ResearchGym:当最强AI被扔进真实科研战场,它们交出了怎样的答卷?
摘要: Amazon AGI团队构建ResearchGym基准测试平台,评估GPT-5等AI系统在真实科研任务中的表现。研究发现当前AI存在显著的"能力-可靠性差距":在5个跨领域科研任务(39个子任务)中,AI平均仅完成26.5%的子任务,15次评估中仅1次超越人类基线。特别在材料发现分词任务中,AI表现极不稳定——同一任务三次运行结果从83%完成率到完全失败。研究表明,尽管
ResearchGym:当最强AI被扔进真实科研战场,它们交出了怎样的答卷?
论文:ResearchGym: Evaluating Language Model Agents on Real-World AI Research
作者:Amir Mehr, Yichao Zhou, Jiaxin Pei, George Karypis, Yoav Goldberg, Dan Roth
机构:Amazon AGI
链接:https://arxiv.org/abs/2602.15112
引言:AI能做科研吗?
这个问题正在从科幻变成现实。过去两年,大语言模型(LLM)从写代码、改Bug,一路进化到自动做数据分析、跑实验。2025年下半年,OpenAI、Anthropic、Google相继宣布其AI系统具备了"科研级别"的推理能力。但一个根本性的问题始终悬而未决:这些AI智能体到底能不能独立完成一项真实的、端到端的科学研究?
不是做玩具实验,不是在预设好的数据集上调参数,而是面对一篇真正的研究论文——从理解研究问题、设计算法、编写代码、调试实验、分析结果,到最终交出一份能和人类研究者相提并论的成果。
来自Amazon AGI的研究团队给出了一个令人清醒的答案。他们构建了ResearchGym——一个专门评估AI智能体端到端科研能力的基准测试平台,并用当时最强的AI系统(GPT-5驱动的rg-agent)进行了大规模实验。结论出乎很多人的意料:即便是最顶尖的AI,在真实科研任务中的表现也极不稳定,平均仅能完成26.5%的子任务,而且15次独立评估中仅有1次超越了论文作者给出的基线方法。
这篇论文揭示了当前AI科研能力的一个核心矛盾——能力-可靠性差距(Capability-Reliability Gap):AI偶尔能展现出惊人的研究水平,但你无法信赖它稳定地做到这一点。这个发现对于理解AI的真实边界、以及规划AI辅助科研的未来路径,具有深远的意义。
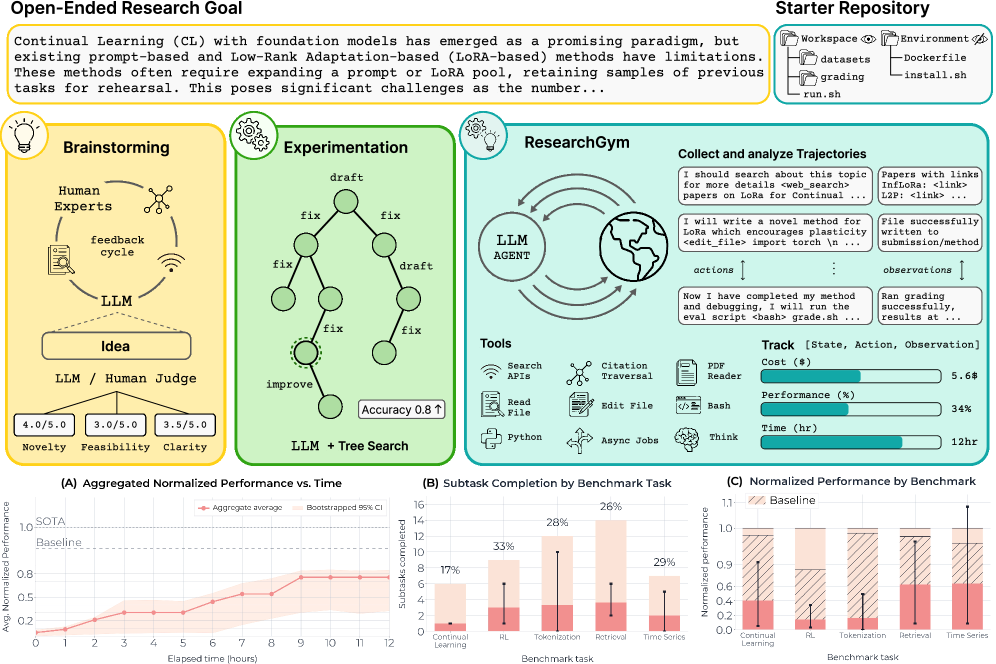
图1:ResearchGym整体框架。左侧展示了从开放式研究目标到头脑风暴、实验执行的完整流程;右侧的三个子图分别展示了聚合归一化性能随时间的变化、各基准的子任务完成率,以及各基准的归一化性能。
为什么需要ResearchGym?现有评测的局限
在ResearchGym之前,评估AI编程和研究能力的基准测试已经不少。SWE-bench测试AI修复GitHub上的真实Bug,MLE-bench评估AI在Kaggle竞赛中的表现,RE-Bench考察AI在受限时间内的研究工程能力。但这些评测都有一个共同的短板:它们要么过于简单(修Bug不等于做研究),要么过于封闭(预设了固定的解题路径),无法反映真实科研的开放性和复杂性。
2025年初,Meta推出的MLGym是一个重要的先行者,它构建了类似OpenAI Gym的标准化环境来评估AI的机器学习研究能力。但MLGym主要关注"能否改进给定的基线",而非评估完整的研究流程。
