字节开源版Seedance发布,超越Sora 2!
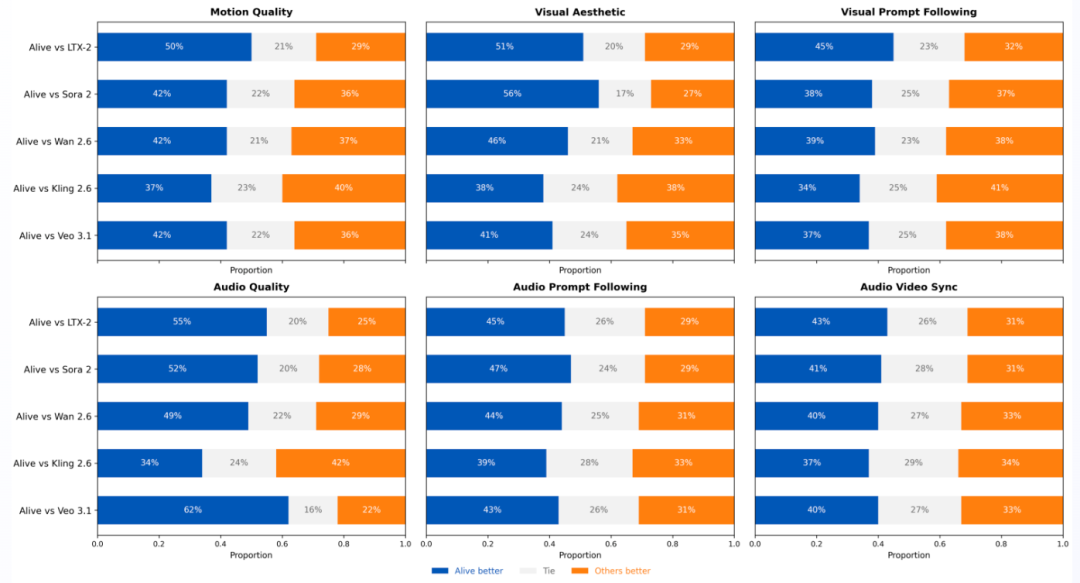
字节Alive团队开发的开源版Seedance 2.0,也要来了。在两轮大规模的人类评估中,Alive甚至超越顶级闭源Sora 2、Veo 3.1等,稳稳的开源最强。Alive通过统一音视频生成架构、独创的时空对齐技术以及巧妙的非对称训练策略,一举解决了AI视频生成中声画不同步和画质音质难两全的行业痛点。
字节刚刚发布了Seedance 2.0:Game over!视频GPT-4o时刻!Seedance 2.0引爆全球。
字节Alive团队开发的开源版Seedance 2.0,也要来了。

在两轮大规模的人类评估中,Alive甚至超越顶级闭源Sora 2、Veo 3.1等,稳稳的开源最强。
Alive通过统一音视频生成架构、独创的时空对齐技术以及巧妙的非对称训练策略,一举解决了AI视频生成中声画不同步和画质音质难两全的行业痛点。
音视频生成的大一统变革
过去很长一段时间里,AI视频生成领域就像是一个偏科生。
我们看到的所谓AI大片,大多是哑巴电影,要么就是后期硬生生贴上去的音效,嘴型对不上,节奏乱糟糟。
因为视觉(Video)和听觉(Audio)在计算机眼里是两种完全不同的语言,它们的数据结构、时间密度截然不同,想把它们揉在一个模型里生成,难度堪比让鸭子和鸡同声翻译。
Alive没有选择先生成视频再配音或者先有声音再配画面的妥协路线,而是音视频联合生成(Joint Audio-Video Modeling)。
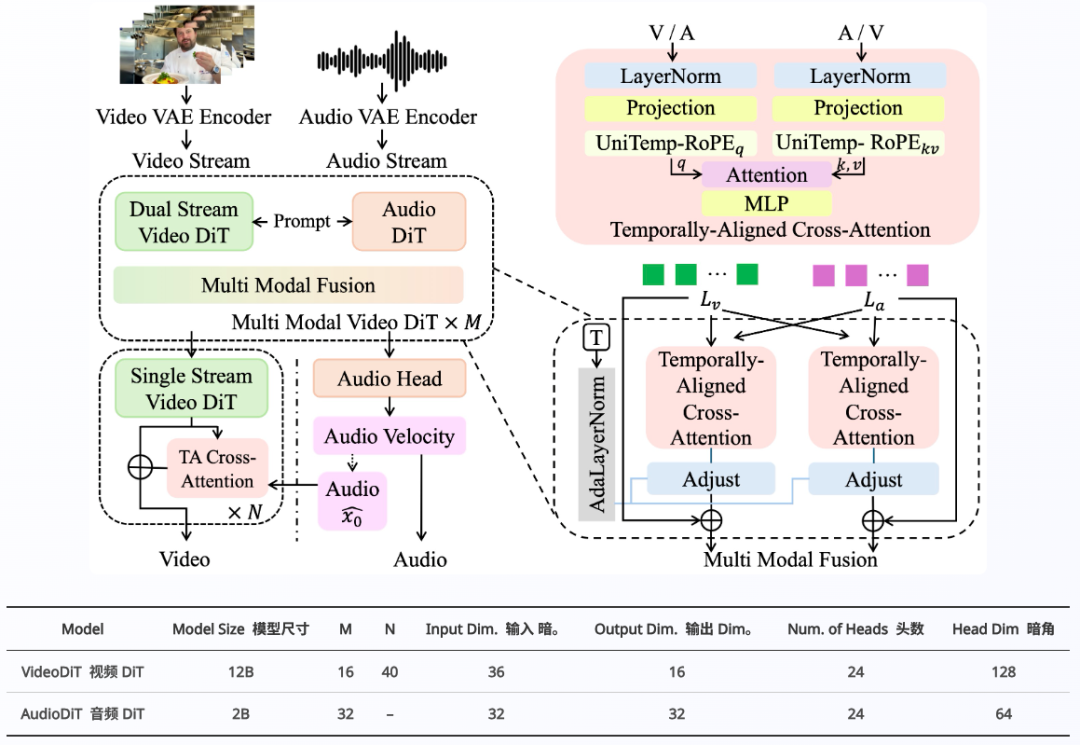
Alive基于MMDiT(多模态扩散Transformer)架构,设计了一种扩展的双流+单流范式。模型参数总14B左右,看起来普通显卡就能跑。
你可以把它想象成一个极其聪明的大脑,左半球管画面,右半球管声音,中间有一座高速桥梁实时交换信息。
这种架构让模型在构思画面的那一毫秒,就已经想好了此刻该有什么声音;在酝酿旋律的那一瞬间,脑海中就已经浮现了对应的光影。
