此任务上的先前表现。这是他们的历史中位数、平均值和吞吐量时间的标准差。
- 他们在队列中的任务数量。
- 他们当前任务剩余的时间。
- 如果代理能够执行下一个任务。
总结
案例与任务
- 案例 (Case): 由一系列任务组成的完整流程实例。
- 任务 (Task): 案例中的单个操作单元。
- 时间戳: 分配、开始、完成时间。
- 环境:由一组案例C组成,其中每个案例 c ∈ C c \in C c∈C是一个任务序列 c T cT cT ,当完成时,它完成一个完整的案例。
任务和案例可以有一个状态:待定(尚未分配或未开始),开放(已分配给代理但未开始),进行中(代理正在处理此任务),已完成
最后,每个任务都可以分配给一个代理,该代理将负责处理这个任务。一旦分配了代理,它就必须处理这个任务。如果某个代理已经有一个或多个任务被分配到他们身上,并且该代理自愿承担了一个或多个任务,则这些任务会添加到任务队列的末尾。
3.2 Agents
在AgentSim论文中定义的行为 a b a_b ab 被每个代理学习的策略所取代,该策略取决于观察空间并用于确定接下来时间步的动作。
基本属性
- 能力 (Capabilities): 固定可执行活动集合及对应性能 PDF。– a c a_c ac
- 策略 (Policy): 学习得到的策略,决定下一步动作。
- 已分配任务 (Assigned Task): 当前正在处理的任务。– a t a_t at
- 任务队列 (Task Queue): 已报名但尚未开始的任务。– a q a_q aq
在我的环境中,每个代理 a ∈ m a t h c a l A a\in mathcal{A} a∈mathcalA 将有一个能力集,表示为 a c a_c ac 。这是一个固定的活动集合,描述了代理可以执行的活动以及直到当前时间步长为止该代理对这些活动的表现。
代理可以有分配给他们的任务,表示为 a t a_t at 。如果它被定义了,这就是他们目前正在处理的任务。它们还有一队任务 a q a_q aq,存储他们自愿承担但尚未开始的任务。
与 AgentSim 的区别
- 不包含类型 (Type) 和日程 (Schedule) 属性。
- 假设每个智能体一次只能处理一个任务。
- 假设每个案例同一时间只有一个活跃任务和一个活跃智能体。
3.3 Action Space

3.4 Reward Function
除了第一个时间步,每个时间步,任务都会在环境中完成。因此,将根据该已完成任务的持续时间 t t t 实施适当的奖励。它被计算为 d = t e n d − t a s s i g n e d d =t_{end}-t_{assigned} d=tend−tassigned 。在这个环境实现中,遵循一个向下线性斜坡,仅使用这个持续时间作为输入。持续时间 d d d 将落在范围 KaTeX parse error: Undefined control sequence: \leg at position 3: d \̲l̲e̲g̲ ̲0 内,并且等于任务的吞吐量时间。奖励函数定义为: f ( d ) = − d f(d) =-d f(d)=−d
奖励特性与目标
线性惩罚: 持续时间越长,惩罚越大。
目标导向: 鼓励快速完成任务,提升整体流程效率。
3.4 Building the experiment environment
作者们在GitHub上公开了AgentSim[10]论文的代码,用于MAS发现和模拟。
该代码主要用于优化,可以重复使用. 创建一个新的代码库,该代码库利用了[10]已经完成的部分工作,但这次是作为PettingZoo环境构建的[22]。PettingZoo是一个广泛使用的Python包,在MARL研究中非常有用。

Task quede
