意图识别模型的在线学习与持续优化
本文聚焦解决AI落地中的核心痛点:当意图识别模型上线后,如何应对用户新需求、新表述带来的"模型老化"问题。我们将覆盖在线学习的原理、关键技术、实战方法,以及持续优化的完整流程。从生活场景引出问题→解释核心概念→拆解技术原理→实战代码演示→真实应用场景→未来趋势展望,层层递进揭开在线学习的本质。意图识别:将用户文本/语音转换为预定义意图标签的任务(如"查询天气"“投诉物流”)在线学习(Online
意图识别模型的在线学习与持续优化:让AI越用越聪明的秘密
关键词:意图识别、在线学习、持续优化、概念漂移、实时训练
摘要:在智能客服、语音助手等AI应用中,意图识别模型就像"用户需求翻译官",但传统离线训练的模型常因用户行为变化"跟不上节奏"。本文将带你揭开"在线学习"的神秘面纱,从核心概念到实战代码,从应用场景到未来趋势,一步一步解析如何让意图识别模型像人类一样"边用边学",始终保持最佳状态。
背景介绍
目的和范围
本文聚焦解决AI落地中的核心痛点:当意图识别模型上线后,如何应对用户新需求、新表述带来的"模型老化"问题。我们将覆盖在线学习的原理、关键技术、实战方法,以及持续优化的完整流程。
预期读者
- 对NLP有基础了解的开发者(熟悉意图识别任务)
- 负责AI系统运维的算法工程师
- 对"AI持续进化"感兴趣的技术爱好者
文档结构概述
从生活场景引出问题→解释核心概念→拆解技术原理→实战代码演示→真实应用场景→未来趋势展望,层层递进揭开在线学习的本质。
术语表
核心术语定义
- 意图识别:将用户文本/语音转换为预定义意图标签的任务(如"查询天气"“投诉物流”)
- 在线学习(Online Learning):模型在处理实时数据时同步更新参数的训练方式
- 概念漂移(Concept Drift):用户需求分布随时间变化(如"苹果"从水果→手机品牌)
- 灾难性遗忘(Catastrophic Forgetting):模型学习新数据后丢失旧知识的现象
相关概念解释
- 离线学习(Batch Learning):传统"训练→上线→不再更新"的模式
- 小批量学习(Mini-batch Learning):介于离线与在线之间的折中方案(每次用少量新数据更新)
- 模型冷启动:新模型上线初期因数据不足导致的性能低下问题
核心概念与联系
故事引入:智能奶茶店的"点单助手"
小明开了家网红奶茶店,用AI点单助手识别用户意图(如"大杯冰奶茶加椰果"“退掉昨天的订单”)。初期模型用历史数据训练,准确率95%。但3个月后出现新情况:
- 年轻人流行说"来杯快乐水(指奶茶)"
- 新增"低糖版杨枝甘露"的点单需求
- 有用户抱怨"不要珍珠要脆波波"的新表述
离线模型无法识别这些新意图,导致点单错误率飙升到30%。这时,小明需要让模型"边接单边学习"——这就是意图识别的在线学习。
核心概念解释(像给小学生讲故事)
核心概念一:意图识别——用户需求的"翻译官"
想象你有一个外星朋友,他说的话你听不懂。意图识别模型就像"翻译官",把用户的话(如"明天北京下雨吗?“)翻译成机器能懂的标签(如"天气查询”)。这个翻译官需要认识所有可能的"外星语言"(用户表述方式)。
核心概念二:在线学习——边考试边学习的"学霸"
传统模型像"考前突击的学生":用历史数据(课本)集中训练,上线后(考试)不再学习。在线学习的模型像"边考试边翻书的学霸":每处理一个新请求(做一道题),就根据结果(对错)更新自己的知识(调整模型参数),越考越厉害。
核心概念三:持续优化——给模型做"定期体检"
即使模型能边学边用,也可能学错(比如把"快乐水"误学为"可乐")。持续优化就像"医生定期体检":监控模型准确率(量体温)、分析错误案例(查病因)、调整学习策略(开药方),确保模型"健康成长"。
