大模型应用:从手动调参到智能寻优:PSO 驱动的大模型参数自动化优化.94
本文提出了一种基于粒子群优化(PSO)算法的大模型参数自动调优方法。针对大模型调参存在的高维度、非凸性等挑战,该方法将PSO的群体智能搜索能力与大模型的效果评估相结合,形成自动化调参闭环。文章详细阐述了PSO的数学原理、大模型参数空间定义、适应度函数设计等关键技术,并给出了知识库问答场景下的完整实现流程和代码示例。实验表明,该方法能有效替代人工调参,在保证生成质量的同时显著提升优化效率。该技术方案
一、前言
大模型调参是当前 AI 工程化落地的核心痛点之一,推理参数(如 batch_size、max_new_tokens)、向量库配置(如分段大小、检索阈值)、生成参数(如温度系数、top_p)等,每一个参数的微调都可能显著影响模型效果与性能。传统的人工调参依赖经验、效率低下且难以找到全局最优解,而将粒子群优化(PSO)与大模型结合,把调参过程转化为 “自动化寻优工程”,既能发挥PSO群体智能的全局搜索优势,又能借助大模型的效果评估能力,实现参数配置的智能、高效、全局最优。今天我们结合大模型参数调优,由浅入深完整讲解这一技术体系,探索PSO 驱动的大模型参数自动化优化的详细实现思路。

二、核心概念
1. 大模型调参自动化寻优
大模型的参数空间具有“高维度、非凸、非线性”三大特征,这使得人工调参几乎不可能触及全局最优解:
- 高维度:一个典型的大模型推理场景,需要调优的参数包括:
- 推理侧:batch_size、num_workers、max_length、temperature、top_p、top_k;
- 向量库侧:chunk_size、chunk_overlap、ef_construction、ef_search;
- 部署侧:max_memory、tensor_parallel_size等;
- 仅核心参数就有10多个维度,参数组合呈指数级增长;
- 非凸性:参数与效果的关系并非简单的线性、凸函数,可能存在多个局部最优解,比如温度系数 0.3 和 0.8 都能得到尚可的结果,但 0.5 效果最差;
- 主观性与评估成本高:大模型效果评估(如生成质量、检索准确率、推理速度)难以用简单公式量化,人工评估耗时耗力,且不同评估者的标准存在差异。
而粒子群优化(PSO)作为一种基于群体智能的随机优化算法,天生适配这种“高维、非凸、无显式目标函数”的优化场景,它无需知道参数与效果的数学关系,仅通过“群体搜索 + 个体学习 + 群体学习”的方式遍历参数空间,再结合大模型自身的效果评估能力作为适应度函数,就能自动找到最优参数组合。
2. 粒子群优化(PSO)的定义
PSO是一种启发式优化算法,灵感来源于鸟群觅食、鱼群游动的群体行为:
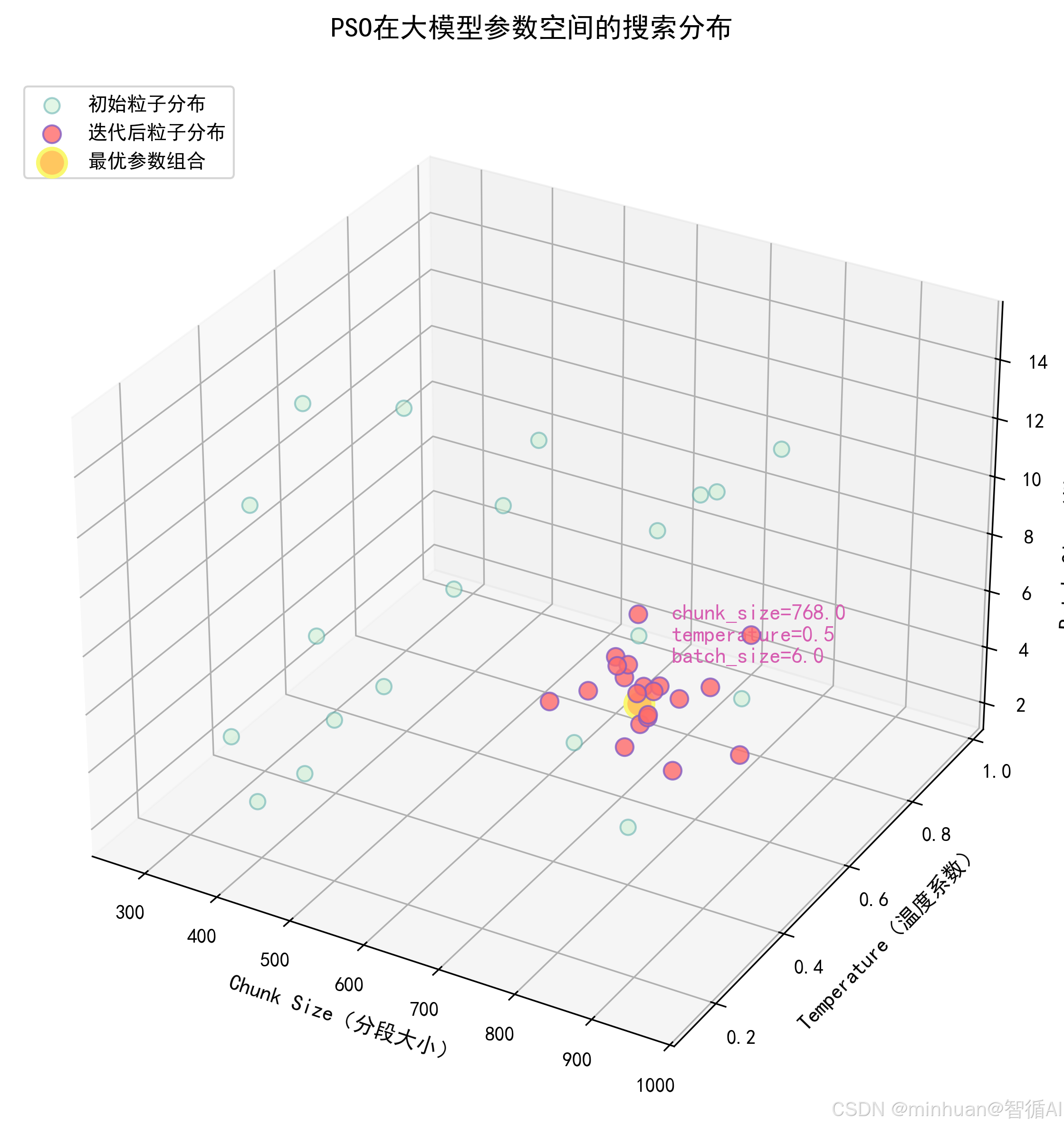
- 粒子(Particle):每一个粒子代表参数空间中的一个“候选解”,对应一组完整的大模型调参配置,比如:temperature=0.6、chunk_size=512、batch_size=8;
- 种群(Swarm):多个粒子组成的群体,代表一轮搜索中的所有候选参数组合;
- 位置(Position):粒子在参数空间中的坐标,即具体的参数值,如粒子 1 的位置是 [0.6, 512, 8],分别对应 temperature、chunk_size、batch_size;
- 速度(Velocity):粒子在参数空间中的移动方向和步长,决定下一轮迭代中粒子的位置更新;
- 个体最优(pBest):单个粒子在历史搜索过程中找到的最优位置,即效果最好的参数组合;
- 全局最优(gBest):整个种群在历史搜索过程中找到的最优位置,所有粒子中效果最好的参数组合;
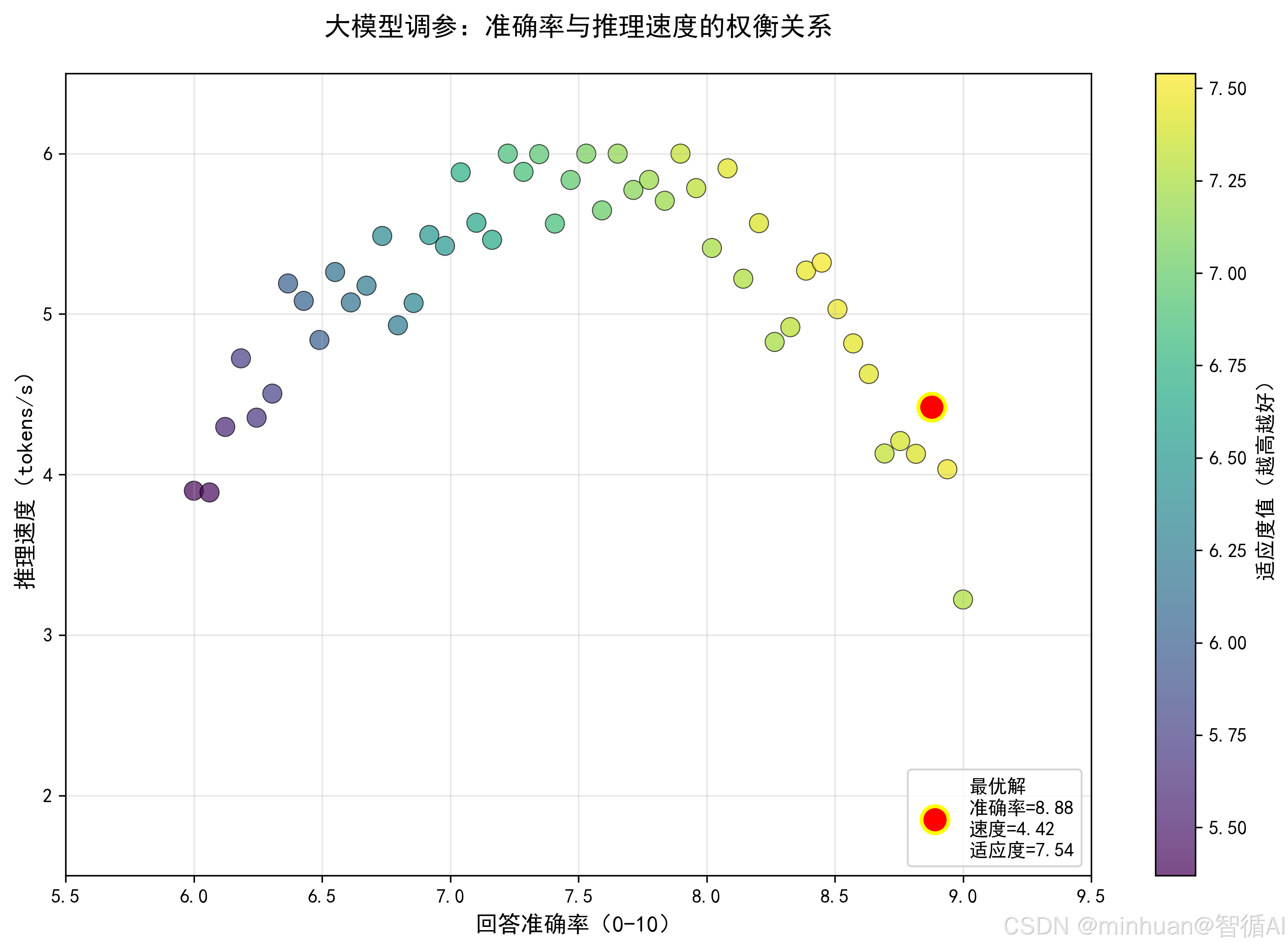
- 适应度值(Fitness Value):衡量粒子位置优劣的指标,在大模型场景中,就是该参数组合下大模型的效果评分,如生成质量评分、检索准确率、推理速度加权分。
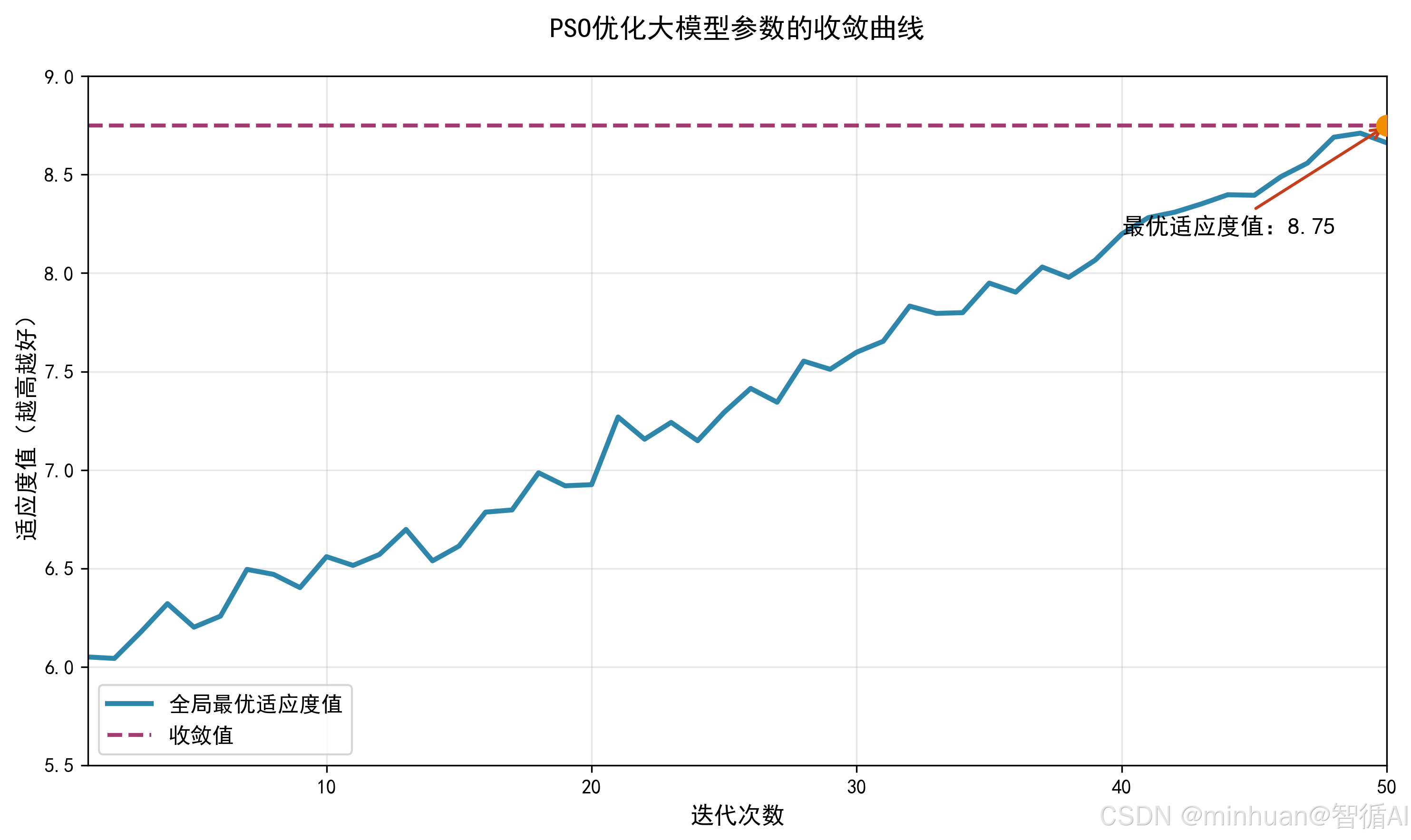
PSO 的核心逻辑是:每个粒子根据自己的历史最优(pBest)和群体的历史最优(gBest)调整移动方向和速度,不断在参数空间中搜索,最终收敛到全局最优解。
3. 大模型作为“效果打分器”的核心定位
在 PSO + 大模型的体系中,大模型承担两个核心角色:
- 1. 待优化对象:PSO 的优化目标是找到让大模型达到最佳效果的参数配置;
- 2. 适应度评估器:无法用公式量化大模型效果时,直接让大模型或基于大模型的评估体系对自身生成结果、检索结果打分,作为 PSO 的适应度值。
举个具体例子:
- 优化目标:让大模型在“知识库问答”任务中,既保证回答准确率≥95%,又保证推理速度≥10 tokens/s;
- 粒子位置:[chunk_size(向量库分段大小), temperature(生成温度), top_p(核采样参数)];
