Linux系统下,C语言进阶
本文摘要: C语言进阶知识总结,主要包含以下核心内容:1.指针进阶(二级指针、指针数组、函数指针等)及其运算规则;2.Linux标准main函数参数使用;3.枚举、共用体和位域等特殊数据类型的应用场景;4.const关键字的常量指针与指针常量区别;5.内存分配函数(malloc/realloc/calloc)和内存操作函数(memset/memcpy)的使用;6.带参宏与条件编译的预处理技巧;7.
·
目录
一.指针
(一).二级指针
1.回忆:
指针? :存放地址的变量。
变量的运算本质上是对变量中数据的运算。
地址有两种运算:+ - 偏移运算地址 +1char 地址 +1 字节int 类型 +4 字节 偏移运算得到的还是地址,地址类型不变
地址是有类型的。 什么类型的地址运算得到什么类型的对象 谁的地址运算得到谁
* 间接运算 一元运算,运算结果不是数值,是地址对应的那个对象。变量 数组 字符串常量int a = 10;*&a;// 运算得到变量 a ,和 a 的值没有关系。printf("%d\n", *&a+1);// 输出 11 是 + 运算将变量 a 中的值取出进行运算,而不是间接运算得到的数值。printf("%d\n", a+1);
定义指针变量:复合声明
int* p;* 说明 p 是指针变量,由于指针变量存放地址,还需要说明存放地址的类型, int 说明 p 要存放 int 类型的地址。用于定义的符号都不是运算符,而是类型。* 指针类型[] 数组类型() 函数类型int* a;int b[10];int c();
2.二级指针的本质
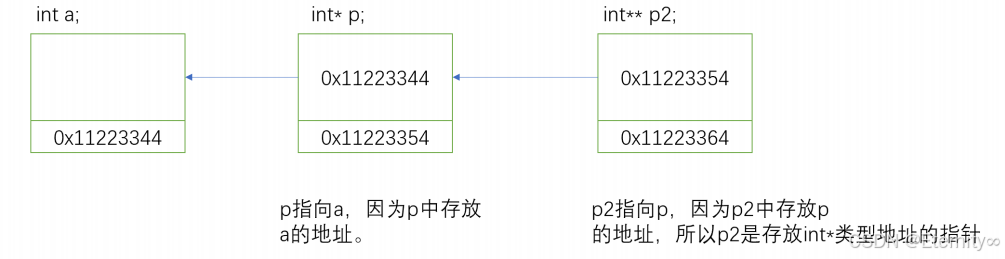
(二).指针数组与数组指针
1.回忆
指针和数组的关系
1. 数组名是数组首元素的地址,是元素类型的地址,是常量。
2. 元素在内存时连续的。
2.指针数组
复杂声明原则
在分析一个标识符的含义时,如果标识符被很多符号修饰,由近及远先右后左。
char* names [ 5 ];
[] 说明 names 是数组, char * 说明数组元素的类型
本质:
元素类型是指针的数组。
int *a[5]; |int *|int *|int *|int *|int *|
实例:(这里和二维数组一点关系都没有。)

3.字符指针数组
本质:数组元素是字符指针的数组。字符指针可以指向字符串常量。
定义: char *p[3]; p[0] p[1] p[2] |char *|char *|char *|

4.指针数组
地址是有类型的。
数组名:是首元素地址,是元素类型的地址,是常量,数组名是整个数组对象。
引例:
数组对象取地址得到数组类型的地址!
数组类型的地址间接运算得到数组对象(当成数组名用)。
#include <stdio.h>int main (){int a [ 5 ];int* p = a ;printf ( "%d %d %p %p\n" , sizeof ( a ), sizeof ( p ), a , p );printf ( "%p %p\n" , a , a + 1 );printf ( "%p %p\n" , & a , & a + 1 ); // 既然 a 是数组对象,就可以给数组对象取地址,偏移 20 字节( *& a )[ 0 ] = 10 ; //*&a 运算得到数组对象,就是数组 a ,所以这里给 a[0] 赋值return 0 ;}
本质:
存放数组类型地址的指针是数组指针。
回忆:
二维数组的本质:元素类型是一维数组的一维数组。
由于使用一个指针指向数组时,指针要定义成数组的元素类型,因为数组名是元素类型的地址。
二维数组的数组名是一维数组类型的地址,所以使用指针指向二维数组我们需要定义数组指针

(三).指针函数、函数指针
1. 指针函数
本质:返回值是指针(地址)的函数就是指针函数。没有特性。
char * strcpy(char *dest,const char *src);错误范例我们要保证返回的地址在函数结束后还有效。int* fun (){int a ;return & a ;}
2.函数指针
本质:存放函数地址的指针。
函数的地址在内存的代码段。所以函数的地址没有间接运算,也没有偏移运算。
我们使用函数指针调用函数。
int get_sum ( int * p , int n );int main (){/*p1 是指针, () 说明指向函数, int* 和 int 是它指向函数的形参列表, int 是它指向函数的返回值类型*/int ( * p1 )( int* , int ); // 定义函数指针p1 = get_sum ; // 函数名就是地址p1 = & get_sum ; // 没有函数对象, &get_sum 和 get_sum 是等价的int a = 10 , b = 20 ;p1 ( & a , b ); // 使用函数指针调用( * p1 )( & a , b ); //*p1 不是运算得到函数对象, p1(&a, b) 和 (*p1)(&a, b) 等价}
函数指针的用处:
通过函数指针传递函数 ( 多态 )
多态:是传递逻辑。
C 语言使用函数指针实现多态
3.函数指针数组
本质:是数组,元素是函数指针。
为什么使用数组?需要若干个类型相同逻辑相似的变量。
使用函数指针数组,需要若干个类型相同,调用的逻辑相似的函数。(有点像多态)
(四).指针总结
1.指针
存放地址的变量。
对变量的运算都是对变量中数据的运算。 对指针变量的运算都是对地址的运算。
2.地址
计算机对内存的编址,字节( byte )为单位。
每个字节都有自己唯一的地址。(如果一个变量占多个字节,地址最小的那个字节的地址作为变量的地址。)
地址的运算偏移运算 + -地址 1+ 整数 = 地址 2地址偏移一个单位,是偏移了一个类型长度。整数 = 地址 2 - 地址 1 得到偏移的单位数地址 1 = 地址 2 - 整数地址是有类型的!!!!间接运算 * 运算结果不是数值,而是地址对应的那个对象。变量,数组,字符串常量int a = 10;int* p = &a;printf("%d\n", *p+1);//11 是 + 运算将变量 a 中的值取出和 1 进行相加,并不是 *p 运算得到 10
