深度学习篇---混合架构
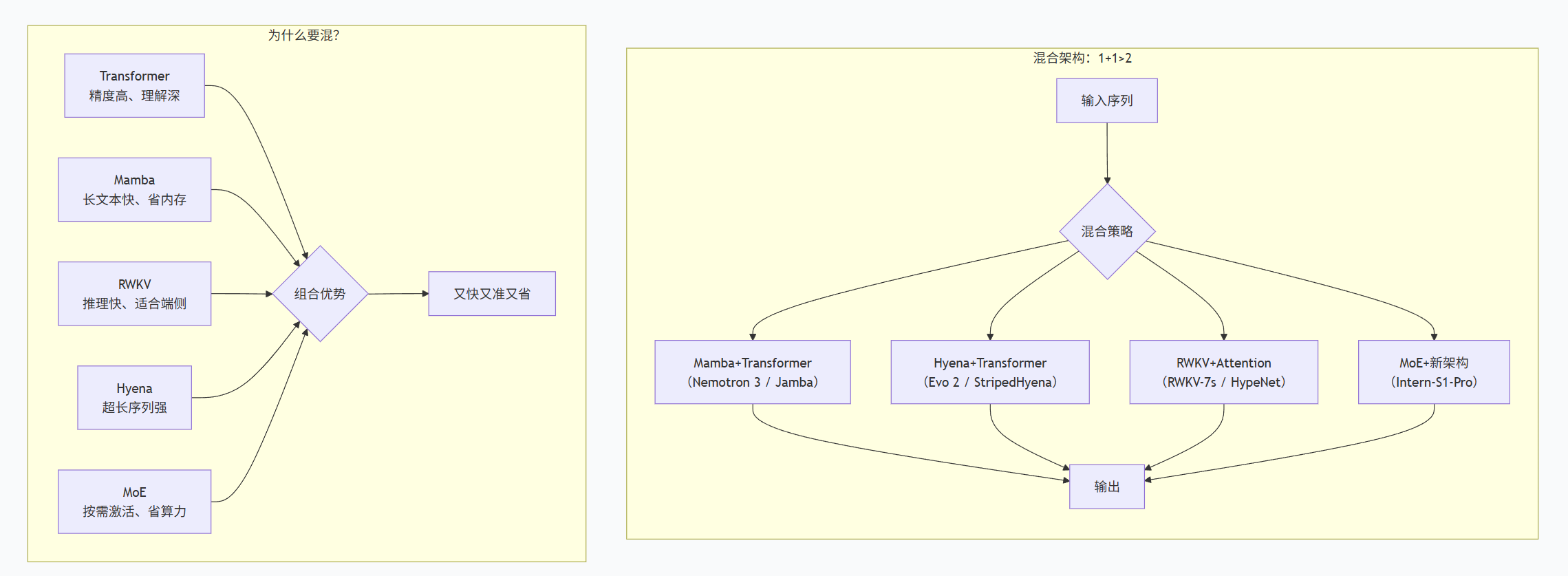
AI混合架构正成为行业新趋势,通过结合不同架构优势来解决单一模型的局限性。主流混合模式包括:Mamba+Transformer(长文本处理+精准推理)、Hyena+Transformer(超长序列分析)、RWKV+Attention(移动端部署)以及MoE+新架构(多领域通用)。这种各司其职的设计理念,让不同架构在擅长的领域发挥作用,既提升效率又保证精度。混合架构的兴起源于应用场景多样化需求、算力
我们来看看当下AI架构圈最火的"混血儿"们——混合架构。
🤔 一、什么是混合架构?
混合架构 = 把不同架构的优点组合在一起
就像混动汽车(油+电)既有燃油车的续航,又有电动车的省油,AI混合架构也是取各家之长:
| 架构 | 优点 | 缺点 |
|---|---|---|
| Transformer | 精度高、理解深、擅长复杂推理 | 计算量大、长文本吃力、推理慢 |
| Mamba | 处理长文本快、省内存 | 某些精细任务表现不如Transformer |
| RWKV | 推理快、适合手机端 | 长文本能力仍在优化 |
| Hyena | 超长序列建模强、速度快 | 通用任务生态还在建设中 |
混合架构的目标:让它们在一起工作,各自干自己最擅长的事。
🧬 二、主流的混合架构模式
模式1:Mamba + Transformer(最火组合)
代表模型:
-
NVIDIA Nemotron 3:Mamba层负责长文本高效处理,Transformer层负责精准推理,再加上MoE(混合专家)让计算更高效
-
Jamba/Samba:Mamba和Attention层交错排列,取长补短
通俗理解:
Mamba像"速记员",飞快地浏览长文档记重点;Transformer像"分析师",对重点内容深入思考。两个人配合,又快又准。
适合场景:长文本处理+复杂推理,比如多轮对话、长文档问答
模式2:Hyena + Transformer
代表模型:
-
Evo 2:用Hyena架构处理百万级DNA序列,Transformer层做精细分析
-
StripedHyena:Hyena和Attention混合,在通用语言任务上比肩LLaMA
通俗理解:
Hyena像"猎犬",能在超长DNA序列中追踪模式;Transformer像"科学家",对找到的模式进行精确解读。
适合场景:生物信息学、超长文档分析
模式3:RWKV + Attention
代表模型:
-
RWKV-7s:RWKV与DEA(DeepEmbed Attention)混合,KV Cache仅为MLA的1/9
-
HypeNet:清华团队提出的新架构,用HyPE位置编码让混合模型长文本能力更强
通俗理解:
RWKV像"电动车",省电(省内存)能跑远;Attention像"涡轮增压",需要爆发力时介入。
适合场景:手机端部署、无限上下文聊天
模式4:MoE(混合专家)+ 新架构
代表模型:
-
Intern-S1-Pro:万亿参数科学大模型,512个专家,每次只激活8个
-
Nemotron 3 MoE:引入Latent MoE,专家数翻4倍,计算成本不变
通俗理解:
不是所有专家都上班,而是根据问题"按需点将"。问物理问题,只叫物理专家;问化学问题,只叫化学专家。
适合场景:多领域通用模型、科学计算
📊 三、Mermaid总结框图(简单明了直接)
🎯 四、各混合架构适合什么场景?
| 混合模式 | 代表模型 | 适合场景 | 核心优势 |
|---|---|---|---|
| Mamba+Transformer | Nemotron 3、Jamba | 长文本对话、多智能体系统 | 1M上下文+高吞吐 |
| Hyena+Transformer | Evo 2 | 基因组学、DNA分析 | 百万级序列+零样本预测 |
| RWKV+Attention | RWKV-7s、HypeNet | 手机端、边缘部署 | KV Cache极小、推理快 |
| MoE+新架构 | Intern-S1-Pro | 科学计算、多学科通用 | 万亿参数但只激活2% |
💡 五、为什么混合架构是趋势?
-
没有完美的单一架构:Transformer不是万能药,新架构各有特长但各有短板
-
应用需求多样化:有的场景要长文本(如DNA),有的要低延迟(如手机),有的要高精度(如数学推理)——单一架构很难兼顾
-
算力效率是王道:混合架构可以在关键处用Attention,大段文本用高效架构,整体算力更省
-
"蒸馏"技术成熟:清华HALO技术可以用2.3B token(不到原训练数据的0.01%)把纯Transformer转成混合架构
🔮 六、一句话总结
混合架构 = 让不同架构各司其职,该快的地方快,该准的地方准
就像一支球队:有前锋(Mamba/Hyena)负责冲,有中场(RWKV)负责控,有后卫(Transformer)负责稳,还有替补(MoE)随时待命。各展所长,才能赢得比赛。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)