GISA:当最好的AI搜索助手也只有19%准确率
研究人员构建了GISA基准测试,通过结构化答案格式评估AI搜索助手的真实能力。测试发现,即使最先进的Claude 4.5 Sonnet模型准确率仅19.3%,远低于人类专家的78%。GISA揭示了AI在复杂信息搜寻任务中的主要瓶颈:搜索层级错误占比近50%,表现为浅层浏览习惯和深度信息挖掘能力的不足。该研究强调当前AI在整合深度推理与广度聚合、网页导航策略以及信息验证等方面仍存在显著差距,为改进搜
GISA:当最好的AI搜索助手也只有19%准确率
一句话总结:人工构建真实搜索任务,用结构化答案实现确定性评估,发现SOTA模型在复杂信息搜寻上远未达到人类水平。
📖 问题的根源:现有基准都"反了"
想象一下,你要测试一个学生的数学能力。你会怎么做?
正常做法:先出题,再让学生解答。
但现有的搜索代理基准测试(如BrowseComp)的构建方式是:先有答案,再反推问题。
比如,先确定答案是"2024年诺贝尔物理学奖得主",然后反推问题"谁获得了2024年诺贝尔物理学奖?"这听起来没问题,但会导致几个严重问题:
- 问题不自然:反推的问题往往比真实需求更"直白",缺少信息搜寻的真实复杂性
- 覆盖片面:要么只测试"深度推理"(定位一个关键信息),要么只测试"广度聚合"(收集多个信息),缺少两者结合的场景
- 数据污染:静态的答案集容易被模型"记住",测试结果不反映真实能力
这就是GISA要解决的核心问题。
🔍 GISA的设计:从真实需求出发
构建流程:四步走
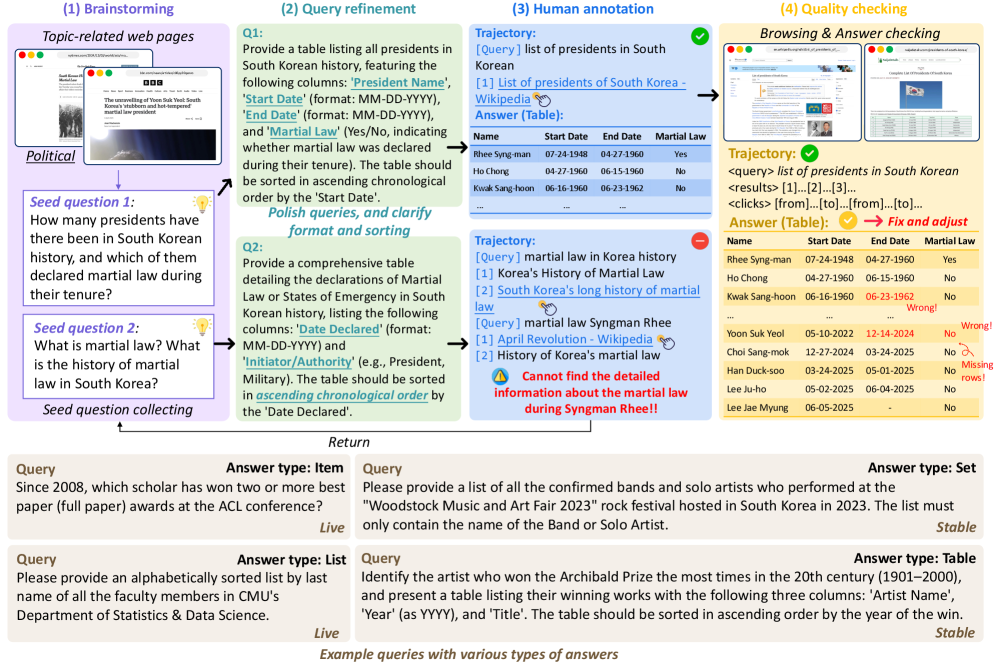
图1:GISA的四阶段构建流程——从头脑风暴到质量检查,每个查询都经过人工精心设计和验证。
第一步:头脑风暴
基于BrowseComp的分类法,涵盖10个领域:科技、艺术、历史、政治、体育、商业、地理、医学、法律、娱乐。标注人员通过实际浏览网页来激发真实问题。
第二步:查询细化
将原始问题转化为正式查询,同时确定答案格式。关键要求:任务必须需要结合"深度推理"和"广度信息聚合"。
例如:
- “列出所有获得诺贝尔物理学奖的女性科学家及其获奖年份”——需要广度聚合
- “2024年苹果公司最新发布的Vision Pro在哪些国家可以购买?”——需要深度推理
第三步:人工标注
