黑马大模型RAG与Agent智能体实战教程LangChain提示词——37(附)、RAG项目(服装商品智能客服)——在线流程代码架构讲解(VectorStoreService、RagService)
文章目录
引言:这是一套怎样的 RAG 在线流程?
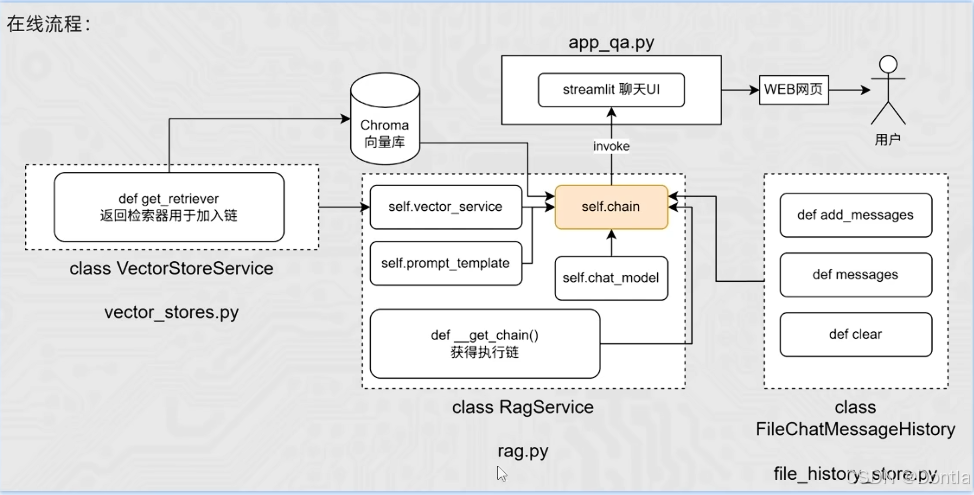
这张图展示的是一个 服装商品智能客服(RAG 问答系统) 从「用户在网页上提问」,到「系统返回答案」整个在线链路的架构。
核心思想是:用向量数据库 + 大模型,把你自己的服装知识库变成一个能实时问答的智能客服。
下面我会按模块,从左到右、从下到上,讲清楚每一块的职责和它们之间是怎么串起来的。
一、整体视角:从用户到答案的一条链
从用户视角看流程:
- 用户在网页上输入问题(比如:“这件羽绒服可以机洗吗?”)
- 前端页面把问题发给后端应用
app_qa.py app_qa.py调用 RagService(rag.py),让它去“想办法”回答:- 先去 向量库 Chroma 找到和问题最相关的服装知识片段
- 把这些片段 + 用户问题组织成提示词模版(prompt)
- 调用 聊天大模型 生成最终回答
- 系统通过 会话历史模块 保留上下文,让聊天更连贯
- 答案返回给用户的浏览器页面 展示出来
也就是说:UI 负责“问”和“展示”,RagService 负责“查”和“想”,向量库负责“记忆”,会话历史负责“上下文”。
二、左侧:向量库与 VectorStoreService
1. Chroma 向量库
- Chroma 是一个本地/嵌入式的向量数据库,用来存储你服装知识库里的每一段文本(比如商品介绍、洗护说明、尺码建议等)的向量表示。
- 当用户提问时,会把问题也转成向量,然后在这里做相似度检索,找到最相关的几段内容。
你可以把 Chroma 理解为:一个按“语义相似”来查找内容的搜索引擎。
2. class VectorStoreService(vector_stores.py)
VectorStoreService 是对 Chroma 的一层封装,图中最关键的是这个方法:
def get_retriever:返回检索器(retriever)用于加入到链中- 它内部会:
- 连接或初始化 Chroma 向量库
- 配置检索参数,如:一次取回多少条、相似度阈值等
- 返回一个 retriever 对象,供 RAG 处理链使用
- 它内部会:
在后面的链式调用里,RagService 不直接和 Chroma 打交道,而是通过 VectorStoreService.get_retriever() 获取“检索能力”,实现模块解耦。
三、中间:核心大脑 RagService(rag.py)
中间虚线框是整个系统的“大脑”,名为 class RagService。
它的任务是:把“检索能力 + 大模型 + Prompt 模版”组装成一个可调用的执行链 self.chain。
1. 关键成员:self.vector_service
- 在
RagService初始化时,会创建或接收一个VectorStoreService实例,通常保存在:self.vector_service
- 后续获取 retriever 时,就是通过
self.vector_service.get_retriever()完成的。
意义:RagService 不关心底层用的是 Chroma 还是别的向量库,只要 VectorStoreService 提供统一接口即可,便于后续替换/扩展。
2. Prompt 模版:self.prompt_template
self.prompt_template定义了给大模型的“提示词结构”,通常包括:- 系统角色说明(你是一个服装商品客服助手……)
- 插入检索到的知识片段(context)
- 插入用户当前问题(question)
- 一些格式或行为要求(语言风格、是否引用来源等)
示例思路(伪代码):
self.prompt_template = """
你是一个专业的服装商品客服助手,以下是与问题相关的知识片段:
{context}
请根据上述信息,用通俗、准确的语言回答用户问题:
{question}
"""
意义:Prompt 模版是“大脑说话的思路”,保证回答风格统一、可控。
3. 聊天模型:self.chat_model
self.chat_model通常是一个大语言模型接口,比如 OpenAI、通义千问、本地 LLM 等。- RagService 会把构造好的 Prompt 发给它,由它生成回答文本。
在代码上看,它一般是某个 LLM 类的实例,比如:
self.chat_model = ChatOpenAI(...) # 或其它模型
4. 执行链:self.chain 与 __get_chain()
图中黄色高亮的就是:self.chain,它是 RagService 核心成果。
def __get_chain():获取执行链- 内部会做大致几件事:
- 调用
self.vector_service.get_retriever()拿到 retriever - 把 retriever(检索)、
self.prompt_template(模版)、self.chat_model(大模型)组装起来 - 形成一个“端到端”可调用的链(Chain):只要给它一个问题,它就会先检索,再补全 Prompt,最后调用 LLM 生成结果。
