Keepalived
高可用集群(High Availability Cluster, HA Cluster)是一组通过软件或硬件方式连接在一起的计算机(节点),它们协同工作,确保即使部分节点发生故障,整个系统仍然能够持续提供服务,从而最大限度地减少停机时间。核心目标消除单点故障(Single Point of Failure, SPOF)实现服务的7×24小时不间断运行类型核心目标典型场景代表技术负载均衡(LB)流量
目录
3.2 场景一:Keepalived + LVS(传统用法)
3.3 场景二:Keepalived + Nginx/HAProxy(现代用法)
1 高可用集群基础
1.1 什么是高可用集群
高可用集群(High Availability Cluster, HA Cluster) 是一组通过软件或硬件方式连接在一起的计算机(节点),它们协同工作,确保即使部分节点发生故障,整个系统仍然能够持续提供服务,从而最大限度地减少停机时间。
核心目标:
-
消除单点故障(Single Point of Failure, SPOF)
-
实现服务的 7×24小时不间断运行
1.2 集群类型概述
| 类型 | 核心目标 | 典型场景 | 代表技术 |
|---|---|---|---|
| 负载均衡(LB) | 流量分发、横向扩展 | Web入口、API网关 | LVS、Nginx、HAProxy |
| 高可用(HA) | 消除单点故障、服务连续性 | 数据库、核心服务 | Keepalived、Pacemaker |
| 高性能(HPC) | 计算密集型任务并行处理 | 科学计算、AI训练 | MPI、Slurm |
实际应用:生产环境常组合使用,如 LB + HA 实现既扩展又高可用。
1.3 系统可用性指标(SLA)
SLA:Service-Level Agreement 服务等级协议(提供服务的企业与客户之间就服务的品质、水准、性能
等方面所达成的双方共同认可的协议或契约)
| 可用性级别 | 年停机时间 | 描述 |
|---|---|---|
| 99%(两个9) | 3.65天 | 基本可用 |
| 99.9%(三个9) | 8.76小时 | 较高可用 |
| 99.99%(四个9) | 52.6分钟 | 高可用 |
| 99.999%(五个9) | 5.26分钟 | 极高可用(电信级) |
计算公式:
可用性(A) = MTBF / (MTBF + MTTR) MTBF:平均故障间隔时间(Mean Time Between Failures) MTTR:平均修复时间(Mean Time To Repair)
1.4 高可用机制
提升系统高用性的解决方案:降低MTTR- Mean Time To Repair(平均故障时间)
1.4.1 单点故障(SPOF)
定义:系统中一旦故障会导致整体失效的组件。
解决思路:冗余 + 自动化故障转移。
🔭建立用于机制:
active、passive(主、备)
active --> HEARTBEAT --> passive
active、active(双主)
active <--> HEARTBEAT <--> active
1.4.2 核心机制
| 机制 | 说明 | 作用 |
|---|---|---|
| 心跳检测 | 节点间周期性健康检查 | 发现故障 |
| 故障转移(Failover) | 主节点故障时,备节点接管 | 保证服务连续性 |
| 虚拟IP(VIP) | 对外提供统一入口,可漂移 | 屏蔽后端变化 |
| 脑裂防护 | 避免网络分区导致双主冲突 | 数据一致性保障 |
1.5 系统故障
硬件故障:设计缺陷、wear out(损耗)、非人为不可抗拒因素。
软件故障:设计缺陷 bug。
2 Keepalived
2.1 Keepalived 概述
2.1.1 发展历程
| 阶段 | 说明 |
|---|---|
| 初期 | 专为 LVS 设计,管理并监控 LVS 集群各节点状态 |
| 发展 | 加入 VRRP 功能,成为通用高可用软件 |
| 现状 | 可独立使用,为各类服务(Nginx、HAProxy、MySQL等)提供高可用保障 |
Keepalived 原生设计目的是管理 LVS/IPVS集群服务,高可用功能(VRRP)是后续扩展。
核心转变:从"管理别人的高可用" → "自己实现高可用" → "通用高可用工具"
