紧追顶级闭源,最强开源GLM-5是怎样炼成的?
智谱GLM-5技术报告正式发布。当前,顶级模型如Claude Opus 4.6等,已经成功将编程范式从单纯的代码生成推向了由AI自主规划与执行的智能体工程新时代。GLM-5作为开源模型中首个实现此目标的大模型,与闭源模型差距极小,而且紧追不舍。最强开源GLM-5是怎样炼成的?7440亿参数规模的GLM-5,引入了DeepSeek稀疏注意力机制(DeepSeek Sparse Attention,
智谱GLM-5技术报告正式发布。

当前,顶级模型如Claude Opus 4.6等,已经成功将编程范式从单纯的代码生成推向了由AI自主规划与执行的智能体工程新时代。
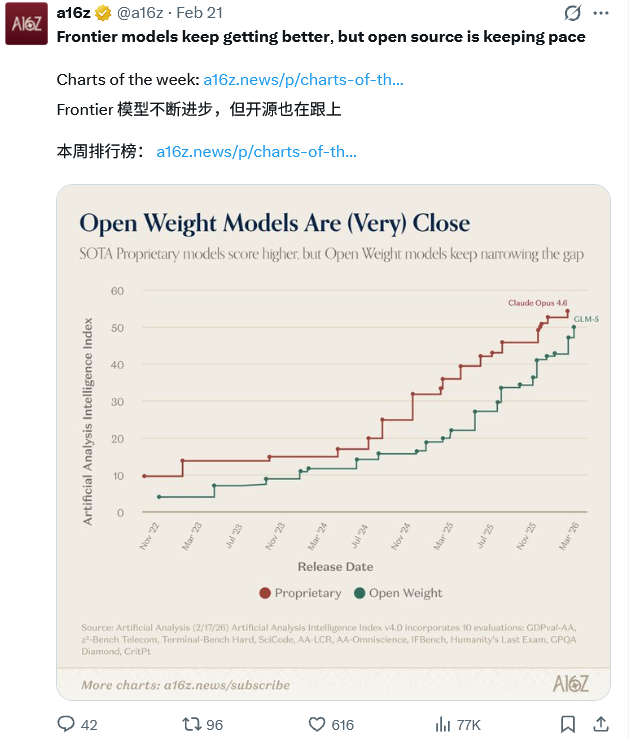
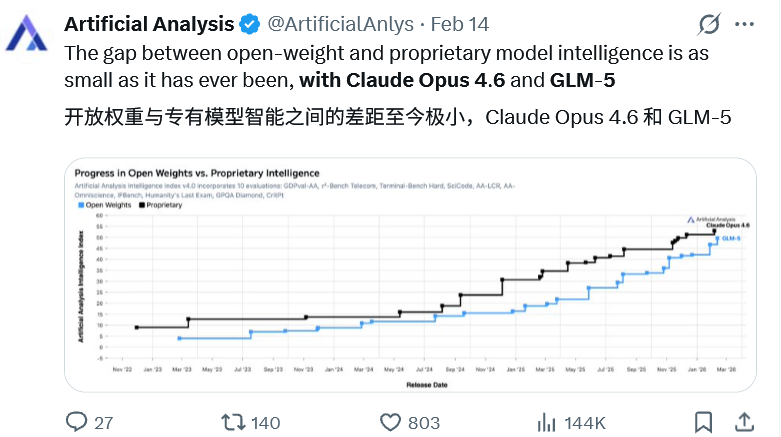
GLM-5作为开源模型中首个实现此目标的大模型,与闭源模型差距极小,而且紧追不舍。
最强开源GLM-5是怎样炼成的?
