冥想盆范式:让大模型学会管理自己的上下文
《冥想盆范式:让大模型学会管理自己的上下文》摘要 本文提出StateLM框架,赋予大语言模型自主记忆管理能力。受《哈利·波特》中冥想盆启发,该框架包含外部笔记本和deleteContext操作两个核心组件,使模型能主动压缩关键信息到外部存储并清理冗余上下文。通过两阶段训练(监督学习模仿专家轨迹+强化学习优化决策),StateLM仅需1/4的上下文窗口即可超越传统长上下文模型。在2M token极端
冥想盆范式:让大模型学会管理自己的上下文
一句话总结:论文提出 StateLM,赋予大语言模型"自主记忆管理"能力,通过主动剪枝、笔记压缩和索引检索,用 1/4 的上下文窗口实现了超越传统长上下文模型的性能。
📖 开篇:邓布利多的困境
《哈利·波特》里有个神奇的物件叫"冥想盆"——一个可以存储、提取和审视记忆的石盆。邓布利多经常把自己的记忆放进去,需要时再拿出来查看。这给了研究者一个启发:
我们已经有成熟的数据库和检索系统(冥想盆),但模型缺一根操作它的魔杖。
现在的大语言模型就像没有能动性的邓布利多,只能被动接受人工构建的上下文。你塞给它什么,它就处理什么。上下文越长,它越累——直到撑爆上下文窗口,直接崩溃。
但如果把魔杖交给模型自己呢?让它自己决定记什么、删什么、什么时候查笔记?
这就是 StateLM 要做的事。
🧠 核心问题:上下文的线性诅咒
传统大模型的工作模式是一个致命缺陷:上下文只能线性累积。
看这张对比图就明白了:
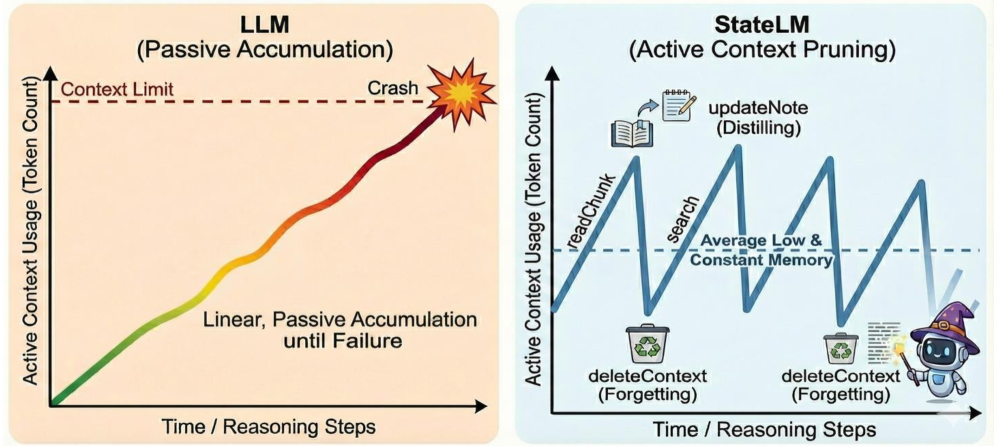
图1:传统LLM的上下文像一条只能增长不能减少的斜线,最终撞墙;StateLM则像锯齿状波形,始终保持紧凑
传统 LLM 的上下文使用是一条斜率恒定的直线——每处理一轮对话、每读取一段文档,上下文就增长一点。直到撞上上下文窗口的天花板,模型直接"脑溢血"(OOM 或性能骤降)。
这就像你读书时,每读一页就在脑子里堆一堆纸,从不扔掉任何东西。读到第100页时,脑子里塞满了前面99页的所有细节,新信息根本塞不进去。
StateLM 的思路是:让上下文像锯齿一样波动。读到关键信息时上下文膨胀,提取完精华后立即"清场",保持工作记忆的轻盈。就像读书记笔记——把要点抄到本子上,原书就可以合上了。
🏗️ StateLM 架构:把魔杖交给模型
Pensieve 范式的两个支柱
StateLM 的核心是 Pensieve 范式,包含两个关键组件:
| 组件 | 功能 | 类比 |
|---|---|---|
| 外部笔记本(External Notebook) | 存储压缩后的关键信息 | 读书时的笔记卡片 |
| deleteContext 操作 | 删除已完成的消息 | 合上已经读完的书页 |
这和传统 RAG 有本质区别。RAG 是"外挂知识库",模型是被动的查询者;StateLM 是"自主记忆管理",模型是主动的决策者。
工具箱:模型的记忆管理利器
论文为模型配备了一套完整的工具,分四类:
1. 上下文感知类
analyzeText:估算输入文档的长度,判断是否需要索引checkBudget:检查当前上下文还能塞多少 token
2. 信息获取类
buildIndex:为长文档构建倒排索引(基于 BM25)searchEngine:关键词检索,返回相关片段readChunk:加载指定片段的完整内容
3. 内存管理类(核心!)
