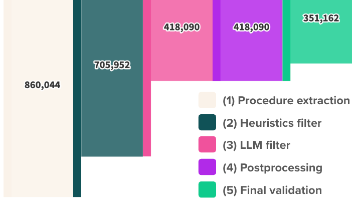
AI时代的矛与盾:隐私增强技术(PETs)实战——差分隐私与同态加密
假设有两位用户,Alice 和 Bob,他们想计算两人健康数据(如心率、卡路里消耗)的平均值,但他们互相不信任,也不信任执行计算的第三方服务器。想象你有一个锁着的、透明的盒子(密文),里面放着一些珠宝(明文)。这个输出清晰地展示了整个流程:数据在客户端被加密,服务器在不知道内容的情况下完成了求平均值的计算,最终解密的结果与直接在明文上计算的结果完全一致,证明了同态加密的正确性。这张图清晰地展示了,
前言
-
技术背景:在当今的攻防体系中,数据已成为核心攻击目标与防护资产。AI模型的广泛应用加剧了这一态势,模型训练需要海量数据,而这些数据往往包含个人可识别信息(PII)。 攻击者不再仅仅满足于拖库,而是通过模型逆向、成员推断等手段,从AI服务的输出结果中反向窃取训练数据中的个人隐私。 隐私增强技术(PETs),特别是差分隐私和同态加密,正是在这一背景下,从防御和合规的视角出发,构建数据安全“护城河”的关键技术。 它们是数据安全从“边界防护”走向“计算过程防护”的里程碑,是实现“数据可用不可见”的核心武器。
-
学习价值:掌握差分隐私,你将能发布既包含宏观统计价值、又无法反推出任何个体信息的“脱敏”数据集,有效应对“统计数据库再识别”攻击。 掌握同态加密,你将能在加密数据上直接进行计算(如模型推理、联合统计),使得即使是云服务提供商或数据处理平台也无法窥探原始数据内容,从根本上解决数据在第三方环境中的信任问题。 这两种技术是构建下一代安全架构、满足日益严苛的数据隐私法规(如GDPR、数据安全法)的必备技能。
-
使用场景:
- 差分隐私:广泛应用于需要发布统计报告、训练机器学习模型等场景。例如,苹果公司用它来收集热门表情、耗电网站等信息,而不会知道具体是哪个用户的数据。 谷歌则用它来分析Chrome浏览器中的恶意软件统计。 在联邦学习中,它也被用来保护各参与方上传的模型更新。
- 同态加密:主要用于安全的“外包计算”。例如,在金融领域,银行可以在加密的客户数据上运行欺诈检测算法;在医疗领域,多家医院可以在不共享原始病历的情况下,联合训练疾病预测模型。 它是构建机密计算、安全多方计算(MPC)和隐私保护数据分析平台的核心。
一、差分隐私 (Differential Privacy) 是什么
精确定义
差分隐私 (Differential Privacy, DP) 是一种提供严格、可量化隐私保障的数学框架。其核心思想是:在一个数据集中添加或删除任意一条记录,对查询结果产生的影响应该是微乎其微、几乎无法察觉的。 这种“不可区分性”确保了攻击者即使拥有除某一个体之外的所有背景知识,也无法确定该个体的数据是否存在于数据集中,从而保护了个体隐私。
一个通俗类比
想象一个教室里有100名学生,老师想知道大家的平均年龄,但又不想知道每个学生的具体年龄。
-
不安全的做法:老师让每个学生把年龄写在纸条上交上来,然后计算平均值。虽然只公布了平均值,但如果一个“攻击者”(比如一个爱打听的同学)知道了其他99人的年龄,他就能轻易算出剩下那一个人的年龄。
-
差分隐私的做法:老师给每个学生发一个可以投出“+1”、“0”、“-1”三种结果的特殊骰子。每个学生在报告自己年龄的同时,投掷骰子,并将骰子结果加到自己的真实年龄上报。老师收集到的是“加了噪”的年龄。
- 由于每个人的上报值都存在随机性,即使攻击者知道其他99个“加噪”后的年龄和最终的平均值,他也无法100%确定某一个人的真实年龄。
- 但对于老师来说,当学生数量足够多时,这些随机的“+1”和“-1”会相互抵消,计算出的平均值依然非常接近真实的平均年龄。
这就是差分隐私的精髓:通过对个体数据注入精心设计的随机噪声来保护隐私,同时在宏观统计层面保持数据的可用性。
实际用途
- 大规模数据统计:苹果、谷歌等公司用它来收集用户行为数据,用于改进产品,如输入法预测、热门Emoji统计等。
- 机器学习:在模型训练过程中对梯度更新添加噪声,防止模型“记住”训练集中的敏感样本,这种技术被称为差分隐私随机梯度下降(DP-SGD)。
- 数据发布:美国人口普查局使用差分隐私技术来公开发布人口统计数据,既服务于社会研究,又保护公民隐私。
技术本质说明
差分隐私的数学定义是其核心,它通过一个名为隐私预算 (Privacy Budget, ε) 的参数来量化隐私保护的强度。
一个随机算法 M 满足 ε-差分隐私,如果对于任意两个仅相差一条记录的相邻数据集 D1 和 D2,以及算法 M 的任何可能输出 S,都满足以下不等式:
Pr[M(D1) ∈ S] ≤ e^ε * Pr[M(D2) ∈ S]
Pr[...]代表概率。ε(epsilon) 是一个小的正数。ε越小,隐私保护强度越高,因为两个数据集输出相同结果的概率比值越接近1,攻击者越难区分。但同时,为了满足更小的ε,需要加入的噪声就越大,数据的可用性就越低。
实现差分隐私最常见的机制是拉普拉斯机制 (Laplace Mechanism),它通过向数值型查询的真实结果中添加服从拉普拉斯分布的噪声来实现。噪声的大小取决于查询函数的全局敏感度(即单个记录变化对查询结果的最大影响)和隐私预算 ε。
以下 Mermaid 图展示了中心化差分隐私(CDP)的工作流程:
这张图清晰地展示了,用户的原始数据被收集后,任何对外的查询都必须经过一个“加噪”过程,最终发布的是一个保护了隐私的统计结果。
二、环境准备 (差分隐私)
我们将使用 Google 开源的差分隐私库 PyDP 来进行实战。
- 工具版本:
- Python: 3.8+
- PyDP: 1.1.1+
- 下载方式:使用 pip 进行安装。
pip install python-dp - 核心配置命令:
PyDP的核心配置在于初始化差分隐私算法时传入的epsilon值。例如,初始化一个有界的均值计算:# 导入有界均值算法 from pydp.algorithms.laplacian import BoundedMean # 配置 epsilon,值越小隐私保护越强 epsilon = 0.8 dp_mean_calculator = BoundedMean(epsilon=epsilon, lower_bound=1, upper_bound=100) - 可运行环境:标准的 Python 环境即可。为了方便管理,建议使用
