RAG系统练手与思考
本博客记录了一个小型RAG(检索增强生成)系统的完整实现过程,包括知识库构建(支持多种分块策略、段落摘要生成、重排序)、基于LangChain的对话代理(集成HyDE检索模式),以及Gradio可视化界面。项目具备灵活的文档处理、混合检索、对话记忆等实用功能。测试中发现三个主要问题:模型自身知识可能“抢答”、HyDE生成的假设文档质量不稳定、错别字导致检索失败。针对这些问题,提出了优先使用检索结果
项目内容
虽然是个练手项目,但在设计时还是尽量让它具备一些实用特性:
github地址
1. 灵活的文档分块策略
知识库的构建往往需要根据文档类型调整分块方式。我实现了三种模式:
- recursive:递归字符分割,适合长文本,可设置
chunk_size和chunk_overlap。 - paragraph:按段落分割(默认
\n),保留自然语义单元。 - row:将 DataFrame 的每一行作为一个完整文档,适用于短文本或已经分好块的数据。
2. 段落摘要生成与混合检索
为了让检索更准确,我加入了段落摘要生成功能。在按段落分割后,可以调用 LLM 为每个段落生成摘要,并将其作为元数据存入向量库。检索时有两种模式:
- 普通模式:只检索原文文档。
- 混合模式:同时检索原文和摘要,然后通过重排序合并结果。这样即使原文表述不够清晰,摘要也可能匹配上。
3. 重排序(Rerank)提升准确性
向量召回通常只能给出粗糙的相似度,而通义千问的 rerank 模型可以对召回结果进行精细打分。我在 search_recall_than_rerank 中实现了先粗筛再精排的流程,并支持设置分数阈值,确保返回的文档足够相关。
import logging
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from typing import List, Literal, Optional, Tuple, Dict
import pandas as pd
import concurrent.futures
import threading
from itertools import islice
from datetime import datetime
from pathlib import Path
import json
import argparse
import tomli as tomllib
import dashscope
from http import HTTPStatus
class Knowledge_FAISS:
# 暂时不支持多向量表征
"""
知识库管理类:负责从DataFrame加载文档,分块、向量化并存储。
当前版本仅支持单向量表征
Args:
model: 自定义嵌入模型
base_url: OpenAI格式支持的base_url 暂时不用,因为我要用Dashscope
api_key: 嵌入模型的api_key
split_method: 分块策略
- "recursive": 递归字符分割,按chunk_size/chunk_overlap切块 注:RecursiveCharacterTextSplitter实际上也倾向于优先使用按自然段落分割
- "paragraph": 按自然段落分割,可指定分隔符,支持段落总结
- "row": 每行作为一个完整文档,不分割
chunk_size: 块大小(字符数或token数,取决于分割器),recursive模式下必填
chunk_overlap: 块重叠大小
paragraph_separator: 段落分割符,paragraph模式下使用,默认"\n"
paragraph_summary: 仅paragraph模式下生效,是否为每个自然段生成摘要并存储
"""
def __init__(self
,model: str
,api_key: str
,split_method:Literal["recursive", "paragraph", "row"]
,chunk_size:Optional[int] = None
,chunk_overlap:Optional[int] = None
,paragraph_separator:Optional[str] = "\n"
,paragraph_summary:bool = False #按照自然段落切片时,是否要进行段落总结
,paragraph_summary_model: Optional[str] = None
,paragraph_summary_base_url: Optional[str] = None
,paragraph_summary_api_key: Optional[str] = None
,paragraph_summary_prompt: Optional[str] = None
,rerank_model: Optional[str] = None
,rerank_api_key: Optional[str] = None
):
self.model = model
self.api_key = api_key
self.embeddings: DashScopeEmbeddings = DashScopeEmbeddings(
model=self.model,
dashscope_api_key=self.api_key
)
self.vectorstore: Optional[FAISS] = None
self.split_method: Literal["recursive", "paragraph", "row"] = split_method
self.chunk_size:Optional[int] = chunk_size
self.chunk_overlap:Optional[int] = chunk_overlap
self.paragraph_separator:Optional[str] = paragraph_separator
self.paragraph_summary: bool = paragraph_summary
self.paragraph_summary_model: Optional[str] = paragraph_summary_model
self.paragraph_summary_api_key: Optional[str] = paragraph_summary_api_key
self.paragraph_summary_base_url: Optional[str] = paragraph_summary_base_url
self.paragraph_summary_prompt: Optional[str] = (
"你是一个专业的文本摘要助手。请对以下中文段落生成一个简洁、准确的摘要,概括其主要内容和关键信息。\n"
"要求:\n"
"- 摘要应突出核心要点,避免冗余和细节;\n"
"- 语言流畅、客观,保持原文主旨;\n"
"- 长度适中,通常不超过200字。\n\n"
"段落内容:\n{paragraph}"
)# 段落总结的提示词模板
self.rerank_model = rerank_model
self.rerank_api_key = rerank_api_key
if paragraph_summary_prompt and len(paragraph_summary_prompt)>0:
self.paragraph_summary_prompt = paragraph_summary_prompt
# 日志与错误记录
self.logger = logging.getLogger(self.__class__.__name__)
if not self.logger.handlers:
handler = logging.FileHandler('log.txt',encoding="utf-8")
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
self.logger.addHandler(handler)
self.logger.setLevel(logging.INFO)
self.summary_dict: Dict[int, str] = {}
self.error_df = pd.DataFrame(columns=["row_id", "function_name", "failed_reason"])
self._lock = threading.Lock()
def store_from_pandas(self,df: pd.DataFrame,text_column: str,metadata_columns: List[str],**kwargs):
"""
从Pandas DataFrame加载文档,按指定方法分块并存储到向量数据库。
Args:
df: 包含文本数据的DataFrame
text_column: DataFrame中待处理文本的列名
metadata_columns: 可选,给到每个段落的元数据; 注意:generated_summary是关键字,会作为模型生成的摘要的键,不要作为DataFrame原始的列
**kwargs: 传递给vectorstore.add_documents的额外参数
"""
if text_column not in df.columns:
raise ValueError(f"DataFrame缺少文本列: '{text_column}'")
documents: List[Document] = []
self.error_df = pd.DataFrame(columns=["row_id", "function_name", "failed_reason"])
raw_texts: List[str] = []
metadatas: List[dict] = []
for idx, row in df.iterrows():
text = row[text_column]
# 构建当前行的全局metadata
if len(metadata_columns)>0:
base_metadata = {col: row[col] for col in metadata_columns if col in row}
else:
base_metadata = {}
if self.split_method == "recursive":
splitter = RecursiveCharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap,
)
raw_texts.extend(splitter.split_text(text=text))
elif self.split_method == "paragraph":
raw_paragraphs = text.split(self.paragraph_separator)
raw_paragraphs = [p.strip() for p in raw_paragraphs if p.strip()]
raw_texts.extend(raw_paragraphs)
elif self.split_method == "row":
raw_texts.append(text)
metadatas.append(base_metadata.copy())
if self.paragraph_summary:
summmaries = self.generate_summaries(raw_texts,batch_size=10)
if len(summmaries) != len(raw_texts):
raise ValueError("错误:总结生成时出现了重复或缺失")
for i,summury in enumerate(summmaries):
if len(summury.strip())==0:
continue
metadatas[i]["generated_summary"] = summury
for i,x in enumerate(raw_texts):
doc = Document(page_content=x, metadata=metadatas[i])
documents.append(doc)
if self.vectorstore is None:
self.vectorstore = FAISS.from_documents(
