SkillRL:让AI智能体学会“练功升级“的递归技能强化学习框架
SkillRL框架摘要 SkillRL提出了一种递归技能增强的强化学习方法,通过将原始交互轨迹蒸馏为可复用的技能卡片(10-20倍压缩率),构建分层技能库(通用+特定任务技能),并与GRPO强化学习协同进化。在ALFWorld和WebShop任务中,该方法超越GPT-4o达41.9%,关键创新在于:(1) 教师模型差异化处理成功/失败轨迹生成技能;(2) 冷启动SFT教会模型使用技能;(3) 训练
SkillRL:让AI智能体学会"练功升级"的递归技能强化学习框架
- 📖 论文:SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
- 🔗 链接:https://arxiv.org/abs/2602.08234v1
- 👥 作者:Peng Xia, Jianwen Chen, Hanyang Wang 等(UNC Chapel Hill & NEC Labs)
- 📅 日期:2026年2月
- 💻 代码:https://github.com/aiming-lab/SkillRL
一句话总结:SkillRL 把智能体与环境交互产生的冗长轨迹蒸馏成紧凑、可复用的"技能卡片",并在强化学习训练过程中让技能库与策略共同进化,在 ALFWorld 和 WebShop 上超越 GPT-4o 达 41.9%。
🎯 这篇论文在解决什么问题?
想象一下:你刚入职一家餐厅做厨师。第一天,你手忙脚乱地完成了一道红烧肉——中间翻了三次锅、调料加错了一次又补救回来、最后忘记收汁又重新加热。如果有人让你明天再做一道红烧排骨,你会怎么做?把今天每一个手忙脚乱的动作原封不动地"回放"一遍?当然不会。你会提炼出几条经验:“先大火煸炒上色,再小火慢炖”、“调料比例大约是酱油2:糖1:料酒1”——这就是技能。
当前的 LLM 智能体恰恰面临这个尴尬处境。它们能在网页购物、家庭机器人控制等复杂任务中与环境交互,但每次交互都是"从头开始"。已有的记忆增强方法(如 Reflexion、ExpeL、MemRL)尝试解决这个问题,但做法大多是把原始交互轨迹直接扔进记忆库——相当于把你做红烧肉时的每一个手忙脚乱的动作都录下来存档。这些轨迹又长又吵,充满了探索性的无用动作和回溯,严重浪费上下文窗口。
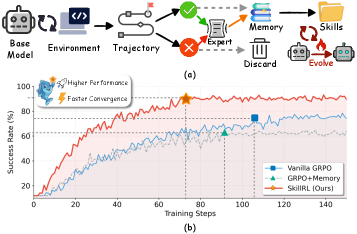
图1:左图(a)对比了传统记忆方法和 SkillRL 的处理流程。传统方法直接存储冗长的原始轨迹作为记忆;SkillRL 则将轨迹蒸馏成紧凑的技能描述。右图(b)展示了训练收敛曲线,SkillRL(蓝色)比普通 GRPO(绿色)和 GRPO+Memory(红色)收敛更快且最终性能更高。
SkillRL 的核心观点直截了当:有效的经验迁移需要抽象,而不是复制粘贴。 人类专家不会记住每个情境下的每一步操作,而是把经验凝练成可复用的技能。SkillRL 就是要让智能体也学会这一点。
🧠 技术背景:你需要知道的前置知识
GRPO:不需要评论家的强化学习
SkillRL 的强化学习骨架是 GRPO(Group Relative Policy Optimization),来自 DeepSeek。传统的 PPO 需要训练一个独立的 critic 网络来估计状态价值函数,而 GRPO 的做法更"接地气":对同一个问题采样一组回答,然后用组内的相对排名来计算优势值。
打个比方:PPO 像是考试后请一个阅卷老师逐题打分(critic),而 GRPO 像是把全班的卷子放在一起排名——你只需要知道自己在这批人里是高是低,不需要知道绝对分数。这省去了训练 critic 的额外开销,同时效果不输 PPO。
GRPO 的核心目标函数:
JGRPO(θ)=Ex,{yi}[1G∑i=1Gmin(riAi,clip(ri,1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref)]\mathcal{J}_{\text{GRPO}}(\theta)=\mathbb{E}_{x,\{y_i\}}\Bigg[\frac{1}{G}\sum_{i=1}^{G}\min\Big(r_i A_i, \text{clip}(r_i,1-\epsilon,1+\epsilon)A_i\Big)-\beta D_{\text{KL}}(\pi_\theta\|\pi_\text{ref})\Bigg]JGRPO(θ)=Ex,{yi}[G1i=1∑Gmin(riAi,clip(ri,1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref)]
其中优势值 Ai=Ri−mean({Rj})std({Rj})A_i = \frac{R_i - \text{mean}(\{R_j\})}{\text{std}(\{R_j\})}Ai=std({Rj})Ri−mean({Rj}) 就是一个简单的 z-score 归一化——你的奖励减去组内均值,再除以标准差。
ALFWorld 和 WebShop:两个经典的智能体评测场
ALFWorld 是一个文本交互版的家庭场景模拟器,与 ALFRED 具身 AI 基准对齐。智能体需要通过文字指令控制一个虚拟管家完成各种家务——“把苹果加热后放到桌上”、"用水壶清洗杯子"之类的。任务类型包括加热(Heat)、冷却(Cool)、拾取(Pick)、查看(Look)、清洁(Clean)等,涉及物体定位、前置条件验证、多步规划。
WebShop 模拟真实的网购场景。智能体要在一个含有 120 万件商品的网站上,根据用户的自然语言需求(“我要一双10码的黑色防滑工作鞋,价格低于50美元”)搜索、浏览、比较、最终下单。这考验的是搜索策略、信息提取和约束满足能力。
已有的记忆/经验方法:Reflexion、ExpeL 和 MemRL
- Reflexion:在每次失败后让模型自我反思生成文字形式的反馈,下次尝试时把反馈附加到 prompt 里。问题是反馈越积越多,上下文窗口吃不消。
- ExpeL:从成功和失败的轨迹中提取"经验"规则存入数据库,推理时检索相关经验。但它只在推理阶段做基于 prompt 的利用,没有与 RL 训练结合。
- MemRL / EvolveR:把记忆系统和 RL 训练挂钩——MemRL 在训练中动态压缩和更新记忆,EvolveR 在线地进化记忆库。但它们存的仍然是比较原始的轨迹片段或经验条目,抽象层次不够高。
🏗️ SkillRL 的方法:三步走构建技能进化体系
SkillRL 的整体架构如图2所示,分为三个核心模块:经验蒸馏、分层技能库构建、递归技能进化。
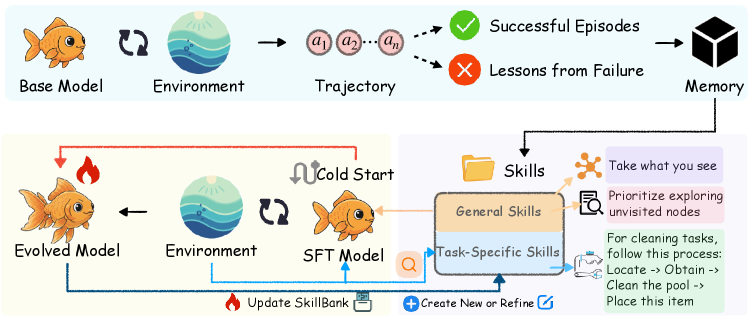
图2:SkillRL 框架全景。从左到右:(1) 智能体在环境中收集成功/失败轨迹;(2) 通过教师模型蒸馏成技能存入 SkillBank;(3) 冷启动 SFT 教会基础模型如何使用技能;(4) RL 训练过程中技能库与策略共同进化,失败轨迹持续反馈给技能蒸馏模块生成新技能。
第一步:经验蒸馏——从"流水账"到"秘籍"
做菜新手可能会写一整页的做菜日记,但老师傅只需要几句口诀。SkillRL 的经验蒸馏做的就是这个事。
具体流程:先让基础 LLM 智能体在目标环境里跑一批任务,收集成功轨迹 T+\mathcal{T}^+T+ 和失败轨迹 T−\mathcal{T}^-T−。注意,失败轨迹也要保留——这和只学习成功案例的方法不同。然后用一个"教师模型"(OpenAI o3)对这两类轨迹做差异化处理:
对于成功轨迹,提取其中的关键决策模式:哪些步骤是决定性的?背后的推理逻辑是什么?这些模式能否推广到类似任务?