note/updateNote:将关键信息压缩存储到外部笔记本readNote:从笔记本检索之前的笔记deleteContext:删除已完成的消息,释放上下文空间
4. 终止类
finish:输出最终答案,结束推理
推理流程:锯齿状上下文是如何形成的
看这张流程图,StateLM 的推理过程一目了然:
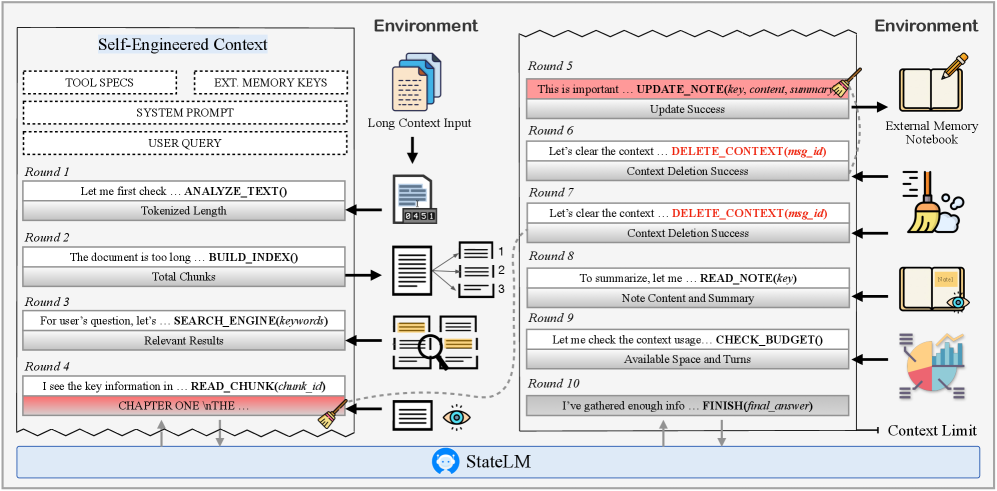
图2:StateLM 的推理流程——每一步都在评估、读取、记录、清理,形成锯齿状上下文
用大白话说,流程是这样的:
- 先量一量:
analyzeText看文档有多长 - 超长就建索引:
buildIndex给文档建目录 - 按需搜索:
searchEngine根据问题关键词找相关片段 - 读关键段落:
readChunk加载具体内容 - 记笔记:
updateNote把关键信息压缩存入外部笔记本 - 立即清场:
deleteContext删除原始片段和中间消息 - 循环直到完成:重复上述过程,直到收集足够信息
- 输出答案:
finish结束推理
关键在第 6 步——读完立刻删。这就像读书时,把要点抄到笔记本上,然后就可以把书合上,脑子瞬间清爽。
🔧 训练方法:教模型用魔杖
光给工具还不够,模型得学会用。StateLM 采用两阶段训练:
阶段一:监督学习(SFT)
用"教师模型"(Claude Opus 4.1)生成专家轨迹——就是一套标准答案般的工具调用序列。
但不是所有轨迹都要。论文设计了两种"拒绝采样":
- 基于结果的拒绝采样:只保留最终答案正确的轨迹
- 基于过程的拒绝采样:筛选出上下文管理行为正确的轨迹(比如该删的时候真的删了)
还有一个重要设计叫行动平衡。如果某种工具调用太少,模型可能学不会用。所以论文对不同工具的样本做了平衡,确保模型学会使用所有工具。
阶段二:强化学习(RL)
SFT 只是让模型"模仿",RL 才是让模型"内化"。
论文采用了类似 GRPO(Group Relative Policy Optimization)的训练目标。GRPO 是 DeepSeek 团队提出的一种高效 RL 算法,特点是省掉了 Critic Model——不需要单独的价值网络来估计动作好坏,而是通过组内相对比较来计算优势。
具体来说:
- 对同一问题生成多个候选轨迹
- 根据最终答案正确性、格式合规性、是否超时等因素计算奖励
- 在组内对奖励归一化,计算相对优势
- 用这个优势来更新策略
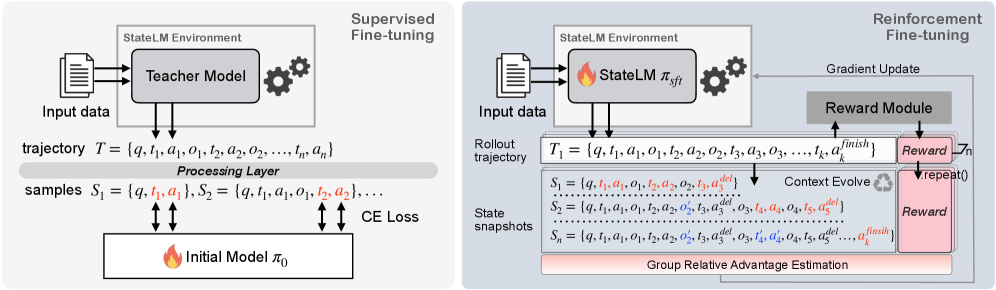
图3:两阶段训练流程——SFT 让模型学会模仿,RL 让模型学会优化
