小红书图像编辑模型开源,媲美NanoBanana Pro
小红书超级智能团队倾力打造的指令驱动图像编辑扩散模型FireRed-Image-Edit开源。这是一个拥有顶级指令理解与像素级控制力的图像编辑大模型。研发团队系统性优化了数据清洗、模型架构、训练策略及多维评测体系。凭借庞大且高质量的训练样本,该模型在自然视觉编辑、文字渲染及创意生成上达到了极高的水准。
小红书超级智能团队倾力打造的指令驱动图像编辑扩散模型FireRed-Image-Edit开源。


这是一个拥有顶级指令理解与像素级控制力的图像编辑大模型。
研发团队系统性优化了数据清洗、模型架构、训练策略及多维评测体系。
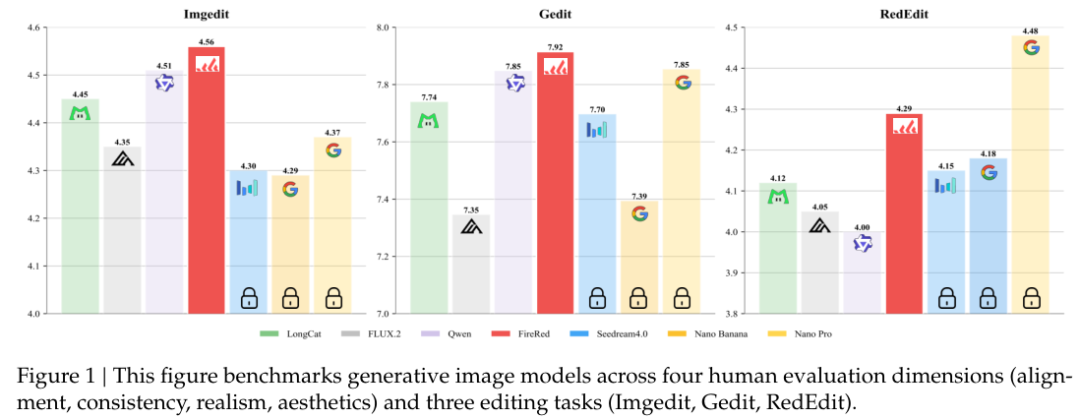
凭借庞大且高质量的训练样本,该模型在自然视觉编辑、文字渲染及创意生成上达到了极高的水准。

构筑十亿级高质量图文数据基石
收集海量数据如同在宽广的河床里淘金。研发团队最初获取了16亿张图像样本。这些样本涵盖9亿张文本生成图像和7亿张图像编辑对。庞大的基座数据确保了模型能见识到足够多的世界知识。
真实场景的数据往往长尾且分布不均。团队通过精细的分层抽样和清洗,最终保留了超过1亿张高质量训练样本。
这其中的文本到图像数据与图像编辑数据比例恰好维持在均衡的状态。这种平衡设计让模型既能拥有强大的文本语义理解力,又能应对千变万化的图片修改需求。

