现代智能汽车系统——Memory
本文分析了高性能计算与AI领域面临的内存瓶颈问题。重点介绍了DRAM、HBM等主流内存技术的特点与应用场景:DRAM适用于PC/服务器(DDR)、移动设备(LPDDR)和GPU(GDDR);HBM通过3D堆叠实现超高带宽,但成本高昂。文章深入探讨了"内存墙"问题的成因与解决方案,包括提升频率(LPDDR5X)、增加位宽(HBM)、存内计算(PIM)等。针对车载领域,指出智能座舱
本文分析了高性能计算与AI领域面临的内存瓶颈问题。重点介绍了DRAM、HBM等主流内存技术的特点与应用场景:DRAM适用于PC/服务器(DDR)、移动设备(LPDDR)和GPU(GDDR);HBM通过3D堆叠实现超高带宽,但成本高昂。文章深入探讨了"内存墙"问题的成因与解决方案,包括提升频率(LPDDR5X)、增加位宽(HBM)、存内计算(PIM)等。针对车载领域,指出智能座舱首选LPDDR5,高阶自动驾驶可能采用HBM。最后介绍了Intel的EMIB和Foveros先进封装技术,为未来芯片设计提供方向。
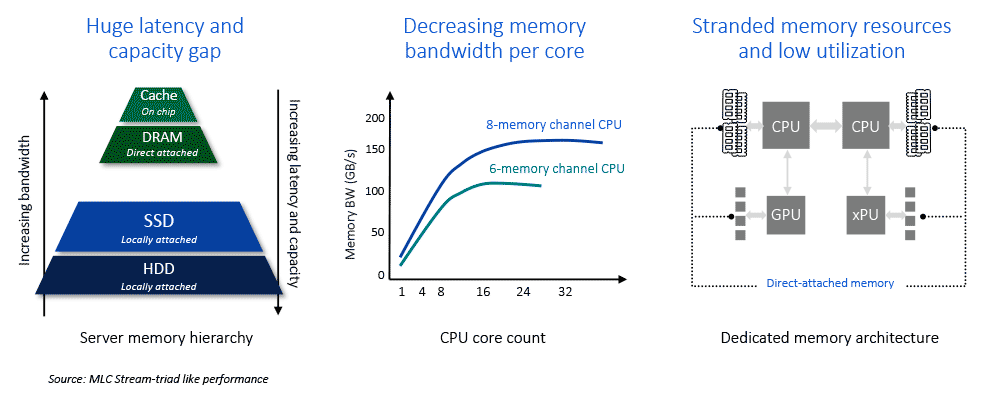
在高性能计算(HPC)、人工智能(AI)以及先进的车载 SoC 领域,内存(Memory)不仅是数据的仓库,更是决定系统整体性能的关键瓶颈。当处理器的算力(FLOPS)飞速增长时,如果内存无法及时供给数据,处理器就会被迫等待,这就是著名的**“内存墙”(Memory Wall)**问题。
以下是对几种关键内存技术(DRAM、HBM 等)的介绍,以及对内存速率瓶颈问题的深度解析。

一、 主流内存技术详解
1. DRAM (Dynamic Random Access Memory) - 动态随机存取存储器
DRAM 是所有主内存技术的基础统称。它使用电容存储电荷来表示 0 和 1,因为电荷会泄漏,所以需要不断刷新(Dynamic)。根据应用场景不同,DRAM 衍生出了多种标准:
-
DDR SDRAM (Double Data Rate Synchronous DRAM)
- 场景: PC、服务器、普通嵌入式设备。
