小白程序员轻松入门vLLM,让大模型推理更快更省!
vLLM 是一个专为大语言模型(LLM)的开源推理框架,由加州大学伯克利分校推出。它通过 PagedAttention(分页注意力)和 Continuous Batching(连续批处理)两大核心技术,显著提升大模型推理的速度和效率,降低显存占用和延迟。vLLM 兼容 OpenAI API,支持多种量化格式,适合个人开发者、初创公司及研究者使用,是当前开源生态中最值得优先尝试的推理引擎之一。
vLLM 是一个专为大语言模型(LLM)的开源推理框架,由加州大学伯克利分校推出。它通过 PagedAttention(分页注意力)和 Continuous Batching(连续批处理)两大核心技术,显著提升大模型推理的速度和效率,降低显存占用和延迟。vLLM 兼容 OpenAI API,支持多种量化格式,适合个人开发者、初创公司及研究者使用,是当前开源生态中最值得优先尝试的推理引擎之一。
一、vLLM 是什么?
vLLM(发音为 “vee-L-L-M”)是一个专为大语言模型(LLM)的开源推理框架。它由加州大学伯克利分校的 Sky Lab 团队于 2023 年推出,目标是:
让大模型推理更快、更省显存、更便宜,同时保持高吞吐和低延迟。
简单说:
- 如果你用 Hugging Face 的
transformers直接跑 Llama 3,可能每秒只能处理 5 个请求; - 但用 vLLM,同样一块 GPU,每秒能处理 100+ 个请求,而且响应还不慢!
二、vLLM 为什么这么快?核心技术创新
vLLM 的高性能主要来自两大核心技术:
- PagedAttention(分页注意力)
- Continuous Batching(连续批处理)
下面我们逐个拆解,并用生活中的例子帮你理解。
技术 1:PagedAttention(分页注意力)
🔍 问题背景:
大模型生成文本时,需要记住之前说过的内容(比如对话历史),这部分记忆叫 KV Cache(Key-Value 缓存)。
- KV Cache 非常占显存!
- 传统方法像“整块租房子”:即使只用一半空间,也得付全款,还不能灵活调整。
🌰 举个生活例子:
想象你要在城市里租仓库放货物(KV Cache):
-
传统方式
你预估最多放 100 箱货,就租一个 100 箱的大仓库。结果今天只来了 30 箱,70% 空着,但租金照付。
-
vLLM 的 PagedAttention
像“共享仓储”——把大仓库切成小格子(比如每格 10 箱),你用多少格就付多少钱。30 箱?租 3 格就行!空出来的格子还能给别人用。
💡 专业解释:
- PagedAttention 借鉴了操作系统中的“虚拟内存分页”机制。
- 它把每个请求的 KV Cache 切成固定大小的“页”(page),这些页在显存中不连续存储,但通过索引表关联。
- 好处:
- 显存利用率提升 2–4 倍
- 几乎消除显存碎片
- 支持动态增长(对话越长,自动加页)
✅ 结果:原来跑不动 32K 上下文的模型,现在轻松跑;原来要 2 块 GPU,现在 1 块就够了。
技术 2:Continuous Batching(连续批处理)
🔍 问题背景:
用户请求是随机到达的——有人问“你好”,有人写 1000 字论文。
- 传统“静态批处理”:等凑够 8 个请求再一起算。但短请求要等长请求,延迟很高!
- 就像公交车:必须坐满 20 人才发车,第 1 个上车的人可能等半小时。
🌰 生活例子:
- 传统批处理 = 公交车(固定班次,必须满员)
- vLLM 的 Continuous Batching = 出租车队(来一个客人就派一辆车,但后台智能拼车)
具体怎么拼?
- 请求 A(短)先进 GPU;
- 请求 B(长)进来后,只要 GPU 还有空闲计算单元,就立刻加入当前批次;
- 请求 A 生成完就退出,B 继续,新请求 C 又加入……
→ GPU 始终满负荷运转!