3.定义指针
定义的时候使用的符号都不是运算符
int* p;//* 说明 p 是指针变量,指针变量存放地址,地址是有类型的, int 说明 p 存放 int 类型的地址。
* 指针 [] 数组 () 函数
int a;
int*p = &a;
p = &a;
4.地址类型
1)普通变量的地址
定义指针变量
int a; //&a 是 int 类型的地址char b;//&b 是 char 类型的地址int* p = &a;char* pb = &b;间接运算得到变量*p;// 运算得到 a*pb;// 运算得到 b
2)结构体变量的地址
定义指针变量间接运算如何得到结构体类型的变量: . 左值结构体变量 ; -> 左值是结构体指针或者结构体地址struct Student{char name[20];int age;};struct Student a;struct Student* p = &a;p->name;// 运算得到变量 a 中的 name 成员,是一个数组对象 char[20](*p).name;//// 运算得到变量 a 中的 name 成员,是一个数组对象 char[20]
3)数组的地址
定义指针变量
int a[10];a 是数组对象,也可以表示首元素地址,是 int 类型地址。&a 得到数组类型的地址, int[10] 类型的地址a 和 &a 打印值虽然是一样的,但是地址的类型不一样。*a 运算得到 a[0] 是 int 类型变量 *&a 运算得到数组对象,是 int[10] 类型的对象&(a+1) 语法错误!!! a+1 就是一个地址,地址不能取地址。int(*p)[10] = &a;间接运算得到数组对象int a[10];int(*p)[10] = &a;*p 运算得到 a ,是 int[10] 类型的对象
4)函数的地址
定义指针变量
int fun(char);int(*p)(char) = fun;p('a');间接运算没有间接运算和偏移运算。
5) 指针变量的地址
定义指针变量
int a;int* p = &a;//&p 是 int* 类型的地址int**p2 = &p;间接运算*p2 运算得到 p ,是 int* 类型的对象
5.指针指向数组
使用指针变量指向一个数组,要存放首元素地址,是元素类型的地址
int a[10];&a;//int[10] 类型的地址&a+1;// 加了 40 个字节&(a+1);// 报错,数组对象可以取地址,但是不能对地址取地址。
1 )指向一维数组
int a[10];// 元素是 int 类型
int* p = a;
2 )指向二维数组
int a[2][3];// 元素是 int[3] 类型
int(*p)[3] = a;
指针类型形参的写法void fun ( int* p ) // 形参 p 是指针变量{}void fun ( int p []) // 形参 p 是指针变量{}void fun ( int p [ 10 ]) // 形参 p 是指针变量{}// 在函数的形参中无论如何定义不了数组, [] 就是和 * 等价
二.linux标准main函数
在 linux 系统中,允许 main 函数写参数(事实上就应该写参数)
形参只有一种写法
/*char *argv[] 等价于 char** argv argument values 参数的值argc argument count 参数个数main 函数的实参是系统给传的,实参是一个字符指针数组argv 是指正字符指针数组的指针argc 是字符指针数组的长度*/int main ( int argc , const char * argv []){return 0 ;}
三.数据类型
基本数据类型: char int short long float double 整数类型可以使用 unsigned
构造数据类型: 指针。 数组。 结构体。 共用体 ( 联合体 ) 。 枚举。
空类型: void 用于函数返回值表示没有返回值 void* 类型不能使用间接运算
1.枚举enum
本质:是 int 常量。
给整型常量起名字
(1)定义:
//enum 是关键字, TimeofDay 是枚举类型的名字enum TimeofDay{// 枚举的成员并不是被包含的关系,而是枚举类型的对象可能有的值// 枚举的每个成员都是一个 int 常量morning , // 0 给 0 起名叫 morningafternoon , //1 给 0 起名叫 afternoonevening //2};enum Week{one , //0two , //1three //2};// 不管枚举有多少成员它的大小都是 int 一样的。sizeof ( enum TimeofDay ); //4enum TimeofDay{morning = 100 , //100afternoon , //101evening //102};enum TimeofDay{morning = 100 , //100afternoon = 99 , //99evening , //100afterevening = 100 , //100};
(2)注意要点:
1 )枚举类型中,声明的第一个枚举成员默认值为 0
2 )以后每个枚举成员值将是前一个枚举成员的值加 1 得到的。
3 )定义枚举类型时,可以为枚举成员显式赋值。允许多个枚举成员有相同的值。
4 )没有显式赋值的枚举成员的值,总是前一个枚举成员的值 +1
(3) 使用示例:
enum TimeofToday{morning ,halfmorninig = 0 ,afternoon ,halfafternoon = 10 ,evening};void printTime ( enum TimeofToday tot ); // 在可读性上传达的信息是应该使用枚举的成员作为实参//void printTime(int tot);// 给人的感觉实参可以是任意整数int main (){// 枚举的成员可以直接作为常量使用printf ( "%d %d %d %d %d\n" , morning , afternoon , evening , halfmorninig , halfafternoon );printTime ( 0 ); // 就算使用枚举类型作为形参,也可以直接使用整数作为实参printTime ( moring );printTime ( afternoon );}void printTime ( enum TimeofToday tot ){printf ( "%d\n" , tot );}
(4) 为什么使用枚举
枚举能够表达出常量之间是有逻辑关系的,还能表达实参和形参的关系。
enum Directory{up ,down ,left ,right};void printDir ( enum Directory dir );int main (){printDir ( up );return 0 ;}void printDir ( enum Directory dir ){switch ( dir ){case up :printf ( " 上 \n" );break ;case down :printf ( " 下 \n" );break ;case left :printf ( " 左 \n" );break ;case right :printf ( " 右 \n" );break ;}}
2.共用体union (联合体)
(1)定义
共用体的所有成员共用同一段内存,共用体占内存是最大基本类型成员的整数倍。
所有成员地址的值相同,都是共用体变量的地址。
union Data{int a ;char b ;};sizeof ( union Data ); //4union Data{int a ;char b [ 18 ];};printf ( "%d\n" , sizeof ( union Data )); //20#include <stdio.h>union Data{int a ;char b ;};int main (){union Data d ;printf ( "%d\n" , sizeof ( union Data )); //4printf ( "%p %p %p\n" , & d . a , & d . b , & d ); // 所有成员的地址值是相等,而且和变量的地址是相等的printf ( "%p %p %p\n" , & d . a + 1 , & d . b + 1 , & d + 1 ); //+4 +1 +4return 0 ;}
(2)要点:
-> 使用内存的方式,与结构体不同。
-> 共用体的各个成员共用内存,各个成员的起始地址是相同的。 ( 占内存小的成员,是在大成员的低位地址 )
-> 整个共用体占用的存储空间以长度最大的成员为准,共用体占内存是最大基本类型成员的整数倍。
-> 一个共用体变量,如果对多个成员赋值,会覆盖掉其他成员的数据。
(3) 代码示例: 测试主机序
字节序:大端对齐(低位地址存放高位数据)和小端对齐(低位地址存放低位数据)。
#include <stdio.h>union Data{int a ;char c ;};int main (){union Data x ;x . a = 0x12345678 ; //12 是高位数据 78 是低位数据//x.c 是低位地址printf ( "%x\n" , x . c ); //78 我们的虚拟机是小端return 0 ;}
(4)共用体的作用
1. 作为数据泛型,一个共用体变量可以表示多种类型的数据。
2. 实现巧妙的数据转换,比如将成员 a 转换为成员 b 。
#include <stdio.h>
#include <string.h>
struct Student//结构体类型,假设这个结构体是我程序中一个重要的类型,现在我要将它通过网络发送出去
{
char name[20];
int age;
};
union Data
{
struct Student stu;//结构体
char buf[sizeof(struct Student)];//和结构体一样大小的数组,这里的char表示一个字节的整数
};
int main()
{
union Data d;
strcpy(d.stu.name, "xiaoming");
d.stu.age = 18;//给联合的结构体成员赋值,本质上也是在给数组赋值
d.buf;//此时数组成员也是有数据的 这个数组可以直接使用write()通过网络发送出去
return 0;
}(5) 共用体对比结构体
结构体每个成员都有独立的内存,而共用体所有成员共用同一段内存
3.位域
使用位域为了节省内存。 位域的成员不能取地址。
(1) 定义:
struct data{unsigned int a : 2 ; // 占一个 int 的 2 个 bit 位unsigned int b : 4 ; // 接着 a 后面占一个 int 的 4 个 bit 位unsigned int : 0 ; // 空域填满上一个 int 的剩余二进制位unsigned int c : 3 ; // 另起一个 int ,占其中的 3 个 bit 位}; // 这个结构体定义的并不节省内存,只是为了演示语法。sizeof ( struct data ); //8struct data{unsigned int a : 2 ;unsigned int b : 4 ;unsigned int c : 3 ;unsigned int : 0 ;};sizeof ( struct data ); //4
(2) 注意要点:
1 )各位域必须存储在同一个类型长度中,不能跨两个类型长度。
2 )位域占用的位数,不能超过类型长度。
3 )允许位域无域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。
四.const
作用:
将变量修饰成只读,就是不能修改。
注意事项:
const 修饰的变量一定要初始化。
const 是在编译是起作用。为了防止我们自己写代码的时候出错的。
什么时候使用const?