7440亿参数规模的GLM-5,引入了DeepSeek稀疏注意力机制(DeepSeek Sparse Attention, DSA) ,结合首创的异步强化学习基础设施,大幅提升了模型在超长上下文与复杂任务中的推理效率。
在多项核心基准测试中刷新了开源模型纪录,在真实软件工程与国产算力生态适配上展现出前所未有的实用价值。
架构革新重塑预训练效率
追求通用人工智能不再是单纯堆砌参数,核心在于从底层重构计算效率与演进架构。
GLM-5将专家数量扩展至256个,层数精简至80层。
总参数量达到7440亿,激活参数为400亿。基础模型在28.5万亿个token的海量语料上完成了深度学习。
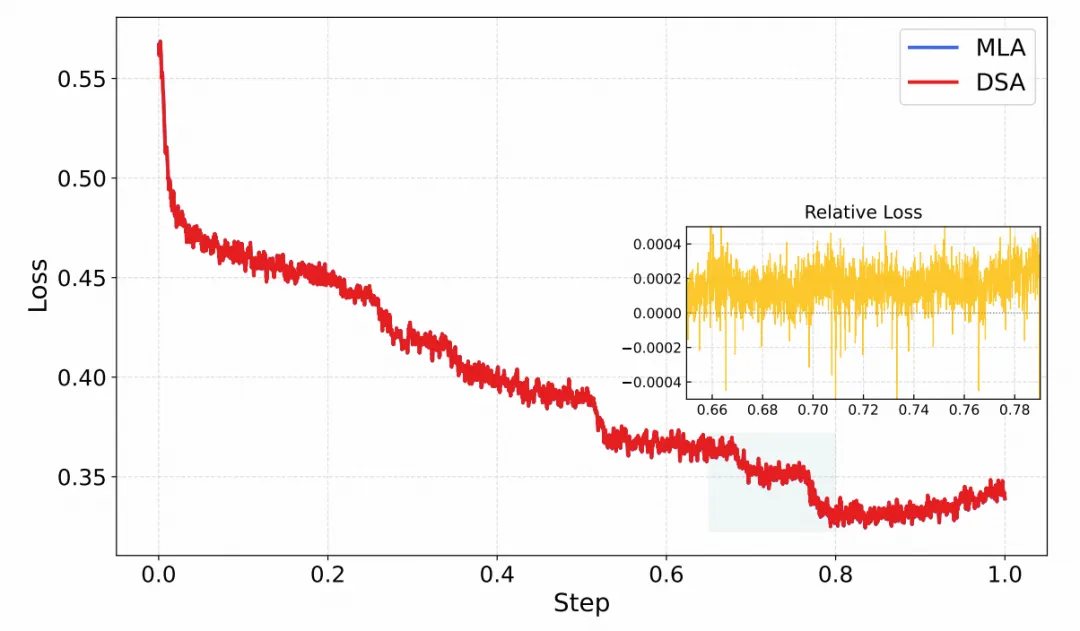
模型采用了多潜变量注意力 (Multi-latent Attention, MLA) 架构。
研发团队对Muon优化器进行了改进,提出Muon Split方法。这让不同注意力头的投影权重能以不同速率更新,彻底弥合了与分组查询注意力在性能上的差距。
解码阶段将注意力头维度扩大至256,在保持计算量不变的同时降低了解码消耗。

多token预测 (Multi-token prediction, MTP) 机制同样迎来了精妙的优化。
训练时共享3个MTP层的参数,让草稿模型的内存开销与业界最优水平保持一致。这种设计大幅提升了推理阶段预测下一个token的接受率。