💡 专业解释:
- Continuous Batching = 动态、异步的请求调度
- 每个请求独立管理自己的 KV Cache(多亏 PagedAttention)
- 调度器实时监控 GPU 负载,随时插入/移除请求
- 效果:
- 吞吐量提升 10–30 倍
- P99 延迟显著降低
✅ 结果:系统既能服务“快速问答”,也能处理“长文生成”,互不拖累。
三、vLLM 的其他关键特性
1. 兼容 OpenAI API
- 你写的调用代码如果是
openai.ChatCompletion.create(...),不用改一行,直接把 endpoint 指向 vLLM 服务就行! - 对应用开发者极度友好。
2. 支持多种量化格式
-
量化
= 把模型参数从高精度(如 FP16)转为低精度(如 INT4),大幅减小模型体积和显存占用。
-
vLLM 支持:
- AWQ(权重量化,精度损失小)
- GPTQ(训练后量化)
- FP8(NVIDIA 新一代低精度格式)
- 举例:Llama-3-8B 原本要 16GB 显存,INT4 量化后只需 6GB,普通消费级显卡(如 RTX 4090)就能跑!
3. 高效上下文管理
- 支持超长上下文(32K、128K tokens)
- 多轮对话时,自动复用历史 KV Cache,避免重复计算
4. 流式输出(Streaming)
- 用户提问后,逐字返回(像 ChatGPT 那样打字效果),而不是等全部生成完才显示。
- 提升用户体验,尤其对长回答很重要。
四、vLLM 的典型使用方式
方式 1:命令行启动(最简单)
# 安装
pip install vllm
# 启动 Llama-3-8B 服务
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--tensor-parallel-size 1 \
--host 0.0.0.0 \
--port 8000
然后你的应用就可以像调用 OpenAI 一样调用它:
import openai
client = openai.OpenAI(base_url="http://localhost:8000/v1", api_key="token")
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3-8B-Instruct",
messages=[{"role": "user", "content": "你好!"}]
)
方式 2:Kubernetes 部署(生产环境)
- 使用 Helm Chart 或 Docker 镜像部署到云集群
- 配合 Prometheus 监控 GPU 利用率、QPS、延迟
五、vLLM 适合谁用?
| 用户类型 | 是否推荐 | 说明 |
|---|---|---|
| 个人开发者 | ✅ 强烈推荐 | 本地快速体验大模型,比 transformers 快得多 |
| 初创公司 | ✅ 首选 | 低成本实现高并发 API 服务 |
| 大厂/云厂商 | ✅ 核心组件 | AWS、阿里云、Databricks 等均已集成 vLLM |
| 研究者 | ✅ | 快速验证新模型推理性能 |
六、常见误区澄清
| 误区 | 正确理解 |
|---|---|
| “vLLM 是一个模型” | ❌ vLLM 是推理引擎,不是模型。它加载 Llama、Qwen 等模型来运行 |
| “vLLM 只支持 NVIDIA GPU” | ✅ 目前主要优化 CUDA,未来可能支持 ROCm(AMD) |
| “vLLM 能训练模型” | ❌ 仅用于推理(inference),不能训练 |
| “vLLM 比 TensorRT-LLM 快” | ⚠️ 在 A100/H100 上,TensorRT-LLM 极致优化后可能略快,但 vLLM 易用性更好、社区更活跃 |
七、总结:vLLM 的核心价值
| 技术 | 解决的问题 | 用户收益 |
|---|---|---|
| PagedAttention | KV Cache 显存浪费、碎片化 | 省显存、支持长上下文 |
| Continuous Batching | GPU 利用率低、延迟高 | 高吞吐、低延迟、省钱 |
| OpenAI 兼容 API | 接入成本高 | 无缝替换,零代码改造 |
| 量化支持 | 模型太大跑不动 | 消费级显卡也能跑大模型 |
💡 一句话记住 vLLM:
“用操作系统的智慧(分页内存 + 动态调度),让大模型推理又快又省!”
如果你正在构建基于大模型的应用,vLLM 几乎是当前开源生态中最值得优先尝试的推理引擎。它不仅性能强悍,而且上手简单,已成为行业事实标准之一。
最后
我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
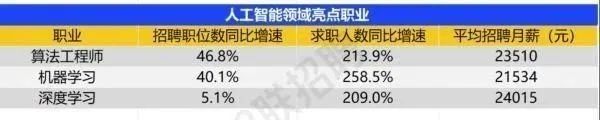
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献998条内容
已为社区贡献998条内容

所有评论(0)