论文简读 | MiniCPM-V 4.5论文内容总结
多模态大语言模型是AI发展前沿,但训练和推理效率成为其落地与规模化的核心瓶颈。为此,论文提出8B参数的MiniCPM-V 4.5,核心改进包含三方面:**统一3D-Resampler架构** 实现图像和视频的高紧凑编码、**文档知识与文本识别的统一学习范式** 摆脱繁重的数据工程、**混合强化学习策略** 兼顾短/长推理模式的性能。OpenCompass评测显示,该模型超越GPT-4o-lates
论文地址:https://arxiv.org/pdf/2509.18154
发表时间:2025 年 9 月 16 日
模型地址:https://www.modelscope.cn/models/OpenBMB/MiniCPM-V-4_5
内容由豆包AI总结
多模态大语言模型是AI发展前沿,但训练和推理效率成为其落地与规模化的核心瓶颈。为此,论文提出8B参数的MiniCPM-V 4.5,核心改进包含三方面:统一3D-Resampler架构 实现图像和视频的高紧凑编码、文档知识与文本识别的统一学习范式 摆脱繁重的数据工程、混合强化学习策略 兼顾短/长推理模式的性能。OpenCompass评测显示,该模型超越GPT-4o-latest等闭源模型和Qwen2.5-VL 72B等大参数量开源模型,且效率突出——如在VideoMME基准上,仅用Qwen2.5-VL 7B 46.7%的GPU显存和8.7%的推理时间,就实现30B以下模型的SOTA性能。
1 Introduction
1.1 研究背景
MLLM能实现文本、图像等多模态的深度理解与推理,但发展过程中数据工程、训练、推理的成本剧增,效率问题成为研究和工业界的核心攻关方向,其效率瓶颈可拆解为三大核心问题:
- 模型架构:高分辨率图像编码产生大量视觉token,视频理解中该问题更严重(如短低清视频需上千token),带来巨大的显存和计算开销;
- 训练数据:文档(PDF/论文/教材)是MLLM的核心知识来源,但现有方法依赖脆弱的外部解析工具转换文档格式,易出错且需大量数据工程;
- 训练方法:强化学习(RL)提升复杂推理能力的同时,会导致模型输出过度冗长,即使简单任务也生成长文本,降低训练和推理效率。
1.2 核心改进
针对上述瓶颈,MiniCPM-V 4.5提出三大关键改进:
- 扩展2D-Resampler为统一3D-Resampler,联合压缩视频的时空信息,将短视频的token量降至128,实现12-24倍压缩,同时支持图像的统一编码;
- 提出文档知识与OCR的统一学习范式,通过动态给文档文本添加不同程度噪声,让模型自适应切换文本识别和上下文知识推理,无需外部解析工具;
- 设计混合RL后训练策略,在训练中随机交替短/长推理模式,实现双模式的灵活控制和性能互促,仅用33.3%的长推理样本即可匹配纯长推理模式的峰值性能。
1.3 研究贡献
- 开源高效高性能的MLLM——MiniCPM-V 4.5,支持高帧率/长视频理解、可控混合推理、鲁棒OCR和强文档解析能力;
- 提出三大技术改进:3D-Resampler编码架构、文档+OCR统一学习范式、混合后训练策略,兼顾性能与效率;
- 通过全面实验验证了所提技术的有效性和模型的综合性能。
2 Approach
本章详细阐述MiniCPM-V 4.5的方法论,包括模型架构、预训练、有监督微调(SFT)、强化学习(RL) 四大核心部分。
2.1 Architecture
模型架构由三大核心模块组成:轻量级视觉编码器、统一3D-Resampler、LLM解码器,核心是统一3D-Resampler,实现图像和视频的高效紧凑编码,且支持短/长推理模式的输出。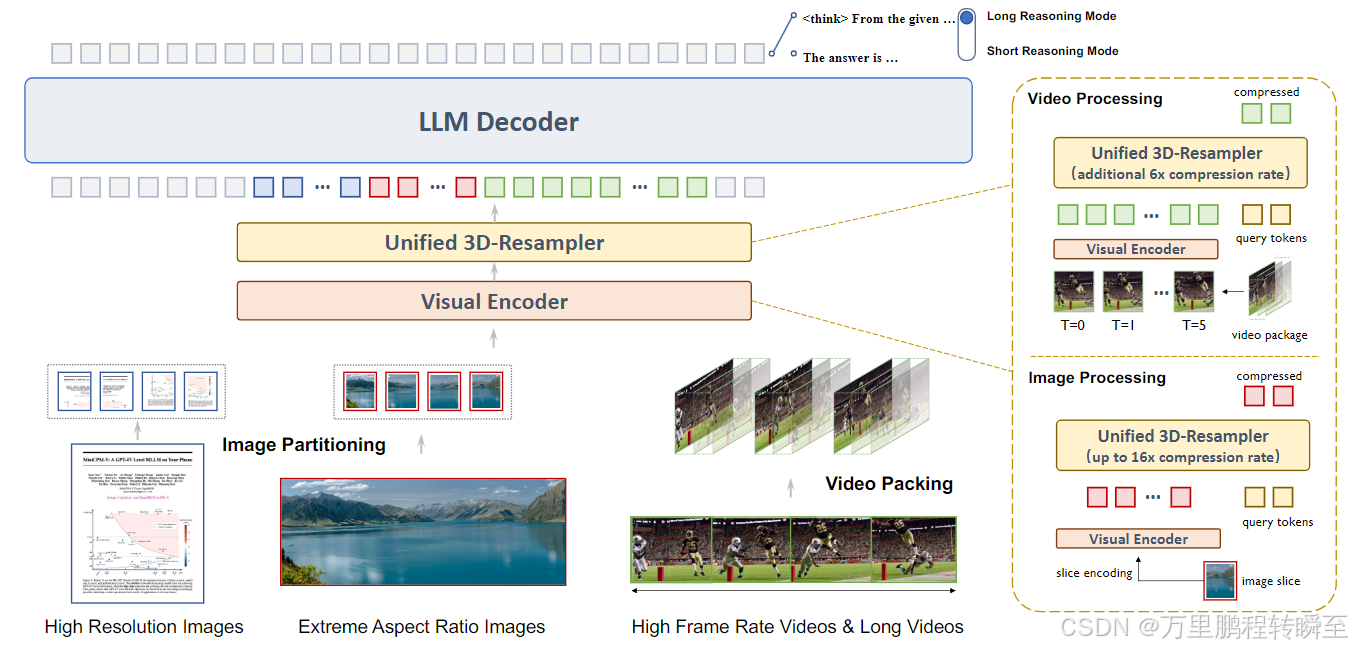