venv创建虚拟环境。# 创建虚拟环境 python -m venv dp_env # 激活虚拟环境 (Linux/macOS) source dp_env/bin/activate # 激活虚拟环境 (Windows) .\dp_env\Scripts\activate # 安装库 pip install python-dp numpy
三、核心实战 (差分隐私)
场景:假设我们是一家健康科技公司,收集了用户的每日步数。为了发布一份公开的《用户平均活跃度报告》,我们需要计算用户的平均步数,但绝不能泄露任何单个用户的具体步数。
实战步骤
-
准备数据:我们模拟一个包含1000名用户每日步数的数据集。步数范围在 1000 到 20000 之间。
-
定义查询:我们的查询是计算这1000名用户步数的平均值。
-
应用差分隐私:使用
PyDP的BoundedMean算法,设置一个合理的隐私预算ε,并对数据集计算差分隐私保护下的平均值。 -
验证结果:比较真实的平均值和经过差分隐私处理后的平均值,并多次运行以观察噪声带来的随机性。
完整可运行示例
# 导入所需库
import pydp as dp
from pydp.algorithms.laplacian import BoundedMean
import numpy as np
# --- 1. 准备数据 ---
# 设置随机种子以保证结果可复现
np.random.seed(42)
# 模拟1000个用户的每日步数,范围在1000到20000之间
lower_bound_steps = 1000
upper_bound_steps = 20000
user_steps = np.random.randint(lower_bound_steps, upper_bound_steps, 1000).tolist()
# --- 2. 计算真实平均值 (用于对比) ---
true_mean = np.mean(user_steps)
print(f"原始数据的真实平均步数: {true_mean:.2f}")
# --- 3. 应用差分隐私 ---
# 目的:计算平均步数,同时保护个人隐私
print("\n--- 开始进行差分隐私计算 ---")
# 设置隐私预算 epsilon。值越小,隐私保护越强,但结果偏差可能越大。
# 这是一个关键参数,需要在隐私和可用性之间权衡。
epsilon = 0.8
print(f"设置隐私预算 (epsilon): {epsilon}")
# 初始化 BoundedMean 算法
# 需要提供 epsilon 和数据的上下界。
# 提前知道数据的边界对于提高准确性至关重要。
dp_mean_calculator = BoundedMean(
epsilon=epsilon,
lower_bound=lower_bound_steps,
upper_bound=upper_bound_steps,
dtype="int" # 指定数据类型
)
# 使用 quick_result 方法计算差分隐私保护下的平均值
# 这一步会添加拉普拉斯噪声
dp_mean_result = dp_mean_calculator.quick_result(user_steps)
print(f"差分隐私保护下的平均步数: {dp_mean_result:.2f}")
# --- 4. 验证与观察 ---
print("\n--- 多次运行以观察噪声效果 ---")
# 多次计算以展示结果的随机性
for i in range(5):
dp_mean_iter = dp_mean_calculator.quick_result(user_steps)
print(f"第 {i+1} 次计算DP平均值: {dp_mean_iter:.2f}")
# 演示隐私预算对结果的影响
print("\n--- 比较不同隐私预算的效果 ---")
epsilon_high_privacy = 0.1 # 更强的隐私保护
epsilon_low_privacy = 5.0 # 较弱的隐私保护
dp_mean_high_privacy = BoundedMean(epsilon_high_privacy, lower_bound_steps, upper_bound_steps, dtype="int").quick_result(user_steps)
dp_mean_low_privacy = BoundedMean(epsilon_low_privacy, lower_bound_steps, upper_bound_steps, dtype="int").quick_result(user_steps)
print(f"真实平均值: {true_mean:.2f}")
print(f"强隐私保护 (ε={epsilon_high_privacy}) 的结果: {dp_mean_high_privacy:.2f}, 误差: {abs(dp_mean_high_privacy - true_mean):.2f}")
print(f"弱隐私保护 (ε={epsilon_low_privacy}) 的结果: {dp_mean_low_privacy:.2f}, 误差: {abs(dp_mean_low_privacy - true_mean):.2f}")
输出结果示例 (每次运行会略有不同):
原始数据的真实平均步数: 10488.91
--- 开始进行差分隐私计算 ---
设置隐私预算 (epsilon): 0.8
差分隐私保护下的平均步数: 10467.58
--- 多次运行以观察噪声效果 ---
第 1 次计算DP平均值: 10467.58
第 2 次计算DP平均值: 10512.43
第 3 次计算DP平均值: 10499.12
第 4 次计算DP平均值: 10480.33
第 5 次计算DP平均值: 10501.01
--- 比较不同隐私预算的效果 ---
真实平均值: 10488.91
强隐私保护 (ε=0.1) 的结果: 10301.23, 误差: 187.68
弱隐私保护 (ε=5.0) 的结果: 10487.15, 误差: 1.76
从输出可以看出,ε 越小,结果的波动越大,与真实值的偏差也可能越大,但隐私保护更强。ε 越大,结果越接近真实值,但隐私保护相应减弱。
自动化脚本
下面是一个更完整的自动化脚本,封装了差分隐私计算过程,并增加了参数化、错误处理和注释。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import numpy as np
import pydp as dp