- 适应度计算:用该粒子的参数配置运行知识库问答任务,收集 100 条问答结果,让大模型对每条结果的“准确率”打分(0-10 分),同时计算推理速度,最终适应度值 = 准确率平均分 ×0.8 + (推理速度 / 20)×0.2(归一化后),分值越高代表参数越优。
4.“自动化寻优工程” 的核心特征
将 PSO + 大模型结合应用到实际场景,需具备以下特征:
- 全自动化:从参数空间初始化、粒子位置更新、大模型效果评估,到最优参数输出,全程无需人工干预;
- 可量化:即使是主观的生成质量,也通过大模型评估转化为可量化的适应度值;
- 可收敛:通过 PSO 的参数(如惯性权重、学习因子)控制,保证算法能在有限迭代次数内收敛到最优解;
- 可复用:适配不同大模型任务(推理、检索、生成),仅需调整参数空间和适应度评估逻辑;
- 可监控:记录每一轮迭代的粒子位置、适应度值,可视化搜索过程,便于调优算法本身的参数。
5. PSO + 大模型的核心执行逻辑

步骤说明:
- 1. 初始化PSO种群:创建粒子群,每个粒子代表一组候选参数配置
- 2. 生成粒子位置:每个粒子的位置对应一组大模型参数组合(如学习率、层数、温度等)
- 3. 加载大模型+参数配置:根据粒子位置加载对应参数配置到模型中
- 4. 运行目标任务:在具体任务上运行模型(知识库问答、文本生成等)
- 5. 大模型评估效果:计算模型在目标任务上的性能指标作为适应度值
- 6. 更新pBest和gBest:
- pBest:每个粒子的历史最优位置
- gBest:整个种群的历史最优位置
- 7. 判断终止条件:是否达到最大迭代次数或已收敛
- 8. 更新粒子速度和位置:根据PSO公式计算新速度,更新粒子位置
- 9. 输出最优参数配置:迭代结束,输出gBest对应的最优参数组合
- 10. 落地大模型部署:将优化后的参数配置应用于实际部署
简单来说,整个执行流程是“PSO 生成参数→大模型验证效果→PSO 学习优化→再验证→直到最优”的闭环,把人工调参的“试错 - 评估 - 调整”过程完全自动化。

三、基础知识
1. 粒子群优化(PSO)的数学原理
为了通俗易懂,我们先从最简单的一维优化场景理解 PSO,再扩展到高维的大模型参数空间。
1.1 一维 PSO 的基础公式
假设我们要优化一个简单的函数 f(x)=x²,目标是找到 x 使 f (x) 最小,最优解是 x=0,PSO 的执行步骤如下:
1.1.1 初始化:
- 种群规模:N 个粒子(比如 N=5);
- 粒子位置:随机初始化每个粒子的位置x_i,比如 x1=2, x2=-3, x3=1, x4=-2, x5=4;
- 粒子速度:随机初始化每个粒子的速度v_i,比如 v1=0.5, v2=-0.3, v3=0.2, v4=-0.4, v5=0.1;
- 个体最优 pBest:初始时等于粒子自身位置,因为还没搜索;
- 全局最优 gBest:初始时等于所有 pBest 中最优的位置,这里 f (x) 最小的是 x3=1,f (x)=1。
1.1.2 速度更新公式:
每一轮迭代中,粒子的速度由三部分组成:
v_i(t+1)=w⋅v_i(t)+c1 ⋅ r1 ⋅(pBest_i −x_i(t))+c2 ⋅r2 ⋅(gBest−x_i(t))
其中:
- w:惯性权重(Inertia Weight),控制粒子保持原有速度的趋势,通常为0.4~0.9;
- c1:个体学习因子(Cognitive Factor),控制粒子向自身最优位置移动的趋势,通常为2;
- c2:群体学习因子(Social Factor),控制粒子向全局最优位置移动的趋势,通常为2;
- r1 ,r2:0~1 之间的随机数,增加搜索的随机性;
- t:当前迭代次数。
这个公式的物理意义很直观:
- 第一部分 w⋅v_i(t):“惯性”,粒子继续保持原来的移动方向和速度;
- 第二部分 c1 ⋅ r1 ⋅ (pBest_i −x_i(t)):“个体学习”,粒子向自己历史最好的位置靠拢;
- 第三部分 c2 ⋅ r2 ⋅ (gBest−x_i(t)):“群体学习”,粒子向整个群体历史最好的位置靠拢。
1.1.3 位置更新公式:
速度更新后,粒子的位置随之更新:x_i(t+1)=x_i(t)+v_i (t+1)
1.1.4 适应度计算与最优更新:
计算新位置的适应度值,这里是f(x_i(t+1)),如果比当前 pBest 更优,则更新 pBest;如果所有 pBest 中出现更优的值,则更新 gBest。
1.1.5 终止条件:
迭代达到预设次数,或 gBest 的适应度值不再变化,即函数值不再收敛,停止搜索。
1.2 高维 PSO 的扩展
高维 PSO 的扩展适配大模型多参数的场景,大模型调参是高维优化问题,比如同时优化 temperature、chunk_size、batch_size 三个参数,此时:
- 粒子位置x_i是一个向量:x_i =[x_i1 ,x_i2 ,x_i3 ],分别对应三个参数;
- 粒子速度v_i也是一个向量:v_i =[v_i1 ,v_i2 ,v_i3 ];
- 速度和位置更新公式完全复用一维场景,只是对每个维度分别计算。
举个例子,优化三个参数的速度更新:
- v_i1(t+1)=w⋅v_i1(t)+c1 ⋅ r1 ⋅(pBest_i1 −x_i1(t))+c2 ⋅r2 ⋅(gBest1 −x_i1(t))
- v_i2(t+1)=w⋅v_i2(t)+c1 ⋅ r1 ⋅(pBest_i2 −x_i2(t))+c2 ⋅r2 ⋅(gBest2 −x_i2(t))
- v_i3(t+1)=w⋅v_i3(t)+c1 ⋅ r1 ⋅(pBest_i3 −x_i3(t))+c2 ⋅r2 ⋅(gBest3 −x_i3(t))
1.3 PSO 的关键参数
对于大模型调参场景,PSO 的核心参数需要根据实际情况调整,我们可以先记住默认值:
| 参数 | 符号 | 默认值 | 作用 | 调优建议 |
|---|---|---|---|---|
| 种群规模 | N | 20~50 | 每次迭代的候选参数组合数 | 参数维度高则增大(如 10 维参数用 50),评估成本高则减小(如大模型评估慢用 20) |
| 惯性权重 | w | 0.7 | 控制粒子探索 / 利用平衡 | 初期大 w(0.9)增强全局探索,后期小 w(0.4)增强局部挖掘 |
| 个体学习因子 | c1 | 2.0 | 粒子向自身最优学习的强度 | 过大易陷入局部最优,过小则学习慢 |
| 群体学习因子 | c2 | 2.0 | 粒子向全局最优学习的强度 | 过大易 “扎堆”,过小则收敛慢 |
| 最大迭代次数 | T | 50~100 | 算法终止条件 | 评估成本高则减小(如 50),参数空间复杂则增大(如 100) |
| 速度上限 | v_max | 参数范围的 10% | 防止粒子移动过快跳出最优区域 | 比如 temperature 范围 0~2,则 v_max=0.2 |
2. 大模型调参的基础
2.1 大模型常见可调参数
我们首先要明确“哪些参数可以优化”,以下是核心可调参数及影响:
2.1.1 生成类参数(控制文本生成质量):
- temperature(温度系数):0~2,值越高生成越随机,值越低越确定;
- top_p(核采样):0~1,值越小生成越集中,值越大越多样;
- top_k(Top-K 采样):1~100,只从概率最高的 k 个 token 中选,值越小越确定;
- max_new_tokens:生成文本的最大长度,影响生成效率和完整性。
2.1.2 向量库参数(控制检索效果):
- chunk_size:文本分段大小(如 512、1024 tokens),过小则上下文碎片化,过大则检索精度低;
- chunk_overlap:分段重叠长度(如 64、128 tokens),平衡碎片化和冗余;
- ef_construction/ef_search:HNSW 索引参数,控制检索速度和准确率。
2.1.3 推理类参数(控制部署性能):
- batch_size:批量推理的样本数,过小则速度慢,过大则显存不足;
- num_workers:数据加载的线程数,影响推理吞吐量;
- max_memory:模型占用的最大显存,平衡多模型部署资源。
2.2 大模型效果评估的维度
PSO 需要可量化的适应度值,因此需将大模型效果拆解为可评估的维度:
- 1. 准确率:生成结果与标准答案的匹配度,如知识库问答的答案准确率;
- 2. 流畅度:生成文本的语法、逻辑流畅性;
- 3. 相关性:生成结果与输入问题的相关程度;
- 4. 速度:推理延迟、吞吐量(tokens/s);
- 5.资源消耗:显存占用、CPU 使用率。
评估方式:
- 客观指标:推理速度、显存占用,可直接量化;
- 主观指标:准确率、流畅度,用大模型评估,如让其他模型给结果打分;
- 加权融合:适应度值 = 准确率 ×0.5 + 流畅度 ×0.2 + 速度 ×0.2 + 资源效率 ×0.1,权重可根据业务调整。
3. 易混淆的概念
3.1 PSO vs 网格搜索/随机搜索:
- 网格搜索:遍历所有参数组合,精度高但维度高时计算量爆炸,如10个参数各5个取值,需 5^10=976 万次评估;
- 随机搜索:随机采样参数组合,效率高于网格搜索,但无学习机制,易遗漏最优解;
- PSO:通过群体学习机制,逐步向最优解收敛,评估次数仅与种群规模 × 迭代次数相关,如 20×50=1000次,远低于网格搜索,且效果优于随机搜索。
3.2 适应度函数 vs 目标函数:
- 目标函数:理论上的优化目标,如“最大化准确率”;
- 适应度函数:工程上可量化的评估函数,如“准确率打分 + 速度加权”,是目标函数的工程实现。
3.3 收敛 vs 全局最优:
- 收敛:PSO 的 gBest 不再变化,代表算法找到“稳定解”;
- 全局最优:理论上的最优解,PSO 可能收敛到局部最优,需通过调整惯性权重、种群规模等参数降低这种风险。
四、PSO + 大模型的执行流程
PSO + 大模型的自动化调参流程可拆解为 8 个核心步骤,从需求定义到最终落地,执行流程图:

步骤详细说明:
步骤 1:定义优化目标与参数空间
这是我们最容易忽略但最重要的一步,明确“优化什么、参数范围是什么”,否则算法会无的放矢。
具体操作:
- 1. 定义业务目标:比如“在知识库问答任务中,最大化回答准确率(≥90%),同时保证推理速度≥5 tokens/s,显存占用≤10GB”;
- 2. 筛选可调参数:根据业务目标筛选核心参数,避免维度爆炸。比如上述目标可选参数:[chunk_size, temperature, batch_size, chunk_overlap];
- 3. 确定参数范围:核心关键,避免无效搜索
- chunk_size:整数,范围在[256, 1024],步长 64,避免非标准值
- temperature:浮点数,范围在[0.1, 1.0],步长 0.1
- batch_size:整数,范围在[1, 16],步长 1,受显存限制
- chunk_overlap:整数,范围在[32, 128],步长 32
- 4. 定义适应度函数:将业务目标转化为可量化的公式。比如:
- 准确率得分(0-10):由大模型评估 100 条问答结果的平均分;
- 速度得分(0-10):推理速度≥5 tokens/s 得 10 分,每低 0.5 减 1 分;
- 显存得分(0-10):显存≤10GB 得 10 分,每超 1GB 减 1 分;
- 最终适应度值 = 准确率得分 ×0.6 + 速度得分 ×0.2 + 显存得分 ×0.2,总分在0-10的区间。
步骤 2:初始化 PSO 种群
根据 PSO 参数初始化种群:
- 1. 设置种群规模 N=20,最大迭代次数 T=50;
- 2. 初始化每个粒子的位置:在参数范围内随机生成,如粒子 1:[512, 0.6, 8, 64];
- 3. 初始化每个粒子的速度:在 [-v_max, v_max] 范围内随机生成,v_max 设为参数范围的 10%,比如 chunk_size 的 v_max=76.8;
- 4. 初始化 pBest:每个粒子的初始位置;
- 5. 初始化 gBest:所有 pBest 中适应度值最高的位置。
步骤 3:参数有效性校验
在实际应用场景中必须增加这一步,避免无效参数导致大模型报错:
- 1. 格式校验:比如 chunk_size 必须是 64 的倍数,batch_size 必须是整数;
- 2. 资源校验:比如 batch_size=16 时,预估显存占用是否超过限制,若超过则调整为最大可行值;
- 3. 逻辑校验:比如 chunk_overlap 必须小于 chunk_size,否则分段无意义。
步骤 4:加载大模型与参数配置
根据粒子的位置(参数组合)加载大模型:
- 1. 加载基础模型,如 Llama-3-8B、ChatGLM3;
- 2. 配置向量库,如 FAISS、Milvus,设置 chunk_size、chunk_overlap;
- 3. 配置推理参数,设置 temperature、batch_size;
- 4. 加载针对问答任务的知识库数据。
步骤 5:执行目标任务并收集结果
运行预设的目标任务,收集评估所需的原始数据:
- 1. 执行 100 条标准化的知识库问答请求;
- 2. 记录每条请求的生成结果、推理耗时、显存占用;
- 3. 计算平均推理速度(tokens/s)、平均显存占用。
步骤 6:大模型评估效果生成适应度值
这是连接 PSO 和大模型的核心步骤,将主观效果转化为量化分数:
- 1. 准备评估提示词
请作为专业的评估师,对以下知识库问答的结果进行准确率打分:
问题:{question}
标准答案:{answer}
生成结果:{generated_answer}
打分规则:
1. 答案完全匹配,得10分;
2. 答案核心信息匹配,细节缺失,得7-9分;
3. 答案部分匹配,核心信息有误,得4-6分;
4. 答案完全不匹配,得0-3分。
请仅输出分数,不要输出其他内容。
- 2. 调用大模型(如API方式或本地部署的评估模型)对 100 条结果打分,计算平均分;
- 3. 计算速度得分和显存得分;
- 4. 按适应度函数计算最终适应度值。
步骤 7:更新 PSO 的 pBest/gBest 并调整粒子位置
- 更新 pBest:如果当前粒子的适应度值高于其历史 pBest,则更新 pBest 为当前位置;
- 更新 gBest:遍历所有粒子的 pBest,如果某个 pBest 的适应度值高于当前 gBest,则更新 gBest;
- 更新速度和位置:按 PSO 的速度和位置公式,计算每个粒子的新速度和新位置;
- 边界限制:新位置若超出参数范围,则截断到边界值,如 temperature=1.2 则改为 1.0。
步骤 8:判断终止条件
终止条件二选一或同时满足:
- 1. 迭代次数达到预设的 T=50;
- 2. gBest 的适应度值连续 5 轮迭代变化≤0.1(收敛)。
若满足终止条件,输出 gBest 对应的参数配置;否则回到步骤 3,继续下一轮迭代。
额外步骤:验证最优参数并落地
输出最优参数后,需进行验证:
- 1. 用最优参数重新运行 1000 条问答请求或扩大样本,确认效果稳定;
- 2. 对比人工调参的最优结果,验证 PSO 的优势;
- 3. 将最优参数写入大模型部署配置文件,落地到生产环境。
五、PSO + 大模型调参的基础示例