- 特点: 通过总线位宽(如 64-bit)和高频率来提供带宽。目前主流是 DDR4 和 DDR5。
- 形态: 内存条(DIMM)。
-
LPDDR (Low Power DDR)
- 场景: 手机、平板、车载 SoC、边缘 AI 芯片。
- 特点: 专为低功耗设计。相比标准 DDR,LPDDR 电压更低,且支持深度睡眠模式。目前主流是 LPDDR4X 和 LPDDR5/5X。
- 优势: 车载首选。因为车载环境对功耗和发热敏感,且 LPDDR 通常直接焊接在主板上(Soldered Down)或以 POP(Package on Package)形式封装在 SoC 上,抗震性好,体积小。
-
GDDR (Graphics DDR)
- 场景: 显卡(GPU)、高阶自动驾驶芯片。
- 特点: 专为高带宽需求设计。虽然名字里有 DDR,但它其实基于 DDR 技术进行了大幅修改,拥有极高的频率和更宽的预取位宽。
- 优势: 带宽远超 LPDDR,适合吞吐量巨大的图像处理和 AI 推理。
- 劣势: 功耗高,发热大,延迟比 LPDDR 略高。
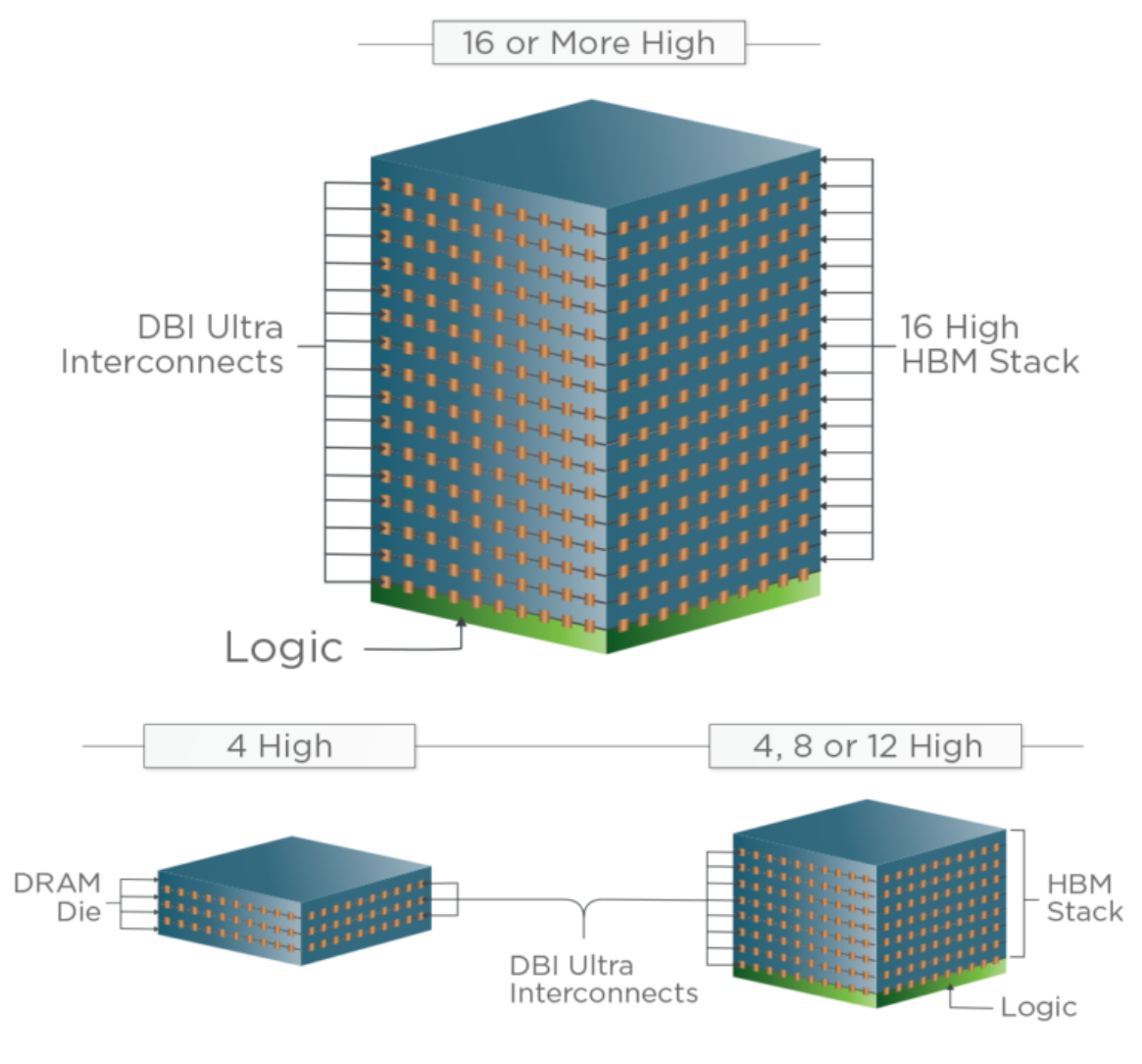
2. HBM (High Bandwidth Memory) - 高带宽内存
- 场景: 顶级 AI 训练芯片(如 NVIDIA A100/H100)、超算、顶级自动驾驶域控。
- 架构革新:
- 3D 堆叠(3D Stacking): HBM 不像 DDR 那样平铺在主板上,而是将多个 DRAM 芯片(Die)像盖楼一样垂直堆叠起来,通过 TSV(硅通孔) 技术在内部垂直打通。
- 超宽位宽: DDR 的位宽通常是 64-bit,而 HBM 的接口位宽可以达到 1024-bit 甚至更高。
- 2.5D 封装: HBM 必须通过 CoWoS(Chip-on-Wafer-on-Substrate)等先进封装技术,紧挨着 SoC 封装在同一个基板(Interposer)上。
- 特点:
- 极致带宽: 单个 HBM3 颗粒带宽可达 819GB/s,远超 DDR5。
- 小体积: 堆叠设计节省了宝贵的水平空间。