documents, self.embeddings
)
else:
self.vectorstore.add_documents(documents, **kwargs)
def generate_summaries(
self,
texts: List[dict],
batch_size: int = 3
) -> List[Optional[str]]:
"""
为文本生成摘要。
使用线程池并发处理,batch_size 控制最大并发数。
记录错误到 self.error_df。
返回添加了摘要列的DataFrame副本。
"""
total = len(texts)
summaries: List[Optional[str]] = [None] * total
# 使用线程池并发执行
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
future_to_index = {
executor.submit(self._generate_summaries_safe, idx, text): idx
for idx, text in enumerate(texts)
}
for future in concurrent.futures.as_completed(future_to_index):
idx = future_to_index[future]
try:
summary, error = future.result() # 返回 (summary, error_info)
if error:
with self._lock:
self.error_df = pd.concat(
[
self.error_df,
pd.DataFrame([{
"row_id": idx,
"function_name": "generate_summaries",
"failed_reason": str(error)
}])
],
ignore_index=True
)
summaries[idx] = ""
else:
summaries[idx] = summary
except Exception as e:
with self._lock:
self.error_df = pd.concat(
[
self.error_df,
pd.DataFrame([{
"row_id": idx,
"function_name": "generate_summaries",
"failed_reason": f"Unexpected error: {e}"
}])
],
ignore_index=True
)
summaries[idx] = ""
self.logger.info(f"摘要生成完成,成功 {total - len(self.error_df)} 行,失败 {len(self.error_df)} 行")
return summaries
def _generate_summaries_safe(self, idx: int, text: str) -> Tuple[str, Optional[Exception]]:
"""
线程安全的摘要生成包装器,返回 (摘要, 异常对象)。如果成功,异常对象为 None。
"""
try:
summary = self._generate_summaries(text)
self.logger.info(f"行 {idx} 摘要生成成功")
return summary, None
except Exception as e:
self.logger.error(f"行 {idx} 摘要生成失败: {e}")
return "", e
def _generate_summaries(self,raw_paragraph:str) -> str:
"""
调用 LLM 为单个段落生成摘要。
"""
llm = ChatOpenAI(
model=self.paragraph_summary_model,
openai_api_key=self.paragraph_summary_api_key,
openai_api_base=self.paragraph_summary_base_url,
temperature=0.0,
)
prompt = PromptTemplate.from_template(self.paragraph_summary_prompt)
chain = prompt | llm | StrOutputParser()
try:
if len(raw_paragraph)>200:
summary = chain.invoke({"paragraph": raw_paragraph})
return summary.strip()
else:
print(f"太短了,无须生成摘要")
return ""
except Exception as e:
print(f"摘要生成失败: {e}")
return ""
def save_summary_to_vector(self,**kwargs):
"""
将原本的metadata中“生成的摘要”作为向量库的一部分
Args:
**kwargs: 传递给vectorstore.add_documents的额外参数
"""
summary_dict = {}
for k,v in self.vectorstore.index_to_docstore_id.items():
doc = self.vectorstore.docstore.search(v)
current_dict = doc.metadata
if "generated_summary" in current_dict.keys():
summary_dict[k] = current_dict["generated_summary"]
del current_dict["generated_summary"]
doc.metadata["origin_ID"] = k
doc.metadata["doc_type"] = "origin"
keys = list(summary_dict.keys())
batch_size = 10000
for i in range(0,len(keys),batch_size):
new_docs: List[Document] = []
batch = list(islice(keys, i, i+batch_size))
for k in batch:
new_docs.append(
Document(
page_content = summary_dict[k],
metadata = {"origin_ID":k,"doc_type":"summary"}
)
)
self.vectorstore.add_documents(new_docs, **kwargs)
def save_ID_summary_dict(self):
# 这个方法是后续加的,为的是维护metadata中origin_ID和docstore_id的字典
self.summary_dict = {}
for k,v in self.vectorstore.index_to_docstore_id.items():
doc = self.vectorstore.docstore.search(v)
current_dict = doc.metadata
if current_dict.get("origin_ID",None) is not None and current_dict.get("doc_type",None) == "origin":
self.summary_dict[current_dict["origin_ID"]] = v
def search_recall(
self,
query: str,
k: int,
use_hybrid: bool
) -> List[Tuple[Document, float]]:
"""
只检索原始文档(doc_type=origin 或无 doc_type 字段)。
返回 (Document, score) 列表,按相似度降序排列。
query: 输入
k: 最相似的k个;应该比最终需要筛选的结果来的要大
"""
if self.vectorstore is None:
return []
if use_hybrid:
my_filter = {}
k *= 2 #避免有“摘要和原文都进入其中,导致最后无法得到前k个”
results = self.vectorstore.similarity_search_with_score(
query=query,k=k,filter=my_filter
)
else:
# 过滤:doc_type 为 origin 或字段不存在
results_origin = self.vectorstore.similarity_search_with_score(
query=query,
k=k,
filter={"doc_type": "origin"}
)
# 2) 获取所有候选结果(不带过滤条件),再筛选出缺少 doc_type 的文档
results_all = self.vectorstore.similarity_search_with_score(
query=query,
k=k,
filter={}
)
# 过滤:保留 metadata 中没有 "doc_type" 的文档
results_missing_type = [
(doc, score) for (doc, score) in results_all
if not getattr(doc, "metadata", {}) or "doc_type" not in doc.metadata
]
# 3) 合并结果(可按分数排序、或简单拼接)
all_res = results_origin + results_missing_type
results = sorted(all_res, key=lambda item: item[1], reverse=True)[:k]
return results
def search_rerank(
self,
query:str,
candidates: List[Tuple[Document, float]],
k: int,
min_score: float = 0.5,
instruct: Optional[str] = "Given a web search query, retrieve relevant passages that answer the query.",
max_retry: int = 3
):
"""
重排并精筛
Args:
query: 原始查询字符串
candidates: 粗筛结果,每个元素为 (Document, similarity_score)
k: 返回的最多文档数;若为 0 则返回所有满足 min_score 的结果
min_score: 重排序分数阈值,只有分数 >= min_score 的文档才会返回
instruct: 可选的指令文本,用于指导重排序(根据模型要求)
max_retry: dashscope报错后最多重试几次
Returns:
精筛后的文档列表,每个元素为 (Document, rerank_score),
其中 Document 始终是原文文档(若原为摘要则替换为对应原文)
"""
res:List[Tuple[str,float]] = []
if not candidates:
return res
docs_text = [doc.page_content for doc,_ in candidates] #原文
retry_times = max_retry
Flag = True
while Flag and retry_times>=0: #此处retry_times=0表示“可以重复0次,一遍过”
try:
resp = dashscope.TextReRank.call(
model=self.rerank_model,
query=query,
documents=docs_text,
top_n=k,
return_documents=True,
instruct=instruct,
api_key=self.rerank_api_key
)
if resp.status_code != HTTPStatus.OK:
raise ValueError("重排序返回错误: {resp.message}")
else:
Flag = False
except Exception as e:
self.logger.error(f"重排序 API 调用失败: {e}")
retry_times -= 1
if Flag:
return res
else:
results = resp.output.results
reranked = {}
for i in results:
idx = i.index # 传入的candidates的下标
score = i.relevance_score
if score < min_score:
continue
origin_doc, origin_score = candidates[idx]
doc_type = origin_doc.metadata.get("doc_type","origin")
if doc_type == "summary":
res_id = self._get_origin_document(origin_doc)
else:
res_id = origin_doc.id
reranked[res_id] = max(reranked.get(res_id,0),score) #防止summary和origin都被筛选中,此时使用最大的那个分数。
sorted_items = sorted(reranked.items(), key=lambda item: item[1], reverse=True) #逆序排序
if len(sorted_items)>k:
sorted_items = sorted_items[:k]
for (key,score) in sorted_items:
res.append((self.vectorstore.docstore.search(key).page_content,score))
return res
def search_recall_than_rerank(
self,
query:str,
k: int,
use_hybrid: bool,
min_score: float = 0.5,
instruct: Optional[str] = "Given a web search query, retrieve relevant passages that answer the query.",
max_retry: int = 3
):
recall_result = self.search_recall(query=query,k=2*k,use_hybrid=use_hybrid)
rerank_result = self.search_rerank(query=query,
candidates=recall_result,
k=k,min_score=min_score,instruct=instruct,max_retry=max_retry)
return rerank_result
def _get_origin_document(self,document:Document):
origin_id = document.metadata.get("origin_ID",None)
if origin_id is not None:
origin_doc_id = self.summary_dict.get(origin_id,None)
if origin_doc_id:
return origin_doc_id
return document.id
def save(self, folder_path: str):
"""
将当前知识库(向量库+配置)保存到指定文件夹。
- 向量库使用 FAISS 的 save_local 保存为 index.faiss 和 index.pkl
- 配置参数保存为 config.json
- 错误记录保存为 errors.csv(如果非空)
"""
folder = Path(folder_path)
folder.mkdir(parents=True, exist_ok=True)
if self.vectorstore:
self.vectorstore.save_local(str(folder), index_name="index")
else:
self.logger.warning("vectorstore 为空,未保存向量库")
mapping_path = folder / "summary_dict.json"
with open(mapping_path, "w", encoding="utf-8") as f:
# 键可能是 int,JSON 要求键为字符串,转换一下
serializable = {str(k): v for k, v in self.summary_dict.items()}
json.dump(serializable, f, ensure_ascii=False, indent=2)
config = {}
exclude_keys = {'embeddings', 'vectorstore', 'logger', '_lock', 'error_df','summary_dict'}
for key, value in self.__dict__.items():
if key in exclude_keys:
continue
try:
json.dumps(value)
config[key] = value
except TypeError:
self.logger.warning(f"配置项 {key} 不可序列化,已跳过")
config_path = folder / "config.json"
with open(config_path, "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=2)
if not self.error_df.empty:
error_path = folder / "errors.csv"
self.error_df.to_csv(error_path, index=False, encoding="utf-8")
self.logger.info(f"错误记录已保存至 {error_path}")
self.logger.info(f"知识库已保存至 {folder_path}")
@classmethod
def load(cls, folder_path: str, **kwargs):
"""
从文件夹加载知识库和配置,返回 Knowledge_FAISS 实例。
注意:FAISS 加载需要 allow_dangerous_deserialization=True,请确保数据来源可信。
Args:
folder_path: 保存时使用的文件夹路径
**kwargs: 可覆盖配置文件中的参数
"""
folder = Path(folder_path)
if not folder.exists():
raise FileNotFoundError(f"文件夹不存在: {folder_path}")
config_path = folder / "config.json"
if not config_path.exists():
raise FileNotFoundError(f"配置文件不存在: {config_path}")
with open(config_path, "r", encoding="utf-8") as f:
config = json.load(f)
# 不覆盖配置
# config.update(kwargs)
instance = cls(**config)
# 加载向量库
if (folder / "index.faiss").exists():
# 注意:FAISS load_local 需要允许反序列化,请确保数据安全
instance.vectorstore = FAISS.load_local(
str(folder),
instance.embeddings,
index_name="index",
allow_dangerous_deserialization=True
)
else:
instance.logger.warning("未找到向量库文件,vectorstore 保持为 None")
# 加载错误记录(如果存在)
error_path = folder / "errors.csv"
if error_path.exists():
instance.error_df = pd.read_csv(error_path)
# 加载 origin_to_doc_ids 映射
mapping_path = folder / "summary_dict.json"
if mapping_path.exists():
with open(mapping_path, "r", encoding="utf-8") as f:
loaded = json.load(f)
# 将键转回 int
instance.summary_dict = {int(k): v for k, v in loaded.items()}
else:
instance.logger.warning("未找到 summary_dict.json,映射保持为空")
return instance
def read_wiki_txt():
parser = argparse.ArgumentParser(description="构建知识库")
parser.add_argument("--config", type=str, required=True, help="TOML 配置文件路径")
args = parser.parse_args()
with open(args.config, "rb") as f:
config = tomllib.load(f)
# 提取各配置节
kb_config = config.get("knowledge_base", {})
data_config = config.get("data", {})
output_config = config.get("output", {})
kb = Knowledge_FAISS(**kb_config)
# 断档重续
iter_skip = 0
current_begin = -999
# kb = Knowledge_FAISS.load("./kb_output")
# 读取数据
with open("./wikibaike_passage_sub.txt",encoding="utf-8") as f:
while True:
current_begin += 1000
# 从文件迭代器中读取最多 batch_size 行
batch = list(islice(f, 1000))
if not batch: # 没有更多行时退出循环
break
if iter_skip>0:
iter_skip -= 1
continue
try:
df = pd.DataFrame({"raw_text":batch})
text_column = data_config.get("text_column")
if not text_column:
raise ValueError("配置文件中缺少 data.text_column")
metadata_columns = data_config.get("metadata_columns", [])
# 存储文档
kb.store_from_pandas(
df=df,
text_column=text_column,
metadata_columns=metadata_columns,
)
# 保存
output_folder = output_config.get("folder", "./knowledge_base")
kb.save(output_folder)
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"{current_time} 知识库已保存到 {output_folder}")
except Exception as e:
kb.logger.info(f"{current_begin}以及后1000个文档保存失败!")
