AI产品经理课程笔记
AI(基栈型产品经理)AI+(行业型产品经理,消费者产品经理)+AI(软件型产品经理,软硬结合产品经理)
分类
AI(基栈型产品经理)
AI+(行业型产品经理,消费者产品经理)
+AI(软件型产品经理,软硬结合产品经理)

技术
AI算法,
数据(数据来源,数据治理的流程)
算力,
硬件
AI产品必须懂的技术
需求层(目标确定)
数据层(数据获取、清洗、整理)
分析层(算法+模型)
输出层(结果展示)

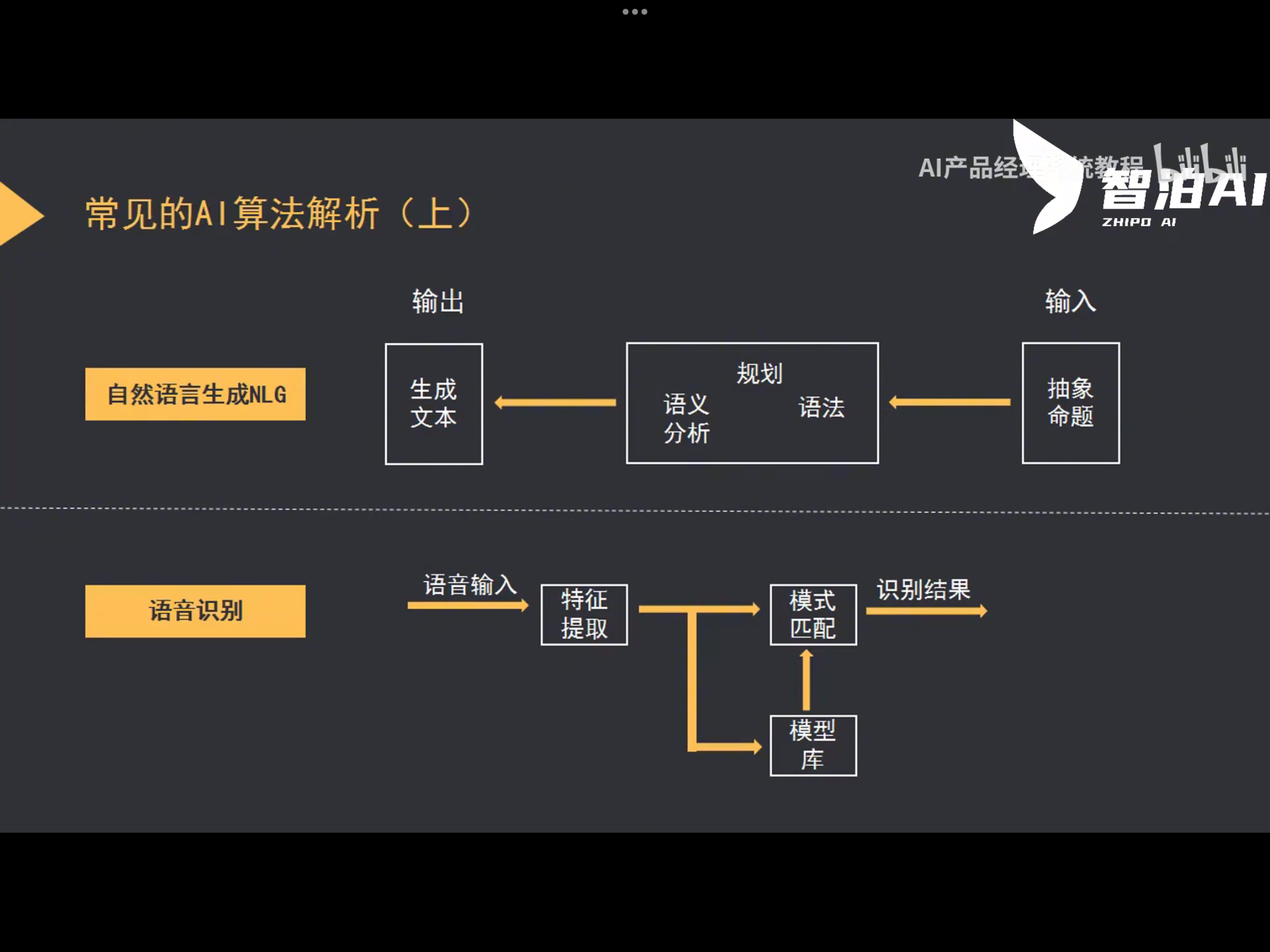
自然语言生成NLG
输入(抽象命题)-->规划(语义分析、语法)-->输出(生成文本)
语音识别
语音输入-->特征提取-->模式匹配(<--模型库)-->识别结果
虚拟现实
采集(360度/720度)-->以人为中心处理图像环境-->输出(VR/SR)
机器学习平台
历史数据(训练)/新数据(输入)-->特征提取--输入-->模型神经网络-->预测未来
深度学习-神经网络
输入层--隐含层--隐含层--输出层
决策管理
知识数据、模型算法、数据库-->神经网络处理-->交互语言系统-->应用
RPA(机器人流程自动化)
输入(需求)-->规则-->输出(目标)
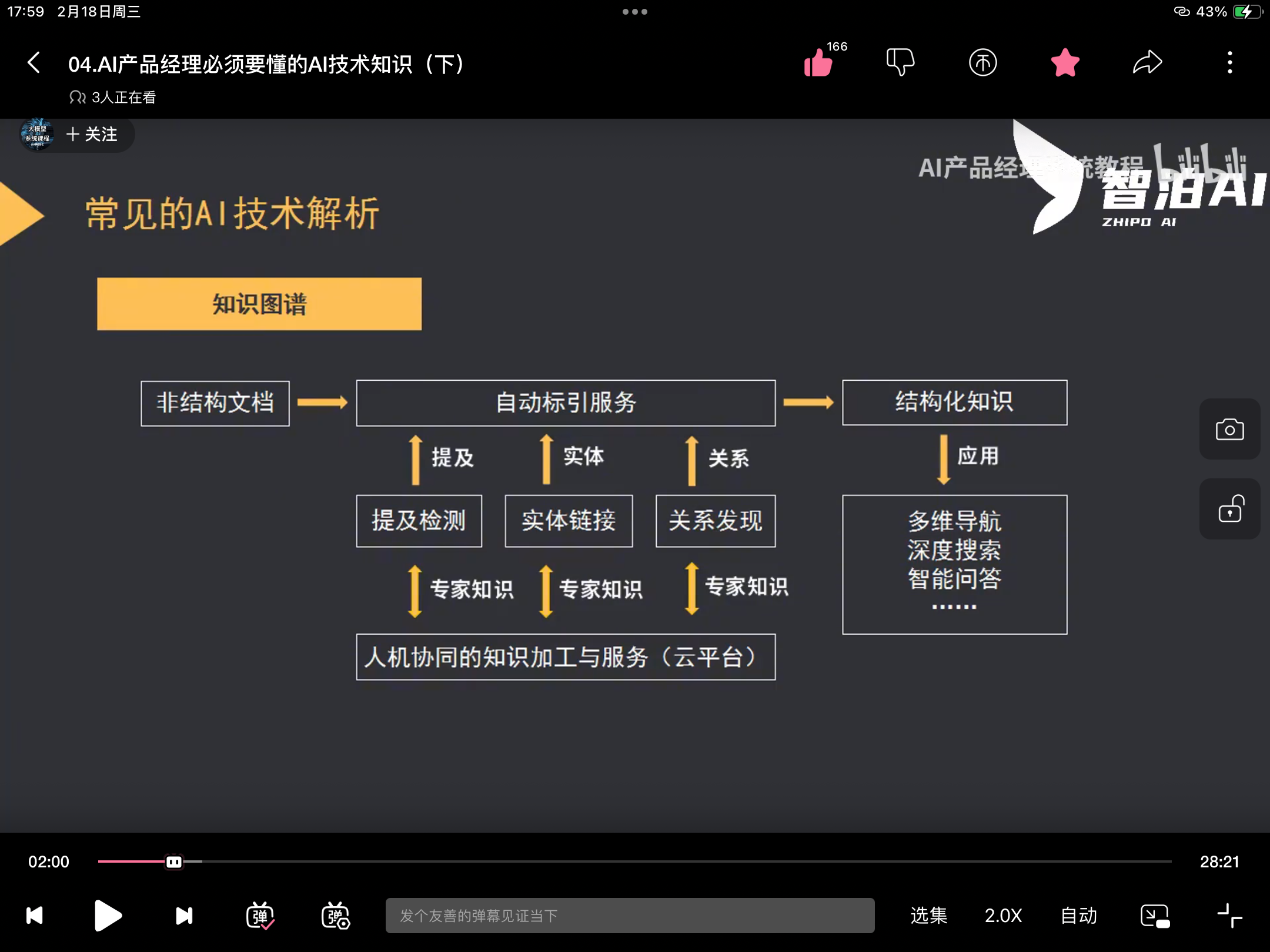
NLP
 知识图谱
知识图谱
机器学习
强化学习
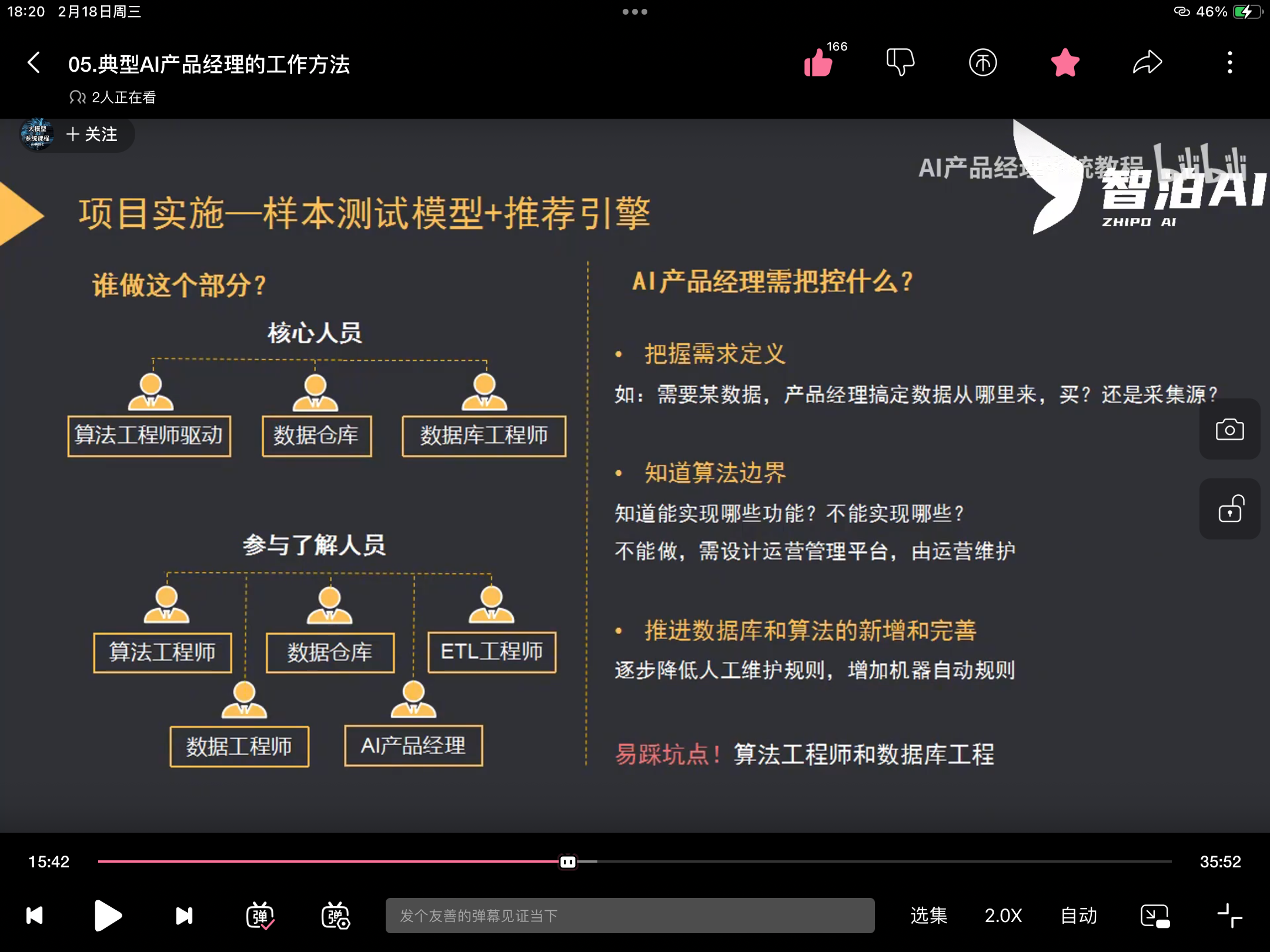
典型工作方法
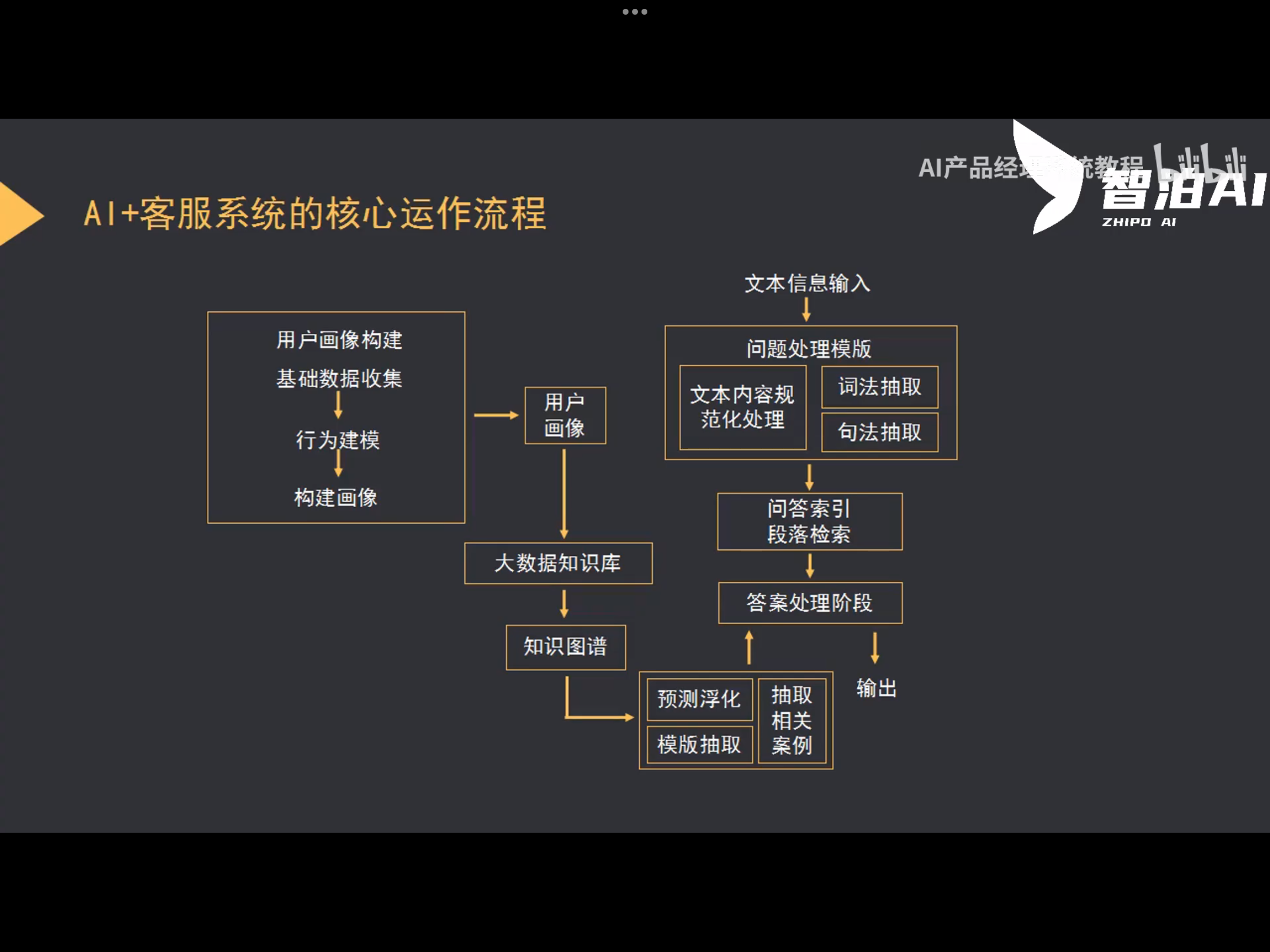
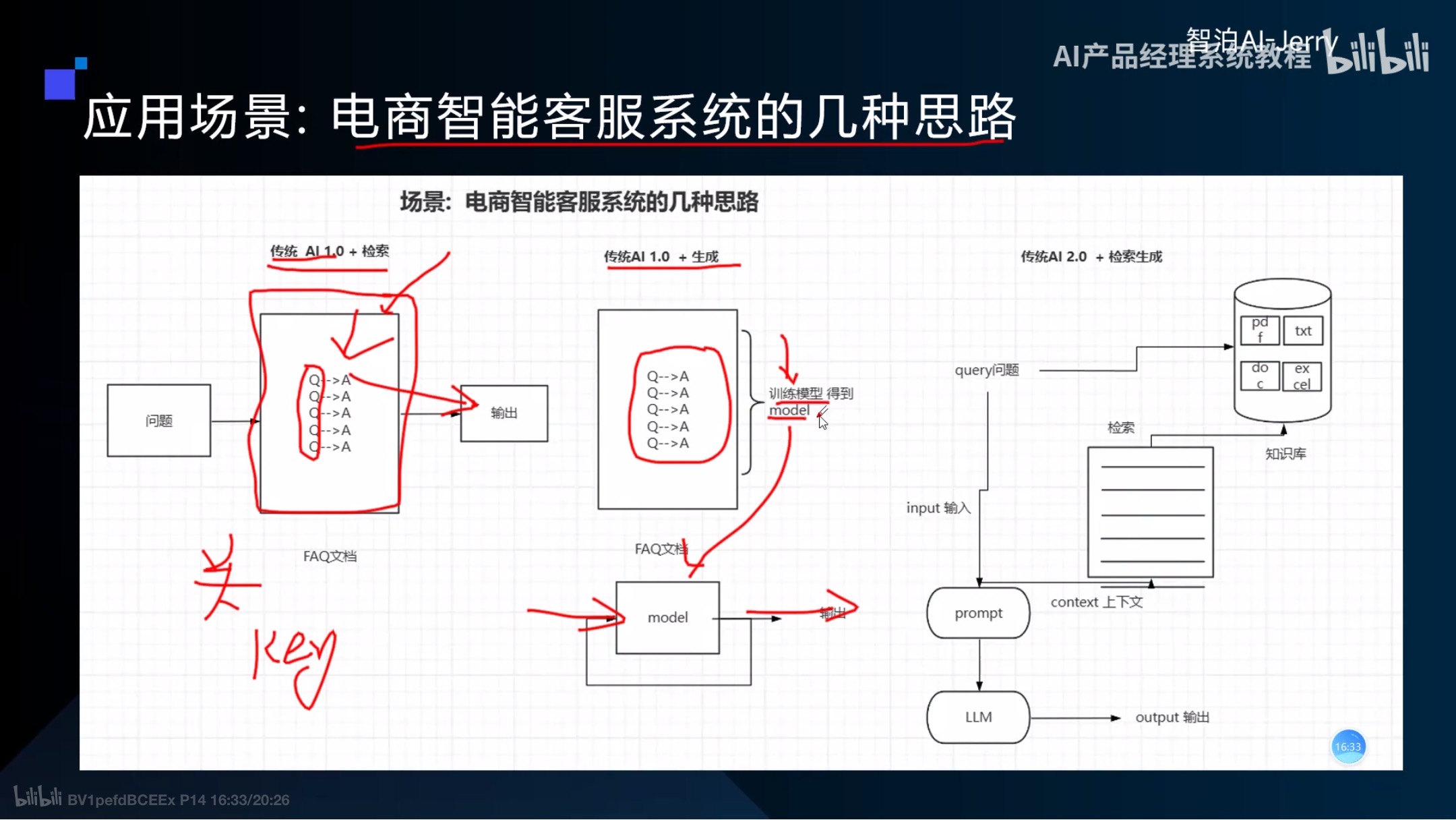
找到核心痛点/需求-->设计知识库(根据行业专业/客服专家)-->更新知识库
e.g.