2.1.2 核心能力
-
VRRP 实现:VIP 漂移、主备选举
-
健康检查:TCP、HTTP、脚本方式检测服务状态
-
LVS 集成:直接管理 IPVS 规则(可选功能)
2.2 VRRP 协议原理
VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议),RFC 3768 定义,是 Keepalived 的核心基础,解决静态网关单点风险。
2.2.1 核心概念
核心术语:
| 术语 | 说明 |
|---|---|
| 虚拟路由器(Virtual Router) | 由一个 Master 和多个 Backup 组成的逻辑路由单元,对外表现为单一网关 |
| 虚拟路由器标识(VRID) | 唯一标识虚拟路由器,范围 0-255,同一广播域内不同 VRRP 组 VRID 必须唯一 |
| VIP | 虚拟 IP 地址,对外提供服务的统一入口,可随 Master 切换而漂移 |
| VMAC | 虚拟 MAC 地址,格式为 00-00-5e-00-01-{VRID},用于响应 ARP 请求 |
| 物理路由器 | 运行 VRRP 的实际物理设备或虚拟机,即 Master 或 Backup 节点 |
| Master | 主设备,持有 VIP 和 VMAC,实际转发数据包,周期性发送通告 |
| Backup | 备用设备,监听 Master 状态,Master 故障时抢占成为新 Master |
| Priority | 优先级,范围 0-255(默认 100),数值越大优先级越高,用于 Master 选举 |
特殊优先级值:
255:保留给 IP 地址拥有者(即 VIP 绑定在物理接口上的节点),该节点永远成为 Master
0:表示当前 Master 主动放弃地位,触发立即重新选举
相关技术:
| 技术项 | 说明 |
|---|---|
| 通告(Advertisement) | VRRP 心跳机制,Master 周期性组播 VRRP 报文(默认间隔 1 秒),包含优先级、VRID 等信息;Backup 据此判断 Master 状态 |
| 工作方式 | 抢占式(默认):高优先级 Backup 或恢复的 Master 立即夺回 VIP;非抢占式:即使优先级高也不抢占,避免频繁切换 |
| 安全认证 | 无认证:默认,依赖网络隔离保障安全;简单字符认证:预共享明文密钥(不推荐,易截获);MD5 认证:基于 HMAC-MD5 的强认证(RFC 3768 支持) |
2.2.2 工作流程
-
初始化:各节点根据优先级竞选 Master,优先级 255 的节点直接成为 Master,否则比较优先级,高者胜;相同则比 IP。
-
Master 职责:绑定 VIP 和 VMAC(00-00-5e-00-01-VRID)、周期性组播 VRRP 通告(224.0.0.18)、响应 ARP 请求,转发数据包。
-
Backup 职责:监听 VRRP 通告,重置超时计时器、超时未收到(默认 3×advert_int)、认为 Master 故障,触发选举。
-
切换过程:新 Master 绑定 VIP 和 VMAC,发送 gratuitous ARP,更新交换机 MAC 表,流量无缝切换到新节点,客户端无感知。
2.2.3 抢占模式
| 模式 | 说明 | 适用场景 |
|---|---|---|
| 抢占模式(默认) | Master 恢复后重新夺回 VIP | 固定主节点场景 |
| 非抢占模式 | Master 恢复后保持 Backup,不抢回 VIP | 避免频繁切换 |
注意:
nopreempt只在 Backup 状态 生效,初始状态为 MASTER 的节点首次仍会抢占。
2.3 Keepalived 架构组件
2.3.1 核心组件
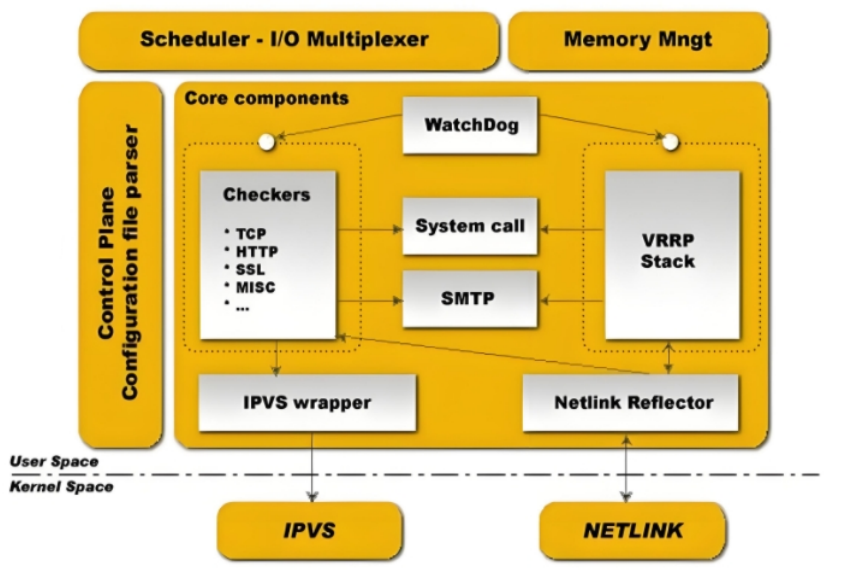
| 组件 | 中文含义 | 功能说明 |
|---|---|---|
| WatchDog | 看门狗定时器 | 监控 Keepalived 父进程状态,若父进程异常退出,则重启整个 Keepalived 进程,防止自身僵死 |
| Checkers | 健康检查器 | 对后端真实服务器(RS)进行健康检测,支持 TCP、HTTP、SSL、MISC(脚本)等多种检测方式 |