1 修饰局部变量
当我们的函数中,或者某个结构中需要常量的时候,此时不适合使用宏定义,因为宏定义全局有效,一般是程序的各个地方都要使用。
此时可以使用 const 修饰一个局部变量
for(i = 0;i < n;i++){const int studentNum = 40;// 此时 studentNum 就相当于一个局部的常量。}
2 函数形参
一般用来修饰指针
char* strcpy(char* dst, const char* src);在函数里不能通过形参 src 修改作为实参的字符串
在 C 语言中, const 绝大部分情况下都是在形参中修饰常量指针。
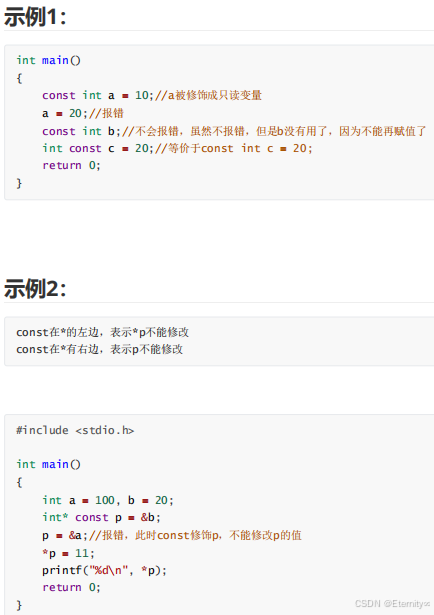

重点:
常量指针 和 指针常量
常量指针:指针指向的对象不能改 , *p 不能改
const int* p;int const* p;
指针常量:指针不能改 p不能改 int * const p;
常量指针常量 p 和*p都不能改 const int* const p;
示例 3 :#include <stdio.h>int main (){int a = 100 ;const int * p = & a ; //p 是常量指针,指向 aa = 80 ; //a 是可以修改的,因为 a 并没有被 const 修饰* p = 60 ; // 报错,因为 p 是常量指针 *p 不能改printf ( "%d\n" , a );return 0 ;}
五.数据存储类型
4 种。 自动 (auto) 、寄存器 (register) 、静态存储 (static) 、外部存储 (extern)
auto 局部变量, auto 关键字在 C 语言总几乎不用了。
register 如果一个变量需要高频的使用,应该被 register 修饰,会把变量定义在离 cpu 更近的位置,所以访问变量的效率会被提高。
1.extern
静态外部链接:使用其他文件中定义的全局变量

2.static
静态修饰
1 ) static 修饰全局变量 :
如果全局变量被 static 修饰,则该全局变量只能在当前文件中使用,不能被外部使用。
///// a.c ////static int a = 200 ;/////////// b.c ////////#include <stdio.h>extern int a ;int main (){printf ( "a = %d\n" , a ); // 报错,因为在 a.c 中 a 被 static 修饰了return 0 ;}
2 ) static 修饰局部变量
可将局部变量定义在静态区间,作用域不变,生命周期和程序一样长。
#include <stdio.h>void fun (){static int a = 90 ; // 此时这个变量不是调用函数时才创建,而是程序开始就创建,程序结束才释放printf ( " %d \n" , a );a ++ ;}int main (){fun ();//printf(" %d \n", a);// 报错,虽然生命周期延长了,但是还是局部变量,作用域没变。fun ();fun ();return 0 ;}输出 :90 90 90修改后: 90 91 92
3 ) static 修饰函数:
被修饰的函数,限定在当前文件内使用。
/////a.c///////////////static void fun (){printf ( “hello world\n” );}/////////////////b.c///////////void fun ();int main (){fun (); // 报错,因为静态函数在其他文件中不能使用return 0 ;}
3.小结
static 和 const 经常在面试中被一起问到,但是他俩又没有任何关系。
static 修饰局部变量 生命周期变得和程序一样长,但是作用域不变
static 修饰全局变量 缩小了全局变量的访问范围,只能在定义全局变量的文件中使用全局变量,生命周期没有改变
static 修饰函数 缩小了函数的访问范围,只能在定义函数的文件中使用
const 将变量修饰成只读的。
常量指针 指向常量的指针, *p 不能变。 const 在 * 左边
指针常量 不能改变指向的指针, p 不能变。 const 在 * 右边
六.内存分配
1.malloc(之前讲过)
2.realloc
reset allocation
作用:改变原有堆空间变量的大小。如果原有的地址,足够改变空间,那么在原有地址基础上改变大小;如果原有地
址的空间不够大,会换一个新的地址。原有的数据拷贝到新的空间。旧空间自动释放。
参数 1 :原有空间的地址,地址必须是堆空间
