AI 也能写爬虫?基于 Bright Data + Warp CLI 的网页抓取实战
爬虫的成功与否,往往和代码本身关系不大。对于一个真实网站来说,是否能抓到数据,取决于一整套运行环境,包括但不限于:请求来源是否可信(IP、地理位置、信誉)是否存在频率限制和行为检测是否启用了验证码、JS 渲染或动态加载是否对自动化行为进行识别和拦截生成一段逻辑上合理的抓取代码。它无法:为你提供稳定、干净的出口 IP帮你绕过真实世界中的反爬机制在请求被拦截时自动切换策略这也是为什么很多“AI 写爬虫

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
2.1 为什么“普通 AI + 爬虫代码”很难跑通真实网页?
2.2 Bright Data:爬虫工程真正的“底层基础设施”
2.3 Warp CLI:为什么选择它作为 AI 的操作入口?
2.4 Web MCP:让 AI 拥有“可执行的网页抓取能力”
4.1 AI 并没有“取代爬虫工程师”,但确实改变了工作方式
4.3 Bright Data + Warp CLI 的适用场景

一、引言
1.1 写过爬虫的人,大概率都踩过这些坑
如果你写过真实可用的爬虫,大概率会对下面这些场景并不陌生:
-
用
requests + headers抓网页,本地测试没问题,一跑就 403 -
稍微高频一点,请求直接被封 IP
-
页面结构一复杂(JS 渲染、动态加载),解析逻辑立刻失效
-
好不容易跑通了,过几天网站一改,代码又得重写
从工程角度看,爬虫真正难的从来不是“写代码”,而是如何在真实网络环境中:稳定访问目标网站、绕过反爬与风控、持续获取真实数据
也正因为如此,很多开发者在学习阶段“写得出爬虫代码”,但在真实项目中却很难把爬虫真正跑起来。
1.2 AI 已经很会写代码了,但它真的能“写爬虫”吗?
这两年,AI 在写代码这件事上的能力进步非常明显。 无论是函数实现、脚本生成,还是简单的数据处理逻辑,AI 基本都能给出像样的结果。
但一旦把问题换成:“帮我抓一个真实网站的数据”
情况就会变得微妙起来。
原因很简单:
-
AI 可以生成“看起来正确”的爬虫代码
-
但它并不能真的帮你解决 IP、反爬、验证码、动态渲染 这些工程问题
结果往往是:
-
代码逻辑没问题
-
但数据抓不到
-
或者抓到的只是“理想环境下”的结果
这也是很多人对“AI 写爬虫”持怀疑态度的根本原因。
1.3 让 AI 不只是“写代码”,而是“驱动抓取”
如果我们换一个角度来看这个问题:
-
AI 擅长的:理解目标、生成流程、调用工具
-
AI 不擅长的:直接对抗真实网站的反爬机制
那是否可以让 AI:不再自己“硬写爬虫”,而是调用一套已经成熟、稳定的网页抓取基础设施?
这正是本文要验证的核心问题。本文将基于 Bright Data + Warp CLI,让 AI 完成一次真实、可复现的网页抓取实战。
具体来说:
-
由 AI 在终端中发起抓取任务
-
由 Bright Data 负责解决真实网页访问问题
-
最终得到确实来自目标网页的真实数据
通过这个过程,来回答一个很实际的问题:AI 到底能不能“把爬虫跑通”?
二、技术与工具介绍
2.1 为什么“普通 AI + 爬虫代码”很难跑通真实网页?
在讨论工具之前,先明确一个容易被忽略的事实:爬虫的成功与否,往往和代码本身关系不大。
对于一个真实网站来说,是否能抓到数据,取决于一整套运行环境,包括但不限于:
-
请求来源是否可信(IP、地理位置、信誉)
-
是否存在频率限制和行为检测
-
是否启用了验证码、JS 渲染或动态加载
-
是否对自动化行为进行识别和拦截
而 AI 在“写爬虫”这件事上,本质上只能做到一件事:生成一段逻辑上合理的抓取代码。
它无法:
-
为你提供稳定、干净的出口 IP
-
帮你绕过真实世界中的反爬机制
-
在请求被拦截时自动切换策略
这也是为什么很多“AI 写爬虫”的示例,只能在非常理想的测试环境下成立,而一旦面对真实网站,就很容易失效。
2.2 Bright Data:爬虫工程真正的“底层基础设施”
要解决上面的问题,关键并不在于“写更复杂的代码”,而在于:有没有一套能够长期稳定访问真实网页的抓取基础设施。
Bright Data 正是定位在这一层。
从工程角度看,它解决的是爬虫中最“脏、最难、最不稳定”的部分,包括:
-
大规模、可调度的代理网络
-
面向反爬场景的 Web Unlocker
-
对复杂网站(JS、验证码)的适配能力
这意味着,当你使用 Bright Data 时:
-
爬虫代码本身可以非常简单
-
更多精力放在“抓什么数据”,而不是“怎么才能连上网站”