| VRRP Stack | VRRP 协议栈 | 实现 VRRP 协议的核心模块,处理 Master/Backup 选举、VIP 漂移、状态切换 |
| IPVS Wrapper | IPVS 包装器 | 与内核 IPVS 模块交互,动态添加/删除 LVS 的虚拟服务器和真实服务器规则 |
| Netlink Reflector | Netlink 反射器 | 通过 Netlink 套接字与内核通信,监听和设置网络接口状态、VIP 绑定/解绑 |
| Scheduler | I/O 多路复用调度器 | 基于 epoll/select 的事件驱动核心,调度所有组件的异步 I/O 操作 |
| Memory Mngt | 内存管理器 | 自定义内存池管理,减少频繁 malloc/free 带来的性能开销和内存碎片 |
| Control Plane | 控制平面/配置解析器 | 解析 keepalived.conf 配置文件,管理各组件生命周期,提供运行时控制接口 |
| System call | 系统调用接口 | 封装底层系统调用,为 Checkers 和 VRRP Stack 提供文件操作、进程控制等能力 |
| SMTP | 邮件通知模块 | 当状态发生切换(Master/Backup/Fault)时,发送告警邮件给管理员 |
2.4 配置文件
2.4.1 相关文件
-
软件包名:keepalived
-
主程序文件:/usr/sbin/keepalived
-
主配置文件:/etc/keepalived/keepalived.conf
-
配置文件示例:/usr/share/doc/keepalived/
-
Unit File:/lib/systemd/system/keepalived.service
-
Unit File的环境配置文件:/etc/sysconfig/keepalived
RHEL7中可能会遇到一下bug,RHEL9中无此问题
systemctl restart keepalived # 新配置可能无法生效 systemctl stop keepalived;systemctl start keepalived # 无法停止进程,需要 kill 停止
2.4.2 配置文件结构
配置文件:/etc/keepalived/keepalived.conf
配置文件组成:
-
GLOBAL CONFIGURATION
-
Global Definitions:全局配置(日志、邮件、route_id、vrrp配置、多播地址等)。
-
-
VRRP CONFIGURATION
-
VRRP Script Definitions:自定义检查脚本。
-
VRRP Instance Definitions:定义每个VRRP虚拟路由器实例(核心)
-
-
LVS CONFIGURATION
-
Virtual server group(s)
-
Virtual server(s):LVS集群的VS和RS。
-
2.4.3 配置语法说明
#检测配置文件语法 [root@KA1 ~]# keepalived -t -f /etc/keepalived/keepalived.conf
全局配置
# /etc/keepalived/keepalived.conf
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
# keepalived 发生故障切换时邮件发送的目标邮箱,可以按行区分写多个
5 acassen@firewall.loc
6 failover@firewall.loc
7 sysadmin@firewall.loc
8 }
9 notification_email_from Alexandre.Cassen@firewall.loc # 发邮件的地址
10 smtp_server 192.168.200.1 # 邮件服务器地址
11 smtp_connect_timeout 30 # 邮件服务器连接timeout
12 router_id LVS_DEVEL # 每个keepalived主机唯一标识,建议使用当前主机名,但多节点重名不影响
13 vrrp_skip_check_adv_addr # 对所有通告报文都检查,会比较消耗性能,启用此配置后,如果收到的通告报文和上一个报文是同一个路由器,则跳过检查,默认值为全检查.