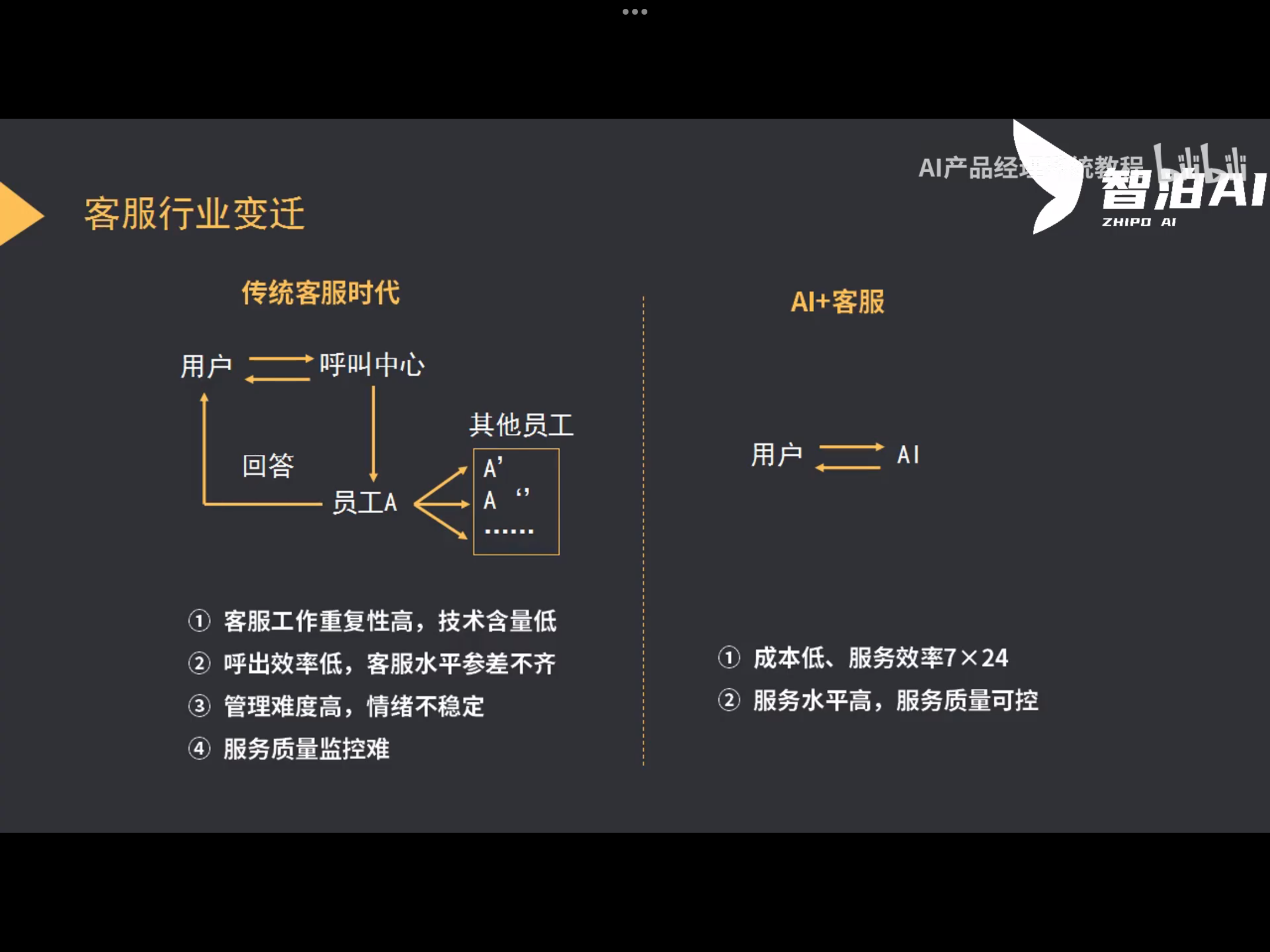
AI+客服系统(联通)
询问问题没有答案的解决方法:找到相似的问题解答,人工解答,不做处理(bug)-->补充知识库
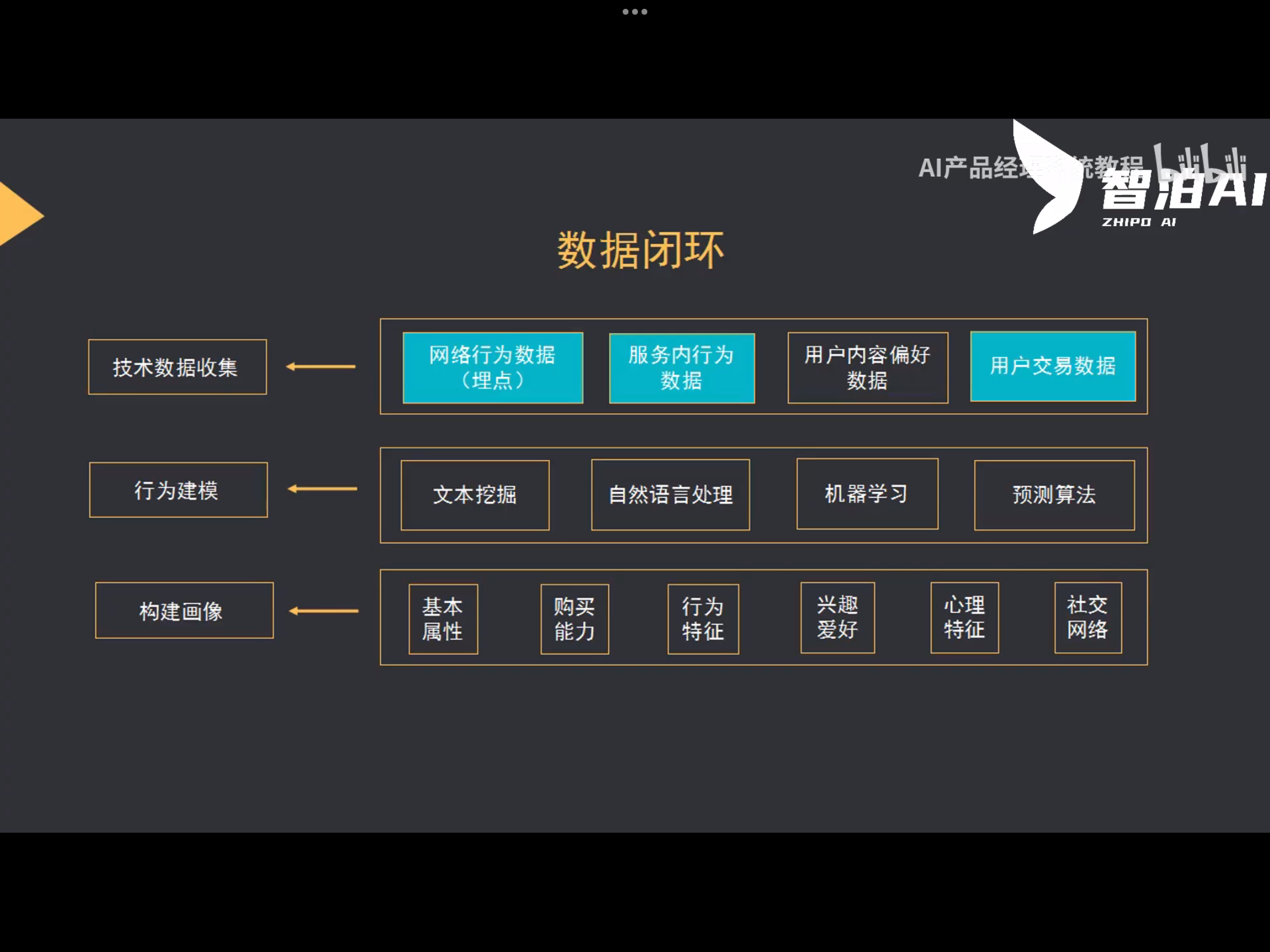
数据闭环
AI产品产业架构
分类

可投大厂的业务整理
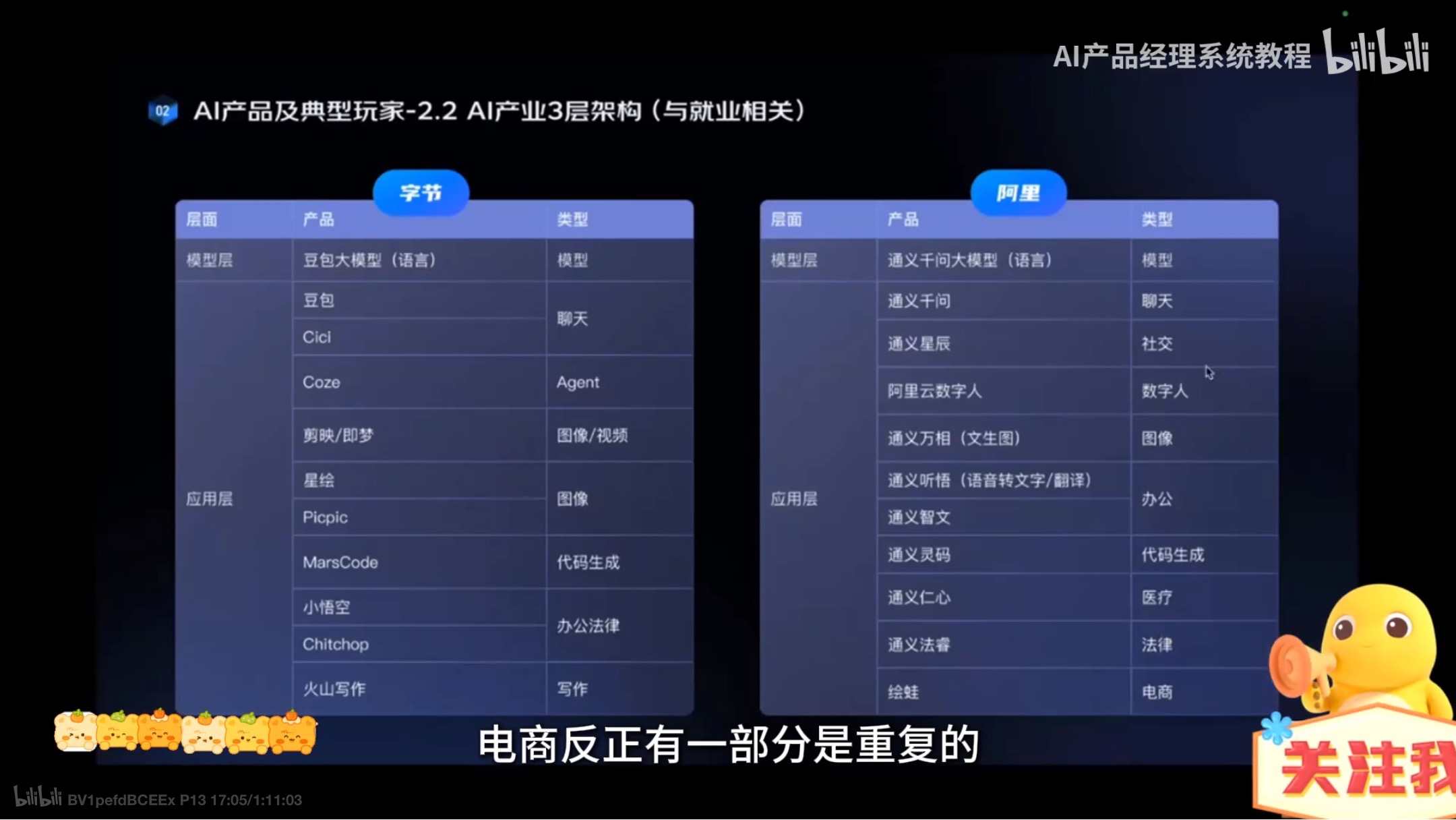
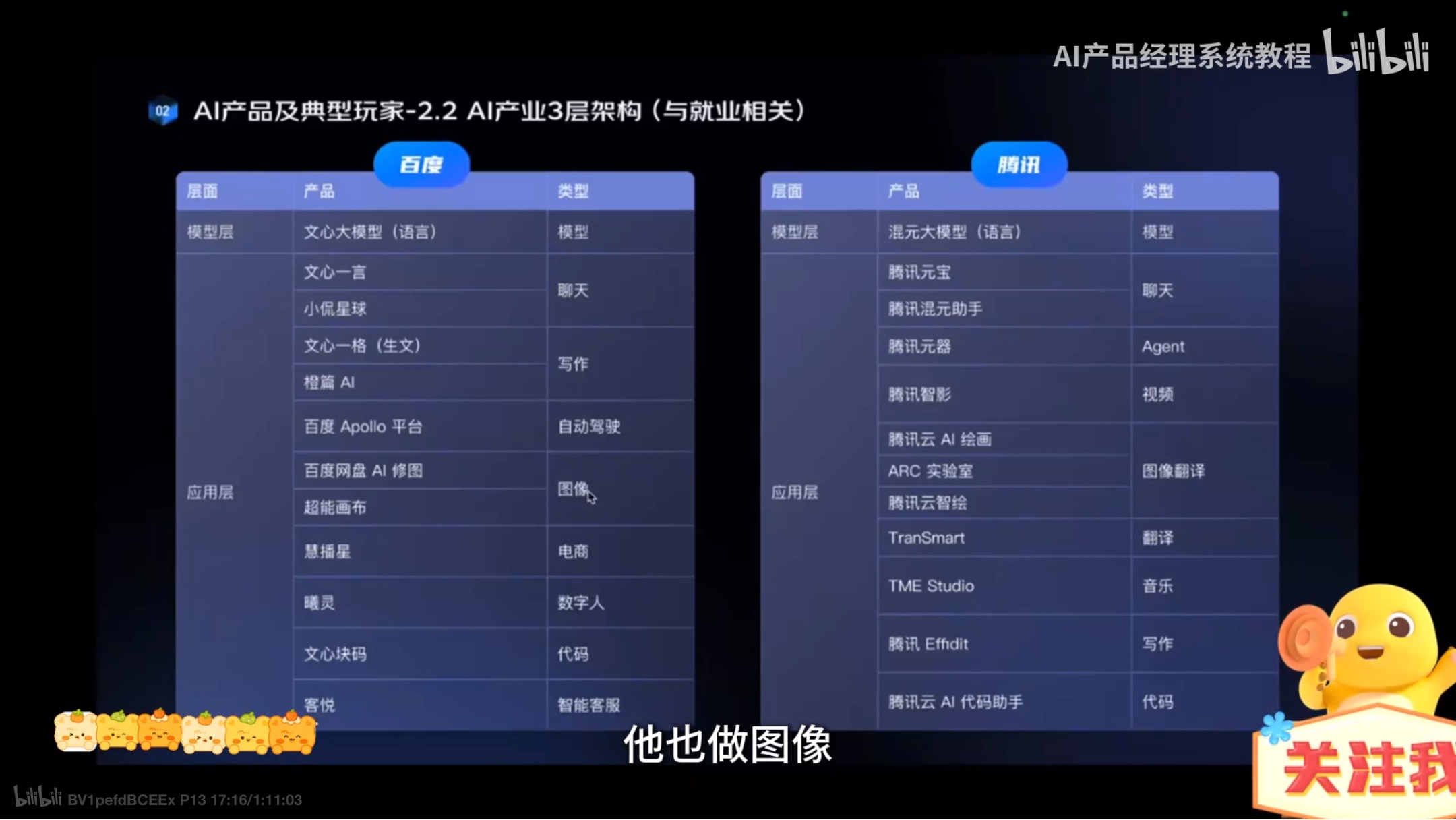
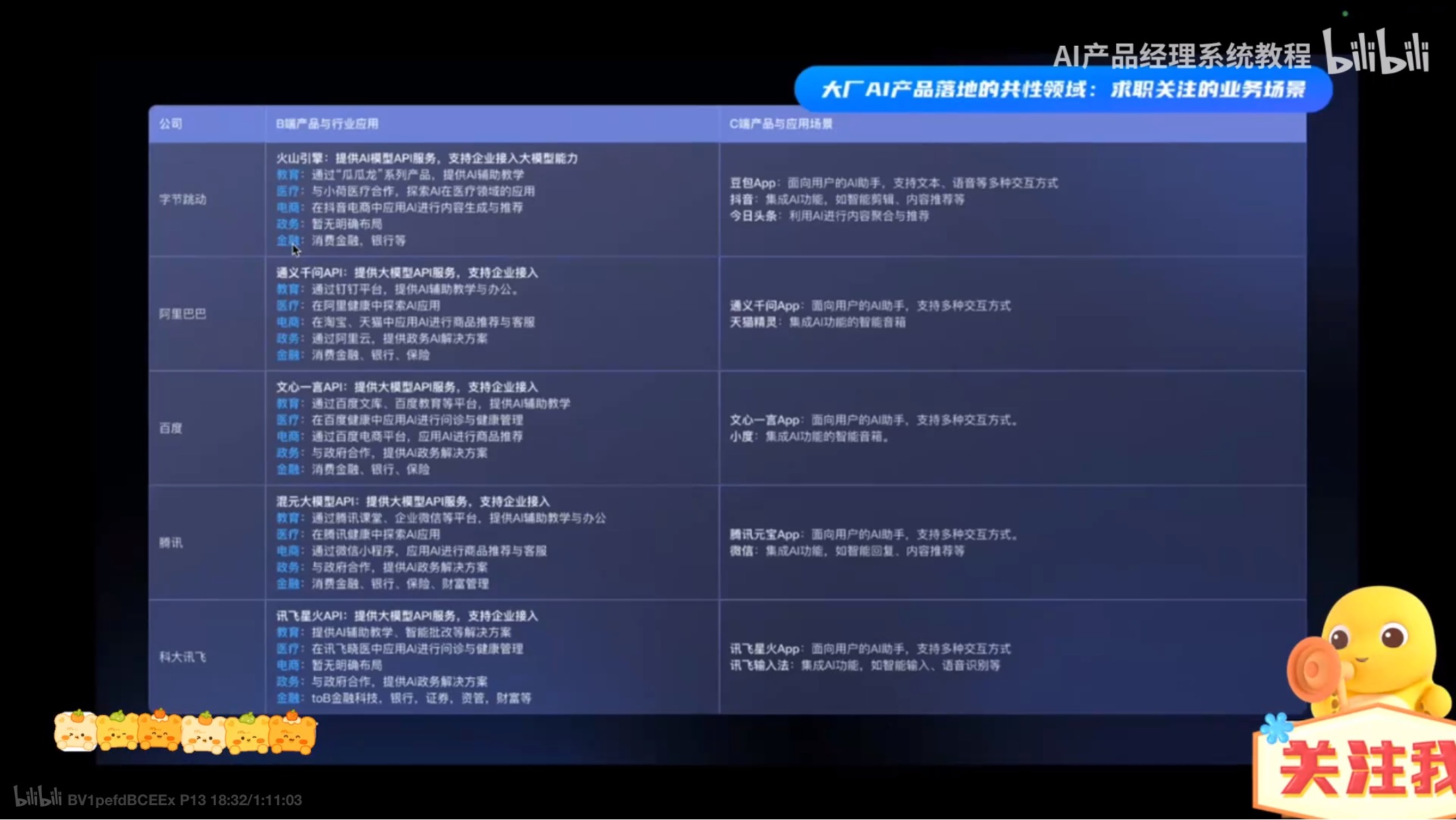
工作流程
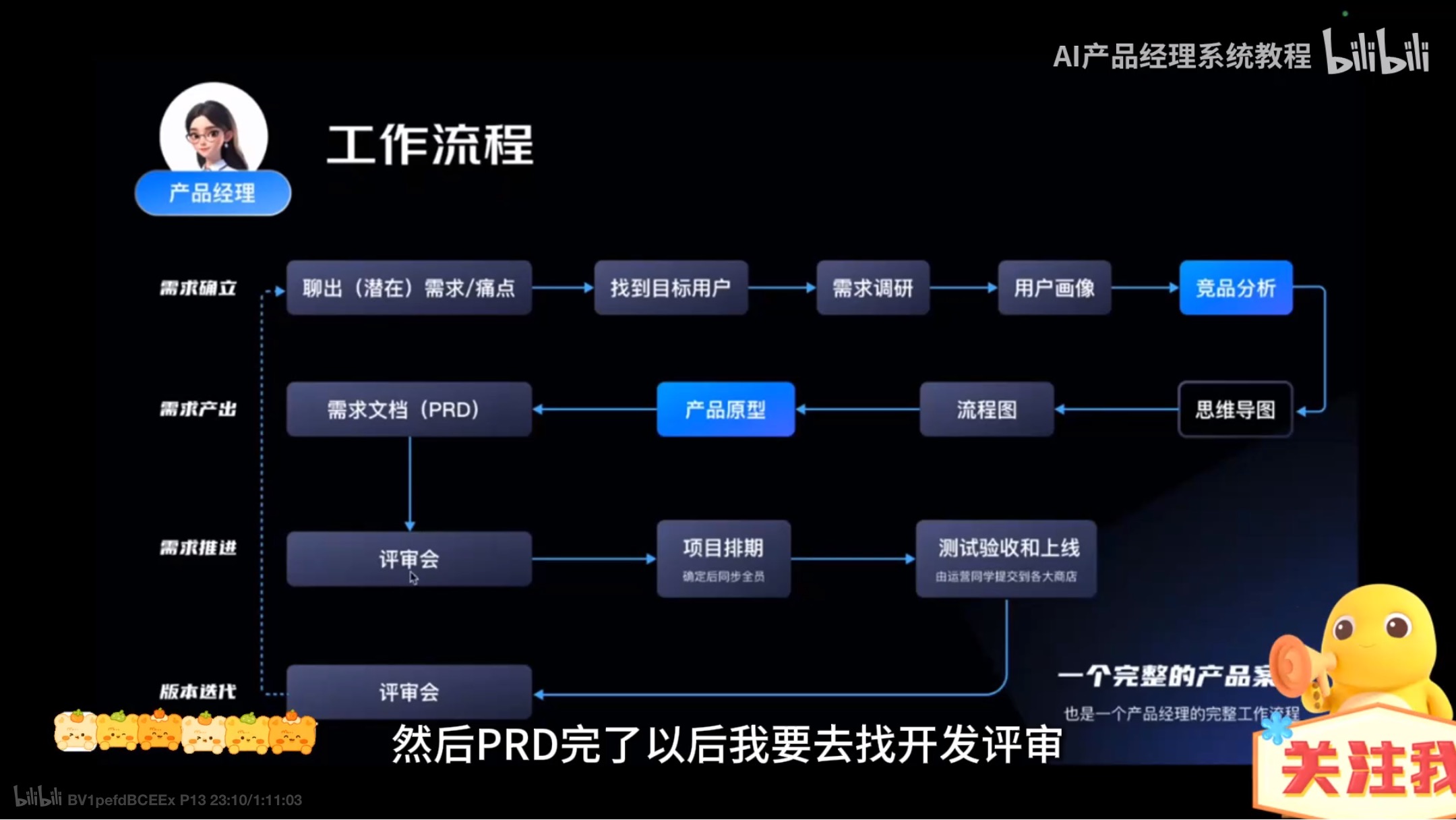
产品经理相关岗位--解决方案
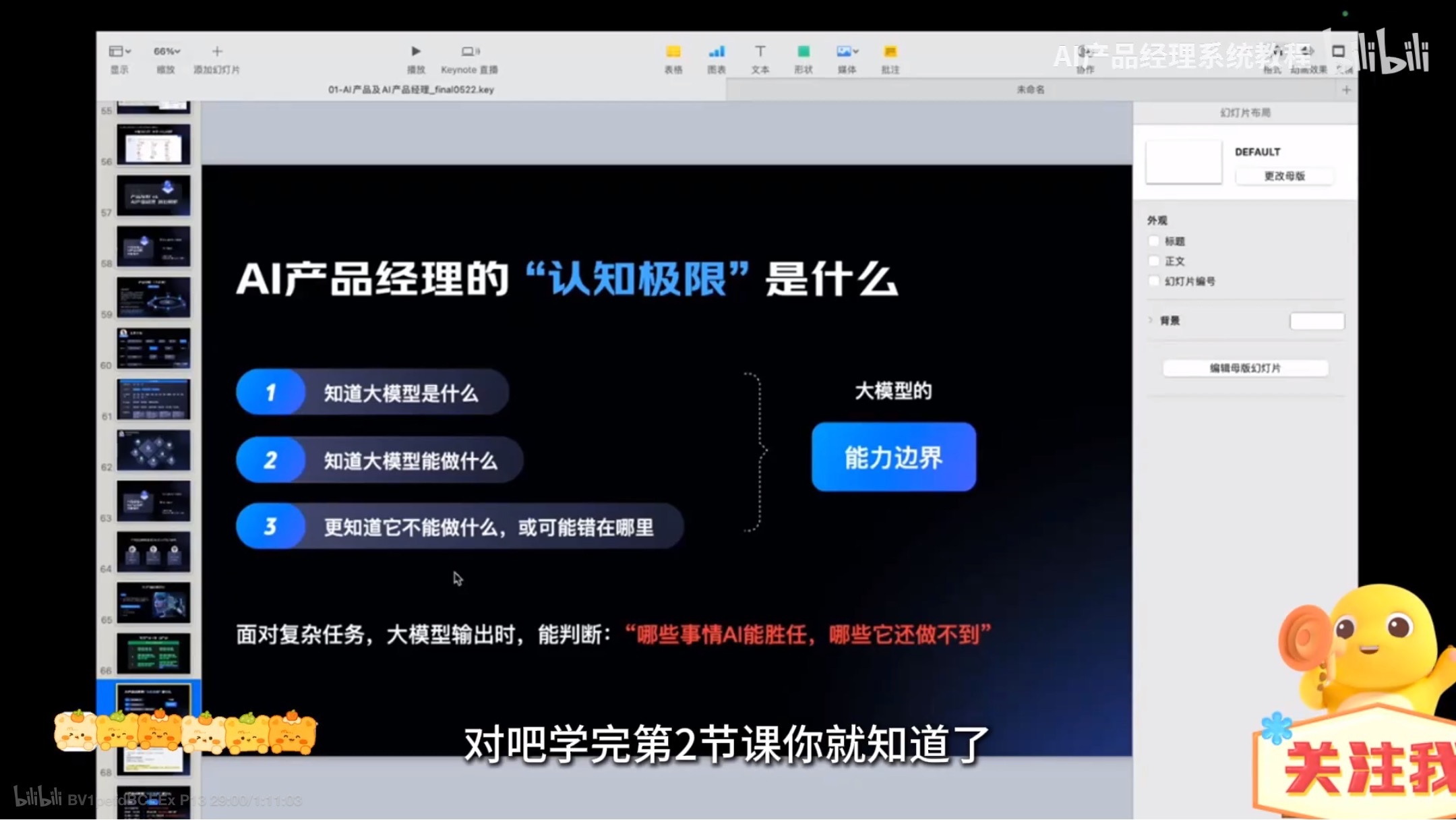
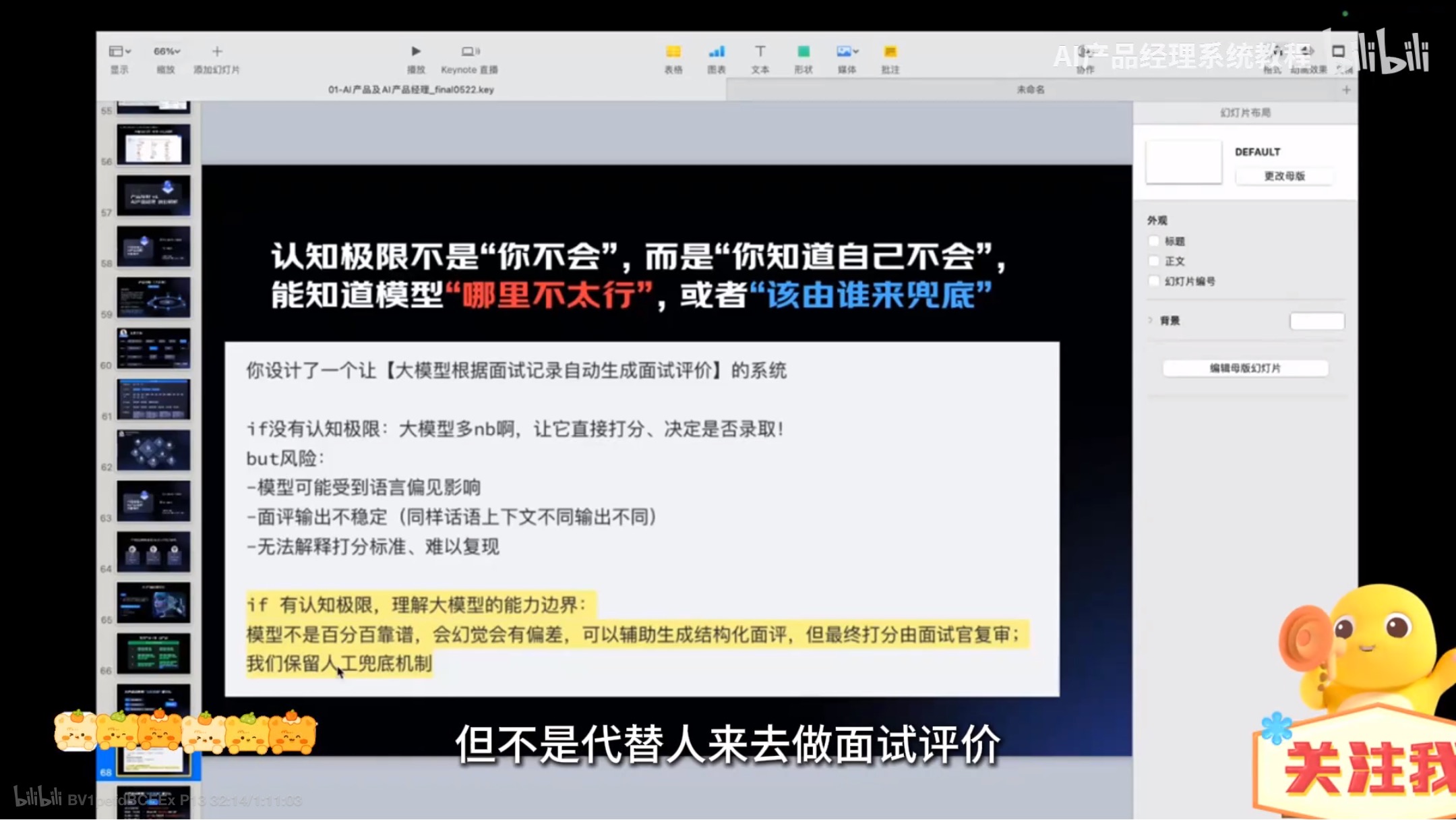
AI产品认知边界

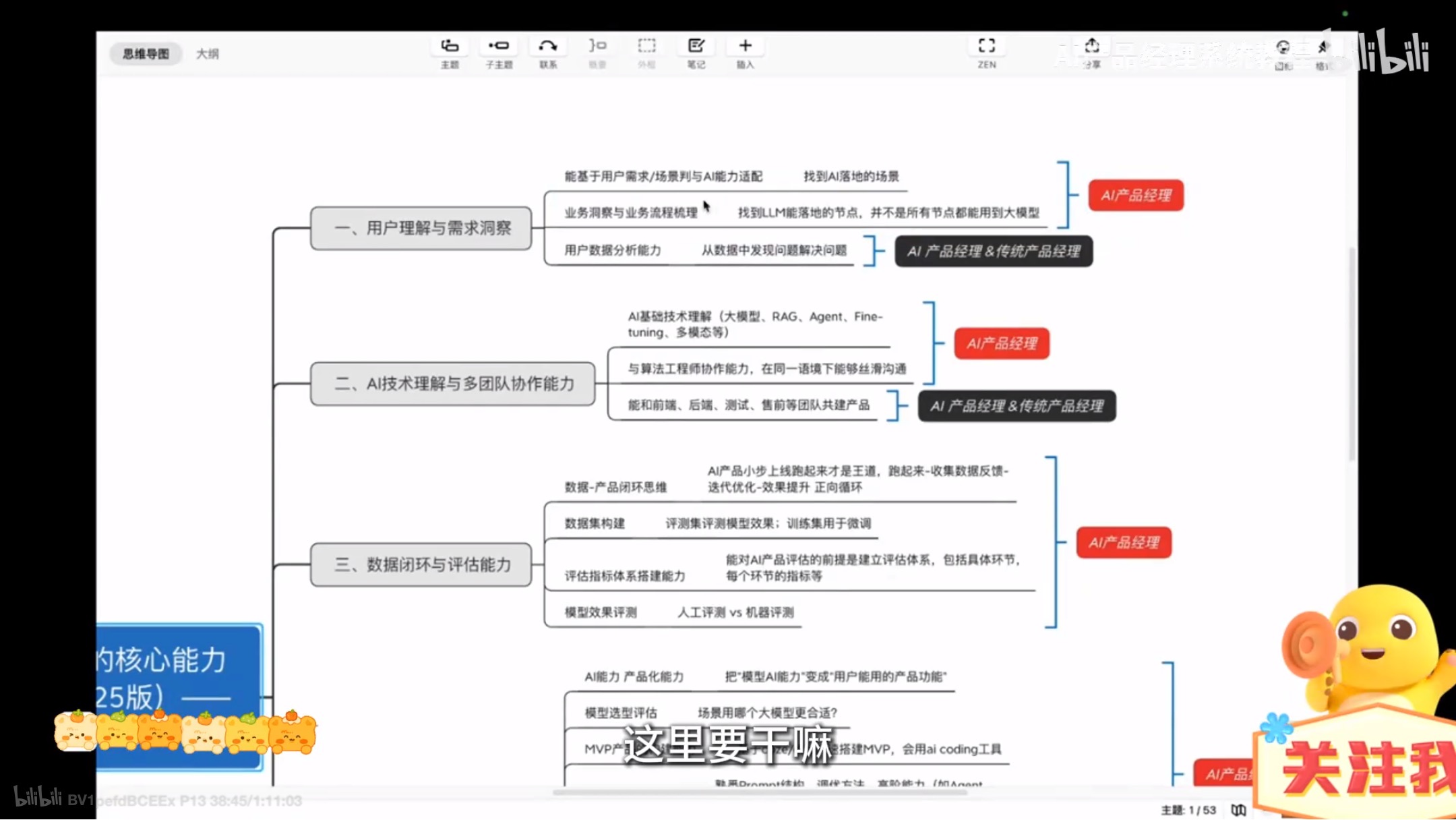
AI产品的核心能力
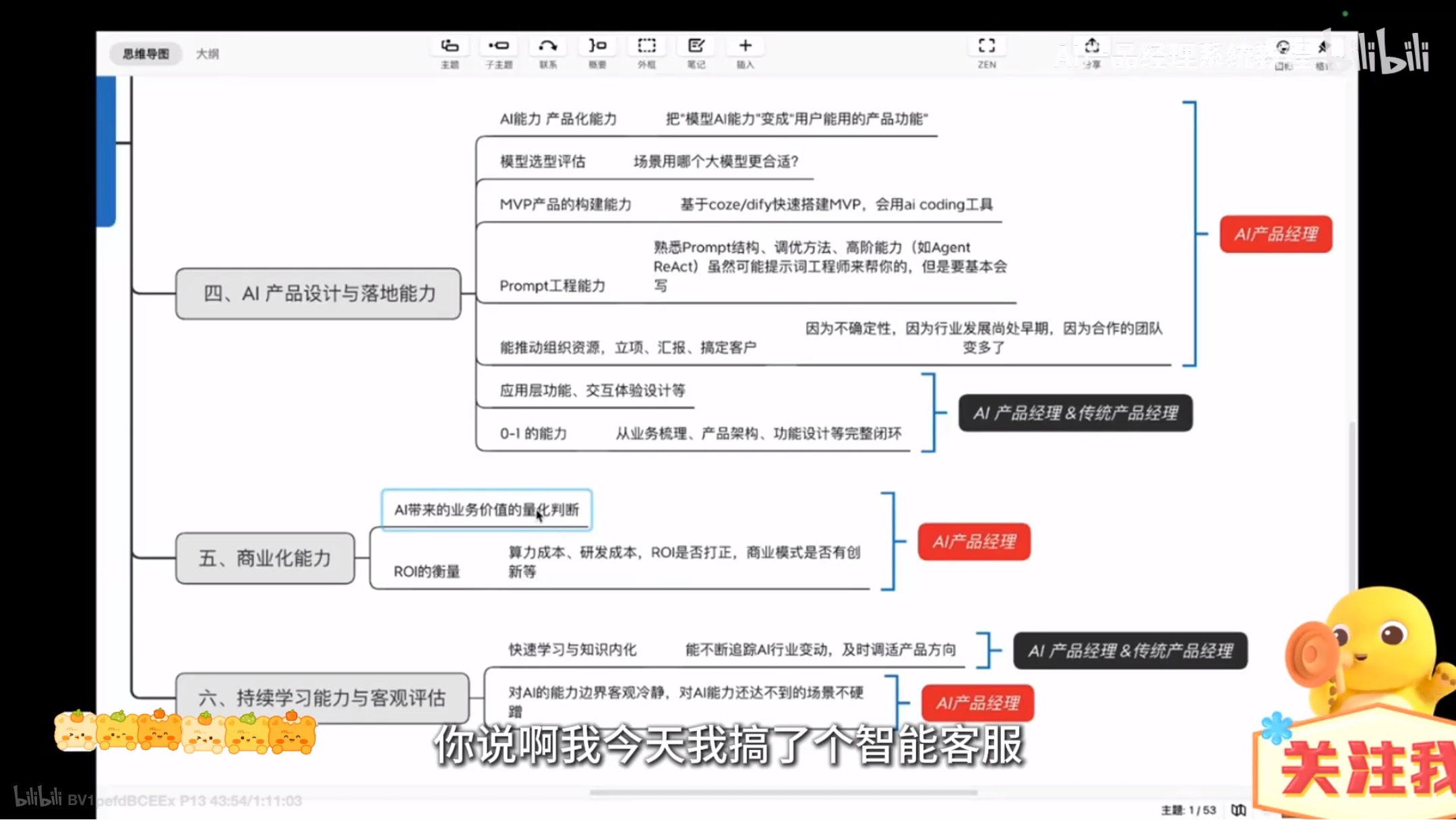

工作流程
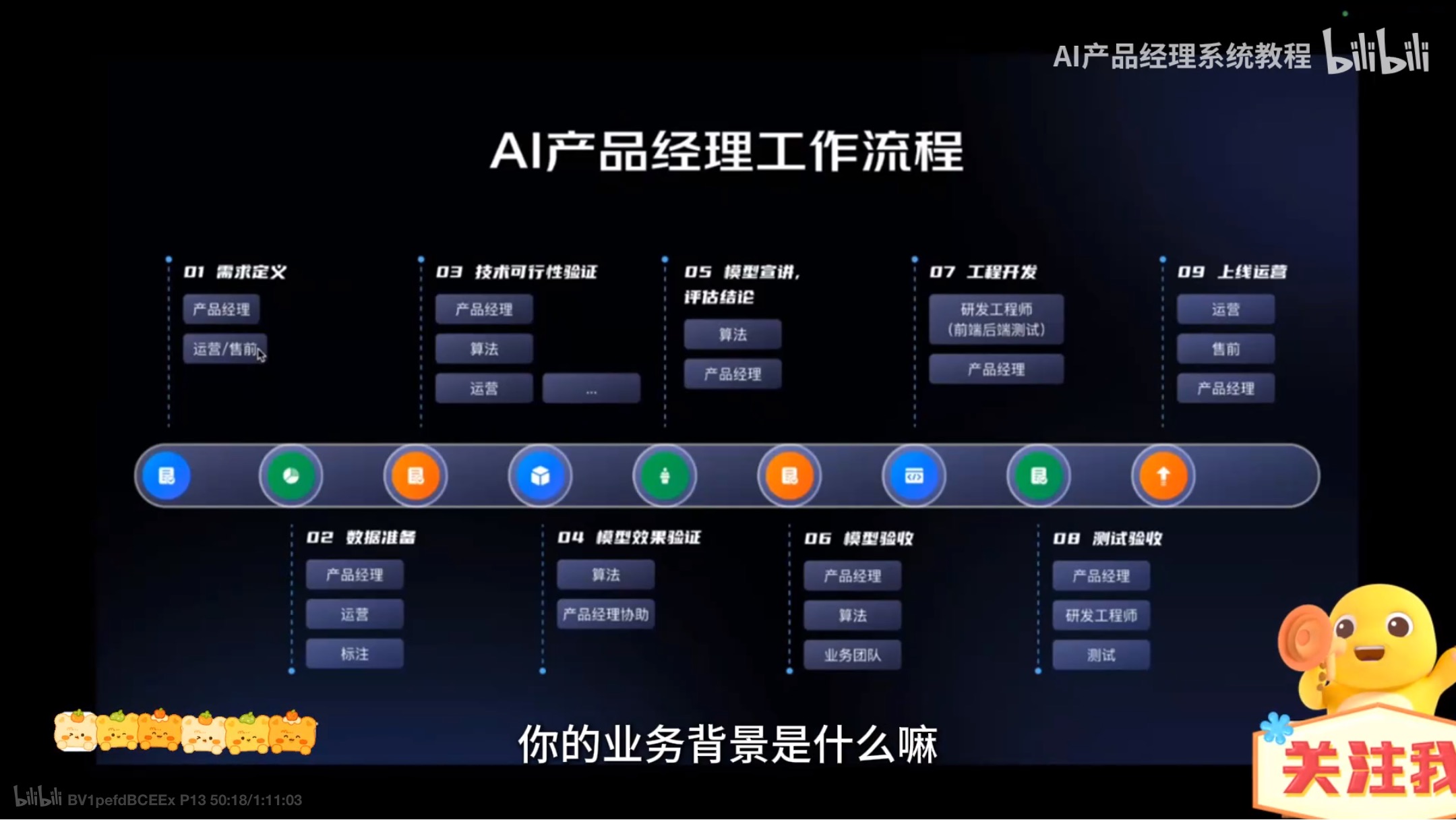
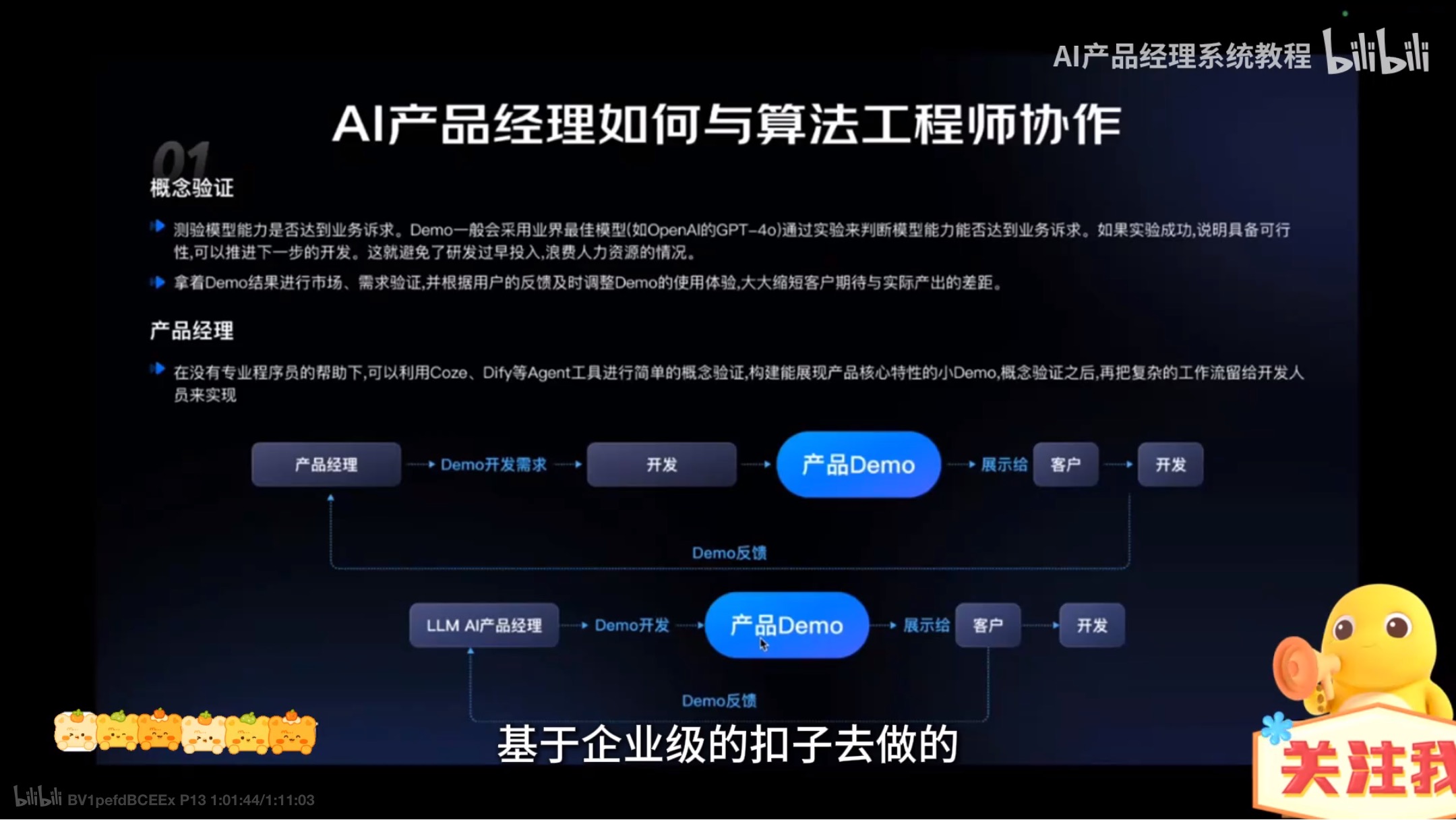
与算法工程师协作


其他相关能力
模型评测
知识库构建
模型评估
先要确定模型具备相关能力了再去简历相应的知识库
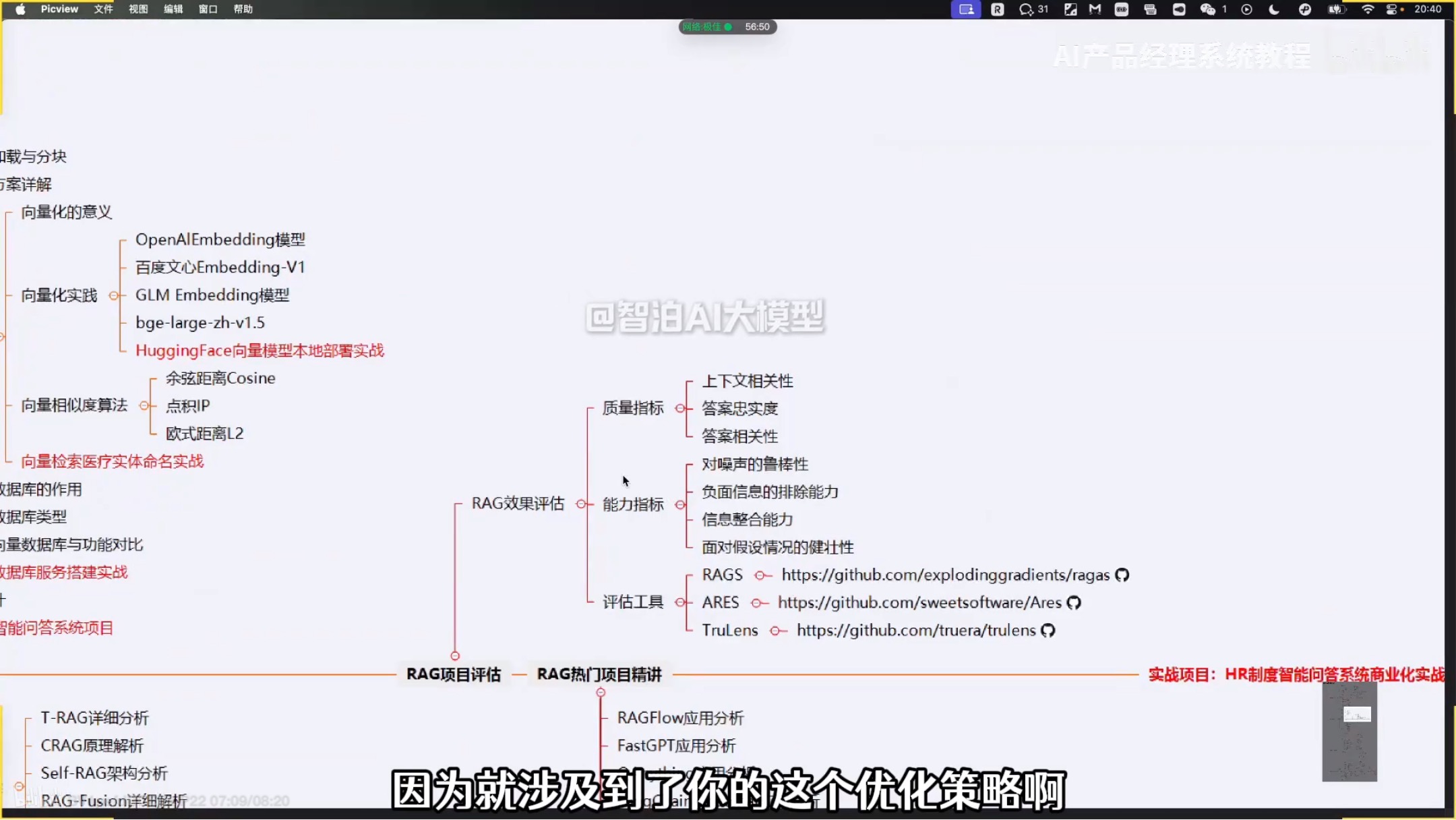
RAG
为什么需要RAG--大模型具有局限性
知识过时
幻觉问题(编造看似合理但错误的信息)
缺乏特定领域知识(如专业数据库、如公司内部文档)
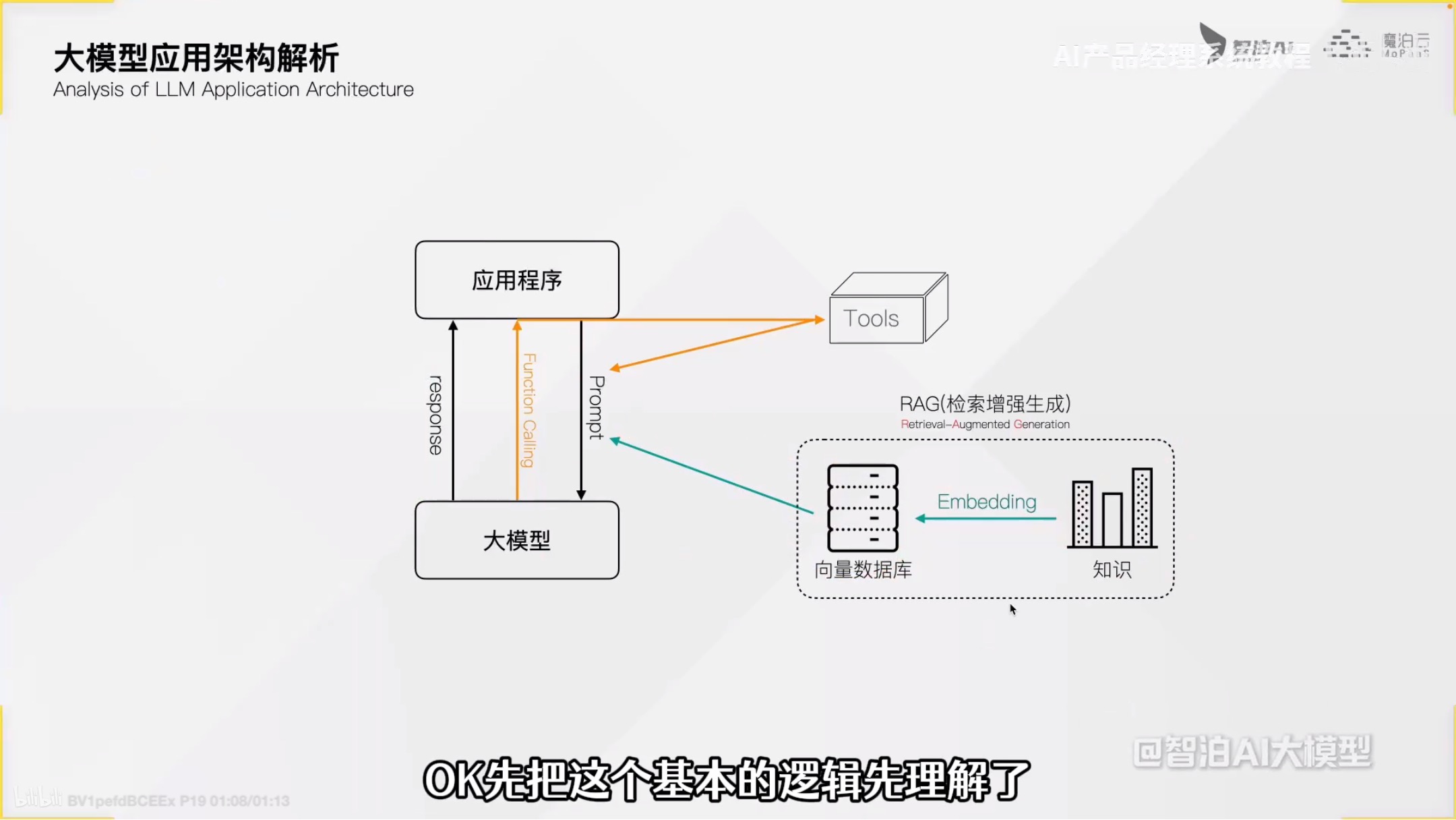
什么是RAG
由两部分组成:
检索模块:在知识库中检索
生成模块:将检索结果与原始输入,通过大模型生成准确、丰富的回答
