AETHER:基于几何-觉察的统一世界建模
25年7月来自中科大、上海AI实验室、上海创智院、上海交大和复旦大学的论文“AETHER: Geometric-Aware Unified World Modeling”。几何重建和生成建模的融合仍然是开发具备类人空间推理能力的AI系统的关键挑战。本文提出AETHER,一个统一的框架,通过联合优化三个核心能力,实现世界模型中的几何感知推理:(1) 4D动态重建,(2) 基于动作的视频预测,以及(3
25年7月来自中科大、上海AI实验室、上海创智院、上海交大和复旦大学的论文“AETHER: Geometric-Aware Unified World Modeling”。
几何重建和生成建模的融合仍然是开发具备类人空间推理能力的AI系统的关键挑战。本文提出AETHER,一个统一的框架,通过联合优化三个核心能力,实现世界模型中的几何感知推理:(1) 4D动态重建,(2) 基于动作的视频预测,以及(3) 基于目标的视觉规划。通过任务交错的特征学习,AETHER实现重建、预测和规划目标之间的协同知识共享。基于视频生成模型,该框架展示零样本合成到真实世界的泛化能力,尽管在训练过程中从未观察到真实世界数据。此外,由于其固有的几何建模能力,方法在动作跟随和重建任务中都实现零样本泛化。值得注意的是,即使没有真实世界数据,其重建性能也与特定领域模型相当甚至更优。此外,AETHER利用相机轨迹作为几何感知的动作空间,从而实现有效的基于动作的预测和视觉规划。
对于合成数据源,遵循 DA-V [74] 和 The-Matrix [17] 的方法,收集包含高质量视频深度数据的大规模合成数据。收集高分辨率 RGB 视频和相应的逐帧深度图,并构建一个鲁棒且全自动的相机标注流程,用于标注相机的外参和内参。如图所示,该流程包含四个阶段:(1)对象级动态掩码生成,(2)有利于重建的视频切片,(3)粗略相机定位和校准,以及(4)基于跟踪的相机优化和捆绑调整。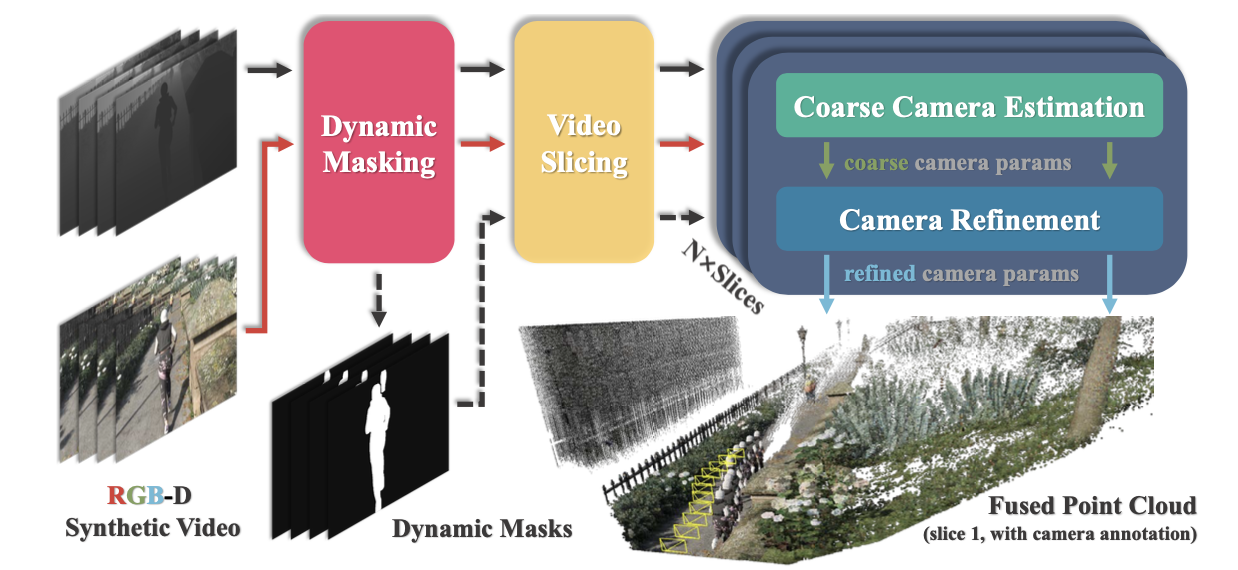
动态掩码生成。区分动态区域和静态区域对于准确估计相机参数至关重要。在这里,利用潜在的动态语义类别(例如,汽车、行人)来分割动态对象。虽然这偶尔会将静态对象(例如,停放的汽车)误分类为动态对象,但它比基于光流的分割方法更鲁棒。具体来说,用 Grounded SAM 2 [50] 来确保动态掩码在长序列上的时间一致性。
视频切片。视频切片在 3D 重建中起着关键作用,主要有两个目的:首先,它可以消除可能影响重建质量的不合适视频片段(例如,场景切换或运动模糊帧)。其次,它可以将长视频分割成更短、时间上连贯的片段,以提高处理效率。帧移除的具体标准如下:(1)特征点不足:用 SIFT [39] 特征描述符从每一帧中提取关键点。丢弃 SIFT 关键点不足的帧,以确保鲁棒的对应关系估计。