这种设计直接带来的好处就是全能。无论是文生视频+音频(T2VA),还是让一张静态图动起来并开口说话(Ref-to-Video/Animation),Alive都能在一个框架内搞定。
它不再是两个模型的拼凑,而是一个原生懂得声画一体的智能体。
搞定音视频同步,最大的拦路虎是时间。
视频是按帧算的,一秒钟24帧或30帧;音频是按采样率算的,一秒钟几万个数据点。
在模型内部,这两者的时间刻度完全对不上,就像两个人约会,一个看的是日历,一个看的是秒表,根本没法同步。
Alive团队为了解决这个问题,祭出了两样法宝:UniTemp-RoPE(统一时域旋转位置编码)和TA-CrossAttn(时序对齐交叉注意力)。
UniTemp-RoPE就像是一个万能的时间翻译器。它强行将音频和视频这两种异构的潜在特征(Latents),映射到了一个共享的、连续的时间坐标系中。
不管你是密集的音频波形,还是稀疏的视频帧,在这个坐标系里,你们都得乖乖遵守物理时间的绝对顺序。
有了统一的时间标尺,TA-CrossAttn就开始发挥作用了。
它像是一个严苛的指挥家,时刻盯着音频流和视频流。当视频生成到第3秒如果出现了爆炸画面,交叉注意力机制会立即拽住音频流,确保在同一毫秒生成爆炸的声响。
这种强制性的物理时间对齐,消除了以往模型中常见的只闻其声不见其人或者嘴巴动了声音没出来的幽灵现象。
追求高画质和高音质通常意味着算力的疯狂燃烧。如果直接生成1080P的高清有声视频,显卡可能会直接冒烟。
Alive团队非常务实,他们设计了一套级联音视频精炼器(Audio-Video Refiner),用一种讨巧的方式实现了高质量输出。
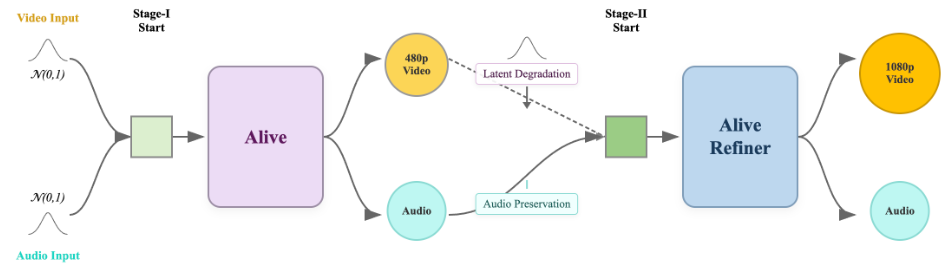
这个过程很像画家的创作逻辑:先画草图,再上色精修。
Alive首先利用一个基础模型快速生成480P分辨率的视频和对应的音频。这一步虽然分辨率不高,但动作、构图和声音的同步关系已经确立了。
接下来,模型将这个低分辨率的草稿输入到精炼模块中,把视频放大到1080P,填补细节,消除模糊和伪影。
而在处理音频时,他们发现了一个关键窍门:音频不需要重画。
基础模型生成的音频Latents通常已经足够清晰,如果强行再生成一遍,反而可能引入杂音。