由于选择实施并行环境,两个代理可以同时自愿接受同一任务。为了避免冲突,代理有一个已分配给他们的任务队列。代理将按照他们被分配到队列的时间顺序(先进先出)处理他们的待办任务。然而,在当前环境中,FIFO原则被使用。
仅靠队列无法解决可能出现的冲突,因此当出现冲突时,将从自愿承担该任务的可用代理中随机选择指定的代理。如果没有任何代理提出申请,则将从所有可用代理中进行随机选择。一个可用代理是指在训练数据中至少完成过一次任务的代理。
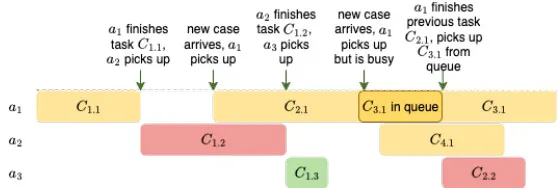
图5:在MASTER环境中的一个简化的运行示例。时间步长中,智能体 a 1 a_1 a1、 a 2 a_2 a2 或 a 3 a_3 a3 选择动作的步骤用箭头标记。这些也是自上次时间步长以来完成的任务的奖励返回的时间步长。案例表示为 C c a s e I D . t a s k I D C_{case}ID.taskID CcaseID.taskID
。
在环境设置好后,示例运行图如图5所示。为了同时考虑现实世界的时间和离散时间步长,在处理环境中,模拟会跟踪现实世界的时戳。在每个离散时间步长中,它检查最早发生的事件(要么是新案例的开始,要么是某个代理完成任务)并立即跳到该点。对于第一个任务,仅从原始数据集中获取开始时间。对于所有其他任务,分配的时间将等于之前完成的任务的完成时间。
- 第一个任务的开始时间:
对于第一个任务,其开始时间是从原始数据集中直接获取的,而不是通过计算或依赖其他任务的完成时间来确定的。这意味着第一个任务的开始时间是预先定义好的,而不是通过其他任务的完成时间推导出来的。- 其他任务的开始时间:
对于所有其他任务(即第二个及以后的任务),它们的开始时间将等于之前完成的任务的完成时间。这意味着任务的开始时间是依赖于前一个任务的完成时间,从而形成一种顺序执行或依赖关系。
3.5 Data and preprocessing

3.6 Training and testing

**第一阶段的训练使用MAPPO(**多智能体近端策略优化)算法进行。正如前面讨论的,这是MARL社区中一个众所周知的算法,并且已经在多个合作智能体环境中被证明是有效的。因此,对于初始实验来说,这是一个安全的选择,特别是为了验证MARL是否是一种可行的方法来解决这个问题。第一阶段的训练将在CVS药店数据集上进行,之后将使用贷款申请和BPI12W数据集.
在验证使用MAPPO方法具有优势后,将使用QMIX算法评估学习策略[20]。这将在所有三个数据集上进行评估。
整个训练是离线完成的。大约有80%的数据在训练期间被使用,而另外20%则留作测试。
3.6.1 Training block
为了简化训练并充分利用有限的计算资源,训练循环被分成多个块。每个块包括一次新的模拟运行,覆盖整个数据集,并使用上一迭代中的策略.
代理的选择、状态和奖励在每个时间步中都被保存在一个缓冲区中。然后,这个缓冲区被用来通过训练神经网络来更新策略,进行一定数量的迭代周期。将这些结果存储在一个缓冲区而不是每次更新策略时都重新运行一个模拟,这可以显著加快处理速度,尤其是在有CUDA或MPS设备可用的情况下。最后,执行多次训练评估。在这些评估期间,使用新策略选择动作来进行训练数据,并利用这些运行来了解代理在给定迭代周期后如何表现。这些训练块会重复执行几次。
3.6.2 Network structure and hyperparameters
MAPPO 和 QMIX 模型的训练使用了基于初步实验选定的一组固定超参数。这些值在模型复杂度、学习稳定性和泛化能力之间提供了良好的平衡,适用于所使用的各个数据集。尽管没有进行正式的超参数调优(如网格搜索或贝叶斯优化),但多次实验运行证实了所选配置始终能产生稳定的性能表现。表 2 列出了所选的值.