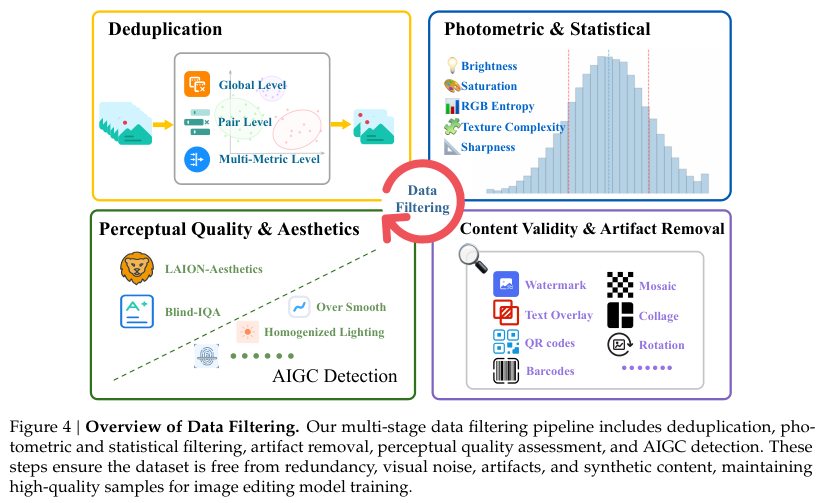
仅仅有海量数据远远不够。杂乱的水域里往往混杂着泥沙。研发团队设计了三级严格的去重机制。从粗粒度的全局特征聚类,到细致入微的峰值信噪比与结构相似度对比,过滤网将高度同质化的废料无情剔除。
消除视觉杂音是确保模型审美在线的关键。
光度与统计过滤机制会识别并丢弃过曝、欠曝或色彩诡异的图像。算法还会揪出那些带有水印、二维码或严重压缩伪影的脏数据。
经过人工智能生成内容检测器的筛查,过于合成化或带有明显机器生成痕迹的图像也被清理出局。
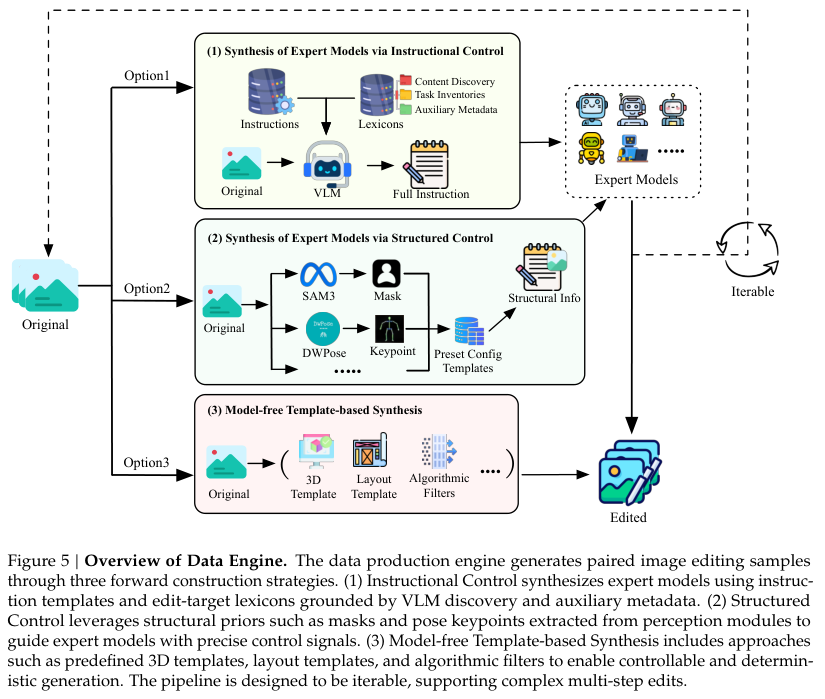
自然界的优质编辑样本毕竟有限。团队搭建了一套庞大的数据生产引擎。指令控制策略让机器像熟练的画师一样,根据文本提示词自动生成目标画面。
结构化控制则利用轮廓遮罩和人体骨骼关键点,精确指挥图像的每一次像素扭曲。
对于那些需要极度精确修改的场景,免模型模板合成技术派上了用场。
三维参数化模板可以稳定输出表情切换、姿态改变等高难度视觉动作。这种做法巧妙绕开了深度学习偶尔出现的幻觉问题。
针对极度缺乏的冷门任务,团队基于海量向量检索库实施查缺补漏,精准打捞对口图像进行针对性训练补充。
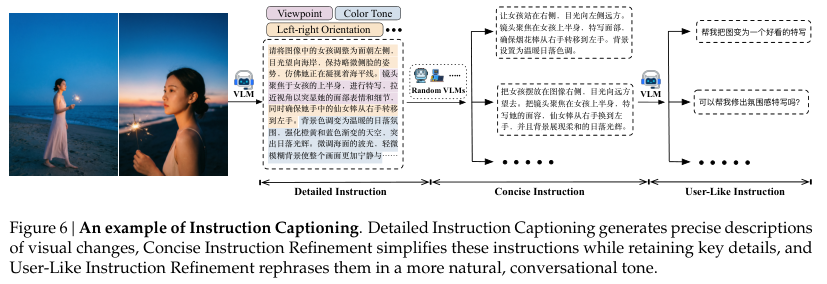
为了让机器深刻理解人类复杂的意图,团队精心打磨了图文标注引擎。
标注过程经历了从结构化描述到用户口语化表达的层层蜕变。结构化描述像是一份详尽的法医鉴定报告,不带感情地记录下主干、背景、光影和视角。
过度严谨的长篇大论并不符合普通人的说话习惯。精简指令优化阶段会将冗长的描述浓缩提炼,去掉多余的修饰词。
用户化指令重写更是赋予了冰冷文字以人情味。机器会学习类似你能帮我把这个修一下吗这样的真实社交语境。长短不一的多元化指令交织在一起,让模型具备了在含糊其辞中精准猜中用户心思的能力。
为了进一步提升数据集的含金量,团队引入了困难负样本挖掘机制。人工智能模型会刻意生成一些看似正确却带有细微错误的指令。真人专家在双盲测试中对这些迷惑性选项进行打分。
基于这些黄金标准数据微调出的视觉语言模型,成为了不知疲倦的自动化质检员。
创新模型架构与极致系统效率
FireRed采用了双流多模态扩散变压器架构。
这种架构能将文本词汇、高清图像潜变量以及参考图像的特征融合进统一的处理流中。
密集的双向交互机制让不同模态的信息能互相沟通,极大提升了模型在执行精确修改时保护原有图像结构的能力。
