深度学习篇---MoE
MoE(混合专家)是一种高效的大模型架构,其核心思想是分诊台+专科医生机制。通过门控网络(分诊台)动态选择最相关的专家网络(专科医生),每次只激活部分专家(通常2-64个),既保持万亿级参数容量又降低计算成本。关键设计包括稀疏激活、负载均衡和专家容量限制。典型应用如Mixtral 8x7B(8专家激活2个)和Switch Transformer(万亿参数)。优势是计算高效、知识容量大,但存在路由学
🤔 一、MoE是什么?
1.1 从生活例子说起
想象你是一家大型综合医院的院长:
-
普通医院:只有一个全科医生,什么病都看。但一个人的知识有限,看不过来,效率也低。
-
MoE医院:你有很多专科医生——心脏科、神经科、儿科、骨科...每个都是各自领域的专家。病人来了,你先判断他是什么病,然后只叫对应的专家来看。
MoE在AI里就是这样的机制:不是用一个巨大的模型处理所有问题,而是训练一群"专家"模型,每次只激活最相关的几个。
1.2 为什么需要MoE?
随着AI模型越来越大(GPT-3 1750亿参数、GPT-4 万亿级),一个严重问题出现了:
| 问题 | 通俗解释 | 类比 |
|---|---|---|
| 计算成本太高 | 参数越多,算得越慢、越贵 | 全科医生再厉害,也看不过来所有病人 |
| 稀疏激活 | 很多参数其实用不上 | 看感冒时,骨科专家的知识闲置 |
MoE的解决方案:把大模型拆成多个"专家",每次只激活一小部分。这样既保留了大规模参数的知识容量,又控制了实际计算量。
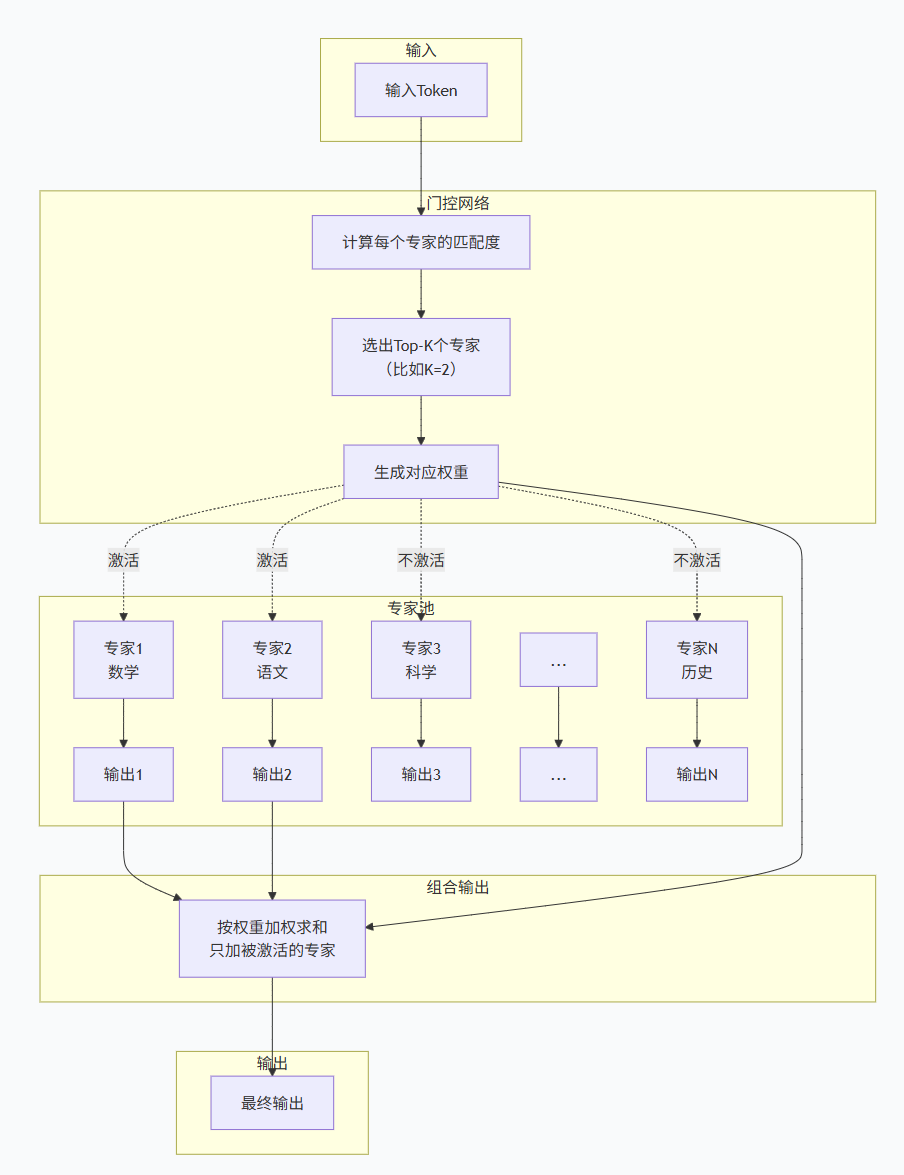
🧩 二、MoE的核心组件
一个典型的MoE层由三个部分组成:
2.1 专家网络(Experts)
-
就是一堆小型的神经网络(通常是FFN,前馈网络)
-
每个专家擅长处理某类特定的输入(比如一个专家擅长数学,一个擅长文学)
-
专家数量可以从几个到几千个不等
2.2 门控网络(Gating Network / Router)
-
这是MoE的"分诊台"
-
它的任务:看当前输入是什么,决定叫哪些专家,以及每个专家贡献多少
-
输出一组权重(比如[0.8, 0.15, 0.05, 0, 0...]),表示每个专家的激活程度
2.3 组合输出
-
