大模型分布式训练策略全攻略:从拆数据到拆模型,一篇搞定!
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。真诚无偿分享!!!vx扫描下方二维码即可加上后会一个个给大家发。
大模型分布式训练策略:从“拆数据”到“拆模型”
分布式训练的本质是“拆分任务、协同计算”,不同策略的核心差异在于“拆什么”“怎么协同”,以下为三种主流策略的适用场景与实操要点。
- 数据并行:入门级首选策略
核心逻辑:将训练数据切分为多个mini-batch,每个设备(GPU/TPU)加载完整模型,各自计算梯度后同步更新参数。
实操案例:4张GPU训练10亿参数BERT-base(单卡可容纳)
- 数据拆分:100万条文本按4:1:1:1分配,每张GPU处理25万条;
- 计算流程:单卡算梯度→AllReduce通信(NCCL协议)汇总梯度→取平均值更新全量参数;
- 工具选择:PyTorch的DDP(DistributedDataParallel),多进程架构比早期DP更稳定,支持多机多卡。
优缺点
- 优势:代码改动小(仅需3-5行DDP初始化代码),适配“模型能装下、数据量超大”场景(10亿参数内模型+千万级数据集);
- 痛点:设备数超8张时,梯度同步通信开销陡增(16张GPU通信耗时占比可达30%),单卡存完整模型导致显存浪费。
- 模型并行:突破单卡显存限制
核心逻辑:拆分模型结构,每个设备仅加载部分模型,通过设备间传递中间结果完成计算。
实操案例:2张GPU训练50亿参数GPT-2(单卡显存不足)
- 模型拆分:将24层Transformer拆分为前12层(GPU 0)、后12层(GPU 1);
- 计算流程:输入数据在GPU 0算前12层隐藏态→传递至GPU 1算后12层并输出损失→反向传播时梯度回传GPU 0,各自更新参数;
- 进阶优化:模型较宽时(如注意力头数多),可按维度拆分(12个注意力头拆为6+6),减少中间结果传输量。
优缺点
- 优势:解决“超大模型单卡装不下”问题,显存利用率比数据并行高50%以上;
- 痛点:设备间依赖强(GPU 1需等待GPU 0计算完成),易出现负载不均(部分GPU空闲)。
- 混合并行:超大规模模型最优解
核心逻辑:结合“模型并行拆结构”与“数据并行拆数据”,是千亿级模型训练的主流方案。
实操案例:8张GPU训练1750亿参数GPT-3
- 混合拆分:先按模型并行将96层Transformer拆为8段(每段12层对应1张GPU),再按数据并行将批次数据拆为4份,用4个“8卡模型组”同步训练;
- 计算流程:单“8卡组”内按模型并行完成全量计算→组间按数据并行同步梯度→全局更新参数;
- 工业界实践:OpenAI训练GPT-3采用“模型并行+数据并行+流水线并行”的3D混合并行,训练效率提升3倍。
优缺点
- 优势:兼顾“大模型装下”与“大数据加速”,支持千亿级模型在百卡集群训练;
- 痛点:实现复杂(需协调拆分粒度与比例),依赖高级API(如Megatron-LM的3D并行接口)。
主流框架实操:配置与避坑指南
选择合适框架并规避实操问题是落地关键,以下为三大主流框架的核心配置、避坑经验及性能对比。
- PyTorch生态:中小团队性价比之选
PyTorch原生工具+扩展库可支撑100亿参数内模型训练,上手成本低。
(1)DDP(数据并行)关键代码
# 1. 初始化分布式环境
import torch.distributed as dist
dist.init_process_group(backend="nccl", init_method="env://") # NCCL为GPU通信最优后端
# 2. 定义模型并包装DDP
model = BertModel.from_pretrained("bert-base-uncased")
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank]) # local_rank为当前设备ID
# 3. 数据加载(需用DistributedSampler拆分数据)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = DataLoader(train_dataset, sampler=train_sampler, batch_size=32)
(2)FSDP(混合并行):解决大模型显存不足
FSDP是PyTorch 1.11+原生支持的参数分片工具,可将模型参数、梯度、优化器状态拆到多卡,显存占用比DDP低70%。
关键配置:
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
model = FSDP(
BertModel.from_pretrained("bert-large-uncased"),
auto_wrap_policy=transformer_auto_wrap_policy, # 自动识别Transformer层拆分