参数 2 :新的大小
返回值:如果原有地址的空间足够扩张,会返回参数 1 ;否则返回新的地址。
void * realloc ( void * _Memory , size_t _NewSize )
#include <stdio.h>#include <stdlib.h> // 头文件int main (){int i ;int* pn = ( int* ) malloc ( 5 * sizeof ( int )); // 先申请 20 字节内存 5 个 intif ( pn == NULL ){printf ( "malloc fail\n" );return 0 ;}printf ( "malloc %p\n" , pn ); // 显示地址for ( i = 0 ; i < 5 ; i ++ )pn [ i ] = i ; // 给数组 5 个元素赋值 0~4pn = ( int* ) realloc ( pn , 10 * sizeof ( int )); // 在原地址基础上扩张到 40 字节 10 个 intif ( pn == NULL ){printf ( "realloc fail\n" );return 0 ;}printf ( "realloc %p\n" , pn ); // 查看是否改变了地址for ( i = 5 ; i < 10 ; i ++ )pn [ i ] = i ; // 给 5~9 赋值 不管地址是否改变, 0~4 的数据都在for ( i = 0 ; i < 10 ; i ++ )printf ( "%3d" , pn [ i ]); // 输出free ( pn ); // 只释放新的地址就行,就算原地址发生改变,也会被 realloc 自动释放掉pn = NULL ;return 0 ;}
3.calloc
clear allocation
作用:将申请的空间全部清 0 。 malloc 申请的空间是不清零的。
参数 1 :申请单元个数
参数 2 :每个单元的大小
void * calloc ( size_t nmenb , size_t size );
#include<stdio.h>#include<stdlib.h>int main (){int i ;int* pn = ( int* ) calloc ( 10 , sizeof ( int )); // 申请 40 个字节, 10 个 intfor ( i = 0 ; i < 10 ; i ++ )printf ( "%d " , pn [ i ]); // 保证内存都被初始化成 0 了printf ( "\n" );free ( pn ); // 释放内存return 0 ;}
4.memset和memcpy
堆、栈、静态都可以用
memset 内存设置,给一段内存赋值
memcpy 内存拷贝,拷贝一段内存的值
#include <string.h> // 头文件/*参数 1 :要设置内存的地址,什么类型都可以参数 2 :要给内存设置的值 ,每个字节都是参数 2 的值参数 3 :内存长度,单位是字节int a[10];memset(a, 0, sizeof(a));// 给数组 a 全部清零*/void* memset ( void* ptr , int value , size_t num );/*参数 1 :向参数 1 的内存拷贝数据参数 2 :被拷贝的内存参数 3 :拷贝内存的长度*/void* memcpy ( void* dest , const void* src , size_t num );
#include <stdio.h>
#include <string.h>
int main() {]
int i, j;
// 示例1:字符串初始化
char str[] = "Hello";//数组长度6
memset(str, 'x', 3);//将str0~2设置成'x'
printf("%s\n", str);//xxxlo
// 示例2:数组清零
int nums[5] = {1, 2, 3, 4, 5};
memset(nums, 1, sizeof(nums));//整个数组全清,每个字节都是1 每个元素的值 0x01010101
for (i = 0; i < 5; i++)
printf("%#x ", nums[i]);//因为每个int占4个字节,所以每个元素的值都是 0x01010101
char map[8][6];
memset(map,'*', sizeof(map));//整个二维数组,每个字节都是'*'
for(i = 0;i < 8;i++)
{
for(j = 0;j < 6;j++)
{
