把简单题“拼“成难题:Composition-RL 如何让大模型越练越聪明
本文提出了一种名为Composition-RL的创新方法,通过将简单数学题拼接组合成复杂题目来提升大模型的推理能力。该方法利用顺序提示词组合(SPC)技术,自动将两道独立数学题合并为一道新题,并保持答案可验证性。实验表明,这种组合显著降低了"全对"样本比例,使训练数据更具挑战性。在多种模型规模(1.5B-30B)的测试中,该方法平均提升8.3个点,在AIME24竞赛题上准确率提
把简单题"拼"成难题:Composition-RL 如何让大模型越练越聪明
论文:Composition-RL: Composing Verifiable Prompts for LLM Reasoning
作者:Haotian Luo, Li Shen, Haiying Luo 等
机构:JD Explore Academy
链接:https://arxiv.org/abs/2602.12036
一句话概括
这篇论文提出了一个巧妙的思路:把多道已有的简单数学题"拼接"成一道新的复杂题,用这些自动生成的高难度题目来训练大模型,让强化学习的效果大幅提升。
问题从哪来?
最近两年,RLVR(Reinforcement Learning with Verifiable Rewards,基于可验证奖励的强化学习)在大模型推理能力训练上火得一塌糊涂。DeepSeek-R1 用它训练出了惊人的数学和代码推理能力,各路团队纷纷跟进。
RLVR 的核心思路很朴素:给模型一道数学题,让它自己生成若干个答案,能答对的就给奖励1,答错的给0——没有人工打分,没有偏好模型,就靠"对不对"这一条硬标准来指导训练。
听上去很完美,但实际操作中有个大问题:训练着训着,大部分题目都变得太简单了。
下面这张图展示了这个现象:
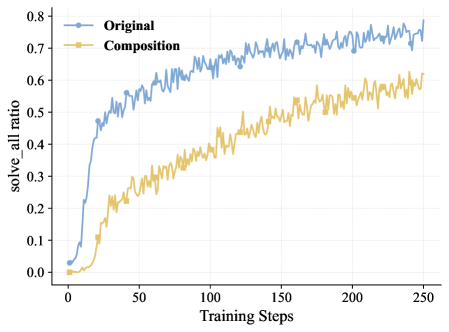
蓝色线(Original)代表用原始数据训练时,“所有采样答案全对”(solve_all)的样本比例变化。可以看到,随着训练推进,这个比例从接近0飙升到了75%以上。也就是说,训练到后期,模型面对的题目里有四分之三已经"不构成挑战"了——每次采样出来的答案全是对的,奖励信号永远是1,模型从中学不到任何东西。
这就好比一个学生天天做自己已经会的题,看上去正确率很高,实际上啥也没学到。
现有的方案(比如 Dynamic Sampling)会把这些"全对"和"全错"的题目跳过,只保留有信息量的样本来训练。但这治标不治本——你跳过的题越来越多,实际能用来训练的数据量就越来越少。
根本问题是:缺少足够多的、难度匹配的训练题目。
那怎么办?去找更难的题?现实中高质量的数学难题资源有限,人工标注更是贵得吓人。
这篇论文给出了一个让人拍大腿的方案:不用去找新题,把现有的简单题拼起来,自动变成难题。
核心方法:SPC——把两道题"焊"在一起
论文提出的方法叫 SPC(Sequential Prompt Composition),翻译过来是"顺序提示词组合"。它的思路直截了当:拿两道独立的数学题 q1 和 q2,通过三个步骤把它们合并成一道新题 q1:2。
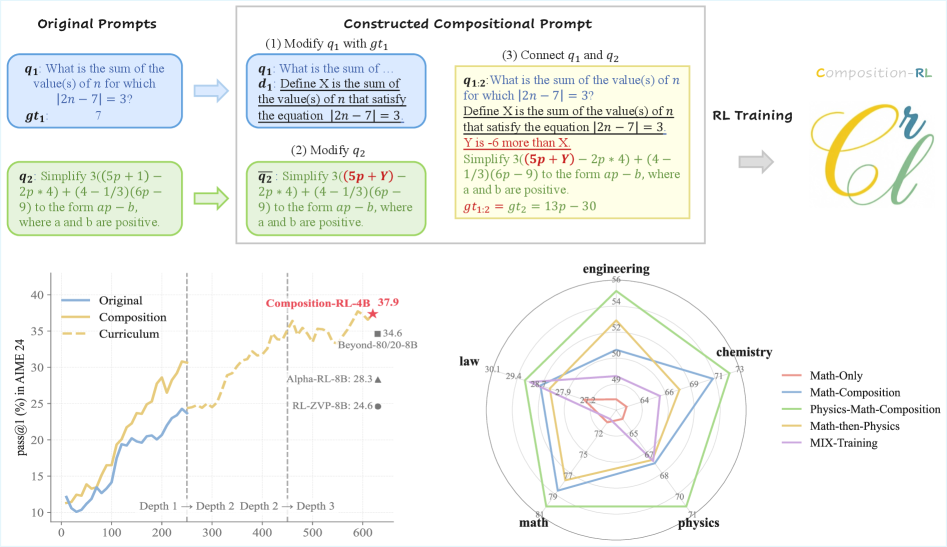
上图左上角完整展示了 SPC 的三步操作。用一个具体的数学例子来说明:
原始题目:
- q1:“数列 {aₙ} 满足 aₙ = 2n - 1,求前5项和 S₅。”(答案:25)
- q2:“一个矩形的长为 L,宽为3,面积是多少?”(这里 L 是某个数值)
Step 1:从 q1 的答案中提取一个数值,定义为变量
从 q1 的答案25中,定义一个变量 v1 = S₅ = 25。这个变量将成为连接两道题的桥梁。
Step 2:用这个变量替换 q2 中的一个数值
把 q2 里矩形的长 L 替换成 v1。于是 q2 变成了:“一个矩形的长为 v1,宽为3,面积是多少?”