表2:用于训练代理的超参数。
尽管通过广泛的超参数调优或架构搜索可能会提高性能,但本论文的目标不是为了在特定数据集上实现最大性能,而是评估将MARL应用于业务流程环境的可行性和通用性。一致的超参数在整个数据集中使用也避免了对特定过程特征的过度拟合,并支持公平比较。
3.7 Performance analysis

四、结果
4.1 MAPPO 在 CVS 数据上的表现
- 实验目的: 验证MAPPO算法在新构建的环境中的学习与优化能力。
- 训练过程: 在CVS数据集上进行20轮训练,观察累积奖励的变化。
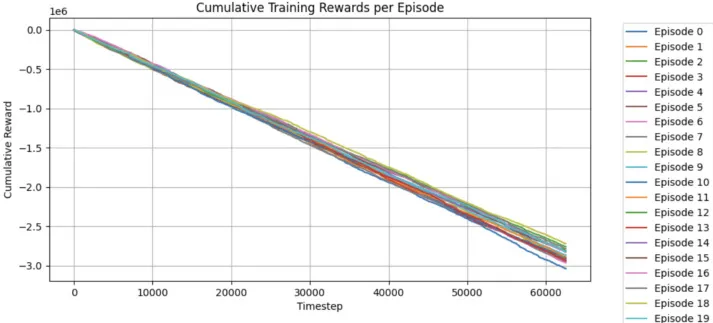
图7:显示MAPPO训练运行中每个完整回合的累积奖励的图表,该训练包括20个完整的回合。
图7解读:(奖励收敛性)
- 每条曲线代表一个训练回合(episode)。
- 奖励值随时间步增加而下降(负值变小),表明任务吞吐时间在被有效优化。
- 早期阶段下降较快,后期趋于平缓,尤其在第15回合后,改进速度明显减缓,出现停滞现象。
结论: 训练过程中奖励持续改善,直接反映了模型学习到有效策略,实现了流程优化。
初步观察:
- 随着训练进行,每轮的累积奖励呈上升趋势。
- 表明智能体正在学习并改进任务处理策略。
- 关键指标: 奖励值为负吞吐时间,奖励值降低(负值变小)意味着吞吐时间缩短,即优化效果
为了更有效地调查优化,使用测试分割的最佳模型计算的模拟事件日志上的指标,并将其与基线进行比较,结果如表3、表4和表5所示.
核心指标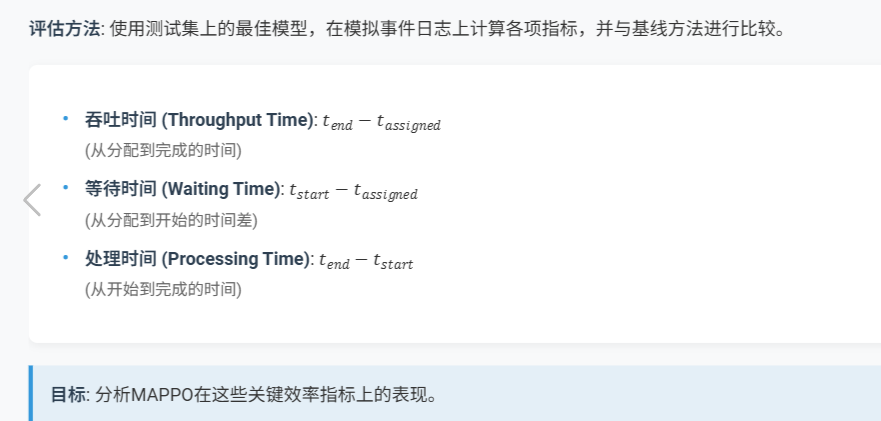
吞吐时间分析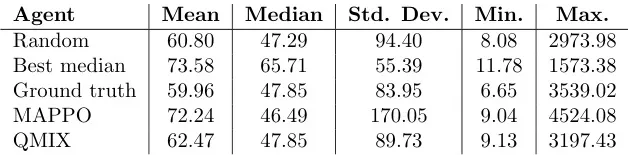
表3:CVS药店数据集上在10次评估运行中,通过时间( t e n d − t a s s i g n e d t_{end}-t_{assigned} tend−tassigned )分布统计,以分钟为单位.