此外,由于光照不足而导致纹理不足的区域的帧也被排除,因为这些区域通常特征辨别能力较差,并且对可靠匹配构成挑战。(2)大面积动态区域:动态区域(从动态标注中获得)占主导地位的帧可能会在相机姿态估计中引入歧义。此类帧会被过滤掉,以确保鲁棒的结果。 (3) 大幅度运动或不准确的对应关系:用现成的光流估计器 RAFT [61] 来估计运动幅度。如果这些幅度超过预设阈值,会在当前帧处截断序列,保留所有之前的帧作为有效片段。类似地,如果前向光流误差与后向光流误差之比超过阈值,也会截断当前帧,以确保时间一致性。
粗略相机估计。对于每个视频片段,首先使用 DroidCalib [25] 利用静态区域的深度信息对相机参数进行粗略估计。然而,由于 DroidCalib 模型的输入分辨率较低且其对应关系估计精度有限,因此需要进行细化过程才能获得精确的相机参数。
相机细化。首先使用最先进的跟踪器 CoTracker3 [33] 来捕获整个片段中准确的长期对应关系,从而开始相机细化过程。从静态区域提取 SIFT [39] 和 SuperPoint [12] 特征点,然后进行跟踪以形成对应关系。随后,对所有帧执行捆绑调整,以最小化所有对应关系的累积重投影误差。由于可以获得高质量的密集深度信息,应用前向-后向重投影来估计和最小化 3D 空间中的误差 [8],这提高每帧相机的精度,同时保持帧间几何一致性。具体来说,用 Ceres Solver [1] 求解非线性优化问题,并应用 Cauchy 损失函数来衡量对应关系残差,从而考虑问题的稀疏性。
一个基础视频扩散模型进行后训练,得到统一的多任务世界模型 AETHER,其中用 CogVideoX-5b-I2V [77] 作为基础模型。
方法概述
主流视频扩散模型 [27, 40] 通常包含两个过程:前向(加噪)过程和反向(去噪)过程。前向过程逐步向干净的潜在样本 z_0 添加高斯噪声,记为 ε ∼ N (0, I),其中 k、c、h、w 分别表示视频潜表示的维度。通过此过程,干净的 z_0 逐渐转化为带噪声的潜表示 z_t。在反向过程中,学习的去噪模型 ε_θ 逐步从 z_t 中去除噪声,以重建原始潜表示。去噪模型 ε_θ 以辅助输入 c 和扩散时间步 t 为条件。
在方法中,目标潜表示 z_0 包含三种模态:彩色视频潜表示 z_c_0、深度视频潜表示 z_d_0 和动作潜表示 z_a_0。该模型还额外接收两种类型的条件作为输入:彩色视频条件 c_c 和动作条件 c_a。对于动作模态,选择相机姿态轨迹作为全局动作,这得益于之前描述的自动化相机姿态标注流程。所有潜表示和条件都进行通道级联。
