用大白话讲解人工智能(18) 多模态AI:让AI同时长出“眼睛“和“耳朵“
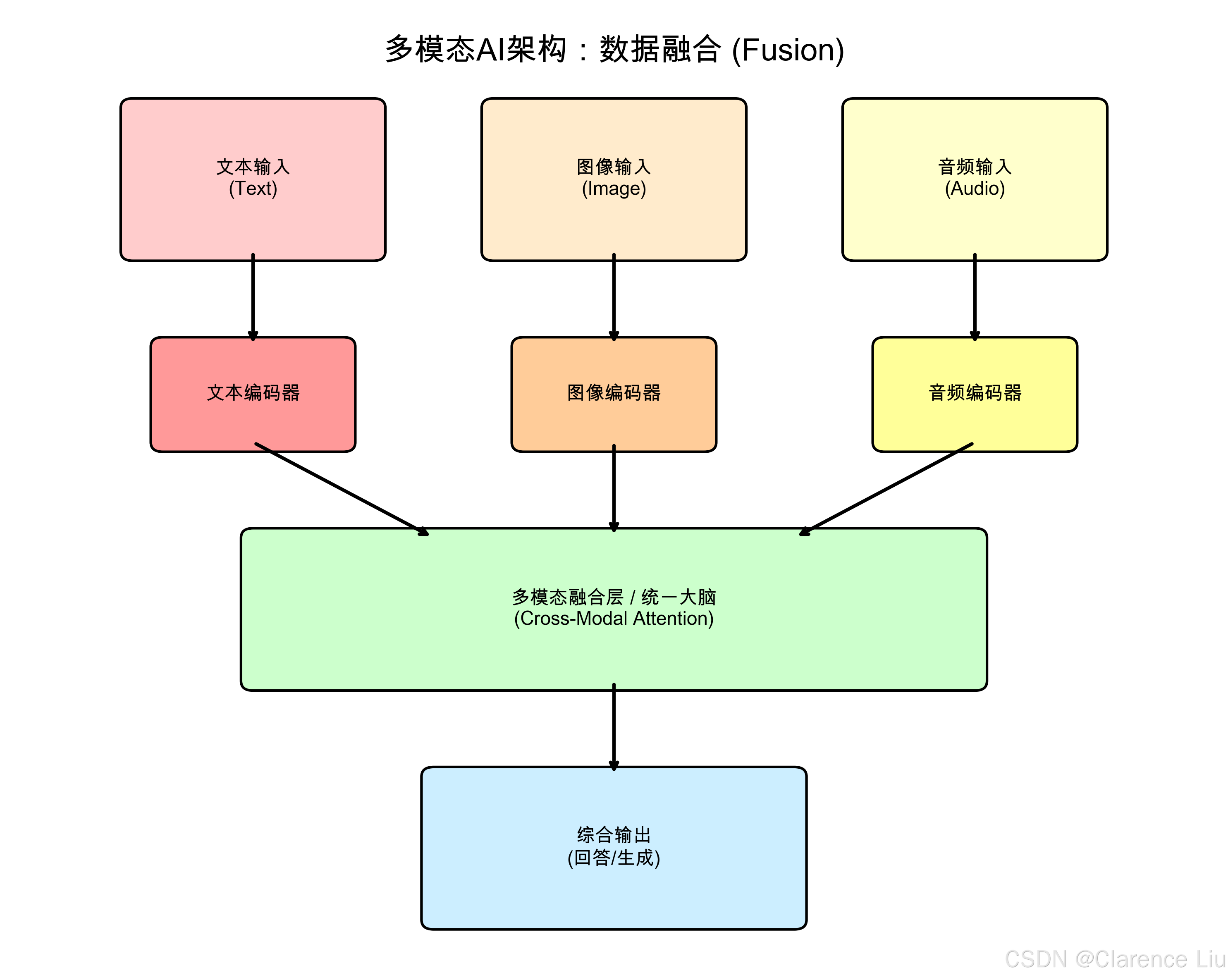
如果你和朋友聊天,你会用到哪些信息?这就叫——综合利用多种感官信息来理解世界。它们互不通气,就像盲人和聋子在交流。而**多模态AI(Multimodal AI)**的出现,打通了任督二脉,让AI能像人一样,同时处理文字、图片、音频甚至视频。
多模态AI:让AI同时长出"眼睛"和"耳朵"
什么是"多模态"(Multimodal)?