对于失败轨迹,由于原始轨迹又长又嘈杂,直接存入上下文效果很差。SkillRL 让教师模型做"失败复盘":(1) 哪里出了错?(2) 错误的推理或动作是什么?(3) 应该怎么做?(4) 能总结出什么防止类似错误的一般原则?
这种差异化处理很关键。成功经验告诉你"应该怎么做",失败经验告诉你"不应该怎么做"和"踩坑后如何爬出来"——两者结合才是完整的技能。
第二步:分层技能库 SkillBank——通用原则 + 专项技巧
蒸馏出来的技能怎么组织?SkillRL 设计了一个两层结构的技能库:
通用技能 Sg\mathcal{S}_gSg:适用于所有任务类型的战略性原则。比如:
- “系统探索:优先搜索未访问过的位置,避免重复”
- “动作前完整性检查:执行操作前确认前置条件是否满足”
- “进度追踪:维护任务进度计数器,只在确认完成后才终止”
特定任务技能 Sk\mathcal{S}_kSk:针对某一类任务的专门知识。比如在 ALFWorld 的加热任务中:“拿起物体后立即使用最近的加热设备(微波炉),不要先放下再去找”;在 WebShop 中:“搜索时优先包含产品类型和1-2个核心属性关键词,省略次要描述词”。
每个技能的结构很简洁:一个名称、一段原则描述、一个 when_to_apply 适用条件。这种"卡片式"组织让检索变得高效。
技能检索的机制也很直观:通用技能始终包含在上下文中作为"基础功";特定任务技能则通过语义相似度检索,给定任务描述 ddd,计算它与每个技能的 embedding 相似度,取 TopK 且超过阈值 δ\deltaδ 的:
Sret=TopK({s∈Sk:sim(ed,es)>δ},K)\mathcal{S}_\text{ret}=\text{TopK}\left(\{s\in\mathcal{S}_k:\text{sim}(e_d,e_s)>\delta\},K\right)Sret=TopK({s∈Sk:sim(ed,es)>δ},K)
关键数字:这种技能蒸馏实现了比原始轨迹 10-20倍的 token 压缩。一条原始轨迹可能有上千个 token,蒸馏后的技能描述只有几十到一百多个 token,但信息密度反而更高。
第三步:递归技能进化——技能库是活的
静态的技能库有个致命问题:它只能覆盖初始收集阶段遇到的场景。随着 RL 训练推进,智能体的策略越来越强,会探索到新的状态空间,遇到以前没见过的困难情况——原有的技能库可能"罩不住"了。
SkillRL 的解决方案是让技能库在 RL 训练过程中持续进化。
冷启动 SFT:一个容易被忽视但至关重要的步骤。基础模型并不知道怎么"用"技能——你给它一堆技能描述,它可能完全无视。所以在 RL 训练前,先用教师模型生成一批"技能增强推理轨迹"作为示范,展示怎样在决策过程中检索、解释和应用技能。基础模型在这些示范上做一轮 SFT,学会"读懂并使用技能"。这个微调后的模型 πθsft\pi_{\theta_\text{sft}}πθsft 既是 RL 训练的起点,也是 KL 散度正则化的参考策略。