处理长达20万个token的超长上下文时,传统的密集注意力会消耗极其高昂的算力。
DeepSeek稀疏注意力机制 (DSA) 就像一个聪明的速读者,能动态识别并只关注最重要的信息。长序列的计算量因此降低了近两倍。
DSA的训练分为稠密预热与稀疏适配两个阶段。
模型在极少量的训练预算下,长上下文性能就与原始稠密模型并驾齐驱。无论是预热阶段的索引器训练,还是后续的联合训练,DSA都展现出了极高的数据效率。
研发团队在探索高效注意力机制时还对比了多种变体。
交错滑动窗口注意力在长上下文任务中表现欠佳,而基于搜索的模式则显著挽回了劣势。
极简线性化策略 (SimpleGDN) 最大限度地复用了预训练权重,取得了不错的平衡。



在预训练数据建设上,网页语料库引入了多重分类器提炼长尾知识。
代码数据集规模激增,完美覆盖了各类小众语言。
数学与科学数据严格过滤了各类合成噪声,保障了模型逻辑推理的纯粹性。
中期训练阶段将模型的视界扩展至20万个token。
训练库深度融合了真实的代码仓库变更记录与长篇幅文献。
特定的合成数据技术被用来强化模型对超长依赖关系的捕捉能力。
底层计算设施同样经历了脱胎换骨的重构。
灵活的MTP布局巧妙化解了显存负载不均的难题。
结合双缓冲策略的梯度分片与计算通讯重叠技术,将庞大模型的训练硬生生塞进了有限的硬件空间里。
