自动驾驶感知:融合摄像头与雷达数据的多模态目标识别
摄像头与雷达的融合,不仅仅是硬件的堆砌,更是两种认知世界的哲学的交汇——视觉追求的是“理解”,雷达追求的是“存在”。从早期的简单后融合,到如今基于Transformer的深度特征对齐,再到即将到来的大模型赋能,这项技术正以惊人的速度进化。作为自动驾驶领域的观察者或实践者,我们不仅要关注模型的精度指标,更要理解背后的物理本质与工程约束。未来的自动驾驶要想真正突破剩余的0.1%安全瓶颈,让机器在暴雨、
引言:单靠一只眼睛,能否看清世界?
想象一下,你正坐在一辆高速行驶的自动驾驶汽车里,车辆需要在一秒钟内做出数十个决策:前方突然窜出的行人、隔壁车道试图加塞的车辆、远处因大雾若隐若现的障碍物……如果这辆车只有“眼睛”(摄像头),它可能会被刺眼的阳光晃得“眼花缭乱”;如果它只有“耳朵”(雷达),虽然能听到“有东西”,却永远分不清那到底是个纸箱还是小孩。
在自动驾驶的感知世界里,没有任何一种传感器是完美的。摄像头拥有丰富的纹理和色彩信息,却在黑暗、强光或雨雪天气面前显得脆弱;雷达虽然能穿透风雨直接测量距离和速度,但其点云稀疏,缺乏识别物体“是什么”的能力 。
为了让机器拥有超越人类的“超感官知觉”,多模态融合技术应运而生。本文将深入探讨自动驾驶领域中,摄像头与雷达这对“黄金搭档”是如何通过深度融合,实现对复杂环境的精准3D目标识别。我们将从融合的必要性、技术路线、前沿算法,聊到行业落地与未来展望。
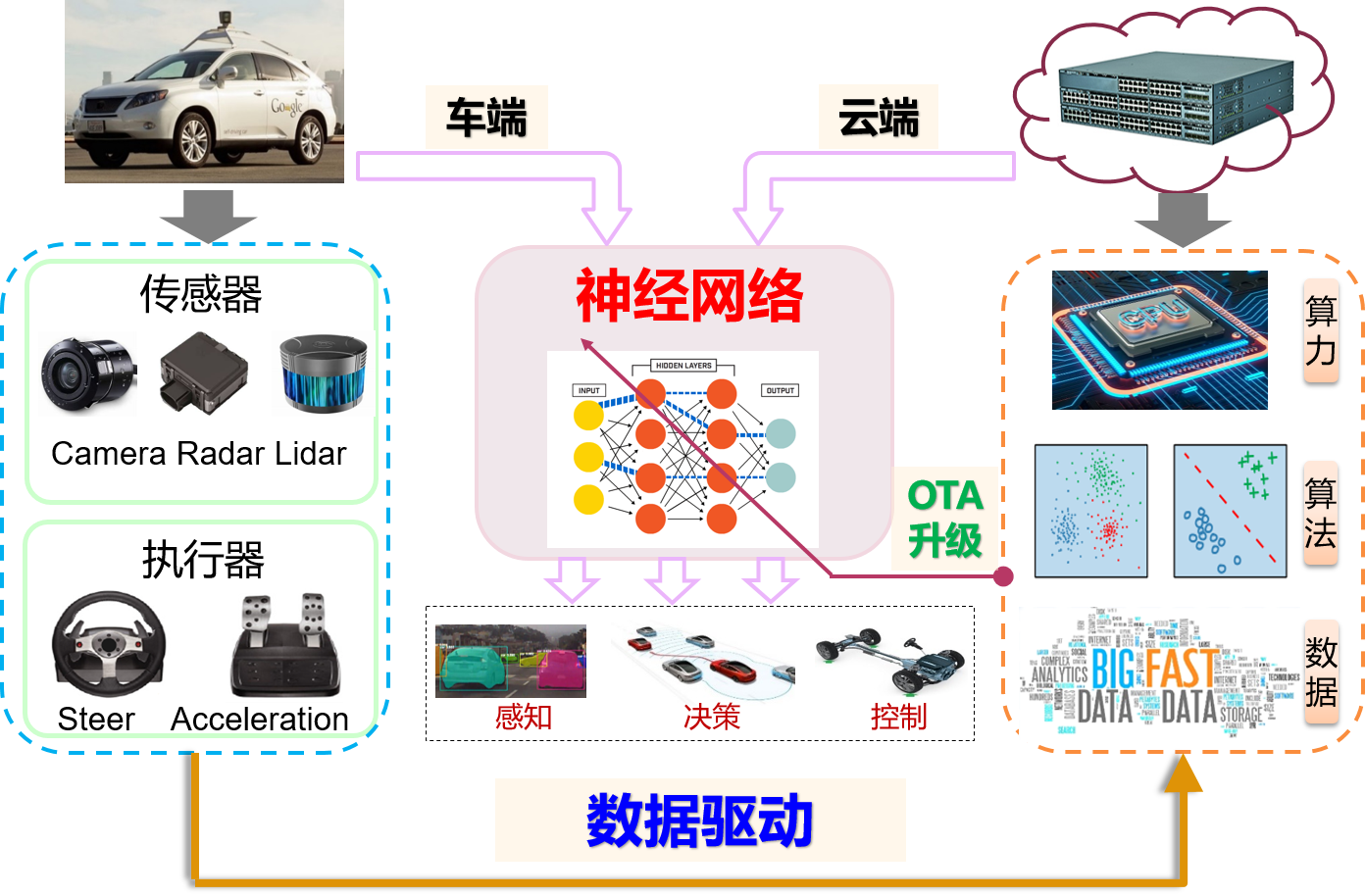
一、传感器的“能力边界”:为什么必须融合?
在讨论融合之前,我们必须先理解被融合的个体。自动驾驶的感知层通常依赖三大核心传感器:摄像头、雷达和激光雷达。本文将聚焦于成本最低廉、普及度最高的组合——摄像头与毫米波雷达。
1. 摄像头:语义丰富的“画家”
摄像头的工作方式类似于人眼,通过CMOS感光元件捕捉可见光。它的优势在于高角分辨率,能够提供丰富的纹理、颜色和轮廓信息。这使得摄像头成为唯一能够识别交通标志、信号灯颜色以及区分行人与非机动车的传感器 。
致命短板:摄像头是被动传感器,极度依赖环境光照。在夜间隧道出口、强烈逆光或雨雾天气下,其性能会急剧下降。此外,单目摄像头天生缺乏深度感知,即便通过深度学习估算距离,其精度也无法满足高速行驶下的紧急制动需求 。
2. 毫米波雷达:稳健可靠的“速算师”
毫米波雷达通过发射和接收电磁波来探测目标。它的看家本领是直接测量径向速度(多普勒效应) 和距离,且具有极强的鲁棒性,不受光照、雾霾、烟尘的影响 。