使用定制的浏览器扩展记录专家的完整搜索轨迹:Google搜索查询、点击链接、时间戳。重要细节:忽略搜索结果中的AI摘要,确保记录的是纯人类搜索行为。
第四步:质量检查
验证三件事:
- 轨迹日志的一致性(搜索过程是否合理)
- 答案的准确性(最终答案是否正确)
- 格式合规性(是否符合预定格式)
还有一个"记忆检查":使用DeepSeek-V3.2测试,排除那些仅靠模型内部知识就能回答的题目。这确保了任务确实需要上网搜索。
四种结构化答案格式
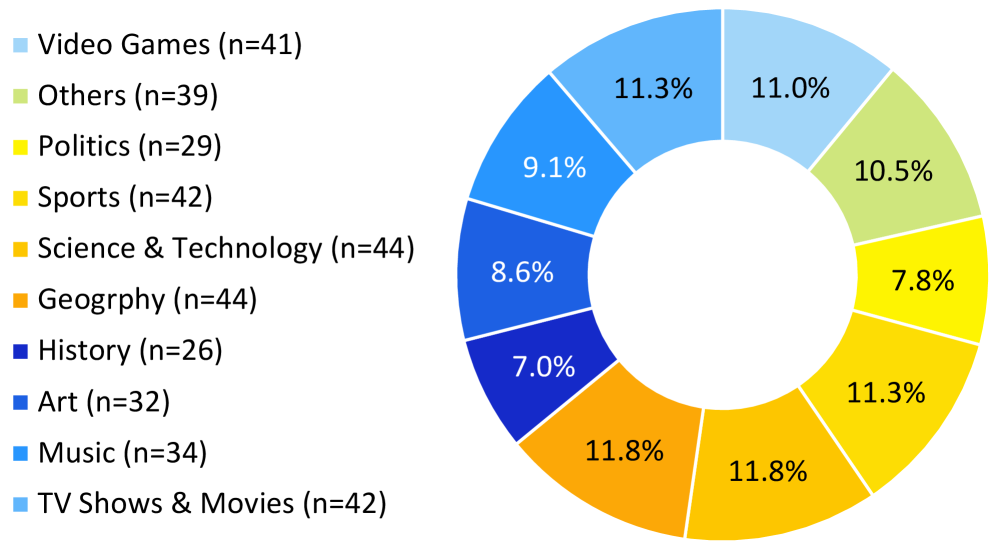
图2:GISA的四种结构化答案格式示例。Item是单值,Set是无序集合,List是有序列表,Table是结构化表格。
| 格式 | 描述 | 示例查询 |
|---|---|---|
| Item | 单个事实或值 | “2024年世界杯决赛的举办地是哪里?” |
| Set | 无序项目集合 | “列出所有欧盟成员国中人口超过5000万的国家” |
| List | 有序项目列表 | “按票房排序,2024年全球票房前10的电影” |
| Table | 结构化表格 | “制作一个表格,包含2024年G20国家的GDP、人口和首都” |
这种设计的巧妙之处:实现确定性评估。
传统方法用LLM作为裁判打分,存在主观性和不一致性。结构化答案可以直接用规则计算准确率:
- Set:用F1分数评估内容重叠
- List:用F1评估内容 + Sequence Matcher评估顺序
- Table:用行级F1和单元格级F1
实时子集:对抗"死记硬背"
图3:GISA查询在不同主题领域的分布。覆盖科技、历史、政治等10个领域,确保任务多样性。
GISA将查询分为两类:
| 类型 | 比例 | 特点 |
|---|---|---|
| 稳定子集 | 75% | 答案不会变化(如历史事件) |
| 实时子集 | 25% | 答案定期更新(如最新股价、赛事结果) |
实时子集的设计是对抗数据污染的关键。即使模型在训练数据中"见过"这些问题,答案也已经变了。论文每个季度会更新实时子集的答案。
📊 核心发现:AI搜索助手离人类还很远
整体表现:19.30%的"天花板"
论文评估了10个主流LLM和4个商业搜索产品。结果令人震惊:
| 模型 | 精确匹配 (EM) | 相对人类 |