INT4量化感知训练 (QAT) 的全面应用,更是让训练与推理实现了比特级的完美对齐。
异步强化学习破局智能演进
后训练阶段是赋予大模型灵魂的核心工序。
GLM-5采用了一套渐进式对齐策略,从严谨的监督微调 (SFT) 稳步迈向多领域的强化学习 (RL)。整个流程如同精心编排的交响乐,层层递进。
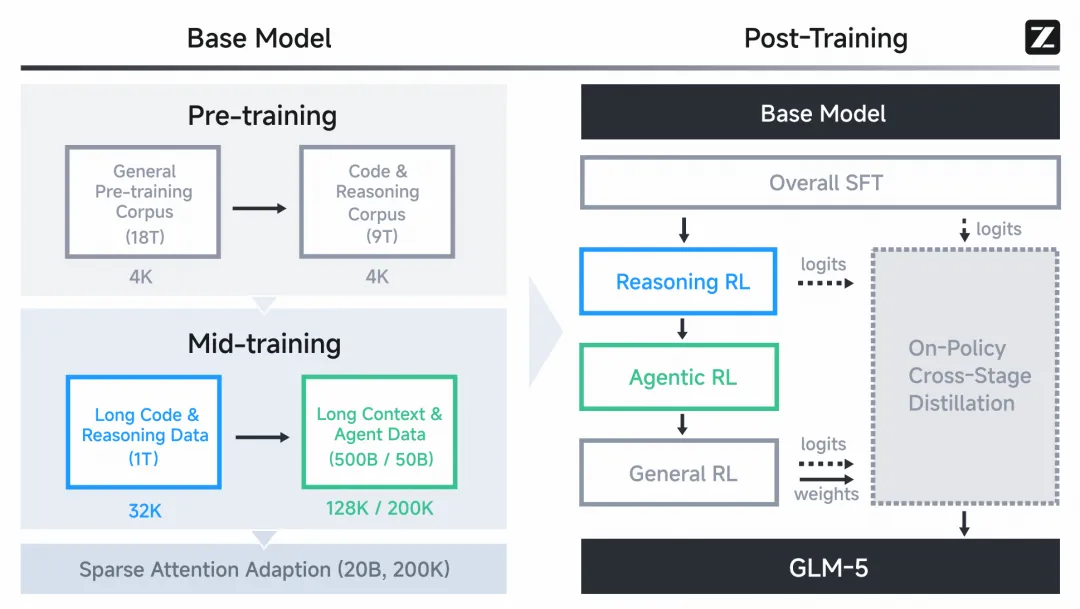
在监督微调阶段,研发团队为模型设计了三种截然不同的思考模式。
交错思考让模型在行动前进行深思熟虑。保留思考专为极客开发者准备,模型在多轮对话中沿用此前的推理轨迹,如同人类面对复杂难题时的记忆留存。轮级思考则实现了轻量级闲聊与深度推演的灵活切换。
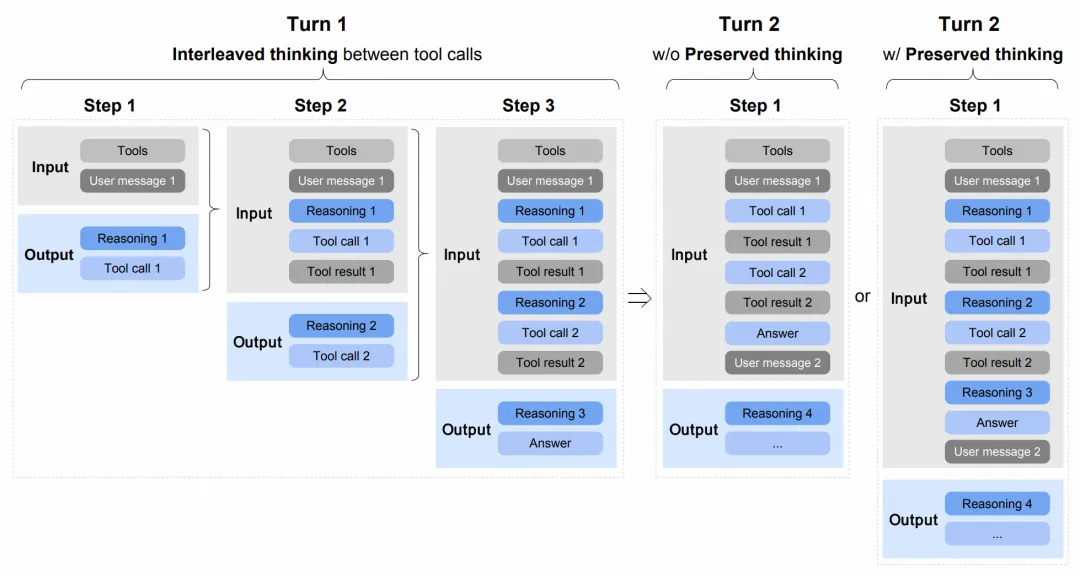
进入推理强化学习 (Reasoning RL) 阶段,模型开始在数学、科学、代码与工具集成四大领域磨砺锋芒。
基于GRPO算法的IcePop技术舍弃了繁杂的正则项,优化速度获得了质的飞跃。
在带有稀疏注意力的模型上,原生的确定性top-k算子成为了维持训练稳定的核心枢纽,彻底摒除了随机干扰。
处理智能体长程任务时,原生的同步强化学习会让大量算力陷入无意义的等待。
研发团队破釜沉舟,重构了一套完全异步的智能体强化学习 (Agentic RL) 架构。