该模型可处理多种视觉输入,包括高分辨率图像和高帧率视频。经过图像分割与视频分块打包处理后,这些输入首先由视觉编码器进行编码,随后送入统一 3D 重采样器(unified 3D-Resampler)。该模块能够高效地将图像和视频特征压缩为紧凑的令牌序列(图像压缩率最高可达 16 倍,视频在此基础上可再实现 6 倍压缩),并将其输入至大语言模型(LLM)解码器。解码器支持两种截然不同的响应生成模式:简洁的短推理模式与分步式的长推理模式。
- 图像处理:采用LLaVA-UHD图像分割策略适配任意高分辨率图像,通过带2D空间位置嵌入的可学习查询token,将448×448图像的编码token降至64(主流模型需256),实现最高16倍压缩;
- 视频处理:将视频按时间维度分块,对每块进行联合时空压缩,查询token添加2D空间+时间位置嵌入,单帧视觉token仅21.3(2D基线为64),整体实现96倍视频token压缩,支持最多1080帧、10fps的视频处理,训练中随机增强块大小和帧率提升鲁棒性;
- 训练效率:3D-Resampler对输入形状无依赖,图像和视频编码共享架构和权重,可通过轻量级SFT从2D-Resampler扩展而来,且实现图像到视频的知识迁移(如无专门训练仍具备视频OCR能力)。
2.2 Pre-training
采用渐进式多阶段预训练策略,结合精心筛选的多模态数据,并提出文档知识与OCR的统一学习范式,系统性构建模型基础能力。
- 预训练策略(三阶段)
- 阶段1:仅训练2D-Resampler,冻结其他模块,用图像-标题数据实现视觉-语言模态的初始对齐,训练成本最低;
- 阶段2:解冻视觉编码器,用OCR富数据+图像-标题数据增强感知能力,冻结LLM解码器(数据质量不足以支撑语言建模);