AETHER 的多任务目标由不同任务的特定条件 c 决定。(1) 重建:c_c 表示输入视频的潜表示。(2) 视频预测:c_c 将观察图像的潜表示作为第一帧,而其他潜表示则用零填充。(3) 目标条件视觉规划:c_c 的第一个和最后一个潜表示分别对应于观察图像和目标图像,所有中间潜表示都用零填充。对于动作条件 c_a,它要么完全被置零掩码,要么在无动作控制或有动作控制的情况下包含完整的目标相机姿态轨迹。如图展示相关示例: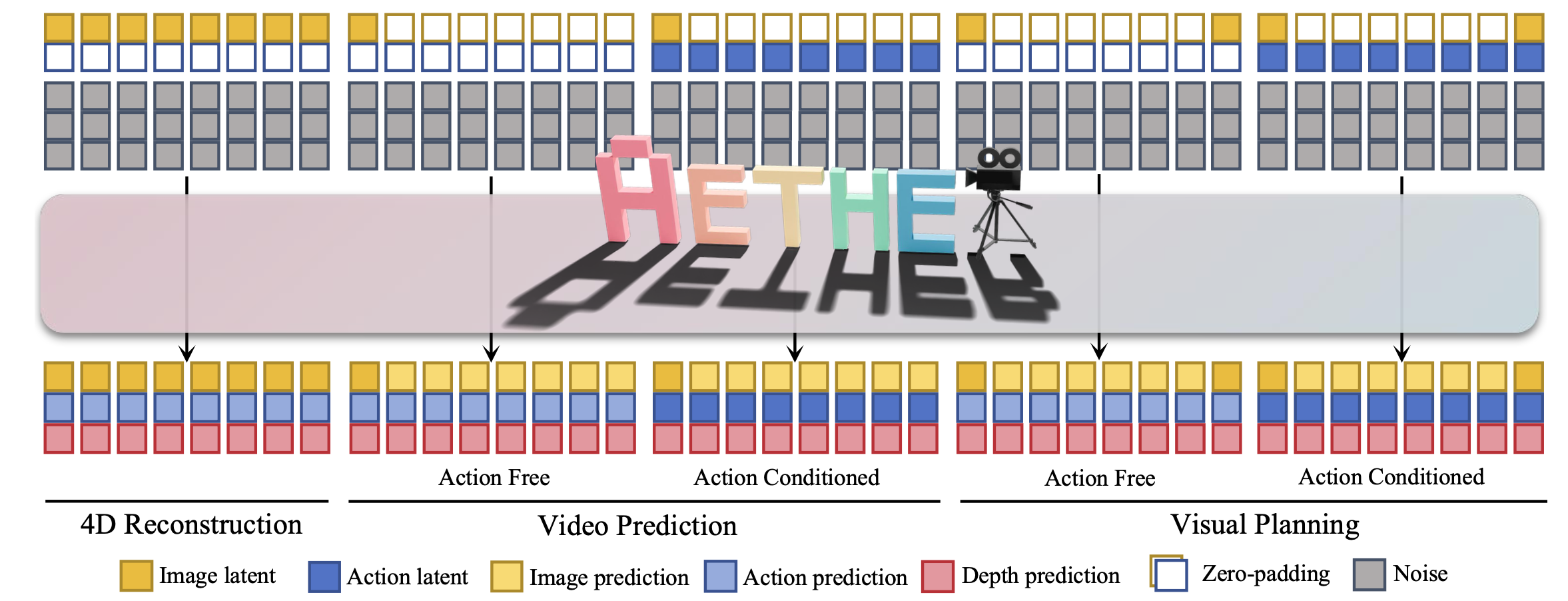
深度视频处理
给定深度视频 x_d,首先将深度值裁剪到预定义的范围 [d_min, d_max]。接下来,应用平方根变换,然后计算倒数,将深度值转换为视差,如文献 [57] 所述。然后,以尺度不变的方式对每个视差视频片段进行归一化。随后,将归一化后的视差值从 [0, 1] 线性映射到 [−1, 1]。为了满足 VAE 的输入要求,将单通道视差图复制到三个通道,如先前的工作 [34, 74] 所述。
相机轨迹处理流程
将相机参数转换为射线图(raymap)视频 [7],以便视频扩散模型能够对其进行兼容处理。具体而言,给定内参矩阵 K 和外参矩阵 E,转换过程可以描述如下:
平移缩放和归一化。相机姿态(外参矩阵的逆矩阵)的平移分量 t 首先乘以常数因子 s_ray 进行缩放,然后使用最大视差值 d_max 进行归一化。为了抑制较大的值,随后对其应用带符号的 log(1 + ·) 变换。
射线图构建。使用内参矩阵 K,计算每个像素在齐次坐标系下的相机射线方向 r_d。请注意,不对其进行单位归一化,而是使其沿 z 轴具有单位值。射线原点 r_o 设置为平移向量 t_log,并在空间维度上进行复制。世界坐标系下的射线图是通过使用外参矩阵 E 变换射线方向 r_d 获得的。最终的射线图 r 包含 6 个通道:3 个用于射线方向 r_d,3 个用于射线原点 r_o。
分辨率下采样。为了使射线图与 VAE 的潜特征维度对齐,在空间和时间上都进行调整。在空间上,使用双线性插值将射线图下采样 8 倍。在时间上,每连续 4 帧沿通道维度进行拼接。得到的重排张量记为 z_a。
将射线图转换回相机矩阵。给定按时间轴重排的生成射线图序列 ˆr = [rˆ_d, rˆ_o],首先通过以下公式恢复射线原点:
rˆ_o′ = sign(rˆ_o) · (exp(|rˆ_o|)−1)/s_ray,
然后,可以通过算法 1 恢复内参和外参。
模型训练
用预训练的 CogVideo-5b-I2V [77] 权重初始化 AETHER,但不包括用于深度和射线图动作轨迹的附加输入和输出投影层通道,这些通道初始化为零。由于未使用文本提示条件,因此在训练和推理期间都提供空的文本嵌入。
由于使用的数据集包含长度和帧率 (FPS) 可变的视频片段,随机选择 T ∈ {17, 25, 33, 41} 帧,并且 FPS 从 {8, 10, 12, 15, 24} 中随机采样。RoPE [59] 系数进行线性插值以与之对齐。在训练过程中,条件输入会被随机掩码,以提高模型在不同任务上的泛化能力。对于 c_c,掩码概率如下:观察图像和目标图像均掩码 30%(视觉规划任务),仅观察图像掩码 40%(视频预测),全彩视频潜表示掩码 28%(4D 重建),以及掩码 c_c 的所有部分,概率为 2%。对于 c_a,轨迹潜表示以相等的概率被保留或完全掩码(支持无动作或动作条件下的射线图条件任务)。这种策略使模型能够适应不同的任务和输入条件设置。