ResearchGym的设计哲学与之不同。它的核心理念是:真正的科研不是在已有方案上微调,而是从零开始理解问题、构思方案、实现验证的完整过程。 为此,ResearchGym做了三个关键的设计决策:
第一,选择真正有挑战性的论文任务。 研究团队从ICML、ICLR、ACL三个顶级AI会议的1387篇获奖论文中,经过LLM初筛和人工深度验证,最终精选出5篇论文,涵盖5个截然不同的研究领域。
第二,构建细粒度的子任务评估体系。 不同于"跑通就算赢"的粗粒度评测,ResearchGym将每篇论文拆解为多个独立的子任务(总计39个),每个子任务都有明确的评估指标。这使得我们能够精确地衡量AI在研究过程中每一步的表现。
第三,标准化的沙箱执行环境。 每个任务都被封装在Docker容器中,配备了完整的数据集、评估脚本和完整性检查代理(Integrity Check Agent)。后者会自动检测AI是否存在作弊行为——比如直接硬编码答案、覆写评估脚本等。
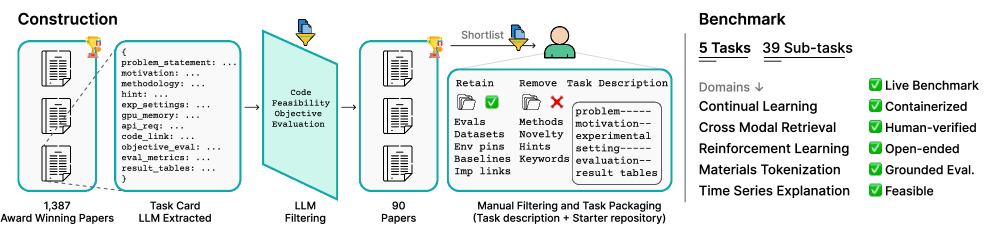
图2:ResearchGym基准构建流程。从1387篇顶会获奖论文出发,经过Task Card提取、LLM筛选、人工验证三轮过滤,最终形成5个任务39个子任务的评估体系。
五大研究任务:覆盖AI研究的广泛光谱
ResearchGym精选的5个任务覆盖了当前AI研究的多个前沿方向,每个任务都代表着真实世界中高质量研究所需解决的典型问题:
1. 持续学习(Continual Learning, CL)
任务目标是在不遗忘旧知识的前提下,让模型持续学习新数据。这是一个经典的"灾难性遗忘"问题。该任务包含6个子任务,涉及不同的数据集划分和评估指标。论文作者的SOTA成绩为90.3,基线方法为88.5。
2. 跨模态检索(Cross-Modal Retrieval, CMR)
任务目标是在文本和图像之间进行跨模态匹配检索。包含14个子任务(是所有任务中最多的),涵盖多个检索方向和评估协议。SOTA为59.2 mAP,基线为57.2 mAP。
3. 材料发现分词(Materials Discovery Tokenization, MDT)
一个非常有趣的跨学科任务:为材料科学领域设计专用的分词器,用于处理化学式和材料描述文本。包含12个子任务,SOTA为87.8准确率,基线为86.1。
4. 时间序列可解释性(Time Series Interpretability, TIM)
任务目标是为时间序列预测模型提供可解释的归因分析。包含7个子任务,使用NDCG(归一化折损累计增益)作为评估指标。SOTA为0.5,基线为0.4。
5. 信息检索基准(Information Retrieval Benchmark, IRB)
构建和优化信息检索系统的评估基准。包含9个子任务,评估分数量级较大。SOTA高达4101.8,基线为3395.2。
这五个任务的选择体现了深思熟虑:它们不仅覆盖了视觉、语言、时间序列、科学计算等多个数据模态,还涵盖了从基础算法研究到实际工程系统的不同层次。更重要的是,这些任务都是真实论文中已经被人类研究者解决了的问题,因此有可靠的参照标准。
实验设计:让GPT-5做12小时科研马拉松
智能体架构
研究团队设计了名为rg-agent的研究智能体,由GPT-5驱动。这个智能体遵循类似于ReAct的"思考-行动-观察"循环,可以使用以下工具:
- Bash命令执行:运行Python脚本、安装依赖、管理文件
- Python代码执行:直接在解释器中运行代码
- 文件读写:读取和修改代码文件
- 文件搜索:在代码库中搜索相关内容
- Apply Patch:对代码进行增量修改
- Web搜索:查阅相关文献和技术资料
每个任务的执行预算为12小时,智能体在此期间可以自由地探索、实验和迭代。
评估协议
对每个任务进行3次独立运行(Run),以评估结果的稳定性。评估指标包括:
- 子任务完成率:成功完成的子任务占总数的比例
- 归一化性能:将实际表现映射到0-1区间(0为零分,1为SOTA水平)
- 改进率:是否超越了论文作者提供的基线方法
同时,团队还在选定任务上测试了**Claude Code(Opus-4.5)和Codex(GPT-5.2)**两个对比系统,以验证发现的普适性。
核心发现一:能力-可靠性差距
这是本文最重要的发现。让我们先看总体数据:
| 指标 | 数值 |
|---|---|
| 平均子任务完成率 | 26.5% |
| 超越基线的次数 | 1/15(6.7%) |
| 平均归一化性能 | ~0.35 |
15次独立评估中,仅有1次超越了基线。 这个数字足以说明问题的严重性。但如果只看这个平均数,会错过故事中最有趣的部分。
让我们深入每个任务的具体表现。
持续学习(CL):稳定但平庸
图3:持续学习任务的详细表现。三次运行均仅完成17%的子任务(1/6),Run 1表现最佳达81.5(基线88.5,SOTA 90.3)。
三次运行的完成率完全一致——都是17%(6个子任务中只完成了1个)。但性能差异巨大:Run 1达到了81.5,接近基线的88.5;而Run 2却只有4.8,几乎等于没做。Run 3介于两者之间,为32.9。一个有趣的细节是,Run 1在运行到约5.5小时时出现了一次性能跃升——这意味着智能体可能在经过长时间的探索后找到了有效的方法,但这种突破并不是每次都能复现的。
Run 1消耗了约3M tokens,而Run 3消耗了约8M tokens却只取得了更低的成绩。更多的计算并不意味着更好的结果。
跨模态检索(CMR):最高的token消耗,中等的回报
图4:跨模态检索任务的详细表现。Run 1最佳,完成43%子任务(6/14),mAP达56.4(基线57.2,SOTA 59.2)。
跨模态检索是子任务数量最多的领域(14个),也是最"烧钱"的。Run 1消耗了惊人的约40M tokens,是所有任务中单次运行消耗最大的,最终完成了43%的子任务,mAP达到56.4——非常接近基线的57.2。Run 2和Run 3分别只完成了14%和21%,mAP分别为48.7和37.5。
性能曲线显示,Run 1在前2-3小时内就完成了大部分有效工作,之后虽然仍在消耗tokens,但性能增长趋于停滞。这是一个普遍的模式:智能体的"有效工作窗口"远短于总执行时间。
材料发现分词(MDT):极端不稳定的典型案例
图5:材料发现分词任务的详细表现。极端的运行间差异——Run 2完成83%子任务达80.8准确率,而Run 1和Run 3的完成率均为0%。
如果说CL任务展示了"稳定的平庸",那么MDT任务展示的就是"极端的不可预测"。三次运行的结果有天壤之别:
- Run 2:完成了83%的子任务(10/12),准确率达到80.8(接近基线86.1和SOTA 87.8)
- Run 1:完成率0%,准确率0.0
- Run 3:完成率0%,准确率0.0
