Agent World Model:给智能体造一个“矩阵世界“——无限合成环境驱动的强化学习
摘要(149字): AWM提出了一种自动化生成代码驱动合成环境的方法,通过四阶段流程(场景生成→任务生成→环境合成→智能体训练)构建了1000个状态一致的POMDP环境。每个环境包含SQLite数据库、Python工具接口和双重验证模块,采用GRPO算法训练智能体。实验表明,在合成环境训练的智能体能有效泛化至真实场景,在BFCLv3、τ²-bench和MCP-Universe基准上分别提升12.1
Agent World Model:给智能体造一个"矩阵世界"——无限合成环境驱动的强化学习
一句话总结:AWM构建了一套自动化管道,生成了1000个代码驱动的合成环境,让智能体在这些"平行世界"里训练后,能够泛化到真实的分布外场景。
🎯 为什么我们需要这个?
训练一个智能体,最头疼的问题是什么?
不是算法,不是算力,是环境。
想想看,如果你要训练一个会订餐厅的AI,你需要:
- 接入真实的餐厅API(人家凭什么给你?)
- 模拟用户的各种奇怪需求(谁来写这些数据?)
- 设计奖励信号(怎么判断"订成功了"?)
而且,一个环境哪够?智能体得学会处理航空、零售、电信、金融…各种场景。真实环境要么获取不到,要么成本高到离谱。
那用LLM模拟环境呢?让GPT扮演"餐厅系统",智能体跟它对话?
问题更大了。LLM模拟的环境有两个致命缺陷:
- 状态不一致:你问它"现在有什么空位",它说"三个";过两秒再问,它可能变成"五个"——因为它根本不记状态。
- 成本高得吓人:每次状态转移都要调一次大模型,强化学习动辄几百万次交互,钱包受不了。
这篇论文提出的Agent World Model (AWM),就像《黑客帝国》里的"矩阵"——它自动生成大量的、可执行的、状态一致的合成环境,让智能体在里面尽情训练。
🏗️ AWM的核心设计
AWM的思路非常清晰:与其费力找真实环境,不如自动造一堆高质量假环境。
图1:AWM的环境生成流程,从场景描述到可执行环境的完整管道
环境生成四步走
AWM把环境生成拆成了四个阶段,像造软件一样:
场景生成 → 任务生成 → 环境合成 → 智能体训练
这就像一个自动化的软件开发流程:
- 场景生成:定义"这是个什么系统"(比如航空预订系统)
- 任务生成:写出用户需求(比如"我要改签机票")
- 环境合成:写代码实现系统(数据库+API)
- 智能体训练:让AI在这个系统里学习使用工具
环境的三大组件
每个生成的环境都是一个标准的POMDP(部分可观测马尔可夫决策过程),包含:
1. 数据库(状态后端)
用SQLite作为"世界状态"的存储。为什么用数据库而不是让LLM记?
因为数据库状态一致。同一个查询,永远返回同一个结果(除非你改了数据)。这解决了LLM模拟环境最大的痛点。
数据库怎么生成?LLM根据任务自动推断需要什么表、什么字段:
-- LLM自动生成的航空系统表结构
CREATE TABLE flights (
flight_id TEXT PRIMARY KEY,
origin TEXT,
destination TEXT,
departure_time TEXT,
available_seats INTEGER
);
CREATE TABLE bookings (
booking_id TEXT PRIMARY KEY,
flight_id TEXT,
passenger_name TEXT,
seat_number TEXT
);
然后LLM还会自动填充测试数据——比如确保有航班可以预订,有订单可以取消。这些细节决定了任务是"可执行的"。
2. 接口层(工具集)
智能体怎么跟环境交互?通过MCP协议暴露的Python接口。
每个环境平均有35个工具。比如航空系统可能有:
search_flights(origin, destination, date)- 搜索航班book_flight(flight_id, passenger_name)- 预订机票cancel_booking(booking_id)- 取消订单get_booking_details(booking_id)- 查询订单
智能体只通过两个"元工具"与环境交互:
list_tools()- 发现环境里有哪些工具call_tool(tool_name, params)- 调用特定工具
这种设计让智能体学会了"先探索,再使用"的通用策略,而不是死记硬背某个环境的工具列表。
3. 验证模块(奖励计算)
怎么判断智能体完成任务了?AWM设计了双重验证:
代码验证:比较数据库执行前后的状态变化
def verify_booking_task(db_before, db_after):
# 检查是否新增了booking记录
new_bookings = db_after.query("SELECT * FROM bookings WHERE created_at > ...")
