成本监控与预算告警体系:大模型规模化应用的“财务管家”
大模型成本监控不是“事后算账”,而是“事前预防、事中控制、事后分析”的全流程管理。看得清:知道钱花在哪,花得是否合理。控得住:在成本失控前自动干预。省得下:量化优化效果,持续改进。成本可观测性,是AI规模化应用的基石。当你不再担心月底账单时,你才能更专注于用AI创造真正的业务价值。
导读:随着大模型深入业务,企业的Token消耗如滚雪球般增长——从几千到几百万,再到上亿。如果没有有效的成本监控和预算告警,月底账单可能让你大吃一惊。如何实时掌握每一分钱的去向?如何在成本飙升前自动熔断?本文将基于真实监控面板,为你拆解大模型成本监控体系的构建方法,包括实时趋势分析、服务级拆分、异常检测与熔断机制,助你实现成本的可观测、可控制、可优化。
一、引言:成本失控,是AI落地的隐形杀手
“我们只是调用了几个API,怎么月底账单5万美金?”——这是2025年不少企业踩过的坑。大模型按token计费的模式,让成本与用量直接挂钩。当业务快速增长时,成本曲线可能比用户曲线更陡峭。更危险的是,一次代码bug导致循环调用,就可能烧掉数万美元。
因此,建立一套完善的成本监控与预算告警体系,不是锦上添花,而是规模化应用的必要基础设施。它让你能:
- 实时看到钱花在哪里
- 预测月度支出,避免超预算
- 快速发现异常暴涨,自动熔断止损
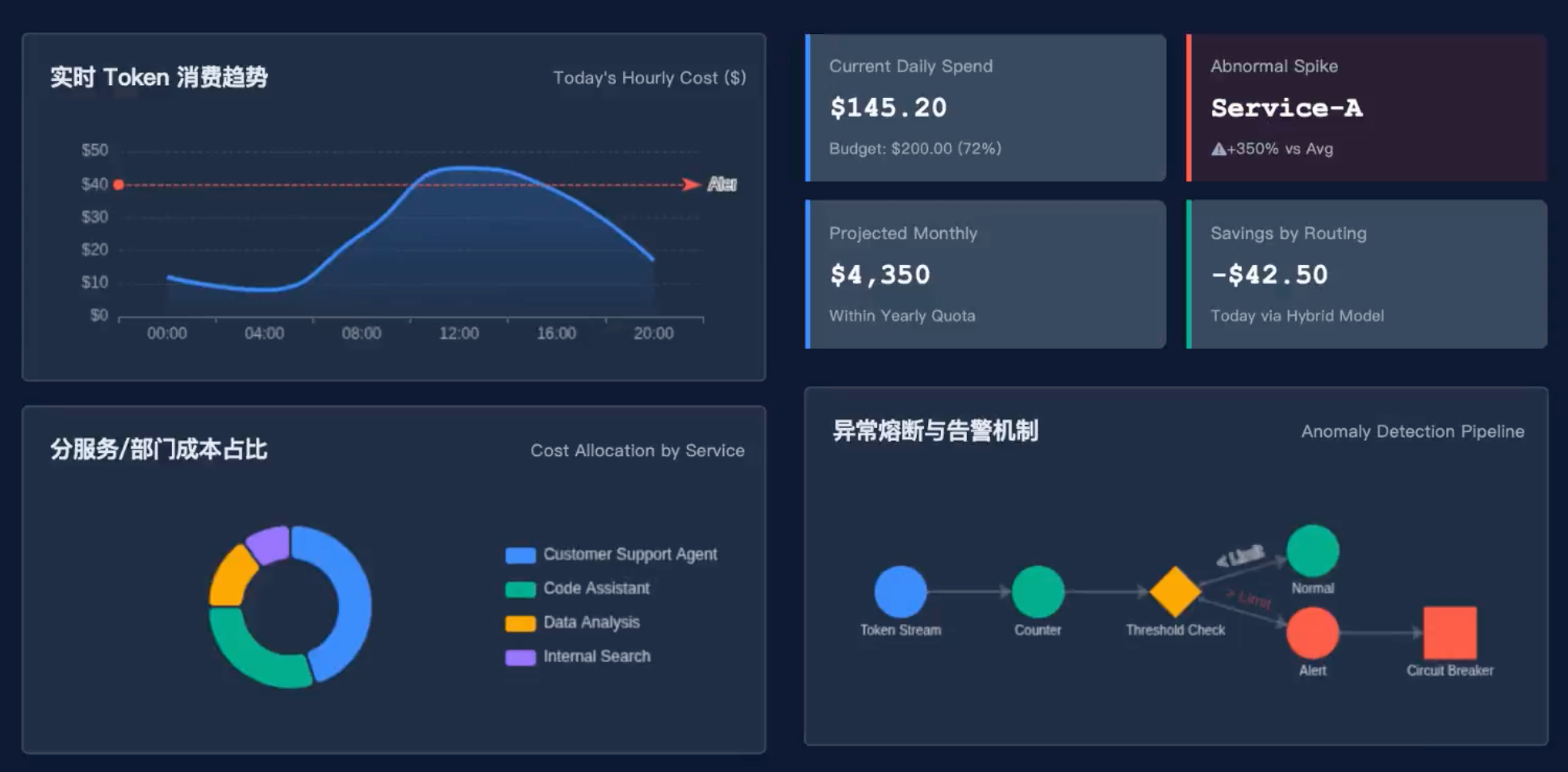
下面,我们就以图中的监控面板为例,详细拆解每一部分的设计思路和实现方法。
二、实时Token消费趋势:掌握每一小时的波动
图中的上半部分展示了一条典型的每小时成本曲线:
- 横轴:时间(00:00 到 24:00)
- 纵轴:每小时成本(美元)
- 曲线:Today‘s Hourly Cost,呈波浪形,白天高、夜晚低,符合业务规律
2.1 为什么需要实时趋势?
