大模型推理成本与优化技术全景解析:从显存估算到Continuous Batching
场景A:低并发、长文本离线处理方案:FP16精度 + Flash Attention + Static Batching。硬件按最大序列估算。场景B:高并发在线服务(如智能客服)方案:INT4量化 + vLLM + Continuous Batching + Speculative Decoding。用消费级显卡(如RTX 4090)即可支撑较高并发。场景C:复杂推理任务(如代码生成)
导读:当大模型从实验室走向生产环境,推理成本和延迟成为决定项目成败的关键。为什么7B模型在RTX 4090上跑得飞起,换70B就需要多卡A100?Flash Attention到底快在哪里?Continuous Batching如何将GPU利用率拉到极致?本文为你拆解推理优化的每一个环节,帮你打造高效经济的AI应用。
一、模型规模与显存估算:你的硬件够用吗?
部署大模型第一步就是算显存。图片中给出了清晰的估算公式和量化权衡,我们逐一解读。
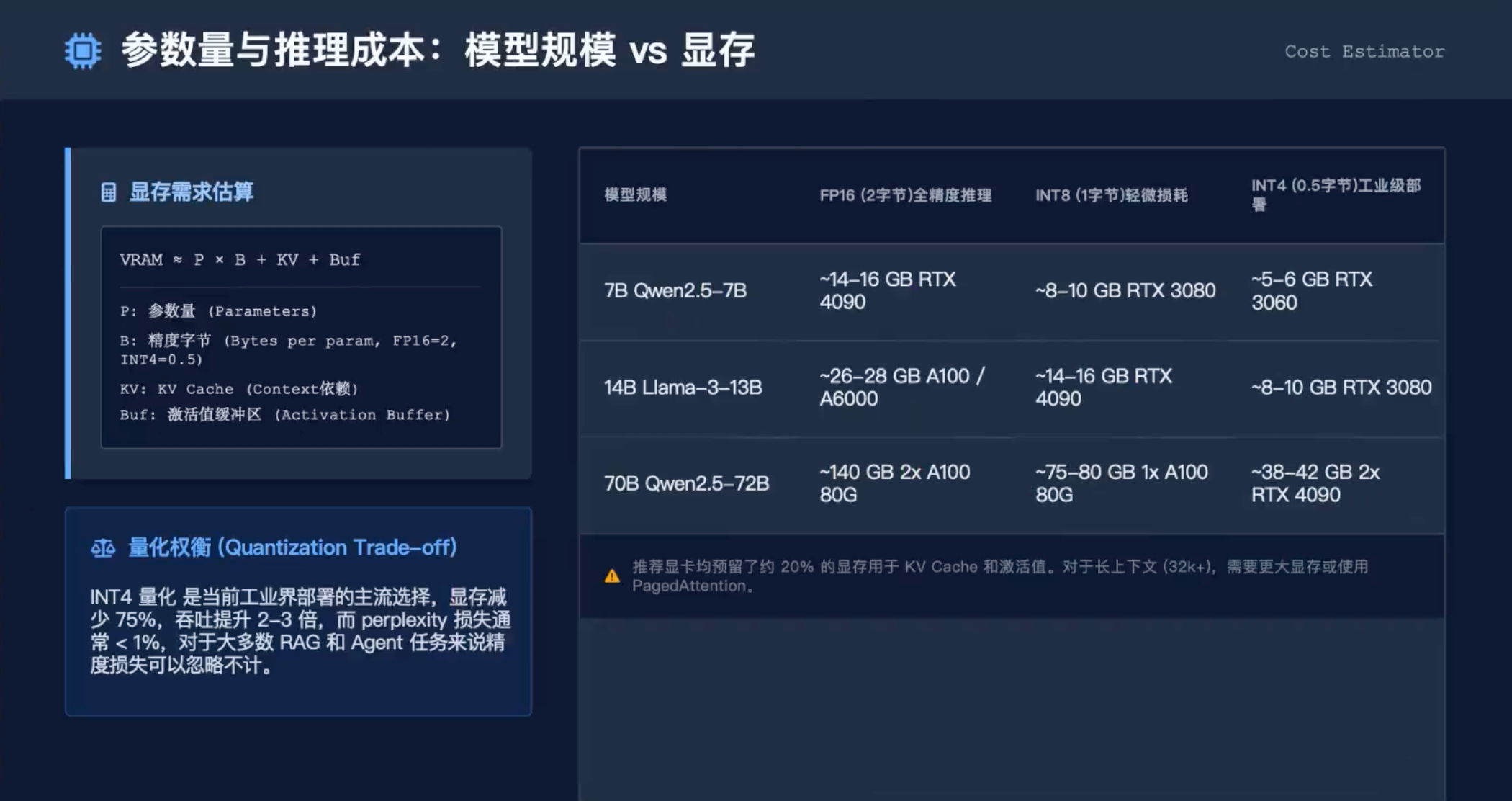
1.1 显存需求估算公式
VRAM≈P×B+KV+BufVRAM≈P×B+KV+Buf
- P(参数量):模型参数数量,如7B、13B、70B。
- B(精度字节):每个参数占用的字节数。FP16=2字节,INT8=1字节,INT4=0.5字节。
- KV(KV Cache):存储注意力键值对的内存,与上下文长度和批处理大小成正比。
- Buf(激活值缓冲区):前向计算中的中间激活值,通常占总显存的10%-20%。
关键点:参数量乘以精度字节就是模型权重占用的显存。例如7B模型FP16权重占用约14GB。但实际推理还需要加上KV Cache和缓冲区,因此表格中预留了20%余量。
1.2 量化权衡:INT4成为工业部署主流
量化是降低显存占用的利器,但会带来精度损失。图片中给出了量化的性价比:
- INT8:显存减半,精度损失极小(perplexity损失<1%),适合大多数场景。
- INT4:显存减少75%,吞吐提升2-3倍,而perplexity损失通常仍<1%!对于RAG、Agent等任务,精度损失可忽略不计,因此INT4已成为工业界部署的首选。
实践建议:如果你的任务需要复杂推理(如代码生成、数学解题),建议用INT8或FP16;如果只是知识库问答、文本分类,INT4足够。
1.3 不同规模模型的硬件推荐
图片中给出了典型模型的显存占用和推荐显卡(已预留KV Cache和激活值):
|
模型规模 |
FP16 (2字节) |
INT8 (1字节) |
INT4 (0.5字节) |
推荐硬件 (FP16) |
|
7B (如Qwen2.5-7B) |