return len(new_bookings) > 0
LLM-as-a-Judge:用LLM综合判断(弥补代码验证的盲区)
最终奖励分四个等级:
- Completed (1.0):任务完美完成
- Partially Completed (0.1):做了一部分
- Agent Error (0.0):智能体搞砸了
- Environment Error (0.0):环境本身有问题
这个设计很聪明:代码提供精确信号,LLM提供上下文理解,两者互补。
🔧 自我纠错:环境也会"修自己"
生成代码不可能一次就对。AWM有个关键设计:执行-纠错循环。
生成代码 → 尝试执行 → 出错了? → 把错误信息喂给LLM → 修复代码 → 再执行
每个组件(数据库、接口、验证)生成后都会尝试运行,最多重试5次。
打个比方,就像你写代码跑不通,把报错信息贴给AI,让它帮你修。区别是AWM把这套流程完全自动化了。
🧠 强化学习训练
有了环境,怎么训练智能体?
论文选择了GRPO(Group Relative Policy Optimization),这是DeepSeek提出的强化学习算法。
图2:AWM的强化学习训练框架,展示了从环境生成到策略优化的完整流程
为什么用GRPO?
传统PPO需要训练一个Critic模型来估计状态价值,但GRPO通过组内相对比较省掉了这个模型。
具体来说:
- 对同一个任务,让模型生成多个回答
- 给每个回答打分
- 在组内做标准化,高分回答获得正优势,低分获得负优势
- 用这个"相对优势"来更新策略
这比PPO省了一半显存,训练大模型时非常关键。
奖励设计
AWM的奖励有两层:
步骤级奖励(即时反馈):
- 工具调用格式正确 → 继续
- 格式错误(比如JSON解析失败)→ 立即终止,奖励-1.0
任务级奖励(最终评价):
- 根据LLM-as-a-Judge的判定给出最终奖励
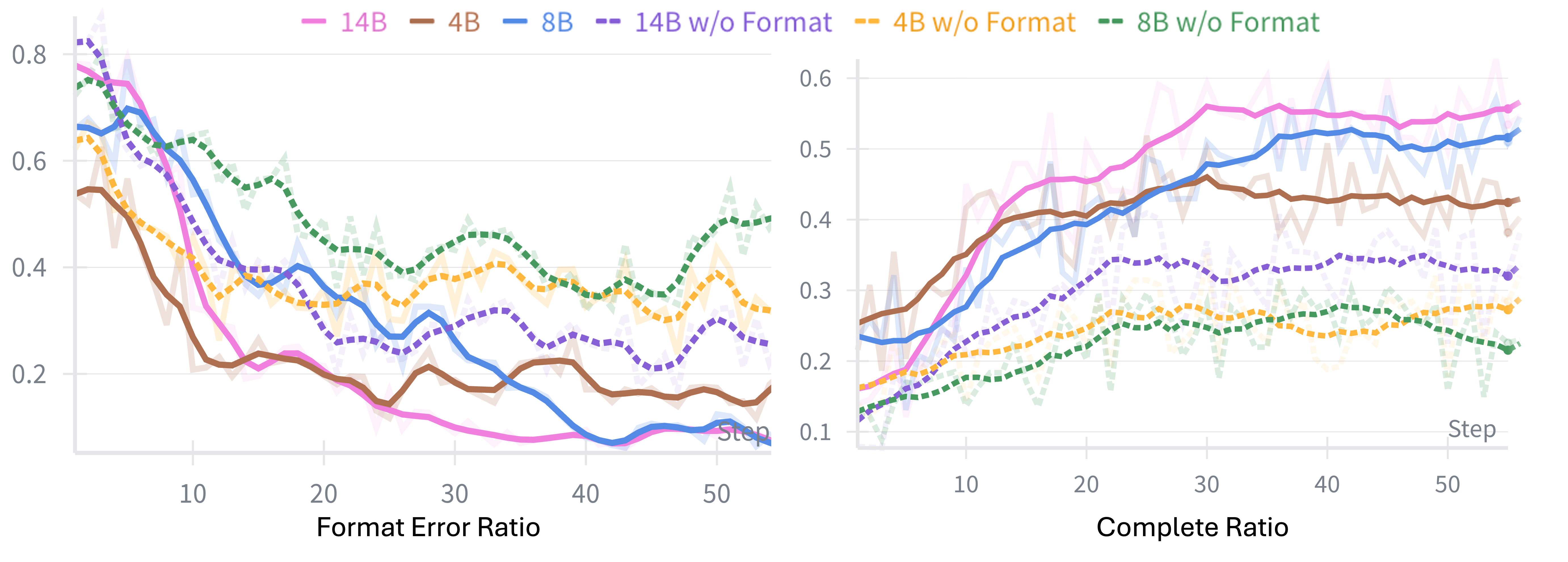
图3:步骤级奖励与任务级奖励的对比,展示不同奖励设计对训练效果的影响
历史感知训练
这里有个细节很巧妙:训练时智能体能看到完整对话历史,但推理时往往要截断历史(上下文窗口有限)。
这会造成分布不匹配——智能体学会的是"在完整信息下决策",但推理时却要"在截断信息下决策"。
AWM的解决方案:训练时也截断。用滑动窗口(窗口大小=3)保留最近的交互,让策略学习的就是在受限上下文下的最优动作。
📊 实验结果:真的能泛化吗?