14 vrrp_strict # 严格遵循vrrp协议,启用此项后以下状况将无法启动服务:1.无VIP地址、2.配置了单播邻居、3.在VRRP版本2中有IPv6地址,建议不加此项配置。
15 vrrp_garp_interval 0 # 免费ARP(Gratuitous ARP)报文时间间隔;免费ARP用于通知网络中其他设备,某IP地址对应的 MAC 地址发生了变化;帮助网络设备更新 ARP 缓存,确保数据能正确转发到新的主节点。
16 vrrp_gna_interval 0 # 用于配置发送 Gratuitous NA(免费邻居通告)报文的时间间隔;通知网络中其他设备,某 IPv6地址对应的链路层地址(MAC地址)发生了变化;帮助网络设备更新邻居缓存(NeighborCache)确保 IPv6 数据包能正确转发到新的主节点。
17 vrrp_mcast_group4 224.0.0.44 # 指定组播IP地址范围
18 }
配置虚拟路由器
# /etc/keepalived/keepalived.conf
19 vrrp_instance VI_1 {
20 state MASTER
21 interface eth0 # 绑定为当前虚拟路由器使用的物理接口,如:eth0,可以和VIP不在一个网卡
22 virtual_router_id 51 # 每个虚拟路由器惟一标识,范围:0-255,每个虚拟路由器此值必须唯一,否则服务无法启动;同属一个虚拟路由器的多个keepalived节点必须相同,务必要确认在同一网络中此值必须唯一。
23 priority 100 # 当前物理节点在此虚拟路由器的优先级,范围:1-254,值越大优先级越高,每个keepalived主机节点此值不同。
24 advert_int 1 # vrrp通告的时间间隔,默认1s
25 authentication { # 认证机制
26 auth_type PASS|HA # AH为IPSEC认证(不推荐),PASS为简单密码(建议使用)
27 auth_pass 1111 # 预共享密钥,仅前8位有效,同一个虚拟路由器的多个keepalived节点必须一样
28 }
29 virtual_ipaddress { # 虚拟IP,生产环境可能指定上百个IP地址
# <IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL>
30 192.168.200.16 # 指定VIP,不指定网卡,默认为eth0,注意:不指定/prefix,默认32
31 192.168.200.17/24 dev eth1
32 192.168.200.18/24 dev eth2 label eth2:1
33 }
34 accept # 开启vip 对外响应ping包,注意此处功能需要关闭vrrp_strict,默认使用nftab策略禁用ping包响应,nft list ruleset 显示策略中即可看到。
35 }
启用keepalived日志功能
# /etc/sysconfig/keepalived KEEPALIVED_OPTIONS="-D -S 6" # 日志级别为0-7
实现独立子配置文件
当生产环境复杂时, /etc/keepalived/keepalived.conf 文件中内容过多,不易管理。
将不同集群的配置,比如:不同集群的VIP配置放在独立的子配置文件中利用include指令可以实现包含子配置文件。
一般include指令放在global_defs模块之后。
2.5 实践
3 Keepalived 高可用实现
3.1 模式选择
keepalived模式推荐:
| 场景 | 推荐模式 | 能否双主 | 原因 |
|---|---|---|---|
| Keepalived + Nginx | 双主 | 适合 | Nginx 无状态,两个 VIP 可以独立服务不同业务或分担流量 |
| Keepalived + LVS | 可以双主,但通常单主 | 技术上可以 | LVS Director 本身无状态,但 LVS 集群通常追求极致性能,双主增加复杂度 |
| Keepalived + HAProxy | 双主 | 适合 | 与 Nginx 类似,无状态,双主可分担 |
| Keepalived + 数据库 | 单主 | 强烈不建议 | 数据库有状态,双主会导致脑裂、数据不一致 |
Keepalived + LVS为什么通常不做双主?