printf("%c ", map[i][j]);
}
printf("\n");
}
return 0;
}#include <stdio.h>
#include <string.h>
int main() {
// 示例1:复制数组
int src_arr[5] = {1, 2, 3, 4, 5};
int dest_arr[5];
memcpy(dest_arr, src_arr, sizeof(src_arr));//拷贝整个src_arr数组到dest_arr数组中
for (int i = 0; i < 5; i++)
printf("%d ", dest_arr[i]);//1 2 3 4 5
// 示例2:复制结构体
struct Point { int x; int y; };//在函数内定义的结构体类型,只能在函数内使用
struct Point src = {10, 20};//定义结构体对象初始化
struct Point dest;
memcpy(&dest, &src, sizeof(src));//将src对象数据拷贝到dest中
printf("(%d, %d)\n", dest.x, dest.y);
//事实上结构体可以struct Point dest = src; 我只想演示memcpy不挑类型
// 示例3:字符串复制(需手动补'\0')
char src_str[] = "Hello";
char dest_str[10];
memcpy(dest_str, src_str, strlen(src_str));
dest_str[strlen(src_str)] = '\0';//由于memcpy没有拷贝\0,因为strlen(src_str)不算\0,所以需要
手动在最后补\0
//memcpy(dest_str, src_str, strlen(src_str)+1);//这样就不需要手动补\0
printf("%s\n", dest_str);
//事实上拷贝字符串最好使用strcpy
return 0;
}七.带参宏
1.宏的特点:
1 ) 宏是在预处理阶段完成的事,完成了用宏值把宏名替换掉。
2 ) 宏值是没有类型的。 宏只是简单的符号替换。无脑替。
3 ) 宏名字一般用大写。为了和变量做以区分。
错误范例:#include <stdio.h>#define NUM 10;int main (){int i ;for ( i = 0 ; i < NUM ; i ++ ) //for(i = 0;i < 10;;i++){printf ( "hello\n" );}return 0 ;}
2.宏的优势:
1. 一改全改
2. 使得常量有意义
实例:带参,给宏名加参数#include <stdio.h>// 宏名后面 () , () 里面是宏的参数,可以不止一个,参数会被替换到宏值中#define EXPAND(x) (10*(x))int main (){//(10*(2+1)) 2+1 是宏的实参,会被替换到宏值中printf ( " %d \n" , EXPAND ( 2 + 1 )); //30return 0 ;}
不写括号的错误范例:#define EXPAND(X) 1+10*Xint main (){// 无脑替,直接使用宏值替换宏名,千万不要思考//5*1+10*2+1printf ( "%d\n" , 5 * EXPAND ( 2 + 1 )); //26return 0 ;}
使用带参宏替换一个函数示例:一般定义函数的逻辑相对固定,只是需要我们自己对函数起名字#include <stdio.h>//C 语言规定宏值必须写在同一行 所以宏值如果要多行写,需要加 \ 表示换行连接#define POW(x) void x()\{\printf("hello world\n");\}POW ( hehe )int main (){hehe ();return 0 ;}
3.多参数的宏
#include <stdio.h>// 多个参数使用 , 分隔#define POW(x,y) ((x)*(y))int main (){//20 替换宏值中的 x 3 替换宏值中的 yprintf ( "%d\n" , POW ( 20 , 3 ));return 0 ;}
4.带参宏 和 函数调用 的区别
宏定义和函数是没有可比性的。
宏定义只是预处理阶段的宏值替换宏名。
函数是程序运行时代码的调用。
带参宏不会对参数类型进行检查。 只是替换,还没到编译的步骤。
带参宏不能定义返回值。 只是替换,根本不执行
带参宏不具备函数调用的灵活性。 只是替换,根本就不存在调用宏的说法
带参宏不执行任何逻辑,仅仅是在预处理阶段进行的代码替换。