- 近存计算: 物理距离极近,降低了数据传输功耗。
- 劣势: 极其昂贵,工艺复杂,散热设计难度大。

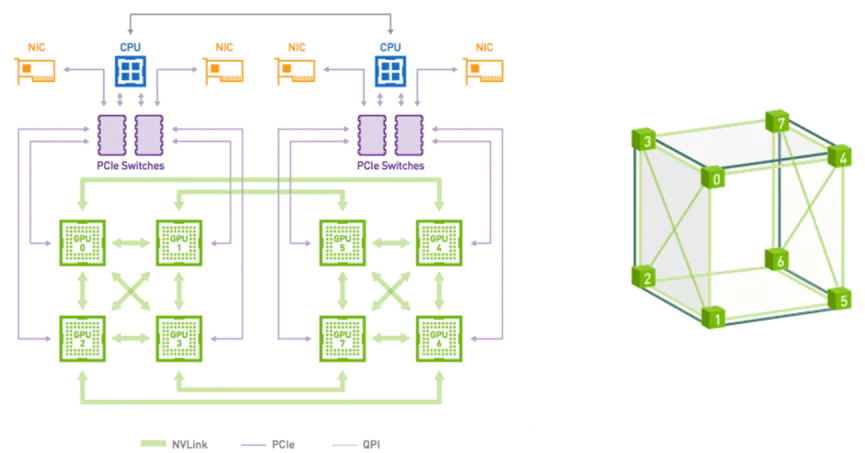
二、 内存的技术指标与瓶颈
评估内存性能主要看两个指标:带宽(Bandwidth) 和 延迟(Latency)。而在 AI 和自动驾驶时代,带宽往往是最大的痛点。
1. 内存带宽计算公式
$$ \text{带宽 (Bandwidth)} = \text{频率 (Frequency)} \times \text{位宽 (Bit Width)} \times \text{通道数 (Channels)} $$
2. 内存墙(Memory Wall)问题
随着 AI 模型参数量爆发(如 GPT 类大模型、端到端自动驾驶模型),算力增长速度远超内存带宽增长速度。
- 现象: 强大的 NPU 可以在 1ms 内算完数据,但内存把数据搬运过来需要 10ms。NPU 90% 的时间在空转等待数据。
- 瓶颈根源:
- 引脚限制(Pin Count): SoC 的物理引脚数量有限,无法无限增加 DDR 的通道数(位宽受限)。
- 信号完整性: 频率越高,信号在 PCB板上的传输衰减和干扰越严重,提升频率越来越难。
3. 解决速率瓶颈的技术路径
-
路径 A:提升单车道速度(DDR/LPDDR 升级)
- 从 LPDDR4 (4266 Mbps) -> LPDDR5 (6400 Mbps) -> LPDDR5X (8533 Mbps)。
- 车载应用: 目前主流高端座舱芯片(如 8295)已全面支持 LPDDR5。
-
路径 B:增加车道数量(HBM 技术)
- 既然提高频率难,那就疯狂增加位宽。HBM 用 1024bit 的超宽接口“大力出奇迹”,通过先进封装绕过 PCB 布线难题,直接在芯片内部微互连。
-
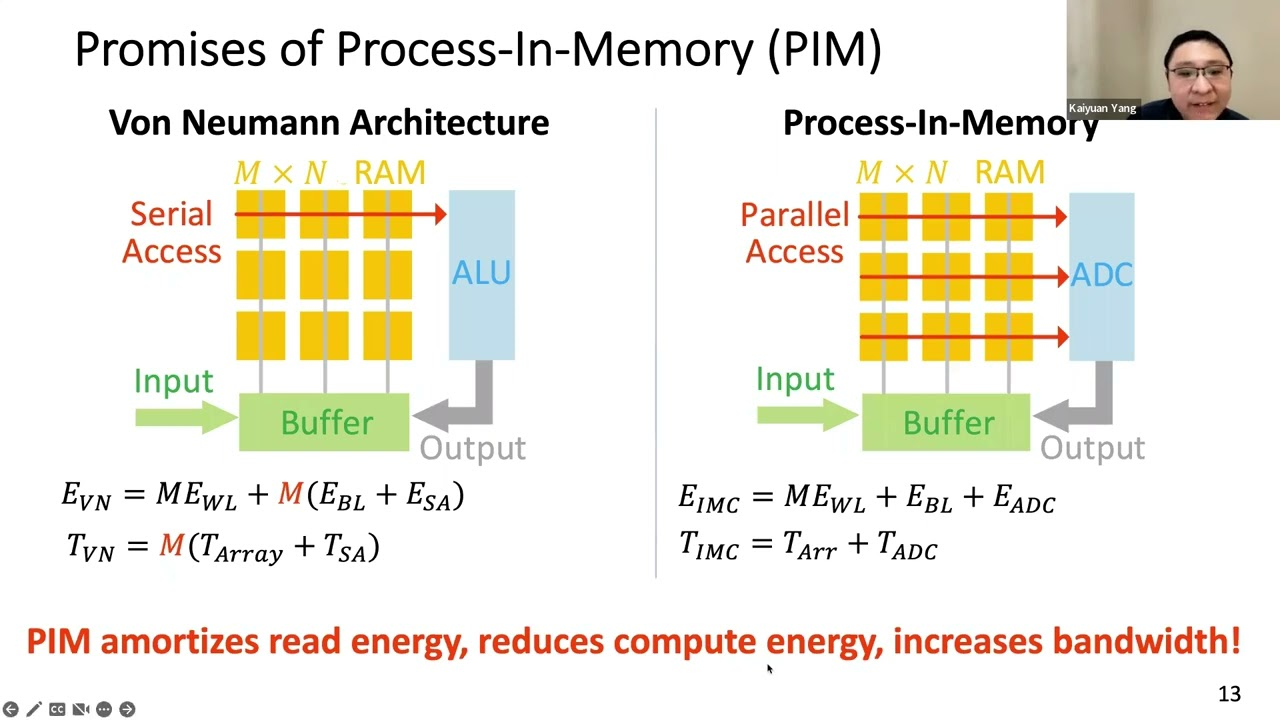
路径 C:减少数据搬运(存内计算 / PIM)
- PIM (Processing In Memory): 直接在内存条里集成简单的计算单元,让数据在原地被处理,不再搬来搬去。这是未来的颠覆性技术。