如果你和朋友聊天,你会用到哪些信息?
- 听觉:听到他的声音和语气。
- 视觉:看到他的面部表情和肢体动作。
- 文字:如果是发微信,你会看文字内容。
这就叫多模态——综合利用多种感官信息来理解世界。
但在2022年之前,AI大多是"偏科生":
- ChatGPT只会看文字(单模态)。
- 图像识别模型只会看图。
- 语音助手只会听音。
它们互不通气,就像盲人和聋子在交流。而**多模态AI(Multimodal AI)**的出现,打通了任督二脉,让AI能像人一样,同时处理文字、图片、音频甚至视频。
多模态AI的三种"超能力"
1. 以文搜图 & 图生文(CLIP技术)
以前的搜图是靠关键词匹配(图片文件名叫"cat.jpg"才能搜到猫)。
OpenAI发布的CLIP模型,把"文字"和"图片"映射到了同一个高维空间:
- 它理解"一只睡在沙发上的橘猫"这段文字的向量。
- 它也理解"橘猫睡觉照片"的向量。
- 两个向量靠得很近,所以不用打标签,AI也能直接读懂图片内容。这为后来的AI画画(DALL-E, Midjourney)奠定了基础。
2. 视觉问答(VQA)
这是GPT-4V的拿手好戏。
- 输入:发一张坏掉的自行车的照片,问"怎么修?"
- 处理:AI识别出链条掉了,结合维修知识库。
- 输出:一步步教你挂链条的图文教程。
这比单纯的文字搜索强大太多,因为它有了"眼睛"。
3. 跨模态生成
- 文生图:输入"赛博朋克风格的故宫",生成图片。
- 图生视频:上传一张静态照片,让Sora把它变成一段5秒的动态视频。
- 语音克隆:输入一段文字和你的3秒录音,AI用你的声音读出这段话。
为什么多模态这么难?
难点1:数据的"对齐"(Alignment)
文字的"苹果"和图片的"苹果"是两码事。
- 文字是逻辑符号,信息密度高。
- 图片是像素矩阵,信息密度低但噪音大。
让AI把这两者对应起来,就像教一个外星人理解"这串代码"等于"这个实物",需要海量的图文配对数据(比如几十亿张带字幕的Instagram图片)。
难点2:计算量的爆炸
处理文字可能只需要几亿个参数,处理高清视频则需要百倍的算力。视频不仅有像素,还有时间维度(动作的连贯性),对显卡是巨大的考验。
现实应用:多模态改变生活
1. 视障人士的"智能导盲犬"
Be My Eyes 等应用接入GPT-4后,视障人士只需拍照,AI就能告诉他:“面前是一瓶牛奶,保质期到明天,还有半瓶。”
2. 自动驾驶
特斯拉的FSD系统就是典型的多模态AI。它不仅看(摄像头),还听(雷达/超声波),并结合导航地图(文字/数据),综合判断"前方有救护车,需要避让"。
3. 智能教育
未来的AI老师不仅能批改作文(文字),还能看懂你画的几何题辅助线(图片),甚至听你的英语口语发音(音频),提供全方位的辅导。
小问题:多模态是通往AGI的必经之路吗?
(提示:是的。人类的智能就是建立在多感官基础上的。一个只读过书但没见过世界的"缸中之脑",很难真正理解"夕阳的壮丽"或"冰雪的寒冷"。多模态让AI接触到了真实的物理世界,是通往通用人工智能(AGI)的关键一步。)
下一篇预告:《AI Agent:从"对话框"到"智能助手"的进化》——为什么说未来的AI不再是等着回答问题,而是主动帮你买票、订餐?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)