给大模型一本参考书,它反而考得更差了?DeR2揭示RAG推理的致命盲区
摘要 最新研究DeR2揭示了一个反直觉现象:当大语言模型在RAG(检索增强生成)场景下获得完整参考文档时,其推理表现反而比闭卷测试更差。通过构建包含16个学科领域、严格校准难度的评测数据集,研究发现: 在四种控制设定(仅指令/仅概念/仅相关文档/完整文档集)下,14个前沿模型的平均得分呈现"开卷不如闭卷"现象(完整文档51.1% vs 仅指令55.9%) 主要归因于两大问题:推
给大模型一本参考书,它反而考得更差了?DeR2揭示RAG推理的致命盲区
你拿着一本教科书去参加开卷考试,结果分数比闭卷还低。听起来荒谬?但这恰恰是当前最强大语言模型在RAG场景下的真实表现。DeR2用一个精心设计的"沙盒"证明了这件事,并找到了两个根源。
- 论文:DeR2: Decoupled Retrieval and Reasoning Benchmark for Retrieval-Augmented Reasoning Assessment
- 链接:https://arxiv.org/abs/2601.21937
- 作者:Shuangshuang Ying 等(M-A-P & ByteDance Seed,指导教师来自哈工大深圳、复旦、北大)
- 代码/数据:https://github.com/M-A-P-MARL/DeR2
一句话总结:DeR2构建了一个将检索能力和推理能力完全解耦的评测沙盒,通过四种控制变量的设定测试14个前沿模型,发现一个反直觉现象——提供完整文档后模型平均得分(51.1%)低于只给指令时(55.9%),并将原因归结为"推理模式切换脆弱性"和"结构性概念误用"两大病灶。
🔬 问题出在哪:现有RAG评测的两个根本缺陷
要理解DeR2在做什么,先看看现有RAG评测是怎么做的。
闭卷问答(Closed-book QA):直接问模型一个问题,看它能不能从参数记忆里找到答案。这只能测模型"记没记住",完全无法评估推理能力。你问一个2024年发表的定理推导,模型训练数据里没有,它当然答不出来——但这不代表它推理能力差,只是它没见过这个知识。
标准RAG评测:给模型一个问题+一堆检索到的文档,让它生成答案。模型答错了——是因为检索到的文档不相关(检索失败)?还是相关文档给到了但模型推理出错(推理失败)?你分不清。检索和推理能力纠缠在一起,诊断不出具体的失败原因。
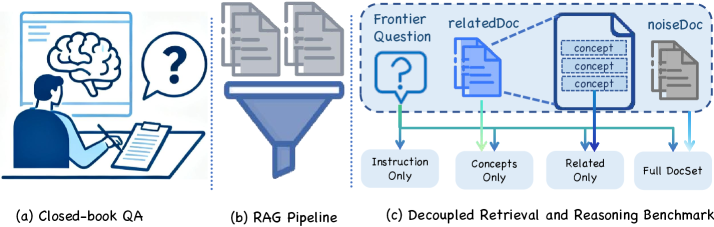
图1:(a) 闭卷QA只评估内在知识;(b) 标准RAG流水线中检索与推理纠缠不清,失败时无法归因;© DeR2的解耦方案——通过四种控制设定(仅指令、仅概念、仅相关文档、完整文档集),把检索和推理的影响逐一分离。
DeR2的想法很直接:既然纠缠分不清,那就设计一个"沙盒",把检索和推理彻底拆开来单独测。
🏗️ DeR2的设计:一个四档控制变量的实验沙盒
DeR2的核心是四种评测设定,每种设定控制了不同程度的信息输入:
Setting 1 — Instruction-only(仅指令):只给模型题目描述,不给任何参考文档。这测的是模型的"参数记忆"——它训练数据里见过类似的知识吗?