把被激活的专家的输出,按门控网络给的权重加权求和
-
得到最终的输出
🔄 三、MoE的工作流程:三步走
用一个具体例子来说明:假设你输入"苹果是什么颜色的?"
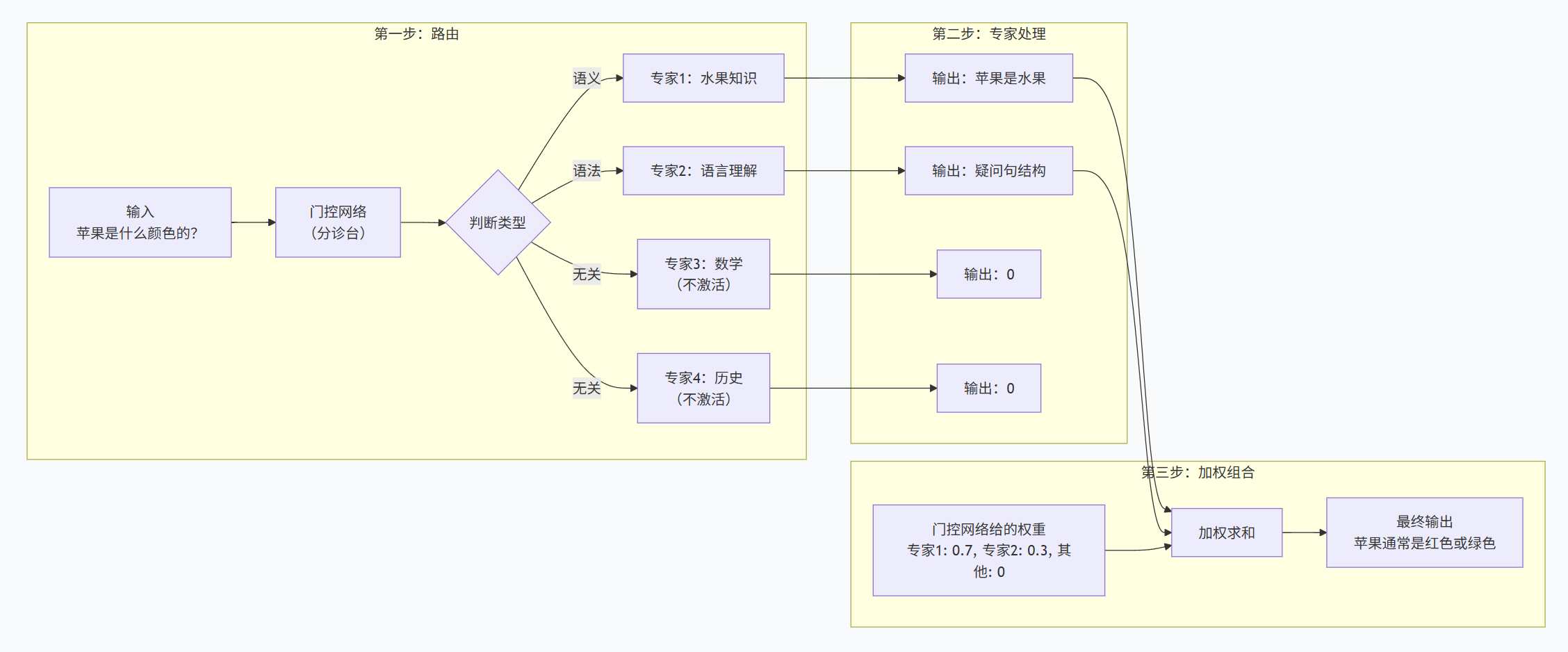
三步通俗理解:
| 步骤 | 做了什么 | 比喻 |
|---|---|---|
| 第1步:路由 | 门控网络看输入,决定叫哪些专家 | 分诊台问"什么病?",决定叫哪个专科医生 |
| 第2步:专家处理 | 被叫到的专家各自给出见解 | 心脏科医生看心脏,骨科医生看骨头 |
| 第3步:组合 | 按权重把专家意见混合 | 综合各科意见,给出最终诊断 |
🎯 四、MoE的关键设计
4.1 稀疏激活(Sparse Activation)
-
不是所有专家都干活,通常只激活Top-K个(比如K=2,只激活最相关的2个)
-
假设有64个专家,每次只激活2个,计算量只有全激活的1/32
通俗理解:医院有50个专科,但一个病人最多看2-3个科室就够了。
4.2 负载均衡(Load Balancing)
-
问题:如果门控网络总叫同一个专家,其他专家就白训练了
-
解决:加一个负载均衡损失,鼓励门控网络均匀地调用所有专家
通俗理解:不能让一个医生累死,其他医生闲死。要合理分配病人。
4.3 专家容量(Expert Capacity)
-
问题:如果某个专家被太多输入同时叫到,会过载
-
解决:给每个专家设一个"最大接诊量",超出的输入会被丢弃或重新路由
通俗理解:每个专家一上午最多看20个病人,超出的挂不上号。
🏆 五、MoE的知名应用
5.1 语言模型领域
| 模型 | 参数量 | 激活参数 | 专家数量 | 特点 |
|---|---|---|---|---|
| Mixtral 8x7B | 470亿 | 130亿 | 8个 | 每层8个专家,激活2个 |
| GShard | 6000亿 | - | 2048个 | Google早期MoE尝试 |
| Switch Transformer | 1.6万亿 | - | 2048个 | 每次只激活1个专家 |
| DeepSeekMoE | 160亿 | 28亿 | 64个 | 更细粒度的专家划分 |
5.2 多模态领域
-
MoE-LLaVA:视觉语言模型中引入MoE,让不同专家处理不同类型的视觉问题