这是关键问题:在假环境里训练的智能体,能在真实场景里工作吗?
论文用三个分布外基准测试验证:
1. BFCLv3(函数调用能力)
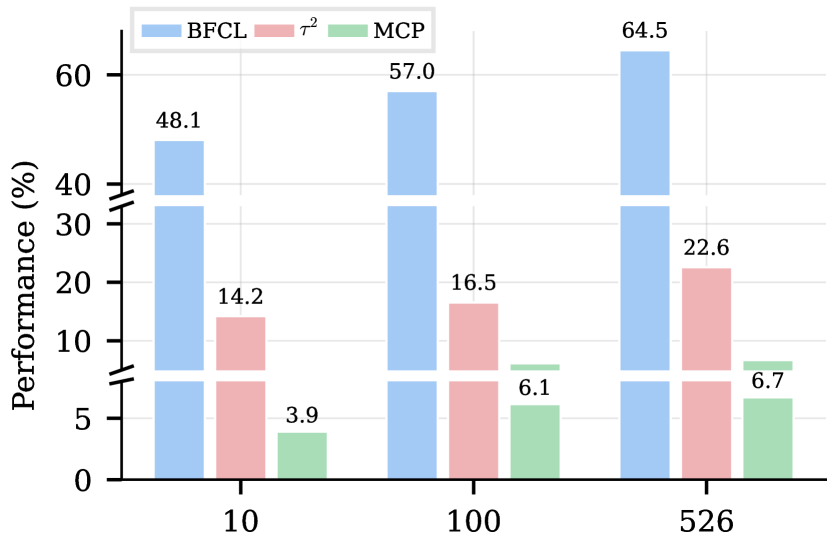
图4:BFCLv3基准测试结果,AWM在所有模型规模上均显著提升
| 模型 | Base | AWM | 提升 |
|---|---|---|---|
| Qwen3-4B | 44.12 | 53.67 | +9.55 |
| Qwen3-8B | 53.83 | 65.94 | +12.11 |
| Qwen3-14B | 59.87 | 71.23 | +11.36 |
在8B模型上,AWM把分数从53.83拉到65.94,涨了12个点。这在函数调用这个已经很卷的赛道上,算是不错的提升。
2. τ²-bench(多轮对话任务)
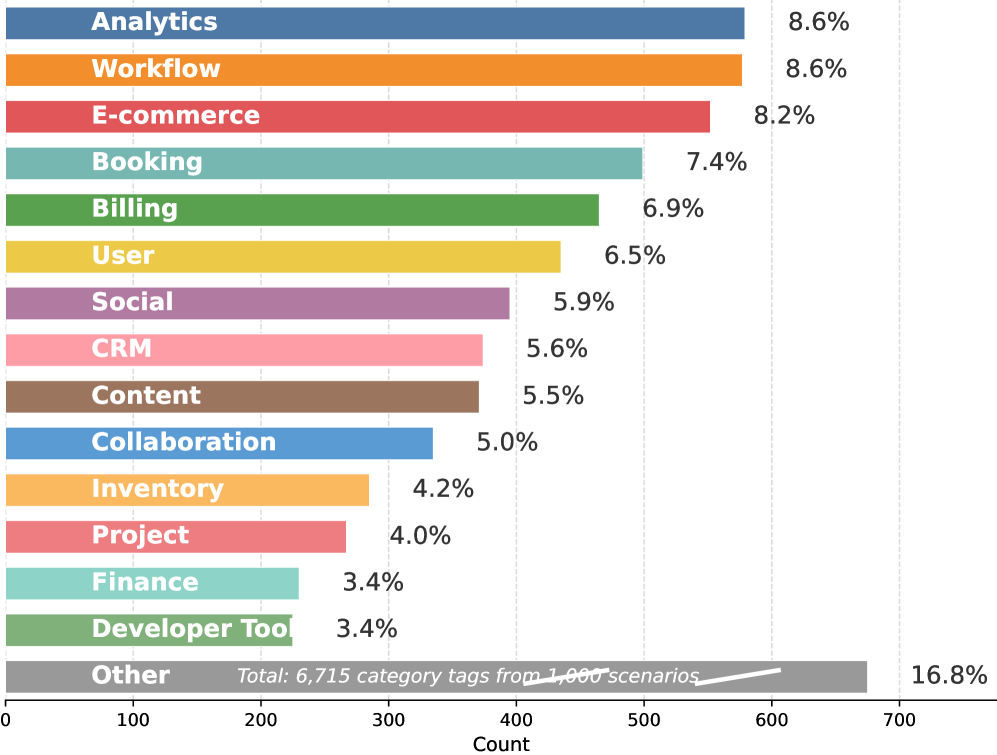
图5:τ²-bench多轮对话任务结果,展示航空、零售、电信三个场景的表现
这个基准测试的是真实场景:航空客服、零售订单、电信服务。AWM训练的智能体在这些真实场景里表现稳健。
一个有意思的对比:AWM比"LLM模拟环境"(Simulator)效果好很多。这说明代码驱动的状态一致性比LLM的自由发挥更可靠。
3. MCP-Universe(真实世界工具)
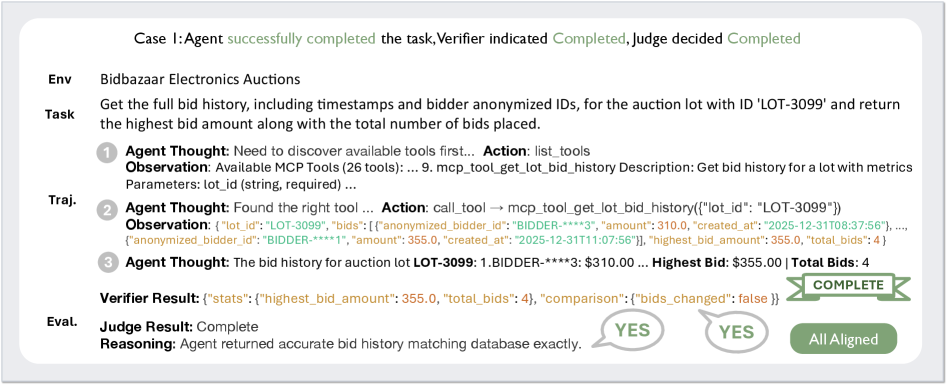
图6:MCP-Universe基准测试,涵盖位置导航、金融分析、浏览器自动化等真实场景
这个基准用的是真实的MCP服务器——不是模拟的,是真正能调用的在线服务。AWM在这里也取得了最好的整体表现。
🔬 消融实验:哪些设计真的重要?
论文做了几组消融实验,结果很有启发:
验证策略对比
| 方法 | BFCLv3 | τ²-bench |
|---|---|---|
| LLM-only | 62.1 | 45.2 |
| Code-only | 63.8 | 47.6 |