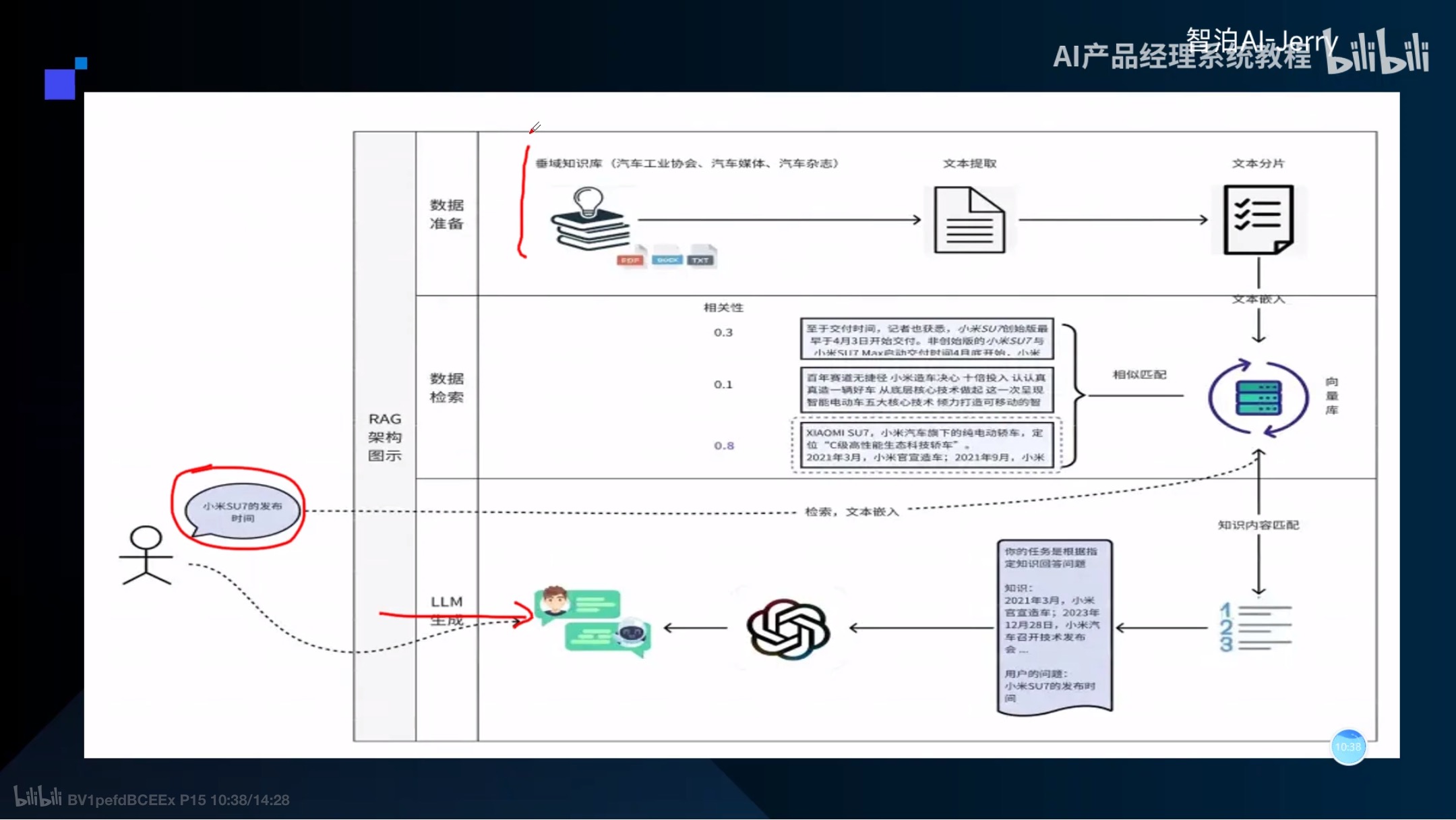
基于文档的LLM回复系统
文档分割
根据句子分割,一个句子一个chunk
按照字符数切分,设置固定的字符数,不连贯
按照固定字符,设置固定字符,结合一定的重复字符
递归方法,设置固定的字符,结合一定的重复字符,再加对应的语意
simple chunk
直接按照固定的字数切分,不推荐;
semantic chunking
不再硬性规定chunk大小,而是计算相邻句子间的相似度,当相似度低于阈值时进行分段。也就是说可以保证分在同一个chunk里的内容都是同一主题的
small-to-big retrival
检索时匹配小的chunk,但在喂给模型时,自动替换为包含该小块的父文档或更大的chunk
context enriched retrival
检索到最相关的chunk后,自动带出其物理位置前后的N个chunk,补充上下文环境。
contextual chunk headers
在分块时,将全文标题或章节摘要作为Header拼接在每个chunk头部
document augmentation文档增强
在检索阶段,让LLM针对每个chunk预生成几个可能的问题,检索时匹配这些预设问题
query transformation
包括查询重写(Rewrite)、回溯提示(Step-back)和子查询分解
reranker重排序
通过向量匹配初筛出Top50,再用高精度二分排位模型(Cross-Encoder)精选Top5:通过给前50的句子的相似度再重新打分后排序
RSE(Relevant Segment Extraction)
检索连续的,具有聚合相关性的片段,而不是孤立的向量Top-K
流程:相似度过滤--上下文窗口查找--片段总分值计算--阈值筛选
Contextual Compression
获取更多的chunk,然后压缩它,过滤之和query相关的句子再给到LLM
Feedback Loop
记录用户交互和LLM反思,动态调整文档权重,实现检索自进行化
用户查询--检索--生成--收集反馈--存储并反思--权重重标定
