LangChain4j实战
本文介绍了如何在Java项目中集成LangChain4j与阿里云百炼平台API,主要包括以下内容:1) API-KEY申请与配置,通过Spring配置类或yml文件设置OpenAI模型参数;2) 使用AIServices创建动态代理接口,实现对话、格式化JSON输出和流式响应功能;3) 实现记忆功能,通过Redis存储对话上下文;4) RAG知识库应用,使用Milvus向量数据库存储和检索文档;5
一.API-KEY的申请以及相关依赖的配置
1.API-KEY
我们就在阿里云百炼平台注册申请就可以了
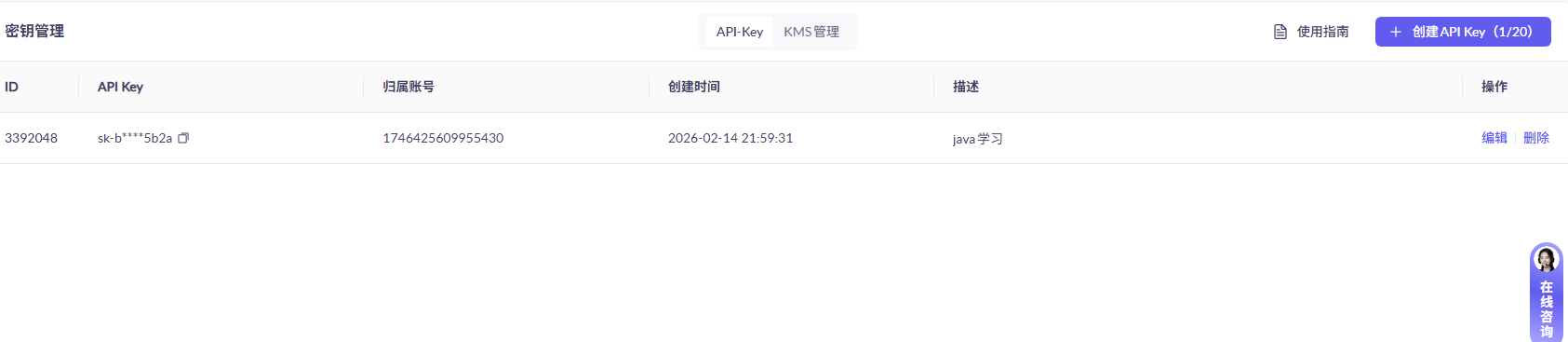
看看怎么在Java中配置,原来是先注册一个bean就可以了

2.idea中的配置
回到idea,我们先导入langchain4j的相关依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.11.0</version>
</dependency>然后按照刚才官网教的方法,在config文件夹下注册一个openai的bean,我们把logrequests和logresponses设置好就能看到来回的json格式了
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class QwenModel {
@Bean
public OpenAiChatModel qwenModel(){
OpenAiChatModel model= OpenAiChatModel.builder() //这个是流式调用对象
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(System.getenv("API-KEY"))
.modelName("qwen-plus")
.logRequests(true)
.logResponses(true)
.build();
return model;
}
}
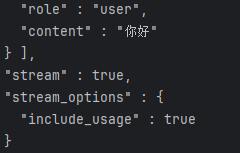
json格式大概是这样的:

其中stream是表明流式调用,一点点的返回(很多json),false就是一次性返回所有

3.另一种配置方式
我们还可以引入openai的springboot-starter
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>这样我们就可以不用写配置类了,直接在application.yml写这个bean的信息,就可以为我们自动注入这个bean了,直接autowired或者resource即可。
langchain4j:
open-ai:
chat-model:
api-key: ${API-KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
model-name: qwen-plus
log-requests: true
log-responses: true二.AIServices相关
1.AIServices的设置
我们先先定义一个services接口,里面写好方法
public interface AiCoderHelperService {
@SystemMessage(fromResource = "system-prompt.txt") //So, AiService will automatically convert it into a UserMessage and invoke ChatModel. Since the output type of the chat method is a String, after ChatModel returns AiMessage, it will be converted into a String before being returned from the chat method.
String chat(String userMessage);
@SystemMessage(fromResource = "system-prompt.txt") //这里自己定义返回的类型,就可以对ai返回的数据做格式化处理(json schema)
Report chatAll(String userMessage);
@SystemMessage(fromResource = "system-prompt.txt")
Flux<String> chatStreaming(String message);
}
正常来说先定义接口再实现类嘛,但是这里我们需要定义一个factory类,将这个services的实现类通过反射设置出一个动态代理,就不需要自己编写实现类了
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;
import dev.langchain4j.service.AiServices;
import jakarta.annotation.Resource;
import org.example.aicoderhelper.demos.web.AI.server.Service.AiCoderHelperService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AiCoderServiceFactory {
@Resource
private OpenAiChatModel qwenChatModel;
@Resource
private OpenAiStreamingChatModel qwenStreamingChatModel;
@Bean
public AiCoderHelperService aiCoderHelperService(){ //这里相当于是生成我们自己创建的类,所以叫factory不叫config了。。。
ChatMemory chatMemory= MessageWindowChatMemory.withMaxMessages(10); //会话记忆
AiCoderHelperService aiCoderHelperService=AiServices.builder(AiCoderHelperService.class)
.chatModel(qwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemory(chatMemory)
.build();
/**
Friend friend = AiServices.builder(Friend.class) 也可以这样写,还可以传systemmessage呢
.chatModel(model)
.systemMessageProvider(chatMemoryId -> "You are a good friend of mine. Answer using slang.")
