SCASRec: A Self-Correcting and Auto-Stopping Model forGenerative Route List Recommendation
注:其中H为用户在历史相同场景下的用户历史序列,对于当前请求不同候选路线是相同的,用来和当前候选路线提供相关性信息(历史选择高架路线)作为当前路线唯一的特征标准。EOR 的奖励系数 α 是一个控制推荐过程停止倾向的超参数:α 值越高,推荐停止得越早,最终推荐的路径数量越少。的全局目标:(被选择路线排名越靠前越好,生成集合的sim_max均值越大越好,整体路线生成集合越少越好)通常而言,Dfail
目录
背景:
现代导航中的路径推荐系统普遍采用多阶段范式,包括召回、粗排、精排与重排,存在一些不足:
- 训练目标与实际效用之间脱节
- 多路线生成依赖人工冗余规则,与指标存在错位
- 相互独立的排序阶段之间难以建立反馈
预备知识:
在路径推荐任务中,系统接收用户的起终点查询,并返回有序的候选路径列表。形式化地说,经过召回(路径规划)与粗排阶段后,我们得到一组共 N 条候选路径,记为:
排序模型的目标是生成一个有序列表,
使其尽可能贴合用户的真实偏好。用户的实际行驶轨迹 u 作为隐式反馈,用于评估
的质量。
一个理想的路径推荐系统应同时满足三个目标:
- 将用户偏好(真实)的路径尽可能排在前列;
- 保证输出列表的整体高质量;
- 在找到偏好路径后,避免展示冗余路径。
为此,我们将优化目标定义为:最大化排序性能与列表覆盖率的综合指标,同时最小化冗余曝光。
指标:
Coverage Rate (CR):路线之间的Jaccard相似度
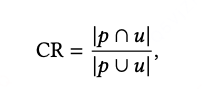
其中具有最高CR的路线被称作,其CR值为
Mean Reciprocal Rank (MRR):被选择路线的排名越靠前,该指标越好
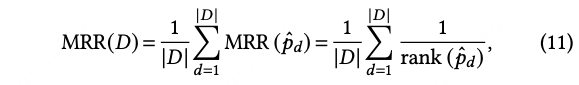