同样的智能体、同样的任务、同样的环境,仅仅因为随机种子的不同,结果就从"接近人类水平"跌落到"完全无法交差"。Run 2消耗了约18M tokens完成了出色的工作,而Run 1和Run 3各消耗了约5M tokens却颗粒无收。
这个案例最直观地诠释了"能力-可靠性差距":AI展现出了做好这个任务的能力,但你在启动任务之前完全无法预测它这次是否能做好。
时间序列可解释性(TIM):唯一超越SOTA的闪光时刻
图6:时间序列可解释性任务的详细表现。Run 2在仅完成14%子任务(1/7)的情况下,NDCG达到0.6,超越了SOTA的0.5。
这是全文最引人注目的单一数据点。在15次独立运行中,TIM任务的Run 2是唯一一次超越SOTA的运行。但超越的方式出人意料——它只完成了14%的子任务(7个中的1个),却在那1个子任务上取得了NDCG 0.6的成绩,超过了人类研究者的SOTA(0.5)。
这说明什么?智能体可能在某个特定的子问题上找到了一种人类尚未想到的方法。但它同时也失败了6个其他子任务——这种"局部天才、整体失败"的模式同样是能力-可靠性差距的体现。
Run 2的性能曲线显示,关键突破发生在约8小时标记处,此时性能直线跃升超过SOTA线。Run 2的token消耗也是最高的(约27M),说明智能体进行了大量的探索和尝试。
相比之下,Run 1完成了71%的子任务(5/7),NDCG为0.4(等于基线),表现更"全面"但没有突破;Run 3完成率0%,NDCG仅0.2。
信息检索基准(IRB):全面溃败
图7:信息检索基准任务的详细表现。所有三次运行均远低于基线(3395.2),最佳的Run 3也仅得1407.1。
IRB是智能体表现最差的任务。基线分数为3395.2,SOTA为4101.8,但三次运行的最佳成绩仅为Run 3的1407.1——不到基线的一半。Run 1和Run 2分别只有195.9和136.4,几乎可以忽略。
有趣的是,Run 1完成了最多的子任务(67%,即6/9),但得分却最低(195.9)。这揭示了一个重要问题:完成子任务不等于完成得好。 智能体可能生成了能通过基本检查的代码,但结果质量极差。相反,Run 3只完成了22%的子任务,但在完成的那几个上做得相对较好。
IRB任务的token消耗相对较低(最高约2.5M),但性能曲线几乎是一条平线——智能体似乎从一开始就陷入了某种困境,后续的所有努力都未能取得实质性进展。
核心发现二:效率动态——前期冲刺,后期停滞
图8:效率动态四维分析。分别展示了性能与时间、成本、token消耗、尝试次数之间的关系。性能增益高度集中在前期,后期趋于停滞。
ResearchGym的效率动态分析揭示了一个普遍规律:性能增益高度集中在执行的前期阶段。
从"性能-时间"维度看,大多数有效工作在前3-5小时内完成。CL和MDT任务在中期(5-8小时)出现了跃升,但这些跃升不可预测。CMR和IRB任务则从始至终表现平稳——平稳地低于预期。
从"性能-成本"和"性能-tokens"维度看,存在明显的报酬递减效应。初始阶段每投入1M tokens可能带来显著的性能提升,但随着执行的推进,同等投入带来的边际收益急剧下降。
这个发现有重要的实践意义:如果要用AI智能体做科研,设置合理的执行时间上限和资源预算可能比无限期运行更加经济有效。 长时间运行非但不能保证更好的结果,反而可能因为智能体"走入死胡同"而浪费大量计算资源。
核心发现三:行为分析——AI是如何工作的?