带参宏仅仅能为我们编码时提供一些便利。
函数调用: 在程序执行之后才进行函数调用。 运行效率没有带参宏的效率高。因为执行阶段才调用。有类型检查,有作用域,有生命周期,有返回值。
八.条件编译
1.作用
if 结构有选择性的执行一部分代码。
条件编译是有选择性的编译一部分代码。
跨平台开发:同样的功能,不同的平台实现的方式可能不一样。
调试:一些输出调试信息的代码,可以使用条件编译,在发布用户版本的时候不编译用于调试的代码。
2.#ifdef
if define 如果定义了某个宏才对代码进行编译
用于 #ifdef 的宏,可以不写宏值
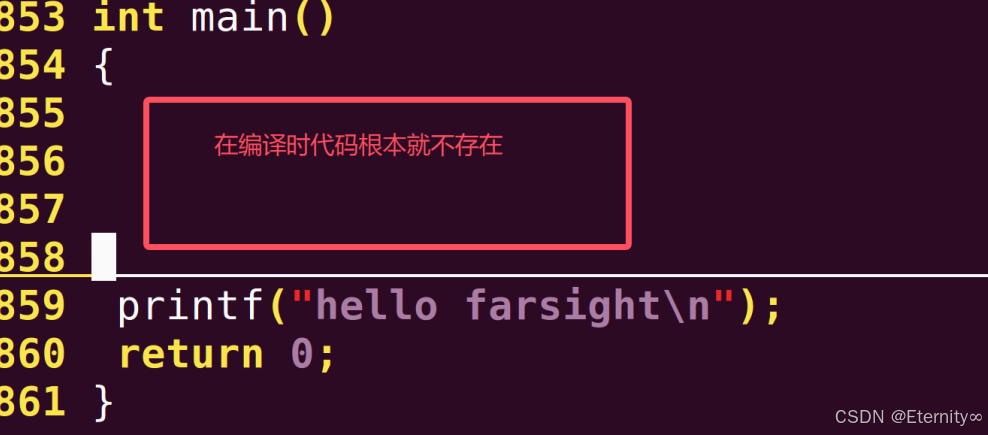
#include <stdio.h>int main (){#ifdef HELLO // 如果定义了 HELLO 这个宏,则编译下面两行代码,没定义 HELLO 宏就不编译printf ( "hello world\n" );printf ( "hello kitty\n" );#endif // 条件编译到这里结束,下面代码到和条件编译没有关系printf ( "hello farsight\n" ); // 这行代码无论如何都会被编译return 0 ;}
gcc -E test.c -o test.i
加宏之后#include <stdio.h>// 用于条件编译 ifdef 的宏,有没有宏值是无所谓的#define HELLOint main (){#ifdef HELLOprintf ( "hello world\n" );printf ( "hello kitty\n" );#endifprintf ( "hello farsight\n" );return 0 ;}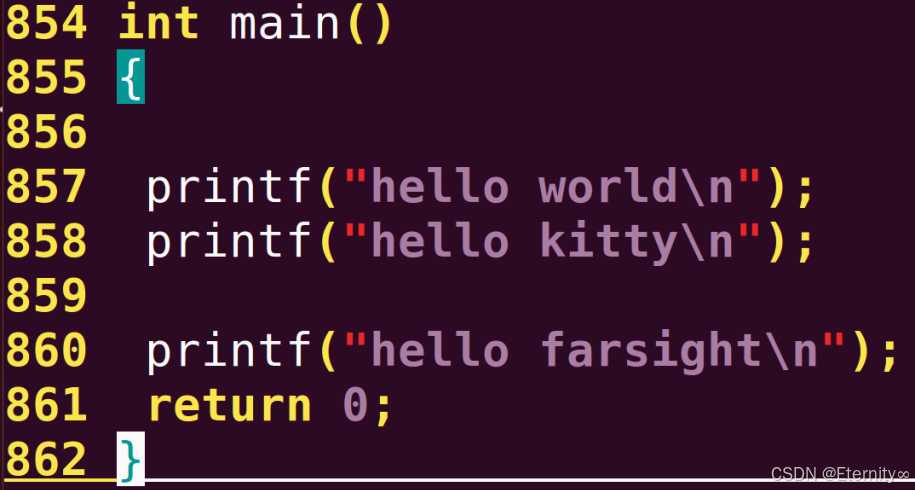
3.#if #else #elif
示例 2:
使用 #else 可以实现两路分支的条件编译
#include <stdio.h>#define DEBUGint main (){#ifdef DEBUG // 如果定义了 DEBUG 宏,会编译下面两行printf ( "hello world\n" );printf ( "hello farsight\n" );#else // 如果没有定义 DEBUG 宏,会编译下面一行printf ( "hello test\n" );#endif // 条件编译范围到此为止printf ( "hello kitty\n" ); // 这一行不受条件编译影响,无论如何都会编译return 0 ;}
#include <stdio.h>// 用于多路分支的宏,必须有宏值,而且宏值是整数#define TEST 1int main (){#if TEST == 1 // 如果 TEST 宏值是 1 则编译 下面 1 行printf ( "hello world\n" );#elif TEST == 2 // 如果 TEST 宏值是 2 则编译 下面 1 行printf ( "hello test\n" );#endif // 条件编译的范围到这里结束printf ( "hello farsight\n" ); // 这一行不受条件编译影响,无论如何都会编译return 0 ;}
4. #ifndef
if not define
主要用于头文件,防止重复定义
示例 3:///////person.h#ifndef PERSON_H#define PERSON_Hstruct Person{char name [ 20 ];int age ;};#endif///////teacher.h#include "person.h"struct Teacher{struct Person p ;char major [ 20 ];};////////student.h#include "person.h"struct Student{struct Person p ;int score ;};////////main.c#include "teacher.h"#include "student.h"int main (){return 0 ;}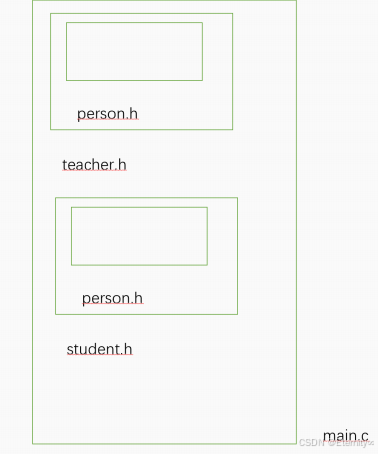
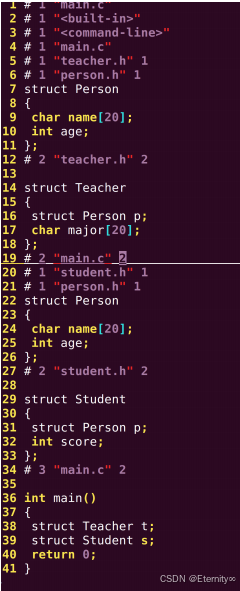
main.c 在经过预处理后,会有两个 Person 结构体,所以提示 Person 结构体重复定义。

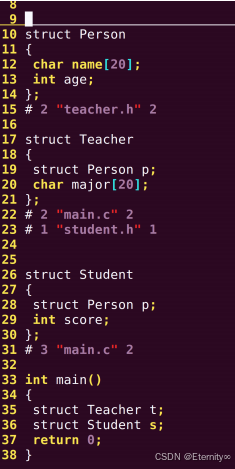
九.类型重定义
关键字 typedef
type define
给类型起别名。
1)为什么要类型重定义?
