深度学习篇---Attention
Attention机制是AI处理序列数据的革命性突破,其核心思想是让模型能够动态聚焦于输入中的关键信息。通过查询(Q)、键(K)、值(V)三个角色,Attention实现了三步计算:相似度比对、权重分配和加权聚合。Self-Attention允许词之间相互关注,Multi-Head机制则从多角度理解关系。虽然Attention本身不区分顺序,但通过位置编码解决了这一问题。相比传统RNN,Atten
我们来聊聊AI世界里最核心、最神奇的机制——Attention(注意力机制)。我会用最通俗的方式,让你彻底理解它是什么、为什么重要、怎么工作。
🤔 一、Attention是什么?
1.1 从生活例子说起
想象你在一个嘈杂的派对上,想听朋友说话:
-
你的耳朵:能听到所有人的声音(全部信息)
-
你的大脑:自动聚焦到朋友的声音上,忽略背景噪音(选择重要信息)
这就是注意力——从大量信息中,聚焦到重要的部分。
Attention在AI里做的是同一件事:让模型在处理当前词时,能从所有词中找到最相关的那些,重点关注它们。
1.2 为什么需要Attention?
在Attention出现之前(2017年以前),AI处理序列主要靠RNN/LSTM:
| 方式 | 问题 | 类比 |
|---|---|---|
| RNN/LSTM | 一步步传递信息,距离越远信息越弱 | 像"传话游戏",传到最后可能面目全非 |
| Attention | 直接关注所有位置,没有距离衰减 | 像"直接打电话",不管多远都能听清 |
Attention的革命性:让模型有了全局视野,不再受距离限制。
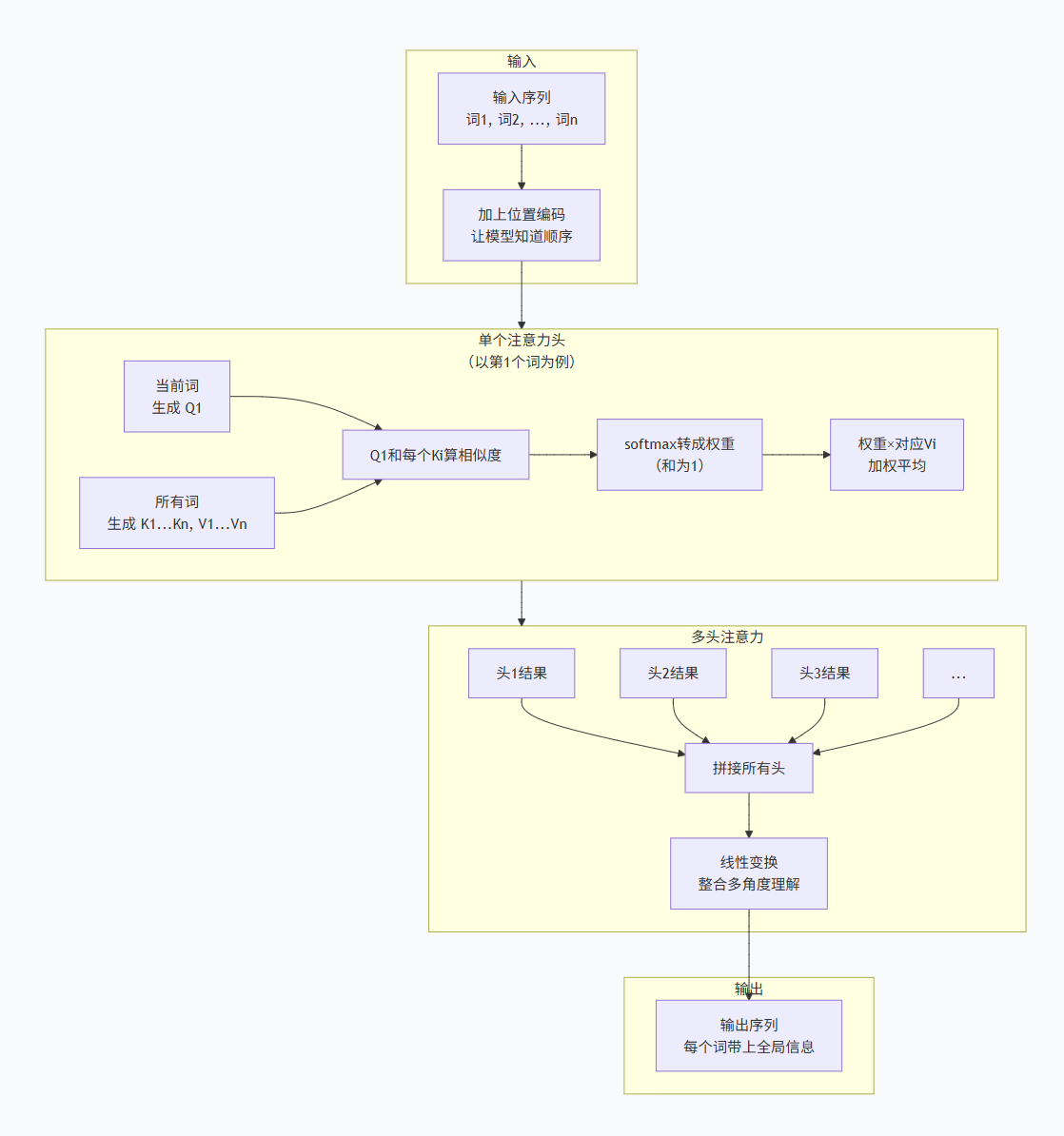
🔧 二、Attention的核心思想:三个角色
Attention机制的核心是三个角色:查询、键、值。用一个图书馆找书的例子来理解:
| 角色 | 符号 | 在图书馆的例子 | 在AI里的作用 |
|---|---|---|---|
| 查询(Query) | Q | 你要找的书名 | 当前词想问:谁和我相关? |
| 键(Key) | K | 书的标签/索引 | 每个词回答:我是什么? |