也正因为如此,Bright Data 并不只是一个“代理服务”,而更像是爬虫工程的基础设施层。
2.3 Warp CLI:为什么选择它作为 AI 的操作入口?
在本文的实战中,AI 并不是通过网页对话框来“写爬虫”,而是运行在终端环境中。
这里选择 Warp CLI,原因主要有三个:
-
AI 原生终端
-
Warp 将 AI 能力直接内置在 CLI 中
-
AI 不只是“给建议”,而是可以参与执行流程
-
-
工程上下文完整
-
文件系统、脚本、输出结果都在同一个终端环境
-
更接近真实开发场景,而不是“演示性质”的对话
-
-
对 MCP(Model Context Protocol)的原生支持
-
AI 可以调用外部工具
-
不局限于“生成文本”
-
这使得 Warp CLI 非常适合作为:AI 驱动工程任务(而非只写代码)的入口。
2.4 Web MCP:让 AI 拥有“可执行的网页抓取能力”
真正把 AI 和 Bright Data 连接起来的关键,是 Web MCP(Model Context Protocol)。
可以简单把 MCP 理解为一件事:给 AI 提供一组“它可以真实调用的工具”。
在本文使用的 Bright Data Web MCP 中,这些工具包括:
-
搜索引擎工具(用于查找目标网页)
-
网页抓取工具(用于获取真实页面内容)
-
面向复杂网站的抓取能力(反爬、验证码处理)
当 AI 通过 Warp CLI 接入 Web MCP 后,它的角色发生了变化:
-
不再只是生成一段“爬虫示例代码”
-
而是可以:调用抓取工具、发起真实请求、返回真实网页数据
从这个角度看,AI 更像是一个:负责任务调度与决策的“执行者”,而不是单纯的代码生成器。
2.5 本文所采用的整体技术链路
综合来看,本文中 AI 驱动爬虫的整体流程可以概括为:
-
Warp CLI 提供 AI 运行与交互环境
-
Bright Data Web MCP 为 AI 提供可调用的网页抓取工具
-
Bright Data 基础设施 负责解决真实网站访问与反爬问题
-
AI 负责发起任务、组织流程并输出结果
三、实战演示
基于 Bright Data+Warp CLI 的爬虫实战
3.1 实战场景说明
在这次实战中,我选择了房地产数据作为抓取目标,原因很简单:
-
页面反爬机制成熟、严格
-
普通
requests几乎必然触发 403 或验证码 -
页面数据结构清晰,抓取结果容易验证真实性
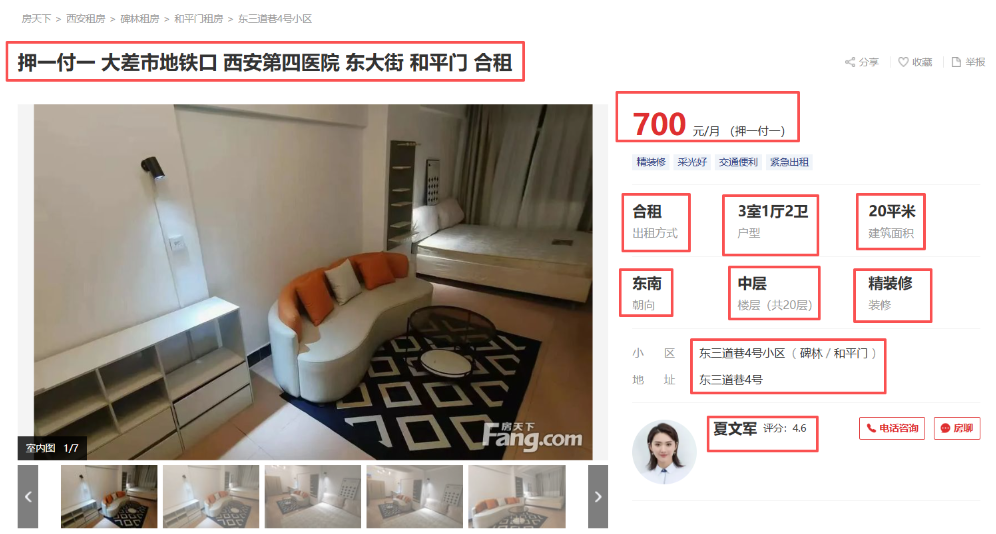
这类页面非常适合作为判断标准:如果这个页面能稳定抓到数据,那这套方案在工程上就是“站得住的”。
3.2 环境准备
在开始之前,需要准备以下环境:
- - Warp CLI:作为 AI 驱动爬虫的终端入口
- - Node.js(LTS 版本即可):用于运行 MCP 服务
- - Bright Data 账号:用于获取 API Key