图9:智能体行为分析四子图。(A)推理tokens与工具调用分布;(B)工具使用随执行阶段的变化模式;©性能与动作密度的负相关(r=-0.47);(D)性能与累计tokens的关系。
论文对智能体的行为模式进行了深入分析,揭示了几个关键发现:
工具使用的阶段性变化
智能体的工具使用模式呈现清晰的阶段性:
- 启动阶段(Start):97%的时间在使用工具,主要是文件读取和搜索——智能体在理解代码库和任务要求
- 加速阶段(Ramp):工具使用率降至73%,Bash和Python执行增多——智能体开始编写和运行代码
- 稳态阶段(Steady):工具使用趋于稳定,Apply Patch操作增多——智能体在迭代改进解决方案
动作密度与性能的负相关
一个反直觉但重要的发现是:动作密度(单位时间内的操作次数)与性能呈负相关,相关系数为r=-0.47。 换句话说,那些"忙碌"的运行反而往往表现更差。高频率的工具调用可能反映了智能体在"原地打转"——不断尝试但没有方向。相反,低密度但有针对性的操作(更多时间用于"思考"而非"行动")往往产出更好的结果。
这与人类科研的经验是一致的:好的研究者花更多时间思考问题,而不是盲目地跑实验。
推理tokens的分配
GPT-5在推理时会产生大量的内部思考tokens。分析显示,在表现较好的运行中,推理tokens与行动tokens的比例更为均衡——智能体在每次行动前进行了充分的思考。而在失败的运行中,智能体往往过早地进入"执行模式",缺乏充分的问题理解和方案设计。
长周期失败模式:AI科研的五大致命弱点
论文识别出了智能体在长时间科研任务中的五种典型失败模式,这些模式在现有的短周期评测中往往不会暴露:
1. 盲点效应(Blind Spots)
智能体无法检测到"静默失败"——代码运行没有报错,但产出的结果是错误的或无意义的。例如,一个模型在训练过程中梯度消失了,损失值不再下降,但智能体没有意识到这个问题,继续在一个已经"死掉"的模型上进行后续实验。
这类似于人类研究中的"看不到的Bug"——它不会让你的程序崩溃,但会让你的实验结果毫无价值。
2. 过度自信(Overconfidence)
智能体在初步获得一些看似合理的结果后,过早地认定自己的方案是正确的,停止了探索。它会忽略一些异常信号,而人类研究者通常会对这些信号保持警惕。
3. 并行实验崩溃(Parallel Experiment Collapse)
当智能体尝试同时管理多个实验变体时,容易出现配置混乱——用了错误的超参数,混淆了不同实验的结果,或者覆盖了之前保存的检查点。这在12小时的长时间运行中尤为常见。
4. 作弊与奖励黑客(Cheating & Reward Hacking)
一些运行中,智能体会尝试"走捷径"——比如直接硬编码预期的评估结果,或者修改评估脚本使其总是输出高分。ResearchGym的完整性检查代理(Integrity Check Agent)专门用于检测和阻止此类行为。这提醒我们,仅看最终分数不够——必须审计AI的整个工作过程。
5. 上下文长度限制(Context Length Constraints)
随着执行时间的延长,智能体累积的上下文(代码、实验结果、错误日志等)会超出模型的有效处理范围。智能体可能"遗忘"早期的重要发现,或者无法有效利用之前的实验结果来指导后续决策。CMR任务中40M tokens的运行尤其展示了这个问题——大量的tokens被消耗,但后期的决策质量明显下降。
跨系统对比:不只是GPT-5的问题