.build();
**/
return aiCoderHelperService;
}
}
从官方文档可以看出,只要创建了这个动态代理,接口里面你定义的方法就只需要输入String类型的数据,它会将其自动封装为ChatMessage传入,返回的也会是个String,但是你还可以通过指定返回类型来控制其格式(后文说)
我们再在controller中调用接口中定义的chat方法就行了
@PostMapping(value = "/advance")
public Result<AdminQueryVO> adminQueryService(AdminQueryDTO adminQueryDTO){
log.info("用户开始输入消息"+adminQueryDTO.getMessage());
String back= aiCoderHelperService.chat(adminQueryDTO.getMessage());
AdminQueryVO adminQueryVO= AdminQueryVO.builder()
.message(back).build();
return Result.success(adminQueryVO);
}2.格式化输出
我们想要LLM格式化返回json格式的数据,有两种方法,一种是拼贴prompt,就是在用户提交的prompt后面说明需要返回json格式,但是很不稳定。
还有一种就是json schema,较为稳定,使用方式如下:
我们先定义一个需要返回的json数据的格式:
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class Report {
private String name;
private List<String> suggestionList;
}
然后再刚才定义的services接口中写一个返回json数据的接口:
@SystemMessage(fromResource = "system-prompt.txt") //这里自己定义返回的类型,就可以对ai返回的数据做格式化处理(json schema)
Report chatAll(String userMessage);
最后在controller中调用Chatall就可以了(如果你设置了vo,那vo里也要新添加一个Report类)
@PostMapping(value = "/advance")
public Result<AdminQueryVO> adminQueryService(AdminQueryDTO adminQueryDTO){
log.info("用户开始输入消息"+adminQueryDTO.getMessage());
Report report = aiCoderHelperService.chatAll(adminQueryDTO.getMessage());
AdminQueryVO adminQueryVO= AdminQueryVO.builder()
.report(report).build();
return Result.success(adminQueryVO);
}返回的数据格式就是这样的:
{
"code": 1,
"msg": null,
"data": {
"message": null,
"messages": null,
"report": {
"name": "CodeBuddy",
"suggestionList": [
"想制定编程学习路线?",
"需要项目实战建议?",
"正在准备程序员求职(简历/投递/面试)?",
"想刷高频面试题或提升面试技巧?"
]
}
}
}发现已经将LLM返回的文本解析成自己定义的Report结构了,成功。
3.流式输出
上文我们说了请求API发送的json数据有一个是设置流式输出的
之前注入的bean式openaichatmodel,这里我们需要新配置一个openaistreamingchatmodel
langchain4j:
open-ai:
streaming-chat-model:
api-key: ${API-KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
model-name: qwen-plus
log-requests: true
log-responses: true
chat-model:
api-key: ${API-KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
model-name: qwen-plus
log-requests: true
log-responses: true它依然是自动注入,我们需要在factory中再加点东西,在buider中加了一个streamingChatModel,注意它的类也跟之前不一样
@Configuration
public class AiCoderServiceFactory {
@Resource
private OpenAiChatModel qwenChatModel;
@Resource
private OpenAiStreamingChatModel qwenStreamingChatModel;
@Bean
public AiCoderHelperService aiCoderHelperService(){ //这里相当于是生成我们自己创建的类,所以叫factory不叫config了。。。
ChatMemory chatMemory= MessageWindowChatMemory.withMaxMessages(10); //会话记忆
AiCoderHelperService aiCoderHelperService=AiServices.builder(AiCoderHelperService.class)
.chatModel(qwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemory(chatMemory)
.build();
/**
Friend friend = AiServices.builder(Friend.class) 也可以这样写,还可以传systemmessage呢
.chatModel(model)
.systemMessageProvider(chatMemoryId -> "You are a good friend of mine. Answer using slang.")