14-16 GB |
8-10 GB |
5-6 GB |
RTX 4090 |
|
14B (如Llama-3-13B) |
26-28 GB |
14-16 GB |
8-10 GB |
A100 / A6000 |
|
70B (如Qwen2.5-72B) |
140 GB |
75-80 GB |
38-42 GB |
2× A100 80G |
注意:长上下文(32k+)需要更大显存,此时KV Cache占比大幅上升,建议使用vLLM等优化方案。
二、推理优化技术栈:让大模型跑得更快
2.1 Flash Attention:IO感知的注意力革命
问题:传统注意力计算需要频繁读写GPU的HBM(显存),速度受限于内存带宽。
Flash Attention核心思想:将注意力计算分块进行,在更快的SRAM(片上缓存)中完成计算,大幅减少HBM访问次数。结果就是:
- HBM访问量减少8-10倍
- 长序列训练/推理加速2-4倍
- 显存占用从O(n²)降至O(n)
最新进展:Flash Attention v2/v3进一步优化了线程束调度和寄存器使用,速度更快,已集成到主流框架。
2.2 vLLM & PagedAttention:解决显存碎片化
问题:传统批处理中,不同请求的KV Cache长度不一,导致显存碎片,实际利用率可能只有50%。
PagedAttention:借鉴操作系统的虚拟内存管理,将KV Cache分页存储,按需分配。就像内存分页一样,消除了内部碎片。
vLLM效果:
- 显存浪费率从30%+降至<4%
- 支持更大并发批处理(Continuous Batching的基础)
- 吞吐量可达传统方案的数倍
2.3 Speculative Decoding:用“小作文”换速度
问题:自回归生成只能逐token进行,无法并行,延迟与生成长度成正比。
投机采样原理:
- 用小模型(Draft Model)快速生成K个候选token(草稿)。
- 大模型(Target Model)并行验证这K个token。
- 如果草稿全部正确,一步就生成K个token;如果有错,则纠正并从错位继续。
效果:在无损精度前提下,解码速度提升1.5-2.5倍。适合生成长文本的场景(如总结、代码生成)。
2.4 部署方案选型
|
方案 |
特点 |
适用场景 |
|
TensorRT-LLM |
NVIDIA官方,极致算子优化,性能最强 |
生产环境,固定硬件,追求极致吞吐 |
|
TGI (HuggingFace) |
生态好,兼容性强,功能丰富 |
快速部署,多模型切换,社区支持好 |
|
vLLM |
吞吐量高,PagedAttention加持 |
高并发场景,长上下文服务 |
三、批处理策略:吞吐与延迟的博弈
批处理是提升GPU利用率的关键,但不同策略对延迟影响巨大。图片中用生动的图示对比了三种策略。