-
路径 D:更快的互连协议(CXL / NVLink)
- CXL (Compute Express Link): 基于 PCIe 5.0/6.0 的互连标准,允许 CPU 与扩展内存池之间共享缓存,极大地扩展了内存容量和带宽。
三、 总结:车载领域的内存选择
- 智能座舱(Cockpit): LPDDR5/5X 是绝对主流。
- 原因:需要大容量(运行 Android)、低功耗(散热受限)、低成本。带宽足以应付 4K 屏和语音交互。
- 自动驾驶(ADAS/AD):
- 中低阶(L2/L2+): LPDDR5 或 GDDR6。GDDR6 在需要大吞吐量感知的场景(多路 800W 摄像头)有优势。
- 高阶(L4/L5 / 端到端大模型): HBM 开始进入视野。随着端到端大模型上车,对显存带宽的需求呈指数级增长,传统 LPDDR 可能撑不住,未来顶级智驾芯片可能会像数据中心 GPU 一样集成 HBM。
一句话总结: 在芯片性能过剩的今天,谁能更快地把数据喂给处理器,谁才是真正的性能王者。 HBM 是解决带宽瓶颈的终极武器,而 LPDDR 是平衡性能与成本的最佳车规级选择。
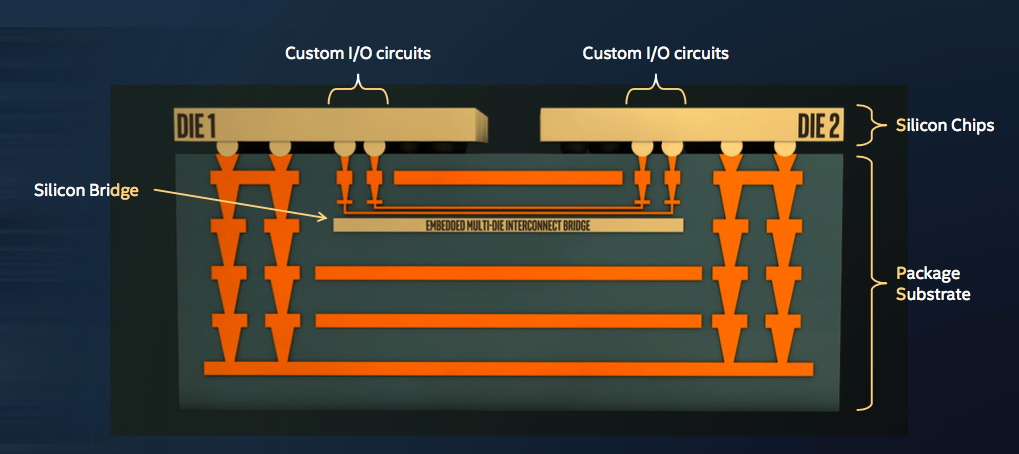
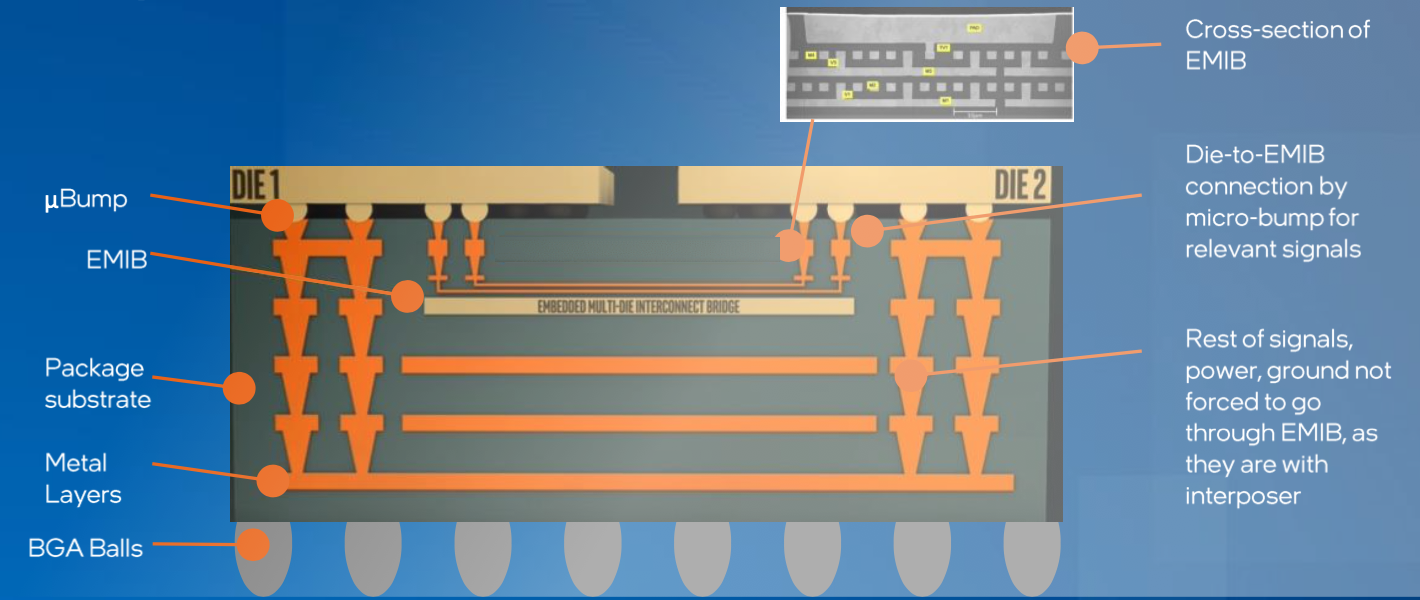
一、 EMIB (Embedded Multi-die Interconnect Bridge) - 嵌入式多芯片互连桥
EMIB 是 Intel 最具代表性的 2.5D 封装技术。它的核心理念是:“只在需要的地方修桥”。
1. 传统 2.5D 封装的痛点(如 CoWoS)
台积电的 CoWoS(Chip-on-Wafer-on-Substrate)技术通常需要一层巨大的**硅中介层(Silicon Interposer)**垫在所有芯片下面。这层硅片很大、很贵,而且容易碎,制造难度高。
2. EMIB 的创新原理
EMIB 不需要一整块巨大的硅中介层。它只在两个需要高速互连的芯片(Die)边缘,在基板(Substrate)内部嵌入一颗小小的硅桥(Silicon Bridge)。