- 发现异常峰谷:如果某小时成本突然飙升至平时的3倍(如图中的“Abnormal Spike”标注),可能意味着有异常流量或调用逻辑错误。
- 预测月度支出:通过当前日均消耗($145.20)推算月度成本($4,350),并与年度配额对比,及时调整预算。
- 评估优化效果:图中右下角“Savings by Routing”显示当天通过混合路由节省了$42.50,说明优化措施可量化。
2.2 如何实现?
在技术层面,你需要:
- 打点统计:在每次API调用时,记录输入/输出token数、服务名、用户ID、时间戳等维度。
- 聚合计算:按小时/天聚合,乘以单价得到成本。可以使用时序数据库(如Prometheus + Thanos)或云厂商的原生监控工具。
- 可视化:用Grafana等工具绘制曲线,设置基线(如过去7天平均)作为参考。
三、分服务/部门成本占比:精细化管理的基础
图中左下角展示了成本分配饼图,将总成本按服务拆分:
- Customer Support Agent:占比最大(约45%)
- Code Assistant:次之(约30%)
- Data Analysis:约15%
- Internal Search:约10%
3.1 为什么要分服务拆分?
- 责任清晰:每个业务线或团队有自己的预算,避免相互挤占。
- 优化优先级:找到成本大头,集中精力优化。例如客服占45%,优先优化其Prompt或改用更便宜的模型。
- 内部结算:如果企业内部实行成本分摊,拆分数据是结算依据。
3.2 实现方法
在调用API时,通过标签(Tags)标记每个请求所属的服务、部门、项目。例如:
python
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[...],
user="service=customer-support,dept=after-sales"
)然后通过监控系统按标签聚合成本。云厂商通常支持在API请求中附加元数据,或者你可以在自己的日志系统中添加维度。
四、异常熔断与告警机制:自动止损的防线
图中右下角展示了异常检测流水线:
text
Token Stream → Counter → Threshold Check → Alert → Circuit Breaker这是成本监控中最关键的一环,它能防止因代码bug、恶意攻击或配置错误导致的成本爆炸。
4.1 检测流程详解
- Token Stream:所有API调用的Token消耗流式进入计数器。
- Counter:实时累加,支持滑动窗口(如最近5分钟)或固定窗口(如当前小时)。
- Threshold Check:与预设阈值对比。阈值可以是绝对数值(如单小时超过$100)或相对值(如比过去24小时平均增长300%)。
- Alert:当触发阈值时,发出告警(短信、钉钉、邮件)。
- Circuit Breaker:对于严重异常,自动熔断——停止调用,返回降级响应(如缓存答案或提示服务不可用)。
4.2 熔断策略设计
- 分级熔断:轻度超限只告警,重度超限自动熔断。
- 逐步恢复:熔断后,可设置冷却时间(如10分钟),之后尝试恢复小流量,观察是否恢复正常。
- 人工确认:关键业务可设置人工确认环节,避免误熔断影响核心服务。
4.3 示例场景
假设某服务因代码bug进入无限循环,每分钟调用100次GPT-4o,每小时成本从$5飙升到$1500。监控系统在5分钟内检测到异常增长(+350%),触发告警并自动熔断该服务的调用,避免了一天$36,000的损失。
五、实际收益:混合路由节省的成本可见
图中的“Savings by Routing”显示当天通过混合路由节省了$42.50。这个数字本身可能不大,但乘以30天,每月可节省$1,275。更重要的是,它证明了优化措施的有效性,为团队继续投入提供了数据支持。
启示:成本优化需要量化。每次改动(如调整模型、压缩Prompt、引入缓存)都应该在监控中体现,用数字说话。
六、构建成本监控体系的最佳实践
结合上述分析,我们总结一套可落地的实践指南:
6.1 多维度标签
为每次调用打上至少以下标签:
- 服务名称(service)
- 部门/团队(department)
- 模型名称(model)
- 用户类型(user_tier,如免费/付费)
- 是否缓存命中(cache_hit)
6.2 预算设置与预警
- 月度硬预算:设定不可逾越的上限,超过后自动熔断所有非核心调用。
- 软预算阈值:80%时发预警,90%时加强告警,100%时限制新调用。
- 动态基线:根据业务增长,每月调整预算。
6.3 异常检测规则
- 绝对值规则:单小时成本 > $100 → 告警
- 相对值规则:比过去24小时平均增长 > 300% → 告警并熔断
- 持续性规则:连续3小时增长 > 50% → 告警
6.4 自动化响应
- 轻量熔断:限制特定服务的并发数或调用频率。
- 降级方案:返回缓存答案、使用更便宜模型、或提示用户稍后重试。
- 通知责任人:熔断时自动创建Jira工单,分配给相关团队。
七、总结:让每一分钱都花得明白
大模型成本监控不是“事后算账”,而是“事前预防、事中控制、事后分析”的全流程管理。通过实时趋势、服务拆分、异常熔断,你可以:
- 看得清:知道钱花在哪,花得是否合理。
- 控得住:在成本失控前自动干预。
- 省得下:量化优化效果,持续改进。
图中的监控面板只是一个缩影,但它传递的核心思想是:成本可观测性,是AI规模化应用的基石。当你不再担心月底账单时,你才能更专注于用AI创造真正的业务价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)