训练过程分为两个阶段。在第一阶段,采用标准潜扩散模型的损失函数,最小化潜空间中的均方误差 (MSE)。在第二阶段,将生成的输出解码到图像空间来优化生成结果。具体来说,引入三个额外的损失项:用于彩色视频的多尺度结构相似性 (MS-SSIM) 损失 [67]、用于深度视频的尺度和位移不变损失 [49],以及用于从生成的深度图和射线图投影的点图尺度和位移不变点图损失 [66]。注:第二阶段的训练步数约为第一阶段的 1/4。
采用混合训练策略,结合计算节点内的全分片数据并行 (FSDP) [87] 和 Zero-2 优化,以及跨节点分布式数据并行 (DDP)。由于深度视频需要在线归一化,因此 VAE 编码器在训练期间也在线运行,并在 DDP 下运行。实现每个 GPU 处理的本地批次大小为 4,因此在 80 个 A100-80GB GPU 上,有效批次大小为 320 个样本。训练使用 AdamW [38] 优化器和 OneCycle [56] 学习率调度器进行,持续两周。
零样本视频深度估计
实现细节。视频深度估计的评估基于两个关键方面:每帧深度质量和帧间深度一致性。这些评估通过使用每序列的尺度对齐预测深度图和真实深度图来完成。用绝对相对误差 (Abs Rel) 和 δ < 1.25(预测深度值在真实深度值的 1.25 倍范围内的百分比)作为评估指标。在实现方面,采用 CUT3R [65] 中概述的设置。基线方法包括基于重建的方法,例如 DUSt3R [66]、MASt3R [37]、MonST3R [82]、Spann3R [63] 和 CUT3R [65],以及基于扩散的深度估计器,包括 ChronoDepth [55]、DepthCrafter [29] 和 DepthAnyVideo (DA-V) [74]。需要注意的是,在与基于扩散的深度估计器进行比较时,对真实深度图应用尺度和偏移对齐,因为大多数这些方法本身并不具有尺度不变性。所有视频都保持原始宽高比进行缩放,使短边与模型的输入尺寸对齐。对于超过模型最大前向处理空间或时间尺寸的视频,采用步长为 8 的滑动窗口策略。在窗口重叠区域,首先通过计算逐元除法的平均值来估计相对尺度。然后使用该相对尺度调整后一个窗口的深度预测。最后,按照类似于先前方法 [29, 80] 的方法,对重叠区域应用线性空间加权平均。
零样本相机位姿估计
