Chatbox添加知识库全流程指南
本文介绍了三种企业知识库构建方案:1)本地部署方案(Ollama+Chatbox),强调数据安全;2)云端API集成方案(CherryStudio/Confluence),适合企业级管理;3)混合模式,平衡安全与效率。详细说明了核心配置要点,包括模型选择(nomic-embed-text/bge-m3)、文档处理策略及性能优化方法。针对常见问题提供解决方案,如检索相关性低、响应速度慢等。最后根据不
·
一、核心方法与步骤
1. 本地部署方案(数据安全优先)
- 环境配置:
- 安装Ollama(通过命令行运行
ollama run deepseek-r1:8b或ollama pull qwen3-embedding:8b)。 - 在Chatbox设置中选择“Ollama”作为模型提供方,API地址填
http://localhost:11434。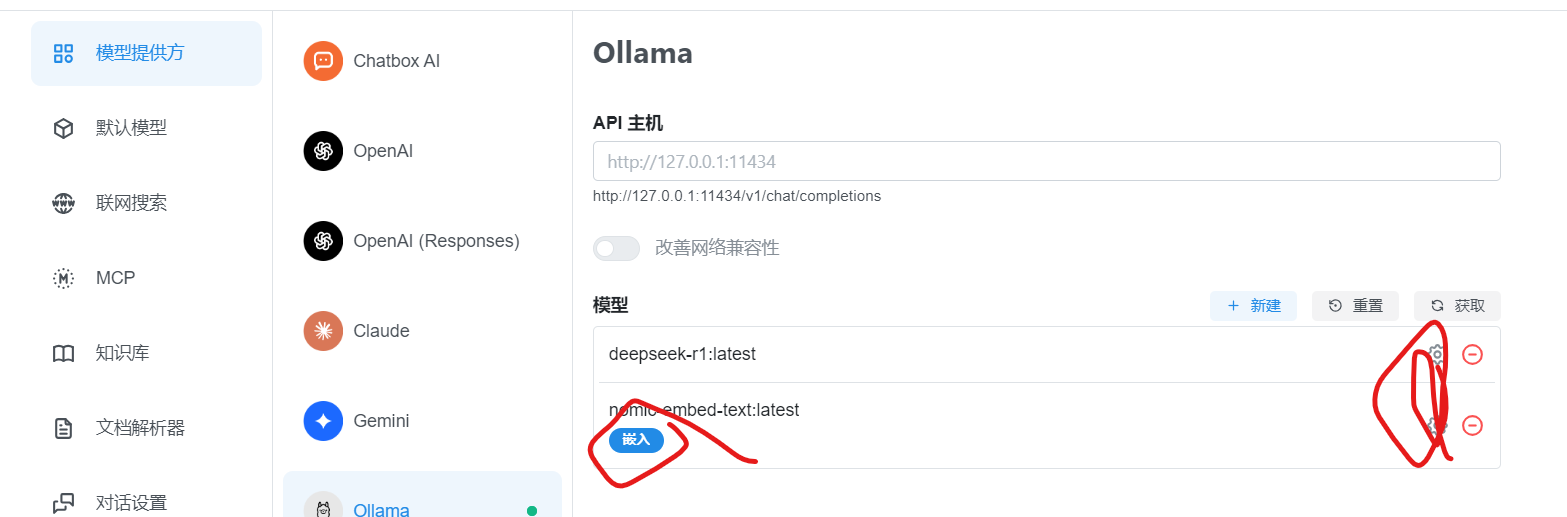
- 安装Ollama(通过命令行运行
- 知识库创建:
- 进入Chatbox的“知识库”页面,点击“添加知识库”,上传PDF/TXT/Markdown等文档(支持批量导入)。
- 系统自动进行文档分块(默认500字符/块,可调整)、向量化(使用nomic-embed-text或bge-m3模型)并构建索引。
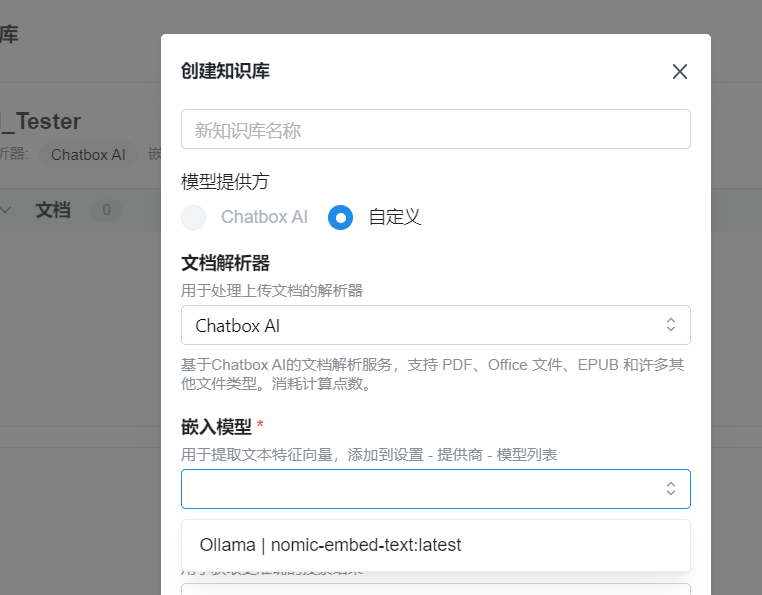
- 对话调用:
- 在聊天窗口勾选已创建的知识库名称(如“技术文档库”),提问时自动检索相关知识片段并生成回答。
2. 云端API集成(企业级管理)
- 方案一:Cherry Studio桥接
- 启动Ollama服务(
net stop ollama && net start ollama),配置Cherry Studio的API端点(如http://本机IP:11434)。 - 在Cherry Studio中管理知识库,上传文档后自动向量化(需安装嵌入模型如bge-m3)。
- 对话时通过指令
@knowledge:库名称调用特定知识库。
- 启动Ollama服务(
- 方案二:自定义API连接
- 配置企业知识库API(如Confluence、SharePoint),设置认证方式(OAuth/API Token)和请求参数。
- 在Chatbox的“远程API”模块中配置端点、请求头和响应解析规则(如JSON路径提取)。
3. 混合模式(安全与效率平衡)