致命短板:雷达点云极其稀疏,且缺乏语义信息。传统雷达甚至无法测量高度,导致无法区分路面上的井盖与头顶的立交桥牌。雷达信号还会产生多径反射和多义散射,在静止物体检测上容易出现虚警 。
3. 对比激光雷达
激光雷达虽能生成稠密的3D点云,精度极高,但成本是毫米波雷达的3倍以上,且在雨雪天气中由于激光散射,性能衰减严重 。因此,“摄像头+毫米波雷达” 的组合成为了兼顾性能、成本与全天候作战能力的最优解,也是目前L2+级量产车的主流选择 。
二、融合的“三重境界”:早期、中期与后期
有了传感器数据,如何将它们结合在一起?根据数据融合发生的阶段,学术界和工业界通常将其分为三个层级 。
1. 后期融合(Late Fusion):各说各话的“辩论赛”
原理:摄像头和雷达分别独立运行各自的检测算法,各自输出“我认为这里有个车”的结果。然后,融合模块将这两份结果通过交并比(IoU) 或卡尔曼滤波进行关联和合并。
优点:系统架构简单,各传感器解耦,计算量小。如果摄像头和雷达来自不同供应商,这种方案集成最快 。
缺点:信息损失最大。当摄像头因逆光没检测到车,而雷达检测到了,融合层仅凭雷达的数据可能因为缺乏分类置信度而被过滤掉。这种“各自为政”的方式浪费了数据互补的潜力。
2. 中期融合(Middle Fusion / Feature Level):取长补短的“参谋部”
原理:在特征层进行融合。摄像头的主干网络提取出图像特征图,雷达的点云经过编码器转换为特征向量。两者在特征空间进行对齐和拼接,再由后续网络进行检测。
优点:这是目前学术界研究的热点,平衡了灵活性与性能。网络可以学习到两种模态特征之间的相关性 。
典型代表:许多基于BEV(Bird‘s-Eye-View,鸟瞰图)的算法将图像特征通过视角变换投影到BEV空间,与雷达特征在同一坐标系下融合 。
3. 早期融合(Early Fusion / Data Level):血脉交融的“联姻”
原理:在数据的最原始层级进行融合。最典型的方式是将雷达点云通过坐标变换投影到图像平面上,然后在RGB图像上叠加雷达的深度或速度信息,形成“RGB+雷达”的多通道数据,送入同一个网络进行推理 。
优点:理论上信息最完整,网络可以充分利用原始数据的细微相关性,性能上限最高。例如麦格纳的实验表明,早期融合能显著提升夜间行人检测的可靠性 。
挑战:对数据时空同步要求极高,且需要巨大的带宽将原始数据汇集到中央计算单元 。
三、学术前沿:从RICCARDO到BEV,算法如何演进?