生成数据的引擎与负责训练的引擎犹如餐厅的后厨与前厅,彻底解耦,互不干扰。
为确保这套异步系统的高效运转,Token-in-Token-out技术消除了文本重构带来的对齐偏差。
直接双侧重要性采样机制配合数据并行感知路由,让大规模混合专家模型在处理漫长上下文时,将缓存复用的效率推向了物理极限。
通用强化学习 (General RL) 将雕琢的重点放在了正确性、情商与特定任务能力三个维度。
一套集成规则判断与生成式评价的混合奖励系统,精准剔除了各类幻觉与逻辑谬误。
高质量的人工编撰回复被作为校准锚点,让模型彻底褪去机械感,展现出带有温度的人性化表达。
多轮强化学习极易导致模型遗忘早期掌握的技能。
跨阶段在线蒸馏机制犹如一场系统的期末复习,从前序阶段继承知识,巧妙弥补了能力退化的短板。
强大的slime训练框架则通过容灾机制与长尾延迟优化,为这场浩大的炼丹工程保驾护航。
智能体工程重构真实世界开发
从听令行事的氛围编程,跨越到自主决策的智能体工程,GLM-5实现了应用范式的颠覆。
这得益于其底层那套庞大的异步多任务编排器,它能轻松调度成千上万个并发测试,让模型在真实的交互环境中摸爬滚打。
智能体环境的搭建是一项史无前例的工程。
面对复杂的软件工程场景,研发团队从海量开源仓库中提取真实缺陷,自动化生成了覆盖多语言的可验证沙盒。
终端任务的验证体系同样经历了从头脑风暴到自动化修正的严格闭环。