- 本地部署向量数据库(如FAISS/Chroma)处理敏感文档,云端调用大模型(如OpenAI、SiliconFlow)进行推理。
- 通过“预处理消息”功能动态插入本地检索结果,结合云端模型生成最终回答。
二、关键配置与优化
- 模型选择:
- 嵌入模型:nomic-embed-text(768维,支持跨模态)、bge-m3(中文优化)。
- 对话模型:deepseek-r1:8b(生成式)、qwen3-embedding:8b(多语言高精度)。
- 文档处理:
- 分块策略:按段落/标题分割(如MarkdownHeaderTextSplitter),避免语义断裂。
- 格式支持:PDF需OCR处理(复杂排版建议用Doc2X转换),Excel支持表格数据提取。
- 性能优化:
- 调整分块大小(500-2000字符)和重叠度(50-100字符),平衡检索精度与效率。
- 启用结果缓存和增量更新(通过
CleanWindow定期清理过期索引)。
三、常见问题与解决方案
- 按钮灰色/无法创建知识库:
- 检查嵌入模型是否下载(如
ollama pull nomic-embed-text),维度是否正确(768维)。 - 确认文档格式支持(如PDF需PyPDFLoader解析)。
- 检查嵌入模型是否下载(如
- 检索结果相关性低:
- 调整分块大小和向量模型(如切换为bge-small-zh-v1.5),优化提示词结构(包含上下文信息)。
- 响应速度慢:
- 减少单次检索文档数量,启用结果缓存,优化硬件配置(如显卡内存≥4GB)。
- 大文件处理失败:
- 分割大型文档(如用Adobe工具拆分PDF),增加超时设置(如
preload.ts中调整timeout参数)。
- 分割大型文档(如用Adobe工具拆分PDF),增加超时设置(如
四、适用场景推荐
- 个人用户:本地部署+nomic-embed-text,适合笔记、代码库管理。
- 企业团队:云端API集成(如Confluence/SharePoint),支持多用户协作和权限管理。
- 动态更新需求:Langchain-Chatchat的动态文档刷新机制,实时同步最新文档变更。
通过以上方法,可灵活构建具备专业领域知识的AI助手,同时保障数据处理的安全性与隐私性。如需具体场景的详细配置,可提供更多需求细节进一步分析。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)