阿里Qwen3.5发布:仅17B激活的高效率、高性能原生多模态
开年第一篇文章献给“源神”阿里!阿里除夕发布了拥有 397B 参数的视觉语言模型,单次推理仅激活 17B 参数,性能直接比肩万亿规模的前沿大模型。这款名为 Qwen3.5-397B-A17B 的开源权重模型打破了视觉与语言的隔离,通过底层混合架构与异步强化学习框架实现了效率与泛化能力的跨越。
开年第一篇文章献给“源神”阿里!
阿里除夕发布了拥有 397B 参数的视觉语言模型,单次推理仅激活 17B 参数,性能直接比肩万亿规模的前沿大模型。

这款名为 Qwen3.5-397B-A17B 的开源权重模型打破了视觉与语言的隔离,通过底层混合架构与异步强化学习框架实现了效率与泛化能力的跨越。
统一感官打破模态隔离
过去的多模态模型普遍采用视觉编码器加上语言模型的拼接方案。
图片需要先被转换为特征向量,随后再交给语言模型去理解和处理。整个过程如同一个翻译官将看到的画面口述给蒙着眼睛的记录员。
Qwen3.5 预训练阶段直接引入了早期文本与视觉的融合机制。视觉信息与语言数据在同一个统一的表征空间中联合学习。
剥离了繁杂的多模型串联流程后,模型端到端处理复杂任务的能力得到了本质上的飞跃。
从视觉推理到空间定位,再到复杂的 GUI 操作与视频内容理解,信息传递不再有中间环节的损耗。