递归进化循环:在每个验证 epoch 之后,SkillRL 检查每个任务类别的成功率。对于成功率低于阈值 δ\deltaδ 的类别,收集其失败轨迹,然后让教师模型分析这些轨迹:(1) 现有技能没覆盖到哪些失败模式?(2) 需要新增什么技能?(3) 哪些现有技能被证明无效需要改进?生成的新技能加入库中:SkillBank←SkillBank∪Snew\text{SkillBank} \leftarrow \text{SkillBank} \cup \mathcal{S}_\text{new}SkillBank←SkillBank∪Snew。
这就形成了一个良性循环——智能体变强 → 遇到更难的挑战 → 催生新技能 → 新技能帮助应对挑战 → 智能体进一步变强。有点像游戏里的"打怪升级":低级副本积攒的技能帮你通过中级副本,中级副本又让你学到更高级的技能。
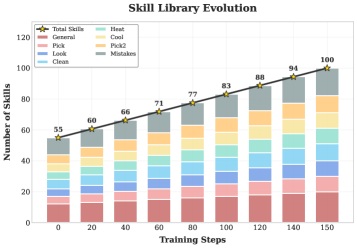
图3:技能库在训练过程中的增长轨迹(ALFWorld)。横轴是训练步数,纵轴是技能数量,不同颜色代表不同任务类别(Heat、Cool、Pick、Look、Clean等)。初始库包含55个技能(12个通用+43个特定任务),经过150步训练后增长到100个技能。增长不是均匀的——在不同训练阶段,不同类别的技能按需增长。
RL 训练:GRPO + 技能增强
最终的策略优化使用 GRPO。每个任务先检索相关技能,再从当前策略采样 GGG 条完整轨迹,每条轨迹得到二元奖励(成功为1,失败为0)。通过组内相对排名计算优势值,用裁剪目标函数更新策略。KL 惩罚锚定在冷启动 SFT 后的参考策略上,防止 RL 过程中"忘记"怎么使用技能。
🧪 实验结果:数据说话
主战场:ALFWorld 和 WebShop
| 方法 | 类型 | ALFWorld | WebShop |
|---|---|---|---|
| GPT-4o | 闭源LLM | 48.0 | 64.5 |
| Gemini-2.5-Pro | 闭源LLM | 60.3 | 60.4 |
| ReAct (Qwen2.5-7B) | Prompt方法 | 17.6 | 47.1 |
| Reflexion (Qwen2.5-7B) | 记忆方法 | 21.6 | 49.1 |
| ExpeL (Qwen2.5-7B) | 记忆方法 | 37.8 | 52.2 |
| GRPO (Qwen2.5-7B) | RL方法 | 77.6 | 69.1 |
| EvolveR (Qwen2.5-7B) | 记忆+RL | 74.6 | 65.1 |
| MemRL (Qwen2.5-7B) | 记忆+RL | 78.4 | 68.2 |