所以,在精炼阶段,音频DiT模块是冻结(Frozen)的。
它只负责把干净的音频信号原封不动地传下去,或者作为参考信号辅助视频的精修。
这样做既节省了巨大的计算成本,又完美保留了基础阶段建立好的音画同步关系。
数据、训练与基准
Alive团队在数据处理上下了狠功夫,建立了一套全方位的音视频数据流水线。
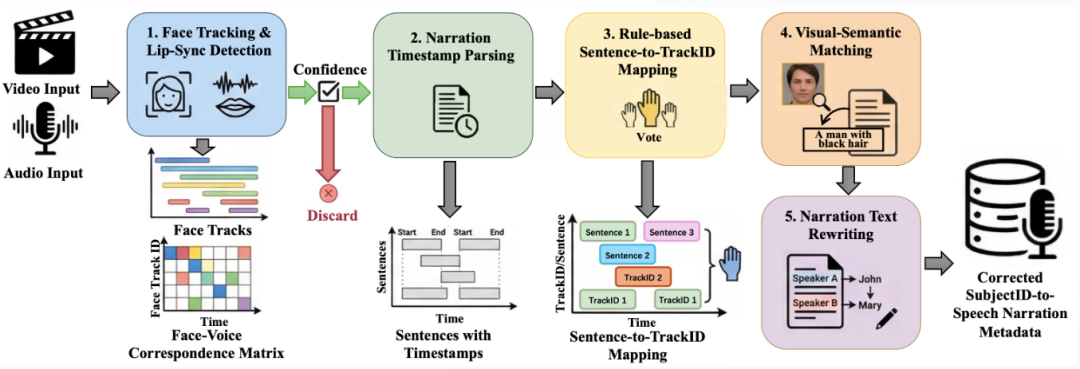
普通的视频数据筛选,往往只看画面清不清晰。Alive则不同,它实施了双重质检——既要画面美,又要声音准。
他们引入了联合视觉+音频的关键词标注系统。
比如一个视频里有狗和汽车,传统的标注可能分不清背景里的声音是狗叫还是车鸣。
Alive的系统能将视觉对象与音频事件精准关联,确保狗对应汪汪,汽车对应轰鸣。
更厉害的是针对多人物场景的主体-语音对应修正(Subject-Speech Correspondence)。
在多人对话的复杂视频中,AI很容易搞混是谁在说话。Alive团队专门优化了这一点,修正了身份和声音的匹配关系。
确保了在生成多角色互动视频时,壮汉不会发出萝莉音,主角说话时旁边的路人不会张嘴,极大地提升了角色身份的一致性和准确性。
在训练过程中,Alive团队发现了一个非常有趣的现象,极具哲学意味:耳朵比眼睛更敏感,但也更健忘。
音频分支(Audio Branch)的学习速度非常快,它能迅速适应新的训练数据,但也因为适应得太快,很容易发生灾难性遗忘(Catastrophic Forgetting)。一旦数据分布稍有变化,它就把之前学到的抗噪能力、音色稳定性丢到九霄云外去了。
相比之下,视频分支学得慢但记得牢。如果用同样的学习率去训练这两个分支,就会出现音频学会了又忘了,视频还在慢慢爬的尴尬局面。
为了解决这个问题,Alive采用了非对称学习率(Asymmetric Learning Rates)。
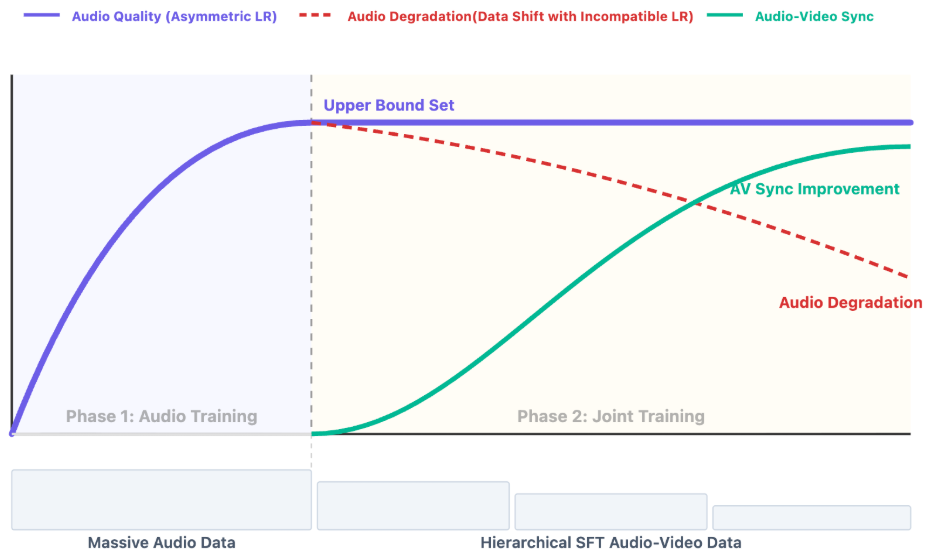
简单来说,就是给音频分支和视频分支制定不同的教学计划。对音频分支管得严一点,步子小一点,防止它学得太快而跑偏;对视频分支则维持正常的训练强度。
此外,他们还发现了一个至关重要的原则:音频质量主要取决于预训练。