在同等规模下,Qwen3.5 的多模态任务表现全面超越了先前的 Qwen3-VL 模型。
视觉-语言融合任务中,Qwen3.5 在视觉理解、数学推理等关键任务上全面领先,超越了参数量级过万亿的 GPT-5.2 及 Claude 4.5 Opus 等顶尖模型。
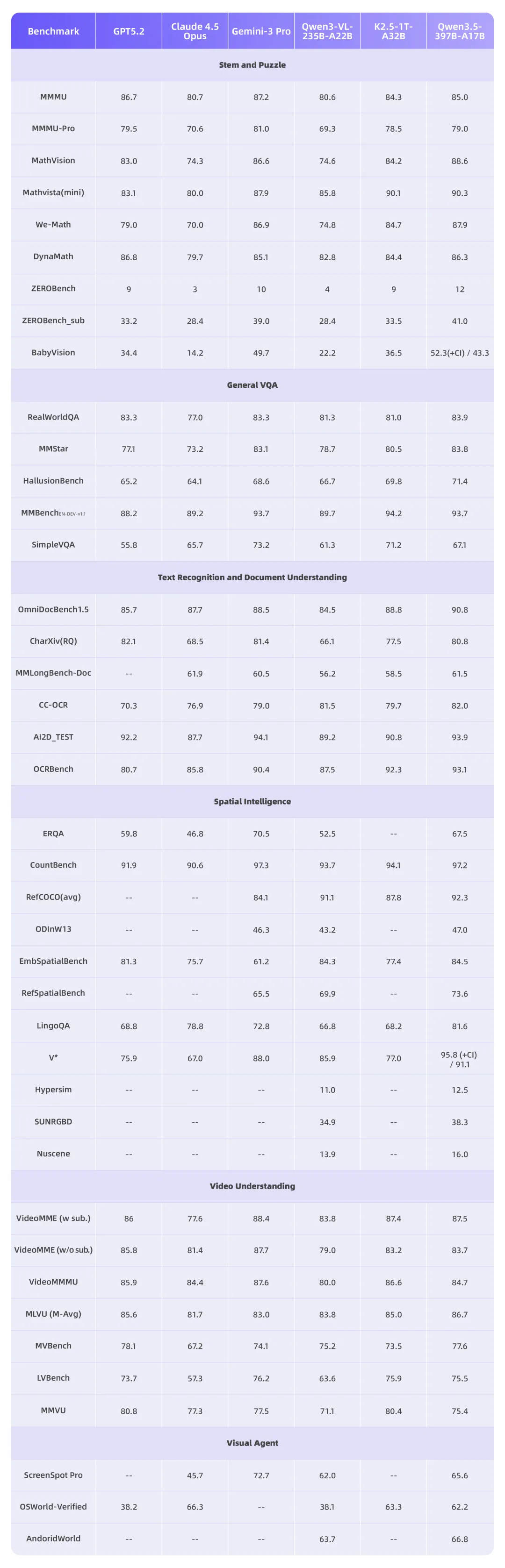
它能极其自然地处理跨模态任务的连贯性问题。开发者无需再为不同的感官输入去维护庞杂的多模型处理管线。
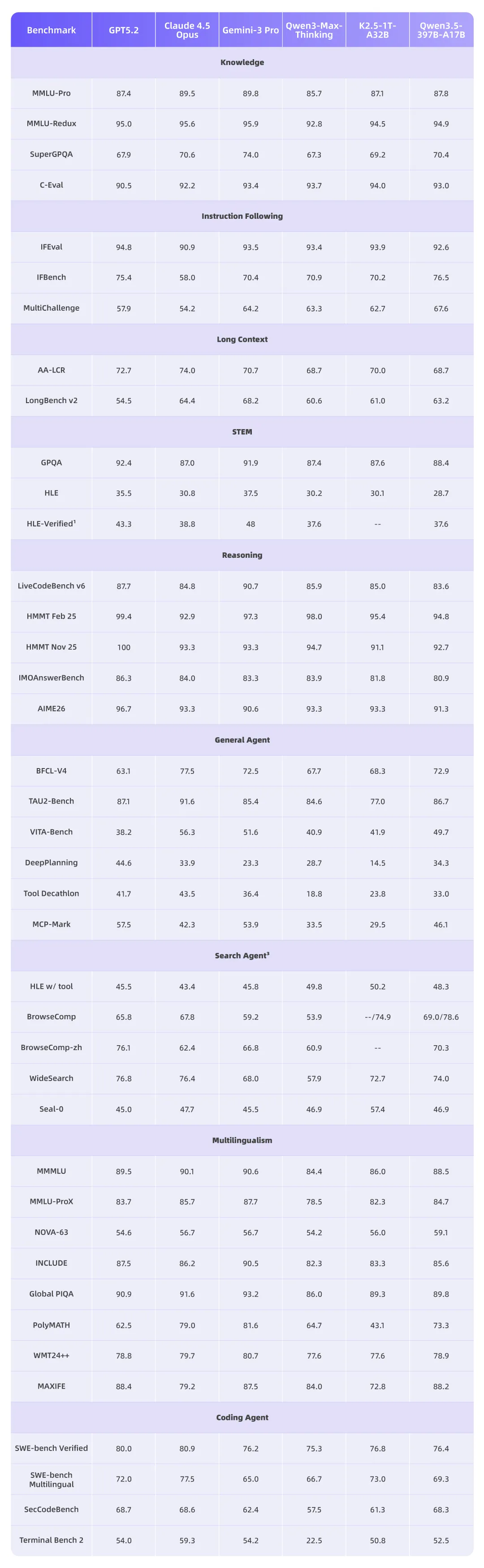
就算是纯文本任务,Qwen3.5 在指令遵循、智能体任务等开发者高频场景,也与 GPT-5.2、Claude 4.5 Opus 等顶尖模型对齐。
混合架构兼顾规模与计算效率
大模型的参数规模与计算成本一直是一对难以调和的矛盾。
Qwen3.5 基于 Qwen3-Next 架构,将线性注意力(Gated Delta Networks)与稀疏混合专家(MoE)相结合。
模型总参数量高达397B,每次前向传播只激活17B,维持庞大知识储备的同时大幅度压低了算力成本。
为了进一步提升处理长文本与生成内容的效率,模型底层整合 Gated DeltaNet + Gated Attention。
而多 Token 预测技术的加入让模型在单次前向推理时能够同时预测出多个字词。