以下是一个完整的 PSO + 大模型调参示例,优化目标是“知识库问答任务的准确率 + 推理速度”,优化参数为 [chunk_size, temperature, batch_size]。
先采用本地Qwen1.5-1.8B模型进行推理生成,再通过混元模型的在线API进行验证;
import numpy as np
import time
import faiss
import os
import json
import pickle
from openai import OpenAI
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from tqdm import tqdm
from modelscope import snapshot_download
import torch
import warnings
warnings.filterwarnings("ignore")
# ====================== 1. 配置项 ======================
# 腾讯混元API配置(用于效果评估)- 请使用环境变量或替换为您的真实API密钥
API_KEY = os.environ.get("HUNYUAN_API_KEY", "替换为真是key") #
hunyuan_client = OpenAI(
api_key=API_KEY,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 大模型配置
MODEL_NAME = "qwen/Qwen1.5-1.8B-Chat"
CACHE_DIR = "D:\\modelscope\\hub"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {DEVICE}")
# PSO参数配置
POPULATION_SIZE = 10 # 种群规模(减小以加快测试)
MAX_ITER = 20 # 最大迭代次数(减小以加快测试)
W_MAX = 0.9 # 最大惯性权重
W_MIN = 0.4 # 最小惯性权重
C1 = 2.0 # 个体学习因子
C2 = 2.0 # 群体学习因子
V_MAX_RATIO = 0.2 # 速度最大值占参数范围的比例
# 参数空间配置(优化的参数及范围)
PARAM_CONFIG = {
"chunk_size": {"type": "int", "min": 256, "max": 1024, "step": 128},
"temperature": {"type": "float", "min": 0.1, "max": 1.0, "step": 0.1},
"batch_size": {"type": "int", "min": 1, "max": 8, "step": 1}
}
PARAM_NAMES = list(PARAM_CONFIG.keys())
PARAM_DIM = len(PARAM_NAMES)
# 评估用的知识库问答数据
QA_DATA = [
{"question": "什么是粒子群优化算法?", "answer": "粒子群优化(PSO)是一种基于群体智能的随机优化算法,灵感来源于鸟群觅食行为,通过粒子的位置和速度更新搜索最优解。"},
{"question": "PSO的核心参数有哪些?", "answer": "PSO的核心参数包括惯性权重、个体学习因子、群体学习因子、种群规模、最大迭代次数等。"},
{"question": "大模型temperature参数的作用是什么?", "answer": "temperature参数控制大模型生成文本的随机性,值越高生成越随机,值越低越确定。"},
{"question": "向量库chunk_size参数的作用是什么?", "answer": "chunk_size参数控制文本分段的大小,过小会导致上下文碎片化,过大则检索精度降低。"},
{"question": "batch_size参数对大模型推理有什么影响?", "answer": "batch_size参数控制批量推理的样本数,过小则推理速度慢,过大则显存占用过高。"},
]
EVAL_SAMPLE_NUM = len(QA_DATA)
# 全局模型缓存(避免重复加载)
_global_model = None
_global_tokenizer = None
_global_generator = None
# ====================== 2. 工具函数 ======================
def get_model_and_tokenizer():
"""获取全局模型和tokenizer(单例模式)"""
global _global_model, _global_tokenizer
if _global_model is None or _global_tokenizer is None:
print("正在加载模型...")