理论讲完,我们来看看学术界最新的“黑科技”。近几年,摄像头-雷达融合领域涌现出了大量创新工作。
1. RICCARDO:让雷达学会“预测”反射
雷达点云的分布非常奇特:它不仅打在物体边缘,还会穿透物体打到内部结构,甚至车底地面反射形成复杂图案 。
创新点:传统的融合方法直接用黑盒网络学习这种分布。而RICCARDO 提出了一种显式的方法:首先利用单目摄像头的检测结果,预测出该物体的“雷达反射分布模型”(即雷达应该打在哪儿);然后,用这个预测的分布作为卷积核,去匹配实际的雷达点。这种方法相当于先给雷达画了个重点,再让网络去验证,从而极大提升了融合检测的精度,在nuScenes数据集上达到了SOTA水平 。
2. 基于BEV与Transformer的统一表达
如果你关注2024-2025年的自动驾驶架构,一定听过BEV+Transformer。
核心思想:将来自摄像头的多视角图像和雷达点云,都转换到统一的BEV栅格空间下。
技术细节:摄像头图像通过LSS(Lift-Splat-Shoot) 或Transformer的注意力机制,预测出深度分布,将2D特征“提升”到3D空间。雷达点云则直接提供精确的深度先验。两者在BEV空间融合后,利用Transformer强大的全局感受野捕捉物体之间的关系 。
优势:这种范式天然支持时序融合,将多帧的BEV特征对齐后叠加,可以显著提升对遮挡目标的识别能力 。
3. RODNet的进化:解决硬件异构性
雷达硬件千差万别,不同车型、不同供应商的雷达信号分布差异巨大,导致训练好的模型换辆车就“失灵”。
最新解决方案:2026年发表于MDPI Sensors的研究提出了一种改进的RODNet框架。它不再仅仅依赖网络结构创新,而是引入了信号级预处理:
-
几何校准:通过改进的PnP算法精确对齐雷达到相机。
-
Z-score标准化:对雷达的chirp信号进行统计标准化,消除不同硬件带来的信号幅度差异。
-
轻量化时序适配器(GTA) :通过时序注意力机制稳定检测结果。
这套组合拳让模型在跨设备测试中的平均精度(AP)提升了22.88个百分点,证明了“数据清洗”有时比“模型魔改”更有效 。
四、实战落地:4D毫米波雷达引领的新潮流
如果说学术圈在追求精度的极限,那么工业界则在追求性价比与稳定性的平衡。
1. 4D毫米波雷达的崛起
传统的3D雷达只能输出距离、速度和水平方位角,缺乏高度信息,导致“立交桥下把轿车当飞机”的笑话。4D成像雷达的出现改变了这一切。
4D雷达增加了高度维度的测量能力,能输出稠密得多的点云(甚至可达每帧数千点),分辨率接近低线束激光雷达 。
工程价值:有了高度信息,融合算法可以更好地判断目标是否在可行驶区域内。配合摄像头语义信息,能精确识别路肩、减速带以及悬空的障碍物。
2. 企业级方案解读:黑芝麻智能的实践
以黑芝麻智能提出的“视觉与4D毫米波雷达前融合算法”为例,看看量产方案是如何做的 :
-
雷达特征提取:针对4D雷达点云稀疏的特点,采用PointPillars将无序点云划分为垂直的“柱体”(Pillars),提取局部特征。
-
RCS编码:利用雷达散射截面积(RCS)粗略衡量目标尺寸。传统方法将RCS扔进网络末端,而新方案将RCS作为先验知识,在BEV编码时把一个雷达点的特征“弥散”到多个像素,解决了稀疏性带来的检测损失。
-
Deformable Attention:引入可变性注意力机制,动态调整感受野,强化关键目标特征,抑制周围建筑物的杂波。