| SimpleMem+GRPO (Qwen2.5-7B) | 记忆+RL | 82.1 | 65.2 |
| SkillRL (Qwen2.5-7B) | 技能+RL | 89.9 | 72.7 |
表1:ALFWorld 和 WebShop 上的主要结果(成功率%)。SkillRL 以 7B 参数模型超越所有基线,包括 GPT-4o。
几个关键发现:
7B 碾压 GPT-4o:SkillRL 用 Qwen2.5-7B 在 ALFWorld 上达到 89.9%,比 GPT-4o 的 48.0% 高了 41.9 个百分点。这不是一个小差距——几乎是翻倍。一个 7B 的小模型通过技能增强 RL 训练后,在特定任务上把万亿参数级别的闭源模型远远甩在身后。这再次说明:在垂直领域,精调后的小模型完全可以打败通用大模型。
SkillRL vs 纯 GRPO:在 ALFWorld 上,SkillRL(89.9%)比纯 GRPO(77.6%)高出 12.3 个百分点。这 12.3% 的增量就是"技能"带来的纯增益。相当于你从一个只会蛮力尝试的新手,变成了一个手里有攻略手册的老玩家。
SkillRL vs 记忆增强 RL:和最强的记忆增强基线 SimpleMem+GRPO(82.1%)相比,SkillRL 仍然高出 7.8 个百分点。这说明"技能抽象"确实比"存储记忆"更有效。
搜索增强 QA:泛化能力检验
| 方法 | NQ | TriviaQA | PopQA | HotpotQA | 2Wiki | MuSiQue | Bamboogle | 平均 |
|---|---|---|---|---|---|---|---|---|
| Search-R1 | 39.3 | 56.4 | 38.5 | 35.8 | 29.2 | 17.2 | 53.3 | 38.5 |
| EvolveR | 43.3 | 57.6 | 42.1 | 45.7 | 32.1 | 20.8 | 60.0 | 43.1 |
| SkillRL | 49.3 | 62.6 | 42.2 | 49.6 | 35.3 | 22.3 | 68.9 | 47.1 |
表2:七个搜索增强 QA 任务上的结果(准确率%)。SkillRL 在所有数据集上均达到最优,平均分 47.1% 显著超过 EvolveR (43.1%) 和 Search-R1 (38.5%)。
值得关注的是多跳 QA 的提升——HotpotQA 上 SkillRL(49.6%)比 EvolveR(45.7%)高 3.9 个百分点,Bamboogle 上更是高出 8.9 个百分点。多跳推理需要更强的规划能力,而 SkillRL 的通用技能恰好提供了这种"元策略"级别的指导。
消融实验:每个组件都不可少
| 配置 | ALFWorld |
|---|---|
| SkillRL (Full) | 89.9 |