处理各种长短不一的高维视觉序列是一项严峻挑战。
模型采用了三维统一旋转位置编码机制。参考图像和目标图像共享相同的空间坐标,仅仅通过时间间隔进行区分。这种坐标对齐方式如同给不同的图像打上了精准的地理定位标签。
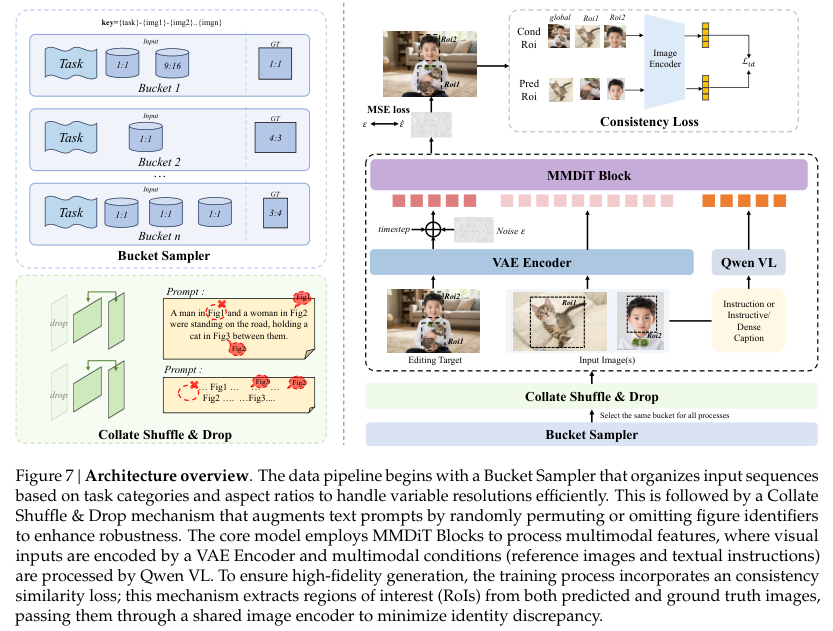
传统的训练加载器往往只认死理,偏爱方形且尺寸一致的图像。多条件感知桶采样器彻底打破了这一桎梏。它会像有经验的快递打包员一样,根据目标宽高比和输入图像的数量,将形状相似的图片塞进同一个批次桶中。
这种巧妙的打包策略极大减少了无用的黑边填充物。公式化计算确保了总视觉序列长度严格贴合显卡的计算上限。通过最小化裁剪面积,算法保全了画面原始的构图比例,让计算资源一滴不漏地全部用在刀刃上。
为了防止模型变成只会死记硬背的书呆子,团队设计了随机指令对齐机制。
在整理训练数据时,参考图像会被随机丢弃或打乱顺序。文本提示词会根据洗牌后的结果动态重新排号。这种刻意制造的混乱强迫模型去理解真正的语义关联,而不是死盯着固定的空间位置。
在系统运行效率层面,团队做出了大刀阔斧的优化。
提前剥离视觉语言模型的编码过程,将计算好的嵌入向量存在线下,省去了反复计算的繁琐。完全分片数据并行技术将庞大的显存开销分摊给了众多显卡集群。混合精度训练如同给运转的机器上了润滑油。
结合集群的高速内部网络,混合分片数据并行策略将显卡节点间的通信瓶颈降到了最低。这种化整为零又紧密协作的方式,让庞大的Transformer模型在海量数据中实现了训练吞吐量的狂飙。
渐进式训练路线与对齐人类偏好
如同培养一名顶尖的艺术大师,模型的训练也遵循着循序渐进的科学路线。
全周期包含了基础预训练、持续预训练、监督微调以及基于人类反馈的强化学习。每一个阶段都背负着特定的进化使命。
基础预训练阶段旨在为模型灌输极其渊博的世界常识。
团队采用了无差别的海量互联网数据,容忍了一定程度的噪音。
渐进式时间步采样策略在初期会大量分配高噪音的粗糙画面,强迫模型先学会勾勒大轮廓。
随着训练深入,采样比例逐渐向平滑的低噪音区域倾斜,模型便开始精雕细琢每一丝纹理。
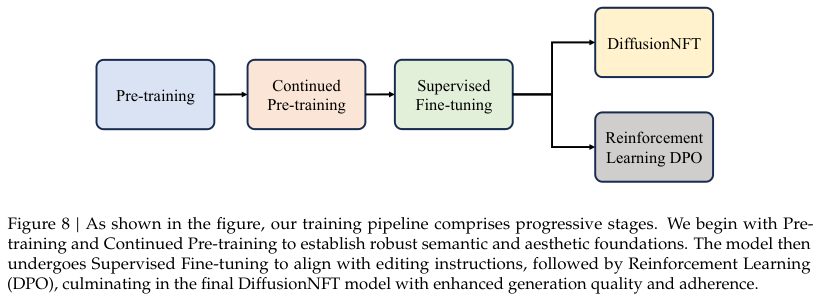
持续预训练阶段缩小了火力圈。模型在更高分辨率的画板上处理融合了纯生成与图像编辑的混合任务。
通过基于语义聚类的严格数据均衡策略,即使是极其罕见的小众艺术风格,也能得到充足的曝光机会,从根本上杜绝了模型偏科的毛病。