- 调用
- 内部会做大致几件事:
最终:
self.chain就是这个执行链的实例app_qa.py只需要调用self.chain.invoke(用户问题)即可,不必关心内部细节
你可以把 self.chain 想象成一个“黑盒函数”:
输入:用户问题 + (会话上下文)
输出:智能客服的自然语言回答
四、右侧:会话历史 FileChatMessageHistory(file_history_store.py)
右侧虚线框是会话历史模块,类名为:
class FileChatMessageHistory(file_history_store.py)
它的职责是:把和某个用户的聊天历史,持久化到文件中,以便每次调用链时可以加载上下文,让对话更连贯。
图中列出了几个核心方法:
def add_messages:向当前会话追加一条新消息(用户/助手)def messages:读取当前会话的所有消息列表def clear:清空当前会话的历史记录(比如“重新开始会话”按钮)
有了它,系统可以做到:
- 记住用户之前问过“这条裤子是高腰还是中腰?”
- 后面用户再问“那它适合冬天穿吗?”时,模型还能理解“它”指的是哪条裤子
通常,在 RAG 链中,会把 messages 里的历史内容也注入到 Prompt 中,或者作为多轮对话输入给 Chat 模型。
五、顶部:app_qa.py 与 Web 聊天界面
最上方是系统的入口应用:
app_qa.py:使用 Streamlit 搭建的聊天 UI- 它负责:
- 渲染一个网页聊天窗口(类似微信聊天框)
- 接收用户输入的问题
- 把问题传给 RagService 的
self.chain(通常通过invoke()调用) - 将大模型的回答显示在对话框中
流程可以理解为:
- 用户在浏览器访问 Streamlit 页面
- 页面上有一个输入框 + 发送按钮
- 用户输入问题 →
app_qa.py接收 → 调用rag_service.chain.invoke() - 得到回答后,通过 Streamlit 把文本显示在聊天记录中
本质上:app_qa.py 把复杂的 RAG 能力“封装成一个网页聊天机器人”。
六、模块之间是如何协同工作的?
综合整个架构图,从左到右串起来的执行过程可以概括为:
-
前端聊天 UI(
app_qa.py+ 浏览器)- 接收用户输入
- 把问题传给 RagService
-
RagService(
rag.py)- 通过
self.vector_service.get_retriever()拿到检索器 - 根据用户问题从 Chroma 中检索相关服装知识
- 把检索结果 + 用户问题 + 会话历史,填入
self.prompt_template - 调用
self.chat_model生成答案 - 返回结果给
app_qa.py
- 通过
-
FileChatMessageHistory(
file_history_store.py)- 记录每一轮的用户消息和模型回答
- 下次用户提问时,RagService 可以将历史作为上下文使用
-
VectorStoreService(
vector_stores.py)- 隐藏 Chroma 的具体操作细节
- 对外只暴露“获取 retriever”的接口,使得 RAG 链的其它部分更简洁
整体上形成了一条清晰的流水线:
UI → RagService → VectorStoreService / Chroma → ChatModel → UI
再加上旁路的 FileChatMessageHistory 来维护会话上下文。
七、这个架构有哪些优点?
-
模块清晰、职责单一
- 存储、检索、RAG 逻辑、会话历史、UI 各自独立,易于维护与扩展。
-
易于替换与扩展
- 想换向量库?只需要改
VectorStoreService。 - 想换大模型?只需替换
self.chat_model初始化部分。 - 想增加新的 Prompt 策略?只改
self.prompt_template和链构建逻辑即可。
- 想换向量库?只需要改
-
天然支持多轮对话
FileChatMessageHistory让系统拥有“记忆”,回答更加贴合用户上下文,而不是一问一答的冷冰冰机器人。
-
适合业务落地
- 对于服装电商场景,可以提前把商品介绍、洗护指南、搭配建议等全部放入向量库,用户就像在和一个“超级懂你店里所有衣服”的店员聊天。
八、结语:如何理解这张图?
如果你再回头看这张在线流程图,可以带着下面这句话去理解:
左边是“记忆”(向量库),中间是“思考”(RagService + 大模型),右边是“记住对话”(会话历史),上面是“和用户对话的嘴巴”(Streamlit Web UI)。
当你理解了这四个角色之间的关系,这张图其实就在讲一个非常简单的故事:
“我有一本关于服装的知识书(向量库),有个会思考的大脑(大模型),我让它每次回答前先翻书(检索),再结合之前的聊天记录(历史),通过网页和顾客对话(UI),于是就诞生了一个真正懂服装的智能客服。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献433条内容
已为社区贡献433条内容

所有评论(0)