- 阶段3:端到端训练所有参数,解冻LLM解码器,使用文本语料、图像-文本交错数据、视频数据等高质量数据,实现多图像推理和时间理解,采用Warmup-Stable-Decay学习率调度,衰减阶段逐步加入高难度指令和知识密集型数据。
- 预训练数据:涵盖图像标题、图像-文本交错、OCR、文档、视频标题五类数据,均经过过滤、重标注、增强等处理,保证数据质量和多样性;
- 文档知识与OCR的统一学习范式
- 核心思路:以从损坏的文档图像中预测原始文本为单一学习目标,通过动态给文本区域添加低/中/高三种噪声,让模型自适应切换能力,摆脱外部解析工具,同时避免过增强导致的幻觉问题;
- 三种训练任务:低噪声实现增强OCR、中噪声实现视觉线索+上下文的融合推理、高噪声实现纯上下文的文档知识推理,最大化数据利用率,同时提升文档解析和OCR双能力。
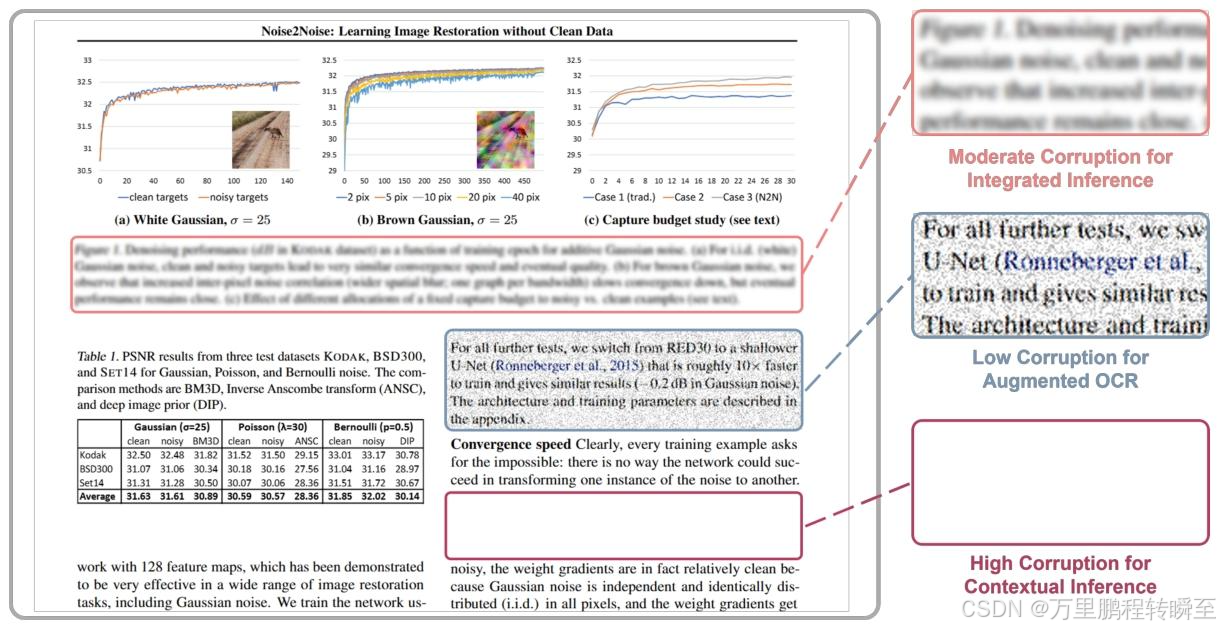
基于动态视觉干扰的文档知识与光学字符识别(OCR)统一学习范式 我们通过设置不同的干扰程度构建了一系列训练任务:低程度干扰保留文本的可识别性,用于训练模型实现鲁棒的光学字符识别能力;高程度干扰迫使模型开展上下文推理;中等程度干扰则要求模型结合视觉线索与上下文进行融合推理。
2.3 Supervised Fine-tuning(SFT)
目标是激活模型的多任务能力,为RL做准备,并在该阶段将2D-Resampler扩展为3D-Resampler,提升视频压缩效率,分为两个阶段:
- SFT策略
- 阶段1(通用SFT):用高质量指令-回复数据微调,激活预训练的通用知识,实现多模态交互对齐,加入10%纯语文本数据防止文本性能退化;