| − 分层结构(只用特定任务技能) | 85.8 |
| − 分层结构(只用通用技能) | 84.3 |
| − 冷启动 SFT | 80.6 |
| − 动态进化(静态技能库) | 84.4 |
| − 技能蒸馏(用原始轨迹替代) | 78.4 |
表3:消融实验结果。每个组件的移除都导致性能下降,其中用原始轨迹替代技能蒸馏带来最大跌幅(-11.5%),直接验证了"抽象优于记忆"的核心假设。
消融实验揭示了几个有意思的发现:
技能蒸馏是核心中的核心。去掉蒸馏、改用原始轨迹后,性能从 89.9% 暴跌到 78.4%——基本回到了纯 GRPO 的水平。这直接证明了:不是"有记忆"就行,关键是记忆的形式。原始轨迹太长太吵,模型根本无法从中提取有用信息。
冷启动 SFT 的贡献出人意料地大。去掉冷启动后掉了 9.3 个百分点(89.9% → 80.6%)。这说明"教会模型如何使用技能"本身就是一个非平凡的问题。你可以给学生一本很好的参考书,但如果不教他怎么查阅和使用,效果会大打折扣。
动态进化 vs 静态技能库:移除动态进化掉了 5.5 个百分点。这验证了技能库需要"与时俱进"——随着智能体变强,面临的挑战也在变化,技能库需要跟上。
通用技能和特定任务技能缺一不可。只用特定任务技能(85.8%)比只用通用技能(84.3%)稍好,但都不如两者结合(89.9%)。通用技能提供"内功心法",特定任务技能提供"招式套路",二者相辅相成。
上下文效率:更少的 token,更好的效果
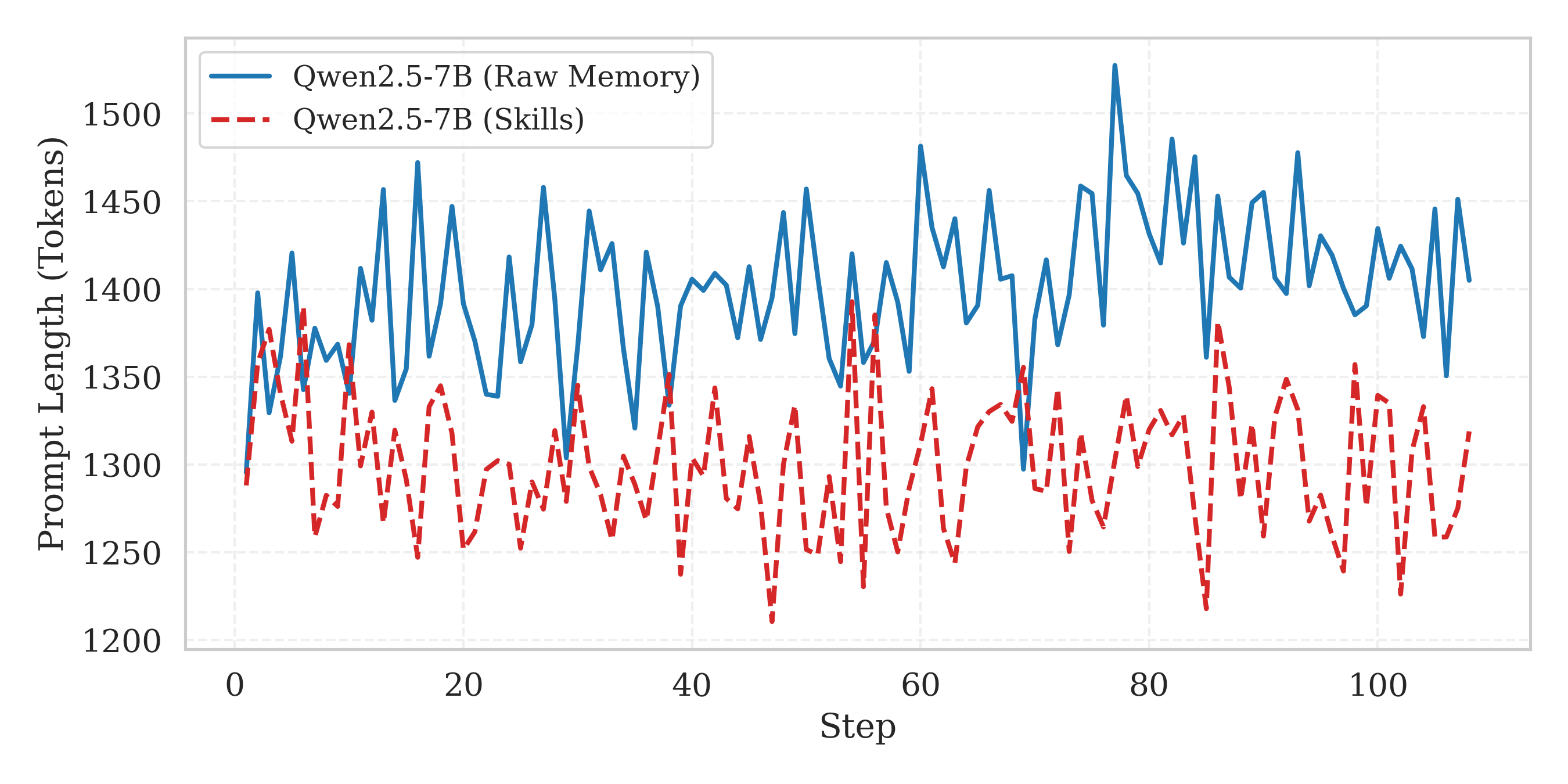
图4:SkillRL(Skills)与原始记忆方法(Raw Memory)在训练过程中的提示长度对比。横轴为训练步数,纵轴为 prompt token 数。Skills 的 prompt 长度不仅更短(约1250-1350 tokens vs 1350-1450 tokens),方差也更小,说明技能描述比原始轨迹更稳定。
SkillRL 的提示长度平均比原始记忆方法短约 10.3%,而且方差更小。这意味着:(1) 技能描述的长度更可控,不会像原始轨迹那样有的很短有的很长;(2) 省出来的上下文窗口可以留给实际的推理过程。
收敛速度:技能进化加速学习
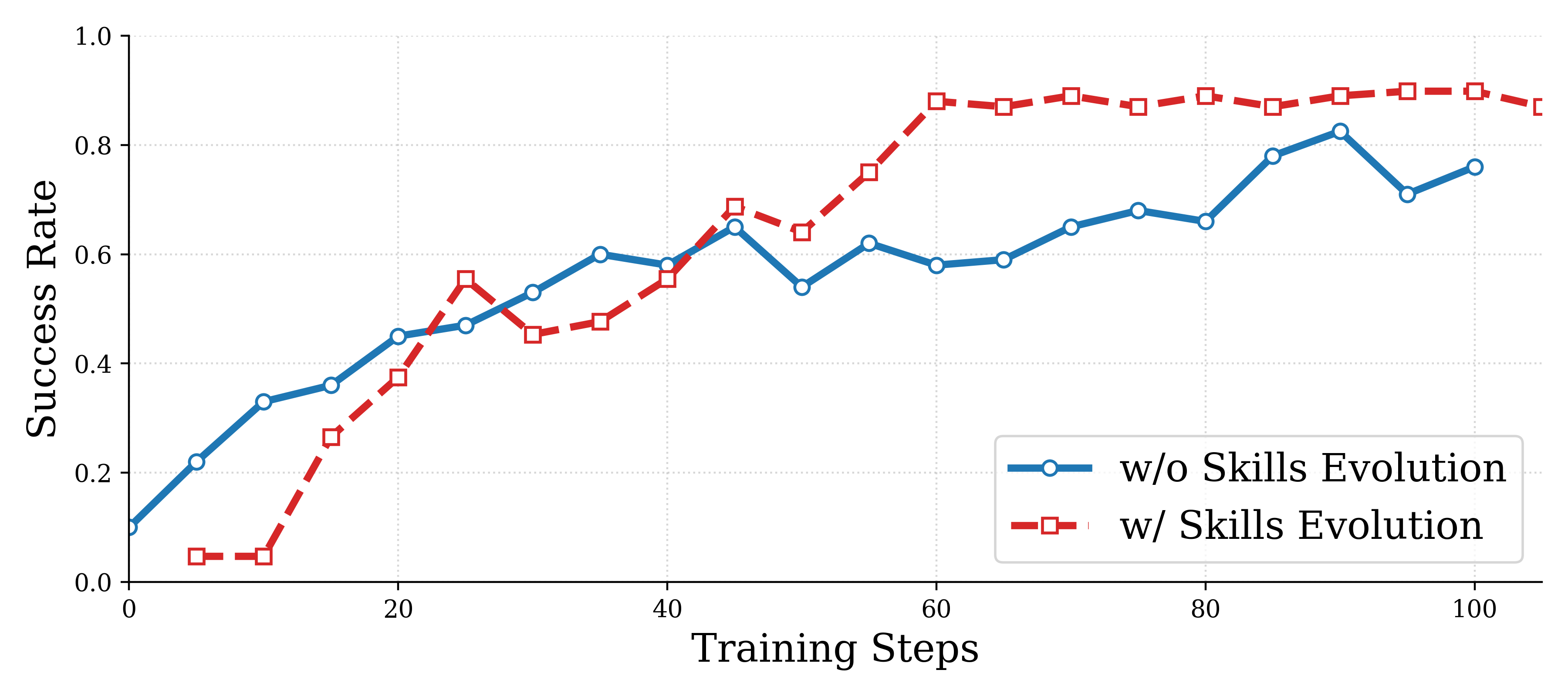
图5:带技能进化(蓝色)vs 不带技能进化(橙色)的 RL 训练曲线。带技能进化的版本在第60步左右就达到约90%的成功率并趋于稳定;不带技能进化的版本到第100步才达到约75%,且仍在缓慢爬升。技能进化不仅提高了最终性能上限,还将收敛速度提升了约 40%。
这张图非常直观地展示了递归技能进化的价值。两条曲线的差距在训练中期最为明显——大约在第40-60步时,带进化的版本已经拉开了近15个百分点的差距。这说明新生成的技能在训练的"瓶颈期"发挥了关键作用,帮助智能体突破性能平台期。