| 值(Value) | V | 书的实际内容 | 每个词的实际信息 |
找书的过程:
-
你拿着书名(Q)去图书馆
-
查看所有书的标签(K),看哪些匹配
-
匹配度高的书,取出它的内容(V)来读
Attention的过程:
-
当前词带着Q去问所有词
-
计算Q和每个词的K的匹配度
-
用匹配度作为权重,对所有词的V进行加权平均
📊 三、Attention的计算:三步走
3.1 核心公式(先看后解释)
Attention(Q, K, V) = softmax(Q·K^T / √d) · V
看起来复杂,拆解成三步就简单了:
3.2 三步通俗拆解
| 步骤 | 计算 | 通俗理解 | 比喻 |
|---|---|---|---|
| 第1步 | Q·K^T | Q和每个K做点积,算出相似度 | 书名和每本书的标签比对,越像分越高 |
| 第2步 | softmax(···) | 相似度转成权重(0-1之间,总和为1) | 比分转成百分比,越相关占比越大 |
| 第3步 | 权重·V | 用权重对V加权平均 | 按百分比取每本书的内容,混在一起 |
3.3 那个√d是什么?
-
d:向量的维度(比如1024维)
-
√d:用来做缩放,防止点积结果太大,softmax后梯度太小
通俗理解:就像音量太大时调小一点,别把耳朵震聋。
🎯 四、Self-Attention:自己和自己玩
上面说的是Q、K、V来自不同地方的情况。但在Transformer里,用的其实是Self-Attention(自注意力):
-
Q、K、V都来自同一个地方——输入序列本身
-
每个词和所有词(包括自己)算注意力
为什么需要Self-Attention?
通俗理解:
当你看"他喜欢吃苹果"时,想知道"他"是谁。你需要看这句话里的其他词来推断。Self-Attention就是让词之间互相"看"对方,理解彼此关系。
👑 五、Multi-Head Attention:多个角度理解
5.1 为什么需要多个头?
一个注意力头只能从一个角度理解关系。但语言是复杂的:
-
语法关系:"猫"和"追"(主谓关系)
-
语义关系:"猫"和"老鼠"(捕食关系)
-
位置关系:"追"和"老鼠"(动宾关系)
