用大白话讲解人工智能(9) Transformer模型:让AI真正理解上下文
想象你正在翻译一句复杂的中文:“尽管天下着大雨,小明还是坚持骑车去图书馆还书,因为那本《深度学习入门》明天就到期了。而Transformer模型却能轻松解决这个问题——它像,一眼就能看到"大雨"和"坚持骑车"的转折关系,"那本"和"书"的指代关系。这种"全局视野"正是Transformer超越RNN的关键。
Transformer模型:让AI真正理解上下文
从"翻译长句子"看Transformer的革命
想象你正在翻译一句复杂的中文:“尽管天下着大雨,小明还是坚持骑车去图书馆还书,因为那本《深度学习入门》明天就到期了。”
如果用RNN逐词翻译,可能会出现这样的问题:
- 翻译到"骑车去图书馆"时,可能已经忘了开头的"天下着大雨",导致漏掉"尽管"这个转折关系
- 处理"因为那本《深度学习入门》"时,可能无法将"那本"与前面的"书"关联起来
而Transformer模型却能轻松解决这个问题——它像同时阅读整句话的人类,一眼就能看到"大雨"和"坚持骑车"的转折关系,"那本"和"书"的指代关系。这种"全局视野"正是Transformer超越RNN的关键。
为什么RNN处理长文本会"断片"?
RNN处理序列数据时像串珠子:必须从第一个词开始,一个接一个地往后串,中间的珠子掉了就接不上。这导致两个致命问题:
问题1:顺序处理效率低
RNN不能并行计算,100个词的句子必须计算100步,就像排队过独木桥,效率极低。
问题2:长期依赖"记不住"
即使是LSTM,处理超过100个词的长文本时,前面的信息也会逐渐淡化。就像你给朋友讲100句话的故事,讲到最后可能忘了开头说了什么。
Transformer的解决方案是:放弃循环结构,用"注意力机制"让每个词直接"看到"其他所有词——就像看一幅画时,你的眼睛可以同时聚焦多个关键细节,而不是只能从左到右逐像素扫描。
注意力机制:像"搜索引擎"一样找重点
用"读书笔记"理解自注意力
当你读一本书时,不会逐字死记硬背,而是会:
- 用荧光笔标出关键句(比如"Transformer的核心是注意力机制")
- 在页边写批注,把相关概念连起来(比如"注意力=搜索+加权")
- 最后根据标注和批注,提炼出全书核心观点
自注意力机制(Self-Attention)做的就是这件事:
- 每个词(如"骑车")会给句子中所有其他词打分("大雨"打90分,"图书馆"打80分,"明天"打30分)
- 分数越高,说明这个词与当前词的关系越密切
- 最后把高分词的信息加权求和,作为当前词的"增强版"表示
用"相亲匹配"理解注意力分数计算
假设句子是"小明爱小红",计算"爱"对其他词的注意力分数:
- Query(问题):"爱"想找和自己相关的词(“谁爱?”“爱谁?”)
- Key(关键词):每个词提供自己的"标签"(小明:“主语”;爱:“动词”;小红:“宾语”)
- 匹配得分:"爱"的Query和"小明"的Key匹配度90分,和"小红"的Key匹配度85分
- 加权求和:"爱"的最终表示 = 90%小明的信息 + 85%小红的信息 + 10%自己的信息
这样,“爱"就同时记住了"谁爱"和"爱谁”,不会像RNN那样"前面的词看完就忘"。
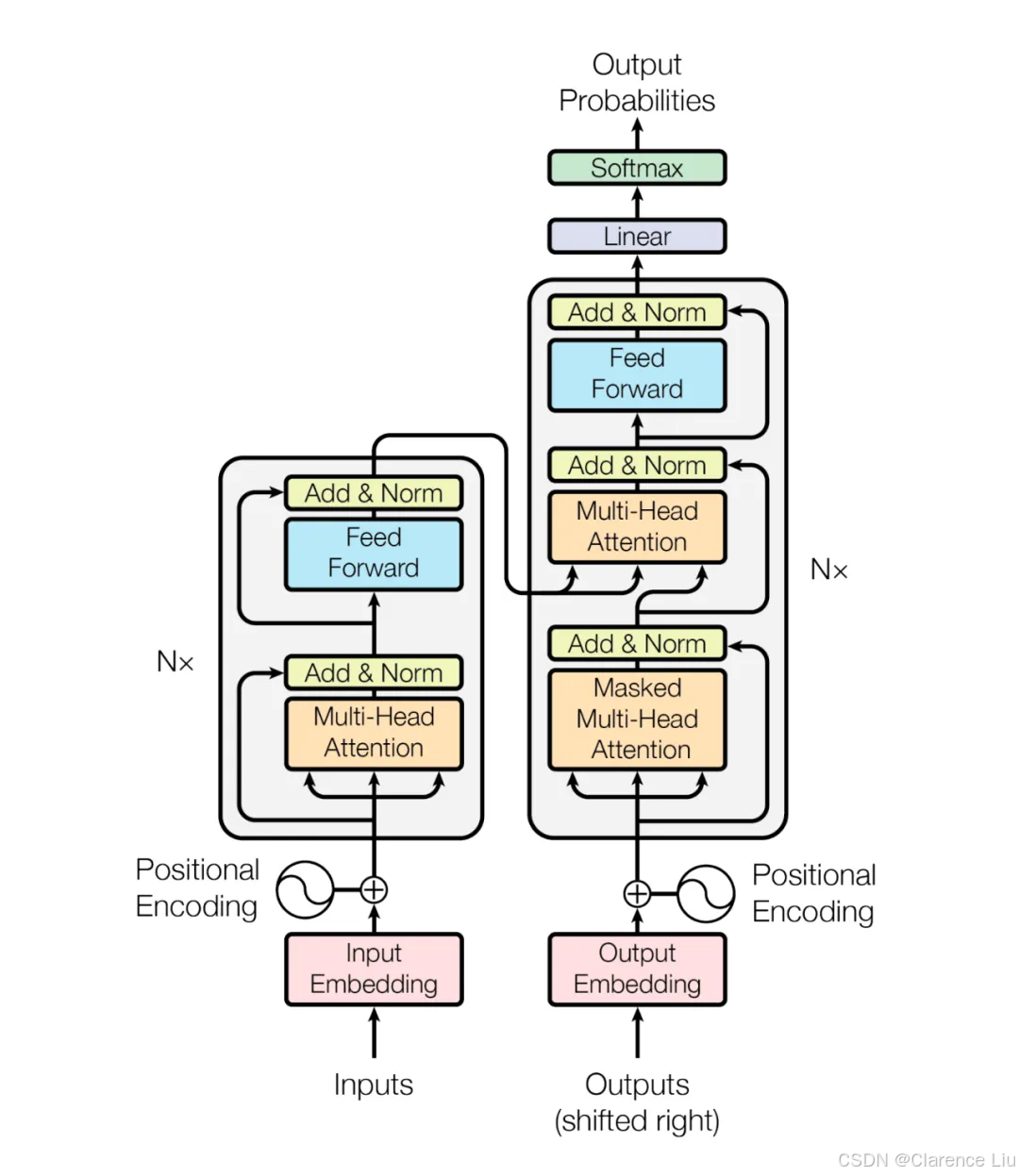
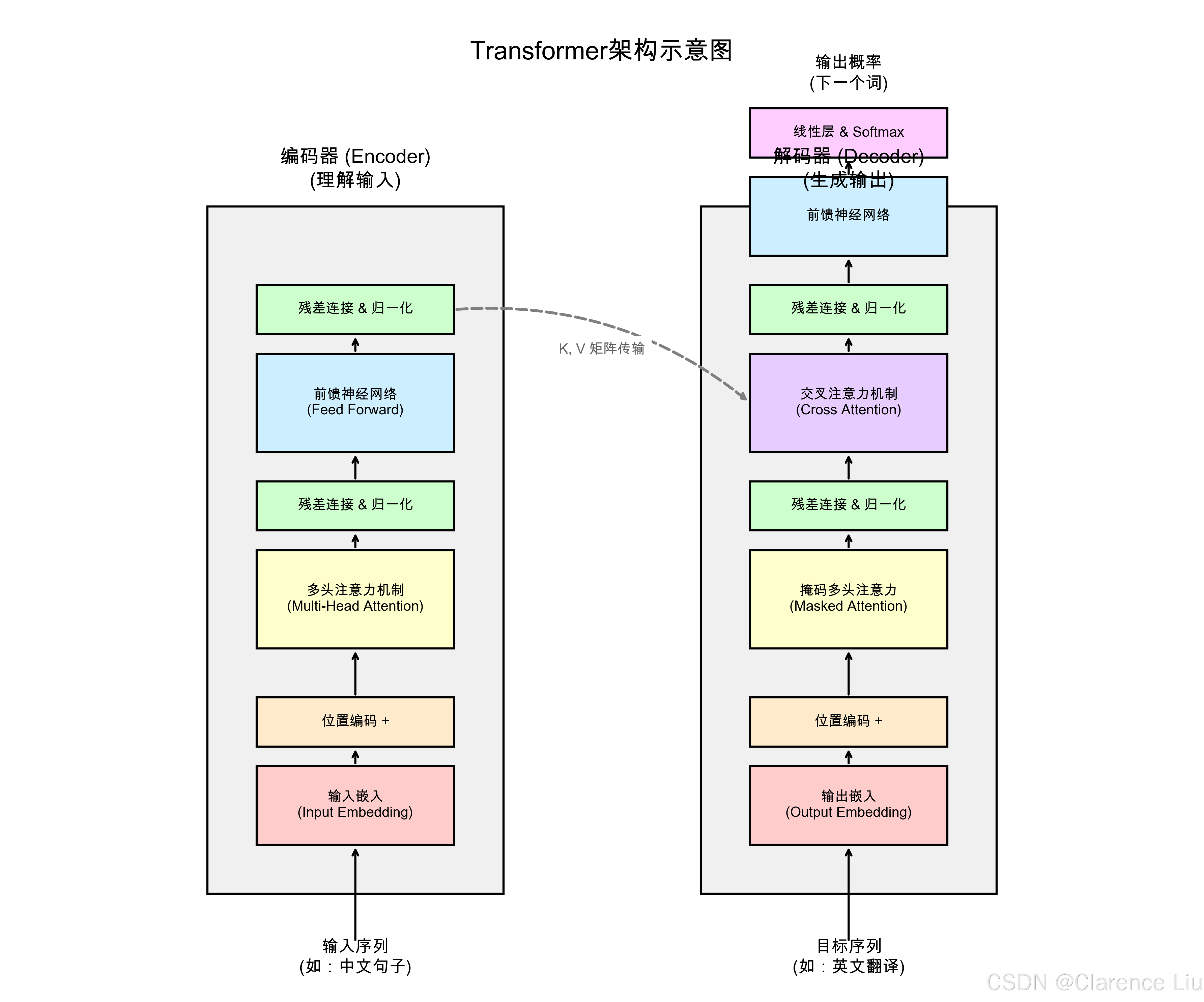
Transformer的"积木结构":编码器-解码器
Transformer由两大块组成,像工厂的"来料加工"流水线:
编码器(Encoder):理解输入内容
- 任务:把输入的文字/语音转换成"意义向量"(理解语义)
- 结构:6层相同的"注意力+前馈网络"模块堆叠(像6个工人接力处理)
- 自注意力层:每个词关注其他词,生成"上下文增强版"词向量
- 前馈网络:对每个词做独立的非线性变换(比如识别"爱"是动词)
解码器(Decoder):生成输出内容
- 任务:根据编码器的"意义向量"生成目标文本(如翻译结果)
- 结构:6层"自注意力+编码器注意力+前馈网络"模块
- 竖注意力(Masked Self-Attention):只能关注前面已生成的词(避免"预知未来")
- 横注意力(Encoder-Decoder Attention):关注编码器输出的"意义向量"(确保内容准确)
以中英翻译为例:
- 编码器处理"我爱中国",生成包含"我、爱、中国"关系的向量
- 解码器先输出"I",再根据"I"和编码器的向量输出"love",最后输出"China"
位置编码:给词加上"坐标"
Transformer没有循环结构,怎么知道词的顺序?答案是位置编码:
- 给每个位置分配一个独特的"坐标值",和词向量相加
- 比如位置1的词加上(0.8, 0.6),位置2的词加上(0.6, -0.8)
