InternAgent-1.5:让AI真正成为科学家——自主科学发现的统一智能体框架
InternAgent-1.5:自主科学发现的新范式 上海人工智能实验室提出的InternAgent-1.5框架突破了传统AI智能体的局限,构建了一个"生成-验证-进化"的闭环系统,使AI能够像人类科学家一样进行长周期的自主研究。该框架包含三个核心子系统:生成子系统负责深度文献分析和假设构建;验证子系统实现实验设计与优化;进化子系统通过长视界记忆实现知识积累和经验迁移。在GPQ
InternAgent-1.5:让AI真正成为科学家——自主科学发现的统一智能体框架
一句话总结:InternAgent-1.5构建了一个"生成-验证-进化"的闭环架构,让AI智能体能够在算法发现和实验科学两个领域实现长周期的自主研究,在多个科学推理基准上取得领先表现。
🎯 为什么我们需要这个?
2025年,AI Agent爆发式增长,但大多数智能体还停留在"一次性任务"层面——问个问题、查个资料、写段代码就结束了。真正的科学研究可不是这样。
科学家做研究是什么样的?
- 假设生成:读文献、找gap、提出新想法
- 实验验证:设计实验、跑代码、分析数据
- 迭代改进:根据结果调整假设、优化方法
- 知识积累:把学到的东西记下来,指导下一次研究
这个过程可能持续几周、几个月甚至几年。现有智能体最大的问题是:缺乏长周期的记忆和自我进化能力。它们就像金鱼,每次对话都从零开始,无法积累经验。
上海人工智能实验室提出的InternAgent-1.5就是要解决这个问题——构建一个能够持续学习、自我进化的科学发现智能体。
🏗️ 核心架构:三位一体的发现引擎
InternAgent-1.5的架构设计非常漂亮,它把科学发现抽象为三个紧密协作的子系统:
┌─────────────────────────────────────────────────────────────┐
│ InternAgent-1.5 架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 生成子系统 │ → │ 验证子系统 │ → │ 进化子系统 │ │
│ │ Generation │ │ Verification │ │ Evolution │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 深度研究 │ │ 方案优化 │ │ 长视界记忆 │ │
│ │ Deep Research │ │ Solution │ │ Long-Horizon │ │
│ │ │ │ Refinement │ │ Memory │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │ │ │ │
│ └───────────────────┴───────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ 科学发现产出 │ │
│ │ (算法+实证发现) │ │
│ └──────────────────┘ │
└─────────────────────────────────────────────────────────────┘
图1:InternAgent-1.5的整体架构,展示了生成、验证、进化三个子系统的协作关系
🔍 生成子系统:深度研究构建假设
这个子系统的任务就像博士生读文献找课题——但速度要快100倍。
核心能力:
- 自动文献分析:阅读论文、提取关键信息、识别研究空白
- 跨领域知识综合:把不同领域的发现拼接成新想法
- 结构化假设生成:产出可验证的研究假设
举个例子,假设要研究"气候变化对海洋环流的影响",生成子系统会:
- 检索相关论文(大西洋经向翻转环流AMOC、气候模型、海洋动力学…)
- 识别关键争议点(AMOC什么时候崩溃?概率多大?)