from pydp.algorithms.laplacian import BoundedMean, BoundedSum, Count
# -----------------------------------------------------------------------------
# 警告:本脚本仅用于授权测试和教育目的。
# 在处理真实敏感数据时,必须谨慎选择隐私参数并遵循相关法律法规。
# -----------------------------------------------------------------------------
def calculate_dp_statistics(data, epsilon, lower_bound, upper_bound, aggregation_type='mean'):
"""
计算数据集的差分隐私统计值。
:param data: list, 输入的数值型数据列表。
:param epsilon: float, 隐私预算 (ε),必须为正数。
:param lower_bound: float, 数据的下界。
:param upper_bound: float, 数据的上界。
:param aggregation_type: str, 聚合类型,支持 'mean', 'sum', 'count'。
:return: float, 经过差分隐私保护的统计结果。
:raises ValueError: 如果输入参数无效。
"""
if not isinstance(data, list) or not data:
raise ValueError("输入数据必须是一个非空的列表。")
if not epsilon > 0:
raise ValueError("隐私预算 (epsilon) 必须是正数。")
if lower_bound >= upper_bound:
raise ValueError("数据下界必须小于上界。")
try:
if aggregation_type == 'mean':
# 初始化有界均值算法
dp_aggregator = BoundedMean(epsilon, lower_bound, upper_bound, dtype="float")
elif aggregation_type == 'sum':
# 初始化有界求和算法
dp_aggregator = BoundedSum(epsilon, lower_bound, upper_bound, dtype="float")
elif aggregation_type == 'count':
# 初始化计数算法
dp_aggregator = Count(epsilon, dtype="float")
else:
raise ValueError(f"不支持的聚合类型: {aggregation_type}")
# 计算并返回差分隐私结果
result = dp_aggregator.quick_result(data)
return result
except Exception as e:
print(f"计算过程中发生错误: {e}")
# 在实际应用中,这里可能需要更复杂的错误处理逻辑
return None
def main():
"""主函数,用于解析命令行参数并执行差分隐私计算。"""
parser = argparse.ArgumentParser(description="使用差分隐私计算数据集的统计信息。")
parser.add_argument("--epsilon", type=float, default=1.0, help="隐私预算 (ε),默认值为 1.0。")
parser.add_argument("--agg", type=str, default="mean", choices=['mean', 'sum', 'count'], help="聚合类型,默认为 'mean'。")
parser.add_argument("--lower", type=float, default=0, help="数据值的下界,默认为 0。")
parser.add_argument("--upper", type=float, default=150, help="数据值的上界,默认为 150 (例如,年龄)。")
parser.add_argument("--size", type=int, default=1000, help="模拟数据集的大小,默认为 1000。")
args = parser.parse_args()
print("--- 自动化差分隐私计算脚本 ---")
print(f"参数: Epsilon={args.epsilon}, Aggregation={args.agg}, Bounds=[{args.lower}, {args.upper}], Size={args.size}")
# 模拟生成数据
np.random.seed(None) # 每次运行使用不同的随机种子
simulated_data = np.random.uniform(args.lower, args.upper, args.size).tolist()
# 计算真实值
if args.agg == 'mean':
true_value = np.mean(simulated_data)
elif args.agg == 'sum':
true_value = np.sum(simulated_data)
else: # count
true_value = len(simulated_data)
# 计算差分隐私值
dp_value = calculate_dp_statistics(
data=simulated_data,
epsilon=args.epsilon,
lower_bound=args.lower,
upper_bound=args.upper,
aggregation_type=args.agg
)
if dp_value is not None:
print(f"\n真实 {args.agg}: {true_value:.4f}")
print(f"差分隐私 {args.agg}: {dp_value:.4f}")
print(f"误差: {abs(dp_value - true_value):.4f}")
if __name__ == "__main__":