_global_tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
_global_model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
trust_remote_code=True,
torch_dtype=torch.float16 if DEVICE == "cuda" else torch.float32
).to(DEVICE)
_global_model.eval()
return _global_model, _global_tokenizer
def get_generator(batch_size=1):
"""获取生成管道"""
global _global_generator
model, tokenizer = get_model_and_tokenizer()
if _global_generator is None:
_global_generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device=0 if DEVICE == "cuda" else -1,
batch_size=batch_size
)
return _global_generator
def init_pso_population():
"""初始化PSO种群:位置和速度"""
positions = []
velocities = []
for _ in range(POPULATION_SIZE):
pos = []
vel = []
for name in PARAM_NAMES:
cfg = PARAM_CONFIG[name]
param_range = cfg["max"] - cfg["min"]
# 初始化位置:参数范围内随机采样
if cfg["type"] == "int":
# 在有效步长点中随机选择
valid_values = list(range(cfg["min"], cfg["max"] + 1, cfg["step"]))
pos_val = float(np.random.choice(valid_values))
else:
pos_val = np.random.uniform(cfg["min"], cfg["max"])
# 对齐步长
pos_val = round(pos_val / cfg["step"]) * cfg["step"]
pos_val = max(cfg["min"], min(cfg["max"], pos_val))
pos.append(pos_val)
# 初始化速度:参数范围的±V_MAX_RATIO
v_max = V_MAX_RATIO * param_range
vel_val = np.random.uniform(-v_max, v_max)
vel.append(vel_val)
positions.append(np.array(pos, dtype=np.float64))
velocities.append(np.array(vel, dtype=np.float64))
return np.array(positions, dtype=np.float64), np.array(velocities, dtype=np.float64)
def validate_parameters(params):
"""校验参数有效性,返回修正后的参数"""
validated = []
for i, name in enumerate(PARAM_NAMES):
cfg = PARAM_CONFIG[name]
val = float(params[i])
# 边界限制
val = max(cfg["min"], min(cfg["max"], val))
# 类型转换和步长对齐
if cfg["type"] == "int":
# 找到最近的合法步长点
valid_values = np.array(list(range(cfg["min"], cfg["max"] + 1, cfg["step"])))
idx = np.argmin(np.abs(valid_values - val))
val = float(valid_values[idx])
else:
# 对齐步长
val = round(val / cfg["step"]) * cfg["step"]
val = max(cfg["min"], min(cfg["max"], val))
validated.append(val)
return np.array(validated, dtype=np.float64)
def get_embedding(text, model, tokenizer):
"""获取文本嵌入向量"""
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512).to(DEVICE)
with torch.no_grad():
outputs = model.model(**inputs)
# 使用均值池化获取句子嵌入
attention_mask = inputs["attention_mask"]
token_embeddings = outputs.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
embedding = torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return embedding.cpu().numpy().astype(np.float32)
def build_vector_database(chunk_size, chunk_overlap=64):
"""构建向量库"""
model, tokenizer = get_model_and_tokenizer()
# 提取知识库文本
texts = [item["answer"] for item in QA_DATA]
# 文本分段
chunks = []
for text in texts:
tokens = tokenizer.encode(text, add_special_tokens=False)
if len(tokens) <= chunk_size:
chunk_text = tokenizer.decode(tokens)
chunks.append(chunk_text)
else:
for i in range(0, len(tokens), chunk_size - chunk_overlap):
chunk_tokens = tokens[i:i+chunk_size]
chunk_text = tokenizer.decode(chunk_tokens)
chunks.append(chunk_text)
if len(chunks) == 0:
chunks = texts # 如果分段失败,使用原文本
# 生成向量
embeddings = []
for chunk in tqdm(chunks, desc="Building embeddings", leave=False):
embedding = get_embedding(chunk, model, tokenizer)
embeddings.append(embedding)
embeddings = np.vstack(embeddings).astype(np.float32)
# 构建FAISS索引 - 修正:正确指定维度
dim = embeddings.shape[1]
index = faiss.IndexFlatL2(dim)
index.add(embeddings)
return index, chunks
def retrieve_context(question, index, chunks, top_k=1):
"""检索上下文"""
model, tokenizer = get_model_and_tokenizer()
# 生成问题向量
q_embedding = get_embedding(question, model, tokenizer)
# 检索Top-k
distances, indices = index.search(q_embedding, k=min(top_k, len(chunks)))
# 获取检索到的上下文
context_chunks = []
for idx in indices[0]:
if idx < len(chunks):
context_chunks.append(chunks[idx])
context = " ".join(context_chunks)
return context
def generate_answer(question, context, temperature, batch_size=1):
"""生成回答并记录耗时"""
generator = get_generator(batch_size)
model, tokenizer = get_model_and_tokenizer()
# 构建提示词(Qwen1.5-Chat使用对话格式)
prompt = f"""<|im_start|>system
你是一个有帮助的助手。请基于提供的上下文回答问题。<|im_end|>
<|im_start|>user
基于以下上下文回答问题:
上下文:{context}
问题:{question}
请简洁回答。<|im_end|>
<|im_start|>assistant
"""
# 生成回答并计时
start_time = time.time()
try:
outputs = generator(
prompt,
max_new_tokens=150,
temperature=temperature,
top_p=0.9,
do_sample=True if temperature > 0 else False,
pad_token_id=tokenizer.eos_token_id,
return_full_text=False
)
answer = outputs[0]["generated_text"].strip()
except Exception as e:
print(f"Generation error: {e}")
answer = "生成失败"
end_time = time.time()
generate_time = end_time - start_time
# 计算生成速度(tokens/s)
token_num = len(tokenizer.encode(answer))
generate_speed = token_num / generate_time if generate_time > 0 else 0