- - Bright Data Web MCP:AI 调用的网页抓取服务
Bright Data注册链接:https://www.bright.cn/blog/ai/warp-cli-with-web-mcp/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_aipaisen202602&promo=brd26
3.3 启动 Bright Data Web MCP 服务
首先,需要在本地启动 Bright Data Web MCP 服务,让 AI 拥有可调用的抓取工具。
在终端中执行(示例):
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" PRO_MODE="true" npx -y @brightdata/mcp关键点说明:
- - `API_TOKEN`:你的 Bright Data API Key
- - `PRO_MODE=true`:启用完整工具集
- - MCP 服务启动后,会在本地监听并等待 AI 调用
首次启动时,MCP 会在你的 Bright Data 账号中自动创建对应的抓取 Zone,用于处理网页访问与反爬问题。当终端中看到类似“Server started successfully”的提示,说明 MCP 服务已经就绪。
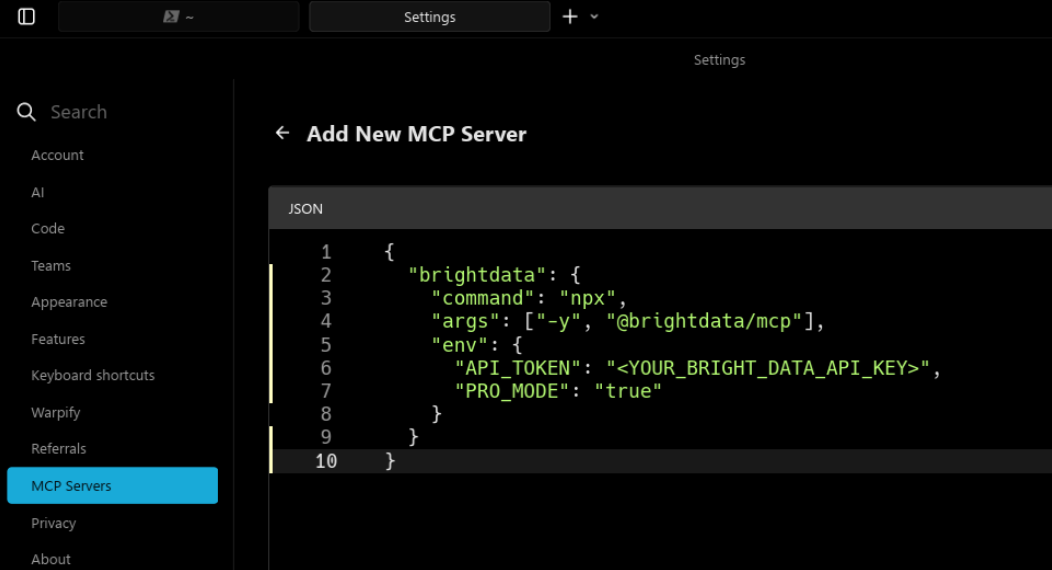
3.4 在 Warp CLI 中配置并连接 MCP
接下来,需要让 Warp CLI 识别并连接这个 MCP 服务。
在 Warp 中:
1. 打开设置或命令面板
2. 进入 MCP Servers 管理界面
3. 添加一个新的 MCP Server,指向本地运行的 Bright Data MCP
4. 保存并确认连接状态
在 MCP 配置面板中,添加以下 JSON 配置:
{
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
连接成功后,你可以在 Warp 的 AI 面板中看到:
- - Bright Data MCP 已被识别
- - 可用的抓取工具列表已加载
这一步非常关键,它意味着:AI 已经不只是“聊天”,而是拥有了真实可执行的网页抓取能力。
3.5 让 AI 执行一次真实网页抓取任务
在 Warp 的 AI 面板中,直接用自然语言下达指令,例如:
Scrape data from "https://xian.zu.fang.com/", save it to a local "data.json" file.AI 在接收到这个任务后,会自动完成几件事:
1. 判断需要使用哪种抓取工具
2. 调用 Bright Data 提供的网页抓取能力
3. 向目标网站发起真实请求
4. 将返回的数据整理为结构化结果
这里非常重要的一点是:这些数据并不是 AI“生成”的,而是直接来自目标网页。