表3数据概览: 展示了不同策略在10次评估运行中吞吐时间的统计分布。
MAPPO表现:
- 中位数吞吐时间略有提升 (46.49 vs Ground Truth 47.85)。
- 平均吞吐时间较高 (72.24 vs Ground Truth 59.96)。
- 标准差最大 (170.05),表明性能波动性大。
关键发现: MAPPO的改进主要源于处理时间的优化,而等待时间仅略逊于真实情况。
意外发现: MAPPO找到的处理时间甚至优于某些“最佳中位数”基线,暗示“最佳中位数”可能并非最优解。
等待时间分析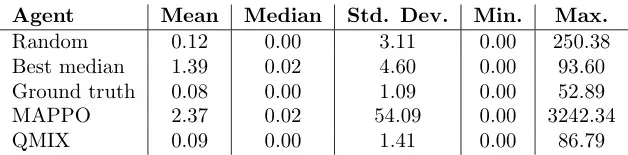
表4:CVS药店数据集中总等待时间 ( t s t a r t − t a s s i g n e d t_{start}-t_{assigned} tstart−tassigned) 的分布统计,以分钟为单位,共10次评估运行.
表4数据概览: 展示了不同策略在10次评估运行中总等待时间的统计分布。
MAPPO表现:
- 最大等待时间极高 (3242.34分钟),表明存在极端长等待的情况。
- 中位数等待时间 (0.02分钟) 极低,几乎可以忽略不计。
其他策略:
- QMIX在均值、标准差和最大值上表现最稳定。
- Ground truth和Random的等待时间也存在较大波动。
结论: MAPPO虽然平均等待时间表现尚可,但存在严重的性能不稳定问题,极端情况下的用户体验很差。
处理时间分析
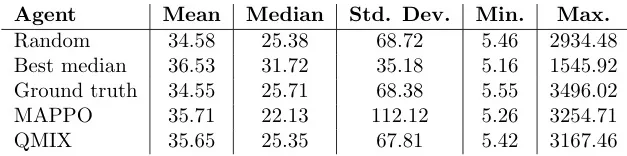
表5:CVS药店数据集中总处理时间 ( t e n d − t s t a r t t_{end}-t_{start} tend−tstart) 的分布统计,以分钟为单位,共10次评估运行。
表5数据概览: 展示了不同策略在10次评估运行中总处理时间的统计分布。
MAPPO表现:
- 中位数处理时间 (46.49分钟) 优于 Ground Truth (47.85分钟)。
- 平均处理时间 (72.24分钟) 低于 Best median (65.71分钟)。
其他策略:
- QMIX的平均处理时间最长 (35.65分钟)。
- Random的处理时间波动最大。’
结论: MAPPO在处理时间这一项指标上表现突出,是其整体性能提升的关键因素