- 提出可验证的假设(“基于CMIP6模型,AMOC在2050年前崩溃的概率是XX%”)
这就像是有一个读过万篇文献的博士生,能在几小时内完成文献综述并提出研究方案。
✅ 验证子系统:解决方案优化与实验执行
假设有了,接下来要验证。这个子系统负责把假设变成可执行的实验。
核心能力:
- 实验设计:将假设转化为可操作的实验协议
- 代码生成与调试:自动编写、调试、执行实验代码
- 智能错误纠正:基于异常情况自动调整策略
这个子系统的关键创新是MLEvolve——一个专门用于算法优化的组件。它在MLEBench上排名第一,能够自主优化机器学习算法。
想象一下,你告诉它"帮我优化一个强化学习算法",它会:
- 搜索SOTA方法(GRPO、PPO、TRPO…)
- 编写代码并测试
- 发现bug自动修复
- 根据结果迭代改进
这就像是有一个能24小时不睡觉的博士后,不断实验、不断优化。
🔄 进化子系统:长周期记忆驱动持续改进
这是InternAgent最独特的部分——它真的能"记住"学到的东西。
核心能力:
- 持久化记忆:跨实验周期积累知识
- 证据驱动优化:根据实验结果改进假设和方法
- 跨任务迁移:把一个领域的经验用到另一个领域
传统智能体的问题是"健忘"——每次对话都像第一次见面。InternAgent通过长视界记忆解决了这个问题。
打个比方:传统智能体像实习生,每天早上都要重新介绍自己;InternAgent像资深研究员,记得三年前的实验失败,知道哪些坑不能踩。
🧠 三大基础能力
架构搭建好了,还需要具体的技术支撑。InternAgent-1.5的核心能力来自三个模块:
深度研究(Deep Research)
这不是简单的"搜索+总结",而是真正的研究级分析:
输入:研究问题
↓
多源信息整合
├── 论文数据库(arXiv、PubMed、ACL...)