📊 案例分析:技能是怎么被用起来的

图6:两个具体案例展示了 SkillRL 如何在实际任务中检索和应用技能。左侧 WebShop 案例:购买衬衫时,智能体检索到"优先核心关键词"技能,在搜索时只保留了"men’s button-down shirt blue"等关键属性。右侧 ALFWorld 案例:加热鸡蛋时,智能体检索到"拿到物体后立刻使用最近的加热设备"技能,拿到鸡蛋后直接找微波炉加热,而不是先放下再去找加热工具。
附录中给出的技能库示例很有参考价值。比如 ALFWorld 中的一个通用技能:
gen_001 系统探索:在重访之前搜索每个合理的表面或容器一次;优先考虑看不见的位置。
何时应用:在定位物体的探索阶段。
还有一个从失败中学到的技能:
gen_015 动作前完整性检查:在执行可能合法失败的操作命令之前,确认先决条件——手是否空闲、容器容量是否充足、设备是否通电。
何时应用:在任何涉及物体交互的步骤前。
WebShop 中也有类似的例子:
err_004 价格变化疏忽:在选择特定尺寸或颜色变体后,未能注意到价格变化导致超出预算。
何时应用:选择产品变体后、确认购买前。
这些技能读起来就像资深玩家写的攻略帖——它们不是空洞的教条,而是非常具体、可操作的指南。
💡 我的思考与工程洞察
观点一:技能蒸馏的本质是"知识压缩+结构化"
SkillRL 的技能蒸馏,本质上在做两件事:压缩和结构化。原始轨迹可能有几千个 token,蒸馏后变成几十个 token——这是压缩。同时,从无结构的动作序列变成了有"名称-原则-适用条件"结构的技能卡片——这是结构化。
这让我联想到知识管理领域的一个经典观点:知识的价值不在于存储量,而在于可检索性和可复用性。 你的笔记 app 里存了一万条笔记,但如果找不到、用不上,那和没存一样。SkillRL 的 SkillBank 设计(结构化描述 + 语义检索)恰好解决了这两个问题。
从工程角度看,这种设计对实际的 Agent 系统很有启发。如果你在做一个要持续与环境交互的 Agent,与其把所有交互日志塞进向量数据库,不如定期用一个强模型把日志"蒸馏"成结构化的经验卡片。检索效率和质量都会好得多。
观点二:冷启动 SFT 是被严重低估的环节
消融实验中,冷启动 SFT 的去除导致了 9.3% 的性能下降。这个数字背后隐藏着一个深层问题:模型不会天然地使用外部知识。
很多做 RAG 系统的工程师可能都有过这种经历:明明检索到了正确的文档,但模型就是"视而不见",回答的时候完全忽略了检索结果。SkillRL 的冷启动 SFT 本质上是在解决同样的问题——通过示范数据教会模型"怎么读技能、怎么把技能融入推理过程"。
我觉得这对 RAG 系统的设计也有参考意义:不要假设模型天生知道怎么使用检索到的信息,可能需要一个专门的训练阶段来"教"模型如何利用外部知识源。
观点三:递归进化机制的上限在哪里?