论文还设计了一个轨迹快照机制。在 RL 过程中,对同一条轨迹的不同阶段截取快照,形成多个训练样本,提高数据利用率。
🧪 实验结果:用更少上下文,做更好的任务
长文档问答:1/4 上下文窗口,全面超越
论文在 NovelQA 和 ∞Bench 两个长文档问答数据集上做了测试。关键发现:
StateLM 只用 32K 上下文窗口,就超越了使用 128K 窗口的标准 LLM。
| 模型 | NovelQA | ∞Bench |
|---|---|---|
| Qwen3-4B | 39.62 | 63.52 |
| StateLM-4B | 70.00 | 77.45 |
| Qwen3-8B | 42.77 | 63.87 |
| StateLM-8B | 67.39 | 67.86 |
| Qwen3-14B | 46.54 | 63.52 |
| StateLM-14B | 63.52 | 78.04 |
更关键的是,StateLM 的性能不随证据位置变化。传统 LLM 在文档后半部分(128-256K token)性能暴跌,而 StateLM 保持稳定:
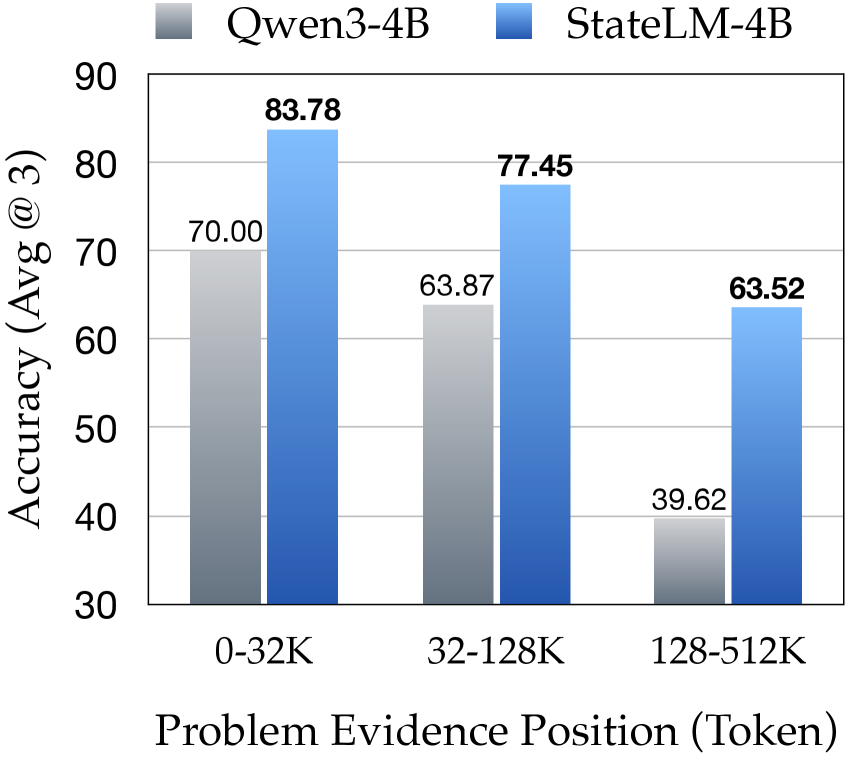
图4:4B 模型对比——StateLM 在远距离证据上优势明显
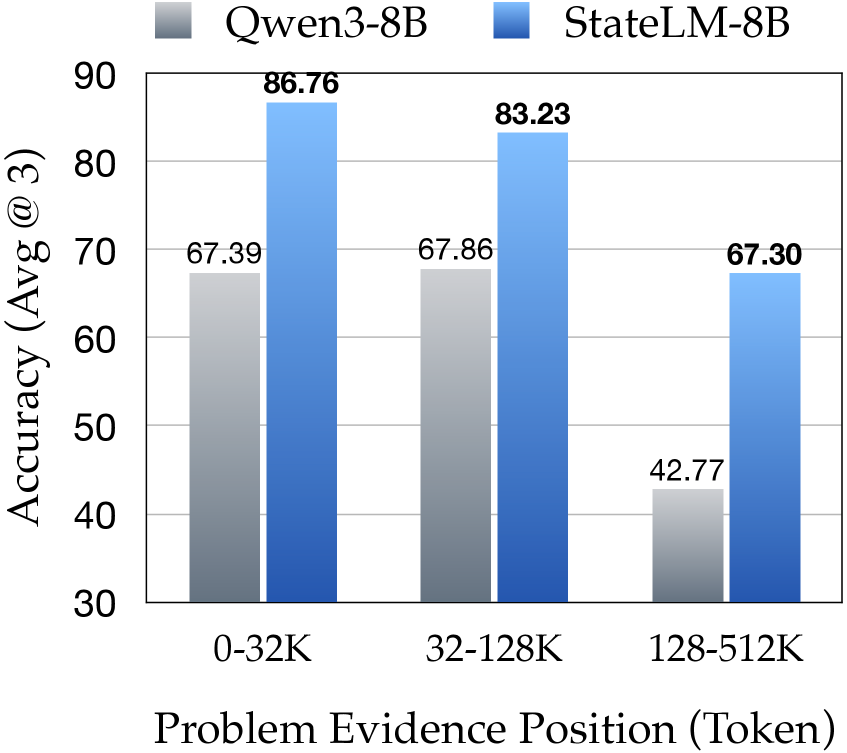