├── 代码仓库(GitHub、PapersWithCode...)
├── 领域数据库(化学数据库、基因库...)
↓
知识图谱构建
├── 实体识别与关联
├── 因果关系推断
├── 争议点识别
↓
结构化假设输出
这套流程让它能够处理真正复杂的科学问题,而不是简单地"找答案"。
解决方案优化(Solution Refinement)
有了假设,怎么验证?这是MLEvolve的核心工作:
# MLEvolve的工作流程(伪代码)
def evolve_solution(task, initial_solution):
best_solution = initial_solution
for round in range(10): # 最多迭代10轮
# 1. 执行当前方案
result = execute(best_solution)
# 2. 分析结果,找出问题
analysis = analyze_result(result)
# 3. 基于分析改进方案
improved = improve(best_solution, analysis)
# 4. 验证改进是否有效
if evaluate(improved) > evaluate(best_solution):
best_solution = improved
return best_solution
这种迭代优化的思想,让AI能够像人类科学家一样"试错-改进"。
长视界记忆(Long-Horizon Memory)
这是InternAgent区别于其他智能体的关键:
| 传统智能体 | InternAgent-1.5 |
|---|---|
| 每次对话独立 | 跨对话知识积累 |
| 无法学习经验 | 实验结果驱动改进 |
| 无上下文延续 | 长周期上下文保持 |