Kolmogorov-Smirnov正态性检验
使用Kolmogorov-Smirnov正态性检验对每个基线-度量对的分布进行统计分析,结果令人惊讶地表明,没有一个分布是正态分布(所有p值均小于0.001)。
Mann-WhitneyU检验
表6显示了MAPPO与基线的Mann-WhitneyU检验结果,其中比较了基线之间的差异
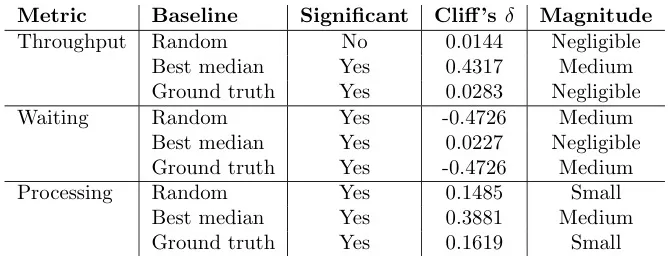
表6:Mann-Whitney U检验结果的总结,比较MAPPO与CVS数据集上的每个基线。正 δ \delta δ值表示MAPPO表现更好;负值表示性能更差。
4.2 MAPPO on various datasets
跨数据集验证
MAPPO在贷款申请数据集上的表现
数据特征: 任务持续时间长,任务量可能大。
表7-9 数据概览:
- 等待时间 (表8): 所有策略的等待时间均显著高于CVS数据集 (均值 > 1600分钟)。
- 原因推测: 任务到达率高或任务处理时间长,导致智能体难以及时响应。
MAPPO表现:
- 吞吐时间、等待时间、处理时间均显著劣于所有基线 (Random, Best median, Ground truth)。
结论: 在此数据集上,MAPPO的表现令人失望,未能超越简单基线。MAPPO在处理时间上有所优化,但整体吞吐时间仍不佳,且在等待时间上表现糟糕。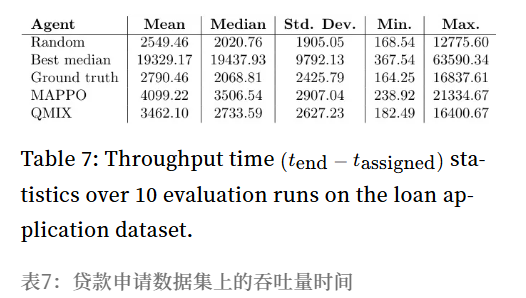
吞吐时间 (表7): MAPPO的中位数 (3506.54) 优于 Best median 和 Ground truth,但劣于 Random
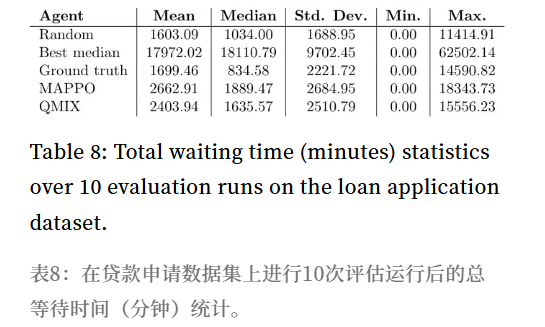

处理时间 (表9): MAPPO的中位数 (≈1617.07) 优于 Best median 和 Ground truth,但劣于 Random。
Mann-Whitney U检验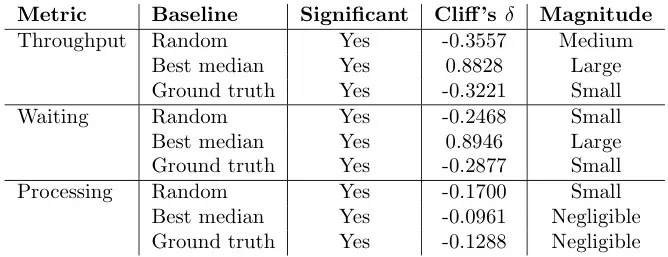
表10:Mann-Whitney U检验结果的总结,比较了MAPPO与每个基线在贷款申请数据集上的表现。正 δ \delta δ值表示MAPPO的表现更好;负 d e l t a delta delta值表示性能更差.