List Coverage Rate (LCR):评估生成集合的整体质量,所有订单生成集合的sim_max的均值。
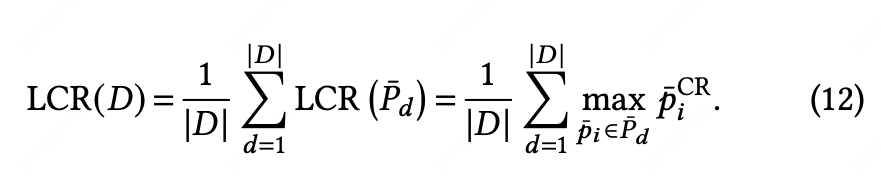
Redundant Item Exposure:比实走路线排名差的路线集合大小(生成路线集合越少越好)
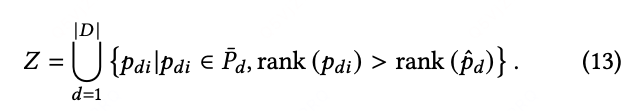
方法:
显式平衡覆盖率与冗余曝光的全局目标:(被选择路线排名越靠前越好,生成集合的sim_max均值越大越好,整体路线生成集合越少越好)
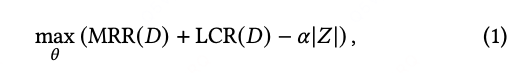
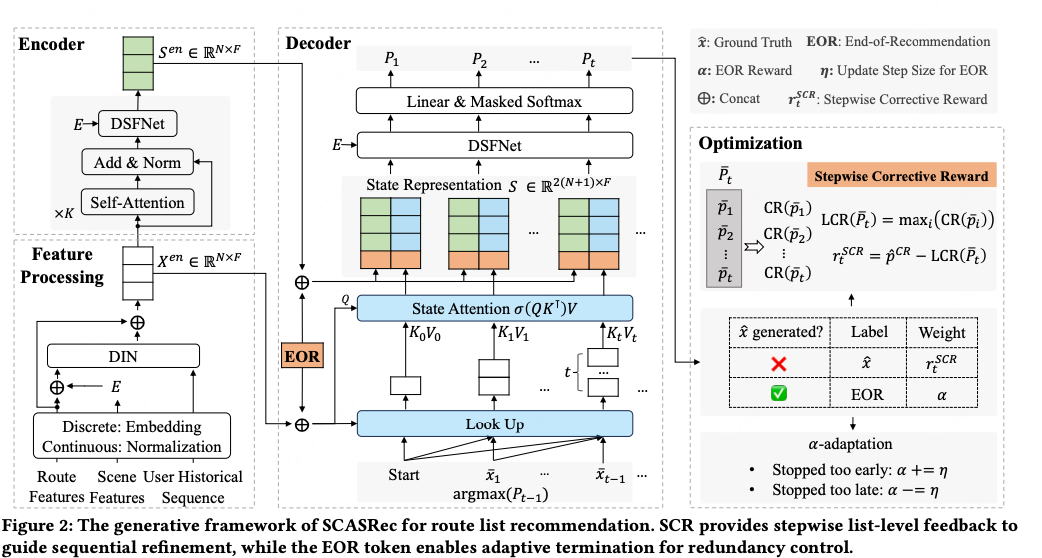
为了让序列解码与这一全局目标对齐,SCASRec 引入了两个核心机制:
- 逐步校正奖励(SCR):在每一步提供列表感知的反馈,引导上下文感知的优化;
- 推荐结束符(EOR):作为可学习的停止条件,无需人工规则即可实现冗余消除。
Stepwise Corrective Reward
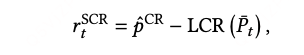
它表示当前列表覆盖率与最优覆盖率之间的剩余差距(一定是正值吧?)。 越大,说明通过进一步校正可获得的收益越高,也意味着该样本在训练中需要被更多地关注。
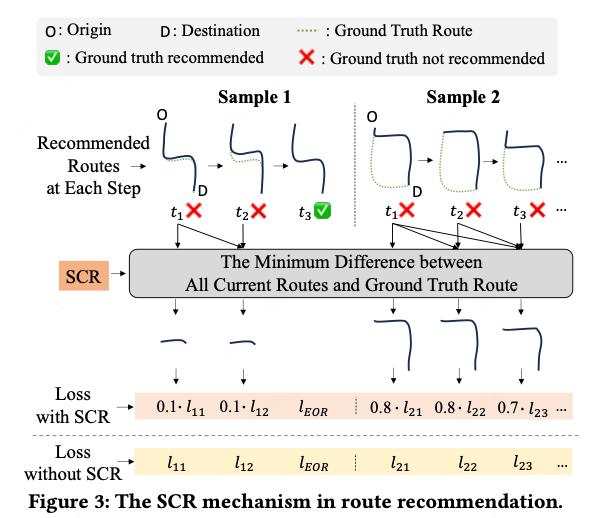
如图 3 所示,SCR 通过计算当前列表与真实路径之间的最小的覆盖率差距,动态反映每一步的提升空间。这种聚焦式信号能够将训练损失引导至收益潜力最大的步骤,使 SCASRec 快速收敛到高质量、低冗余、且与用户意图高度匹配的推荐列表。
样本1与label差距小,loss小;样本2差距大, loss大,受到关注更多;即生成路线越接近真实label,loss越小;
这个是生成过程?