sharding_strategy=ShardingStrategy.FULL_SHARD # 全分片模式(显存最优)
)
避坑指南:
- FSDP需用多进程启动(如torchrun),不可用单进程多线程;
-自定义模型层需手动编写autowrappolicy,避免拆分不彻底导致显存溢出。
- DeepSpeed:显存优化神器
DeepSpeed主打“少卡训大模型”,核心为ZeRO(零冗余优化器),适配200亿参数以上模型。
(1)ZeRO-3核心配置(ds_config.json)
{
"train_batch_size": 128,
"gradient_accumulation_steps": 4,
"optimizer": {"type": "AdamW"},
"zero_optimization": {
"stage": 3, # 1=优化器分片,2=梯度+优化器分片,3=全部分片
"offload_optimizer": {"device": "cpu"} # 优化器状态存CPU,进一步省显存
},
"fp16": {"enabled": true} # 混合精度训练,显存再省50%
}
(2)工业界案例:8张A100训130亿参数LLaMA-2
- 硬件:8张A100(40GB显存);
- 优化方案:ZeRO-3 + CPU Offload + FP16混合精度;
- 效果:单卡显存占用从“溢出”降至28GB,训练速度比纯FSDP快25%。
避坑指南:
- 卡显存充足(如A100 80GB)时,可关闭CPU Offload以减少通信耗时;
- 需用DeepSpeed的initialize接口包装模型,不可直接用PyTorch DDP。
- Megatron-LM:千亿模型训练利器
专为Transformer设计,支持3D并行(数据+模型+流水线),适配超大规模集群(百卡以上)。
(1)3D并行启动命令(关键参数)
torchrun --nproc_per_node=8 train.py \
--model-parallel-size 2 \ # 模型并行维度(8卡拆为4组,每组2卡)
--data-parallel-size 4 \ # 数据并行维度(4组同步训练)
--pipeline-model-parallel-size 2 # 流水线并行维度(每组2卡按层拆流水线)
(2)典型案例:1024张A100训5300亿参数Megatron-Turing NLG
- 并行策略:3D并行(模型并行=8,数据并行=128,流水线并行=1);
- 核心优化:流水线并行“气泡消除”(重叠计算与通信减少空闲);
- 效果:训练周期从半年缩短至1个月,算力利用率达80%(行业平均约60%)。
- 2024前沿:FlashAttention-2与分布式协同
FlashAttention-2从注意力计算底层优化,与分布式策略形成“1+1>2”效果,是2024年必用技术。
(1)技术原理
传统注意力计算内存访问量随序列长度二次增长,导致分布式场景中中间结果传输量大、梯度同步效率低。FlashAttention-2通过三大优化解决:
- GPU硬件感知重排:拆分计算适配GPU SRAM,减少90% HBM访问量;
- 线程块分区优化:重构工作分配,长序列算力利用率从40%升至73%;
- 原生支持大序列与GQA/MQA:适配32k上下文(如GPT-4)。
在A100上,FlashAttention-2训练速度达225 TFLOP/s,是传统实现的5-9倍,显存占用降低56%。
(2)PyTorch 2.2集成实操
# 1. 确保PyTorch版本≥2.2
import torch
assert torch.__version__ >= "2.2.0", "需升级PyTorch到2.2+"
# 2. 模型中启用FlashAttention-2
classTransformerLayer(torch.nn.Module):
def__init__(self):
super().__init__()
self.attn = torch.nn.MultiheadAttention(...)
defforward(self, x):
attn_output = torch.nn.functional.scaled_dot_product_attention(
query=x, key=x, value=x,
attn_mask=torch.nn.functional.causal_mask(x.size(1)),
dropout_p=0.1,
is_causal=True# 启用因果掩码优化
)
return attn_output
# 3. 与FSDP结合启动(torchrun --nproc_per_node=8 train.py)
model = FSDP(TransformerModel(), auto_wrap_policy=...)