if __name__ == "__main__":
read_wiki_txt() # Knowledge_FAISS.py --config config.toml
# kb = Knowledge_FAISS.load("./kb_with_summary_dict")
# res = kb.search_recall_than_rerank("寂静岭2 主角 姓名",5,True)
# print(res)
4. HyDE 检索模式
HyDE(Hypothetical Document Embeddings)是一种有趣的思路:先让 LLM 根据用户问题生成一个“假设性文档”,然后用这个假设文档去检索真实文档。我把它作为一个可开关的模式集成到对话代理中。如果启用,retrieve 工具的提示词会指导 LLM 生成一段类似真实知识库的文本,从而提升检索的语义匹配度。
5. 对话记忆与持久化
基于 LangGraph 的 checkpointer 和 SQLite,系统能够记住多轮对话的上下文。每次新建对话都会生成一个唯一的 checkpoint_id,可以继续之前的对话。知识库本身也支持保存和加载,包括配置、向量索引和错误记录,方便断点续建。
import logging
from typing import Optional, List, Tuple
from Knowledge_FAISS import Knowledge_FAISS
from langgraph.checkpoint.sqlite import SqliteSaver
import sqlite3
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_openai import ChatOpenAI
import uuid
from langchain_core.runnables import RunnableConfig
TOOL_PROMPT = """**函数名**: `retrieve`
**功能描述**:
从知识库中检索与查询最相关的文档片段,返回精筛后的文档列表及匹配分数,以补充回答所需的外部信息。LLM应基于检索结果整合生成最终回复。
**调用时机**:
✅ **建议调用**:
- 用户问题涉及**专业知识、事实性信息、特定领域内容**,而模型自身知识可能不完整或过时
- 用户明确要求“查询资料”、“参考文档”、“根据知识库回答”等
- 需要引用权威来源或确保答案准确性时
❌ **避免调用**:
- 模型能够基于通用知识或对话历史自信地回答
- 问题属于闲聊、常识或无需外部佐证
- 检索可能返回大量无关内容,增加处理负担
**参数说明**:
| 参数 | 类型 | 要求 | 示例 |
|------|------|------|------|
| `query` | 字符串 | **检索关键词或问题描述**,应:<br>- 简洁、具体,聚焦单一主题<br>- 包含核心实体和关键意图<br>- 避免过于宽泛或模糊 | `"Python 列表推导式语法"`<br>`"2023年诺贝尔物理学奖得主"`<br>`"公司内部休假政策"` |
**返回值**:
`retrieve` 函数返回一个列表,每个元素为 `(文档原文, 匹配分数)` 的元组。
- **文档原文** (字符串): 知识库中匹配到的文本片段。
- **匹配分数** (浮点数): 表示文档与查询的相关程度,**分数越高相关性越强**(取值范围通常为0~1或更高)。
列表按分数从高到低排序,LLM应优先使用高分文档作为主要信息来源。
**注意事项**:
- 如果用户问题包含多个子问题,可考虑拆分多次调用(若知识库支持)。
- 调用后,LLM需综合多个返回文档(特别是高分文档)进行信息整合,确保回答连贯且准确。
- 若返回列表为空或所有分数极低(如低于阈值),可告知用户未找到相关信息,并尝试重新表述查询。
- 避免直接拼接文档原文,应根据理解用自己的语言组织回答,必要时可引用文档。"""
SystemPrompt = """### 角色定位
你是一个能够自主决策的智能问答助手,具备以下能力:
- 利用内置知识回答通用问题
- 当需要外部知识时,可以调用 `retrieve` 函数从知识库中检索相关信息
- 遵循 **ReAct(Reasoning + Acting)** 范式:通过**推理**决定下一步行动,执行**行动**(调用检索),**观察**返回结果,然后继续推理,直至给出完整准确的答案
### 核心原则
1. **优先推理**:先分析用户问题的性质,判断是否需要检索。如果需要,明确检索目的和关键词。
2. **精准检索**:构造的 `query` 应聚焦问题核心,避免过于宽泛(如“什么是人工智能”)或过于琐碎。必要时可拆分复杂问题为多次检索。
3. **允许多次检索**:
- 如果初次检索结果不充分或过于笼统,可以再次检索,调整关键词或从不同角度切入。
- 如果问题包含多个子问题,可以分别检索,逐步收集信息。
4. **整合与验证**:将检索结果与自身知识结合,验证信息的准确性和相关性,确保回答连贯、逻辑清晰。
5. **透明度**:在回答中可简要说明信息来源(如“根据知识库资料……”),但不必展示内部检索步骤。
### 工作流程示例
1. **用户提问**:例如“Python中如何实现多线程?”