论文中技能库从55个增长到100个,训练只跑了150步。一个自然的问题是:如果训练更久,技能库会无限膨胀吗?技能之间会出现冲突吗?
从图3来看,技能增长的速度在后期明显放缓,说明系统有一定的自我调节能力——当大部分失败模式都被覆盖后,新技能产生的速度自然下降。但论文没有讨论技能库的"清理"机制,比如淘汰过时的或相互矛盾的技能。在更长期的训练或更复杂的环境中,这可能成为一个问题。
工程落地建议
-
教师模型成本:SkillRL 用 OpenAI o3 做技能蒸馏。在生产环境中,可以考虑用开源的强模型(如 Qwen2.5-72B、DeepSeek-R1)替代,降低 API 成本。技能蒸馏是离线操作,对延迟不敏感。
-
技能库的版本管理:实际部署时,技能库需要版本控制。当基础模型升级或任务分布变化时,旧技能可能失效。建议实现技能的"有效性评分"机制,定期清理低分技能。
-
多环境技能迁移:论文在 ALFWorld 和 WebShop 分别训练了独立的技能库。一个有趣的方向是探索技能的跨环境迁移——比如"系统探索"这种通用技能,理论上在很多环境中都适用。
-
硬件开销:论文使用 8 张 H100 80GB 训练约 30 小时。对于 7B 模型来说这个开销是合理的。如果用 4 张 A100 40GB 可能需要开启梯度累积和 DeepSpeed ZeRO-3,训练时间会翻倍左右。
🤔 局限性与未来方向
论文没有明确讨论局限性,但从实验和方法设计中可以观察到几点:
对教师模型的强依赖。技能蒸馏、冷启动数据生成、递归进化中的失败分析,都依赖一个强大的教师模型(o3)。如果教师模型本身在某些领域知识薄弱,蒸馏出的技能质量也会打折扣。能否让智能体自己做技能蒸馏(self-distillation)?
评测环境的局限。ALFWorld 和 WebShop 虽然是经典基准,但动作空间相对有限、环境确定性较高。在更开放、更动态的环境(如真实网页浏览、软件操作)中,技能的复杂度和多样性会急剧增加,SkillRL 的表现还有待验证。
技能库的可扩展性。100 个技能对于当前的基准足够,但真实世界的 Agent 可能需要数千甚至上万个技能。检索策略、技能间的冲突解决、层次化组织是否还能保持有效性?
📝 总结
SkillRL 提出了一个很有说服力的框架:把智能体的原始交互经验蒸馏成结构化的技能,构建分层技能库并在 RL 训练中让技能库动态进化。从实验结果看,7B 模型在 ALFWorld 上达到 89.9%(超 GPT-4o 41.9 个百分点),在 WebShop 上达到 72.7%,在 7 个 QA 任务上平均 47.1%,全面超越所有基线。
这篇工作最让我认可的一点是:它抓住了一个正确的抽象层次。不是存储原始轨迹(太低层),也不是总结出几句空洞的经验教训(太高层),而是提炼出具体、可操作、有适用条件的技能。这和人类学习技能的过程高度一致——我们不会记住每次做饭的全部过程,也不会只记一句"做饭要注意火候",而是积累一条条具体的技巧:“油温七成热时下锅”、“糖色要小火慢熬到琥珀色”。
SkillRL 的三个核心贡献——经验蒸馏、分层技能库、递归进化——都有清晰的动机和扎实的实验支撑。特别是递归进化机制,让整个系统从"用技能"变成了"自己造技能",这是一个质的飞跃。
对于做 Agent 系统的研究者和工程师来说,SkillRL 提供了一个明确的信号:经验的抽象层次决定了经验的价值。 与其在记忆系统的存储和检索上做文章,不如在经验的蒸馏和结构化上下功夫。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)