图5:8B 模型对比——StateLM 保持稳定,传统模型在后半部分断崖下跌
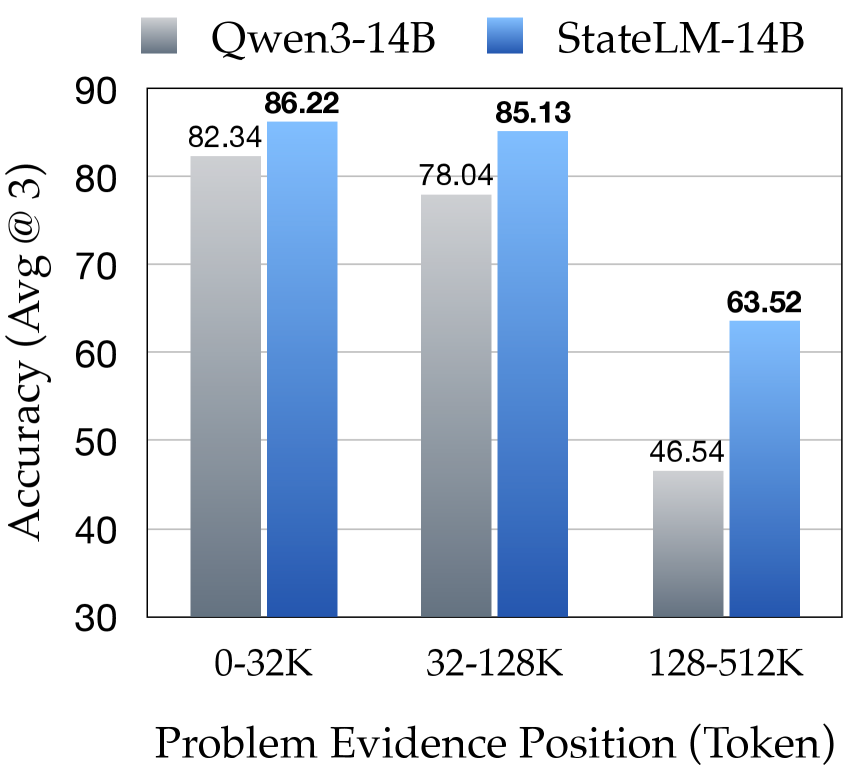
图6:14B 模型对比——StateLM 在所有位置都优于传统模型
极限测试:2M Token 的 Needle-in-a-Haystack
在大海捞针测试中,当上下文长度超过 128K 时,标准 Qwen3-14B 的准确率跌到 1.7% 左右。而 StateLM-14B 在 2M token 的极端情况下仍保持 83.89% 的准确率。
这就像在一个 200 万字的小说里找一句特定的对话,传统模型几乎放弃了,StateLM 依然能准确定位。
对话记忆:10%-20% 的绝对提升
在 LongMemEval-S 数据集(测试聊天助手的长期记忆能力)上,StateLM 实现了 10% 到 20% 的绝对准确率提升。
这个任务测试五种能力:信息提取、多轮推理、时间推理、知识更新、弃权(知道什么时候该说"我不知道")。StateLM 在 Multi-Hop(多跳推理) 问题上优势最大——需要关联多个历史对话才能回答的问题。
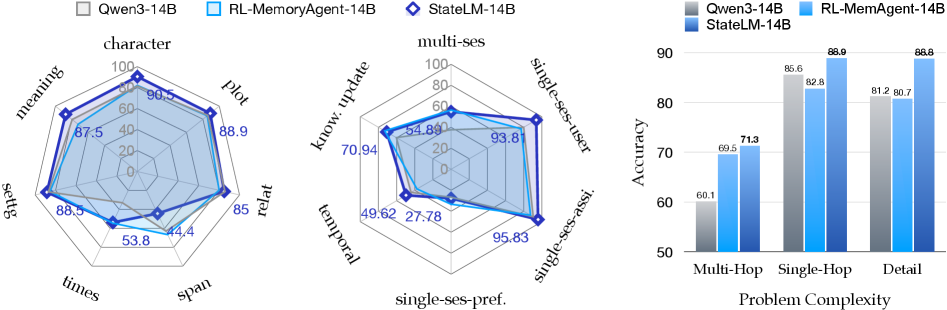
图7:Multi-Hop 问题上 StateLM 优势最大,Single-Hop 相对较弱