Setting 2 — Concepts-only(仅概念):给模型题目描述 + 解题所需的核心概念名称和定义。不给完整文档,只给"解这道题需要用到XXX定理、YYY方法"这样的概念清单。这是一个Oracle设定——如果模型拿到了准确的概念仍然做错,那就是纯粹的推理能力不足。
Setting 3 — Related-only(仅相关文档):给模型题目描述 + 与题目相关的论文文档,但不包含噪声文档。这模拟的是"完美检索"——检索系统恰好返回了所有相关文档。
Setting 4 — Full-set(完整文档集):给模型题目描述 + 相关文档 + 噪声文档。这模拟的是真实RAG场景——检索结果里既有有用的,也有不相关的干扰项。
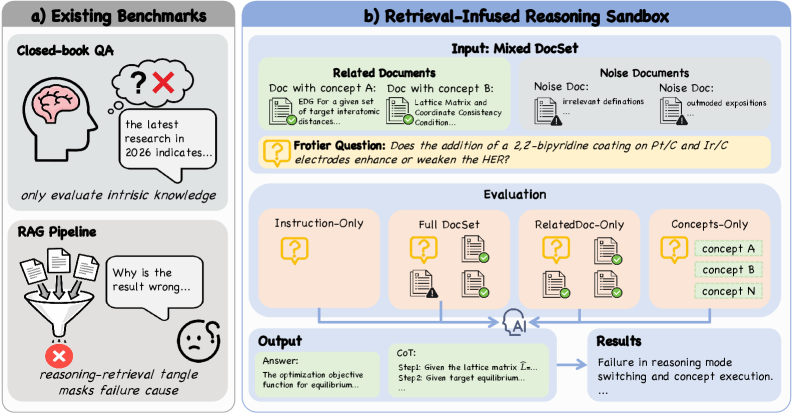
图2:左半部分展示了现有评测的局限——闭卷QA只评估内在知识,RAG流水线中检索与推理纠缠无法归因。右半部分是DeR2沙盒的设计:输入由相关文档(含概念A/B)和噪声文档组成的混合文档集,通过四种控制设定分别测试,输出答案+推理链,最终精确定位推理模式切换失败和概念执行失败两类问题。
这四种设定的妙处在于它们形成了一个逻辑递进链:
- Setting 1 → Setting 2:加入概念后性能提升多少?= 概念知识对推理的增益
- Setting 2 → Setting 3:从精确概念变成完整文档后性能变化如何?= 模型从文档中提取概念的能力
- Setting 3 → Setting 4:加入噪声文档后性能下降多少?= 模型的抗干扰能力
特别地,论文定义了一个**检索损失(Retrieval Loss, RLoss)**指标:
RLoss = Score Concepts-only − Score Full-set \text{RLoss} = \text{Score}_{\text{Concepts-only}} - \text{Score}_{\text{Full-set}} RLoss=ScoreConcepts-only−ScoreFull-set
RLoss衡量的是:模型在"拿到精确概念"与"拿到完整文档集"之间的性能差距。这个差距越大,说明模型在真实RAG场景下的推理退化越严重。
📐 数据怎么来的:一个高门槛的四步标注流程
DeR2的数据质量决定了它的评测结论是否可信。论文设计了一个相当严格的标注流程。
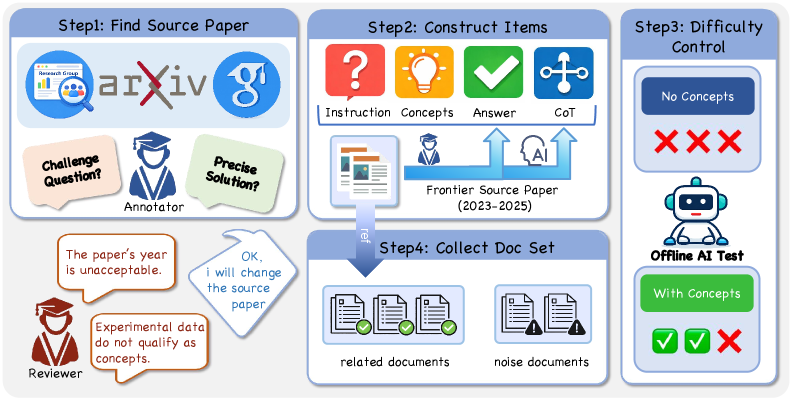
图3:四步流程——Step 1: 从2023-2025年的arXiv论文中筛选源文献,标注员构造挑战性问题并经过审核反馈;Step 2: 构建指令/概念/答案/推理链四元组;Step 3: 难度校准——无概念时模型必须连续3次失败,有概念时至少1次成功;Step 4: 收集相关文档和噪声文档。
Step 1:选源论文。 所有问题基于2023-2025年发表的前沿理论论文。为什么要限制年份?为了防止参数记忆泄漏——如果题目基于2020年的经典论文,模型大概率在训练时见过,那测出来的就不是推理能力,而是记忆力。标注团队是来自985高校的博士生,每个人在自己的专业领域内出题。
Step 2:构建四元组。 每道题包含:Instruction(问题描述)、Concepts(解题需要的核心概念及定义)、Answer(标准答案)、CoT(完整的推理链)。这里的Concepts不是模糊的关键词,而是精确的定义+使用方法——这保证了Setting 2(Concepts-only)是一个真正的"金标准"Oracle。
Step 3:难度校准。 这一步是DeR2数据质量的关键保障。采用两阶段验证协议:
- 无概念必须失败:在Instruction-only设定下,模型必须连续3次回答错误。如果模型凭"记忆"就能答对,说明这道题对参数知识没有去掉依赖,需要替换。
- 有概念必须成功:在Concepts-only设定下,模型至少1次回答正确。如果拿到了精确概念还答不对,说明这道题本身的推理难度超出了模型能力范围,也不是好的评测题目。