5.3 科学计算
-
Intern-S1-Pro:万亿参数科学大模型,512个专家,每次只激活8个
📊 六、MoE的优缺点
| 优点 | 通俗解释 |
|---|---|
| ✅ 计算高效 | 参数多但计算少,激活部分专家就行 |
| ✅ 容量大 | 可以容纳超大规模知识(万亿参数) |
| ✅ ** specialization ** | 每个专家专注一类任务,效果更好 |
| ✅ 训练稳定 | 专家之间互不干扰,并行训练 |
| 缺点 | 通俗解释 |
|---|---|
| ❌ 通信开销大 | 专家可能在不同GPU上,数据传来传去慢 |
| ❌ 路由难学 | 门控网络需要学会正确分配,训练复杂 |
| ❌ 负载不均 | 容易有的专家累死、有的闲死 |
| ❌ 推理复杂 | 部署时多个专家要同时准备,工程挑战大 |
📈 七、MoE的发展趋势
7.1 细粒度专家
传统:一个专家就是一个完整的FFN
现在:把专家拆得更细,每个专家负责更小的知识面
7.2 共享专家
-
设置一些"共享专家",所有输入都必须经过
-
保证基础能力,再让专科专家补充
7.3 与新架构结合
-
MoE + Mamba:Nemotron 3,高效处理长文本
-
MoE + RWKV:探索中,结合高效推理
7.4 动态路由
-
不固定激活K个专家,而是根据输入复杂度动态决定
🧩 八、Mermaid总结框图(简单明了直接)
💡 九、一句话总结
MoE = 一个"分诊台" + 一群"专科医生",每次只叫最相关的几个专家看病
-
分诊台(门控网络):看输入是什么,决定叫谁
-
专科医生(专家网络):各自擅长不同领域
-
只激活Top-K:省计算、保效率
-
负载均衡:不让个别专家累死
它的伟大之处:
| 传统大模型 | MoE大模型 |
|---|---|
| 所有人干所有事 | 专人干专事 |
| 参数多,算得也慢 | 参数多,但算得快 |
| 知识全混在一起 | 知识分模块存放 |
| 难扩展 | 容易加新专家 |
这也是为什么几乎所有顶级大模型(GPT-4、Mixtral、DeepSeek)都在用MoE——用更少的算力,撬动更大的知识容量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)