Step 3:用自然语言把两道题串起来
最终合成的 q1:2 大概长这样:“数列 {aₙ} 满足 aₙ = 2n - 1,求前5项和 S₅。然后,用 S₅ 作为矩形的长,宽为3,求矩形的面积。”
答案就是 25 × 3 = 75。
这个操作看上去简单,但仔细想想会发现几个精妙之处:
第一,新题的答案可以自动验证。因为 q1 和 q2 各自的答案都是确定的,组合后的最终答案也是确定的——直接把 v1 的值代入 q2 计算就行。不需要任何人工标注。
第二,新题的难度显著高于原始题。模型必须先正确解出 q1 得到 v1,再把 v1 代入 q2 求解,任何一步出错最终答案就错了。这意味着即使 q1 和 q2 单独都很简单,组合后也能构成真正的挑战。
第三,这个过程可以递归。q1:2 可以继续和 q3 组合,变成 q1:2:3,也就是"组合深度"(Composition Depth)为3的题目。理论上可以无限叠加,不过论文实验中最多做到了深度3。
来看看组合后的效果有多显著:
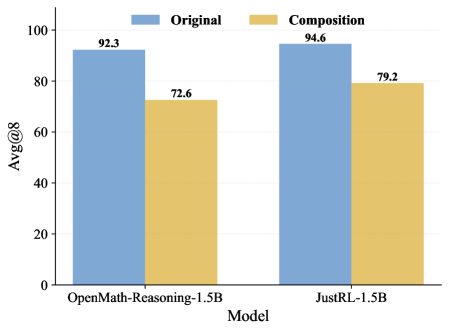
这张柱状图直观地展示了组合的威力。以 OpenMath-Reasoning-1.5B 模型为例,原始数据集中 solve_all 的比例高达 92.3%——几乎所有题都是"全对"的水题。经过 SPC 组合后(深度2),这个比例降到了 72.6%。换句话说,组合操作一下子把将近20%的"废数据"变成了有信息量的训练样本。JustRL-1.5B 上也是类似的效果,从 94.6% 降到 79.2%。
完整训练流程
有了 SPC 生成的组合数据,Composition-RL 的训练流程是这样的:
数据准备阶段:
- 拿到原始数学题数据集(论文用的是 MATH12K,12000道题)
- 对每一对题目(q1, q2),用 LLM(比如 GPT-4o)执行 SPC 三步操作,生成组合题 q1:2
- 对组合题再和新的 q3 组合,生成深度3的题目 q1:2:3
- 最终得到 Original + Depth-2 + Depth-3 三套数据集
训练阶段:
- 使用 GRPO(Group Relative Policy Optimization)算法训练。这是 DeepSeek 提出的强化学习算法,核心思想是对同一道题采样一组回答,计算每个回答在组内的相对优势来更新策略,不需要额外的 Critic 网络。
- 搭配 Dynamic Sampling:过滤掉所有回答全对(pass_rate=1)和全错(pass_rate=0)的样本,只用有区分度的样本来训练。
- 这就是 Composition-RL 的基础版本。
课程学习版本(Curriculum Learning):
- 不是一股脑把所有深度的数据混在一起训练,而是分阶段:先用 Depth-1(原始题)训练一段,再切到 Depth-2,最后上 Depth-3。
- 这就像先让学生做基础题打好底,再逐步增加难度。实验表明这种渐进式策略效果更好。
实验结果:全面碾压
论文做了非常充分的实验,覆盖了从 1.5B 到 30B 的多种模型规模。主要评测基准包括 AIME24(美国邀请赛数学竞赛,30道难题,用 pass@1 评估)、AMC(美国数学竞赛)、MATH500、Minerva Math、OlympiadBench(奥赛题)等。
主实验
以 Qwen3-4B 为例(这是个40亿参数的模型):
- 纯 RLVR 基线:Overall 平均分 28.1
- Composition-RL(用深度2的组合数据训练):Overall 31.4,提升了 3.3 个点