2. **推理**:判断该问题涉及编程细节,可能需要查阅最新文档或库的使用说明,决定调用 `retrieve`。
3. **行动**:调用 `retrieve(query="Python 多线程 threading 模块 用法")`
4. **观察**:得到若干文档片段,包含示例代码和注意事项。
5. **推理**:结果是否覆盖了用户期望?如果缺少性能对比,可再次检索。
6. **再次行动**:调用 `retrieve(query="Python 多线程 vs 多进程 性能对比")`
7. **最终整合**:综合两次结果,生成详细回答,解释多线程基本用法、适用场景以及与多进程的区别。
### 注意事项
- **避免过度检索**:对于常识性、模型已知的问题,直接回答即可。
- **处理空结果**:若检索无返回,告知用户“未找到相关信息”,并尝试用自身知识解释或建议用户换个说法。
- **保持对话连贯**:不要因为检索而打断对话流程,最终回答应自然流畅。
请按照以上原则处理用户请求,在需要时灵活调用 `retrieve` 函数,以提供最准确、有用的答案。"""
HYDEPromptTemplate = """**函数名**: `retrieve`
**功能描述**:
从知识库中检索与**假设性文档**最相关的真实文档片段,返回精筛后的文档列表及匹配分数,以补充回答所需的外部信息。
**调用时机**:
✅ **建议调用**:
- 用户问题涉及专业知识、事实性信息,需要从知识库中查找依据
- 模型自身知识可能不完整或过时
- 需要引用权威来源
❌ **避免调用**:
- 问题属于常识、闲聊,或模型能自信回答
- 检索可能引入大量无关内容
**参数说明**:
| 参数 | 类型 | 要求 | 示例 |
|------|------|------|------|
| `query` | 字符串 | **必须填入一个假设性文档片段**,该片段应:<br>- 基于用户问题,想象一段**可能包含答案**的文本(就像从某本百科全书或技术文档中摘录的段落)<br>- 语言风格类似真实文档,包含关键实体、概念和细节<br>- 长度适中(50~200词),不过于简略或冗长<br>- **不要直接使用用户原问题**,也不要添加“根据查询,我推测……”等元描述 | 水浒传概述 《水浒传》,是以官话白话文写成的章回小说,列为中国古典四大文学名著之一,六才子书之一。成书年代极争议,主流支持「明代嘉靖说」,约1524年。其内容讲述北宋山东梁山泊以宋江为首的梁山好汉,由被逼落草,发展壮大,直至受到朝廷招安,东征西讨的历程。又称《忠义水浒全传》、《江湖豪客传》、《水浒全传》,一般简称《水浒》,全书定型于明朝。作者历来有争议,一般认为是施耐庵所著,而罗贯中则做了整理,金圣叹删减为七十回本。此书是中国《四大名著》之一,亦是《四大奇书》之一。 |
**返回值**:
`retrieve` 函数返回一个列表,每个元素为 `(文档原文, 匹配分数)` 的元组,按分数从高到低排序。
**注意事项**:
- 假设文档的质量直接影响检索效果:越接近真实知识库的表述风格,越容易召回正确答案。
- 如果用户问题包含多个方面,可以考虑分次调用,每次生成聚焦一个方面的假设文档。
- 若检索结果为空或分数极低,可调整假设文档的措辞后重试。
- LLM 最终需综合检索结果生成答案,可引用文档内容但避免直接拼接。"""
class RAGChatAgent:
"""
RAG 对话代理类。
负责接收用户输入,根据当前模式调用知识库检索函数,并返回结果。
"""
def __init__(
self,
retriever: Knowledge_FAISS,
model:str = "",
base_url:str = "",
api_key:str = "",
use_HyDE: bool = False,
HyDE_prompt: Optional[str] = HYDEPromptTemplate,
k:int = 3,
use_hybrid: bool = True,
min_score: float = 0.5,
instruct: Optional[str] = None,
max_retry: int = 3,
tool_description: Optional[str] = None,
prompt_instructions: Optional[str] = None,
sqllite_db_path: Optional[str] = None,
checkpoint_id: Optional[str] = None
) -> None:
"""
Args:
retriever: 知识库,也就是我建的Knowledge_FAISS
model: 模型名称
base_url: API 基础地址
api_key: API 密钥
use_HyDE: 是否使用HyDE(Hypothetical Document Embeddings)
HyDE_prompt: HyDE模式下的函数提示词
k: 检索时返回的最多文档数;若为 0 则返回所有满足 min_score 的结果
use_hybrid: 检索时是否将摘要也混入其中
min_score: 检索重排序分数阈值,只有分数 >= min_score 的文档才会返回
instruct: 检索时可选的指令文本,用于指导重排序(根据模型要求)
max_retry: dashscope报错后最多重试几次
tool_description: 函数描述
prompt_instructions: 系统提示词
sqllite_db_path: SQLLite的目录
checkpoint_id: 长期记忆的id,存在SQLLite里面
"""
self.retriever: Knowledge_FAISS = retriever
self.logger = logging.getLogger(self.__class__.__name__)
self.model = model
self.base_url = base_url
self.api_key = api_key
self.use_HyDE = use_HyDE
self.HyDE_prompt = HyDE_prompt
#检索时用的属性:
self.k = k
self.use_hybrid = use_hybrid
self.min_score = min_score
self.instruct = instruct
if instruct is None or len(instruct.strip()) == 0:
self.instruct = "Given a web search query, retrieve relevant passages that answer the query."
self.max_retry = max_retry
self.prompt_instructions = prompt_instructions if prompt_instructions else SystemPrompt
self.tool_description = tool_description if tool_description else TOOL_PROMPT
# 日志配置
if not self.logger.handlers:
handler = logging.FileHandler('log.txt',encoding="utf-8")
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
self.logger.addHandler(handler)
self.logger.setLevel(logging.INFO)
self.sqllite_db_path = sqllite_db_path
self.checkpoint_id = checkpoint_id
self._init_db()
if not self.checkpoint_id:
self.checkpoint_id = self._generate_unique_guid()
self.last_query = "" # for Gradio
self.last_results = "" # for Gradio
def _init_db(self):
"""初始化数据库,创建 guids 表(如果不存在)"""
with sqlite3.connect(self.sqllite_db_path) as conn:
conn.execute('''
CREATE TABLE IF NOT EXISTS guids (
guid TEXT PRIMARY KEY -- 主键自动保证唯一性
)
''')
def _generate_unique_guid(self):
"""
生成一个不在数据库表中的新 GUID,插入后返回该 GUID 字符串。
如果生成的 GUID 已存在(极低概率),则自动重试直到成功。
"""
retry = 100000
while retry>0:
new_guid = str(uuid.uuid4())# 生成随机 UUID(版本4)
try:
with sqlite3.connect(self.sqllite_db_path) as conn:
conn.execute(
"INSERT INTO guids (guid) VALUES (?)",
(new_guid,)
)
# 插入成功,返回 GUID
return new_guid
except sqlite3.IntegrityError:
# GUID 已存在(违反主键唯一约束),继续循环重新生成
retry -= 1
continue
def chat(self, ipt: str) -> str:
"""
单轮对话
query: 用户输入的自然语言。
"""
try:
conn = sqlite3.connect("./db_for_memory.db",check_same_thread=False) # 本地文件
checkpointer = SqliteSaver(conn)
self.last_query = "" # for Gradio
self.last_results = "" # for Gradio
if self.use_HyDE:
tool_description = self.HyDE_prompt
else:
tool_description = self.tool_description
retriever = tool(
"retrieve",
self.retrieve,
description=tool_description
)
cht = ChatOpenAI(
model=self.model,
openai_api_key=self.api_key,
openai_api_base=self.base_url,
temperature=0.0,
)
agent = create_agent(
model=cht,
tools=[retriever],
checkpointer=checkpointer,
system_prompt=self.prompt_instructions
)
config: RunnableConfig = {"configurable": {"thread_id":self.checkpoint_id}}
res = agent.invoke({"messages": [{"role": "user", "content": ipt}]},config=config)
conn.close()
return res["messages"][-1].content
except Exception as e:
print(e)
return ""
def retrieve(self,
query:str,
):
"""
粗筛->重排并精筛
Returns:
精筛后的文档列表,每个元素为 (Document, rerank_score),
其中 Document 始终是原文文档(若原为摘要则替换为对应原文)
"""
res: List[Tuple[str, float]] = self.retriever.search_recall_than_rerank(
query,self.k,self.use_hybrid,self.min_score,self.instruct,self.max_retry
)
print(f"触发检索!{query}")
self.logger.info(f"检索query:{query},检索结果:{res}")
self.last_query += "\n\n"+query # for Gradio
self.last_results += "\n\n" + "\n".join(str(i[0])+"\n"+str(i[1]) for i in res) # for Gradio
return res
if __name__ == '__main__':
DB_PATH = './db_for_memory.db'
kb = Knowledge_FAISS.load("./kb_with_summary_dict")
RAG_Agent = RAGChatAgent(retriever=kb,
model="qwen3-max",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-xxxxxx",
use_HyDE=True,
sqllite_db_path=DB_PATH)
res = RAG_Agent.chat("《水浒传》是什么时候成书的?")