核心概念之间的关系(用小学生能理解的比喻)
- 意图识别与在线学习:翻译官(意图识别)需要不断学习新词汇(新用户表述),在线学习就是"翻译官的速成班",让他边工作边学新单词。
- 在线学习与持续优化:边学边用可能学歪(比如把"快乐水"记成"汽水"),持续优化就像"翻译官的老师",定期检查他的翻译结果,纠正错误,调整学习方法。
- 意图识别与持续优化:翻译官的终极目标是准确翻译(高准确率),持续优化通过监控和调整,确保翻译官不会因为"学新忘旧"(灾难性遗忘)而犯错。
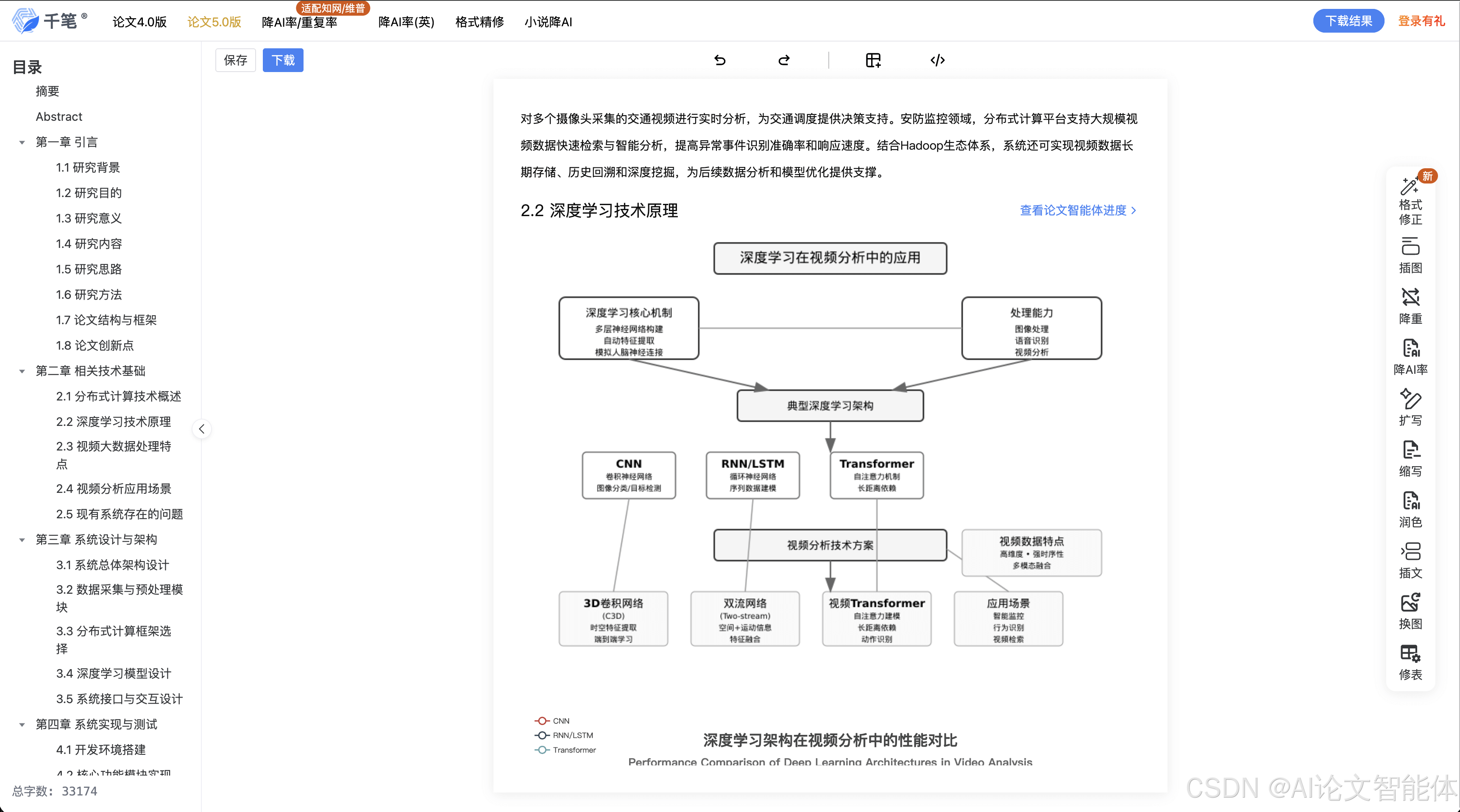
核心概念原理和架构的文本示意图
用户请求 → 意图识别模型(当前参数)→ 输出预测标签
│
└─(若标注反馈可用)→ 计算误差 → 在线学习模块 → 更新模型参数
│
└─(持续优化模块)→ 监控准确率 → 调整学习率/触发重训 → 模型优化
Mermaid 流程图
核心算法原理 & 具体操作步骤
在线学习的数学本质:从批量更新到逐样本更新
传统离线学习用批量数据计算平均梯度:
θt+1=θt−η⋅1N∑i=1N∇L(θt;xi,yi) θ_{t+1} = θ_t - η \cdot \frac{1}{N} \sum_{i=1}^N ∇L(θ_t; x_i, y_i) θt+1=θt−η⋅N1i=1∑N∇L(θt;xi,yi)
在线学习每次用1个样本更新参数(随机梯度下降SGD):
θt+1=θt−η⋅∇L(θt;xt+1,yt+1) θ_{t+1} = θ_t - η \cdot ∇L(θ_t; x_{t+1}, y_{t+1}) θt+1=θt−η⋅∇L(θt;xt+1,yt+1)
关键区别:离线学习像"用全班作业的平均错误改卷子",在线学习像"拿到一张卷子就改一张",更实时但可能波动大。
意图识别在线学习的3个关键步骤
- 数据实时接收:从业务系统获取用户请求(如客服对话)及标注结果(人工/规则标注)
- 模型快速更新:用新数据计算损失,反向传播更新模型参数(如BERT的最后几层)
- 学习率动态调整:初期用大学习率快速适应新数据,后期用小学习率保持稳定
Python代码示例(基于PyTorch的简单在线学习)
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertForSequenceClassification
# 初始化模型和分词器(假设已训练好基础意图识别模型)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=10 # 假设预定义10种意图
)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # 在线学习常用SGD
loss_fn = nn.CrossEntropyLoss()
def online_learn(text, true_label):
"""接收新文本和真实标签,执行在线学习"""
# 1. 数据预处理
inputs = tokenizer(text, return_tensors='pt', padding='max_length', truncation=True)
# 2. 前向传播
outputs = model(**inputs)
logits = outputs.logits
# 3. 计算损失
loss = loss_fn(logits, torch.tensor([true_label]))
# 4. 反向传播更新参数
loss.backward()
optimizer.step()
optimizer.zero_grad() # 清空梯度,准备下一次更新
return loss.item()
# 模拟在线学习过程:处理3个新样本
new_samples = [