深度研究任务:最惊人的差距
BrowseComp-Plus 是一个"深度研究"任务——模型需要通过搜索引擎迭代检索、交叉验证信息,回答复杂问题。
这是所有任务中差距最大的:
| 模型 | 准确率 |
|---|---|
| Qwen3-14B(标准) | ~5% |
| StateLM-14B-RL | 52% |
差了 40 多个百分点。这个结果很说明问题:深度研究需要大量的迭代和信息整合,传统模型的上下文很快就会溢出或变得混乱,而 StateLM 的锯齿状上下文管理让整个过程井井有条。
📊 消融分析:为什么光有提示词不够?
论文做了一个有意思的对比:给标准 Qwen3 模型配上同样的工具和详细的系统提示,让它"假装"自己能管理上下文。结果:
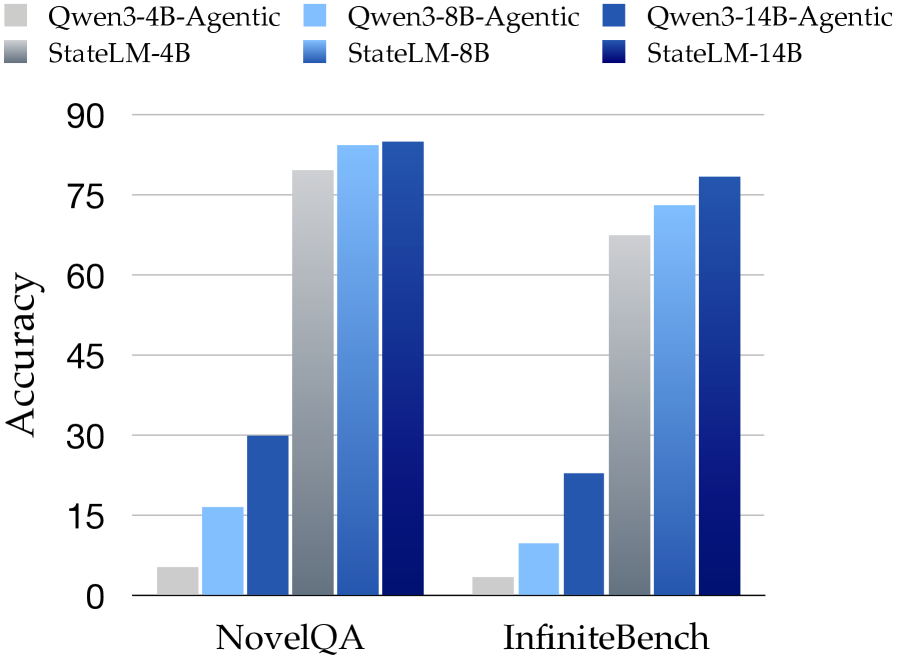
图8:即使配上详细提示词,标准 LLM 也远不如经过训练的 StateLM
在 NovelQA 和 ∞Bench 上,这种"提示词工程"的方法准确率比 StateLM 低了一大截,而且经常出现上下文溢出错误。
这证明了:光靠提示词教不会模型真正管理上下文。模型需要通过训练,内化"什么时候该删、什么时候该记"的判断能力。
错误分析:StateLM 还有哪些短板?