- Curriculum Learning(Depth 1→2→3 逐步训练):Overall 36.4,提升了 8.3 个点
在最难的 AIME24 上更夸张:RLVR 基线只有 13.7%,Curriculum Learning 达到了 37.9%——一个 4B 的小模型,在 AIME 上的准确率几乎翻了三倍。
论文特别强调,这个 4B 模型的 AIME24 成绩超过了好几个 8B 模型的最新结果。比如 Beyond-80/20-8B(34.6%)、Alpha-RL-8B(28.3%)、RL-ZVP-8B(24.6%)。一个小一倍的模型靠更好的训练数据就能超过大一倍的模型,这说明数据质量和训练策略的重要性远超单纯堆参数。
换到更大的模型,效果依然稳定。Qwen3-30B-A3B(一个30B参数的MoE模型,实际激活3B)上:
- RLVR 基线:Overall 29.2
- Composition-RL:39.7,提升 10.5 个点
多规模一致性
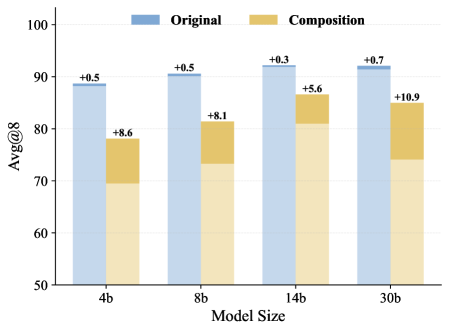
这张图把 4B、8B、14B、30B 四个规模的模型放在一起对比。蓝色条(Original RLVR)的提升幅度微乎其微(+0.3 到 +0.7),而橙色条(Composition-RL)在每个规模上都有大幅度提升(+5.6 到 +10.9)。特别是 30B 模型上提升最大,达到了 +10.9,说明这个方法对大模型同样有效,甚至效果更好。
跨域组合:1+1 > 2
论文还探索了一个有趣的方向:跨领域组合。
具体做法是把物理题和数学题拼在一起。比如 q1 是一道物理运动学题(求某个速度值),q2 是一道纯数学题(用到这个速度值作为参数)。
跨域组合的结果让人意外:
| 训练策略 | Overall |
|---|---|
| MATH12K(纯数学训练) | 28.1 |
| Physics+Math 混合训练 | 26.8 |
| 先 Physics 再 Math 顺序训练 | 29.5 |
| Physics-Math Composition | 32.6 |
直接把物理和数学数据混在一起训练,效果反而比纯数学还差(26.8 vs 28.1)。顺序训练稍微好一点(29.5)。但用 SPC 把物理题和数学题组合起来,效果直接飙到了 32.6——比纯数学训练高了 4.5 个点。
更有意思的是看雷达图。跨域组合训练出来的模型不仅在数学和物理上表现好,在工程、化学、法律等完全没训练过的领域也有提升。这说明组合训练确实培养了某种更通用的推理能力,而不仅仅是在特定领域上刷分。
消融实验:哪些设计选择是关键的?
论文做了详细的消融实验来回答几个关键问题:
组合题中哪些部分重要?
组合数据分为两个"深度层":D1(用于组合的原始题)和 D2(组合生成的新题)。实验对比了几种策略:
| D1策略 | D2策略 | Overall |
|---|---|---|
| Random采样 | Full(全部使用) | 31.4 |
| Full | Full | 30.9 |
| Random | Random | 28.0 |
最优配置是 D1 随机采样 + D2 全部使用。这说明组合生成的新题(D2)是核心价值所在,必须全部保留;而原始题(D1)反而只需要适量就够了,太多反而会稀释训练效果。
D1=Random + D2=Random 的结果(28.0)甚至还不如纯 RLVR 的部分配置,进一步证明了组合题本身才是提升的关键。
Dynamic Sampling 有多重要?