3.1 Static Batching(静态批处理)
- 原理:等待所有请求到达或超时,将多个请求打包成一个Batch,按最长请求进行Padding(填充)。
- 缺点:短板效应——短请求必须等待长请求完成,导致高延迟;Padding浪费显存。
- 适用:离线批处理,对延迟不敏感。
3.2 Dynamic Batching(动态批处理)
- 原理:服务端动态组合即时到达的请求,形成新Batch。减少Padding,但仍需等待整个Batch生成完毕。
- 特点:吞吐提升,但仍有偶发高延迟(因为要等最慢的请求)。
- 适用:延迟容忍度中等的在线服务。
3.3 Continuous Batching(连续批处理)
- 原理:在每次迭代(每个token生成)级别进行调度。一旦某个请求生成完毕,立即插入新请求,无需等待整个Batch结束。
- 优势:最大化GPU利用率,延迟最低(尤其是P99延迟)。
- 实现:vLLM、TGI均已支持。
对比总结:
|
策略 |
吞吐量 |
延迟(P99) |
显存效率 |
|
Static Batching |
低 |
高 |
低 |
|
Dynamic Batching |
中 |
中 |
中 |
|
Continuous Batching |
高 |
低 |
高 |
3.4 SLA驱动的队列管理
在生产环境中,不能只看平均吞吐,更要关注长尾延迟(Tail Latency,如P99)。需要设置:
- 最大队列大小:防止请求堆积过多导致超时。
- 超时阈值:超过一定时间未处理的请求直接拒绝或降级。
目标:在吞吐和延迟之间找到平衡,确保SLA(服务等级协议)。
四、总结:如何构建高效的推理系统?
根据你的应用场景,可以选择不同的优化组合:
- 场景A:低并发、长文本离线处理
方案:FP16精度 + Flash Attention + Static Batching。硬件按最大序列估算。 - 场景B:高并发在线服务(如智能客服)
方案:INT4量化 + vLLM + Continuous Batching + Speculative Decoding。用消费级显卡(如RTX 4090)即可支撑较高并发。 - 场景C:复杂推理任务(如代码生成)
方案:FP16/INT8精度 + TensorRT-LLM优化 + Dynamic Batching,保证质量同时提升吞吐。
最终建议:先用量化工具测试INT4下的效果(一般没问题),再引入vLLM提升并发能力,最后根据P99延迟决定是否启用Speculative Decoding。记住,监控是关键——实时跟踪显存、延迟、吞吐,才能持续优化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)