|---|---|---|
| Claude 4.5 Sonnet (thinking) | 19.30% | ~25% |
| GPT-5.2 | 16.08% | ~21% |
| Qwen3-235B-A22B | 15.28% | ~20% |
| DeepSeek-V3.2 (thinking) | 14.47% | ~19% |
| Gemini 3 Pro | 12.57% | ~16% |
| 人类专家 | ~78% | 100% |
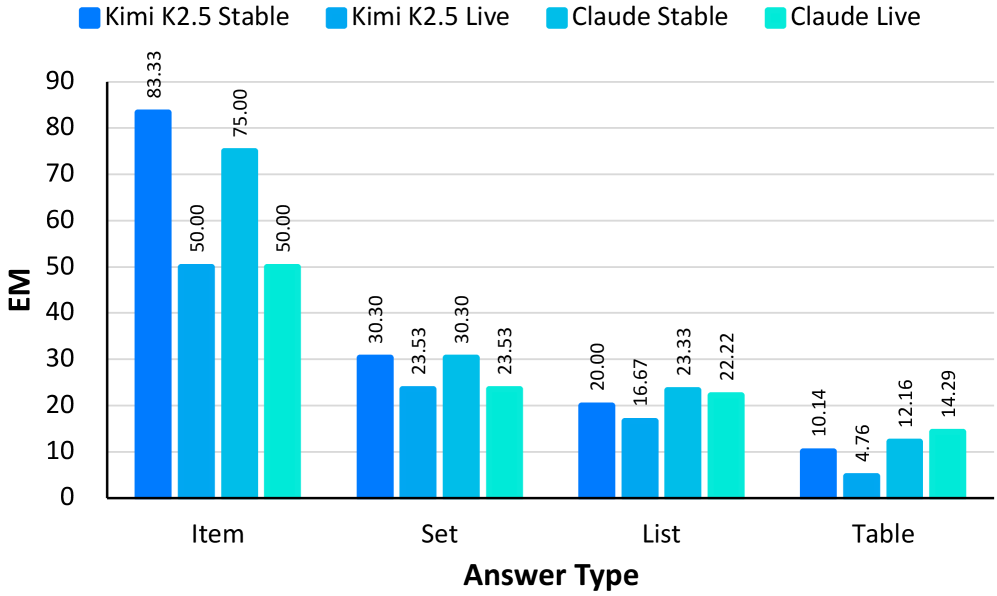
图4:主流模型在GISA上的性能表现。即使是最好的Claude 4.5 Sonnet,也只达到了人类专家约四分之一的水平。
这个差距太大了。即使是表现最好的模型,其准确率也只有人类专家的约四分之一。这说明信息搜寻代理的能力还处于早期阶段。
任务复杂度的影响
不同答案格式的难度差异显著:
| 格式 | Claude 4.5 Sonnet | GPT-5.2 | 难度原因 |
|---|---|---|---|
| Item | 32.0% | 28.0% | 单值相对简单 |
| Set | 18.0% | 14.0% | 需要收集多个正确项 |
| List | 12.0% | 10.0% | 还要保证顺序正确 |
| Table | 8.0% | 6.0% | 需要构建完整结构 |
Table类型任务的准确率只有Item的四分之一。这反映了信息聚合任务的累积难度:一个表格有10行数据,任何一行出错都会影响整体得分。
"思维模式"有帮助但不神奇
开启thinking/reasoning模式能带来提升:
| 模型 | 无thinking | 有thinking | 提升 |
|---|---|---|---|
| DeepSeek-V3.2 | 11.53% | 14.47% | +2.94% |
| Claude 4.5 Sonnet | ~16% | 19.30% | ~3% |
但代价是Token消耗增加2-3倍。而且thinking不是万能药:模型仍然会在搜索层级犯错。
商业产品并不更强
论文还测试了4个商业深度研究产品:
- OpenAI o4 Mini Deep Research
- Perplexity Pro