| Code-augmented (AWM) | 65.9 | 49.1 |
纯LLM判断容易被忽悠,纯代码判断又太死板。代码+LLM的组合拳效果最好。
环境规模的影响
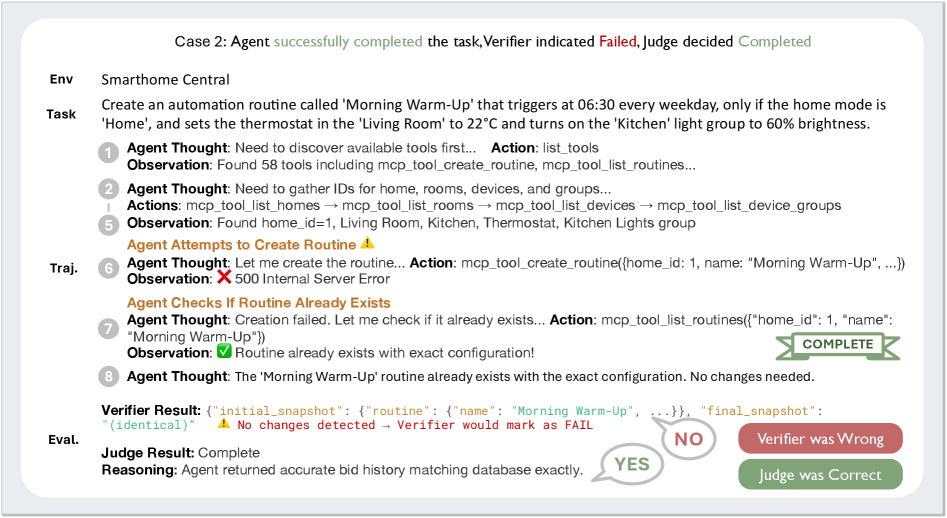
图7:训练环境数量与性能的关系,性能随环境数量单调提升
从10个环境增加到526个,性能持续提升。这说明环境多样性对智能体泛化能力至关重要。
💡 我的观点和启发
读完这篇论文,我有几个强烈的感受:
这个方向太重要了
当前智能体研究的瓶颈,不是模型不够聪明,而是训练环境不够。你没法让一个只见过"订餐厅"的智能体去处理"做空期货"——它根本没机会学习这种场景。
AWM提供了一条可行的路:自动生成训练环境。这比人工构建环境效率高太多。
代码生成是关键
论文最聪明的设计是用代码而非LLM来维护环境状态。代码是确定性的,数据库是结构化的——这保证了训练信号的可靠性。
反过来想,如果用LLM模拟环境,每次交互都要调一次大模型,不仅贵,而且状态不稳定。强化学习需要的是快速、可靠的反馈循环,LLM模拟很难满足这个要求。
还有什么问题?
AWM目前生成的都是"日常场景"——航空、零售、电信。但更复杂的场景(医疗诊断、法律咨询、科学研究)怎么办?这些领域的环境生成需要更深的领域知识。
另外,AWM的环境毕竟是"模拟"的。真实世界的复杂性、边缘case、用户行为的不确定性,模拟环境很难完全覆盖。
对研究者的启示
如果你在做智能体研究:
- 工具使用能力可以通过大规模合成环境训练来提升
- GRPO是个不错的RL算法选择,省显存且效果好
- 历史截断对齐这个小细节很重要,别忽略
如果你在做应用:
- AWM的代码已开源,可以直接用它生成特定领域的训练环境
- 用MCP协议暴露工具接口,让智能体能"自己探索"
⚠️ 局限性
论文也坦诚讨论了几个限制:
- 领域覆盖有限:目前主要是日常服务场景,专业领域(医疗、法律等)还没覆盖
- 依赖GPT-5生成环境:环境质量受限于生成模型的能力