main()
使用方法:将代码保存为 dp_auto_script.py,然后在命令行中运行。
# 计算平均值
python dp_auto_script.py --epsilon 0.5 --agg mean --lower 1000 --upper 20000 --size 5000
# 计算总和
python dp_auto_script.py --epsilon 1.2 --agg sum --lower 0 --upper 100 --size 10000
# 计算数量
python dp_auto_script.py --epsilon 0.1 --agg count --size 1000
这个脚本展示了如何将差分隐私原理应用到可复用的代码中,是构建更复杂隐私保护数据管道的基础。
接下来的部分将深入探讨同态加密,包括其原理、与差分隐私的对比、以及使用 TenSEAL 库进行的核心实战。由于内容较长,将分段呈现。
一、同态加密 (Homomorphic Encryption) 是什么
精确定义
同态加密 (Homomorphic Encryption, HE) 是一种特殊的加密形式,它允许在密文上直接执行计算(如加法和乘法),得到一个加密的结果。这个加密结果在解密后,与在明文上执行相同计算所得到的结果完全一致。 简而言之,它实现了“加密地计算”。
一个通俗类比
想象你有一个锁着的、透明的盒子(密文),里面放着一些珠宝(明文)。你想让一位工匠(例如,云服务器)帮你把这些珠宝重新组合成一条项链,但你又不信任这位工匠,不希望他能直接触摸或拿走任何珠宝。
-
传统加密:你把盒子给工匠,他打不开,什么也做不了。你必须先把盒子打开(解密),让他操作珠宝,然后再把新项链锁起来(加密)。这个过程中,工匠完全接触了你的珠宝,存在风险。
-
同态加密:你给了工匠一个带有特殊手套的、锁着的盒子。工匠可以把手伸进手套,在盒子内部操作珠宝(在密文上计算),但他无法将珠宝拿出盒子,也无法看清珠宝的真实材质和价值。当他完成工作后,把盒子还给你。只有你用自己的钥匙(私钥)才能打开盒子,取出制作好的项链(解密结果)。
在这个类比中,工匠在完全不知道珠宝是什么的情况下完成了加工任务,这就是同态加密的魔力:数据处理方可以在不访问原始数据的情况下,完成计算任务。
实际用途
- 安全云计算:用户可以将加密数据上传到云端,并让云服务商在加密数据上执行数据分析、机器学习模型训练或推理等任务,而云服务商无法获取用户的原始数据。
- 隐私保护数据分析:在金融、医疗等多个数据所有者希望联合分析数据但又不愿共享原始数据的场景中,同态加密可以用来安全地计算聚合统计数据。
- 联邦学习:与差分隐私结合,用于在聚合来自多方的模型更新时,保护每一方的更新内容不被中心服务器知晓。
技术本质说明
同态加密的核心在于其代数结构。一个加密方案 (KeyGen, Enc, Dec) 如果支持同态运算 ⊚ (对密文) 和 ⊕ (对明文),则它需要满足:
Dec(Enc(m1) ⊚ Enc(m2)) = m1 ⊕ m2
根据支持的运算类型和次数,同态加密分为几类:
- 部分同态加密 (PHE):仅支持一种运算(加法或乘法)无限次。例如,经典的RSA算法支持乘法同态。
- 有限同态加密 (SHE/SWHE):支持有限次数的加法和乘法运算。每次运算都会导致密文中的“噪声”增长,当噪声超过某个阈值时,解密就会失败。
- 全同态加密 (FHE):支持无限次的加法和乘法运算。这是通过一种称为自举 (Bootstrapping) 的革命性技术实现的。自举过程可以周期性地“刷新”密文,减少累积的噪声,从而允许进行任意深度的计算。
我们本次实战使用的 CKKS (Cheon-Kim-Kim-Song) 方案是一种先进的近似同态加密方案,它特别擅长处理浮点数(实数),非常适合机器学习等应用场景。
以下 Mermaid 图展示了同态加密的典型工作流程:
此图清晰地展示了数据所有者如何使用公钥加密数据并将其发送给服务器。服务器在密文上执行计算,然后将加密的结果返回。全程私钥都保留在数据所有者手中,服务器无法解密任何数据。
二、环境准备 (同态加密)
我们将使用 TenSEAL 库,它是一个基于 Microsoft SEAL 构建的优秀 Python 同态加密库,特别适合处理张量(向量和矩阵)运算。
- 工具版本:
- Python: 3.8+
- TenSEAL: 0.3.1+
- 下载方式:使用 pip 安装。
pip install tenseal - 核心配置命令:
TenSEAL的核心是创建TenSEALContext。配置它需要选择加密方案(如CKKS)、设定多项式模数次数和系数模数位大小。这些参数共同决定了安全性、计算性能和精度。import tenseal as ts # 创建一个 TenSEAL 上下文 context = ts.context( ts.SCHEME_TYPE.CKKS, poly_modulus_degree=8192, coeff_mod_bit_sizes=[60, 40, 40, 60] ) # 设置全局缩放因子,影响浮点数精度 context.global_scale = 2**40 # 生成 Galois keys,用于向量内部的旋转操作 context.generate_galois_keys() - 可运行环境:标准的 Python 环境即可。同样建议使用虚拟环境。
# 创建虚拟环境 python -m venv he_env # 激活 source he_env/bin/activate # 安装库 pip install tenseal
三、核心实战 (同态加密)
场景:假设有两位用户,Alice 和 Bob,他们想计算两人健康数据(如心率、卡路里消耗)的平均值,但他们互相不信任,也不信任执行计算的第三方服务器。他们希望在不泄露各自原始数据的情况下完成计算。
实战步骤
-
初始化:服务器创建一个
TenSEAL上下文并生成密钥对(公钥、私钥)。服务器将公钥分发给 Alice 和 Bob,自己保留私钥(在真实场景中,私钥应由数据所有者或可信第三方持有,此处为简化演示)。 -
加密:Alice 和 Bob 各自用收到的公钥加密自己的健康数据向量。
-
发送与计算:Alice 和 Bob 将加密后的向量发送到服务器。服务器接收到两个密文向量后,执行同态加法,然后与一个明文向量
[0.5, 0.5, ...]进行同态乘法,以计算平均值。 -
返回与解密:服务器将计算得到的加密平均值向量返回给持有私钥的一方(或约定的数据使用者)。该方使用私钥解密,得到最终的明文平均值结果。