Self RAG
模型自我反思:是否需要检索?检索结果是否相关?生成内容是否由数据支撑?
Knowledge Graph
从文档中抽取实体entity和关系relationship。在检索时,不仅根据向量搜索相关实体,还沿着关系边进行图搜索(Graph Traversal),挖掘章节、跨文档的隐性关联信息。(成本高,但是准确率高)
Hierachical Indicates
系统通过两级向量库(Summary/Chunk)实现:Query先在粗颗粒度的Summary库中定位相关章节,再在这些特定章节的细粒度chunk库中进行精确检索
HyDE(Hypothetical Document Embeddings)
先让LLM生成一个“假答案”,用假答案的向量去检索真文档。
Fusion
向量(语义)检索+BM25(关键词)检索,通过RRF算法进行结果融合。
CRAG(Corrective RAG)
c是指Corrective:纠错的过程。通过对检索到的内容进行相关性评分(高/中/低),动态决定回答策略,高相关性直接回答,中相关性结合Web补充,低相关完全依靠Web
文本向量化
过程
tokenization(把一个句子分为不同的字/词为一个token)-->向量化(计算每个token的各纬度的相关度)
余弦距离cos:基于两个向量夹角的余弦值来衡量相似度
向量数据库
也叫矢量数据库,主要用来存储和处理向量数据
检索方法
单独比较(类似于全表扫描)
index
Approximate Search(近似搜索),更准确地说是Approximate Nearest Neighbor Search(ANNS,近似最近邻搜索)
LSH 局部敏感哈希
IVF(倒排文档)+PQ(乘积量化)
HNSW
DiskANN
向量数据库举例:
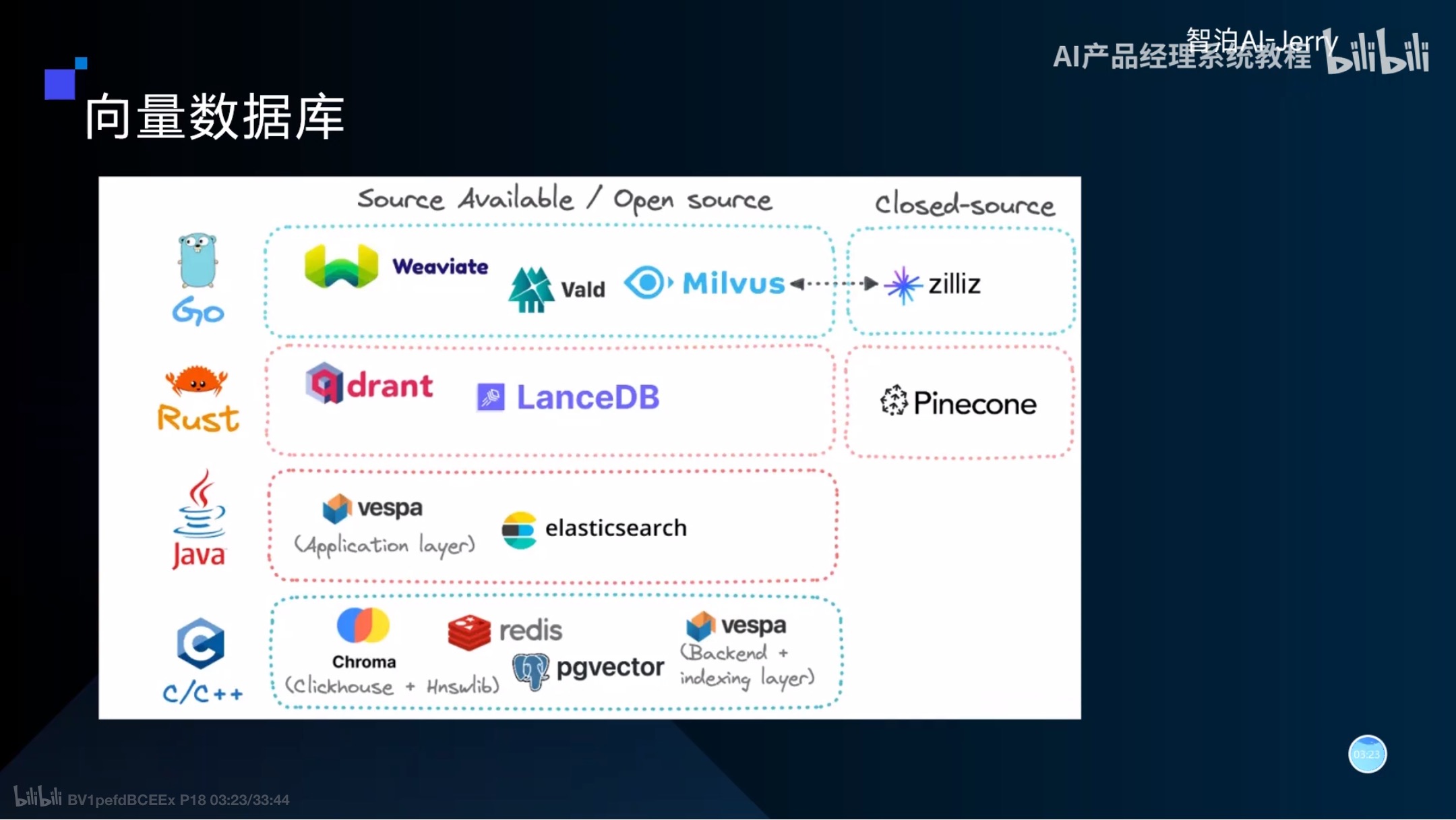

向量比较
按照余弦相似度、距离、欧氏距离等进行比较
RAG实战中常见问题
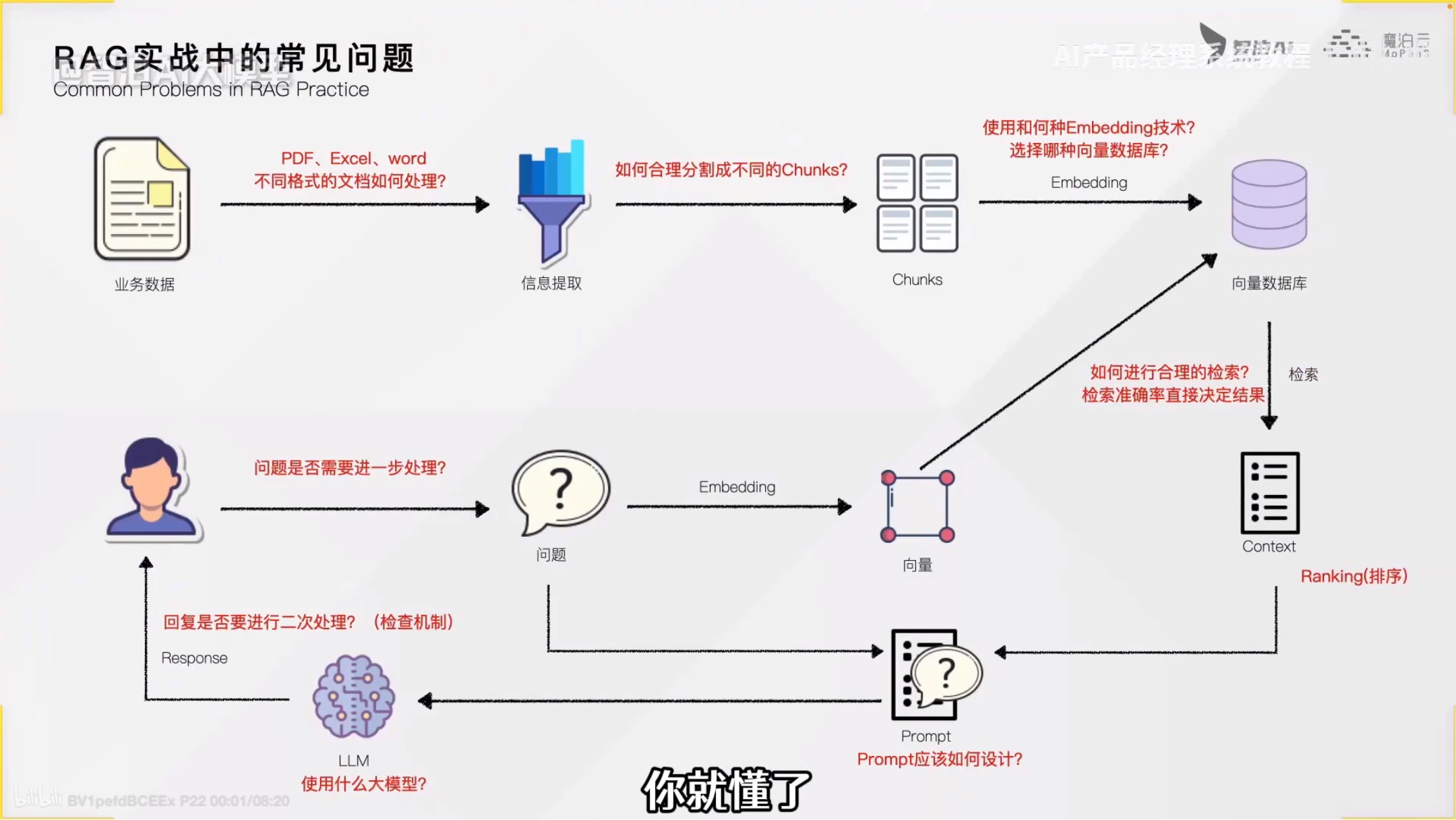
1.信息如何有效的提取?