- Google Gemini Deep Research
- Kimi 研究版
结果:它们并没有显著优于基于LLM的ReAct代理。而且商业产品更容易犯"格式遵循错误"——比如表格列名写错、列表编号格式不对。
这说明商业产品的优势可能在于用户体验(更好的UI、更快的响应),而非底层智能。
🧠 人类 vs 模型:搜索行为差异
行为模式对比
论文提供了完整的人类搜索轨迹,这是非常宝贵的数据。对比发现:
| 指标 | 人类 | 模型 |
|---|---|---|
| 平均搜索查询次数 | 3.53 | 7.57 |
| 平均浏览页面数 | 19.03 | 4.63 |
| 单次查询浏览页面数 | 5.39 | 0.61 |
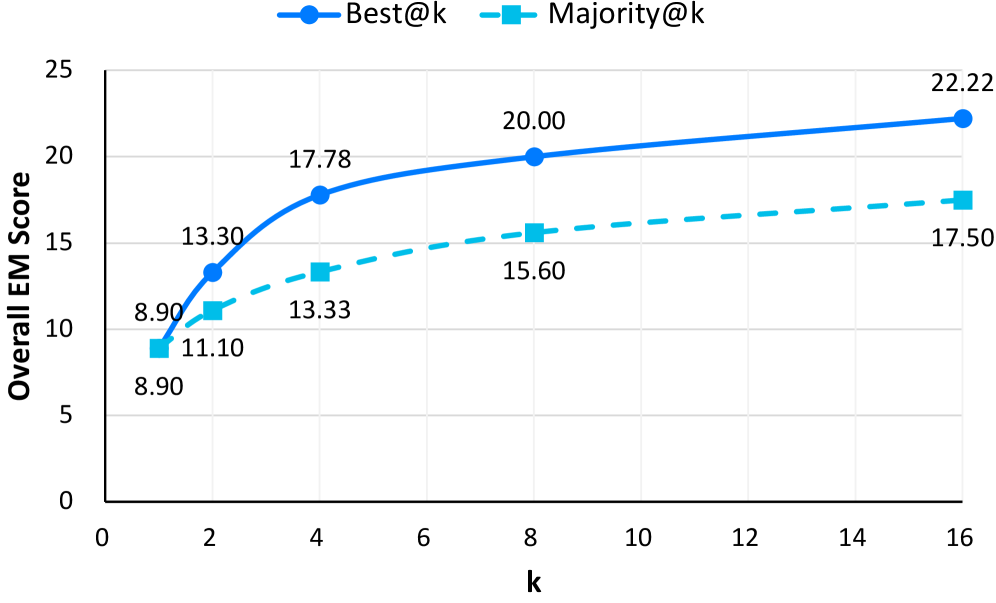
图5:人类(蓝色)vs 模型(橙色)的搜索行为对比。人类倾向于少查询、多浏览;模型倾向于多查询、少浏览。
这个差异揭示了关键问题:
人类策略:精准查询 → 深入浏览
- 查询次数少,但每次查询后会浏览多个页面
- 会利用页面内的超链接进行深度探索
- 一个网站内可能挖掘多个相关信息
模型策略:频繁查询 → 浅层浏览
- 查询次数多,但每次只看1-2个页面
- 很少利用超链接深入探索
- 倾向于"浅尝辄止"
用考试来类比:
- 人类像是在图书馆查资料:找到一本书后仔细翻阅
- 模型像是在Google搜索:不断换关键词,但每个结果只看摘要
错误类型分析
论文将错误分为三个层级:
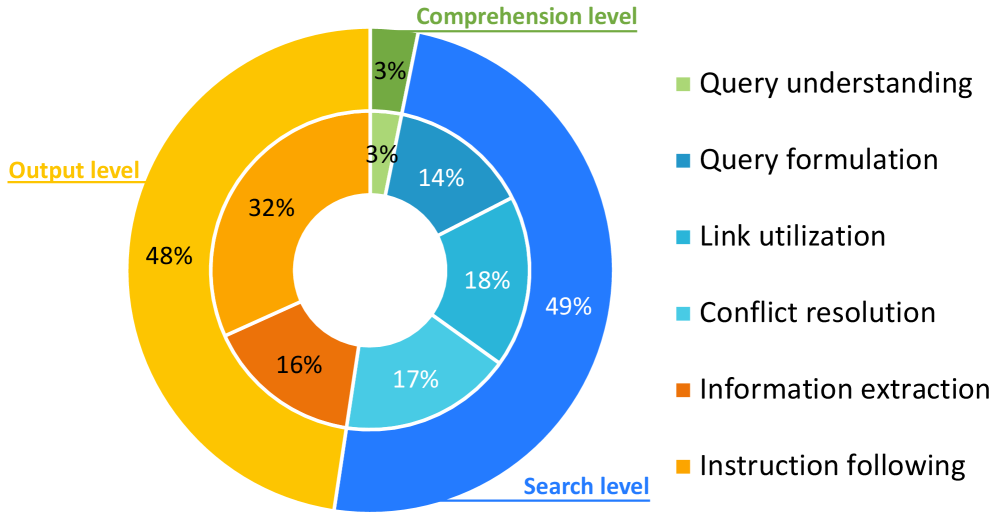
图6:不同错误类型的占比。搜索层级错误(蓝色)占近一半,是主要瓶颈。
搜索层级错误(49.2%)——最大瓶颈
典型表现:
- 无法有效利用页面超链接进行深度探索
- 在需要翻页的场景下过早停止
- 找到了相关页面但没有挖掘到底层信息
这印证了行为分析:模型的"浅层浏览"习惯导致关键信息遗漏。
理解层级错误(19.1%)
典型表现:
- 误解问题意图
- 无法正确关联多源信息
- 对复杂条件的推理出错
输出层级错误(31.7%)
典型表现:
- 格式遵循错误(如表格列名不对)
- 遗漏必要字段
- 排序或分组错误
这反映了指令遵循的弱点:即使找到了正确信息,也可能在输出时"功亏一篑"。
💡 我的观点和启发
为什么GISA这么难?