("今天的快乐水要加椰果", 5), # 假设标签5代表"奶茶点单"
("退掉昨天的杨枝甘露订单", 3), # 标签3代表"订单取消"
("脆波波替换珍珠可以吗", 5)
]
for text, label in new_samples:
loss = online_learn(text, label)
print(f"处理样本:{text},损失:{loss:.4f}")
代码解读:
- 模型使用预训练BERT作为基础,只需要微调最后一层分类器(适合在线学习,减少计算量)
- 优化器选择SGD而非Adam,因为在线学习需要更"敏感"的参数更新(Adam的动量可能平滑掉新数据的影响)
- 每次处理一个样本就更新参数,真正实现"边用边学"
数学模型和公式 & 详细讲解 & 举例说明
学习率(η)的动态调整策略
在线学习的核心挑战是平衡"适应新数据"和"保留旧知识",学习率的设置至关重要。常用策略:
- 衰减学习率:η_t = η_0 / √t(随时间逐渐减小,初期学得多,后期学得少)
- 基于误差的自适应:误差大时增大η(急需学习),误差小时减小η(保持稳定)
- 温启动(Warmup):初期用很小的η避免"学歪",稳定后再增大
举例:
假设初始η=0.1,用衰减策略η_t=0.1/√t:
- 第1次更新:η=0.1(快速适应新数据)
- 第100次更新:η=0.01(逐渐稳定)
- 第10000次更新:η=0.001(几乎不再大改)
概念漂移的检测与应对
概念漂移是在线学习的主要敌人,比如用户突然大量使用"快乐水"代替"奶茶"。检测方法:
- 统计特征漂移:监控输入文本的词频变化(如"快乐水"出现频率从0→30%)
- 模型性能漂移:准确率从95%→70%(连续3天下降)
- 分布差异检测:用KL散度比较新数据与旧数据的分布差异
应对公式:
当检测到漂移(如KL散度>D阈值),触发:
ηnew=ηold×α(α>1,增大学习率快速适应) η_{new} = η_{old} \times α \quad (α>1,增大学习率快速适应) ηnew=ηold×α(α>1,增大学习率快速适应)
项目实战:代码实际案例和详细解释说明
开发环境搭建
- 硬件:CPU即可(在线学习通常用轻量级微调,GPU可选)
- 软件:Python 3.8+、PyTorch 1.9+、transformers 4.20+、scikit-learn(用于评估)
- 数据:真实业务场景的用户对话(需带意图标签),模拟数据流用Flask搭建API接收新请求
源代码详细实现和代码解读
我们将实现一个完整的在线学习系统,包含:
- 基础意图识别模型(预训练BERT微调)
- 在线学习模块(接收新数据并更新)
- 监控模块(检测概念漂移)
- 重训触发(当漂移严重时重新训练全量数据)
import torch
import numpy as np
from transformers import BertTokenizer, BertForSequenceClassification
from sklearn.metrics import accuracy_score
from flask import Flask, request, jsonify
# ---------------------- 初始化模块 ----------------------
app = Flask(__name__)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=10 # 预定义10种意图
)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
# 历史数据统计(用于概念漂移检测)
history_vocab = {} # 记录历史词频