1.更有利于理解类型的含义
// 给 unsigend int 起别名叫 student_num_t t 是 type 缩写typedef unsigend int student_num_t ;void showStudents ( student_num_t stuNum );
2.便于后期对类型修改
//typedef char student_num_t;typedef int student_num_t ;student_num_t a ;student_num_t b ;student_num_t c ;student_num_t d ;
2)普通类型重定义
typedef 只是起别名,原来的类型名还能用。
typedef int data_t ; // 给 int 起别名叫 data_tint main (){data_t a = 10 ; // 等价于 int a = 10;int b = 20 ; //int 类型还是可以使用的printf ( "%d %d\n" , a , b ); //10 20;return 0 ;}通常:typedef char s8 ; //8 表示 8bit s 表示 signed 有符号 8 位整数typedef unsigned char U8 ; //8 表示 8bit u 表示 unsigned 无符号 8 位整数typedef short S16 ;typedef unsigned short U16 ;typedef int S32 ;typedef unsigned int U32 ;//STM32 单片机的 HAL 库, int8_t uint16_t
3)结构体类型重定义
struct student{char name [ 20 ];int score ;};struct student s1 ;struct student * p ;为了便于开发者typedef struct student stu_t ; // 给 struct student 起别名叫 stu_tstu_t s1 ; // 定义结构体变量stu_t * p ; // 定义结构体指针变量
4)实例
给一个已经存在的结构体起别名#include <stdio.h>struct student{char name [ 20 ];int score ;};typedef struct student stu_t ; // 给结构体 struct student 类型起别名叫 stu_tint main (){stu_t s1 = { "xiaoli" , 96 };printf ( "%s, %d\n" , s1 . name , s1 . score );return 0 ;}
直接定义结构体时就 重命名,最常见的用法#include <stdio.h>typedef struct student{char name [ 20 ];int score ;} stu_t , * pstu_t ;// 在定义结构体的时候直接起别名叫 stu_t , pstu_t 是 typedef struct student * pstu_t; 既结构体指针类型int main (){stu_t s1 = { "xiaoli" , 96 };printf ( "%s, %d\n" , s1 . name , s1 . score );//pstu_t 就是指针类型,所使用它定义指针变量不需要使用 *pstu_t ps = & s1 ;printf ( "%s, %d\n" , ps -> name , ps -> score );return 0 ;}
可以省略结构体名#include <stdio.h>// 省略了结构体本身的名字,只要别名typedef struct{char name [ 20 ];int score ;} stu_t , * pstu_t ;typedef struct{char name [ 20 ];int age ;} tea_t , * ptea_t ;int main (){stu_t s1 = { "xiaoli" , 96 };pstu_t p = & s1 ;printf ( "%s, %d\n" , p -> name , p -> score );return 0 ;}
注意:struct{char name [ 20 ];int score ;} stu_t , * pstu_t ;stu_t 就不是结构类型了,是结构体变量pstu_t 是结构体指针变量而且这个结构体类型除了以上两个变量,再也定义不了变量了,因为没有名字
5)函数指针和数组指针类型
#include <stdio.h>typedef int ( * arr_ptr_t )[ 10 ]; //arr_ptr_t 是数组指针类型typedef void ( * fun_ptr_t )( int ); //fun_ptr_t 函数指针类型void fun ( int a ){printf ( "hehe\n" );}int main (){int a [ 10 ];arr_ptr_t p = & a ; //p 就是数组指针,存放 int[10] 类型地址的指针变量fun_ptr_t p2 = fun ; //p2 是函数指针return 0 ;}
十.函数递归调用
1.函数入栈
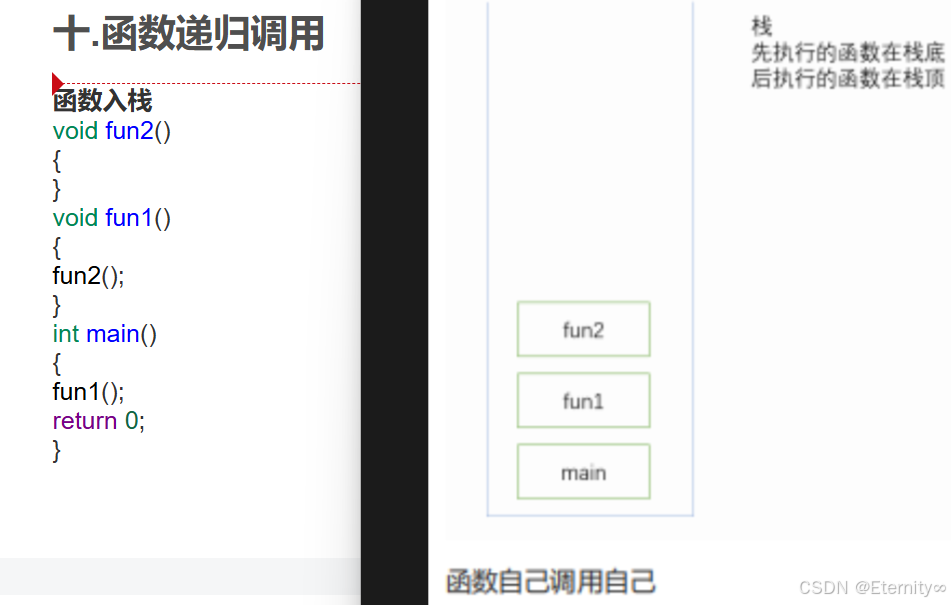
调用形式:void fun1 (){fun1 (); // 严格来说这个不叫递归 因为这个函数只递 不 归}void fun2 ( int num ){printf ( "start:%d\n" , num );if ( num == 5 )return ;fun2 ( num + 1 );printf ( "fun %d finish\n" , num );}int main (){fun2 ( 1 );return 0 ;}
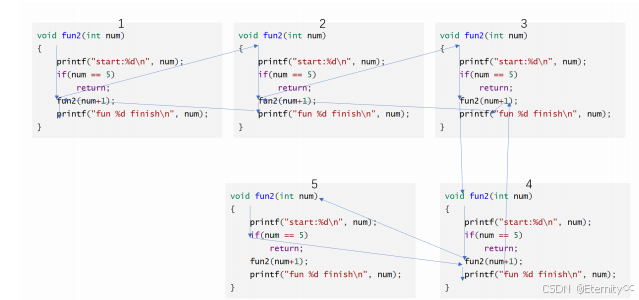
2.要成功使用递归函数,需要注意的是:
一定要写明递的结束条件。 在满足结束条件后就不再递归了。
递归的结束条件,有时可以作为思考递归的一个逻辑入口。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)