进入监督微调阶段,模型开始拥抱极其严苛的审美标准。
人工精挑细选的高分辨率图片成为唯一的教材。严格的指令跟随监督如同定海神针,让模型彻底抛弃早期积累的劣质绘画习惯。
指数移动平均技术将不同训练周期的经验融会贯通,有效熨平了学习曲线中的抖动。
为了让机器的审美无限趋近于人类,传统的直接偏好优化虽然好用,却经常面临双重退化的窘境。
机器在努力远离劣质作品的同时,往往连画好优秀作品的能力也一起丢失了。团队巧妙提出了正样本强化策略,给优秀作品加上了高额的权重系数。
这种不对称的梯度优化迫使模型始终将精力集中在临摹顶尖杰作上。基于混合策略构建的对比数据集,让模型在不断突破自身天花板的同时,彻底摆脱了自我闭环生成的死胡同。
文字渲染一直是图像生成领域的顽疾。团队基于流匹配误差优化推出了极具创新的排版感知文字奖励机制。传统的评判标准只看单词拼写对不对。聪明的模型很容易钻空子,画出巨大且突兀的字符来骗取高分。
排版感知机制就像是一位严苛的书法老师。它会把生成的文字拆解成一个个独立的字符,仔细打量它们的位置和大小是否合乎常理。
距离偏差和过度缩放都会招致严厉的惩罚。轻量级的门控机制确保只有在拼写大体正确时才计入排版得分,这让文字编辑任务的排版显得极度自然。
在人像编辑中保护人物ID一致性是一项高阶技术。团队引入了基于身份一致性约束的训练机制。就像素描起稿定下了骨点,早期的粗糙高噪音阶段其实已经勾勒出面部的稳固轮廓。
在这个关键窗口期,算法会从模糊的画面中提取并对齐人脸特征,计算其与原图的特征向量余弦距离。
动态的权重衰减机制让这项约束在后期刻画细节时悄然离场。这既保全了主角的独特身份,又避免了僵硬的五官破坏了肌肤的光影质感。
为了不让分布式训练的某些显卡算力闲置,分布式分层时间步采样保证了每一次迭代都能完美覆盖所有噪音阶段。逻辑正态损失权重分配机制则把好钢用在了刀刃上。
优化器会主动忽略过于简单或完全无望的极端时间段,将全部算力砸在决定图像核心语义结构的中期关键阶段。
全面多维评测体系与卓越编辑能力
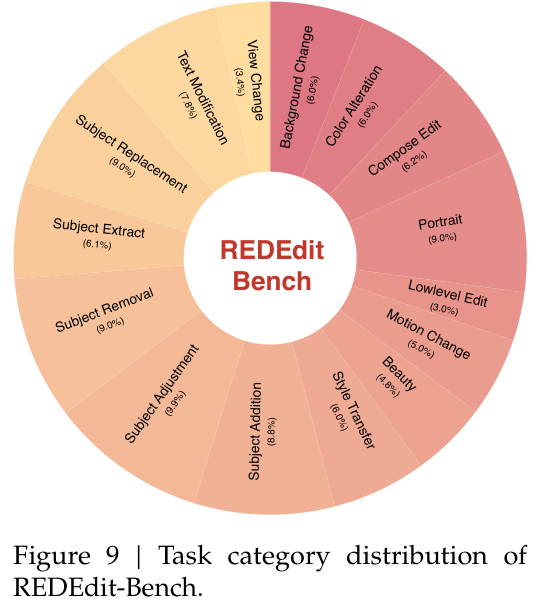
为了真实衡量模型的能力边界,团队自建了涵盖多种中英双语的评测基准体系(REDEdit-Bench)。
一千六百多组由专业人士手写的编辑对覆盖了从基础修图到复杂面部美化的十五种主流场景。这填补了开源界缺乏高质量实用评估工具的空白。