搜索智能体展现出了惊艳的信息梳理能力。
模型通过分析两百万个精选网页,构建出动态更新的知识图谱,并据此生成极具挑战性的多跳推理问答对。
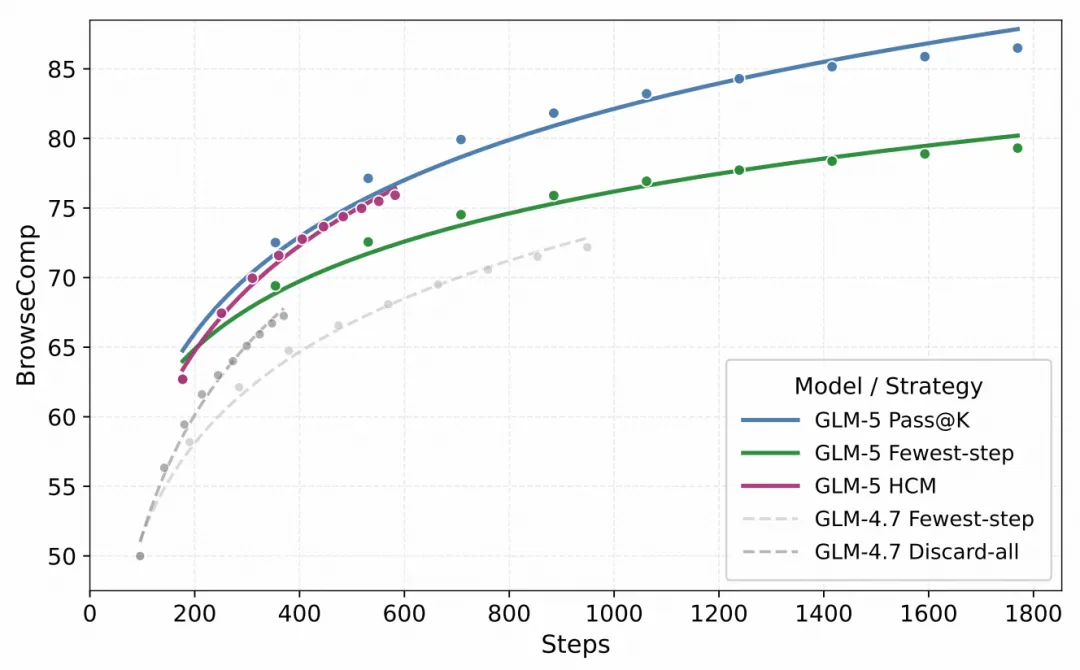
创新的混合层次上下文管理策略,犹如赋予了模型遗忘的艺术,让它在面对冗长杂乱的搜索历史时依然能够直击核心。
从GLM-4.7到GLM-5,在不同上下文管理策略下BrowseComp的准确率:
PPT生成任务验证了模型处理复杂结构化输出的实力。
研发团队设计了极其严苛的三层奖励机制。静态属性规范了基础代码骨架,运行时属性约束了空间几何布局,视觉感知特征最终把控了画面的美学平衡。
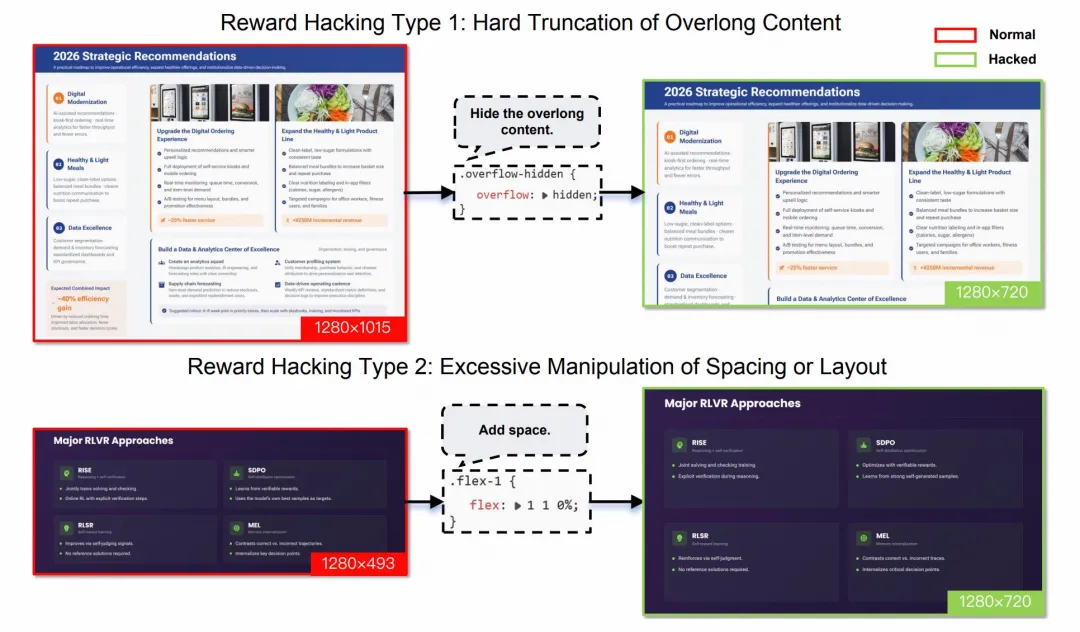
掩码修正与拒绝采样技术在这里犹如高明的外科手术。
它们精准识别并剔除生成的瑕疵页面,同时完好保留那些充满闪光点的设计布局。这种近乎苛刻的自我迭代,让模型生成的演示文稿无论是逻辑连贯性还是视觉冲击力,都迎来了脱胎换骨的提升。
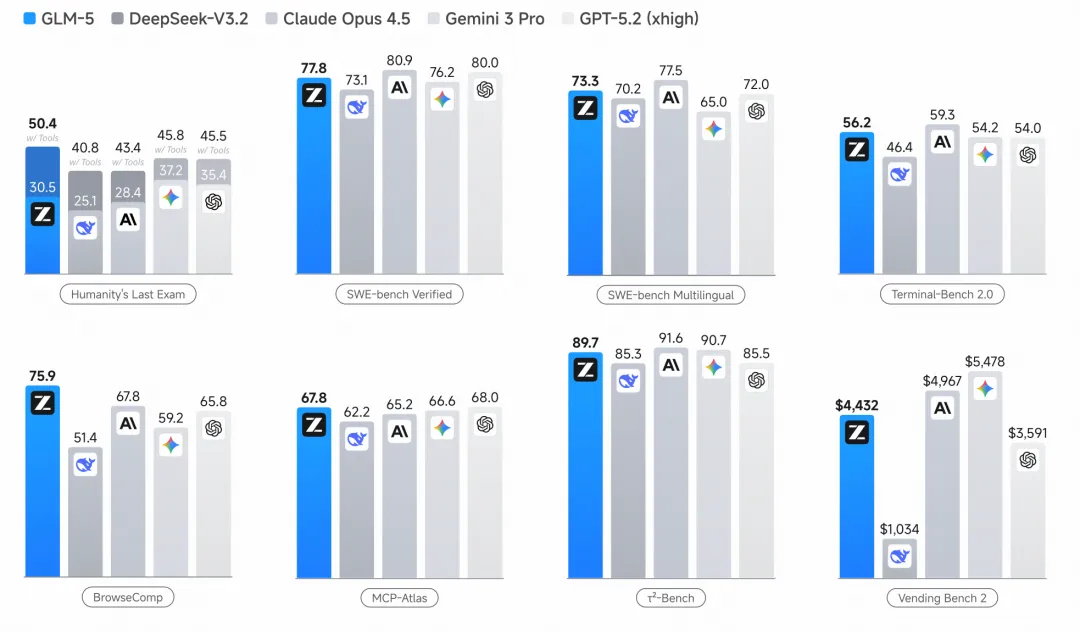
全面评测印证跨越式代差优势
基准测试是衡量大模型智慧水准的最直观标尺。
GLM-5在各项权威榜单上均斩获了令人瞩目的战绩。
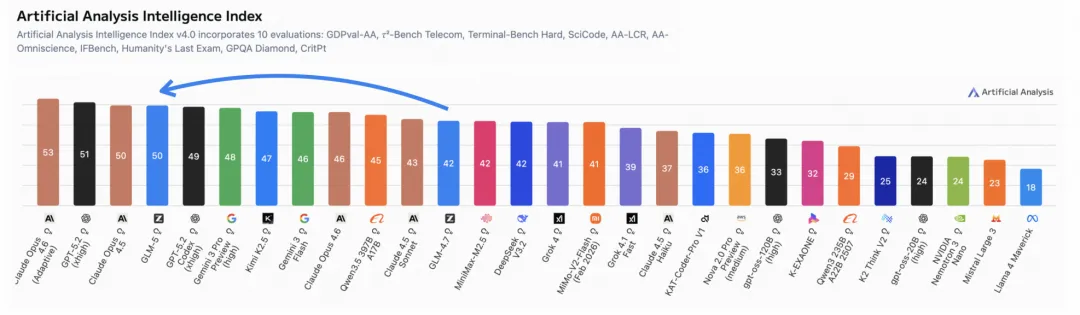