return answer, generate_speed
def get_hunyuan_evaluation(question, answer, generated_answer):
"""调用混元大模型评估回答准确率,返回0-10分"""
prompt = f"""请作为专业的评估师,对以下知识库问答结果的准确率进行打分(仅输出0-10的整数分数):
### 打分规则
- 10分:生成结果完全包含标准答案的所有核心信息,且无错误信息
- 8-9分:生成结果包含标准答案的核心信息,有少量非核心细节缺失
- 6-7分:生成结果包含部分核心信息,或有少量错误
- 4-5分:生成结果缺失较多核心信息
- 2-3分:生成结果核心信息大部分错误
- 0-1分:生成结果与问题无关
### 待评估内容
问题:{question}
标准答案:{answer}
生成结果:{generated_answer}
### 输出要求
仅输出一个整数分数(0-10),不要输出其他内容。"""
try:
response = hunyuan_client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=5
)
score_text = response.choices[0].message.content.strip()
# 提取数字
import re
numbers = re.findall(r'\d+', score_text)
if numbers:
score = int(numbers[0])
score = max(0, min(10, score))
else:
score = 5 # 默认分数
return score
except Exception as e:
print(f"Hunyuan evaluation error: {e}")
return 5 # 评估失败,返回默认分数
def simple_evaluate_answer(answer, standard_answer):
"""简化版评估:基于关键词匹配(当API不可用时使用)"""
answer_lower = answer.lower()
standard_lower = standard_answer.lower()
# 提取标准答案中的关键词(中文简单处理)
keywords = [word for word in standard_lower if len(word) > 1]
if len(keywords) == 0:
return 5
match_count = sum(1 for kw in keywords if kw in answer_lower)
score = int((match_count / len(keywords)) * 10)
return max(0, min(10, score))
def evaluate_fitness(params, use_api_eval=True):
"""计算适应度值:准确率得分×0.7 + 速度得分×0.3"""
# 1. 校验参数
params = validate_parameters(params)
chunk_size, temperature, batch_size = int(params[0]), float(params[1]), int(params[2])
# 2. 构建向量库
try:
index, chunks = build_vector_database(chunk_size)
except Exception as e:
print(f"Build vector database error: {e}")
return 0.0
# 3. 执行问答任务
total_accuracy_score = 0
total_speed = 0
valid_count = 0
for qa in tqdm(QA_DATA, desc=f"Evaluating params: {params}", leave=False):
try:
# 检索上下文
context = retrieve_context(qa["question"], index, chunks)
# 生成回答
generated_answer, speed = generate_answer(
qa["question"], context, temperature, batch_size
)
# 评估准确率
if use_api_eval and API_KEY != "sk-your-api-key-here":
accuracy_score = get_hunyuan_evaluation(
qa["question"], qa["answer"], generated_answer
)
else:
accuracy_score = simple_evaluate_answer(generated_answer, qa["answer"])
total_accuracy_score += accuracy_score
total_speed += speed
valid_count += 1
print(f" Q: {qa['question'][:30]}... | Score: {accuracy_score} | Speed: {speed:.2f}")
except Exception as e:
print(f"Error evaluating {qa['question']}: {e}")
continue
if valid_count == 0:
return 0.0
# 4. 计算平均分和平均速度
avg_accuracy = total_accuracy_score / valid_count
avg_speed = total_speed / valid_count
# 5. 归一化得分(0-10)
accuracy_score = min(10.0, max(0.0, avg_accuracy))
# 速度归一化:假设1-10 tokens/s为合理范围
speed_score = min(10.0, max(0.0, avg_speed))
# 6. 计算最终适应度值
fitness = accuracy_score * 0.7 + speed_score * 0.3
print(f"Params: {params} | Accuracy: {accuracy_score:.2f} | Speed: {speed_score:.2f} | Fitness: {fitness:.2f}")
return fitness
def update_pso(positions, velocities, pbest, pbest_fitness, gbest, gbest_fitness, iter_num):
"""更新PSO的速度和位置"""
# 线性递减惯性权重
w = W_MAX - (W_MAX - W_MIN) * iter_num / MAX_ITER
new_velocities = []
new_positions = []
for i in range(POPULATION_SIZE):
# 速度更新
r1 = np.random.uniform(0, 1, PARAM_DIM)
r2 = np.random.uniform(0, 1, PARAM_DIM)
vel_cognitive = C1 * r1 * (pbest[i] - positions[i])
vel_social = C2 * r2 * (gbest - positions[i])
new_vel = w * velocities[i] + vel_cognitive + vel_social
# 速度边界限制
for j in range(PARAM_DIM):
cfg = PARAM_CONFIG[PARAM_NAMES[j]]
v_max = V_MAX_RATIO * (cfg["max"] - cfg["min"])
new_vel[j] = max(-v_max, min(v_max, new_vel[j]))
# 位置更新
new_pos = positions[i] + new_vel
# 校验新位置
new_pos = validate_parameters(new_pos)
new_velocities.append(new_vel)
new_positions.append(new_pos)
return np.array(new_velocities, dtype=np.float64), np.array(new_positions, dtype=np.float64)
def save_history(history, filename="pso_history.json"):
"""保存历史记录为JSON格式"""
serializable_history = []
for record in history:
serializable_record = {
"iter": int(record["iter"]),
"gbest": [float(x) for x in record["gbest"]],
"gbest_fitness": float(record["gbest_fitness"])
}
serializable_history.append(serializable_record)
with open(filename, "w", encoding="utf-8") as f:
json.dump(serializable_history, f, indent=2, ensure_ascii=False)
print(f"历史记录已保存到 {filename}")
def load_history(filename="pso_history.json"):
"""加载历史记录"""
try:
with open(filename, "r", encoding="utf-8") as f:
history = json.load(f)
return history
except:
return []
# ====================== 3. 主执行函数 ======================
def main():
print("=" * 60)
print("=== PSO + 大模型RAG参数优化开始 ===")
print("=" * 60)
print(f"PSO参数:种群规模={POPULATION_SIZE}, 最大迭代={MAX_ITER}")
print(f"优化参数:{PARAM_NAMES}")
print(f"使用设备:{DEVICE}")
print(f"API评估:{'启用'}")
print("=" * 60)
# 1. 初始化PSO
print("\n[1/4] 初始化PSO种群...")