- 结构: 这颗硅桥就像一座地下通道,内部蚀刻了超高密度的导线,专门负责连接左右两边的芯片(例如 GPU 核心和 HBM 显存)。
- 非互连区域: 其他不需要高速互连的部分,依然通过普通的基板布线连接。
3. EMIB 的优势
- 成本更低: 避免了使用超大面积的硅中介层。
- 良率更高: 小硅桥更容易制造,不容易出现整片报废。
- 灵活性: 可以任意组合不同工艺节点的芯片(例如 10nm 的 CPU + 7nm 的 GPU + 14nm 的 IO Die),实现异构集成(Chiplet)。
4. 应用案例
- Intel Kaby Lake-G: 将 Intel CPU 和 AMD Vega GPU 封装在一起。
- Intel Sapphire Rapids (至强处理器): 利用 EMIB 连接多个计算单元。
- Agilex FPGA、Xe 显卡(Ponte Vecchio): 连接计算核心与 HBM 显存。
二、 关于 ZAM 的推测与 Foveros 技术
在 Intel 的公开技术文档中,直接名为“ZAM”的核心封装技术并不常见。推测这可能指代以下两个概念之一:
- Z-height Assembly / Alignment Module:在垂直堆叠(3D封装)中,Z轴(高度)的控制和对准至关重要。这可能指代某种特定的组装工艺或模组。
- Zeta-scale / Zetta-scale Architecture Module:指代未来 Z 级计算架构的模块。
但如果讨论的是与 EMIB 并列的封装技术,那么你真正想了解的极大概率是 Foveros(Intel 的 3D 封装技术)。
Foveros (3D Face-to-Face Stacking)
如果说 EMIB 是水平方向的“搭桥”,那么 Foveros 就是垂直方向的“盖楼”。
1. 技术原理
Foveros 允许将两颗芯片**面对面(Face-to-Face)**地垂直堆叠在一起,并通过极微小的 Micro-bumps(微凸块) 或 Hybrid Bonding(混合键合) 进行电气连接。