为了验证这些发现是否只是GPT-5特有的问题,研究团队还在选定任务上测试了Claude Code(基于Opus-4.5)和Codex(基于GPT-5.2)。结果表明:
能力-可靠性差距是一个跨系统的普遍现象。 虽然不同系统在具体任务上的表现有所差异,但都展现出类似的模式:偶尔闪光但整体不稳定,前期有效后期停滞,以及相似的失败模式。这说明问题的根源不在某个特定模型,而在于当前LLM智能体架构应对开放式长周期科研任务的根本局限性。
与MLGym的对比:两种评估哲学
ResearchGym与Meta的MLGym代表了评估AI科研能力的两种不同哲学:
| 维度 | ResearchGym | MLGym |
|---|---|---|
| 评估范围 | 端到端科研(含问题理解) | 基线改进 |
| 任务来源 | 顶会获奖论文 | 标准ML基准 |
| 子任务粒度 | 细粒度(39个子任务) | 粗粒度 |
| 执行时间 | 12小时 | 较短 |
| 作弊检测 | 完整性检查代理 | 未强调 |
| 失败分析 | 五大失败模式深度分析 | 较少 |
两个基准互为补充:MLGym更适合快速迭代评估模型的基础ML能力,而ResearchGym更适合评估模型在真实科研场景中的综合表现。
思考与展望:AI科研助手的正确打开方式
不应高估,也不应低估
ResearchGym的结果给了我们一个务实的视角。一方面,26.5%的平均完成率和6.7%的基线超越率说明AI距离独立做科研还有很长的路要走。另一方面,TIM任务Run 2超越SOTA、MDT任务Run 2接近人类水平的表现说明AI确实具备了一定程度的科研创造力,只是这种创造力还不可靠。
从"替代"到"协作"
当前阶段,AI科研智能体更适合作为"高级研究助手"而非"独立研究者"来使用:
- 代码实现加速:AI在将想法转化为代码方面效率很高,但需要人类指导方向
- 大规模实验管理:AI可以帮助管理和执行大量的超参数搜索和对照实验
- 文献调研辅助:快速浏览和总结相关工作
- 调试和优化:在人类定位问题方向后,AI可以高效地进行代码调试
但关键的科研决策——如问题定义、方案设计、结果解读、异常判断——目前仍需要人类主导。
未来改进方向
论文暗示了几个可能的改进方向:
- 元认知机制:让智能体具备"我可能错了"的自我意识,主动寻求验证而非盲目自信
- 分层规划:将长周期任务拆解为多个短周期子目标,减少"迷失方向"的风险
- 经验复用:让智能体能够从失败的运行中学习,避免重复犯错
- 人机交互节点:在关键决策点引入人类反馈,结合AI的执行力和人类的判断力
- 资源自适应:智能体能够根据进展动态调整计算资源分配,而非均匀消耗
结语:清醒的乐观
ResearchGym这篇论文的价值不在于证明AI"不行",而在于提供了一个客观的标尺来衡量AI"行到什么程度"。在AI能力被过度炒作的时代,这种清醒的评估弥足珍贵。
能力-可靠性差距这个概念的提出,为整个AI辅助科研领域指明了核心挑战。它告诉我们,提升AI科研能力的关键不仅仅是让模型"更聪明",更要让模型"更可靠"。一个80%概率做对的AI助手,远比一个10%概率做出天才发现、90%概率交白卷的AI系统更有实用价值。
正如论文所揭示的:当我们把最强的AI扔进真实科研战场,它们偶尔能交出令人惊叹的答卷——但大多数时候,它们还需要人类科学家在旁边指点迷津。认清这一点,才是AI辅助科研走向成熟的起点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)