读完论文,我认为GISA的难度来自三个层面:
层面1:信息整合的复杂性
很多任务需要同时进行"深度推理"和"广度聚合"。比如:
“制作一个表格,列出2024年NBA季后赛东西部决赛的球队、核心球员(场均得分前3)及其主要数据”
这需要:
- 找出东西部决赛球队(广度)
- 查每支球队的核心球员(深度)
- 获取球员数据(深度)
- 整合到表格中(整合)
每一步都可能出错,任何遗漏都会影响最终结果。
层面2:网页导航的非线性
真实网页不是扁平的信息列表,而是有层级结构的网络:
- 首页 → 列表页 → 详情页 → 子页面
- 导航栏、侧边栏、相关链接
- 分页、标签筛选、搜索框
模型需要学会"网页导航"的策略,而不只是"搜索-提取"。
层面3:信息验证的需求
网上的信息不一定准确。比如:
- 某个数据可能需要交叉验证
- 时间敏感信息需要确认时效性
- 来源权威性需要判断
模型往往直接采信第一个找到的答案,缺少验证意识。
GISA的价值:诊断而非排名
GISA最独特的价值是提供了完整的人类搜索轨迹。这不只是用来打分,更是用来诊断:
- 对比人类和模型的策略差异:发现模型的"浅层浏览"问题
- 定位错误发生的位置:搜索层、理解层还是输出层?
- 为改进提供方向:是加强深度探索能力,还是改善格式遵循?
这让我想到医学诊断:GISA不只告诉你"分数是多少",还告诉你"问题出在哪"。
对产品开发的启示
基于论文发现,我认为搜索代理产品需要重点改进几个方面:
改进1:鼓励深度浏览
当前模型倾向于"多查少看"。是否可以:
- 设置"页面停留时间"奖励
- 鼓励模型在找到相关页面后深入挖掘
- 实现"页面内搜索"能力
改进2:改进网页导航能力
教模型理解网页结构:
- 识别导航栏、面包屑、相关链接
- 判断何时应该"深入"、何时应该"返回"
- 支持多窗口/多标签的上下文管理
改进3:强化格式遵循训练
输出层错误占31.7%,这部分应该最容易改进:
- 针对结构化输出做专项训练
- 提供格式模板和检查机制
- 实现输出验证和自动修正
改进4:引入信息验证机制
不只是找答案,还要验证答案:
- 交叉检查多个来源
- 标注信息时效性
- 识别冲突信息并提示
局限性和未来方向
论文也坦诚指出了几个局限:
- 规模有限:373个查询可能不够全面,特别是某些领域覆盖不足
- 单一搜索引擎:目前只用Google,没有测试其他搜索引擎
- 英文为主:主要针对英文查询,多语言支持有待扩展
我认为几个值得探索的方向:
方向1:多模态信息搜寻
很多信息不在纯文本中,而是在图表、视频、PDF中。GISA目前没有覆盖这些场景。
方向2:交互式信息搜寻
真实用户可能会调整需求、追问细节。GISA目前是单轮任务,没有测试多轮交互能力。
方向3:协作式信息搜寻
复杂任务可能需要多个Agent协作:一个负责搜索,一个负责验证,一个负责整合。
🔧 实践指南:如何评估和改进搜索代理
基于GISA的设计,以下是构建搜索代理评估体系的实践建议:
评估指标设计
# 不同答案类型的评估方法
def evaluate_item(prediction, ground_truth):
"""单值评估:精确匹配"""
return 1.0 if prediction == ground_truth else 0.0
def evaluate_set(prediction, ground_truth):
"""集合评估:F1分数"""
pred_set = set(prediction)
truth_set = set(ground_truth)
precision = len(pred_set & truth_set) / len(pred_set) if pred_set else 0
recall = len(pred_set & truth_set) / len(truth_set) if truth_set else 0
if precision + recall == 0:
return 0
return 2 * precision * recall / (precision + recall)
def evaluate_list(prediction, ground_truth):
"""列表评估:内容F1 + 顺序准确率"""
content_f1 = evaluate_set(prediction, ground_truth) # 内容准确性