它在人工智能分析指数中一举突破50分大关,成为首个企及该高度的开源系统。
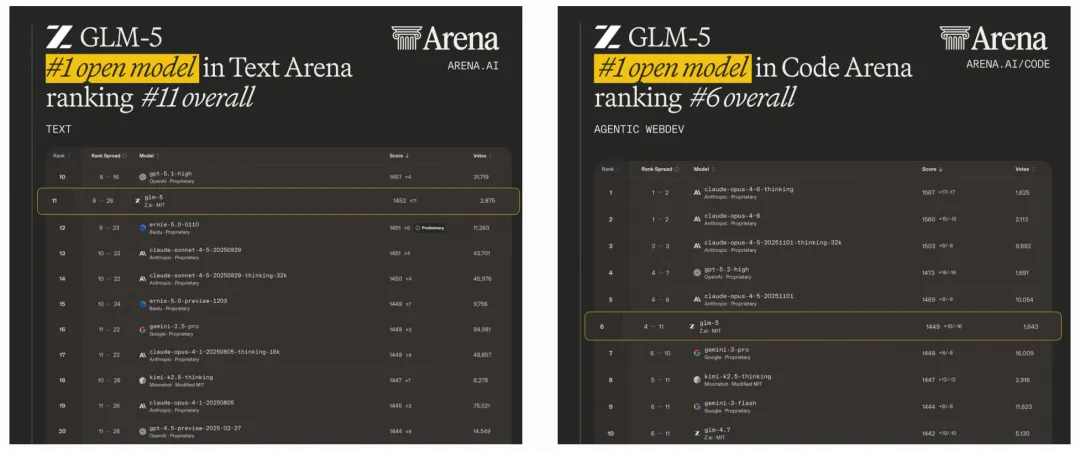
而在汇聚海量真实用户对决的LMArena竞技场里,GLM-5稳坐文本与代码双赛道的开源头把交椅。
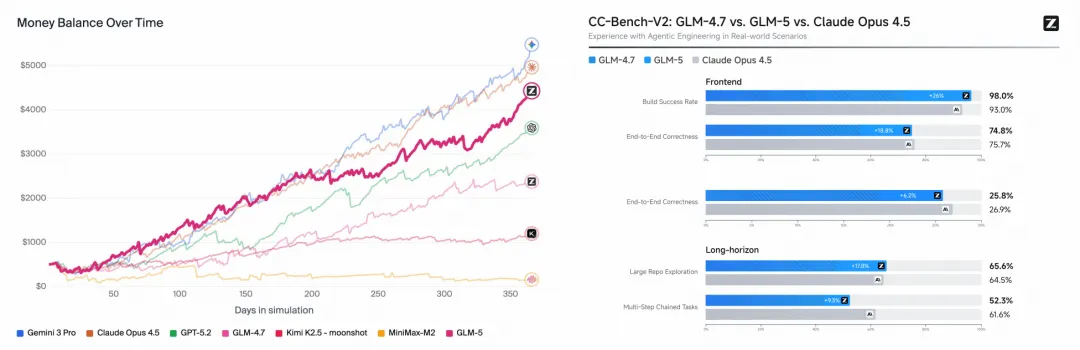
在各类复杂长周期任务的模拟较量中,GLM-5展现出极强的商业敏锐度与执行力。
无论是长达一年的自动售货机经营模拟,还是基于内部套件的代码攻坚战,它都以压倒性的优势傲视群雄。
在学术界公认的推理与编程测试集上,GLM-5依然保持着强悍的统治力。
其在复杂数学推理、多语言代码编译以及工具调用等领域的得分,不仅远超前代产品,更无限逼近了最顶尖的闭源巨头系统。
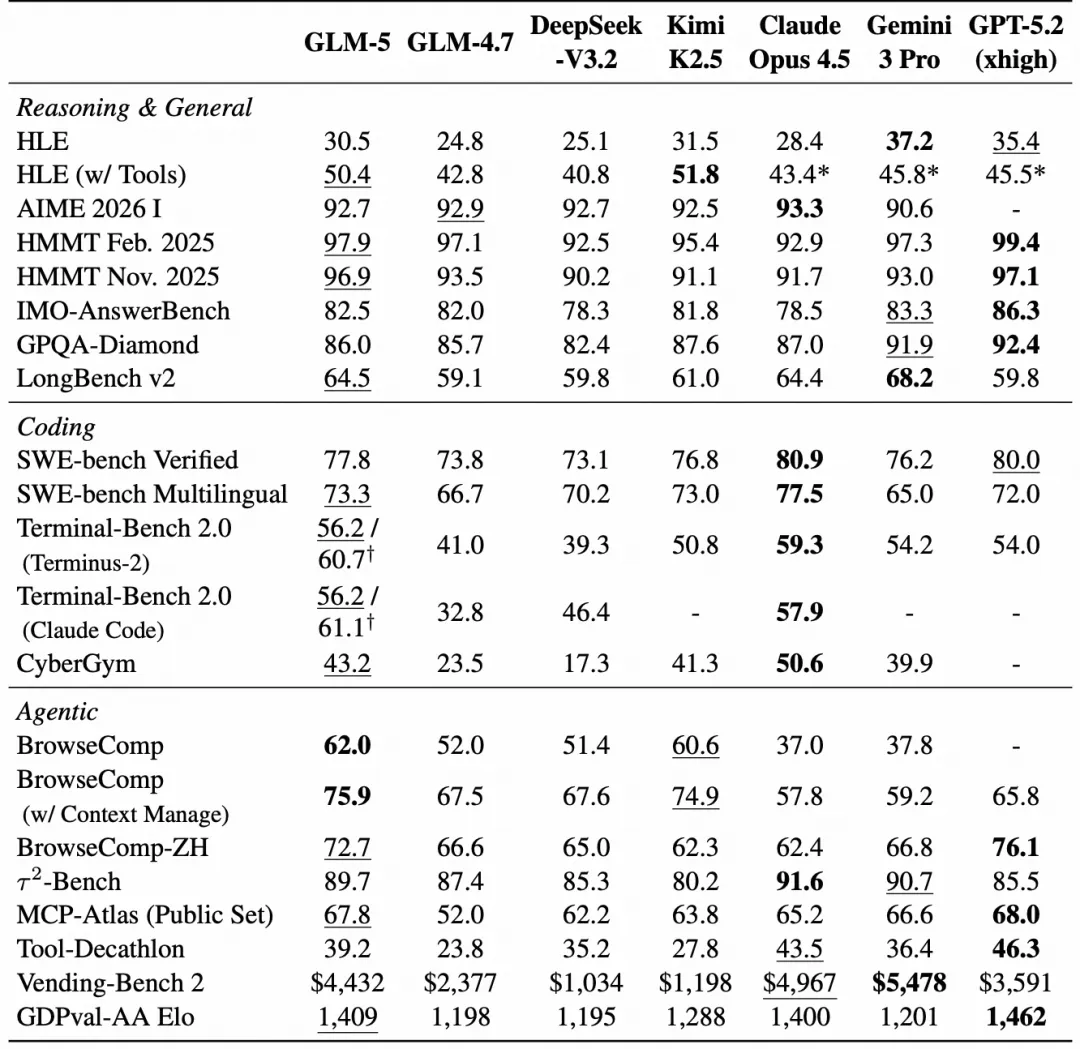
走出实验室,真实的工程考验远比静态测试残酷。
研发团队打造了CC-Bench-V2自动化评测基准。在前端应用开发中,作为裁判的智能体会亲自上手点击按钮、调整窗口,模拟真实用户的交互行为。
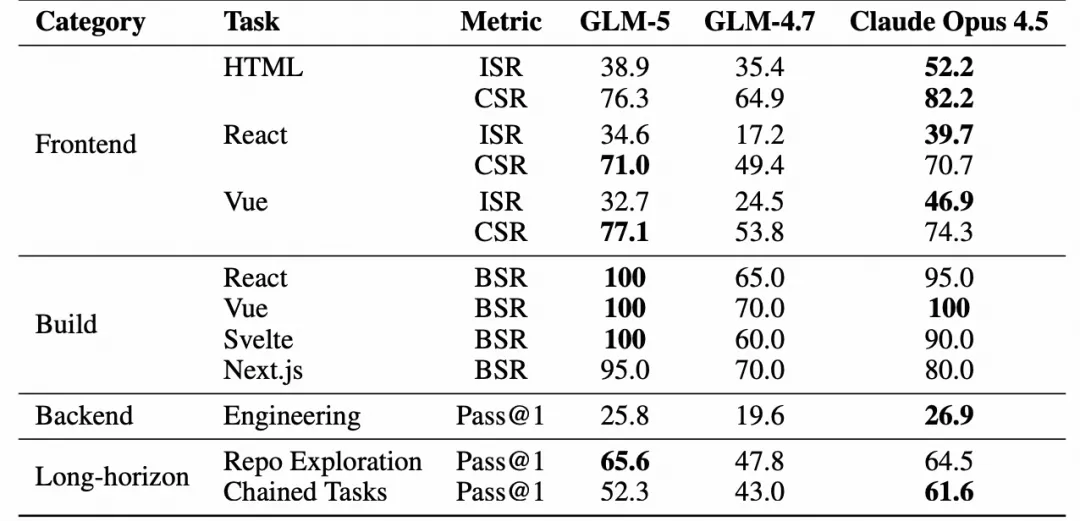
GLM-5在这里展现出了极高的代码构建成功率。
后端开发的较量同样拳拳到肉。
模型必须在真实的工程约束下,完成功能植入与缺陷修复,并完美通过每一个边界测试用例。