- 阶段2(Long-CoT+3D-Resampler):引入Long-CoT预热指令,让模型学会分步显式推理(长推理模式);同时升级为3D-Resampler,加入高帧率/长视频数据,实现时间理解能力的增强,且因架构统一,仅需少量高质量视频数据即可完成升级。
- SFT数据:包含STEM数据(视觉依赖的多学科问题)、长尾知识数据(维基百科构建)、Long-CoT数据(聚焦模型薄弱的挑战性提示,经多阶段验证和改写),核心结论:过滤简单提示、聚焦挑战性问题是Long-CoT预热的关键。
2.4 Reinforcement Learning(RL)
目标是提升推理性能、实现推理模式可控、降低幻觉,核心是混合RL策略,并结合奖励质量控制、奖励塑造、RLAIF-V等技术。
- RL数据:涵盖数学、文档/表格/图表、通用推理、指令跟随四大领域,均经过人工参与的清洗和去重,保证数据质量;
- 奖励质量控制:从标签准确性(人工清洗)、奖励准确性(简单答案用规则验证,复杂答案用RLPR概率奖励)、奖励覆盖度(加入奖励模型实现人类偏好对齐)三方面保障奖励信号的可靠性;
- 混合强化学习:支持提示控制的短/长推理模式,SFT初始化双模式能力,RL训练中随机交替两种模式的rollout,采用GRPO优化且移除KL/熵损失提升稳定性,实现双模式的交叉泛化(长推理提升短推理的分析能力,短推理让长推理更简洁);
- 奖励塑造:最终奖励由准确性、格式、重复惩罚、偏好奖励四部分加权组成,偏好奖励仅对长推理模式的最终答案打分,避免规则模型无法评估长推理链的问题,提升训练稳定性;
- RLAIF-V:针对视觉幻觉问题,将AI反馈扩展至视频模态,通过响应采样、原子声明分解验证、偏好学习(DPO) 三步,让模型输出更贴合视觉输入的事实,且不损失语言流畅性。
3 Experiments
本章通过主评测、推理效率分析、消融实验,从定量和定性角度验证MiniCPM-V 4.5的性能、效率及所提技术的有效性。