3.6 保存并验证抓取结果
抓取完成后,当前工作目录中会生成一个 `data.json` 文件。
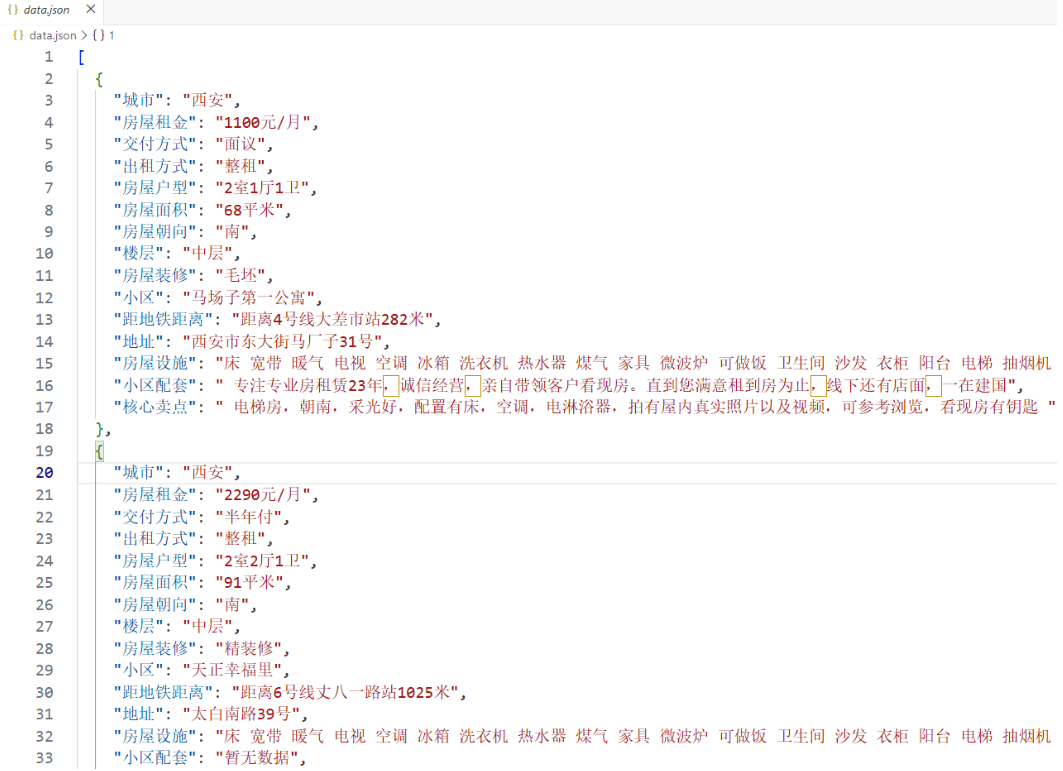
到这里,一次完整的“AI 驱动网页抓取”流程就已经跑通了。
四、总结
4.1 AI 并没有“取代爬虫工程师”,但确实改变了工作方式
通过前面的实战可以看到一个很现实的结论:AI 并没有凭空解决爬虫的技术难题。
反爬机制、网络环境、稳定性问题依然存在,而且仍然需要专业的基础设施来支撑。AI 并不会让这些问题自动消失。但变化在于,开发者与爬虫系统的交互方式正在发生改变:
- 过去:
- - 人写代码
- - 人调策略
- - 人反复试错
- 现在:
- - 人描述目标
- - AI 组织流程
- - 底层抓取由成熟工具完成
这种变化并不是“替代”,而是重心的上移。
4.2 从“写爬虫代码”到“描述抓取目标”
在传统模式下,写爬虫往往意味着:
- - 大量时间花在调 headers、IP、Cookie
- - 很少时间真正思考“我要什么数据”
而在本次实战中,可以明显感受到:抓取目标的表达,开始变得比代码细节更重要。
你只需要明确:抓什么页面、要哪些字段、结果保存成什么形式
至于请求如何发、反爬如何处理、网络环境如何保证,这些细节可以交由底层基础设施来解决。
4.3 Bright Data + Warp CLI 的适用场景
结合这次实践,这种 “AI 驱动 + 爬虫基础设施” 的方式,特别适合以下场景:
- - 快速验证某个网站是否“可抓”
- - 数据分析或研究前的样本采集
- - 原型阶段或内部工具开发
- - 对稳定性要求高、但不想自己维护反爬逻辑的项目
需要注意的是,它并不是万能解法:
- - 超大规模爬取仍然需要系统设计
- - 高度定制化场景仍然需要人工介入
但在效率与可用性之间,它提供了一个非常实用的平衡点。
4.4 写在最后
回到文章开头提出的问题:AI 也能写爬虫吗?
从这次实战来看,更准确的说法可能是:AI 并不是在“写爬虫”,而是在“驱动爬虫执行”。
当 AI 被赋予:可调用的工具、稳定的底层能力、明确的工程边界
它就不再只是一个“会写代码的聊天机器人”,而是一个可以真正参与工程流程的执行者。
这或许才是 AI 在爬虫、数据采集乃至更多工程领域中,最现实、也最可落地的价值所在。
感兴趣的小伙伴点击下方链接注册体验:
Bright Data注册链接:https://www.bright.cn/blog/ai/warp-cli-with-web-mcp/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_aipaisen202602&promo=brd26
资料获取,更多粉丝福利,关注下方公众号获取


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)