论文也诚实地指出了几个问题:
-
搜索限制:基于 BM25 的关键词检索对隐含或意译查询效果有限。比如问题问"主角为什么难过",但原文用的是"心如刀绞",关键词匹配就找不到。
-
格式错误:在超长轨迹或小模型上,偶尔会出现工具调用格式错误。
-
删除不及时:有时删除操作会滞后,导致上下文短暂溢出。
💡 我的观点
这个工作的亮点
1. 范式转变的勇气
从"模型是被动的上下文接收者"转变为"模型是主动的上下文管理者",这个思路很漂亮。与其不断扩展上下文窗口(128K → 1M → 10M…),不如让模型学会"断舍离"。
2. 锯齿状上下文的直觉
"锯齿状上下文"这个比喻很到位。就像人的工作记忆——容量有限,但可以通过"记笔记+清脑子"的方式处理无限量的信息。这不是扩展内存,而是优化内存使用策略。
3. 工程友好的设计
StateLM 的工具箱设计很务实。deleteContext 和 notebook 的组合,本质上就是一个轻量级的"外部内存"方案,不需要复杂的向量数据库,部署成本可控。
需要关注的问题
1. BM25 的局限性
论文使用的检索方案是基于关键词的 BM25,这在语义理解上明显不如向量检索。对于"换个说法"的查询,StateLM 可能会漏掉关键信息。
我自己在工程实践中遇到过类似问题:用户问"用户流失率",但文档里写的是"客户减少比例",BM25 直接找不到。换成向量检索后,召回率明显提升。
2. 小模型的工具学习能力
从实验数据看,4B 模型的 StateLM 相比基线提升最大,但绝对性能仍不如 8B 和 14B。这说明"学会用工具"这件事对小模型仍有挑战。
3. 训练数据的质量依赖
SFT 阶段依赖 Claude Opus 4.1 生成的专家轨迹。如果教师模型在某些场景下的上下文管理策略不够优雅,学生模型也会继承这些问题。
工程落地的思考
如果要在实际项目中落地 StateLM,我会关注以下几点:
-
检索升级:把 BM25 换成向量检索 + 关键词检索的混合方案,解决语义匹配问题。
-
笔记格式标准化:外部笔记本的格式可以更结构化,比如使用 JSON Schema,方便后续检索和更新。
-
预算动态调整:当前的
checkBudget是静态的,可以根据任务复杂度动态调整上下文预算。 -
多模态扩展:论文只处理文本。如果扩展到多模态,"笔记"可以是图像摘要、表格提取等,deleteContext 也需要处理多模态消息。
🔗 相关工作对比
| 方法 | 上下文管理方式 | 特点 |
|---|---|---|
| 标准 LLM | 被动累积 | 简单直接,但窗口受限 |
| RAG | 外挂检索 | 外部知识库,模型被动查询 |
| ReadAgent | 提示词压缩 | 通过提示让 LLM 压缩记忆片段 |
| MemAgent | RL 增量处理 | 基于 RL 的增量式长文本处理 |
| StateLM | 主动管理 | 模型自主决策删、记、查 |
StateLM 和 RAG 的关键区别在于"主动性"。RAG 是外挂知识库,模型是被动的查询者;StateLM 是把记忆管理的决策权交给模型本身,让模型自己决定什么时候需要查、什么时候需要记、什么时候需要忘。
📚 总结
StateLM 的核心贡献不是发明新工具,而是改变范式——把模型从被动的"上下文填充者"变成主动的"上下文工程师"。
用一句话概括:上下文窗口不是越大越好,而是用得越聪明越好。
当业界还在疯狂卷上下文长度时,这篇论文提醒我们:也许该换个思路,教模型学会"断舍离"。
论文信息:
- 标题:The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
- arXiv:https://arxiv.org/abs/2602.12108
- 作者:Xiaoyuan Liu, Tian Liang, Dongyang Ma, Deyu Zhou, Haitao Mi, Pinjia He, Yan Wang

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)