用离线AI测试(GPT-4o等模型)来执行这个校准过程。通过双重筛选的题目才能进入最终数据集。
Step 4:收集文档集。 为每道题收集相关文档(包含解题概念的论文)和噪声文档(同领域但与解题无关的论文),构成完整的文档集。
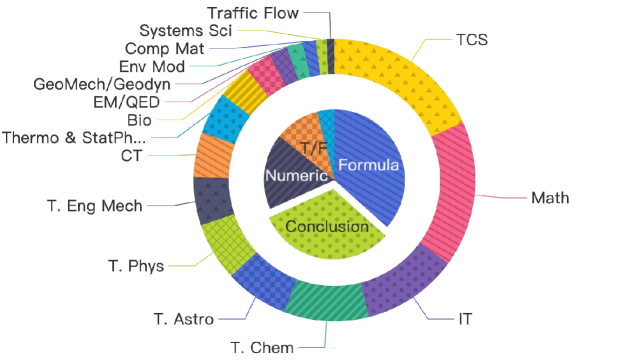
图4:外环是领域分布——覆盖理论计算机科学(TCS)、数学、信息论、理论化学/天体物理/物理、工程力学、生物、控制论、热力学/统计物理、电磁学/量子电动力学、地球力学/地球动力学、环境建模、计算材料、系统科学、交通流等16个学科。内环是答案类型分布——公式、结论、数值、判断题四类。
覆盖16个理论学科领域,答案类型包含公式推导、理论结论、数值计算和真假判断四类。这不是一般的NLP数据集——能出这种题的标注员本身就需要博士级别的专业知识。
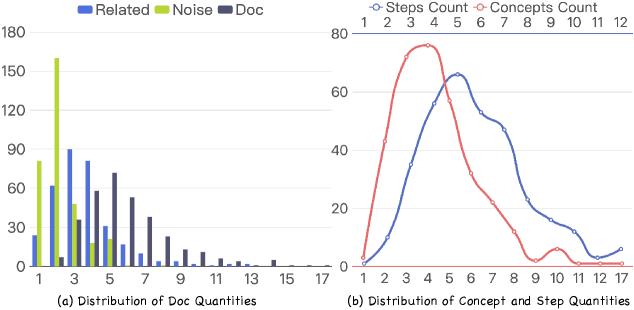
图5:(a) 文档数量分布——每道题包含的相关文档、噪声文档和总文档数量直方图;(b) 概念数和推理步数的分布曲线——概念数集中在4-5个,推理步数集中在5-6步。
📊 实验结果:开卷反而考更差
论文评测了14个前沿模型,四种设定下的完整结果:
| 模型 | Instruction-only | Concepts-only | Related-only | Full-set | RLoss |
|---|---|---|---|---|---|
| GPT-5.2-high | 65.8 | 83.8 | 71.4 | 71.1 | 12.7 |
| Gemini-3-Pro-Preview | 64.2 | 80.3 | 56.3 | 53.7 | 26.6 |
| Gemini-3-Flash-Preview | 54.9 | 66.2 | 53.3 | 53.9 | 12.3 |
| GPT-5.1-high | 56.4 | 78.1 | 59.9 | 56.7 | 21.4 |
| DeepSeek-V3.2-Exp-Thinking | 56.2 | 80.6 | 56.0 | 55.3 | 25.3 |
| Moonshot-kimi-k2-thinking | 58.1 | 71.8 | 53.1 | 53.7 | 18.1 |
| Gemini-2.5-Pro | 56.1 | 77.3 | 53.4 | 49.8 | 27.5 |
| GLM-4-6 | 56.2 | 75.1 | 53.4 | 48.1 | 27.0 |
| QwenAPI-3-max-0923 | 56.6 | 76.1 | 52.3 | 51.0 | 25.1 |
| Claude-Sonnet-4.5 | 55.2 | 74.5 | 45.3 | 44.2 | 30.3 |
| Doubao-1.8-1228-high | 50.2 | 74.8 | 47.4 | 46.4 | 28.4 |
| DeepSeek-V3.1-terminus-thinking | 53.4 | 70.2 | 45.3 | 44.0 | 26.2 |
| Doubao-1.6-1015-high | 50.2 | 67.2 | 41.5 | 39.5 | 27.7 |
| Claude-Opus-4.1-thinking | 49.3 | 80.3 | 53.3 | 47.9 | 32.4 |
| 平均 | 55.9 | 75.4 | 52.8 | 51.1 | 24.4 |
这张表里藏着几个非常值得深挖的发现。
发现一:给文档反而降分——推理模式切换脆弱性
看平均数据:Full-set(51.1%)< Instruction-only(55.9%)。14个模型中,绝大多数在拿到完整文档后成绩不升反降。
最夸张的例子是Gemini-3-Pro-Preview:Instruction-only拿到64.2%,Full-set跌到53.7%,掉了10.5个百分点。这意味着在真实RAG场景下,Gemini-3-Pro-Preview还不如"什么文档都不给"的闭卷表现。