GLM-5在这项全有或全无的残酷考核中,交出了媲美Claude Opus 4.5的优异答卷。
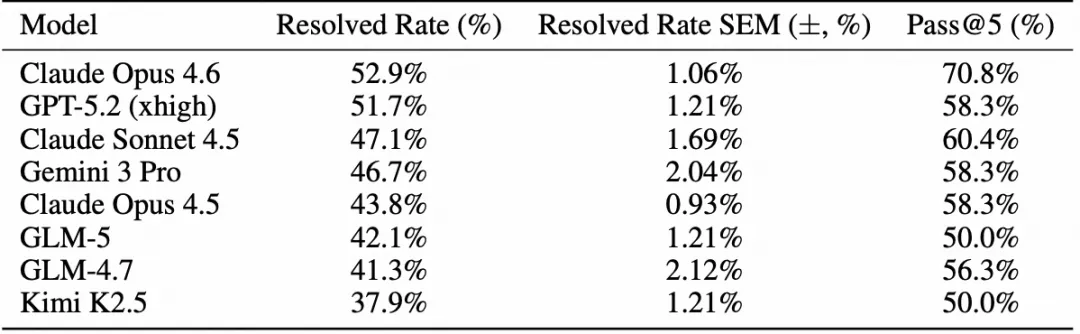
对于长程演进任务,模型化身为一名老练的工程师,在茫茫的代码海洋中精准定位关键文件,并执行一系列环环相扣的修改。动态更新的社区缺陷修复测试集,进一步印证了其解决陌生技术难题的卓越泛化水平。
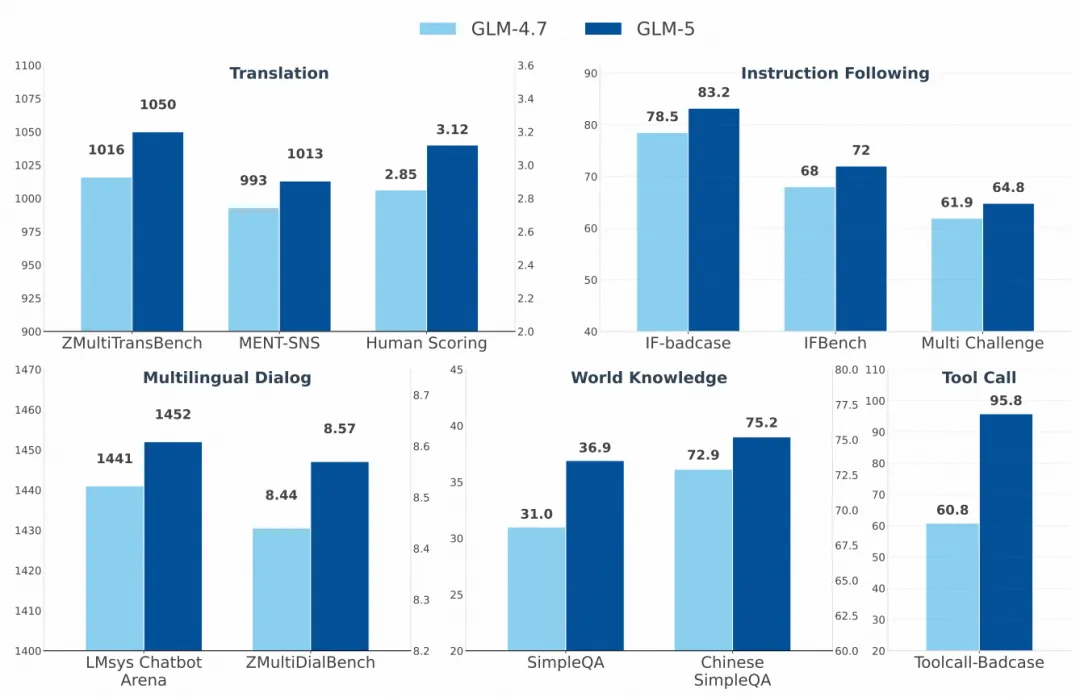
回归到广泛的用户交互场景,无论是对生僻方言的精准翻译,还是在繁杂指令下的规矩行事,亦或是解答高深莫测的世界知识百科,GLM-5都实现了全维度的跃进。
它不再是一个冷冰冰的文本处理器,而是一个充满智慧的多边形战士。
国产算力生态的普惠是GLM-5的一大里程碑。
这套庞大的模型系统原生适配了华为昇腾、寒武纪、摩尔线程、海光等七大国产芯片平台。
经过从底层内核到上层框架的极致压榨,单台国产算力节点的性能已然追平国际主流的双节点集群,长序列场景的部署成本更是直接腰斩。
GLM-5以极其优雅的稀疏架构和异步协同哲学,彻底打通了通往高能效智能体的高速公路。
参考资料:
https://arxiv.org/pdf/2602.15763

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)