具体实现上,InternAgent维护了一个结构化的记忆库:
- 实验记录(做了什么、结果如何)
- 方法库(哪些方法有效、哪些无效)
- 知识图谱(领域知识、因果关系)
这让智能体能够像真正的科学家一样"越做越好"。
🧪 实验表现:基准测试与真实发现
论文从两个层面验证了InternAgent-1.5的能力:基准测试和真实发现任务。
科学推理基准
在GAIA、HLE、GPQA和FrontierScience四个基准上,InternAgent-1.5都取得了领先成绩:
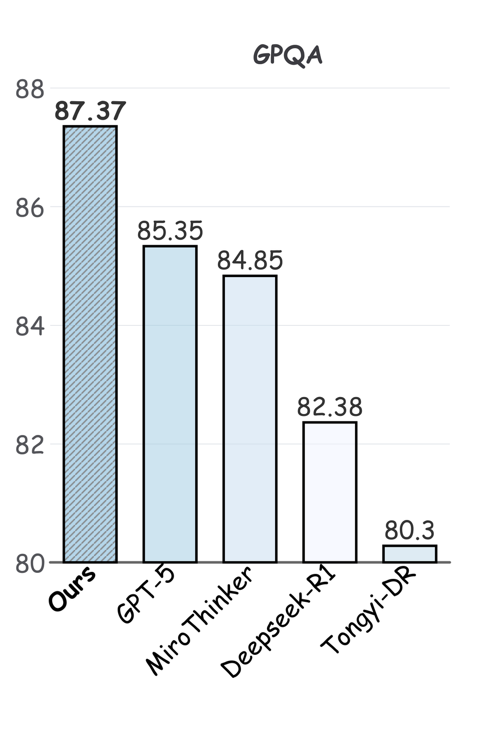
图2:GPQA-Diamond基准测试结果,InternAgent-1.5在生物、化学、物理三个领域平均达到87.37%
| 基准 | InternAgent-1.5 | 对比最佳方法 |
|---|---|---|
| GPQA-Diamond | 87.37% | DeepSeek-R1: 85.35% |
| GAIA (文本) | 领先 | 超越DeepSeek-R1、Gemini-3 |
| HLE | 领先 | 多领域领先 |
| FrontierScience | 显著领先 | 化学、物理领域突出 |
这些基准测试的是"科学推理能力"——理解问题、调用工具、综合分析的能力。InternAgent-1.5的表现说明它已经具备了处理复杂科学问题的能力。
真实发现任务
基准测试只是起点,论文更让人兴奋的是真实科学发现:
算法发现:为ML问题设计新方法
InternAgent-1.5能够自主设计机器学习算法,包括:
- LLM推理的测试时缩放(Test-Time Scaling)
- 智能体的长期记忆管理
- 测试时强化学习
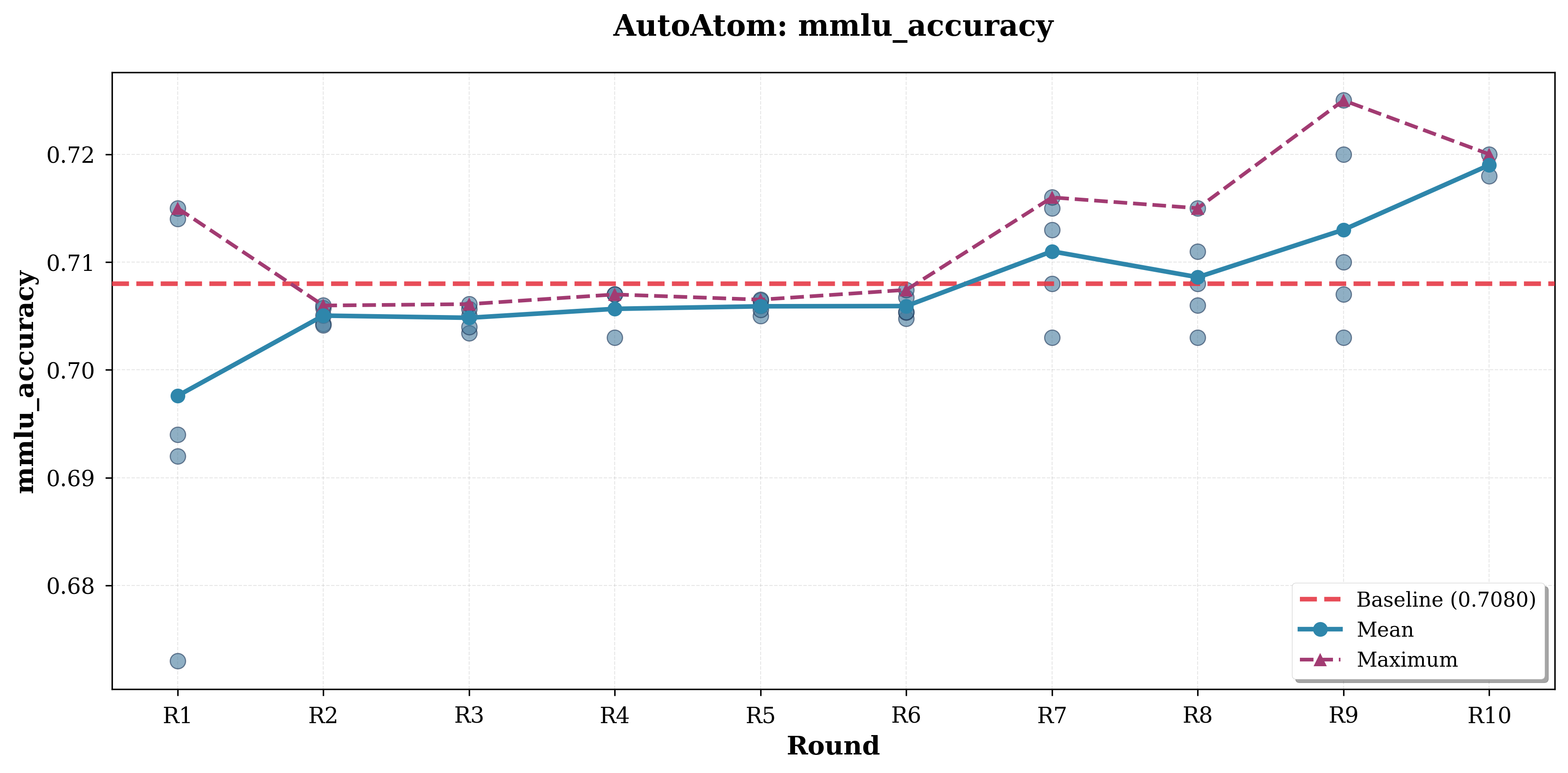