3.1 Baselines and Benchmarks
- 对比基线:三类模型——Qwen2.5-VL 72B等SOTA开源模型、InternVL3 8B/GLM-4.1V 9B等同参数量模型、GPT-4o-latest等前沿闭源模型;
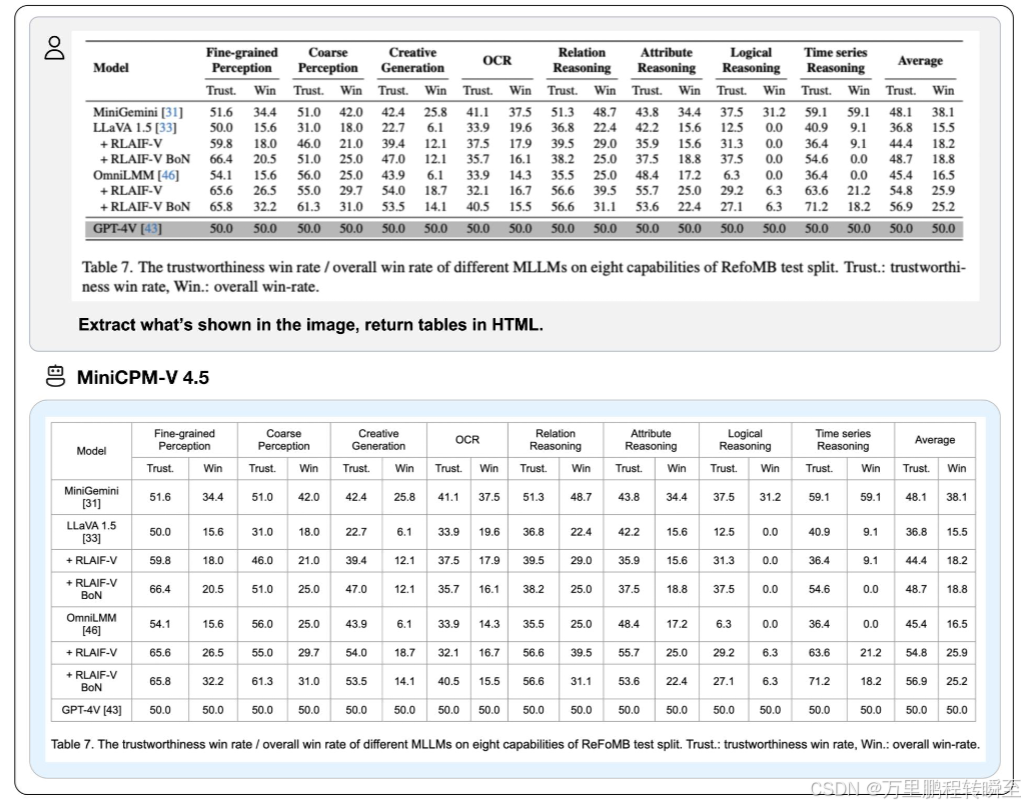
- 评测基准:覆盖六大能力维度,共30+基准,包括综合多模态理解(OpenCompass/MMVet)、STEM推理(MMMU/MathVista)、文档/OCR/图表(OCRBench/DocVQA)、幻觉评估(HallusionBench/ObjHalBench)、多图像/现实世界/指令跟随(Mantis/RealWorldQA)、视频理解(Video-MME/LongVideoBench)。
3.2 Main Results
MiniCPM-V 4.5在8B参数下实现性能与效率的双重领先,核心结果如下:
- 综合能力:OpenCompass获77.0分,超越GPT-4o-latest(75.4)和Qwen2.5-VL 72B(76.1),为30B以下模型最高分;
- 视频理解:在Video-MME、MotionBench、FavorBench等高帧率/长视频基准上表现优异,为30B以下模型SOTA;
- OCR与文档分析:OCRBench获89.0分超越GPT-4o-latest,OmniDocBench的PDF解析能力为通用MLLM中的SOTA;
- 幻觉抑制:在ObjHalBench、MMHal-Bench等基准上的幻觉率显著低于其他模型,RLAIF-V的引入大幅提升了模型的可信度;
- STEM推理:在MMMU、MathVista等核心基准上,性能接近/超越9B/72B参数量的对比模型,展现强视觉-逻辑融合推理能力。