A. 不同格式文档怎么处理(eg如果资料既有图片又有文字怎么办)?
用多模态的方式使用文字去表述图片内容
或者自己定制化一个向量数据库
2.如何分割成不同的chunks?
太细的chunks可能会有语义丢失
3.使用和何种Embedding技术?选择哪种向量数据库?
上魔达社区可以搜索到不同的模型
4.如何进行合理的检索?检索准确率直接决定结果
5.prompt该如何设计?
例如:编码的场景用Json会更适合
{
“project_name”: “智能助手开发”,
“version”: “1.0.0”,
“overview”: “本项目旨在开发一款基于大模型的智能助手”,
“features”: [
“自然语言理解”,
“任务规划与执行”,
“多轮对话管理”
],
“tech_stack”: {
“language”: “Python 3.9+”,
“model”: “GPT-4”,
“framework”: “LangChain”
},
“notes”: “开发过程中需重点关注模型的推理效率。”
}普通常态的交互用Markdown会更好一些
Markdown 是一种轻量级的标记语言,它的核心思想是让人们使用易读易写的纯文本格式编写文档,然后可以转换成有效的 HTML。
简单来说,它就是用一些简单的符号来给纯文本添加格式,但看起来依然很清爽。
常见的 Markdown 语法:
-
标题:
# 一级标题、## 二级标题 -
加粗:
**加粗文字** -
列表:
-
无序列表:
- 项目一或* 项目一 -
有序列表:
1. 项目一
-
-
代码块:用三个反引号 ``` 包裹起来,可以指定语言(如 python)实现语法高亮。
-
引用:
> 这是一段引用 -
表格:使用
|和-来创建表格。
6.使用什么大模型比较好?
大模型的参数不是越大越好
7.回复是否要进行二次处理?(检查机制)
要和文化传统,法律法规,价值文化对齐
e.g. 360儿童手表回答诋毁事件
检索前优化
微调ebedding模型
混合检索
问题转换(针对具体场景转换用户问题)
检索后优化
召回重排
信息压缩
知识融合
设计前问题?
如何将产品拆分为每个不同的模块?每个模块回复的评价标准是怎样的?
RAG还是微调?
知识是不断更新的就推荐用rag,80%以上的都用rag

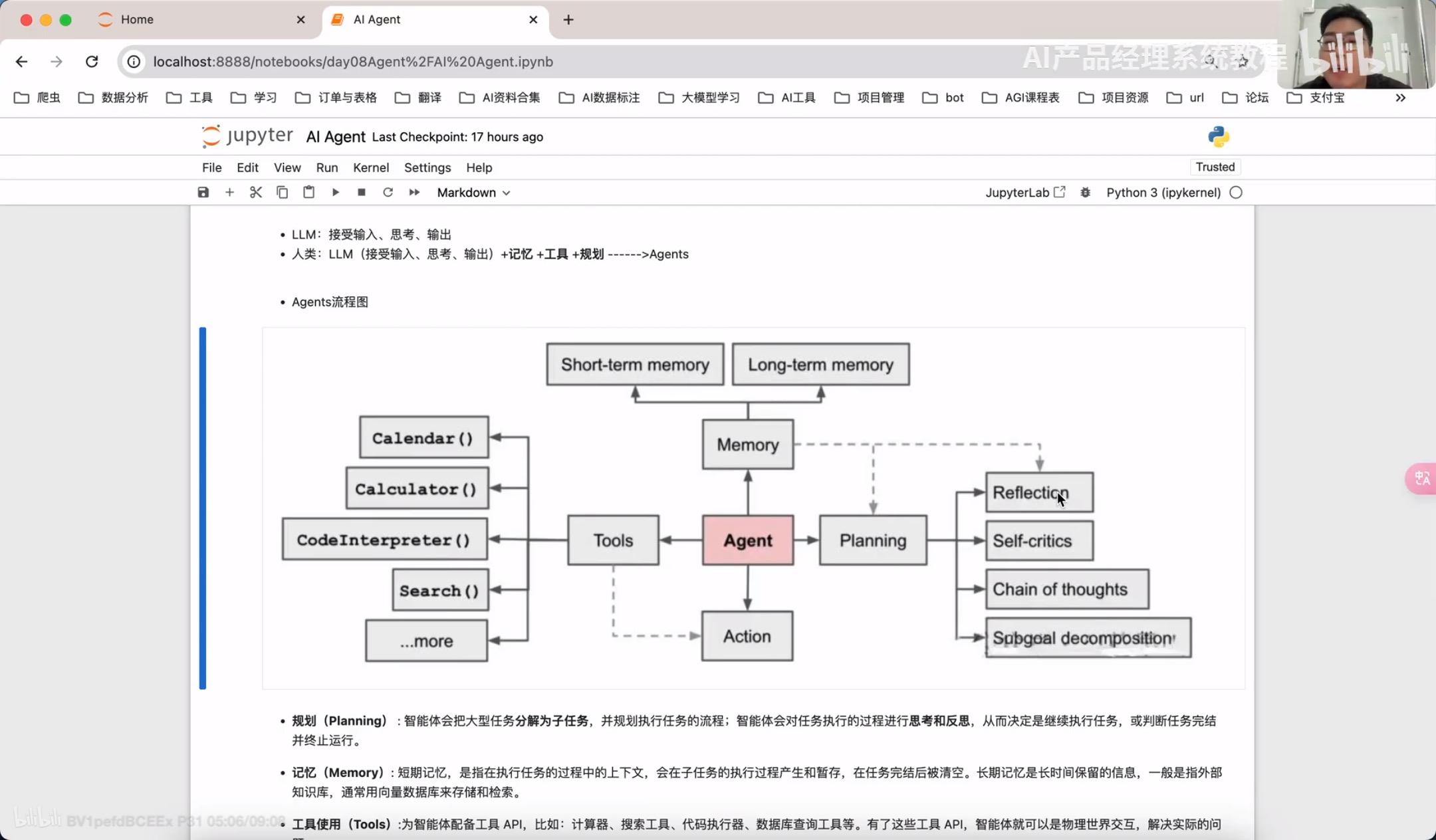
AI Agent
根据任务的工作流进行定制
Agent=LLM+memory+planning skills(规划)+tool use(工具)
记忆:长期记忆(回调);短期记忆(rag)
应用场景:text to SQL
拆解
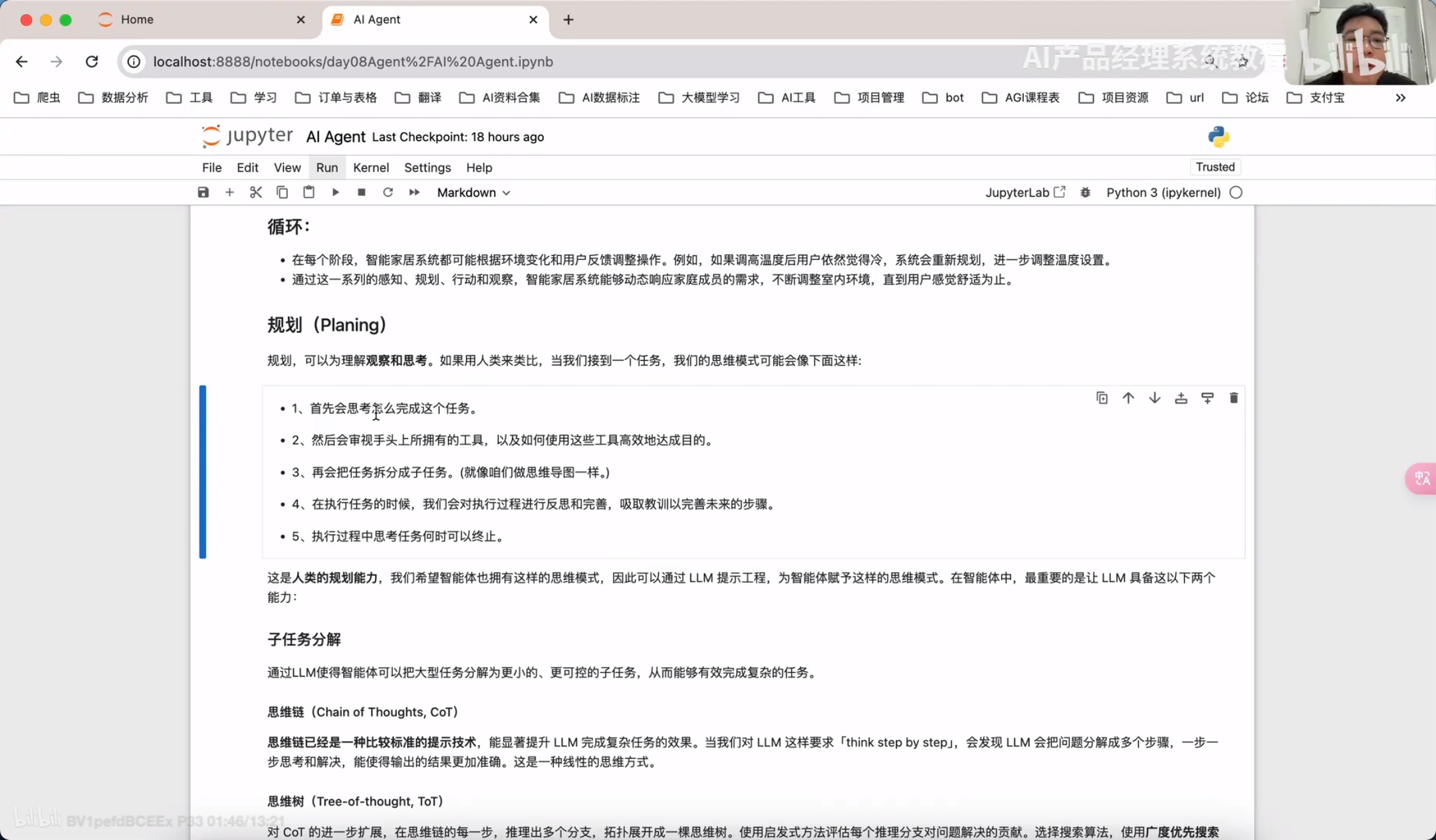
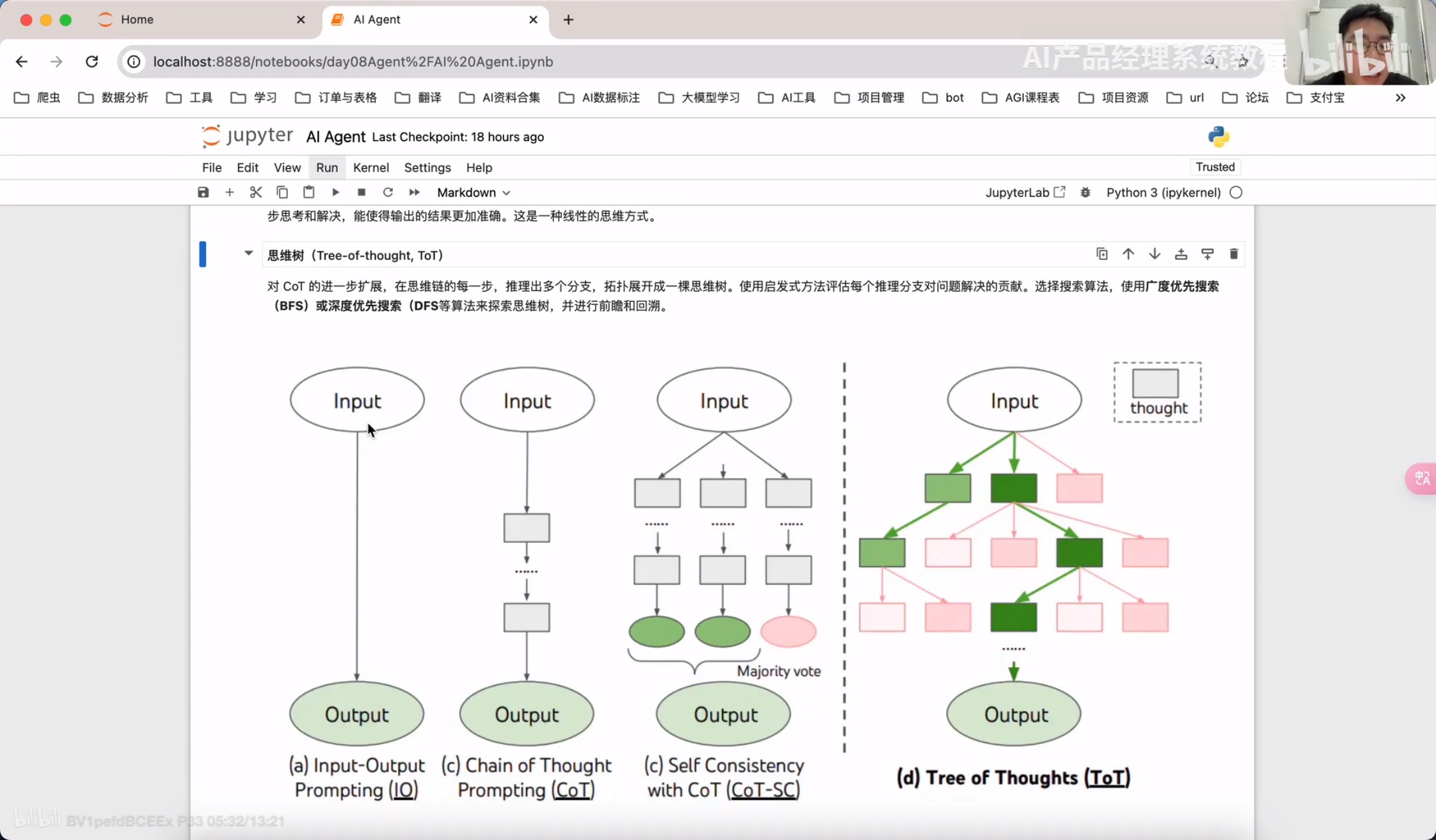