完整可运行示例
import tenseal as ts
import numpy as np
# -----------------------------------------------------------------------------
# 警告:本脚本仅用于授权测试和教育目的。
# 同态加密的参数选择对安全性和性能至关重要,生产环境需由专家配置。
# -----------------------------------------------------------------------------
def homomorphic_average_demo():
"""演示使用同态加密安全地计算两个向量的平均值。"""
# --- 1. 初始化 (通常在服务器或可信设置中完成) ---
print("--- 1. 初始化 TenSEAL 上下文和密钥 ---")
try:
context = ts.context(
ts.SCHEME_TYPE.CKKS,
poly_modulus_degree=8192,
coeff_mod_bit_sizes=[60, 40, 40, 60]
)
context.global_scale = 2**40
context.generate_galois_keys()
print("上下文创建成功。")
except Exception as e:
print(f"创建上下文失败: {e}")
return
# 密钥生成
secret_key = context.secret_key()
# 将公钥序列化,以便分发
public_key_serialized = context.serialize(save_public_key=True, save_secret_key=False, save_galois_keys=True, save_relin_keys=True)
print("密钥已生成,公钥已序列化准备分发。")
# --- 模拟客户端接收公钥 ---
# Alice 和 Bob 从服务器获取公钥并创建自己的上下文
alice_context = ts.context_from(public_key_serialized)
bob_context = ts.context_from(public_key_serialized)
# --- 2. 客户端加密数据 ---
print("\n--- 2. Alice 和 Bob 加密各自的数据 ---")
# Alice 的健康数据: [心率, 卡路里, 步数]
alice_data = [75.5, 320.0, 5120.0]
# Bob 的健康数据
bob_data = [82.0, 450.5, 7800.0]
print(f"Alice 的明文数据: {alice_data}")
print(f"Bob 的明文数据: {bob_data}")
# 使用各自的上下文加密
enc_alice_data = ts.ckks_vector(alice_context, alice_data)
enc_bob_data = ts.ckks_vector(bob_context, bob_data)
print("数据加密完成。")
# --- 3. 服务器端同态计算 ---
print("\n--- 3. 服务器在密文上执行计算 ---")
# 服务器接收到加密数据 enc_alice_data 和 enc_bob_data
# a. 同态加法
enc_sum = enc_alice_data + enc_bob_data
print("已完成同态加法 (enc_alice + enc_bob)。")
# b. 同态乘法 (与明文标量/向量相乘)
# 计算平均值,即乘以 0.5
enc_avg = enc_sum * 0.5
print("已完成同态乘法 (enc_sum * 0.5) 来计算平均值。")
# --- 4. 解密结果 ---
print("\n--- 4. 解密最终结果 ---")
# 服务器将加密结果 enc_avg 发送给持有私钥的一方
# 使用原始上下文(包含私钥)进行解密
context.data = enc_avg.serialize()
decrypted_avg = context.decrypt()
# 为了美观,对结果进行四舍五入
decrypted_avg_rounded = [round(x, 2) for x in decrypted_avg]
print(f"解密后的平均值: {decrypted_avg_rounded}")
# --- 验证正确性 ---
print("\n--- 5. 验证结果 ---")
expected_avg = [(a + b) * 0.5 for a, b in zip(alice_data, bob_data)]
expected_avg_rounded = [round(x, 2) for x in expected_avg]
print(f"在明文上直接计算的期望平均值: {expected_avg_rounded}")
# 使用 numpy 进行更精确的比较
np.testing.assert_array_almost_equal(decrypted_avg, expected_avg, decimal=1)
print("\n验证成功:同态计算结果与明文计算结果一致!")
if __name__ == "__main__":
homomorphic_average_demo()
输出结果示例:
--- 1. 初始化 TenSEAL 上下文和密钥 ---
上下文创建成功。
密钥已生成,公钥已序列化准备分发。
--- 2. Alice 和 Bob 加密各自的数据 ---
Alice 的明文数据: [75.5, 320.0, 5120.0]
Bob 的明文数据: [82.0, 450.5, 7800.0]
数据加密完成。
--- 3. 服务器在密文上执行计算 ---
已完成同态加法 (enc_alice + enc_bob)。
已完成同态乘法 (enc_sum * 0.5) 来计算平均值。
--- 4. 解密最终结果 ---
解密后的平均值: [78.75, 385.25, 6460.0]
--- 5. 验证结果 ---
在明文上直接计算的期望平均值: [78.75, 385.25, 6460.0]
验证成功:同态计算结果与明文计算结果一致!