实现细节。遵循 MonST3R [82] 和 CUT3R [65] 的方法,在 Sintel [6]、TUM Dynamics [58] 和 ScanNet [10] 数据集上评估相机位姿估计精度。值得注意的是,Sintel 和 TUM Dynamics 数据集都包含高度动态的物体,这对传统的SfM和SLAM系统提出严峻的挑战。按照 [65] 中的方法,在与真实值进行 Sim(3) 对齐后,报告绝对平移误差 (ATE)、相对平移误差 (RPE Trans) 和相对旋转误差 (RPE Rot)。实现设置与 CUT3R [65] 中使用的设置一致。所有视频都保持原始宽高比进行缩放,然后进行中心裁剪,以匹配模型的输入尺寸。对于超过模型最大时间序列处理长度的长视频,采用步长为 32 的滑动窗口策略。在窗口重叠区域,相机位姿按照先前的方法 [64] 进行对齐。平移对齐使用线性插值,而四元数旋转则使用球面线性插值进行插值。此外,生成的相机轨迹存在噪声,这可能是由于去噪步骤数量有限造成的。为了缓解这个问题,应用简单的卡尔曼滤波器 [71] 来平滑轨迹。
视频预测
实现细节。用 CogVideoX-5b-I2V [77] 作为基线模型。为了确保公平比较,构建一个包含两个子集的验证数据集:域内数据和域外数据。域内子集包含来自与训练数据集相同的合成环境中的全新、未见过的场景,而域外子集包含来自全新合成环境的数据。两个模型都以第一帧作为观察图像。对于无动作预测,由于 CogVideoX 严重依赖文本提示,用 GPT-4o [31] 生成图像描述和未来场景预测作为 CogVideoX 的提示。相比之下,AETHER 使用空文本提示进行评估。对于动作条件预测,还在验证数据集中标注相机轨迹,并生成相应的射线图序列作为 AETHER 的动作条件。对于基线模型,除了用于无动作预测的提示之外,还使用 GPT-4o [31] 生成物体和相机运动的详细描述,使基线模型能够使用语言作为动作条件。对 CogVideoX 的文本提示使用默认的无分类器引导(CFG)值 6,对 AETHER 的观察图像使用值 3。为了确保公平性,没有对动作条件应用无分类器引导(CFG)。评估指标遵循视频生成标准基准 VBench [30]。
视觉规划
实施细节。在验证集上评估 AETHER 的动作条件导航能力。为了证明多任务目标的有效性,特别是重建目标的引入,还对一个不包含视频深度目标的消融模型进行后训练,该模型记为 AETHER-no-depth。给定观察图像、目标图像和相机轨迹,生成的视频应该是高度确定的。因此,报告动作条件导航的像素级重建指标,包括 PSNR、SSIM [68]、MS-SSIM [67] 和 LPIPS [83]。对于无动作的情况(代表视觉路径导航任务),也报告 VBench 指标。在这两项任务中,都没有使用任何无分类器引导(CFG)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献218条内容
已为社区贡献218条内容

所有评论(0)