第十章-竞赛题目选讲
举个例子,我们的枚举上限是 114514,目前枚举到的是 1045,此时虽然 5 这一位相等,但是不论以后怎么枚举,我们枚举的数字一定小于 114514。一但一个区间的g相等了,随着右端点右移,这个区间的g会一直相同,所以将相同的g压缩了。给一个长度为 n(n≤105)的数列 a(ai≤1012),找到一个连续子序列使得子序列的公约数与长度的乘积最大,求这个最大值。在满足 ∣x∣≤a,∣y∣≤b
例题:10-22 统计问题 The Counting Problem
给定两个整数 a 和 b,求 a 和 b 之间的所有数字中 0 ~ 9 出现次数。
例如,a = 1024,b = 1032,则 a 和 b 之间共有 9 个数如下:
1024 1025 1026 1027 1028 1029 1030 1031 1032
其中 0 出现 10 次,1 出现 10 次,2 出现 7 次,3 出现 3 次等等……
解:
首先确定总体思路:一次性统计出十个数字的出现频率较难,因此我们分开处理每一个数字的出现次数。
- 第一部分 搜索
采取搜索的方式,pos 代表搜到了哪一位,numi 代表这一次选定的数字(参数 k)出现的次数,lim 表示当前位是否有限制(1 表示有限制),pre 表示当前位是否为前导零(1 表示是)。
int dfs(int pos,int numi,bool lim,bool pre,int k){
if(pos == 1) return numi;
int up = lim ? num[pos-1]:9;
int ans = 0;
for(int i = 0;i <= up;i ++){
ans += dfs(pos-1,numi + (k == 0?(!pre && i == k):(i == k)),(lim && i == up),(pre && i == 0),k);
}
return ans;
}
up 的含义是当前枚举位的最高限制,是为了让枚举的数字不超过给定数字。
numi + (k == 0?(!pre && i == k):(i == k)) 的意思是如果我们在统计 0 的数量,那么如果是前导零计数器就不能增加;否则只要这一位与统计的数字相等,计数器自增。
(lim && i == up) 是指如果之前有限制,并且这一位还与上界相等,那么限制依然存在。为什么用与运算而不用或运算?举个例子,我们的枚举上限是 114514,目前枚举到的是 1045,此时虽然 5 这一位相等,但是不论以后怎么枚举,我们枚举的数字一定小于 114514。
(pre && i == 0) 是指如果这一位是前导零,并且枚举的还是 0,那么前导零状态就要延续。
至此本题的重点——搜索部分就写完了。
但是纯暴力搜索复杂度是不优的,因此我们需要采用记忆化搜索。
- 第二部分 记忆化搜索
我们直接选取 dfs 函数的参数当作状态,设 f[pos][numi][lim][pre] 表示艘至第 pos 位,当前数字出现了 numi 次,限制和前导零状态分别为 lim 和 pre 时的答案,初始化为 -1。在搜索函数中添加判断语句,如果当前状态下 f 不等于 −1,则直接返回该值。每次搜索完毕后,将答案赋给 f 数组。
#include <bits/stdc++.h>
using namespace std;
#define int long long
int f[15][15][2][2],num[15],n,l,r;
int dfs(int pos,int numi,bool lim,bool pre,int k){
if(f[pos][numi][lim][pre] != -1) return f[pos][numi][lim][pre];
if(pos == 1) return numi;
int up = lim ? num[pos-1]:9;
int ans = 0;
for(int i = 0;i <= up;i ++){
ans += dfs(pos-1,numi + (k == 0?(!pre && i == k):(i == k)),(lim && i == up),(pre && i == 0),k);
}
return f[pos][numi][lim][pre] = ans;
}
int work(int x,int k){
memset(f,-1,sizeof(f));
int u = 0;
while(x){
num[++u] = x % 10;
x /= 10;
}
n = u;
return dfs(n+1,0,1,1,k);
}例题:10-24 ASCII面积 ASCII Area
多组数据
每组数据给定长和宽n,m。