history_accuracy = [0.95] # 初始准确率假设95%
# ---------------------- 核心功能 ----------------------
def update_vocab(text):
"""更新历史词频统计"""
words = tokenizer.tokenize(text)
for word in words:
history_vocab[word] = history_vocab.get(word, 0) + 1
def detect_concept_drift(new_texts):
"""检测概念漂移(简化版:统计新词比例)"""
new_words = 0
total_words = 0
for text in new_texts:
words = tokenizer.tokenize(text)
total_words += len(words)
for word in words:
if word not in history_vocab:
new_words += 1
new_word_ratio = new_words / total_words
return new_word_ratio > 0.3 # 新词占比超30%视为漂移
def online_learn(text, true_label):
"""执行在线学习并更新模型"""
inputs = tokenizer(text, return_tensors='pt', padding='max_length', truncation=True)
outputs = model(**inputs)
loss = loss_fn(outputs.logits, torch.tensor([true_label]))
loss.backward()
optimizer.step()
optimizer.zero_grad()
return loss.item()
# ---------------------- API接口 ----------------------
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
text = data['text']
inputs = tokenizer(text, return_tensors='pt', padding='max_length', truncation=True)
with torch.no_grad():
outputs = model(**inputs)
pred_label = outputs.logits.argmax().item()
return jsonify({'predicted_label': pred_label})
@app.route('/learn', methods=['POST'])
def learn():
data = request.json
text = data['text']
true_label = data['true_label']
# 1. 执行在线学习
loss = online_learn(text, true_label)
# 2. 更新词频统计
update_vocab(text)
# 3. 检测概念漂移(每100个样本检测一次)
if len(history_vocab) % 100 == 0:
recent_texts = [text] # 实际应取最近100条
if detect_concept_drift(recent_texts):
# 触发重训逻辑(这里简化为打印提示)
print("警告:检测到概念漂移,建议重新训练全量数据!")