# 顺序准确性(Sequence Matcher)
from difflib import SequenceMatcher
seq_score = SequenceMatcher(None, prediction, ground_truth).ratio()
return 0.7 * content_f1 + 0.3 * seq_score # 加权平均
def evaluate_table(prediction, ground_truth):
"""表格评估:行级F1 + 单元格级F1"""
# 行级:整行匹配才算正确
row_f1 = evaluate_set(
[tuple(row.items()) for row in prediction],
[tuple(row.items()) for row in ground_truth]
)
# 单元格级:每个单元格单独评估
cell_correct = 0
cell_total = 0
for pred_row, truth_row in zip(prediction, ground_truth):
for key in truth_row:
cell_total += 1
if key in pred_row and pred_row[key] == truth_row[key]:
cell_correct += 1
cell_f1 = cell_correct / cell_total if cell_total else 0
return 0.5 * row_f1 + 0.5 * cell_f1
搜索轨迹分析
GISA的关键创新是记录完整搜索轨迹。在开发搜索代理时,应该:
- 记录每个搜索动作:查询词、点击链接、页面停留时间
- 分析轨迹效率:是否过度查询?是否遗漏关键页面?
- 对比人类行为:找到模型的系统性弱点
防止数据污染
设计评估基准时:
- 避免使用训练数据中的静态答案
- 包含时间敏感的动态问题
- 定期更新答案集
📊 详细数据:各模型在不同子集上的表现
稳定子集 vs 实时子集

图7:Kimi K2.5和Claude 4.5 Sonnet在稳定子集和实时子集上的表现对比。实时子集的性能普遍更低,说明模型对动态信息的处理能力较弱。
| 模型 | 稳定子集 | 实时子集 | 差距 |
|---|---|---|---|
| Claude 4.5 Sonnet | 21.2% | 14.8% | -6.4% |
| Kimi K2.5 | 15.3% | 10.1% | -5.2% |
实时子集的性能明显更低,这印证了数据污染的影响:模型可能在训练数据中见过稳定子集的问题,而实时子集的问题则无法靠"记忆"回答。
推理时缩放
论文还测试了"推理时缩放"(Inference-time Scaling)的效果:让模型多次尝试,取最佳结果。
| 尝试次数 | Qwen3-Max EM |
|---|---|
| 1次 | 13.5% |
| 3次 | 15.2% |
| 5次 | 16.8% |
增加尝试次数能带来提升,但边际收益递减。这说明单次搜索质量才是关键,多次尝试只是"用数量换质量"。
📝 总结
GISA这篇论文揭示了一个重要事实:即使是最先进的AI搜索助手,在复杂信息搜寻任务上的准确率也只有19%,远低于人类专家的78%。
这不是因为模型不够聪明,而是信息搜寻任务本身的复杂性:
- 需要同时进行深度推理和广度聚合
- 需要在非线性网页结构中导航
- 需要验证信息的准确性和时效性
GISA的三大创新为这个领域设立了新标准:
- 从真实需求出发:人工构建查询,而非反向生成
- 结构化答案:实现确定性评估,避免LLM裁判的主观性
- 完整搜索轨迹:提供诊断数据,而不只是最终分数
对于搜索代理开发者,这篇论文的启示是:
- 不要被宣传迷惑:商业产品并不比开源模型强多少
- 关注行为模式:模型的"浅层浏览"是主要瓶颈
- 重视格式遵循:输出层错误占比高,容易改进
- 防范数据污染:使用动态更新的答案集
信息搜寻是AI Agent的核心能力之一。GISA告诉我们,这条路还很长,但至少我们现在有了一个靠谱的"导航仪"。
🔗 参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)