- 这样模型就能区分"我爱你"和"你爱我"
这个过程类似给每个词贴标签:"我"是第1个词,"爱"是第2个词,保证顺序信息不丢失。
多头注意力:从不同角度理解句子
人类理解句子时会关注不同方面:
- 语法层面:谁是主语,谁是宾语
- 语义层面:褒义还是贬义
- 上下文:指代关系(比如"他"指谁)
Transformer的多头注意力就是模拟这种多角度理解:
- 将注意力机制复制多份(如12个头),每个头关注不同特征
- 有的头关注语法结构,有的头关注语义情感,有的头关注指代关系
- 最后将各头的结果拼接起来,形成更全面的理解
就像一群专家会诊:心脏专家关注心脏,神经专家关注大脑,最后汇总诊断结果。
为什么GPT和BERT都用Transformer?
GPT(生成式):只用解码器
- 特点:从左到右生成文本,适合写文章、编故事
- 原理:解码器的自注意力只能关注前面的词,模拟人类写作时的思考过程
- 应用:ChatGPT、自动写代码、故事生成
BERT(理解式):只用编码器
- 双向注意力:同时关注左右两边的词,适合理解句子含义
- 应用:情感分析(判断"这部电影烂到家了"是负面情绪)、命名实体识别(识别"北京"是城市)
Transformer就像一个万能积木,通过组合不同模块,既能理解又能生成,这就是它能成为AI领域"瑞士军刀"的原因。
为什么Transformer能处理超长文本?
传统RNN处理1000词需要1000步,而Transformer可以并行处理,且通过注意力机制直接建立长距离依赖:
- 对于"小明的爸爸的妹妹的儿子",Transformer能直接将"儿子"与"小明"关联
- 而RNN需要一步步传递,可能到"儿子"时已经忘了"小明"
这使得Transformer能处理上万词的文档,为大语言模型(LLM)的出现奠定了基础。
小问题:为什么说Transformer是AI领域的"内燃机革命"?
(提示:就像内燃机取代蒸汽机彻底改变了交通,Transformer取代RNN后,AI在NLP领域的能力实现了质的飞跃,催生了GPT、BERT等革命性应用,是深度学习的"工业革命"。)
下一篇预告:《生成式AI:从"模仿"到"创造"的飞跃》——用"学画画"的例子,讲透GPT等生成式模型的工作原理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)