自动化的多模态大语言模型裁判配合光学字符识别技术,构成了冷酷无情的计分板。
成功率、过度编辑率、风格融合度被量化得清清楚楚。模型究竟有没有老老实实听从指令,画面看着违不违和,各项指标一览无余。
在极具权威的盲测人类评价中,多个模型的作品被打乱后呈现在审阅者面前。不带任何滤镜的盲选结果显示,FireRed在指令跟随维度紧咬行业顶级闭源模型。

在保护原图不被破坏的一致性保留评价上,它以最高分傲视群雄,尽显其在精确手术刀式修改上的从容。
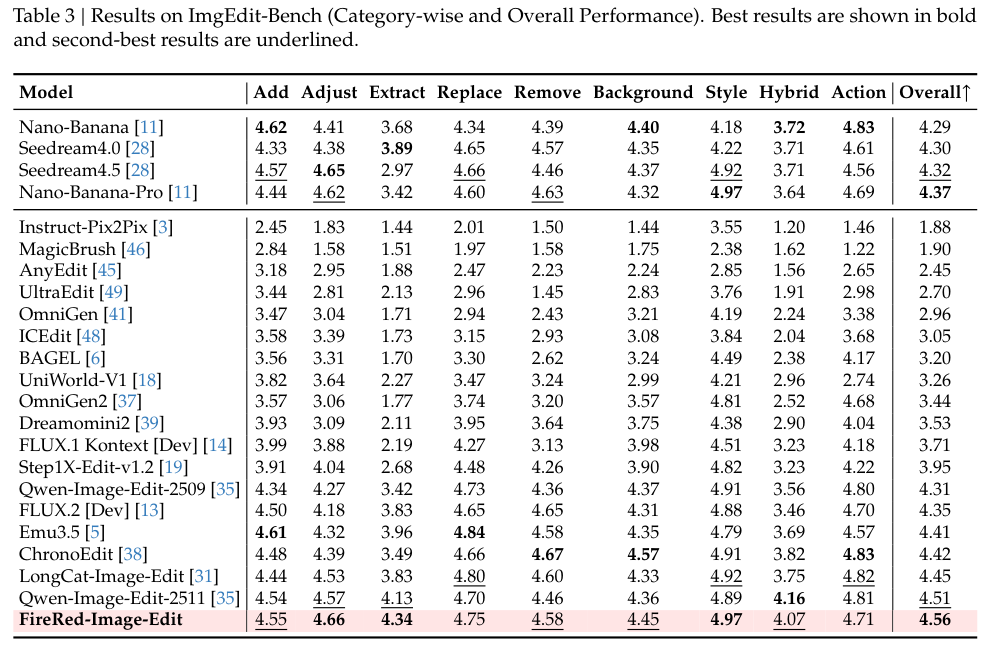
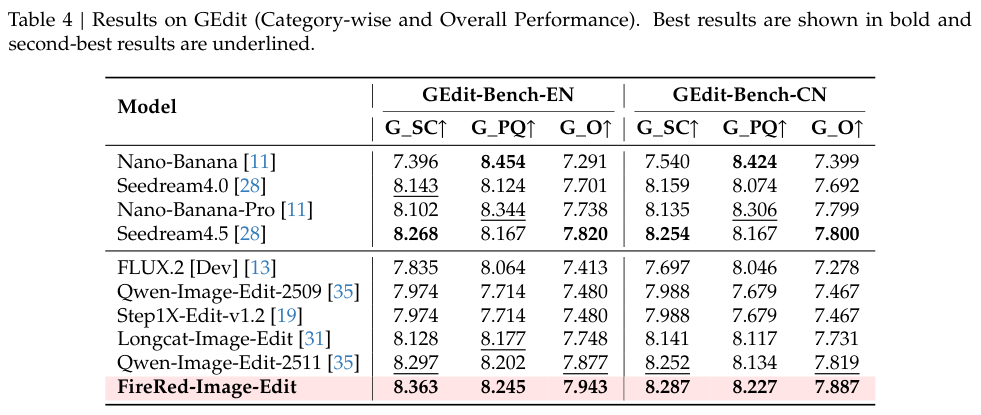
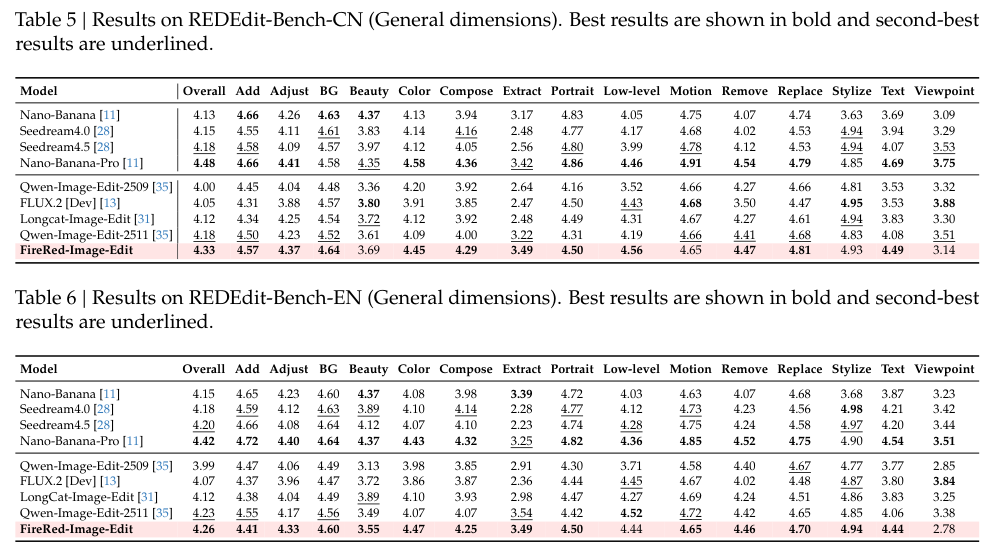
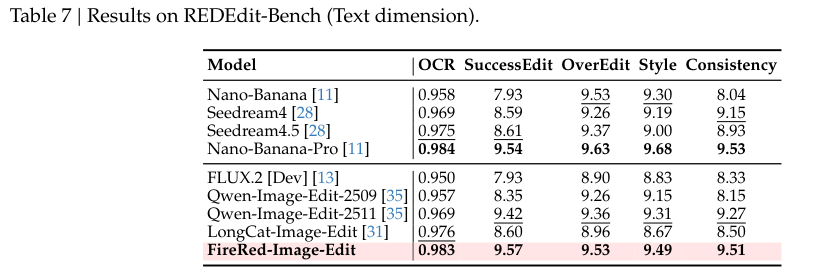
无论是简单常见的替换物件,还是大刀阔斧的重构背景,各项维度的定量分数稳稳霸榜。精妙复杂的复合编辑指令和严苛的不变区保留要求,均被妥善处理。
基于文本维度的专向评估,深入考量了模型在长段落生成、文字完美替换与纠错上的造诣。字体样式、文字走向以及与底层图形背景的融洽度均经受住了严苛的视觉检验。

在各类极限测试用例中,无论是给床上休息的人加上一台电脑,还是手腕上佩戴精巧的雪花手链,边缘与阴影的过渡都找不出丝毫破绽。


老旧照片的除噪与细节修复同样干脆利落。原本模糊的眉眼在重新生成后依然紧贴着人物的原始骨相。


充满脑洞的创造性编辑任务最能考验模型对空间的深层理解。从剖面图构造到漂浮物体布局,模型展现出了无视物理限制却又极度符合视觉逻辑的构图美学。

虚拟试衣功能更是将布料的光泽、褶皱与人物原有的姿态巧妙折叠进同一个三维空间内。

通过这一整套在数据工程、系统底座以及策略打磨上的组合拳,FireRed交出了最不可思议的图像编辑魔法。
参考资料:
https://github.com/FireRedTeam/FireRed-Image-Edit
https://huggingface.co/FireRedTeam/FireRed-Image-Edit-1.0
https://modelscope.cn/models/FireRedTeam/FireRed-Image-Edit-1.0

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)