print(res)
6. Gradio 界面:让交互更直观
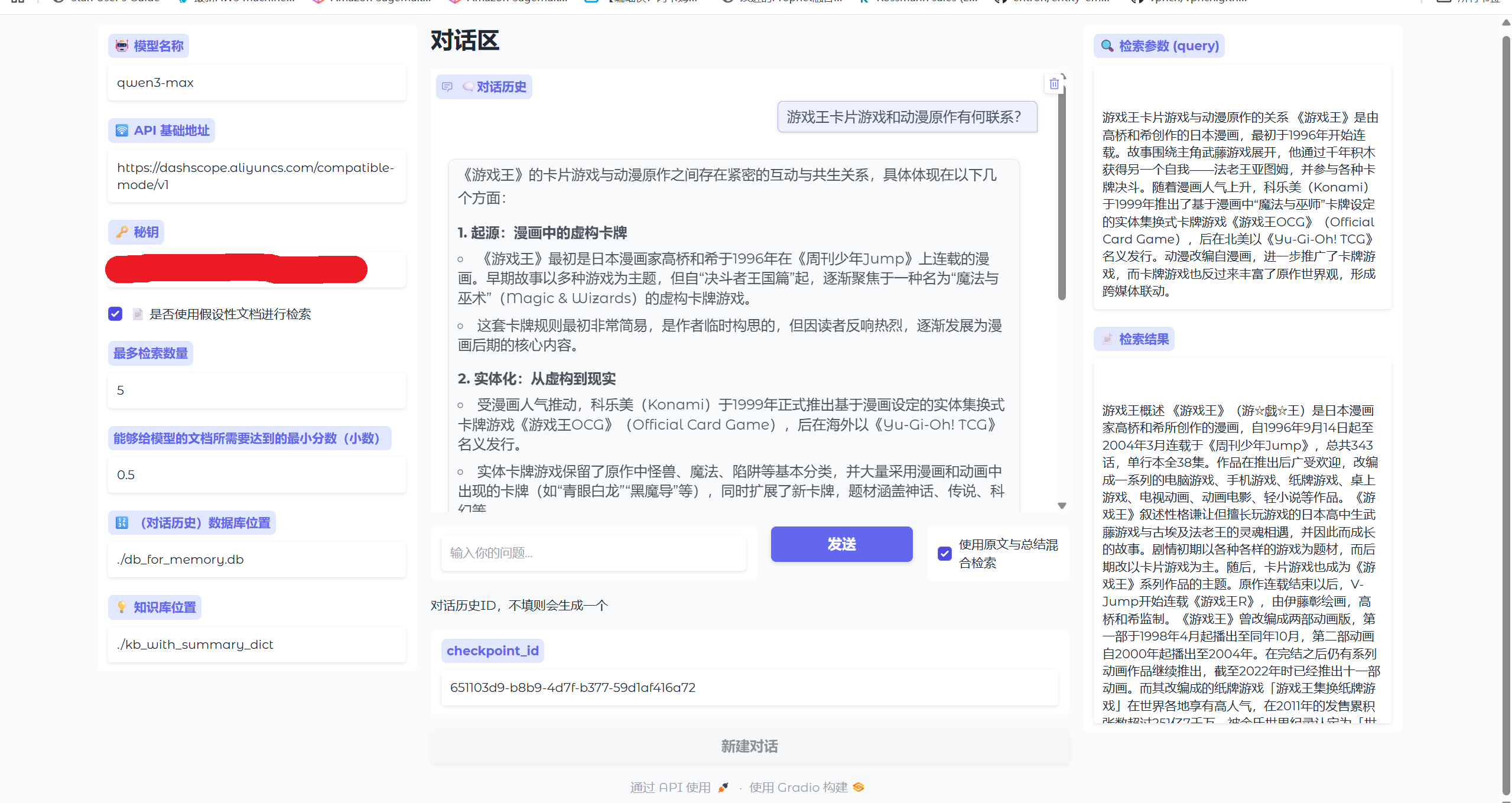
为了让项目“看得见摸得着”,我写了一个 Gradio 界面(如下图)。左侧可以配置模型参数、知识库路径,中间是对话区域,右侧会实时显示本次检索使用的查询语句和召回结果。这对于调试和演示都非常有用。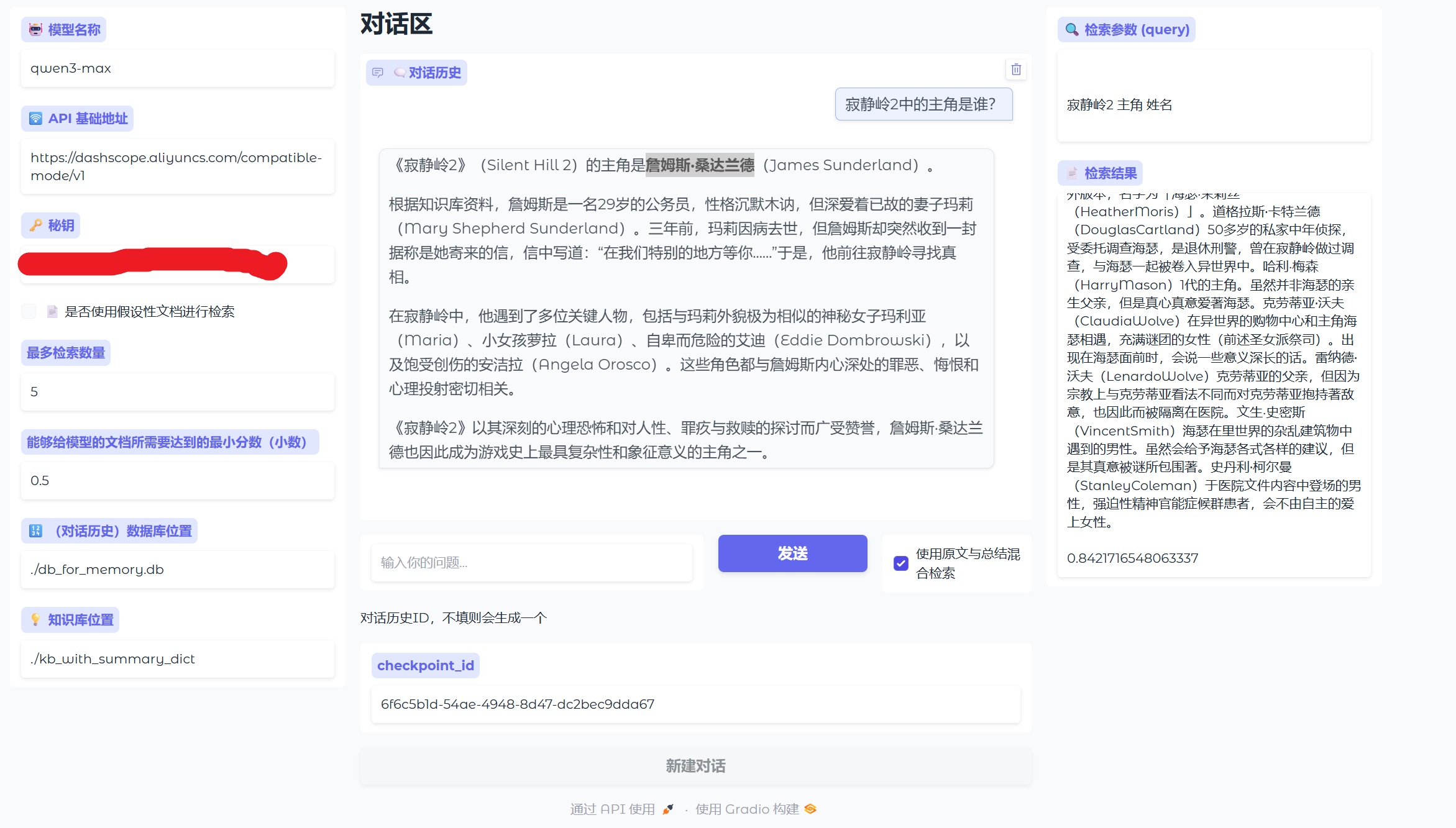
import gradio as gr
from Knowledge_FAISS import Knowledge_FAISS
from AugmentedChat import RAGChatAgent
from typing import Optional
class RAGChatUI:
def __init__(self):
self.agent: Optional[RAGChatAgent] = None
with gr.Blocks(title="RAG", theme=gr.themes.Soft()) as self.demo:
with gr.Row():
with gr.Column(scale=1):
self.model_name = gr.Textbox(
value="qwen3-max",
label="🤖 模型名称",
interactive=True
)
self.base_url = gr.Textbox(
value="https://dashscope.aliyuncs.com/compatible-mode/v1",
label="🛜 API 基础地址",
interactive=True
)
self.api_key = gr.Textbox(
value="sk-xxxxx",
label="🗝️ 秘钥",
interactive=True
)
self.use_HyDE = gr.Checkbox(
value=False,
label="📄 是否使用假设性文档进行检索",
interactive=True
)
self.k = gr.Textbox(
value=5,
label="最多检索数量",
interactive=True
)
self.min_score = gr.Textbox(
value=0.5,
label="能够给模型的文档所需要达到的最小分数(小数)",
interactive=True
)
self.sqllite_db_path= gr.Textbox(
value="./db_for_memory.db",
label="🔢 (对话历史)数据库位置",
interactive=True
)
self.knowledge_position= gr.Textbox(
value="./kb_with_summary_dict",
label="💡 知识库位置",
interactive=True
)
# 对话区域
with gr.Column(scale=2):
gr.Markdown("# 对话区")
self.chatbot = gr.Chatbot(label="🗨️对话历史", height=500)
with gr.Row():
self.msg = gr.Textbox(
scale=4,
show_label=False,
placeholder="输入你的问题...",
interactive=False
)
self.send_btn = gr.Button("发送", scale=1, variant="primary",interactive=False)
self.use_Hybrid = gr.Checkbox(True,label="使用原文与总结混合检索", scale=1, interactive=True)
gr.Markdown("对话历史ID,不填则会生成一个")
self.checkpoint_display = gr.Textbox(
label="checkpoint_id",
value=None if self.agent is None else self.agent.checkpoint_id,
interactive=True
)
self.start_btn = gr.Button("新建对话")