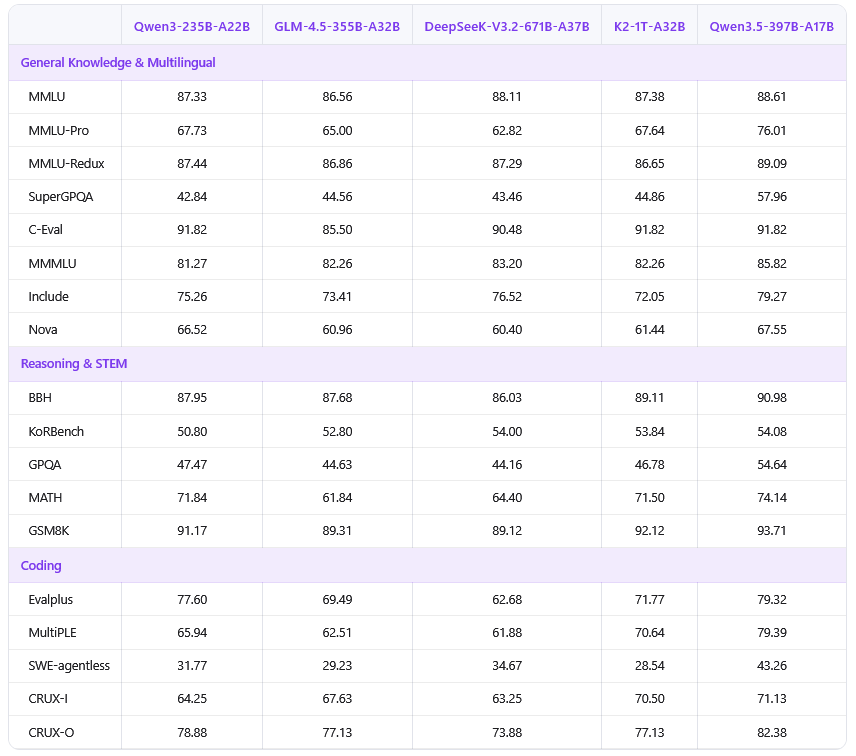
在 32k 上下文长度下,解码吞吐量是 Qwen3-Max 的 8.6 倍,是 Qwen3-235B-A22B 的 3.5 倍。
在 256k 上下文长度下,解码吞吐量是 Qwen3-Max 的 19.0 倍,是 Qwen3-235B-A22B 的 7.2 倍。
而且性能不减,甚至更好。

跨越语种与强化学习的边界
在训练数据的筛选与培育上,开发团队引入了更为严苛的数据过滤策略。
中英文语料、多语言文本以及 STEM(科学技术工程和数学)与推理数据得到了显著的强化,确保了进入模型大脑的知识处于高纯度状态。
为了让全球不同地区的用户都能无障碍地使用,Qwen3.5 的语言/方言覆盖范围从 119 种跨越到了 201 种。
研发团队重点扩充了对非洲、南亚地区、中国少数民族语言及其他低资源语言的支持。
模型词表被扩容至 25 万,庞大的词表让模型在处理长尾语言与复杂表达时变得游刃有余。多数语言的编码与解码效率提升了 10% 到 60%。
它如同给模型配备了一本更加厚实精准的字典,系统可以直接调用确切的词汇来表达偏僻概念。
开发团队构建了一套可扩展的异步 RL(强化学习)框架来持续挖掘模型潜力。
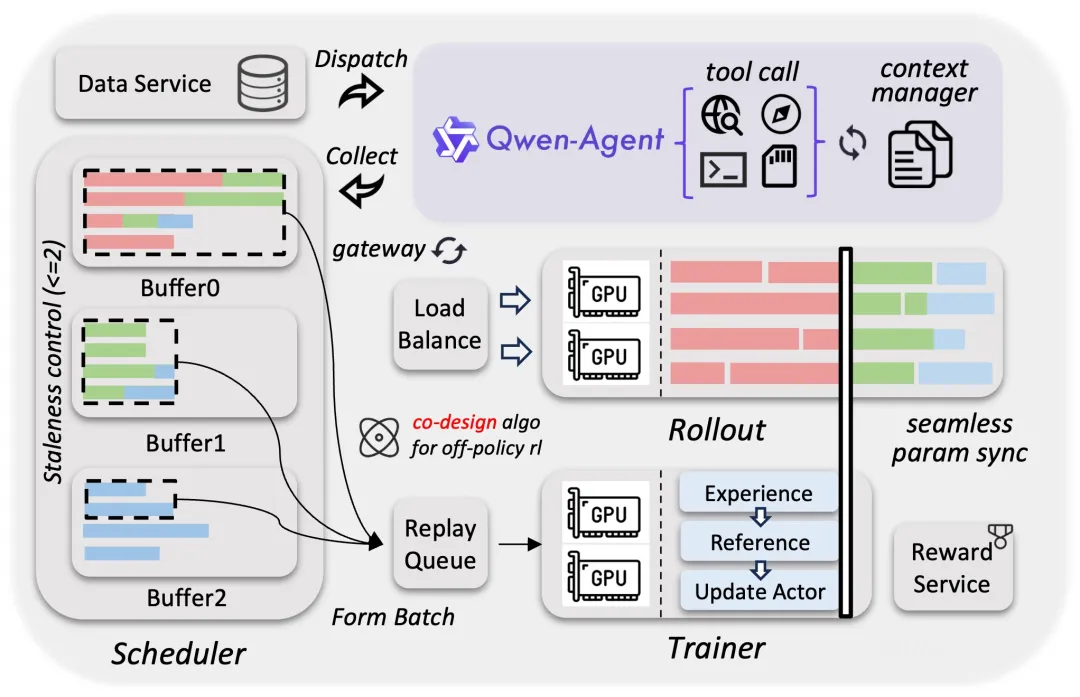