一旦真实路径被纳入列表,会达到
,使得
降至 0,表示继续增加路径对覆盖率或排序质量的提升可以忽略不计。
此外,与已推荐路径相似的候选路径对 几乎没有贡献,只会带来微小的
下降;而能显著拓展轨迹覆盖率的多样化方案,则会带来更大的奖励下降。这隐式地鼓励模型选择有实质差异的路径,在无需显式约束或后处理过滤的情况下提升推荐多样性。
推荐结束机制(EOR)
EOR(End-of-Recommendation) 标记:
由于在 之后推荐的任何路径都会增大冗余长度 ∣Z∣,因此最优策略应在
步立即停止生成。
据此,我们为 EOR 设计如下奖励:
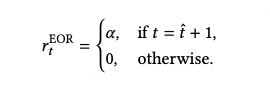
该奖励让 EOR 直接对应公式中的冗余惩罚项 −α∣Z∣,使模型不仅能学习 “推荐什么”,还能学习 “何时停止”。
统一训练目标
在每一步解码 t,模型输出一个概率分布 ,覆盖 N 条候选路径与 EOR 标记。
定义label:
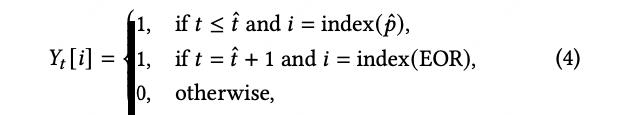
其中 index(⋅) 将路径映射到候选集中的编号。
为融入列表级反馈,使用组合奖励对每一步的监督损失进行加权:
![]()
最终训练目标为加权交叉熵损失:
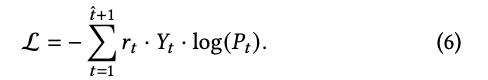
特征处理模块:
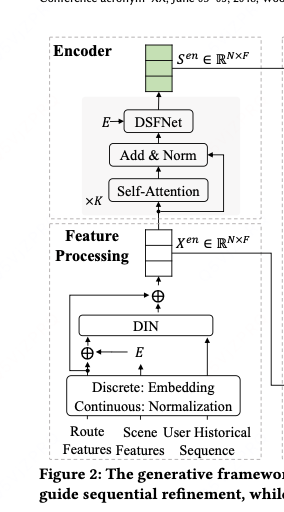
特征包括:路径特征、场景特征和用户历史序列特征

为用户历史偏好标准:
= DIN(concat(
, E ), H)
= concat(
,
)
注:其中H为用户在历史相同场景下的用户历史序列,对于当前请求不同候选路线是相同的,用来和当前候选路线提供相关性信息(历史选择高架路线)作为当前路线唯一的特征标准
C.2 编码器:
引入近期提出的多场景框架 DSFNet 作为encoder,输入X_en,输出 作为全局上下文表征;
C.3 解码器
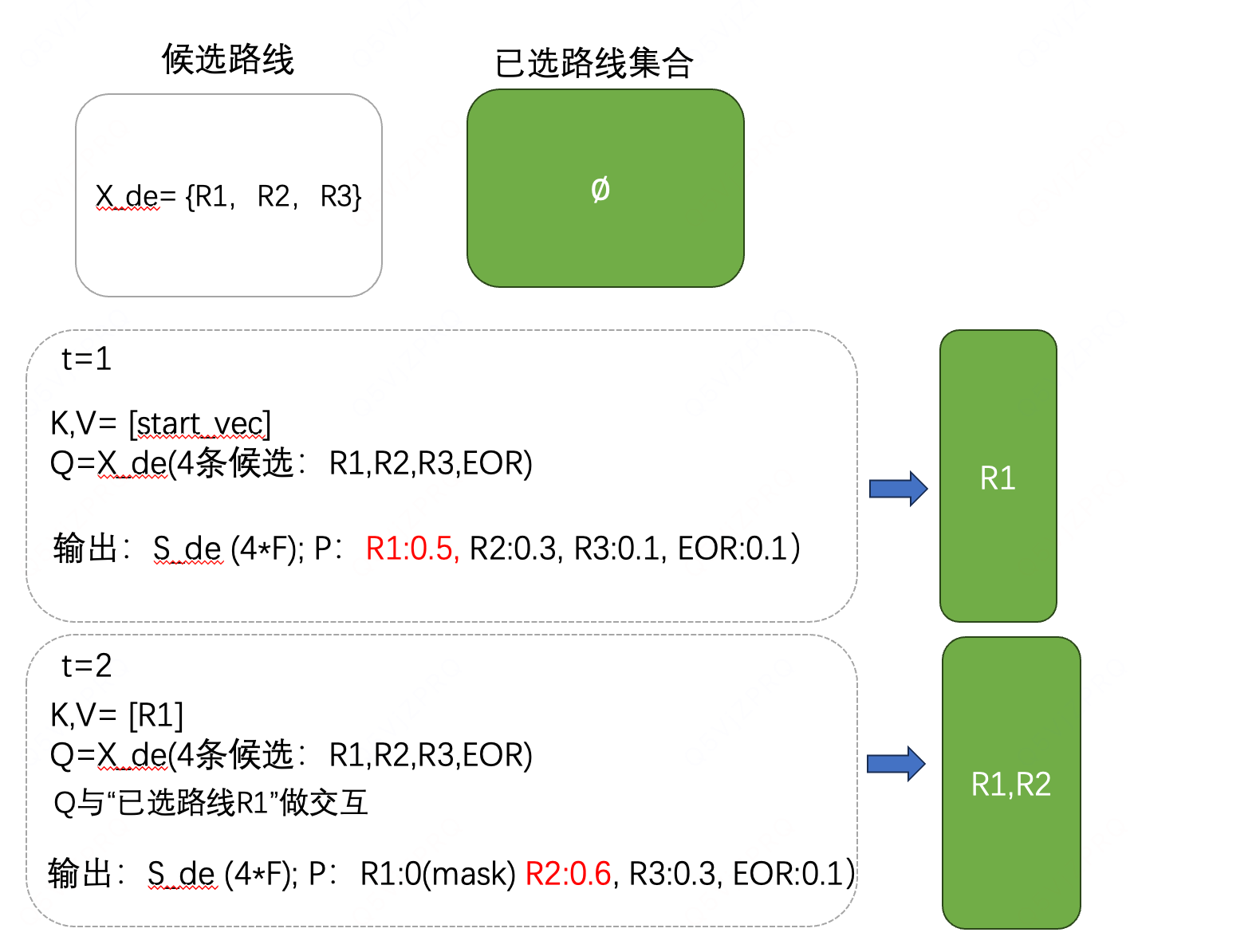
候选路线集合:
已推荐路线集合:
候选路线作为Q,已选路线表征 作为键和值,得到上下文表征