表10 数据概览: Mann-Whitney U检验结果。
- 吞吐时间: 显著劣于所有基线。
- 等待时间: 显著劣于 Random 和 Ground truth,但显著优于 Best median。
- 处理时间: 显著劣于所有基线。
- 综合结论: 在贷款申请数据集上,MAPPO表现不佳。只有在处理时间上相对Best median有显著改善,但在吞吐时间和等待时间上均不如基线。这可能是因为任务持续时间过长,单智能体处理模式成为瓶颈。
4.3 MAPPO在BPI12W数据集上的表现
数据特征: 智能体数量最多,但唯一任务类型最少。
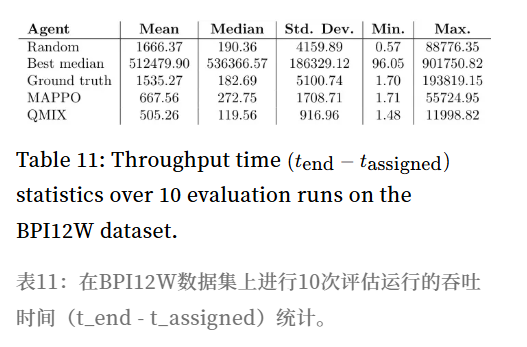
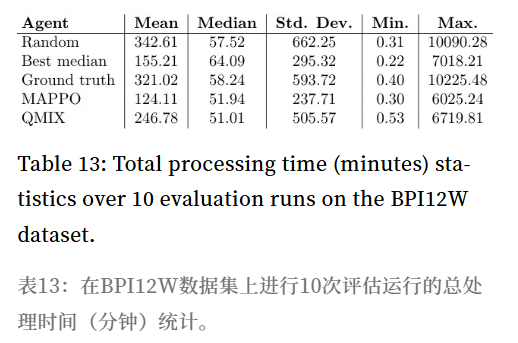
表11-13 数据概览:
- 等待时间 (表12): MAPPO的中位数等待时间 (117.60) 显著高于 Random 和 Ground truth,但低于 Best median。
- 处理时间 (表13): MAPPO的中位数处理时间 (272.75) 优于 Best median 和 Ground truth。
- 吞吐时间 (表11): MAPPO的中位数吞吐时间 (≈390.35) 优于 Best median,但劣于 Random。
- 结论: MAPPO在处理时间上表现良好,但因等待时间过长,导致吞吐时间反而不如基线。标准差较低,说明性能更稳定

Mann-Whitney U检验结果
表14 数据概览: Mann-Whitney U检验结果。
- 吞吐时间: MAPPO显著优于 Best median,但显著劣于 Ground truth。
- 等待时间: MAPPO显著优于 Best median,但显著劣于 Ground truth。
- 处理时间: MAPPO显著优于所有基线。
- 综合结论: 在BPI12W数据集上,MAPPO在处理时间上实现了微小但显著的改进,牺牲了等待时间换取了这一点效率。在吞吐时间上,虽然优于最差的Best median,但不如Ground truth。

4.4 QMIX在各种数据集上的表现
QMIX回顾: 另一种多智能体强化学习算法,与MAPPO并列测试。
跨数据集表现:
- CVS: 表现与多数基线相似,略逊于MAPPO的中位数吞吐时间,但分布右偏(平均值更高)。
- Loan Application: 表现优于MAPPO,但仍不及基线。
- BPI12W: 表现最佳,优于所有基线和MAPPO。
核心发现: QMIX在不同数据集上的表现波动较大,似乎对任务类型数量敏感(BPI12W任务类型少,QMIX表现好)。
4.5 QMIX在CVS数据集上的表现
表15 数据概览: Mann-Whitney U检验结果 (QMIX vs 基线 & MAPPO)。