plannig规划拆解
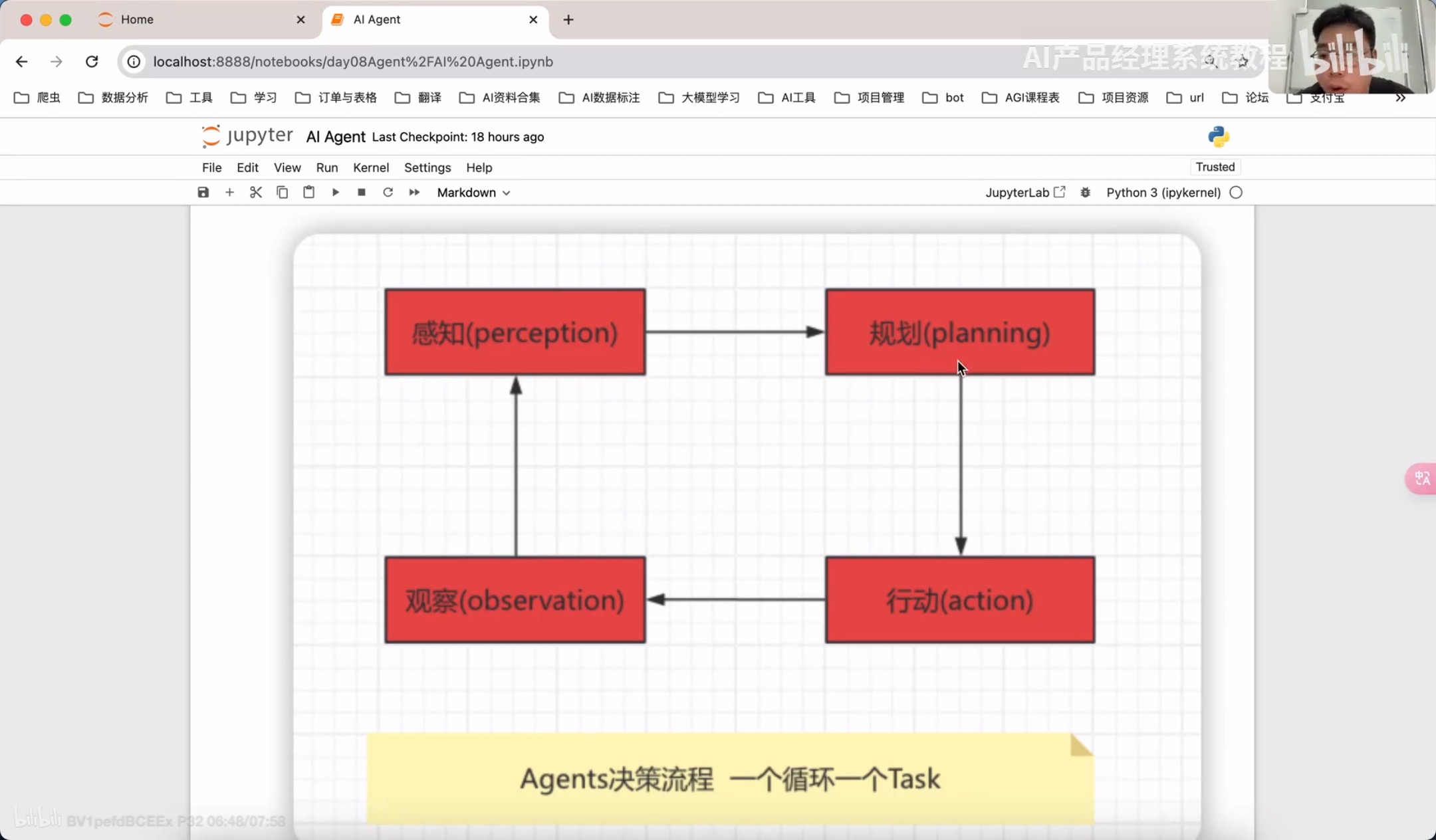
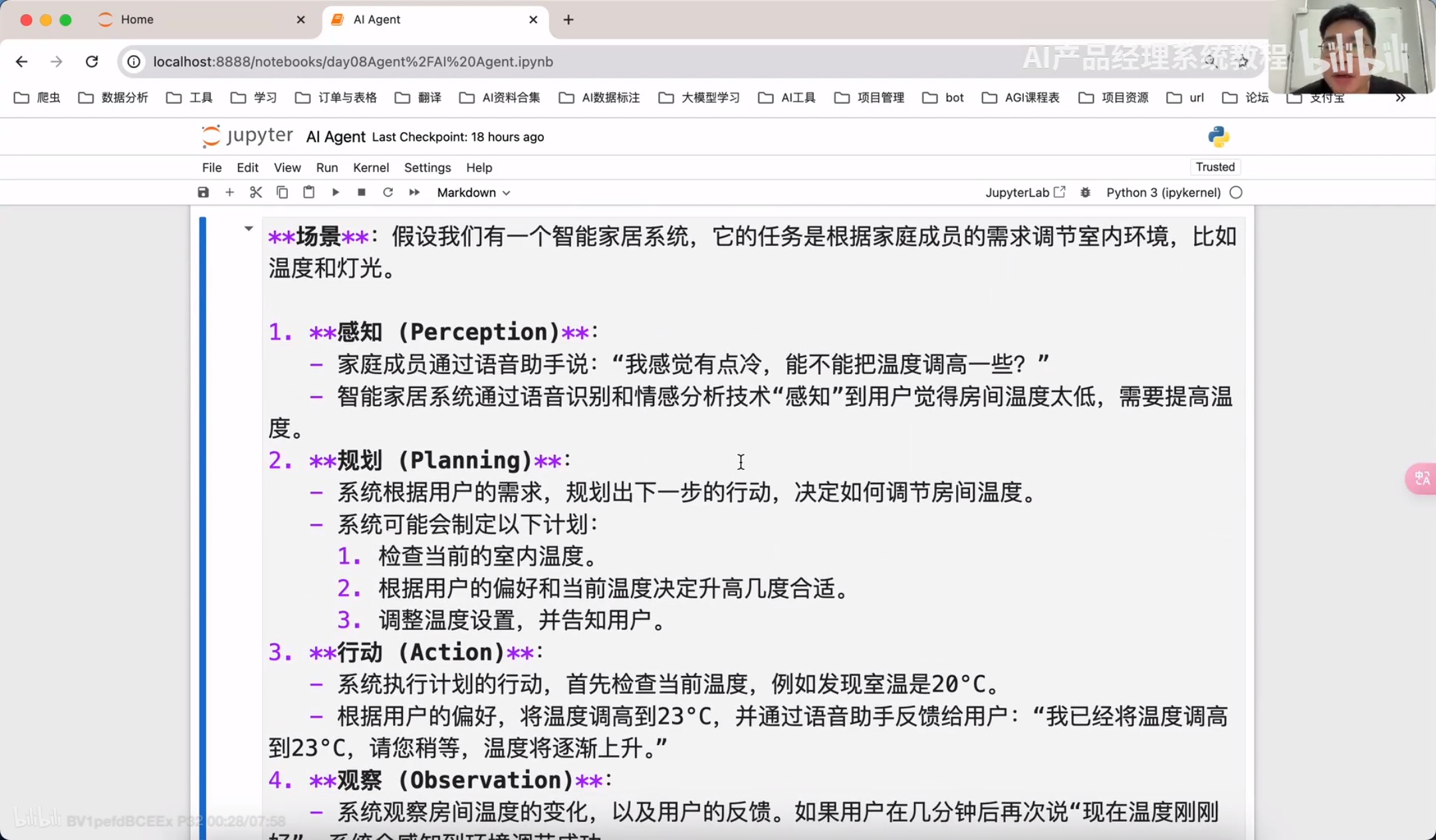
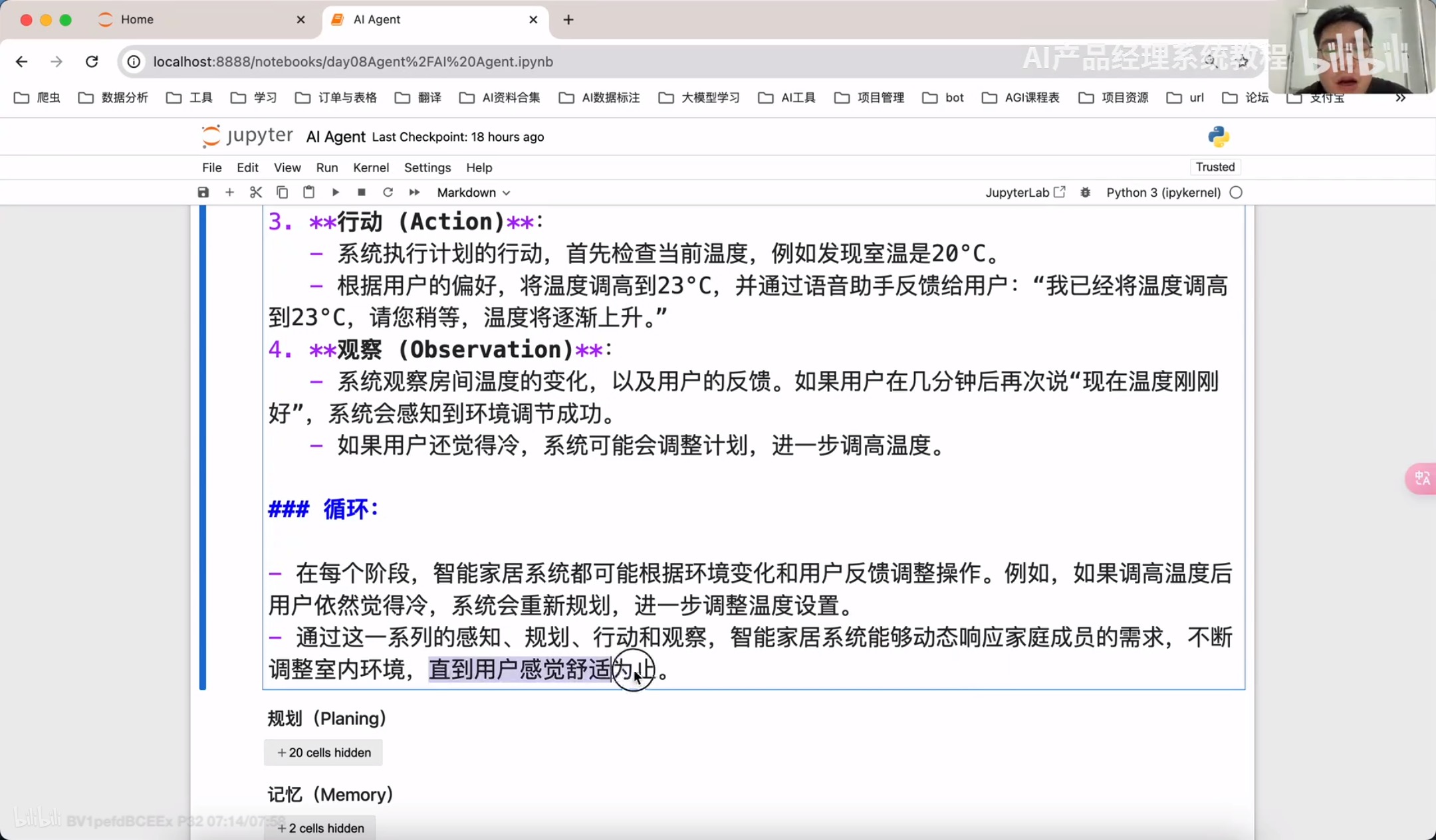
规划(Planning):智能体会把大型任务分解为子任务,并规划执行任务的流程;智能体会对任务执行的过程进行思考和所思,从而决定是继续执行任务,或判断任务完结并终止运行。
记忆memory
记忆(Memory):短期记忆,是指在执行任务的过程中的上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空。长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索。
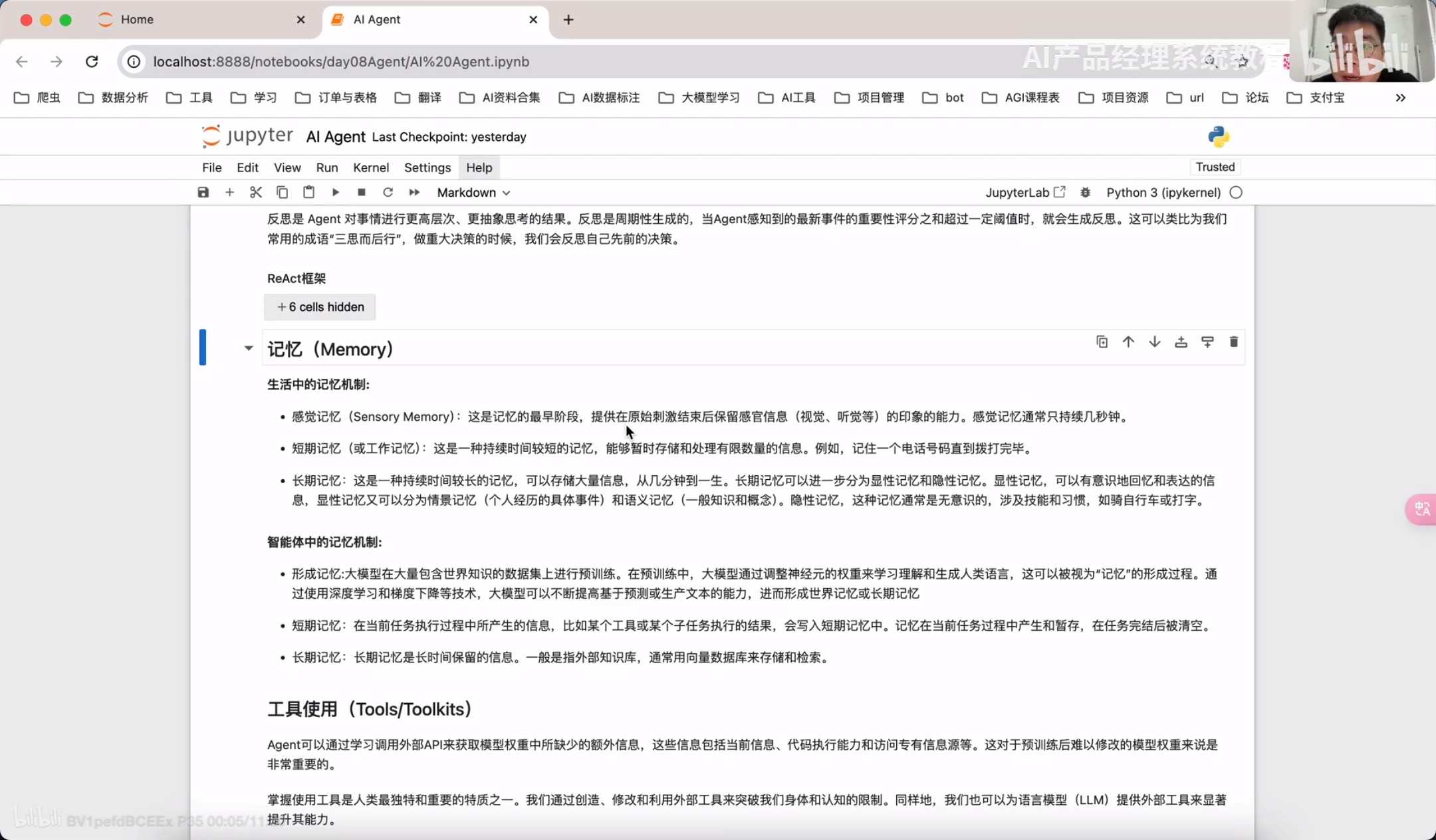
工具使用Tools/Toolkits
工具使用(Toos):为智能体配备工具 API、比如:计算器、搜索工具、代码执行器、数据库查询工具等。有了这些工具 API、智能体就可以实现物理世界交互,解决实际的问题。
执行Action
执行(Action):根据规划和记忆来实施具体行动,这可能会涉及到与外部世界的互动或通过工具来完成任务
其他Agent框架与策略分析
其他Agent认识框架
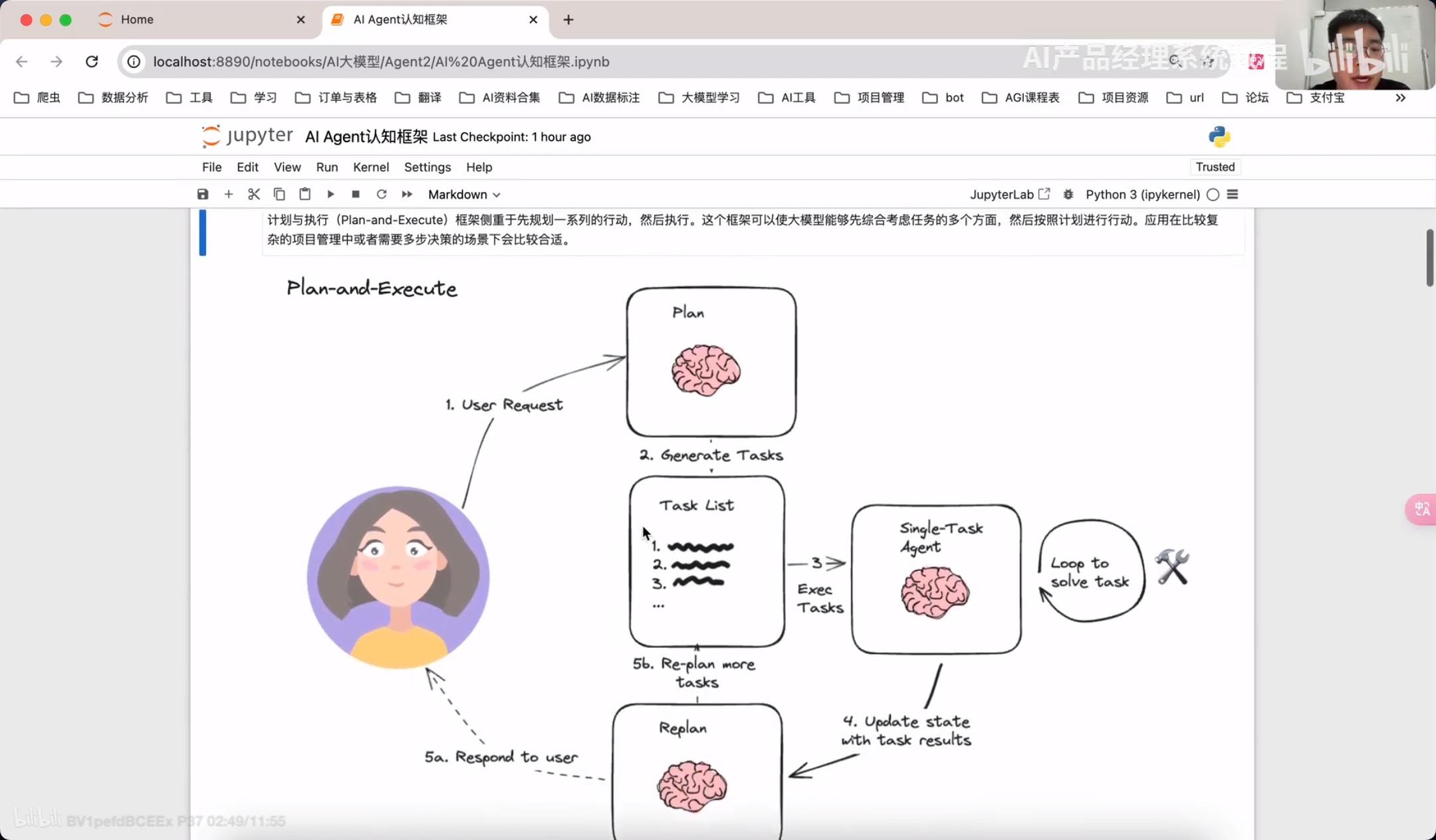
Plan-and-Execute
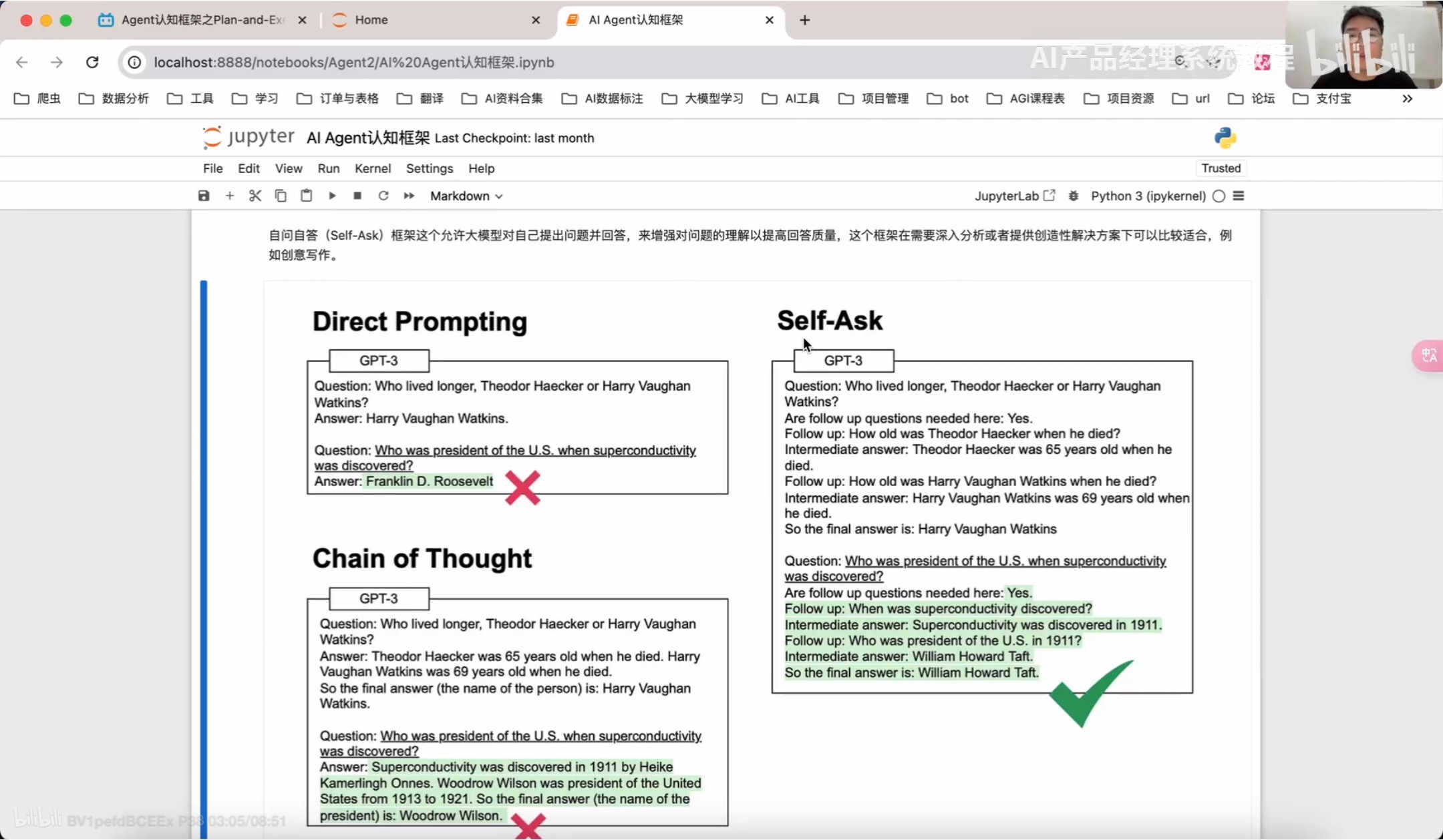
Self-Ask
Thinking and Self-Refection
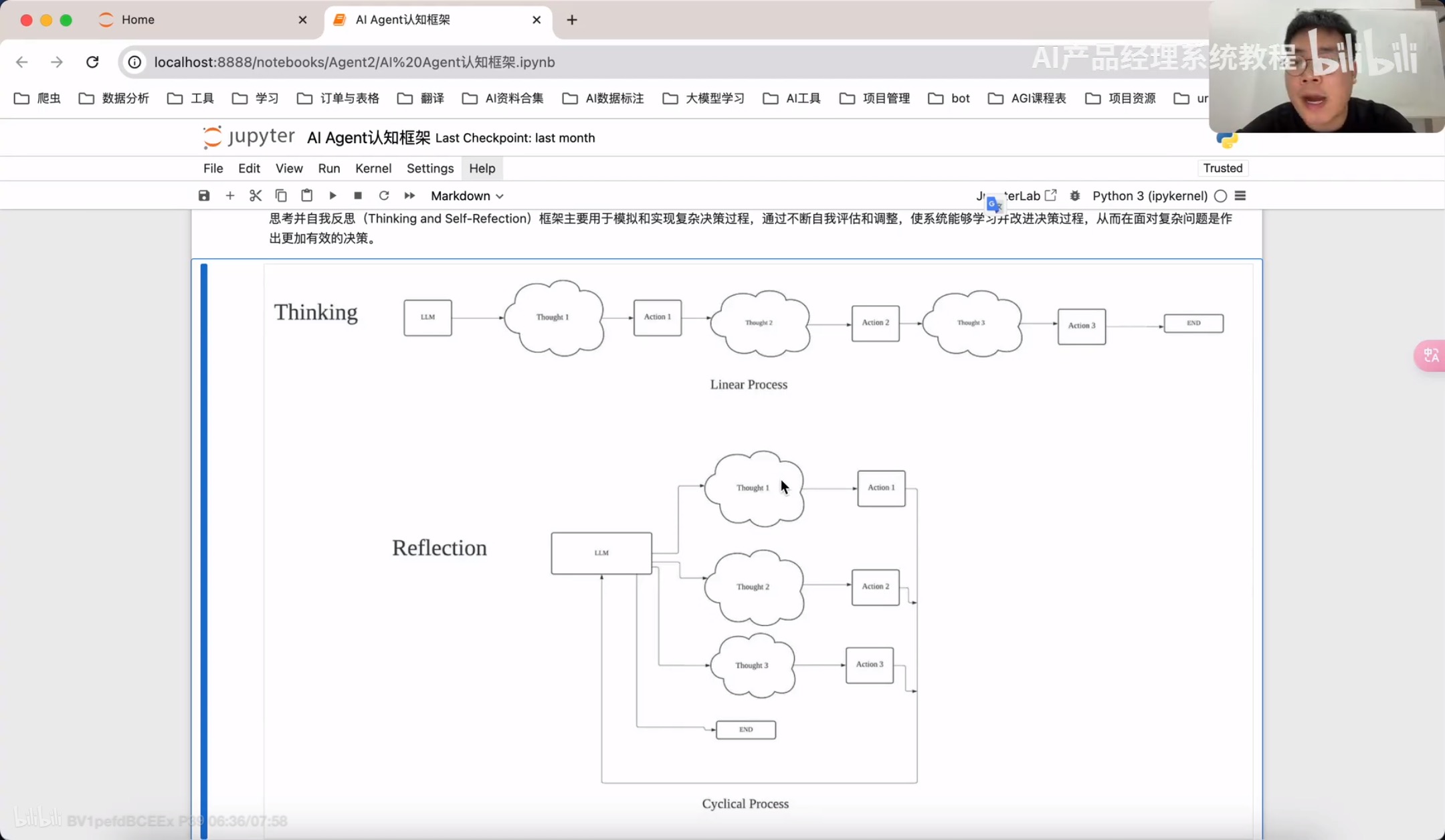
React框架
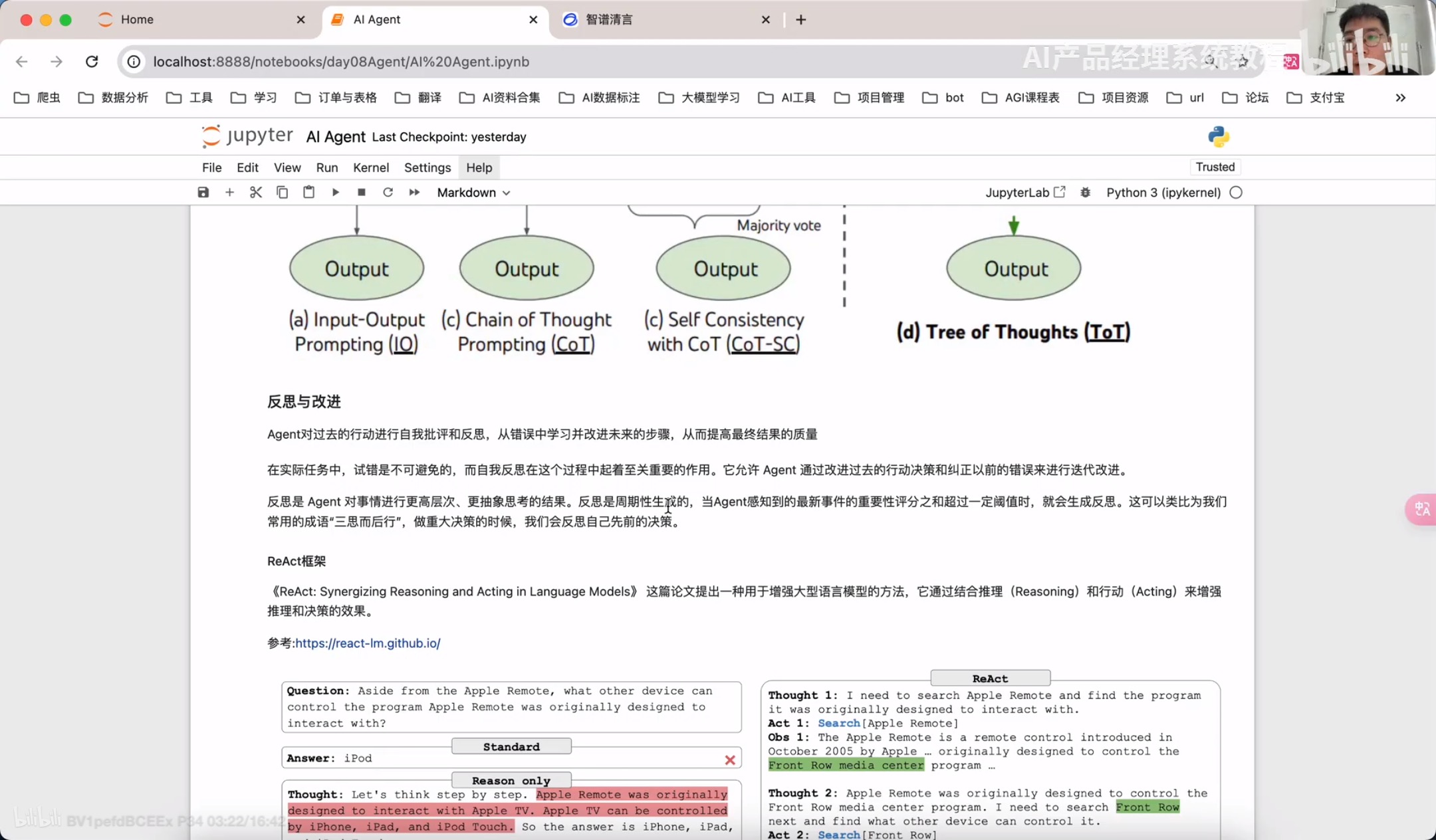
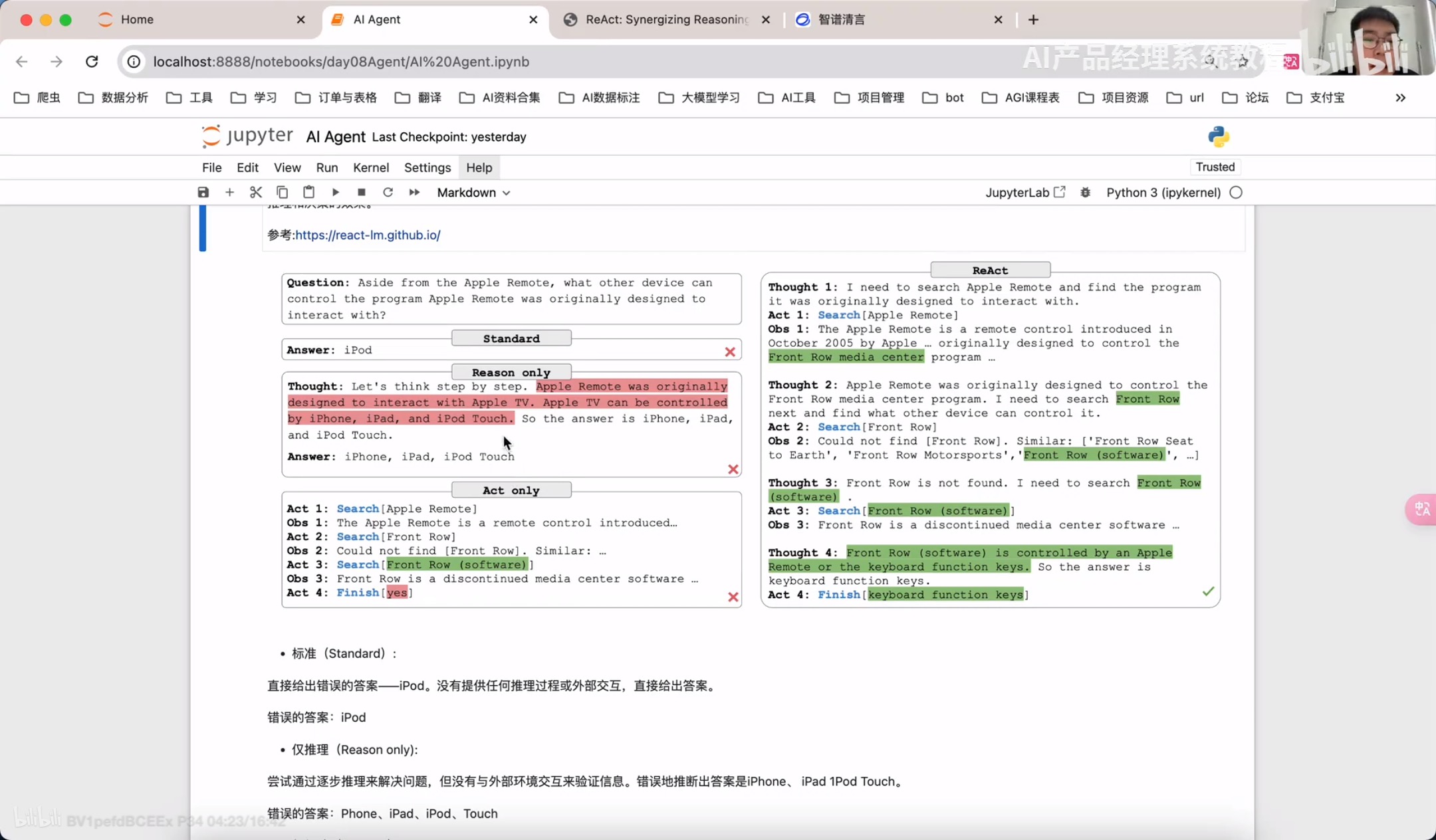
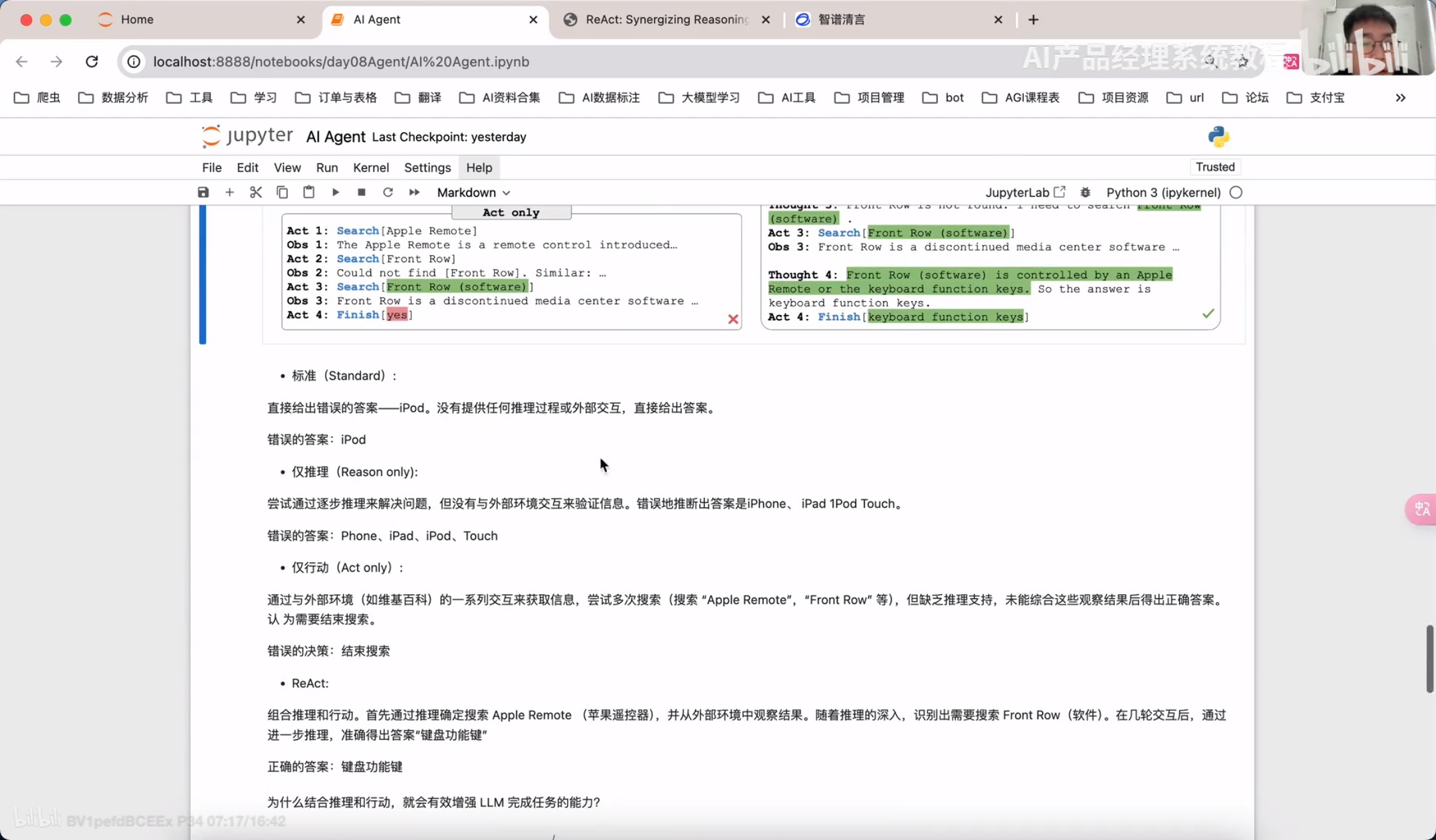
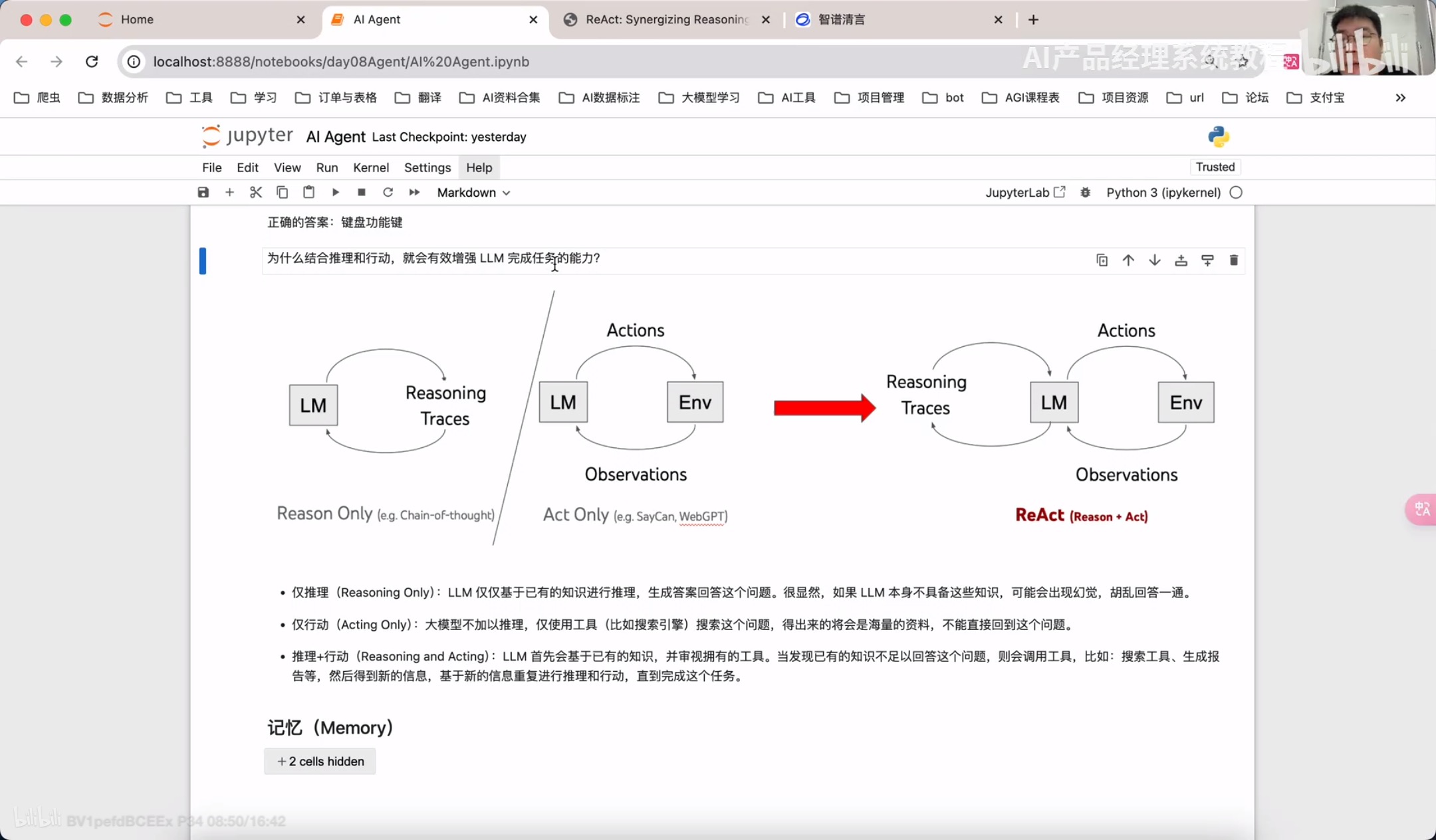
通过llamindex实现React RAG Agent
智能体开发框架
(微软Autogen,crowagent)
Agent(智能体)开发框架旨在简化构建自主或半自主 AI 系统的过程,特别是那些能够使用工具、进行多轮对话、执行复杂任务以及协作解决问题的智能体。
Agent(智能体)开发框架旨在简化构建自主或半自主 AI 系统的过程,特别是那些能够使用工具、进行多轮对话、执行复杂任务以及协作解决问题的智能体。随着大语言模型(LLM)的普及,涌现出大量专注于 LLM Agent 的开源框架。以下是当前常见的几类框架及其简要介绍:
1. LangChain
简介:最流行的 LLM 应用开发框架之一,提供了丰富的组件(如 Chains、Agents、Memory、Tools)来构建复杂的 Agent 工作流。
特点:
支持多种 LLM 模型(OpenAI、Hugging Face 等)。
内置多种 Agent 类型(如 Zero-shot ReAct、Conversational 等)和工具(如搜索引擎、计算器)。
与 LangSmith、LangServe 集成,便于调试和部署。
适用场景:构建基于 ReAct 模式的通用对话助手、RAG 应用、自动化工作流。
### 2. **AutoGen**
- **简介**:由 Microsoft 推出的多智能体协作框架,允许定义多个可对话的 Agent 并让它们通过对话协作完成任务。
- **特点**:
- 强调“对话即编程”,Agent 之间通过自然语言交互。
- 支持人类介入(Human-in-the-loop)和代码执行。
- 提供灵活的对话模式和群聊管理。
- **适用场景**:需要多个专业 Agent 分工合作的复杂任务,如代码生成、数据分析、多轮谈判模拟。
### 3. **Semantic Kernel**
- **简介**:微软的另一轻量级 SDK,专注于将传统编程语言(C#、Python)与 AI 能力结合,支持插件(Planners)实现目标驱动的 Agent。
- **特点**:
- 深度集成 Azure OpenAI,支持函数调用、记忆、规划。
- 强调“内核”(Kernel)概念,将技能、记忆、连接器统一管理。
- 适合与现有 .NET 或 Python 应用无缝集成。
- **适用场景**:企业级应用,需要将 AI 能力嵌入已有业务逻辑的场景。
### 4. **CrewAI**
- **简介**:专注于角色扮演的多智能体编排框架,允许定义具有不同角色(如研究员、写手)的 Agent,并分配任务形成工作流。
- **特点**:
- 简单直观的 API,基于“角色-工具-任务”模型。
- 内置层级管理(Manager Agent)和任务委托机制。
- 与 LangChain 工具兼容。
- **适用场景**:内容创作、报告生成、市场调研等需要多角色协作的流水线任务。
### 5. **Dify**
- **简介**:开源的 LLM 应用开发平台,提供可视化的 Workflow 编排,支持快速构建 Agent 并发布为 API。
- **特点**:
- 低代码/无代码界面,内置知识库、工具、插件市场。
- 支持 Agent 与 RAG 的混合模式。
- 提供完整的生命周期管理(调试、日志、监控)。
- **适用场景**:快速原型开发、非技术团队构建 AI 助手、中小企业部署私有 Agent。