5.2 Multi-Head怎么工作?
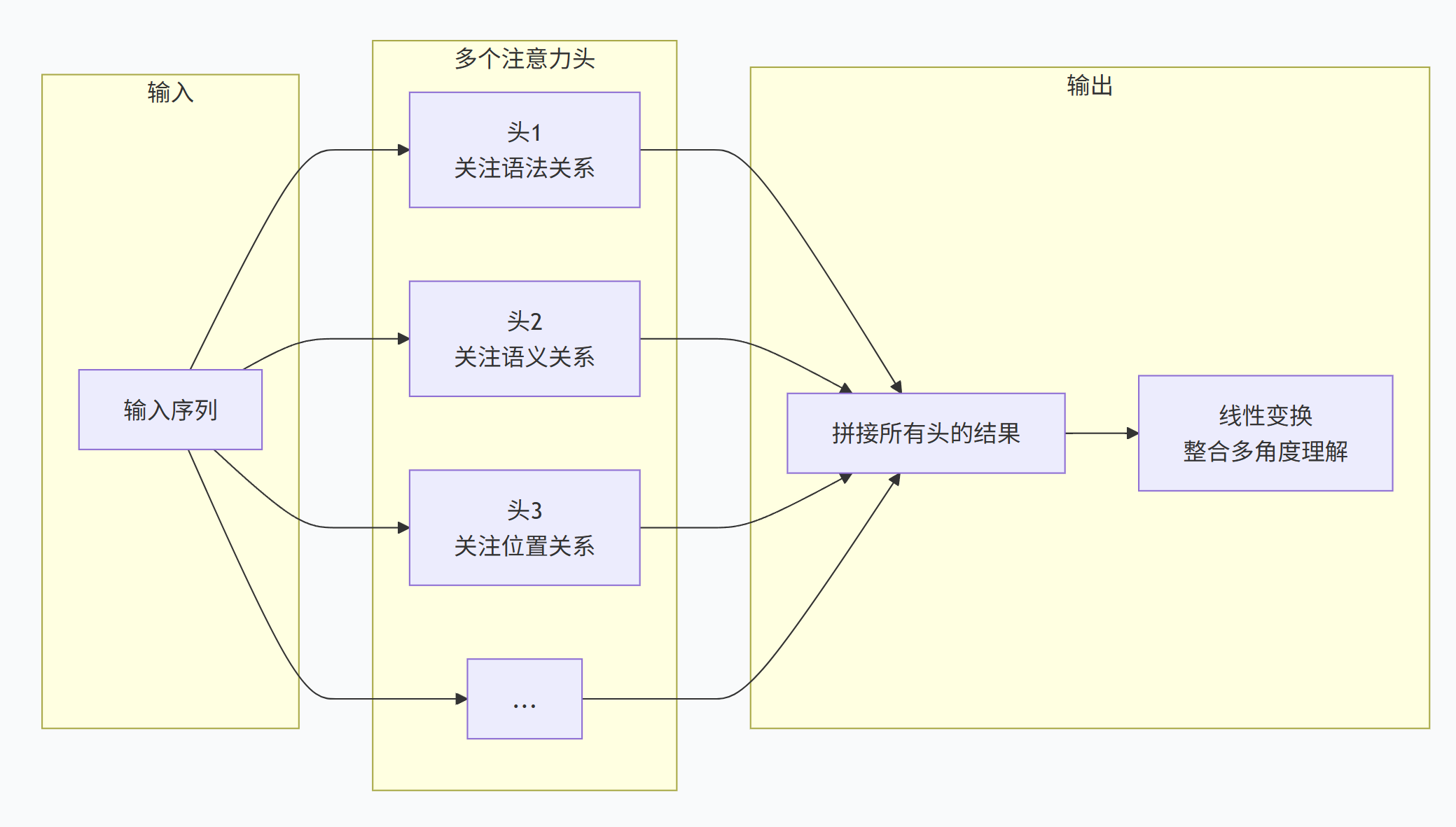
通俗理解:
就像一个团队同时从语法、语义、逻辑、情感等多个角度分析一句话,最后把所有人的见解汇总,得到更全面的理解。
🧩 六、Position Encoding:给词加上位置
6.1 问题:Attention本身不分顺序
Attention计算时,如果把词顺序打乱,结果是一样的——因为它只算"谁和谁相关",不管"谁先谁后"。
6.2 解决办法:加上位置信息
给每个词加上一个位置编码,就像给每个学生发一个学号:
输入 = 词向量 + 位置向量
这样模型就知道:"我"在第1位,"爱"在第2位,"你"在第3位。
📊 七、Mermaid总结框图(简单明了直接)
💡 八、一句话总结
Attention = 用Q去问所有K谁重要,按重要程度取V的信息
-
Q:当前词想问什么
-
K:每个词说自己是什么
-
V:每个词的实际内容
-
softmax:相似度转成权重
-
加权平均:按权重取信息
它的伟大之处:
| 之前(RNN) | 之后(Attention) |
|---|---|
| 信息只能一步步传 | 信息可以直接跳 |
| 越远信息越弱 | 没有距离衰减 |
| 难并行 | 可以并行计算 |
| 长文本吃力 | 长文本也能处理 |
这也是为什么Transformer叫"Attention Is All You Need"——有了Attention,RNN/CNN都不需要了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)