- 吞吐时间: QMIX显著优于 Best median,与 MAPPO 差异显著但微小 (QMIX略差)。
- 等待时间: QMIX显著优于 Best median 和 MAPPO。
- 处理时间: QMIX显著优于 Best median,与 MAPPO 差异显著但微小 (QMIX略差)。
- 结论: 在CVS数据集上,QMIX在等待时间和处理时间上优于Best median和MAPPO,但在吞吐时间上与MAPPO接近,且分布可能不如MAPPO理想。
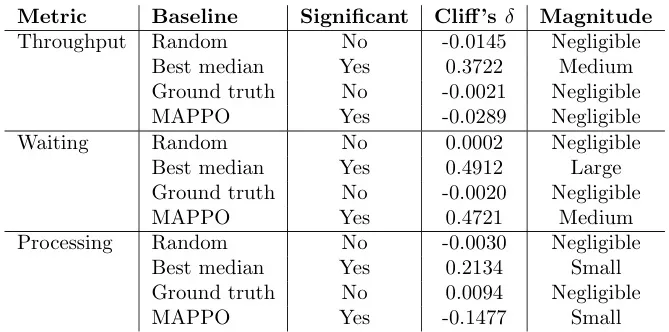
表15:比较QMIX与CVS数据集上的每个基线和MAPPO的Mann-Whitney U检验结果。正 δ \delta δ值表示QMIX表现更好;负 δ \delta δ值表示性能更差
4.6 QMIX在贷款申请数据集上的表现
表16 数据概览: Mann-Whitney U检验结果 (QMIX vs 基线 & MAPPO)。
- 吞吐时间: QMIX显著优于所有基线,但与MAPPO差异微小 (QMIX略好)。
- 等待时间: QMIX显著优于所有基线,但与MAPPO差异微小 (QMIX略好)。
- 处理时间: QMIX显著优于 Best median 和 Ground truth,显著优于 MAPPO。
- 结论: 在贷款申请数据集上,QMIX在吞吐时间和等待时间上均优于所有基线,但在处理时间上略逊于MAPPO。整体表现优于MAPPO,但仍不理想。
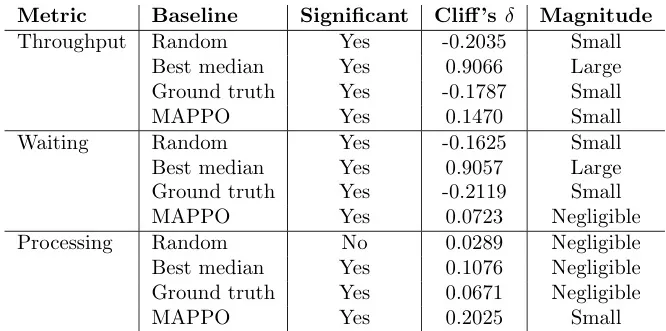
表16:比较QMIX与每个基线和MAPPO在贷款申请数据集上的U检验结果。正 δ \delta δ值表示QMIX表现更好;负 δ \delta δ值表示性能更差。
4.7 QMIX在BPI12W数据集上的表现
表17 数据概览: Mann-Whitney U检验结果 (QMIX vs 基线 & MAPPO)。
- 吞吐时间: QMIX显著优于所有基线和MAPPO。
- 等待时间: QMIX显著优于所有基线和MAPPO。
- 处理时间: QMIX与所有基线和MAPPO差异均不显著。
- 结论: 在BPI12W数据集上,QMIX表现最佳,显著优于所有基线和MAPPO,尤其是在吞吐时间和等待时间上。这与其在该数据集上任务类型少的特点相符。
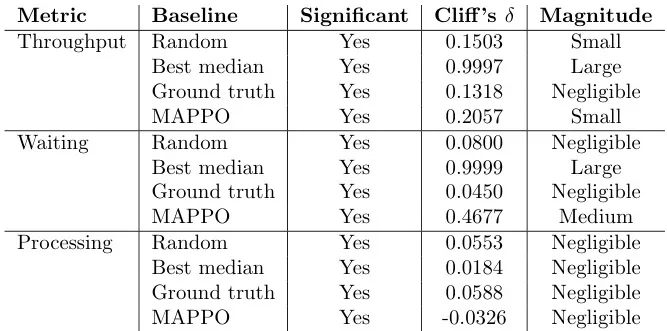
表17:比较QMIX与每个基线和MAPPO在BPI12W数据集上的结果。正的 δ \delta δ值表示QMIX表现更好;负的值表示性能更差。
五、结论与展望




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)