接下来n行每行m个字符,均为'.','/',''。
其中'/',''表示该格一半被覆盖,'.'表示该格被完全覆盖或完全未被覆盖。
每组数据输出一行一个整数,表示被覆盖的面积。
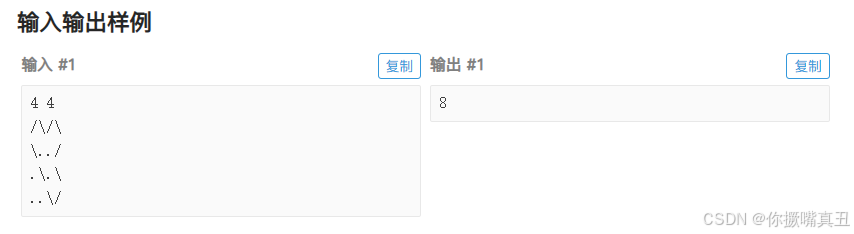
每一个格子要么全白,要么全黑,要么半白半黑,只要能准确的判断出来即可。
字符“\”和“/”都是半白半黑,问题在于“.”到底是全白还是全黑。
解决方法是从上到下从左到右处理,沿途统计“/”和“\”。当这两个字符出现偶数次时说明接下来的格子在多边形外;奇数次则说明接下来的格子在多边形内。
可以用一个变量来判断是否在多边形外。
#include <iostream>
using namespace std;
int main()
{
int n, m;
while (cin >> n >> m){
int ans = 0;
for (int i = 1; i <= n; i++){
bool flag = false;
for (int j = 1; j <= m; j++){
char c;
cin >> c;
if (c == '/' || c == '\\'){
ans++;
flag = !flag;
}
if (c == '.' && flag) ans += 2;
}
}
cout << ans / 2 << endl;
}
return 0;
}
例题:10-27 树林里的树 Trees in a Wood.
-
在满足 ∣x∣≤a,∣y∣≤b 的网格中,除了原点之外的整点各种一棵树,树的半径忽略不计,但是可以互相遮挡,求从原点能看到多少颗树。
-
输出的为能看到的树除以所有树的比,输出 7 位小数即可。
-
a<2000,b≤2e6。
这道题比较难,主要用到不同的数学公式,所以有不同做法。
例题:10-29 魔法GOD Magical GCD
给一个长度为 n(n≤105)的数列 a(ai≤1012),找到一个连续子序列使得子序列的公约数与长度的乘积最大,求这个最大值。共 T 组数据。
解:
本题可以利用gcd的性质来优化n方暴力
随机生存序列,观察序列的gcd后缀,发现:
1.gcd的值从后向前单调递减。
2.大量gcd相等。
考虑枚举右端点,随着左端点离右端点越来越远,gcd可以用以前的gcd更新。
我们可以用以前的区间gcd计算现在的区间gcd。g [ j ] 表示从j到目前右端点i的区间gcd。g[ j ] = gcd( a[ i ] , g[ j ] ). g[ i ]的初值等于a[ i ] .
一但一个区间的g相等了,随着右端点右移,这个区间的g会一直相同,所以将相同的g压缩了。nxt[ i ]表示下一个与g[ i ]不同的g的位置。pre[ i ]表示上一个与g[ i ]不同的g。每次移动左端点时将其移到它的nxt,复杂度就降下来了。
同时提供另一个做法 st表+二分找左端点 不过没有本做法优秀。
其实还有其他数学做法,可以自行查找。
推荐一道类似的题 :洛谷3794 签到题IV。
#include<bits/stdc++.h>
using namespace std;
typedef long long dnt;
const int N=100010;
dnt g[N],a[N],nxt[N],pre[N];
int T,n;
dnt gcd(dnt a,dnt b){
dnt t;while(b){t=a;a=b;b=t%b;}
return a;
}
dnt max(dnt a,dnt b){return a>b?a:b;}
int main(){
scanf("%d",&T);
while(T--){
memset(pre,0,sizeof(pre));
memset(nxt,0,sizeof(nxt));
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%lld",&a[i]);
pre[i]=i-1;
nxt[i]=i+1;
g[i]=a[i];
}
pre[n+1]=n;
nxt[0]=1;
dnt ans=0;
for(int i=1;i<=n;i++){
for(int j=nxt[0];j<=i;j=nxt[j]){
g[j]=gcd(g[j],a[i]);
ans=max(ans,g[j]*(i-pre[j]));
if(g[j]==g[pre[j]]){
nxt[pre[pre[j]]]=j;
pre[j]=pre[pre[j]];
}
}
}
printf("%lld\n",ans);
}
return 0;
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)