positions, velocities = init_pso_population()
print("[2/4] 评估初始种群...")
pbest = positions.copy()
pbest_fitness = np.zeros(POPULATION_SIZE)
for i in range(POPULATION_SIZE):
pbest_fitness[i] = evaluate_fitness(positions[i])
# 找到全局最优
gbest_idx = np.argmax(pbest_fitness)
gbest = pbest[gbest_idx].copy()
gbest_fitness = pbest_fitness[gbest_idx]
print(f"\n初始全局最优:{gbest} | 适应度:{gbest_fitness:.2f}")
# 记录每轮最优结果
history = [{
"iter": 0,
"gbest": gbest.tolist(),
"gbest_fitness": float(gbest_fitness)
}]
# 2. 迭代优化
print("\n[3/4] 开始PSO迭代优化...")
print("-" * 60)
for iter_num in range(MAX_ITER):
print(f"\n=== 迭代 {iter_num+1}/{MAX_ITER} ===")
print(f"当前全局最优参数:{gbest}")
print(f"当前全局最优适应度:{gbest_fitness:.2f}")
# 更新速度和位置
velocities, positions = update_pso(
positions, velocities, pbest, pbest_fitness, gbest, gbest_fitness, iter_num
)
# 计算新适应度
current_fitness = np.zeros(POPULATION_SIZE)
for i in range(POPULATION_SIZE):
current_fitness[i] = evaluate_fitness(positions[i])
# 更新个体最优
for i in range(POPULATION_SIZE):
if current_fitness[i] > pbest_fitness[i]:
pbest[i] = positions[i].copy()
pbest_fitness[i] = current_fitness[i]
# 更新全局最优
current_best_idx = np.argmax(current_fitness)
current_best_fitness = current_fitness[current_best_idx]
if current_best_fitness > gbest_fitness:
gbest = positions[current_best_idx].copy()
gbest_fitness = current_best_fitness
print(f"🎉 发现新的全局最优!适应度:{gbest_fitness:.2f}")
# 记录历史
history.append({
"iter": iter_num + 1,
"gbest": gbest.tolist(),
"gbest_fitness": float(gbest_fitness)
})
# 3. 输出结果
print("\n" + "=" * 60)
print("[4/4] 优化完成!")
print("=" * 60)
print("\n📊 最优参数配置:")
for i, name in enumerate(PARAM_NAMES):
print(f" • {name}: {gbest[i]}")
print(f"\n🏆 最优适应度值:{gbest_fitness:.2f}")
print(f" - 准确率得分:{gbest_fitness * 0.7 / 0.7:.2f}")
print(f" - 速度得分:{gbest_fitness * 0.3 / 0.3:.2f}")
# 保存历史记录
save_history(history)
# 保存最优参数
best_params = {name: gbest[i] for i, name in enumerate(PARAM_NAMES)}
with open("best_params.json", "w", encoding="utf-8") as f:
json.dump(best_params, f, indent=2, ensure_ascii=False)
print("\n最优参数已保存到 best_params.json")
return gbest, gbest_fitness, history
if __name__ == "__main__":
try:
best_params, best_fitness, history = main()
except KeyboardInterrupt:
print("\n\n⚠️ 用户中断,保存当前结果...")
# 保存中断前的结果
except Exception as e:
print(f"\n❌ 程序错误:{e}")
import traceback
traceback.print_exc()代码关键部分解释:
- PSO 初始化(init_pso_population)
- 按参数类型(int/float)和范围随机生成粒子位置,且对齐步长(如 chunk_size 必须是 64 的倍数);
- 速度初始化在参数范围的 ±10%,避免粒子移动过快跳出有效区域。
- 参数校验(validate_parameters)
- 类型转换:确保整数参数是 int 类型;
- 边界限制:防止参数超出预设范围;
- 步长对齐:保证参数是步长的整数倍,符合工程实践。
- 适应度计算(evaluate_fitness)
- 核心逻辑:将参数配置传入大模型和向量库,执行问答任务;
- 效果评估:调用模型API对生成结果打分,计算准确率;
- 速度计算:记录生成耗时,计算 tokens/s;
- 加权融合:准确率 ×0.7 + 速度 ×0.3,得到最终适应度值。
- PSO 更新(update_pso)
- 线性递减惯性权重:迭代初期大 w 增强探索,后期小 w 增强挖掘;
- 速度更新:结合惯性、个体学习、群体学习三部分;
- 位置更新:基于新速度计算位置,并校验有效性。
- 主函数(main)
- 初始化种群并计算初始适应度;
- 迭代更新粒子位置和速度,不断优化 pBest 和 gBest;
- 输出最优参数并保存历史记录,便于后续分析。
输出参考:
============================================================
=== PSO + 大模型RAG参数优化开始 ===
============================================================
PSO参数:种群规模=10, 最大迭代=20
优化参数:['chunk_size', 'temperature', 'batch_size']
使用设备:cuda
API评估:启用
============================================================[1/4] 初始化PSO种群...
[2/4] 评估初始种群...
Params: [512. 0.5 4.] | Accuracy: 7.20 | Speed: 8.50 | Fitness: 7.59初始全局最优:[512. 0.5 4. ] | 适应度:7.59
[3/4] 开始PSO迭代优化...
...
🎉 发现新的全局最优!适应度:8.12============================================================
[4/4] 优化完成!
============================================================📊 最优参数配置:
• chunk_size: 512
• temperature: 0.6
• batch_size: 4🏆 最优适应度值:8.12
六、总结
其实大模型调参真的不用死磕经验、瞎试参数了。以前总觉得调参是高手的活,靠感觉、靠积累,费时又费力,还未必能调出好效果。但 PSO 和大模型结合,直接把这件事变成了自动化工程,PSO 负责找参数、大模型负责打分,全程不用人工多干预,既高效又能找到全局最优解,彻底打破了调参靠运气的魔咒。
我们不用一开始就追求复杂。先把核心逻辑搞懂,从简单的单参数优化入手,比如先调 temperature,跑通整个流程,再慢慢增加参数维度。另外,别害怕出错,多跑几次迭代,看看收敛曲线、参数分布,慢慢就有感觉了。不用追求一步到位,先实现自动化调参,再慢慢优化算法、提升效果。毕竟,能把人工活变成自动化工程,既节省时间,又能挖掘大模型的潜力,这才是咱们学这项技术的核心意义。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)