-
结果:相比纯视觉,融合方案在100米范围内的mAP(平均精度均值)提升了5%,速度预测误差(mAVE)降低了33.85%。
五、核心挑战:时空同步与域适应
尽管融合技术突飞猛进,但在实际部署中,工程师们依然面临几座难以逾越的大山。
1. 时空同步的“魔鬼细节”
-
时间对齐:摄像头通常是30fps,雷达是20fps。雷达点云是一段时间内的累积,而图像是某一时刻的抓拍。简单粗暴的“最近邻”匹配会导致运动畸变。高精度方案需要利用INS(惯性导航系统)进行插值和外推。
-
空间对齐:相机与雷达的安装位置不同,需要联合标定。哪怕是行驶中微小的震动导致外参偏移,都会导致投影误差——本来应该在车身上的雷达点,飘到了路面上 。
2. 域适应与泛化性
深度学习模型非常“挑剔”。源域(训练集,比如 sunny 的美国加州)和目标域(实际路况,比如下雨的中国重庆)的数据分布差异巨大。
雷达信号受周围电磁环境、温度甚至车身覆盖件的影响。正如 的研究指出,跨设备部署是雷达感知的头号难题。未来的解决方案可能依赖更强大的域自适应算法,如基于扩散模型或大语言模型(LLM)的特征对齐 。
3. 极端天气与“长尾问题”
融合的目的是处理极端情况。但在某些场景下,所有传感器同时失效。例如,在积雪覆盖道路时,车道线消失(摄像头失效),积雪吸收雷达波(雷达失效),路面变成水膜导致激光雷达误反射。这就需要融合算法具备深度认知,结合高精地图和V2X(车路协同)来弥补感知的空白 。
六、未来展望:大模型与生成式AI重塑感知
站在2026年年中回望,AI的浪潮已经席卷了自动驾驶感知的每一个角落。未来摄像头与雷达的融合将走向何方?
1. 端到端与神经符号推理
传统的“检测-跟踪-预测-规划”流水线正在被端到端模型挑战。多模态融合的特征可以直接输入到 Planner(规划器)中。特斯拉的“光子计数”理念虽然偏重视觉,但业界普遍认为,真正安全的端到端必须融合雷达的物理测量值,以消除视觉的幻觉 。
2. VLM与LLM赋能
视觉-语言模型(VLM) 正在进入自动驾驶领域 。想象一下,当雷达检测到一个形态诡异的点云簇,摄像头也看不太清时,模型可以像人类一样思考:“虽然看不清那是什么,但根据上下文,那是施工区域常见的锥桶,所以减速慢行。”
大语言模型(LLM) 的常识推理能力可以作为融合感知的“最后一道防线”,处理那些从未在训练数据中出现过的“长尾场景”。
3. 生成式AI用于数据增强
获取完美的、时空同步的真实雷达-相机数据成本极高。未来,扩散模型可能会被用来生成高保真的雷达数据,或者进行雷达数据的超分辨率重建,甚至直接将仿真数据“风格迁移”成真实数据,解决数据匮乏的难题 。
结语
摄像头与雷达的融合,不仅仅是硬件的堆砌,更是两种认知世界的哲学的交汇——视觉追求的是“理解”,雷达追求的是“存在”。
从早期的简单后融合,到如今基于Transformer的深度特征对齐,再到即将到来的大模型赋能,这项技术正以惊人的速度进化。作为自动驾驶领域的观察者或实践者,我们不仅要关注模型的精度指标,更要理解背后的物理本质与工程约束。
未来的自动驾驶要想真正突破剩余的0.1%安全瓶颈,让机器在暴雨、大雪、黑夜中依然游刃有余,答案就藏在这“多模态融合”的二重奏里——让每种传感器发挥其长,再合奏出一曲完美和谐的交响乐。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)