联合训练阶段的主要任务是磨合同步性,而不是提升音质。
如果一开始的AudioDiT没训练好,指望在联合训练阶段突击补课是没用的。
这决定了Alive的训练路线图:先在海量音频数据上把AudioDiT练成金耳朵,再拉到联合模型里去学配合。
在让静态照片动起来(Reference-to-Video)这件事上,很多模型都有一个通病:为了保持人物长得像,生成的视频就像是把照片里的人剪下来平移,毫无生气,这被称为复制粘贴偏差(Copy-Paste Bias)。
Alive引入了一种跨配对流水线(Cross-Pair Pipeline)和统一编辑基准的增强方案。
它不再死板地把参考图当作第一帧,而是将其视为一个持久的身份锚点(Persistent Identity Anchors)。
模型理解的是这个人的长相特征,而不是这张照片的像素排列。
因此,Alive生成的动画中,人物可以大幅度转头、变幻表情、甚至改变光影,但你依然能认出这就是那个人。
配合多参考条件控制(Multi-Reference Conditioning),用户还可以通过调整时间偏移量,精准控制人物动作的起止,让照片复活真正具备了电影级的动态表现力。
为了证明自己不是PPT战神,Alive团队构建了一个极其严苛的竞技场——Alive-Bench 1.0。
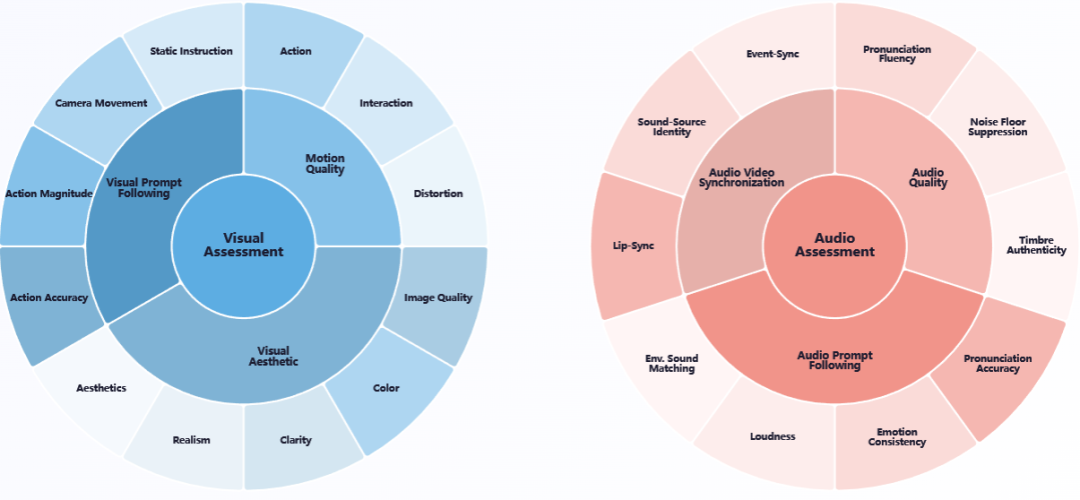
这是一个包含20多个细分维度的综合基准测试,涵盖了动作质量、视觉美感、音频质量、声画同步性等方方面面。
这个测试集的提示词(Prompts)不像学术界那么刻板,而是完全模仿真实用户的口语化描述,主打一个实战模拟。
Alive用精妙的架构设计和对数据特性的深刻理解,填平了视觉与听觉之间的鸿沟。
参考资料:
https://foundationvision.github.io/Alive/
https://arxiv.org/pdf/2602.08682
https://github.com/FoundationVision/Alive

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)