return jsonify({'status': 'success', 'loss': loss})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
代码解读与分析
- /predict接口:处理用户请求,返回意图预测结果(无参数更新,保证实时性)
- /learn接口:接收人工标注的正确标签,执行在线学习(参数更新)
- 概念漂移检测:通过统计新词比例(如"快乐水""脆波波"等历史未出现的词),当新词占比超30%时触发警告
- 学习率策略:示例中使用固定学习率,实际可扩展为随时间衰减(如
lr = 0.001 / np.sqrt(len(history_vocab)))
实际应用场景
1. 智能客服系统
- 痛点:用户常使用新网络用语(如"绝绝子"“栓Q”),离线模型无法识别
- 在线学习方案:客服人工纠正错误时(如将"绝绝子奶茶"标注为"奶茶点单"),模型实时更新,下次遇到同类表述直接识别
2. 语音助手(如小爱同学)
- 痛点:用户口音变化(如"下雨"说成"下鱼")、新功能需求(如"打开家庭监控")
- 在线学习方案:用户纠正语音识别结果时(“我说的是’下鱼’,就是下雨”),模型更新语音→意图的映射关系
3. 电商推荐(搜索意图识别)
- 痛点:促销活动期间用户搜索词变化(如"双11优惠"→"618满减")
- 在线学习方案:实时跟踪搜索点击数据(用户搜"618满减"后点击了满减商品),更新搜索意图模型
工具和资源推荐
工具库
- Hugging Face Transformers:提供预训练模型,快速搭建意图识别基础模型
- Fugue:分布式在线学习框架(支持Spark/Dask,处理大规模数据流)
- MLflow:模型监控工具(跟踪准确率、学习率、概念漂移指标)
- spaCy:轻量级NLP库(适合对延迟敏感的在线学习场景)
论文与资料
- 《Online Learning and Stochastic Approximation》(Bottou, 1998):在线学习经典理论
- 《Continual Learning in Natural Language Processing》(ICLR 2022):NLP持续学习最新进展
- 《Handling Concept Drift in Online Learning for Sentiment Analysis》(ACL 2023):情感分析中的概念漂移应对
未来发展趋势与挑战
趋势1:小样本在线学习
未来模型可能只需少量新样本(甚至1个)就能高效学习,结合元学习(Meta-Learning)实现"快速适应"。例如,模型学会"如何学习新意图",遇到"快乐水"时自动关联到"奶茶"意图。
趋势2:隐私保护的联邦在线学习
在金融、医疗等敏感领域,数据不能集中存储。联邦在线学习让模型在各终端(如手机)本地更新,仅上传参数变化,既保护隐私又实现全局优化。
挑战1:灾难性遗忘的解决
当前模型学习新意图时可能忘记旧意图(如学会"快乐水→奶茶"后,忘记"珍珠奶茶→奶茶")。未来需要更智能的参数保护机制(如弹性权重巩固EWC),让模型"记得更牢"。
挑战2:噪声数据的鲁棒性
在线学习可能接收错误标注(如人工误标),导致模型学错。需要发展"抗噪声在线学习",通过数据清洗(如置信度过滤)、主动学习(选择高价值样本标注)提升鲁棒性。
总结:学到了什么?
核心概念回顾
- 意图识别:把用户语言翻译成机器能懂的意图标签(像"翻译官")
- 在线学习:模型边处理新数据边更新参数(像"边考试边学习的学霸")
- 持续优化:监控模型状态,调整学习策略(像"定期体检的医生")
概念关系回顾
- 意图识别是目标,在线学习是实现目标的"实时工具",持续优化是保证工具有效的"维护机制"
- 三者共同作用,让AI模型从"一次性训练"进化为"终身学习"
思考题:动动小脑筋
- 假设你的智能音箱经常收到"播放孤勇者"的请求(标注为"音乐播放"),突然有一天用户说"放首孤勇者",模型正确识别。这是在线学习的功劳吗?如果用户从未标注过"放首"这个表述,模型为什么能识别?
- 在线学习时,如果连续收到100条错误标注的数据(比如故意标错的"奶茶点单"为"投诉"),模型会怎样?如何避免这种情况?
- 你认为未来的AI模型会像人类一样"自主选择学习内容"吗?这对在线学习系统设计有什么新要求?
附录:常见问题与解答
Q:在线学习会导致模型过拟合吗?
A:会!如果新数据集中有噪声(如重复的错误标注),模型可能过度适应这些噪声。解决方法:限制学习率衰减(后期学慢)、引入正则化(如权重衰减)、主动过滤低置信度样本。
Q:实时性要求高的场景(如10ms内响应),如何优化在线学习的延迟?
A:可以只微调模型的最后几层(如分类器),而不是整个预训练模型;使用轻量级模型(如DistilBERT)替代BERT;将参数更新异步化(预测和更新分开线程)。
Q:没有人工标注的场景(如用户无反馈),如何做在线学习?
A:可以用弱监督方法(如规则生成伪标签)、自训练(模型用高置信度预测作为标签),或者结合强化学习(用用户行为反馈,如点击、下单作为奖励信号)。
扩展阅读 & 参考资料
- 书籍:《自然语言处理入门》(何晗)—— 意图识别基础
- 论文:《On the difficulty of training Recurrent Neural Networks》(Pascanu et al., 2013)—— 在线学习中的梯度问题
- 博客:Hugging Face官方文档《Fine-tuning a pretrained model》—— 预训练模型微调指南
- 工具:Fugue文档《Online Learning with Fugue》—— 分布式在线学习实践

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)