这个输出清晰地展示了整个流程:数据在客户端被加密,服务器在不知道内容的情况下完成了求平均值的计算,最终解密的结果与直接在明文上计算的结果完全一致,证明了同态加密的正确性。
自动化脚本
为了将此能力产品化,我们需要一个更通用的脚本,能够处理任意数量的客户端和任意长度的向量数据。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import tenseal as ts
import numpy as np
import json
# -----------------------------------------------------------------------------
# 警告:本脚本仅用于授权测试和教育目的。
# 生产环境中的同态加密参数选择和密钥管理是极其严肃的安全问题。
# -----------------------------------------------------------------------------
class SecureAggregator:
"""一个使用同态加密进行安全聚合的服务器端类。"""
def __init__(self, poly_modulus_degree=8192):
"""
初始化聚合器,创建 TenSEAL 上下文和密钥。
:param poly_modulus_degree: int, 多项式模数次数,影响安全性和性能。
"""
try:
self.context = ts.context(
ts.SCHEME_TYPE.CKKS,
poly_modulus_degree=poly_modulus_degree,
coeff_mod_bit_sizes=[60, 40, 40, 60]
)
self.context.global_scale = 2**40
self.context.generate_galois_keys()
self.context.generate_relin_keys()
except Exception as e:
raise RuntimeError(f"初始化 TenSEAL 上下文失败: {e}")
def get_public_context(self):
"""序列化并返回公共上下文(不含私钥),用于分发给客户端。"""
return self.context.serialize(save_secret_key=False)
def aggregate_and_average(self, encrypted_vectors):
"""
对一组加密向量进行同态求和与平均。
:param encrypted_vectors: list, 包含序列化后的 CKKS 向量的列表。
:return: bytes, 序列化后的加密平均值向量。
"""
if not encrypted_vectors:
raise ValueError("加密向量列表不能为空。")
# 反序列化第一个向量作为累加起点
sum_vector = ts.ckks_vector_from(self.context, encrypted_vectors[0])
# 累加剩余的向量
for i in range(1, len(encrypted_vectors)):
enc_vec = ts.ckks_vector_from(self.context, encrypted_vectors[i])
sum_vector += enc_vec
# 计算平均值
avg_vector = sum_vector * (1 / len(encrypted_vectors))
return avg_vector.serialize()
def decrypt_result(self, encrypted_result):
"""
使用私钥解密最终结果。
:param encrypted_result: bytes, 序列化后的加密结果。
:return: list, 解密后的明文结果列表。
"""
result_vector = ts.ckks_vector_from(self.context, encrypted_result)
return result_vector.decrypt()
def client_encrypt_data(public_context_serialized, data):
"""
客户端函数,使用公共上下文加密数据。
:param public_context_serialized: bytes, 服务器分发的公共上下文。
:param data: list, 客户端的明文数据。
:return: bytes, 序列化后的加密向量。
"""
client_context = ts.context_from(public_context_serialized)
encrypted_vector = ts.ckks_vector(client_context, data)
return encrypted_vector.serialize()
def main():
"""主函数,模拟多客户端安全平均值计算场景。"""
parser = argparse.ArgumentParser(description="模拟使用同态加密进行多方安全平均值计算。")
parser.add_argument("--clients", type=int, default=5, help="模拟的客户端数量。")
parser.add_argument("--vector_size", type=int, default=4, help="每个客户端数据向量的维度。")
args = parser.parse_args()
print("--- 自动化同态加密聚合脚本 ---")
# 1. 服务器初始化
print(f"[服务器] 初始化安全聚合器...")
try:
aggregator = SecureAggregator()
public_context = aggregator.get_public_context()
print("[服务器] 初始化完成,已生成公共上下文。")
except RuntimeError as e:
print(e)
return
# 2. 客户端加密并上传数据
all_client_data = []
encrypted_data_from_clients = []
print(f"\n[客户端] {args.clients} 个客户端正在加密数据...")
for i in range(args.clients):
# 模拟生成客户端数据
client_data = np.random.rand(args.vector_size) * 100
all_client_data.append(client_data)
print(f" - 客户端 {i+1} 明文数据: {[round(x, 2) for x in client_data]}")
# 客户端加密数据
encrypted_vector = client_encrypt_data(public_context, client_data.tolist())
encrypted_data_from_clients.append(encrypted_vector)
print("[客户端] 所有数据已加密并发送至服务器。")
# 3. 服务器聚合计算
print("\n[服务器] 收到所有加密数据,开始同态聚合与平均计算...")
try:
encrypted_average = aggregator.aggregate_and_average(encrypted_data_from_clients)
print("[服务器] 计算完成,加密结果已生成。")
except ValueError as e:
print(f"[服务器] 错误: {e}")
return
# 4. 服务器(或授权方)解密结果
print("\n[授权方] 收到加密平均值,开始解密...")