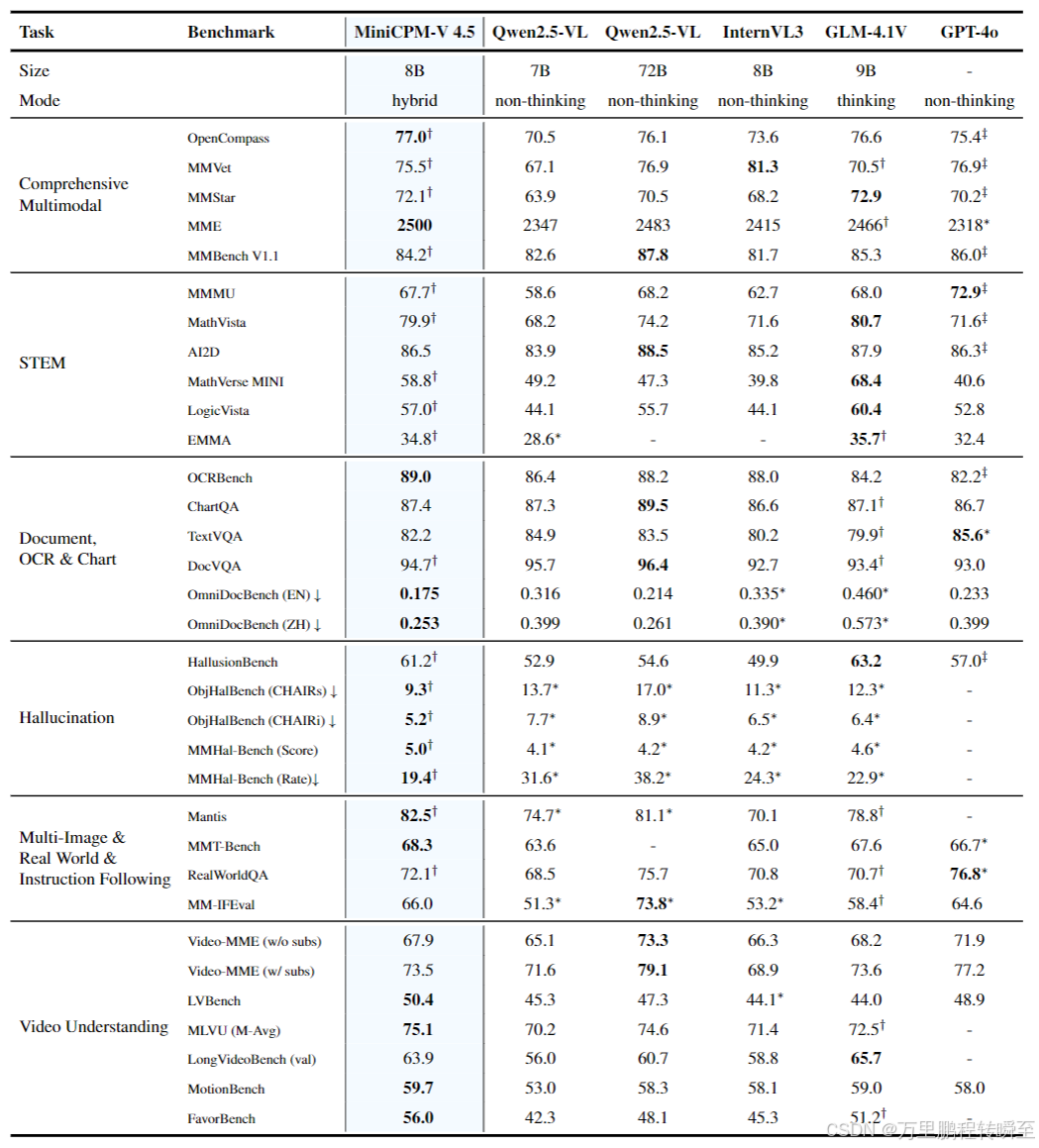
多类视觉 - 语言评测基准的综合评估结果
最优性能以粗体标注。
∗ 表示相关模型的评估基于我们自行对其官方发布的权重检查点(checkpoint)进行的测试。
† 表示评估所采用的推理模式,为保证评估结果的鲁棒性,表中数据为三次独立运行后的平均得分。
‡ 表示 GPT-4o-latest 的评估结果源自 OpenCompass 评测平台;其余场景下均使用 GPT-4o-1120 进行评估,原因是 GPT-4o-latest 仅支持通过网络应用程序接口(Web API)调用。
3.3 Inference Efficiency
在8张A100 GPU的标准配置下,模型的推理效率大幅领先对比模型:
- OpenCompass评测:仅用7.5h完成评测,是GLM-4.1V 9B(17.5h)的42.9%,且得分更高;
- Video-MME评测:获73.5分的同时,仅用0.26h推理时间(GLM-4.1V 9B为2.63h,近10倍提速),GPU显存仅28G(为Qwen2.5-VL 7B的46.7%);
- 效率优势的核心来源:3D-Resampler的时空联合压缩(视频编码)、混合RL的双推理模式灵活切换(图像/综合任务)。

3.4 Ablations
针对核心技术进行消融实验,验证各模块的有效性,核心结论:
-
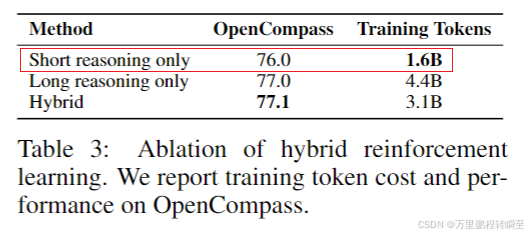
混合RL策略:相比纯短/纯长推理模式,混合模式在OpenCompass获最高分77.1,且仅用3.1B训练token(纯长模式为4.4B),实现更少样本、更高性能、更低成本;
-
规则+概率混合奖励:相比纯规则奖励,混合奖励让模型在OpenCompass的得分更高,且响应长度和熵更稳定,为通用推理提供更可靠的奖励信号;