# 检索信息展示
with gr.Column(scale=1):
self.retrieve_param = gr.Textbox(
label="🔍 检索参数 (query)",
lines=4,
interactive=False
)
self.retrieve_result = gr.Textbox(
label="📄 检索结果",
lines=6,
)
# 绑定发送事件
self.send_btn.click(
fn=self.respond,
inputs=[self.msg, self.chatbot, self.use_Hybrid],
outputs=[self.chatbot, self.retrieve_param, self.retrieve_result, self.msg]
)
# 回车键同样触发
self.msg.submit(
fn=self.respond,
inputs=[self.msg, self.chatbot, self.use_Hybrid],
outputs=[self.chatbot, self.retrieve_param, self.retrieve_result, self.msg]
)
self.start_btn.click(
fn=self.create_agent,
inputs=[
self.model_name,
self.base_url,
self.api_key,
self.use_Hybrid,
self.use_HyDE,
self.k,
self.min_score,
self.sqllite_db_path,
self.checkpoint_display
],
outputs=[
self.model_name,
self.base_url,
self.api_key,
self.use_HyDE,
self.k,
self.min_score,
self.sqllite_db_path,
self.knowledge_position,
self.checkpoint_display,
self.start_btn,
self.send_btn,
self.msg
]
)
def create_agent(self,
model,
base_url,
api_key,
use_hybrid,
use_HyDE,
k,
min_score,
sqllite_db_path,
checkpoint_display
):
kb = Knowledge_FAISS.load(self.knowledge_position.value)
kwargs = {
"retriever": kb,
"model":model,
"base_url":base_url,
"api_key":api_key,
"use_hybrid":use_hybrid,
"use_HyDE": use_HyDE,
"k": int(k),
"min_score": float(min_score),
"sqllite_db_path": sqllite_db_path
}
if checkpoint_display is not None and len(checkpoint_display.strip())>0:
kwargs['checkpoint_id'] = checkpoint_display.strip()
else:
kwargs['checkpoint_id'] = None
RAG_Agent = RAGChatAgent(**kwargs)
self.agent = RAG_Agent
res = [gr.update(interactive=False) for _ in range(8)] #除了use_Hybrid以外的其他组件
res +=[gr.update(interactive=False,value=self.agent.checkpoint_id)] + [gr.update(interactive=False)] #checkpoint_id+新建对话组件(禁用)
res +=[gr.update(interactive=True) for _ in range(2)] # 发送组件(2个)
return res