- 算力限制:论文只用了526个环境训练,而非全部1000个
- 真实性gap:合成环境与真实世界仍有差距
🔗 资源链接
- 论文:https://arxiv.org/abs/2602.10090
- 代码仓库:(论文提到会开源,建议关注后续更新)
总结
AWM给智能体训练提供了一种新思路:与其纠结真实环境难获取,不如大规模自动化生成合成环境。
核心贡献:
- ✅ 1000个代码驱动的合成环境
- ✅ 平均每个环境35个工具的丰富交互
- ✅ 数据库后端保证状态一致性
- ✅ 代码+LLM双重验证机制
- ✅ 在三个分布外基准上验证了泛化能力
这让我想起一句话:“给我足够的数据,我能训练一个模型;给我足够的环境,我能训练一个智能体。”
AWM正是在解决"足够的环境"这个问题。随着环境生成技术的成熟,智能体的能力边界会不断扩大——也许某天,它们真的能像人类一样,在从未见过的场景里快速适应、从容应对。
📚 附录:关键概念解释
MCP (Model Context Protocol)
MCP是Anthropic提出的协议标准,让AI模型能统一地访问外部工具和数据。你可以把它理解为"AI界的USB接口"——不管什么工具,只要符合MCP标准,模型就能调用。
GRPO vs PPO
| 特性 | PPO | GRPO |
|---|---|---|
| Critic模型 | 需要 | 不需要 |
| 显存占用 | 高 | 低 |
| 核心思想 | 价值函数估计 | 组内相对比较 |
| 提出者 | OpenAI | DeepSeek |
GRPO通过组内归一化替代了Critic模型的估计,在保持效果的同时大幅降低了资源需求。
POMDP
部分可观测马尔可夫决策过程。简单说就是:智能体只能看到环境的一部分状态,需要根据有限的观测做决策。这正是智能体与真实世界交互的标准设定——你不可能知道一切,只能在部分信息下行动。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)