GPT-5.2-high是唯一在Full-set下保持高性能的模型(71.1%),且RLoss最低之一(12.7),说明它在模式切换上相对稳健。
论文将这个现象命名为推理模式切换脆弱性(Mode Switching Fragility)——模型在"依赖参数记忆做推理"和"依赖外部文档做推理"之间切换时,推理质量会显著下降。它不是简单地"没看到有用信息",而是外部文档的引入干扰了模型原本的推理路径。
发现二:概念能说对但执行做错——结构性概念误用
看Concepts-only列:平均75.4%。这说明模型在拿到精确概念时推理表现相当不错。但对比Full-set(51.1%)和Related-only(52.8%),差距达到了22-24个百分点。
论文分析了具体的失败案例,发现了一种典型的失败模式:模型能正确地说出概念名称,但无法将概念作为过程正确执行。 比如一道需要"拉格朗日对偶"的题,模型会在推理链中写出"使用拉格朗日对偶方法",但随后执行的步骤却是一个泛化的启发式模板,而不是这个具体问题需要的对偶变换步骤。
换个说法:模型知道"要用拉格朗日对偶",但不会"做拉格朗日对偶"。它把概念当成了一个标签贴在推理链上,而不是当成一组需要精确执行的操作步骤。
这就是结构性概念误用(Structural Concept Misuse)——概念被正确识别但错误实例化。
发现三:噪声的影响是非线性的
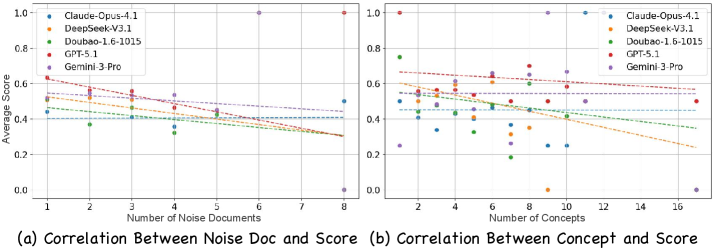
图6:(a) 噪声文档数量与得分的散点图——随噪声增加,多数模型得分下降,Claude-Opus-4.1-thinking和DeepSeek-V3.1下降最为显著;(b) 概念数量与得分的关系——需要的概念越多,得分越低,大部分模型呈负相关。
噪声文档对性能的损害不是简单的线性叠加。论文发现,少量噪声文档就能造成显著的性能下降,而进一步增加噪声文档数量后,额外的下降幅度反而变小。这暗示噪声文档改变了模型推理的初始拓扑结构——一旦模型在推理早期被噪声信息带偏,后续的推理轨迹就会不可逆地偏离正确路径。这不是一个简单的"信噪比"问题,而是推理路径的拓扑敏感性问题。
发现四:RLoss的巨大差异暴露了模型间的鲁棒性鸿沟
RLoss最低的是Gemini-3-Flash-Preview(12.3)和GPT-5.2-high(12.7),最高的是Claude-Opus-4.1-thinking(32.4)。32.4意味着什么?意味着Claude-Opus-4.1-thinking在从"拿到精确概念"切换到"拿到完整文档集"时,性能损失了近三分之一。
一个有意思的对比:Claude-Opus-4.1-thinking在Concepts-only设定下拿到80.3%(和GPT-5.2-high的83.8%接近),但Full-set下暴跌到47.9%(GPT-5.2-high是71.1%)。这两个模型的"纯推理能力"相差不大,但"在噪声中推理"的能力相差悬殊。
🧠 为什么会这样?两个层面的解释
浅层解释:注意力被稀释
给模型一堆文档后,它需要在长上下文中识别哪些信息有用、哪些是干扰。上下文变长意味着注意力权重被分散,模型可能把本该聚焦在关键概念上的"认知资源"浪费在了无关内容上。
但这个解释不够——如果只是注意力稀释,Related-only(没有噪声文档)的表现应该接近Concepts-only。实际上Related-only(52.8%)远低于Concepts-only(75.4%),说明问题不仅是"信息太多找不到"。
深层解释:推理策略的冲突
Instruction-only设定下,模型被迫使用参数化推理——它只能依靠训练中学到的知识和推理模式。这时候模型会调用一套相对稳定的"内部推理模板"。
一旦引入外部文档,模型需要切换到"文档驱动推理"模式——从文档中提取信息,与题目要求对齐,然后组合推理。问题在于,当前模型在这两种模式之间的切换机制很脆弱。文档的引入不是单纯地"添加信息",而是改变了整个推理的起点和路径。
具体来说:
- 模型在文档中找到了一些"看起来相关"的概念,就会放弃自己参数记忆中更准确的推理路径,转而尝试拼接文档中的信息
- 但文档中的概念表述可能与模型内部表征的格式不完全对齐,导致概念虽然被识别但无法被正确执行
- 噪声文档中的"伪相关"信息会进一步干扰概念提取和推理路径选择
💡 批判性思考
1. 数据集规模和领域偏向
论文覆盖了16个理论学科领域,但没有公布每个领域的题目数量分布。如果某些领域题目过少(比如交通流或环境建模),这些领域的评测结论可能缺乏统计显著性。此外,所有题目都来自"理论性"学科——纯工程、实验科学领域的推理模式可能与理论推导非常不同,DeR2的结论能否推广到这些领域是个问号。
2. 两阶段验证协议的盲区
两阶段校准要求"Instruction-only连续3次失败"+“Concepts-only至少1次成功”。但"3次失败"作为阈值够不够严格?如果一道题模型有20%的概率猜对,那连续3次失败的概率仍有51.2%——有近一半概率这道题其实不符合"模型不知道"的假设。更保守的做法是要求5次甚至更多次连续失败。
3. 评测模型的选择
14个模型全是API调用的闭源或半开源模型(如GPT-5.2、Gemini-3、Claude-Opus-4.1等)。这意味着:(a) 无法控制模型的解码参数(温度、采样策略等),这些参数对推理任务影响很大;(b) 闭源模型的版本更新可能导致评测结果不可复现;© 没有覆盖开源的7B/14B量级模型,无法回答"小模型是否有不同的失败模式"这个问题。
4. RLoss指标的解读需要谨慎
RLoss = Score(Concepts-only) - Score(Full-set) 是一个差值指标。但Concepts-only给的是人工精选的概念清单,Full-set给的是完整文档——两者的信息形式完全不同。RLoss大未必意味着模型"不会用文档",也可能只是说明"人工概念清单就是比完整文档更好用"。一个更公平的对比可能是:从完整文档中自动提取概念,与人工概念清单做对比。
5. 对RAG系统设计的实际启示
论文的发现对RAG工程有直接的指导意义:与其给模型灌入一堆检索到的原始文档,不如先做一层"概念提取"——从文档中抽出关键概念和定义,以结构化的形式喂给模型。Concepts-only(75.4%)和Full-set(51.1%)之间24个百分点的差距,说明"信息预处理"可能比"检索更多文档"重要得多。
📌 关键信息速查
| 项目 | 内容 |
|---|---|
| 标题 | DeR2: Decoupled Retrieval and Reasoning Benchmark for Retrieval-Augmented Reasoning Assessment |
| 核心贡献 | 构建解耦检索与推理能力的评测沙盒,四种控制变量设定 |
| 数据来源 | 2023-2025年arXiv理论论文,985高校博士生标注 |
| 覆盖领域 | 16个理论学科(TCS、数学、信息论、理论物理/化学/天文等) |
| 答案类型 | 公式、结论、数值、判断 |
| 评测模型 | 14个前沿模型(GPT-5.2、Gemini-3-Pro/Flash、Claude-Opus-4.1-thinking等) |
| 核心发现 | Full-set平均51.1% < Instruction-only平均55.9%;RLoss平均24.4 |
| 最佳模型 | GPT-5.2-high(Full-set 71.1%,RLoss 12.7) |
| 最大RLoss | Claude-Opus-4.1-thinking(32.4) |
| 两大病灶 | 推理模式切换脆弱性 + 结构性概念误用 |
| 难度校准 | 两阶段验证:Instruction-only连续3次失败 + Concepts-only至少1次成功 |
| 代码 | https://github.com/M-A-P-MARL/DeR2 |
如果觉得有用,欢迎点赞、在看、转发三连~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)