图3:MLEvolve在AutoAtom任务上的优化曲线,经过多轮迭代,MMLU准确率从基线的70.8%持续提升
这就像是有一个AI研究员,能够自主发明新的机器学习方法。
实证发现:真实的科学研究
更令人惊叹的是,InternAgent-1.5能够执行完整的计算或湿实验:
气候科学:
- 自动化气候诊断
- AMOC(大西洋经向翻转环流)崩溃风险分析
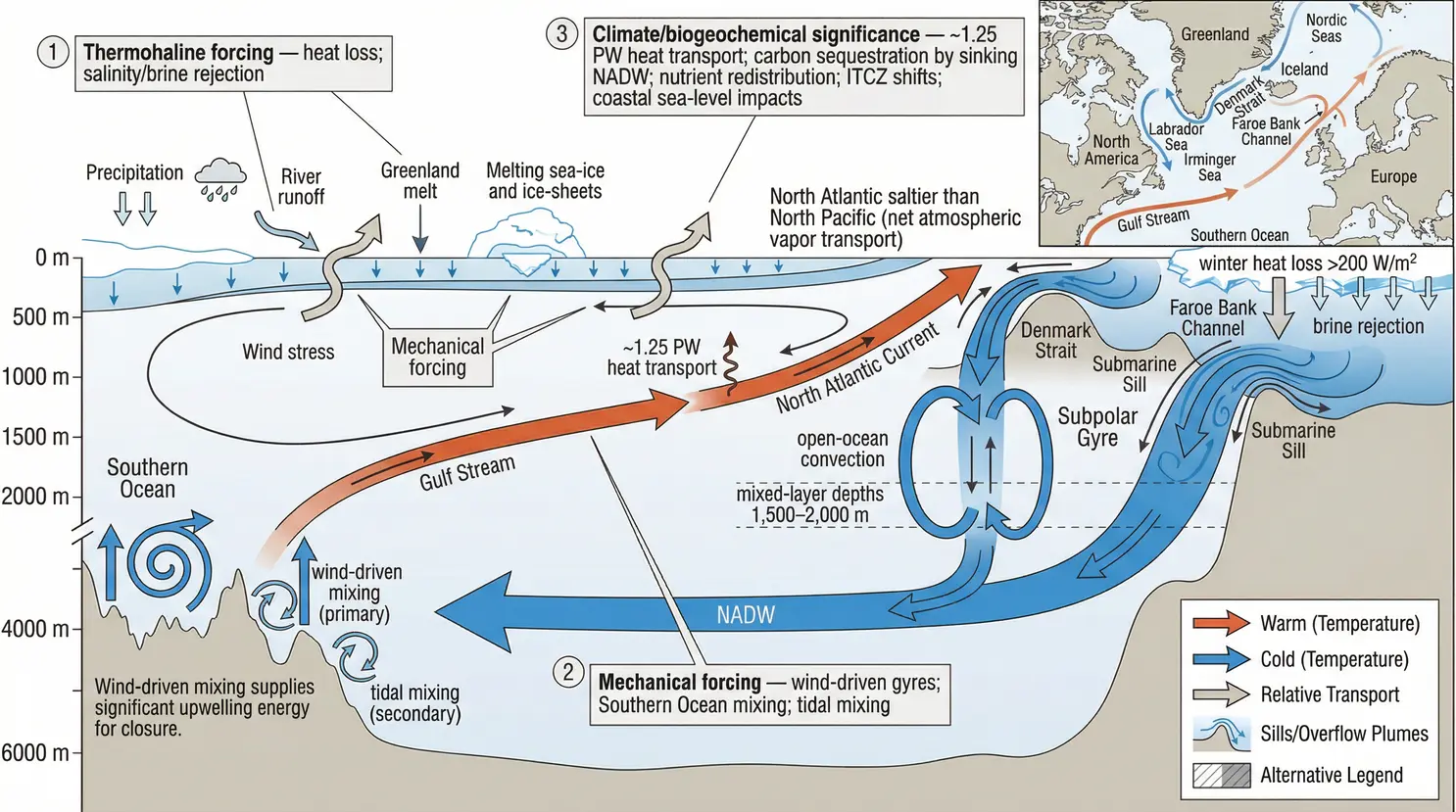
图4:北欧海域的气候/生物地球化学意义分析图,展示了热盐环流的复杂动力学
生命科学:
- 生物证据合成与靶点发现
- 精氨酸代谢与癌症免疫的关系研究
图5:Arg2介导的精氨酸代谢通路图,展示了其在肿瘤微环境中的作用机制
蛋白质工程:
- 荧光蛋白工程优化
- 设计更稳定、更亮的荧光蛋白变体
图6:荧光蛋白工程的设计空间,展示了稳定性、溶解度与功能性的权衡
这些不是简单的"信息检索",而是完整的科学发现流程——从假设到实验到结论。
🔬 关键创新点
InternAgent-1.5的成功来自几个关键设计决策:
1. 统一框架覆盖"干湿实验"
传统科学智能体要么只做计算(干实验),要么只做实验(湿实验),InternAgent-1.5把两者统一到一个框架里。
这就像是有一个既能写代码跑模拟,又能设计实验操作仪器的研究员——而且两个技能可以相互促进。
2. 结构化的记忆架构
记忆不是简单的"存起来",而是结构化的知识组织:
记忆结构
├── 实验记录
│ ├── 实验ID、时间戳
│ ├── 输入参数、输出结果
│ └── 成功/失败原因分析
├── 方法库
│ ├── 有效方法(带条件)
│ ├── 失败方法(带原因)
│ └── 适用场景标注
└── 知识图谱
├── 实体节点(基因、蛋白、化合物...)
├── 关系边(调控、结合、抑制...)