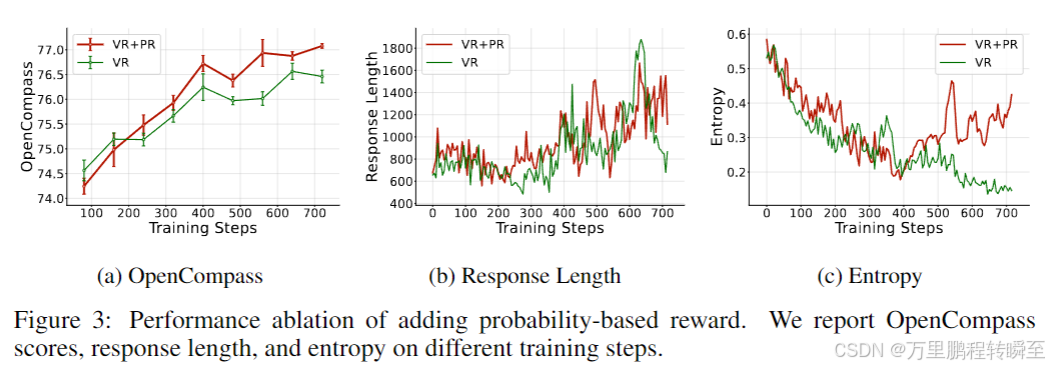
-
文档+OCR统一学习范式:相比基于外部解析工具的基线,统一范式在MMMU、AI2D、OCRBench上均有提升,有效减少了解析工具引入的噪声;
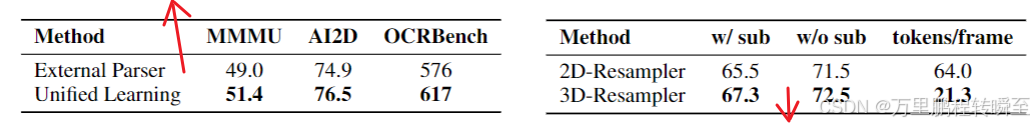
-
3D-Resampler:相比2D-Resampler,3D版本在Video-MME上的得分更高(71.5 vs 65.5),且单帧视觉token仅为2D版本的1/3,实现更低token成本、更高视频理解性能。
4 Conclusion
论文总结了MiniCPM-V 4.5的核心设计和价值:
- 该模型通过架构、数据、训练方法的三重创新,实现了MLLM训练和推理的高效性,8B参数下超越多款大参数量开源模型和主流闭源模型;
- 3D-Resampler架构实现了图像/视频的统一高效编码,为高帧率/长视频理解提供了新方案;
- 文档知识与OCR的统一学习范式,摆脱了对外部解析工具的依赖,大幅降低了数据工程的复杂度;
- 混合RL后训练策略,实现了短/长推理模式的可控性和性能互促,同时提升了训练和推理效率;
- MiniCPM-V 4.5为解决MLLM的效率瓶颈提供了可行路径,为高效多模态模型的研发和落地奠定了基础。
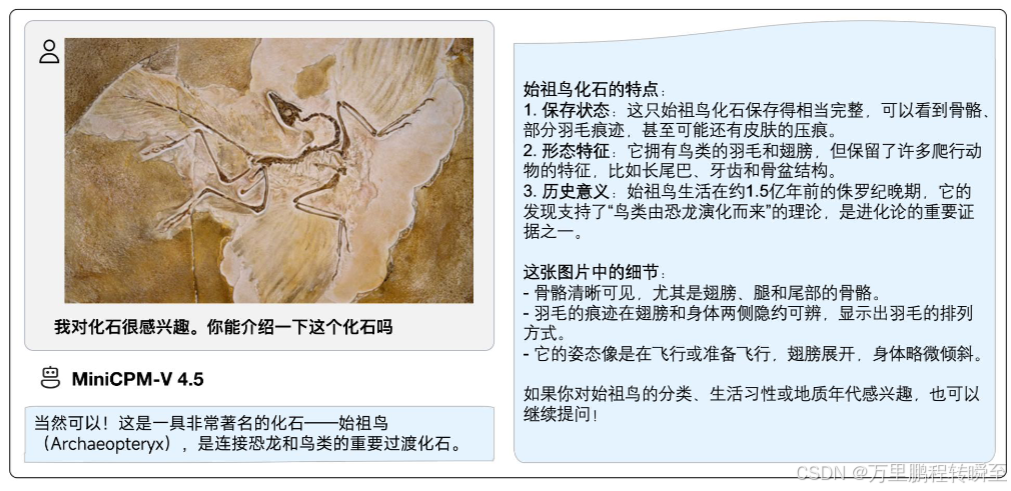
案例



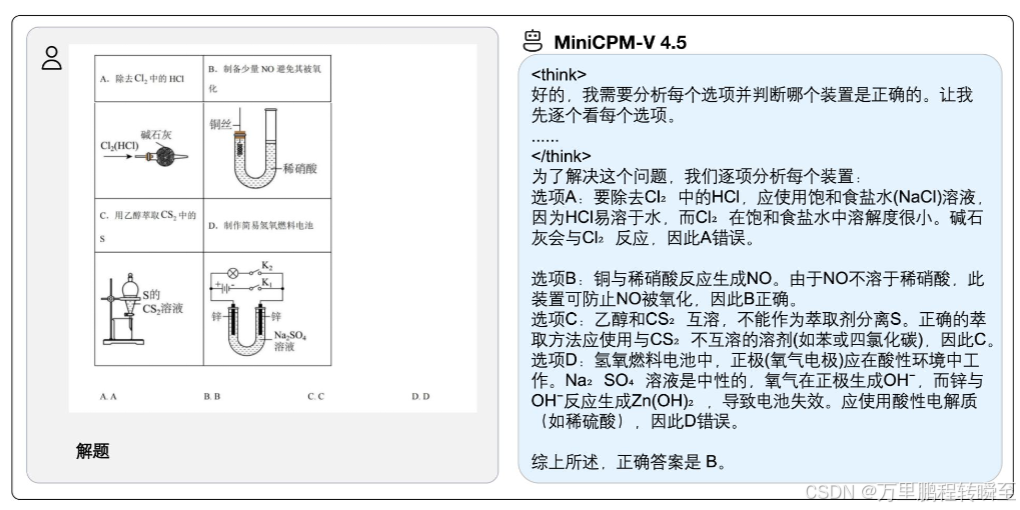
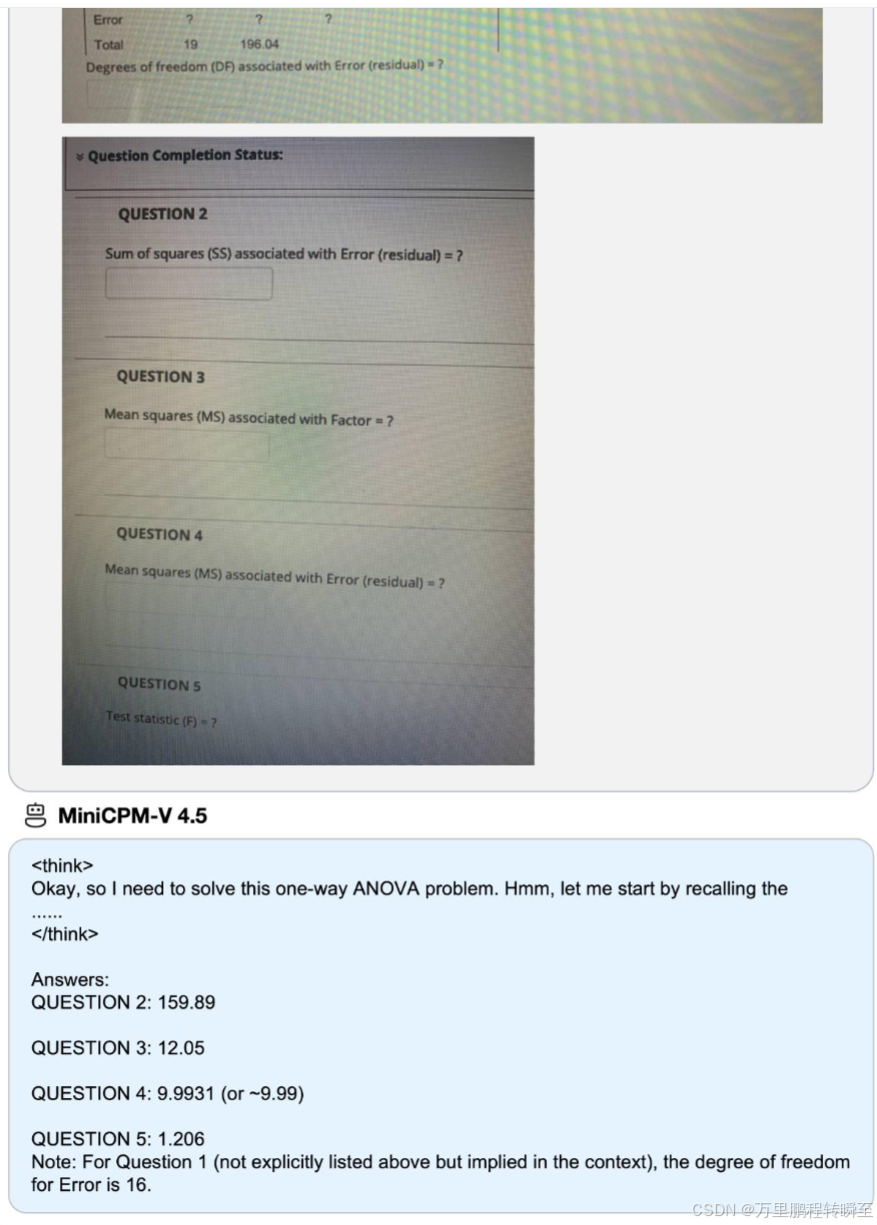

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)