| 原因 | 说明 |
|---|---|
| 性能已足够 | 单台 LVS Director 可支持 百万级并发,很少需要双主分担 |
| 复杂度增加 | 需要维护两套 IPVS 规则,RS 需要配置两个 VIP 的 ARP 抑制 |
| 一致性风险 | 两个 Director 的转发规则如果配置不一致,会导致问题 |
| 运维习惯 | LVS 场景通常是 "一主一备" 的思维定式 |
使用双主场景:超大规模集群,单机性能瓶颈;多业务隔离,不同业务走不同 VIP;多机房部署,每个机房一个 VIP。
使用主备场景:
核心系统,稳定性优先-->银行核心交易、支付系统、电信计费
有状态服务(数据库、缓存)-->MySQL、Redis、MongoDB、Elasticsearch
配置复杂,难以保持一致-->HAProxy 规则复杂、Nginx 配置多变
资源充足,不需要压榨备机-->企业内部系统、中小型项目
网络分区风险高的环境-->跨机房、网络不稳定、云环境
维护窗口需要快速切换-->计划内维护、升级、配置变更
异构硬件或软件版本-->新旧服务器混用、灰度升级
比较:
| 特性 | 主备模式(Active-Standby) | 双主模式(Active-Active) |
|---|---|---|
| 资源利用率 | 50%(备机空闲) | 100%(两机都工作) |
| 复杂度 | 低 | 高 |
| 故障域 | 单一 | 多个 |
| 切换频率 | 低 | 可能较高 |
| 配置一致性 | 只需维护一份 | 需维护两份,保持一致 |
| 适用场景 | 核心系统、有状态服务、简单场景 | 高性能需求、多业务隔离 |
3.2 场景一:Keepalived + LVS(传统用法)
架构:Keepalived 同时承担 HA + LB 双重角色
特点:
-
Keepalived 管理 IPVS 规则,自动添加/删除后端 RS
-
同时保证 Director 自身高可用
3.3 场景二:Keepalived + Nginx/HAProxy(现代用法)
架构:Keepalived 只负责 HA,Nginx 负责 LB/反向代理
这是目前更常见的用法,Nginx 七层代理能力比 LVS 更灵活。
配置要点:
-
Nginx 本身不做集群,各自独立运行相同配置
-
Keepalived 只检测 Nginx 进程,实现 VIP 漂移
-
需要配合脚本检测 Nginx 状态(非简单进程检测)
3.4 场景三:数据库高可用
| 数据库 | 方案 | 说明 |
|---|---|---|
| MySQL | Keepalived + MySQL 主从 | VIP 漂移实现主库切换(配合半同步复制) |
| Redis | Keepalived + Redis Sentinel | Sentinel 做主从切换,Keepalived 保 Sentinel 高可用 |
| PostgreSQL | Keepalived + Patroni | Patroni 管理流复制,Keepalived 提供 VIP |
注意:数据库 HA 更关注 数据一致性,Keepalived 仅解决入口漂移,需配合复制机制。
3.5 实践
3.6 其他高可用方案对比
3.6.1 Pacemaker + Corosync
| 特性 | 说明 |
|---|---|
| 定位 | 通用集群资源管理器,不限于 VIP 漂移 |
| 能力 | 管理数据库、文件系统、服务等复杂资源 |
| 复杂度 | 配置复杂,学习曲线陡峭 |
| 适用 | 企业级复杂集群、需要 STONITH 的场景 |
与 Keepalived 对比:
-
Keepalived:轻量、专注 VIP + 健康检查、易配置
-
Pacemaker:重量级、资源管理全面、支持更多场景
3.6.2 云原生高可用方案
| 方案 | 特点 |
|---|---|
| Kubernetes | Pod 自动重启、多副本、Ingress LB,平台级 HA |
| 云服务 SLB | AWS ALB/NLB、阿里云 SLB,托管免运维 |
| 服务网格 | Istio 自动处理服务故障转移、流量管理 |
3.6.3 方案选型建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 小型 Web 集群 | Keepalived + Nginx | 轻量、稳定、易维护 |
| 大型 LVS 集群 | Keepalived + LVS | 四层高性能转发 |
| 复杂企业应用 | Pacemaker + Corosync | 资源管理更全面 |
| 云环境 | 云厂商 SLB 或 K8s | 免运维、弹性扩展 |
| 数据库集群 | 专用方案(MHA、Patroni) | 数据一致性优先 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)