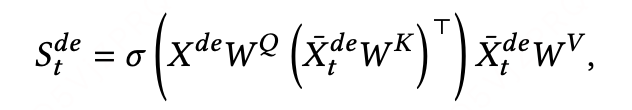
将encoder输出与当前步的状态表征拼接,通过DSFNet和softmax计算得到概率:

解码过程:
- 每一步都看已经选了什么,在已经选择的结合上面做选择;
- 每一步都可以选择终止,靠EOR(可学习向量);
- 其中sigmoid不做过一化,而是保留列表原始长度信息;
C.4 Noise-aware 𝛼-adaptation:
EOR 的奖励系数 α 是一个控制推荐过程停止倾向的超参数:α 值越高,推荐停止得越早,最终推荐的路径数量越少。
假设在给定 α 的情况下,数据集 D 被划分为两个子集:
- Dsuc:真实路径
被成功推荐的样本集;
- Dfail:真实路径
通常而言,Dfail 中的样本更难学习,且更可能包含噪声。定义 Dfail 的占比为:
![]() 其中 ∣Dfail∣、∣D∣ 分别表示 Dfail 和数据集 D 的样本总量;数据集的整体估计噪声比例记为 β。
其中 ∣Dfail∣、∣D∣ 分别表示 Dfail 和数据集 D 的样本总量;数据集的整体估计噪声比例记为 β。
噪声感知 α 自适应是一种启发式算法,核心是在训练过程中动态调整 α,使 e(未成功推荐样本占比)逐步逼近 β(估计噪声比例)。具体而言,每训练完一个批次(batch)后,我们计算当前的 e 值,并根据以下公式更新:
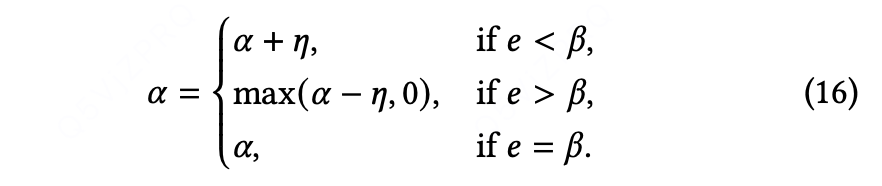
未成功推荐的样本太多,则减小reward,增加推荐步骤;
核心作用:解决 α 人工设定难、易受噪声干扰的问题,让模型的停止时机(EOR 选择)自动适配数据质量;
整体算法流程:

实验:
采用能够同时反映排序质量与用户满意度的列表级指标:
-
HR@K:衡量用户实际行驶路径是否出现在前K个推荐结果中。
-
LCR@K:量化推荐路径列表与真实行驶轨迹之间的覆盖率。
-
MRR:评估最优路径的排序位置。当不同模型的MRR相同时,更高的LCR代表更优的推荐性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)