这套框架支持 Qwen3.5 全尺寸模型,全面覆盖文本、多模态以及多轮交互场景。
框架内部采用了训推分离的解耦式设计,提升了底层硬件的使用率。
它如同一个调度精密的大型交通枢纽,实现了动态负载均衡与细粒度的故障恢复。
配合 FP8(八位浮点数)训推、投机采样以及多轮路由回放等技术,系统的吞吐量与训推一致性得到了全面优化。
系统与算法的协同设计在严格控制样本陈旧性的基础上缓解了数据长尾问题。
底层优化最终取得了 3 到 5 倍的端到端加速,能够支撑百万级规模的 Agent 脚手架与环境扩展。
异构算力与交互模式的重构
在各项严格的基准测试中,Qwen3.5 在各类强化学习任务和环境中,通用智能体能力随着环境扩展带来了确切的性能增益。
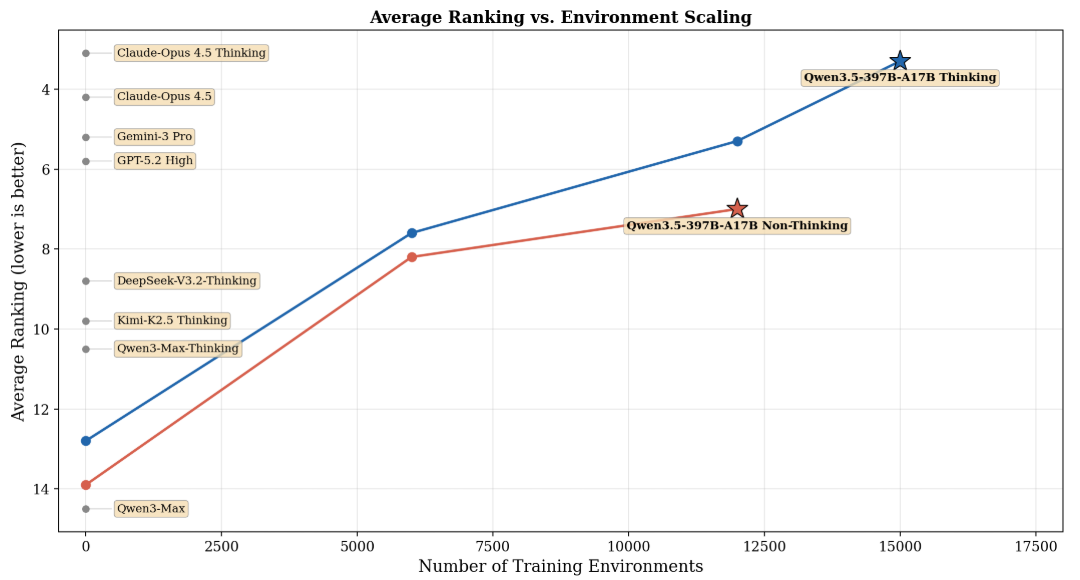
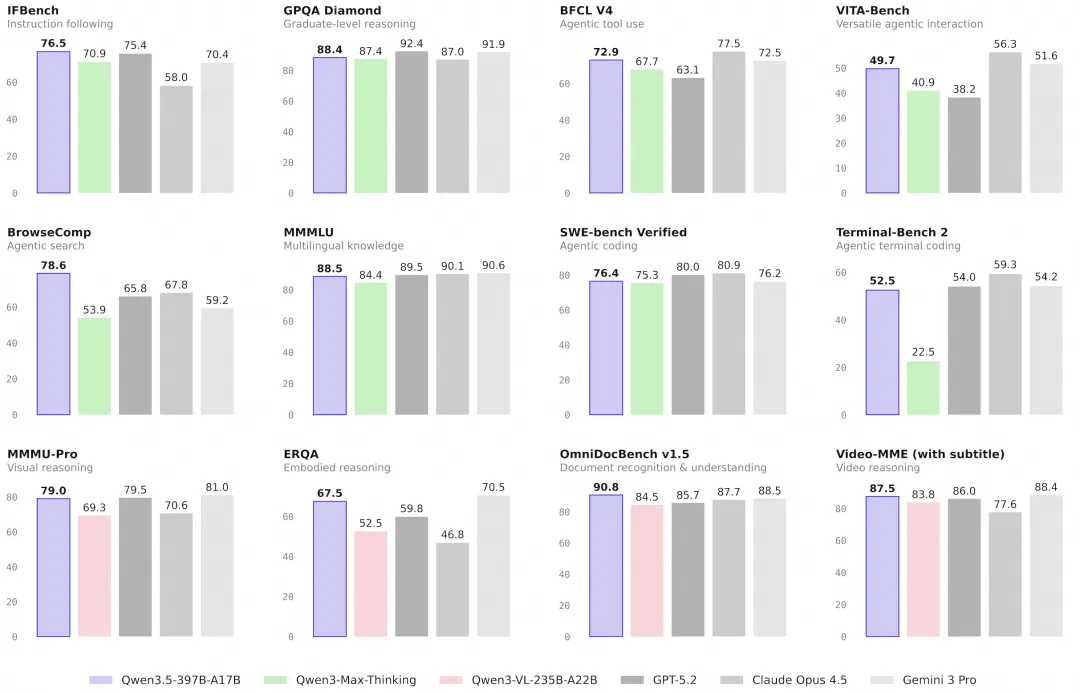
在 BFCL-V4、VITA-Bench、DeepPlanning、Tool-Decathlon 以及 MCP-Mark 等权威基准测试的平均排名中,模型表现出了卓越的竞争力。
与开源模型性能比较,展现了强大的统治力。
为了支撑庞大的训练工程,研发团队在异构基础设施上实现了高效的原生多模态训练。
他们在视觉与语言组件上实行了解耦并行策略,规避了传统统一方案带来的低效问题。
通过稀疏激活机制,模型实现了跨模块计算的完美重叠。
在混合文本、图像、视频的庞大数据集上,其训练吞吐量几乎达到了纯文本基线的 100%。
原生 FP8(八位浮点数)流水线对激活、路由与矩阵运算采用了低精度处理。
系统会通过运行时监控,在敏感的网络层保留 BF16(十六位脑浮点数)的高精度计算。
这套精细的算力调配方案使得激活显存降低了约 50%,运算速度提升超过 10%,并能稳定扩展至数万亿个 Token 。
目前用户可以直接访问 chat.qwen.ai 体验对话交互。
系统提供了三种不同的对话模式供调用。
自动模式能够开启自适应思考能力并自主调用工具,思考模式专注解决复杂的深层问题,快速模式省去了思考 Token 的消耗,提供即时的问答反馈。
技术演进的车轮不断向前,Qwen3.5 用混合架构与原生多模态设计,在参数规模与计算效率之间确立了新的平衡坐标。
参考资料:
https://qwen.ai/blog?id=qwen3.5
https://github.com/QwenLM/Qwen3.5
https://huggingface.co/Qwen/Qwen3.5-397B-A17B
https://modelscope.cn/models/Qwen/Qwen3.5-397B-A17B

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)