(3)分布式性能对比(32卡训100亿参数模型)
| 方案 | 单卡显存占用 | 训练速度 | 通信耗时占比 |
|---|---|---|---|
| DDP + 标准注意力 | 38GB | 1x | 35% |
| FSDP + 标准注意力 | 22GB | 1.2x | 28% |
| FSDP + FlashAttention-2 | 16GB | 2.1x | 15% |
工业界案例:32张A100训100亿参数长文本模型(16k上下文),训练周期从14天缩至6天,成本降57%,序列长度支持从8k提升至16k。
- 跨框架性能对比(8张A100训100亿参数LLaMA-2)
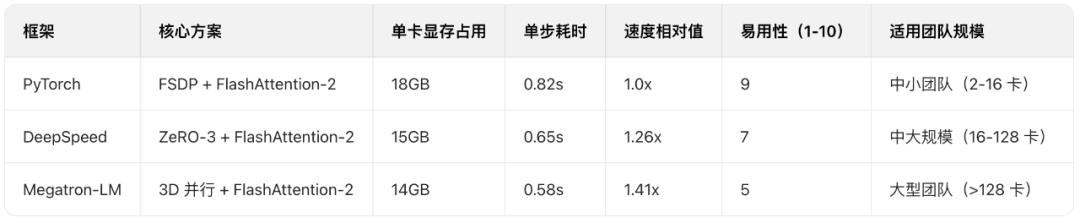
数据解读:
- 显存:DeepSpeed ZeRO-3显存降幅44%,最优;
- 速度:Megatron流水线并行优势显著,但小规模集群(<16卡)效果不明显;
- 易用性:PyTorch FSDP自动拆分,Megatron需手动调3种并行维度。
典型应用场景:技术落地创造业务价值
- NLP:千亿对话模型工业化训练
场景:大厂训练100亿参数专属对话模型(替代GPT-3 API降本)
- 痛点:单卡显存不足,10TB对话数据训练慢;
- 方案:DeepSpeed ZeRO-3 + DDP + FlashAttention-2(32张A100);
- 效果:训练周期从3个月缩至20天(成本降40%),内部客服准确率达92%(比10亿参数模型高15%)。
- 计算机视觉:超大规模ViT高效训练
场景:自动驾驶公司训20亿参数ViT(识别复杂路况)
- 痛点:ViT注意力层显存高,1亿张路况图训练慢;
- 方案:Megatron-LM(模型并行拆注意力头+数据并行)(16张A100);
- 效果:单卡显存从“溢出”降至35GB,雨天模糊路况识别准确率88%(比传统CNN高20%)。
- 推荐系统:千亿特征模型实时更新
场景:电商训50亿参数DeepFM(实时推荐)
- 痛点:日增1000万用户行为数据,模型需“日更”但训练滞后;
- 方案:PyTorch DDP + 梯度累积 + FlashAttention-2(8张T4 GPU);
- 效果:训练时间从12小时缩至3小时(实现日更),推荐点击率升8%,GMV间接增5%。
未来技术演进趋势
- 通信优化:硬件加速+算法减量化
- 硬件:NVLink 4.0、PCIe 6.0提升通信速度2-3倍;
- 算法:梯度压缩(FP8/INT4)、稀疏通信,减少50%+通信量(如Meta方案降GPT-4通信成本60%)。
- 自动化并行:AI选最优策略
Google Alpa框架可根据模型结构、硬件自动选并行策略,普通开发者用10卡可达传统20卡效果,2025年有望成为中小团队主流。
- 跨硬件协同:GPU+CPU+TPU混合集群
- 分工:GPU算Transformer注意力层、CPU存非激活参数、TPU做矩阵运算;
- 案例:Google训Gemini用“GPU+TPU v5e”,成本降35%,速度升20%。
- 算法-框架协同:效率革命深化
- 专用算子:MoE分布式路由算子、长序列稀疏注意力算子;
- 编译优化:PyTorch Inductor与分布式联合编译;
- 硬件感知:框架自动适配GPU型号(A100/H100)调整策略。
核心要点与落地建议
- 核心要点
- 策略选择:<10亿参数+大数据→DDP;>20亿参数单卡装不下→模型并行/FSDP;>100亿参数+10TB数据→混合并行(DeepSpeed/Megatron);
- 框架选型:中小团队→PyTorch FSDP+FlashAttention-2;中大规模→DeepSpeed;超大规模→Megatron;
- 必用优化:长序列(>4k)开FlashAttention-2,显存省50%+,速度升2倍以上;
- 关键指标:算力利用率目标>70%,每亿参数训练成本优化至5万元内(行业平均10万)。
- 落地建议
- 新手入门:先练DDP+FlashAttention-2(2-4卡训BERT),再学FSDP;
- 工业实践:优先用开源成熟配置(如DeepSpeed ZeRO-3默认+FlashAttention-2);
- 成本优化:非核心实验用“FP8+梯度累积”减卡数;长期项目选云GPU按需租用(如AWS p3),成本降30%。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献598条内容
已为社区贡献598条内容

所有评论(0)