decrypted_average = aggregator.decrypt_result(encrypted_average)
decrypted_average_rounded = [round(x, 2) for x in decrypted_average]
print(f"[授权方] 解密后的平均值: {decrypted_average_rounded}")
# 5. 验证
print("\n--- 验证结果 ---")
true_average = np.mean(np.array(all_client_data), axis=0)
true_average_rounded = [round(x, 2) for x in true_average]
print(f"明文直接计算的平均值: {true_average_rounded}")
np.testing.assert_array_almost_equal(decrypted_average, true_average, decimal=1)
print("\n验证成功!")
if __name__ == "__main__":
main()
使用方法:将代码保存为 he_auto_script.py,然后在命令行中运行。
# 使用默认参数(5个客户端,4维向量)运行
python he_auto_script.py
# 自定义参数运行
python he_auto_script.py --clients 10 --vector_size 8
这个脚本将同态加密的使用方法封装成了一个可复用的类,清晰地划分了服务器和客户端的职责,是构建真实隐私保护计算服务的原型。
四、进阶技巧
差分隐私 (DP)
- 常见错误:
- 重复使用隐私预算:对同一数据集的多次查询会累加消耗隐私预算。例如,对同一批用户数据,先查询平均年龄(消耗ε1),再查询平均收入(消耗ε2),总隐私预算消耗为ε1+ε2。必须通过组合性定理来管理总预算。
- 错误的敏感度计算:拉普拉斯机制中噪声的大小直接依赖于查询的全局敏感度。敏感度计算错误会导致隐私泄露或数据完全不可用。例如,对于求和查询,敏感度是数据范围的上限;对于均值查询,敏感度是
(upper-bound - lower-bound) / n。
- 性能/成功率优化:
- 收紧数据边界:
BoundedMean等算法的准确性高度依赖于你提供的数据上下界。边界越紧,为达到相同ε所需的噪声就越小,结果越精确。在预处理阶段,可以通过裁剪异常值(outliers)来设定一个更合理的范围。 - 选择合适的ε:
ε的选择是艺术而非科学。通常建议从一个较小的值(如0.1)开始,评估数据可用性,然后逐步增大。在实践中,ε的值通常在0.1到10之间,具体取决于法规要求和业务需求。
- 收紧数据边界:
- 实战经验总结:
- 差分隐私不是“是或否”的开关,而是一个带有成本的“旋钮”。隐私保护越强,数据效用损失越大。
- 本地差分隐私 (LDP) vs 中心化差分隐私 (CDP):我们演示的是CDP,需要一个可信的数据收集方。LDP则是在数据离开用户设备前就进行加噪,用户不需信任任何人。LDP的隐私保护更强,但需要更多数据才能获得同等的数据效用。
- 对抗/绕过思路:
- 重构攻击 (Reconstruction Attack):如果对一个数据集进行了过多的查询,即使每次都满足ε-DP,攻击者也可能通过解线性方程组的方式重构出部分原始数据。这就是隐私预算耗尽的后果。
- 利用辅助信息:差分隐私的承诺是“无法确定某一个体是否在数据集中”。但如果攻击者有强大的先验知识(例如,知道某人肯定在数据集中),他或许能推断出该个体数据的更精确范围。
同态加密 (HE)
- 常见错误:
- 参数选择不当:
poly_modulus_degree太小,安全性不足;太大,性能急剧下降。coeff_mod_bit_sizes决定了计算深度,如果乘法次数超过了参数允许的范围,会导致“噪声爆炸”,解密失败。 - 忽略明文槽 (Plaintext Slots):CKKS方案将一个向量打包到一个密文中进行SIMD(单指令多数据)运算。如果不理解这一点,可能会为每个数字单独加密,导致性能下降数千倍。
- 不处理缩放因子:在CKKS中,乘法会导致密文的
global_scale变化。必须通过重缩放 (rescaling) 操作来管理它,否则后续计算的精度会出问题。TenSEAL在一定程度上自动化了此过程,但深入使用时必须理解其原理。
- 参数选择不当:
- 性能/成功率优化:
- 批处理 (Batching):将多个数据点打包到一个
ckks_vector中,利用SIMD特性并行计算,这是HE性能优化的第一关键。 - 选择合适的加密方案:CKKS适合浮点数运算(机器学习),BFV/BGV方案适合整数运算(精确计数、数据库查询)。选对方案事半功倍。
- 优化计算电路:尽量减少乘法深度。例如,计算
x^4时,使用(x*x)*(x*x)(深度2)而不是x*x*x*x(深度3)。
- 批处理 (Batching):将多个数据点打包到一个
- 实战经验总结:
- 同态加密的性能开销是巨大的(计算速度慢几个数量级,密文体积大)。它不适合通用计算,只适用于对隐私要求极高的特定计算任务。
- 目前的HE主要用于隐私保护推理 (Inference),即在加密数据上运行已训练好的模型。用HE进行模型训练仍然是一个活跃的研究领域,计算开销极大。
- 对抗/绕过思路:
- 侧信道攻击 (Side-channel Attack):虽然HE在数学上是安全的,但其在物理硬件上的实现可能泄露信息。攻击者可以通过测量计算过程中的功耗、电磁辐射或计算时间来推断关于底层明文的信息。