### 6. **AgentGPT / SuperAGI**
- **简介**:这类框架聚焦于让用户通过 Web 界面直接创建和运行自主 Agent(类似 AutoGPT 的实现)。
- **特点**:
- 提供浏览器内的 Agent 配置和运行环境。
- Agent 可以自主规划、执行任务(如浏览网页、执行代码)。
- 通常开源,支持自定义工具和模型。
- **适用场景**:研究实验、个人自动化助理、探索自主 Agent 能力边界。
### 7. **RLlib**(强化学习领域)
- **简介**:Ray 生态下的强化学习库,用于训练分布式智能体,支持多智能体强化学习(MARL)。
- **特点**:
- 高度可扩展,支持各种 RL 算法(PPO、DQN、A3C 等)。
- 提供丰富的环境接口(如 Gym、PettingZoo)。
- 适合需要与环境交互学习策略的智能体。
- **适用场景**:游戏 AI、机器人控制、资源调度等传统强化学习任务。
---
**总结**:
- 如果你需要快速构建通用 LLM Agent,**LangChain** 和 **Semantic Kernel** 是首选。
- 多智能体协作推荐 **AutoGen** 或 **CrewAI**。
- 可视化开发可考虑 **Dify**。
- 研究自主 Agent 行为可选 **AgentGPT** 类框架。
- 强化学习场景则用 **RLlib**。
多Agent协作
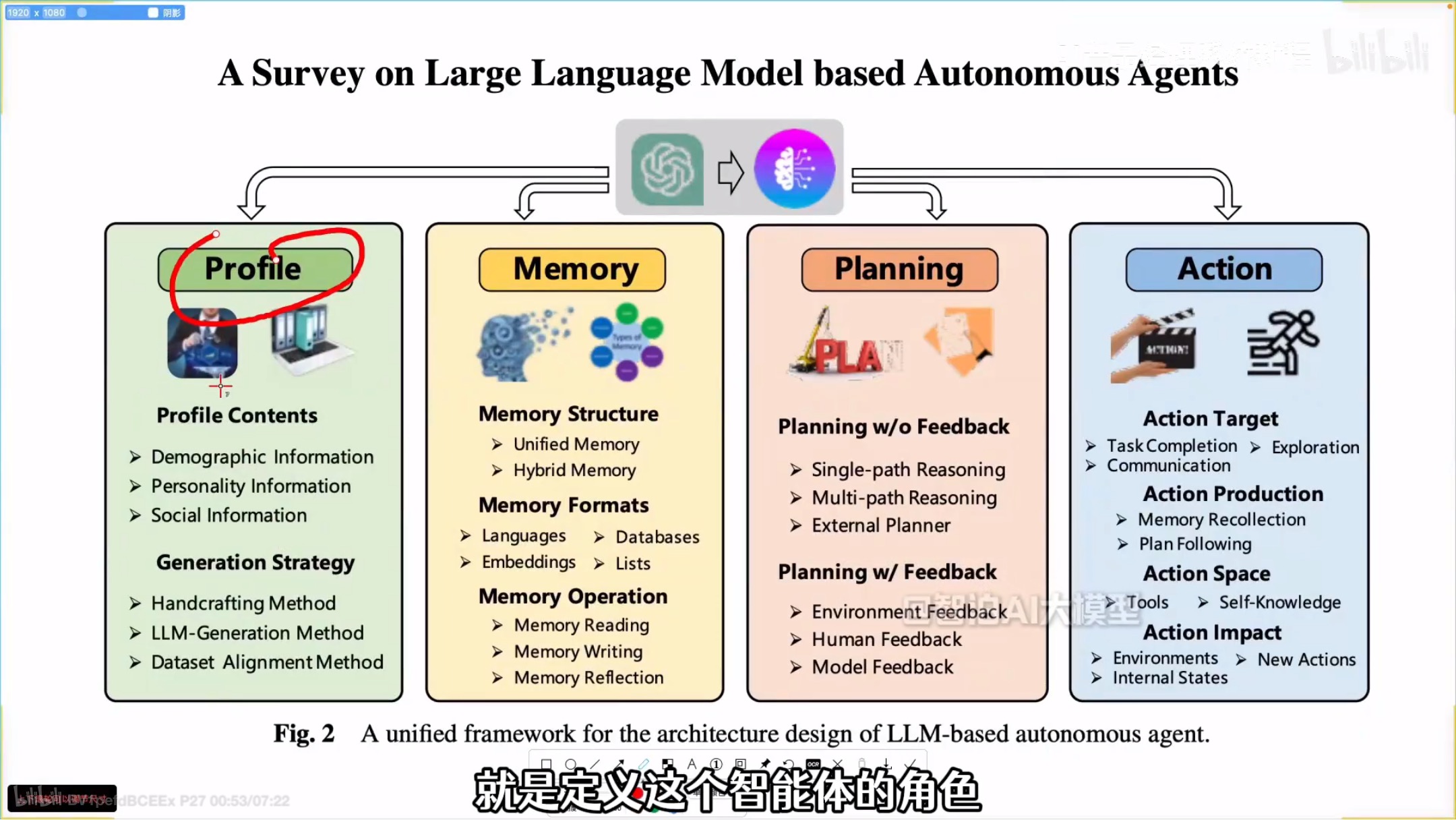
profile:用prompt定义边界和能力
memory
planning:怎么将大的任务进行拆解/规划
action:将什么任务给什么智能体,再将执行结果反馈给memory,memory再给planning,直到planning觉得可以了,就结束循环
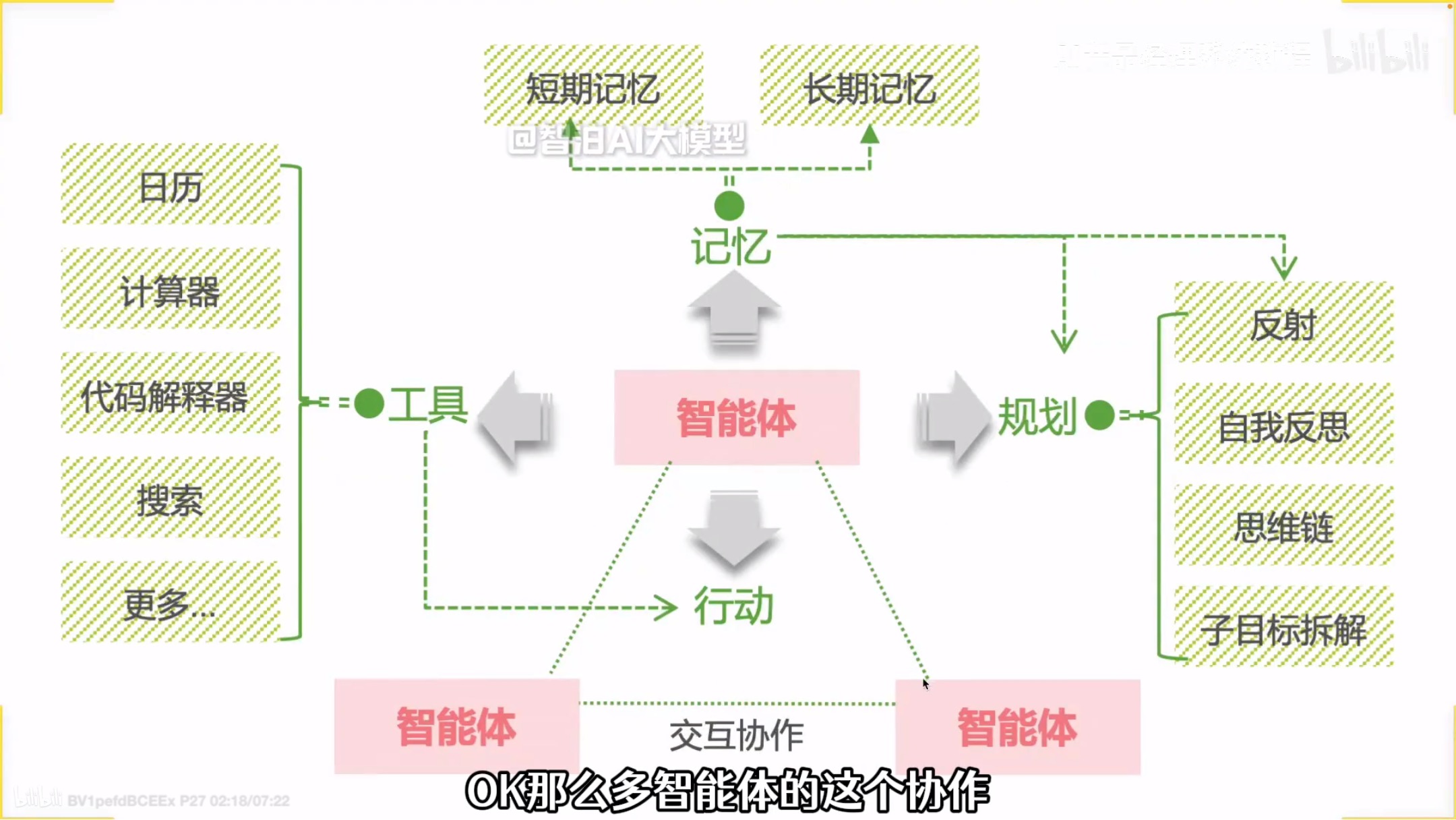
单智能体和多智能体对比:
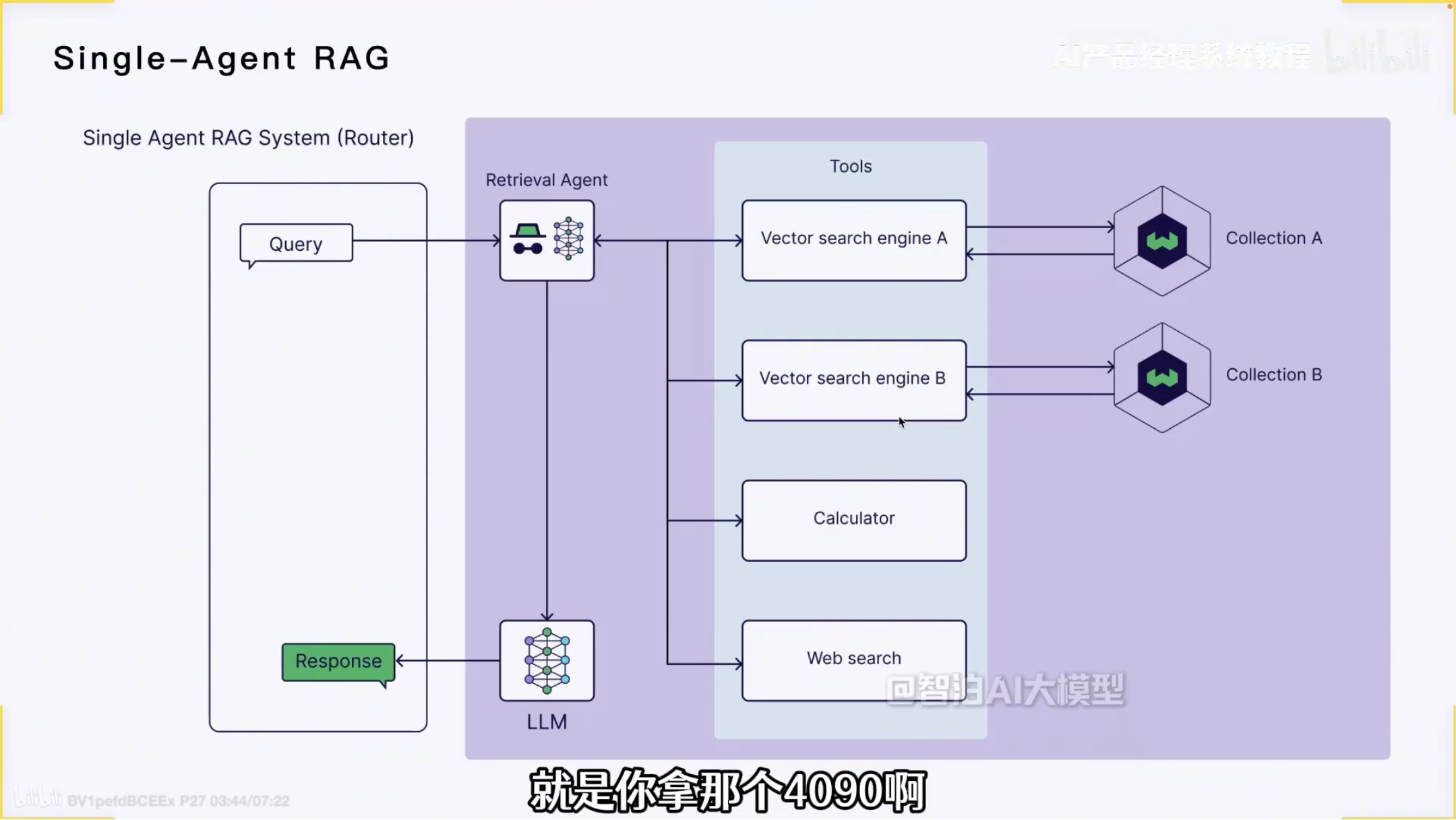
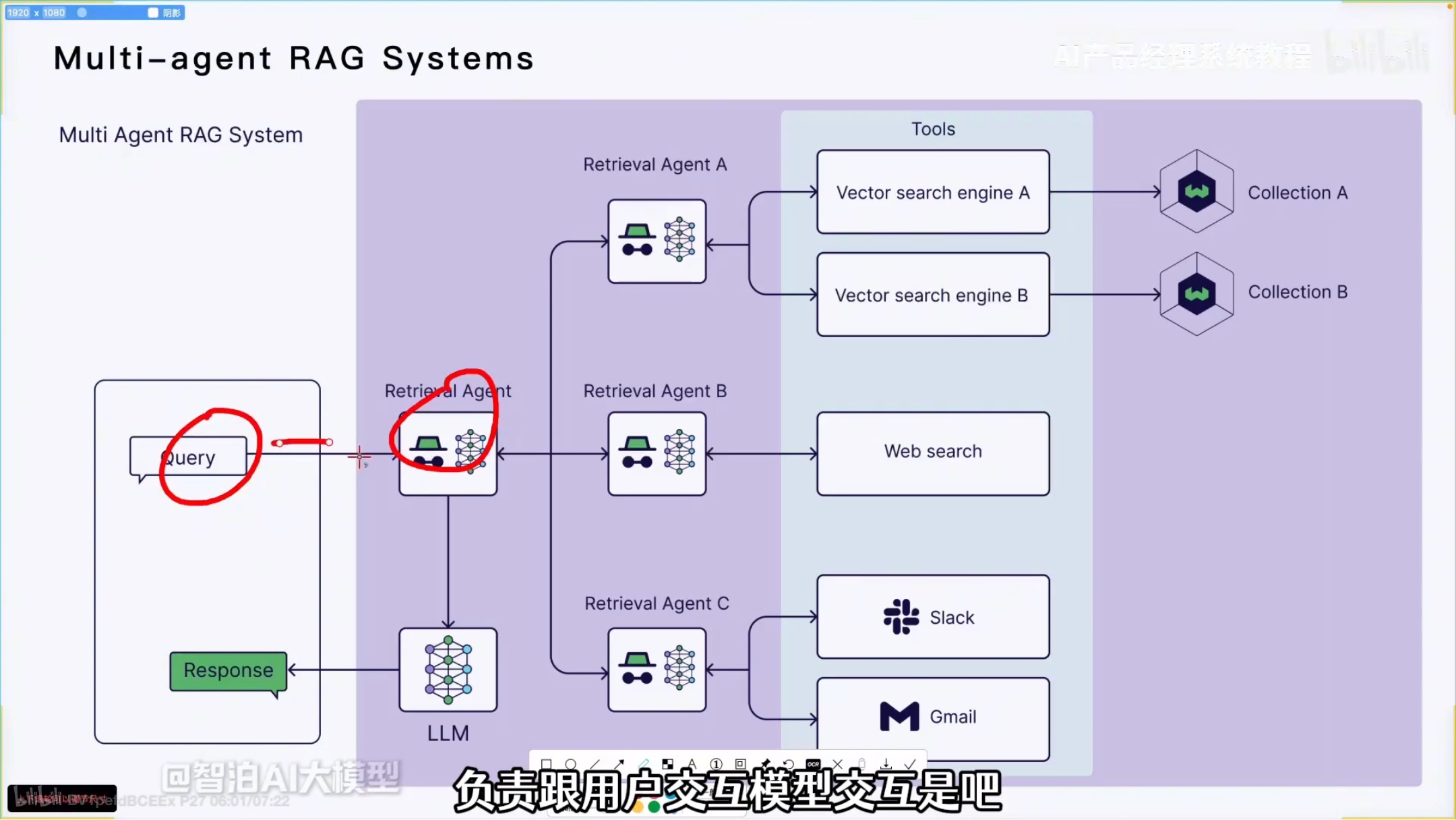
举例
大模型+智能客服

自动化测试
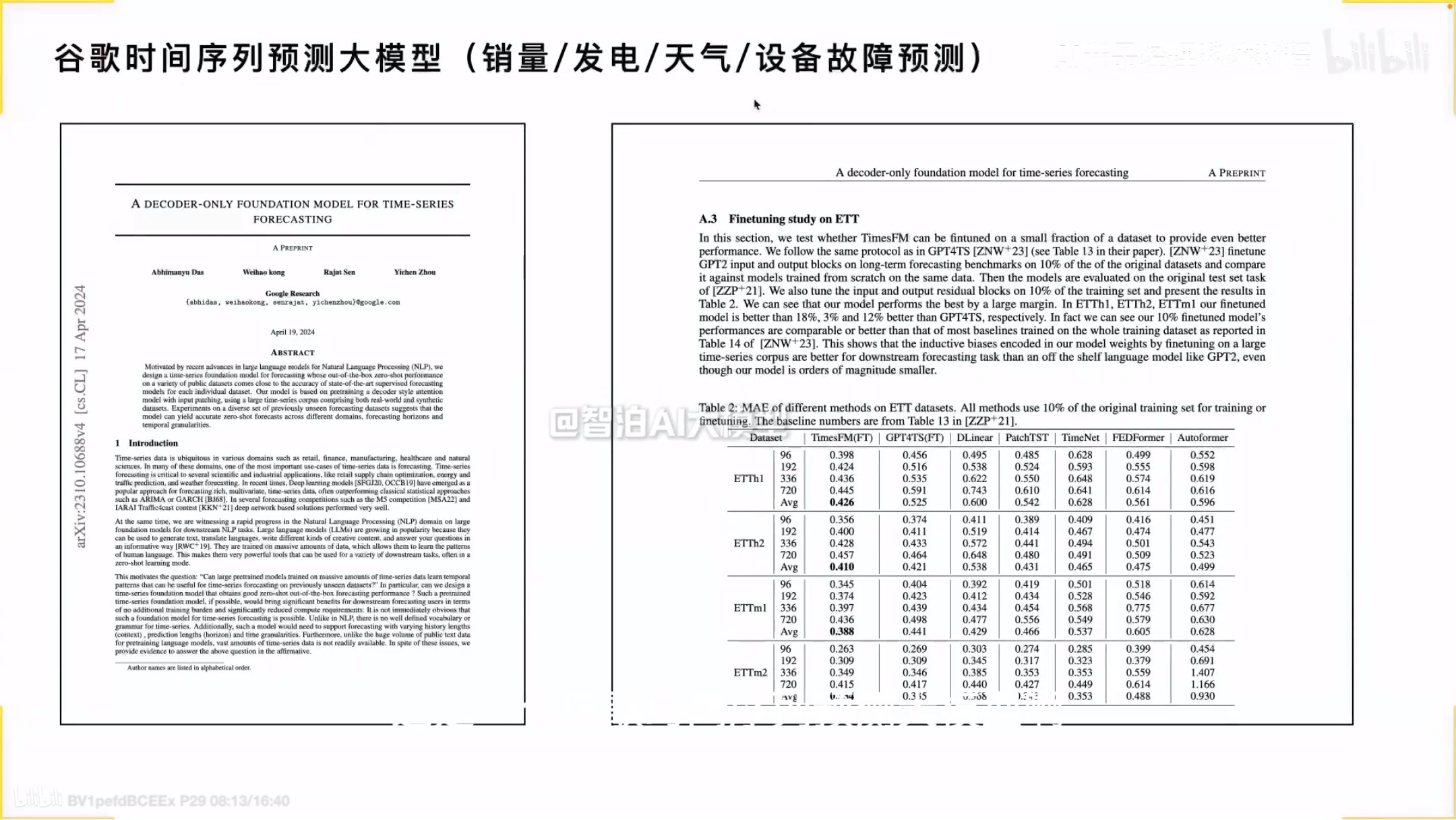
预测大模型
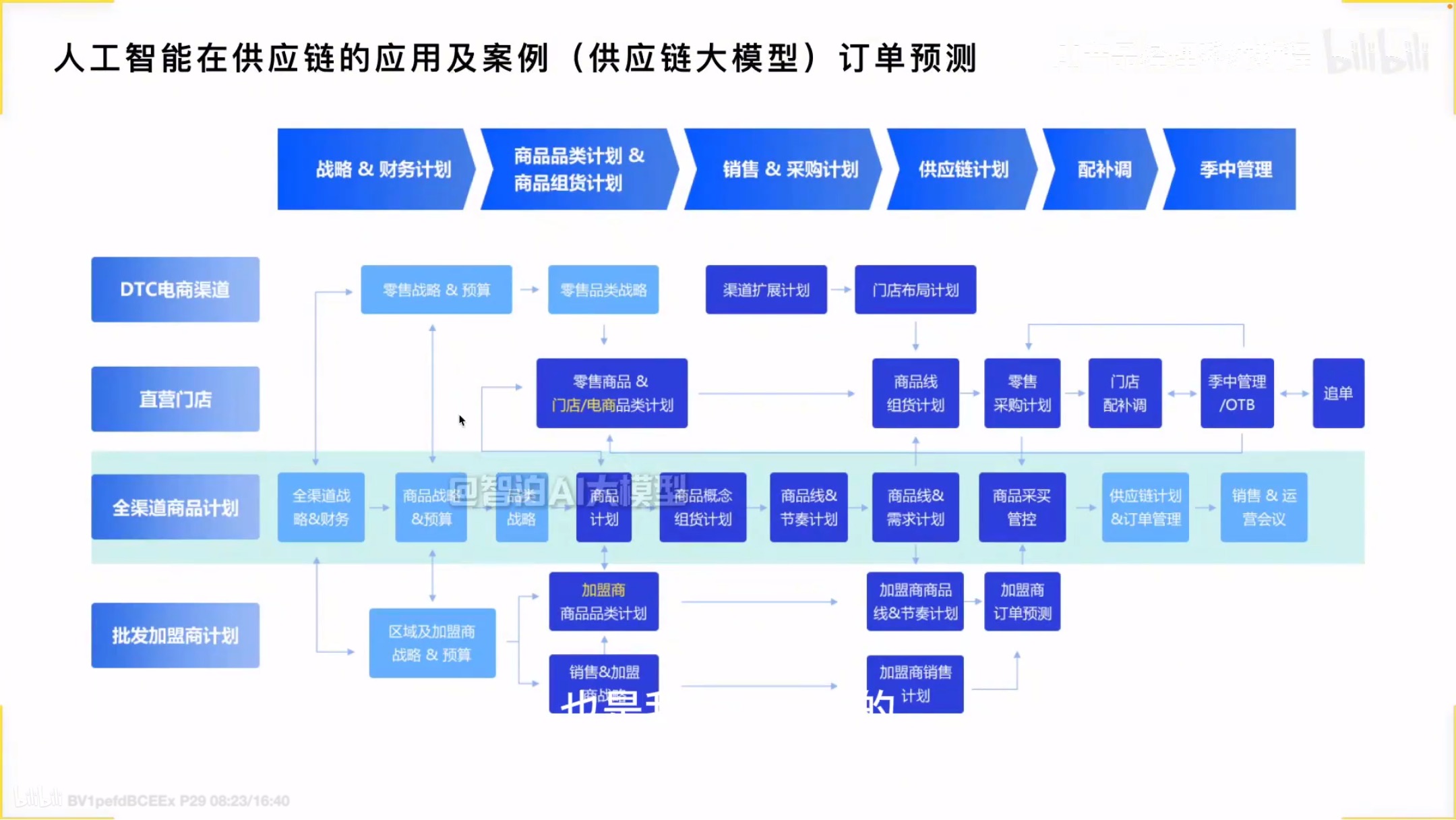
供应链
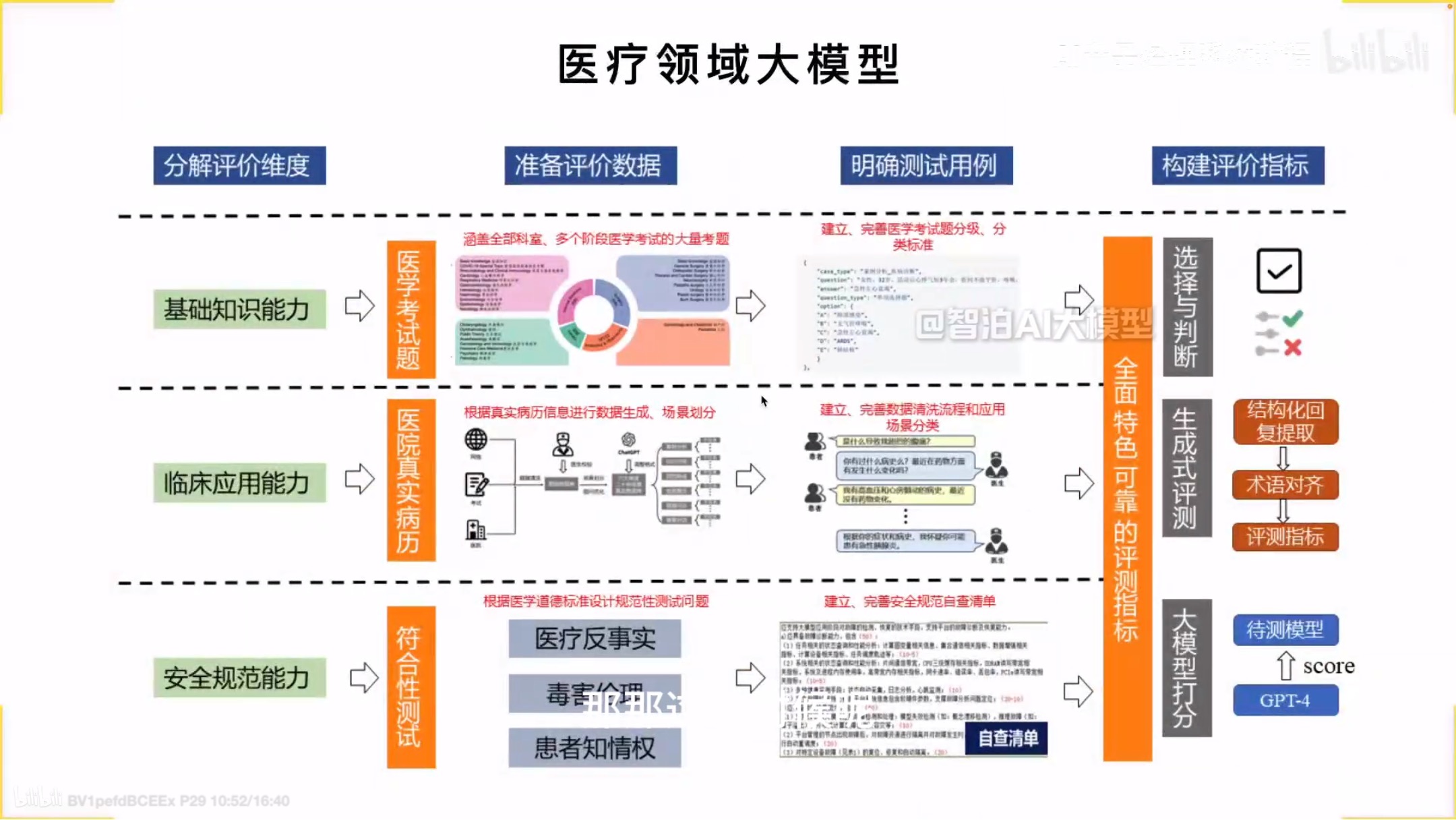
医疗领域大模型
人力资源
决策场景
Agent数字人
提示词工程
其他概念
泛化:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)