def respond(self, message, chat_history, use_hybrid):
"""处理用户输入,更新聊天历史和右侧检索信息"""
try:
self.agent.use_hybrid = use_hybrid
answer = self.agent.chat(message)
chat_history.append((message, answer))
last_query = self.agent.last_query
last_results = self.agent.last_results
# 如果检索结果为空,可显示提示
if not last_results:
last_results = "本次对话未调用检索工具"
return chat_history , last_query, last_results, ""
except Exception as e:
error_msg = f"对话出错:{str(e)}"
print(e)
chat_history.append((message, error_msg))
return chat_history, "", "", ""
if __name__ == "__main__":
demo = RAGChatUI()
demo.demo.launch()
测试中发现的问题
在完成基本功能后,我用中文维基百科的一个子集作为知识库,进行了一系列测试,包括普通问答、多跳问题以及故意写错别字、口语化提问。下面是几个有趣的发现:
发现 1:模型自身知识的“干扰”
由于我选用的数据集(中文维基)很可能已经被各大模型用作训练语料,导致即使检索模块没有召回正确答案,LLM 自己也能回答出来。例如问“合金装备2中出现的角色“雷电”在后续哪部作品中作为主角出现?”,模型直接说出了答案,但实际上它并没有成功检索出对应的结果。
这既是优点也是缺点:优点是在知识库覆盖不足时模型仍能作答,缺点是难以判断回答是否真的来自知识库,可能掩盖检索模块的问题。如果希望严格检验检索效果,需要用模型未见过的新数据。
发现 2:HyDE 生成的假设文档质量不稳定
HyDE 模式在理想情况下能提升召回,但实际测试中特别是多跳问题时效果不佳。比如问“恶魔城系列中,哪些作品采用了时间穿越的剧情?”,模型生成的假设文档可能过于泛泛,导致检索不到准确信息。问题在于 HyDE 的生成质量直接依赖 LLM 对问题的理解和知识库文档风格的模仿能力。如果生成的假设文档与真实文档的表述差异较大,反而会引入噪声。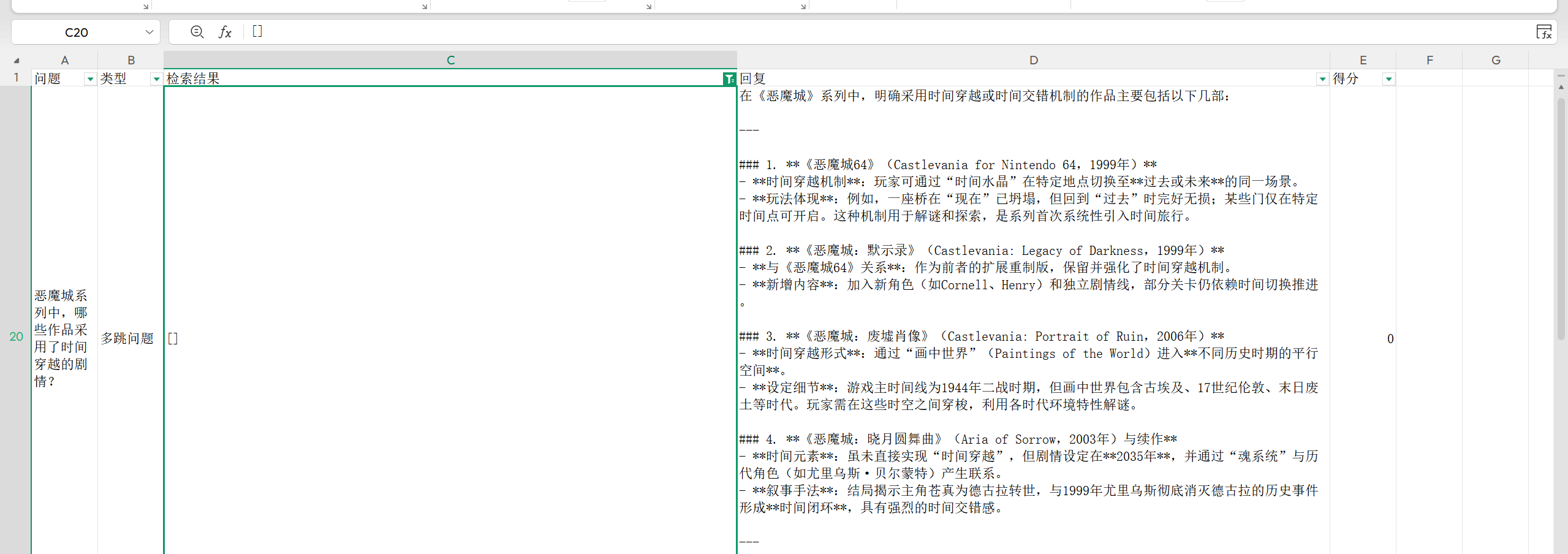
发现 3:错别字导致检索失败
用户提问时难免有错别字或口语化表达,比如把“游戏王”写成“游喜王”。由于这个词是一个专有名词,这类问题往往召回不到合适内容。这在实际应用中是很常见的痛点。
可能的改进方向
针对上述问题,我思考了一些可行的优化思路:
1. 融合模型知识与检索结果
为了避免模型“抢答”,可以在系统提示词中明确要求模型优先使用检索结果,只有在检索结果为空或明显不相关时才依赖自身知识。更精细的做法是:对检索结果进行可信度评估(如分数阈值),如果高分结果存在,则强制模型基于它们回答;如果分数较低,可以结合模型知识并注明信息来源。
2. 提升 HyDE 的可靠性
- 多假设生成:让 LLM 生成多个不同风格的假设文档,分别检索后合并结果。
- 查询改写先行:先用一个轻量级模型对用户问题进行改写(纠错、扩展关键词),再用改写后的查询生成假设文档。
- 引入混合步骤:不止依赖于假设性文档,因为这里我是“轻量级”实现的(单纯地只是改了检索函数的提示词),后续有可能的话,可以试试将使用AI生成的假设性文档与AI本身不带假设性文档传入检索函数后的结果进行比对用某种策略进行交叉验证。
3. 增强对错别字的鲁棒性
- 拼写纠错:在检索前先用一个拼写检查模型或词典对用户问题进行纠错。
- 模糊检索:嵌入模型本身对轻微拼写错误有一定容忍度,但可以结合字符级的 n-gram 索引(如 Elasticsearch 的模糊匹配)做第一轮召回。
- 同义词扩展:对于有着更细致场景的生产项目,可以利用 WordNet 或自定义词典,将问题中的关键词扩展为同义词后再检索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)