- Active Base Die(有源基底层): 传统的封装基底通常是被动的(只有导线),但 Foveros 的底层也是一颗有功能的芯片(通常负责 I/O、供电、SRAM 缓存)。
- Compute Die(计算层): 上层堆叠高性能的 CPU/GPU 核心。
2. 优势
- 极短的互连距离: 垂直连接距离几乎为零,延迟极低,带宽极高。
- 超小体积: 芯片面积(Footprint)减半,非常适合对体积要求苛刻的移动设备。
- 能效比: 数据传输功耗大幅降低。
3. 应用案例
- Intel Lakefield: 史上著名的“五合一”芯片,将 CPU、内存、I/O 全部堆叠在指甲盖大小的封装里。
- Meteor Lake (Core Ultra): 结合了 Foveros 3D 封装技术。
三、 终极形态:Co-EMIB (Foveros + EMIB)
Intel 并不满足于单一维度的扩展,而是将两者结合,推出了 Co-EMIB 技术。
- 原理:
- 利用 Foveros 将芯片垂直堆叠(3D)。
- 再利用 EMIB 将这些堆叠好的 3D 模块在水平方向连接起来(2.5D)。
- 意义: 这使得制造超大规模、超高性能的芯片成为可能(如 Ponte Vecchio GPU),打破了单芯片制造的光罩尺寸限制(Reticle Limit)。
总结
- EMIB (2.5D): 水平方向的微型桥梁。低成本、高灵活性的 Chiplet 互连方案,特别适合连接 HBM 和计算核心。
- Foveros (3D): 垂直方向的摩天大楼。极致的小体积和低延迟,适合高集成度的 SoC。
- 车载应用前景:
- 未来的高阶自动驾驶芯片(如 Mobileye EyeQ Ultra 或 Intel 自身的车载 SoC)极有可能采用 EMIB 来集成 HBM 内存以解决带宽瓶颈,或者利用 Foveros 将 AI 加速器堆叠在 I/O 芯片之上,以实现更高的算力密度和更小的体积,适应汽车有限的 ECU 空间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)