- 恶意函数执行:如果客户端将加密数据发送给一个恶意的服务器,服务器虽然无法解密数据,但可以故意执行一个“错误”的函数(例如,将你的医疗数据乘以一个巨大的负数),返回一个无意义但加密的垃圾结果。这是一种对可用性的攻击。
五、注意事项与防御
差分隐私 (DP)
- 错误写法 vs 正确写法
- 错误:对一个数据集反复调用DP查询函数,每次都使用相同的ε,且不追踪总预算。
- 正确:使用
pydp.accounting等工具来追踪和管理总隐私预算的消耗,确保总ε在一个预设的安全阈值内。
- 风险提示:差分隐私保护的是“个体”,而非“群体”。如果一个群体的所有成员都具有某个共同的敏感属性,DP无法隐藏这个群体属性。
- 开发侧安全代码范式:
# 正确范式:封装DP逻辑,并强制进行预算管理 class PrivacyProtectedQuerier: def __init__(self, total_epsilon): self.total_epsilon = total_epsilon self.spent_epsilon = 0 # 使用 pydp.accounting.BudgetAccountant 进行管理 def query_mean(self, data, epsilon_per_query, bounds): if self.spent_epsilon + epsilon_per_query > self.total_epsilon: raise Exception("隐私预算耗尽!") # ... 执行查询 ... self.spent_epsilon += epsilon_per_query return dp_result - 运维侧加固方案:建立一个中心化的“隐私预算服务”,所有需要访问敏感数据的服务都必须向该服务申请预算,由该服务统一审计和管理。
- 日志检测线索:监控对敏感数据集的查询频率和次数。异常高频的查询,即使每次都声称使用了DP,也可能是隐私预算滥用或攻击的前兆。
同态加密 (HE)
- 错误写法 vs 正确写法
- 错误:在生产环境中使用默认或从教程中抄来的加密参数。
- 正确:根据所需的安全级别(如128位、256位安全)和计算深度,使用标准的安全参数生成指南(如HomomorphicEncryption.org的标准)来选择
poly_modulus_degree等参数。
- 风险提示:密钥管理是HE的阿喀琉斯之踵。私钥的泄露将导致所有历史和未来的数据被解密。
- 开发侧安全代码范式:
# 正确范式:严格分离密钥管理和计算逻辑 # 密钥管理模块(应在HSM或安全环境中) def generate_and_store_keys(): # ... 生成密钥并存储在硬件安全模块 (HSM) 中 ... pass # 计算模块 def perform_computation(public_context_serialized, encrypted_data): # 该模块完全接触不到私钥 context = ts.context_from(public_context_serialized) # ... 执行同态计算 ... return encrypted_result - 运维侧加固方案:
- 私钥管理:必须使用硬件安全模块(HSM)或可信执行环境(TEE,如Intel SGX)来存储和使用私钥。私钥永远不应以明文形式出现在内存或硬盘上。
- 公共参数验证:客户端在加密前应能验证服务器提供的公共上下文参数是否符合安全标准,防止服务器恶意提供弱参数。
- 日志检测线索:监控密文的大小和计算耗时。如果一个本应很快完成的计算任务耗时异常长,可能表明正在执行一个非预期的、复杂度很高的恶意计算。同时,审计所有对私钥的访问请求。
总结
- 核心知识:
- 差分隐私通过向统计结果中添加数学上精确控制的噪声,实现“数据可用但个体不可区分”。其核心是隐私预算
ε。 - 同态加密通过特殊的加密算法,实现“在密文上进行计算”,保证数据在处理过程中的机密性。其核心是支持加法和乘法运算。
- 差分隐私通过向统计结果中添加数学上精确控制的噪声,实现“数据可用但个体不可区分”。其核心是隐私预算
- 使用场景:
- DP:适用于大规模统计发布、隐私保护的机器学习模型训练(保护训练数据)。
- HE:适用于安全外包计算,如云端隐私保护数据分析、多方安全计算(保护计算过程)。
- 防御要点:
- DP防御:关键在于严格管理和审计隐私预算的消耗。
- HE防御:关键在于使用硬件安全模块(HSM) 等手段保护私钥的绝对安全。
- 知识体系连接:
- 这两种技术都属于隐私增强技术(PETs) 范畴,是构建零信任数据架构和满足合规要求(如GDPR)的重要工具。
- 它们经常与联邦学习(FL) 和安全多方计算(MPC) 结合使用,形成更强大的隐私保护解决方案。例如,在联邦学习中,可以使用DP保护每个参与方的模型更新,或使用HE安全地聚合这些更新。
- 进阶方向:
- DP:研究高级组合性定理(如zCDP)、不同噪声机制(如高斯机制)及其在复杂算法(如图算法)中的应用。
- HE:探索全同态加密的自举(Bootstrapping)过程,研究HE在神经网络推理中的优化技术,以及BFV/BGV等其他加密方案。
自检清单
- 是否说明技术价值?
- 是否给出学习目标?
- 是否有 Mermaid 核心机制图?
- 是否有可运行代码?
- 是否有防御示例?
- 是否连接知识体系?
- 是否避免模糊术语?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)