└── 证据强度(强/中/弱)
这种结构让"经验"真正可查询、可复用、可迁移。
3. 迭代优化而非一次性生成
大多数智能体采用"一次生成"模式——给出问题,生成答案,结束。InternAgent-1.5采用迭代优化模式:
初始方案 → 执行 → 分析 → 改进 → 执行 → ... → 最终方案
这种模式更接近人类科学家的工作方式——很少有一次性成功的研究。
📊 方法对比
InternAgent-1.5与其他科学智能体的对比:
| 能力维度 | 传统智能体 | CoScientist | InternAgent-1.5 |
|---|---|---|---|
| 长周期记忆 | ❌ | ❌ | ✅ 结构化记忆 |
| 干湿实验统一 | ❌ | 部分 | ✅ 完整支持 |
| 自我进化 | ❌ | ❌ | ✅ 迭代优化 |
| 真实发现产出 | 文献调研 | 模拟实验 | 完整科学发现 |
| 开源程度 | 部分开源 | 未开源 | 核心组件开源 |
InternAgent的核心优势在于:它不是"回答科学问题"的工具,而是"做科学研究"的伙伴。
💡 我的观点和启发
读完这篇论文,我有几点深刻的感受:
这才是AI Agent应该有的样子
现在的AI Agent市场,太多"玩具级"产品了——能订餐厅、能写邮件、能查资料。但真正的生产力提升需要的是能解决复杂问题的智能体。
InternAgent-1.5展示了AI Agent的真正潜力:不是替代人类的某个动作,而是扩展人类的能力边界。一个研究员一辈子能做多少实验?InternAgent可以并行做十倍百倍的实验。
长周期记忆是智能体的圣杯
这篇论文最大的贡献,可能不是"做科学发现",而是证明了长周期记忆的可行性。
传统智能体最大的痛点是"健忘"——每次对话都像第一次见面。InternAgent通过结构化记忆架构解决了这个问题。这套方案不仅适用于科学发现,也可以迁移到其他需要长期任务的场景。
工程落地的挑战
虽然论文展示了令人印象深刻的结果,但工程落地还有几个挑战:
- 成本问题:长周期研究意味着大量API调用,成本可能很高
- 可靠性:科学研究容错率低,AI的"幻觉"问题需要更严格的控制
- 领域适配:不同学科的方法论差异很大,通用框架需要更细的领域知识注入
不过,论文已经开源了MLEvolve组件,相信社区会推动这些问题的解决。
对研究者的启示
如果你是AI研究者:
- 长周期任务是一个值得深挖的方向,传统RL的reward signal设计可能需要重新思考
- 结构化记忆比简单的RAG更有潜力,值得探索更好的记忆组织形式
如果你是应用研究者:
- 可以尝试用InternAgent框架解决自己领域的问题
- 开源的MLEvolve可以直接用于算法优化任务
⚠️ 局限性与未来方向
论文也坦诚地讨论了几个局限性:
- 领域覆盖:虽然覆盖了多个学科,但每个领域的深度还有提升空间
- 可解释性:AI的发现过程有时像"黑盒",科学家难以完全信任
- 实验验证:计算发现需要实验验证,完全自主还有距离
未来的方向可能包括:
- 更强的领域专家知识注入
- 人机协作的工作流设计
- 发现结果的可解释性增强
🔗 资源链接
- 论文:https://arxiv.org/abs/2602.08990
- 代码仓库:https://github.com/Alpha-Innovator/InternAgent
- MLEvolve组件:已在GitHub开源,可直接用于算法优化任务
- 实验平台:https://discovery.intern-ai.org.cn/(实证发现任务)
总结
InternAgent-1.5向我们展示了AI Agent的真正潜力——不是简单的任务自动化,而是成为科学研究的参与者。
通过"生成-验证-进化"的闭环架构,它实现了:
- ✅ 长周期的自主研究能力
- ✅ 结构化的知识积累
- ✅ 干湿实验的统一框架
- ✅ 真实的科学发现产出
这让我想起一句话:AI不应该只是"更快地做人类能做的事",而应该是"做人类做不到的事"。InternAgent-1.5正在向这个方向迈进。
对于AI研究者来说,这篇论文提供了一套完整的智能体架构设计范式;对于应用研究者来说,这是一个可以真正拿来用的科学发现工具。
科学发现的下一个突破,可能就来自AI与人类的协作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)