去掉 Dynamic Sampling 后,Composition-RL 的效果从 31.4 降到 30.0。虽然还是比纯 RLVR 好,但差距缩小了不少。这说明 Dynamic Sampling 和 Composition 是互补的:Composition 提供更多有难度的数据,Dynamic Sampling 确保模型只在有信息量的数据上学习。
为什么有效?两个角度的解释
论文从两个角度分析了 Composition-RL 为什么能有效提升推理能力。
角度一:组合泛化
认知科学和机器学习中都有一个概念叫"组合泛化"(Compositional Generalization)——通过重新组合已知的基本元素来理解和处理新的复杂情况。
SPC 生成的组合题天然具备这个特点。模型在解组合题时,必须灵活运用和连接不同的知识模块(比如先用数列求和的知识,再用几何面积的知识)。这种"连接不同知识模块"的练习,恰好是提升通用推理能力的关键。
这也解释了为什么跨域组合效果特别好:跨领域的知识连接迫使模型建立更抽象的推理路径,而不是只在单一领域内打转。
角度二:隐式过程监督
这是一个很深刻的发现。
传统的"过程监督"(Process Supervision)需要人工标注每一步推理的对错,成本极高。而 RLVR 只看最终答案——所谓"结果监督"(Outcome Supervision)。
但组合题有个巧妙的副作用:虽然奖励信号只看最终答案对不对,模型必须正确求解中间变量 v1 才能得到正确的最终答案。换句话说,对最终答案的验证间接地验证了中间步骤的正确性。这就是"隐式过程监督"。
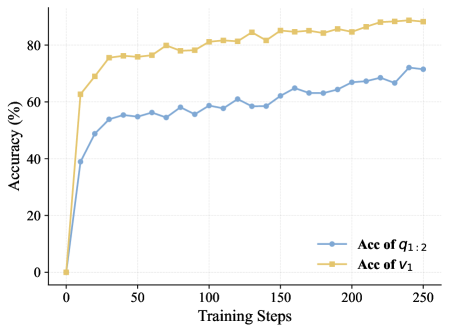
这张图提供了直接证据。黄色线是中间变量 v1 的准确率,蓝色线是组合题最终答案的准确率。可以看到:
- v1 的准确率随着训练稳步提升,从接近0升到约90%
- v1 的准确率始终高于最终答案的准确率(约90% vs 约72%)
- 两条线的走势高度一致
这意味着模型确实学会了"分步正确求解"的能力,而不是靠碰运气蒙对最终答案。虽然没有人工标注中间步骤的对错,但组合题的结构天然地提供了过程级别的学习信号。
和其他方法的关系
论文中还提到了几个相关的数据增强方向:
- 合成数据(如 s1, NuminaMath):用强模型生成新题,需要大量计算资源,且生成质量不稳定
- 难度过滤(如 Beyond 80/20 Rule):从现有数据中筛选合适难度的题目,不产生新数据
- 提示词改写(如 RL-ZVP):对现有题目做表述变换,不改变本质难度
相比之下,Composition-RL 不需要强模型生成新题内容——它只是用 LLM 做"拼接"操作(SPC 三步都是格式化的、确定性的操作),成本远低于合成数据。同时它确确实实创造了新的、更难的题目,效果远好于单纯的难度过滤和改写。
局限性
公平地说,这个方法也有一些局限:
-
依赖数值型答案:SPC 的核心机制是用 q1 的数值答案作为 v1 代入 q2,所以对证明题、开放性推理题不太适用。不过数学和科学领域的大量题目都是数值型的,适用范围其实很广。
-
组合质量不均:不是所有的题对都能组合出有意义的新题。论文中用 LLM 来执行组合操作,偶尔会产生不自然或者矛盾的题目。不过消融实验表明,即使有一定比例的低质量组合题,整体训练效果仍然是正面的。
-
深度3以上未充分探索:论文只做到了组合深度3,更深的组合是否还能带来持续收益?还是会出现边际递减?这些问题留待后续工作回答。
总结
Composition-RL 的核心贡献可以用一句话概括:用组合已有简单题的方式自动生成更难的训练题目,从而突破 RLVR 训练中数据利用率下降的瓶颈。
具体来说:
- SPC 方法:三步操作把两道题拼成一道新题,可递归叠加,答案自动可验证
- 效果显著:4B 模型超过多个 8B baseline,30B 模型提升 10+ 个点
- 跨域有效:物理+数学组合优于简单混合训练,且能泛化到未训练领域
- 理论优雅:组合泛化 + 隐式过程监督,两条理论线索互相支撑
这个工作最让人欣赏的地方在于它的简洁。没有复杂的模型架构改动,没有昂贵的数据合成流程,就是一个朴素的"把题目拼起来"的想法,配合严谨的实验验证,就取得了很好的效果。
在 RLVR 训练数据日益成为瓶颈的今天,"如何低成本地获取更多高质量训练数据"是一个核心问题。Composition-RL 提供了一个不依赖外部数据源、不需要强模型生成内容的解决路径,思路清晰且易于复现。对于正在做大模型推理能力训练的团队来说,这个方法值得认真考虑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)