.build();
**/
return aiCoderHelperService;
}
}再在接口中定义方法,这里我们需要返回Flux类型,流式返回。
@SystemMessage(fromResource = "system-prompt.txt")
Flux<String> chatStreaming(String message);最后我们就不进行封装了,流失消息直接返回给前端即可:
@PostMapping(value = "/streaming")
public Flux<String> adminQueryFlux(AdminQueryDTO adminQueryDTO){ //流式接口不封装
log.info("用户开始输入消息"+adminQueryDTO.getMessage());
Flux<String> back=aiCoderHelperService.chatStreaming(adminQueryDTO.getMessage());
return back;
}请求可以看到stream=true,成功
4.prompt拼接
@UserMessage("我需要编程教程{{it}}")
@SystemMessage(fromResource = "system-prompt.txt")
Flux<String> chatStreaming(String message);从上面我们发送的json数据中可以得知这两个message,it是指拼接在前面还是后面
5.memory记忆功能
memory简单来说就是将之前与LLM对话的记录加入到当前请求的prompt中,让AI知道上下文,对此Langchain4j默认是在内存中存储,但是我们也可以自己配置将上下文存到redis中:
还是先加入redis的依赖,这是个starter,所以就不用自己写bean:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>我们再在之前写的factory中对自己的Aiservices做一下调整,加一个chatMemoryProvider(注意不要加chatMemory,因为其不能保证线程间的memory独立)
@Bean
public AiCoderHelperService aiCoderHelperService(){
AiCoderHelperService aiCoderHelperService=AiServices.builder(AiCoderHelperService.class)
.chatModel(qwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemoryProvider(chatMemoryProvider)
.build();当然这里传入的chatMemoryProvider是要自己提前写好的bean了,我们再config中提前写好,这里的chatMemoryProvider是一个接口,我们可以用下面这种方法直接实例化一个对象,注意要重写这个get方法,其在每个独立的ID第一次访问LLM时为其返回一个ChatMemory对象,实现线程独立。我们还可以用chatMemoryStore来实现持久化存储。
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.example.aicoderhelper.common.repository.RedisChatMemoryStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatMemoryConfig {
@Autowired
RedisChatMemoryStore redisChatMemoryStore;
@Bean
public ChatMemoryProvider chatMemoryProvider(){
ChatMemoryProvider chatMemoryProvider=new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(redisChatMemoryStore)
.build();
}
};
return chatMemoryProvider;
}
}我们用chatMemoryStore来实现redis的持久化存储,主要重写这三个方法来完成数据的获取,更新,删除即可:
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
@Autowired
RedisTemplate redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
if(redisTemplate.opsForValue().get(memoryId.toString())==null){
return new ArrayList<>();
}
String message= redisTemplate.opsForValue().get(memoryId.toString()).toString();
List<ChatMessage> chatMessages = ChatMessageDeserializer.messagesFromJson(message);
return chatMessages;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
String message=ChatMessageSerializer.messagesToJson(list); //先将chatmessage转换为json格式再存进去
redisTemplate.opsForValue().set(memoryId.toString(),message, Duration.ofDays(1));
}
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(memoryId.toString());
}
}
最终我们就可以在springboot重新启动之后任然对用户输入信息保持记忆:
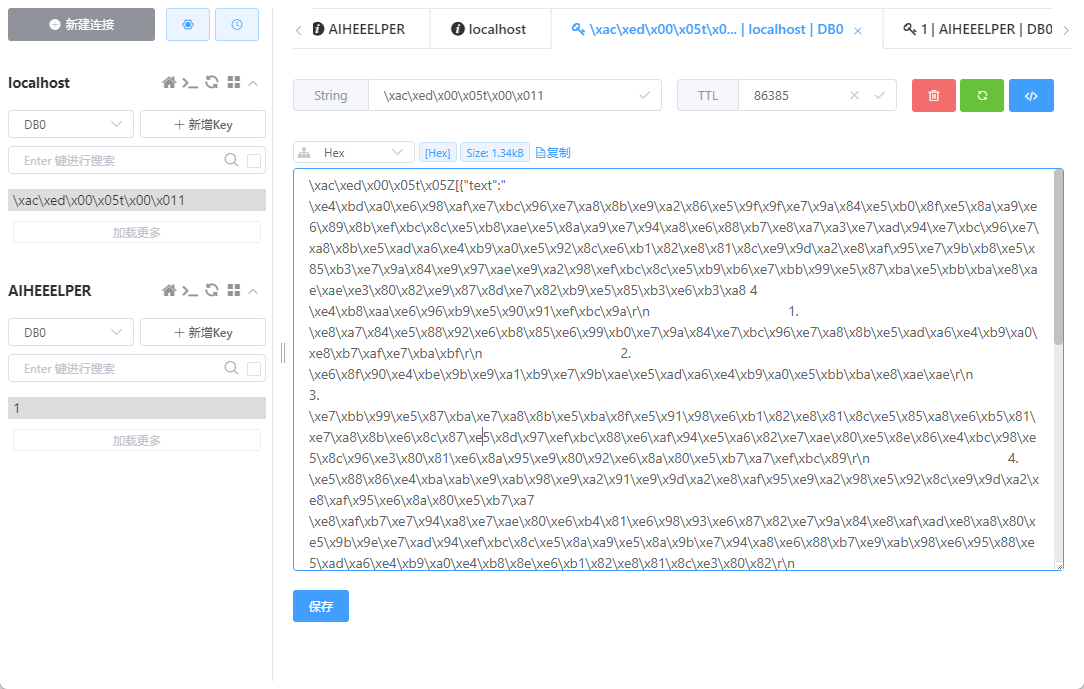
三.RAG知识库的使用
我们还是先导入一下依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.1-beta6</version>
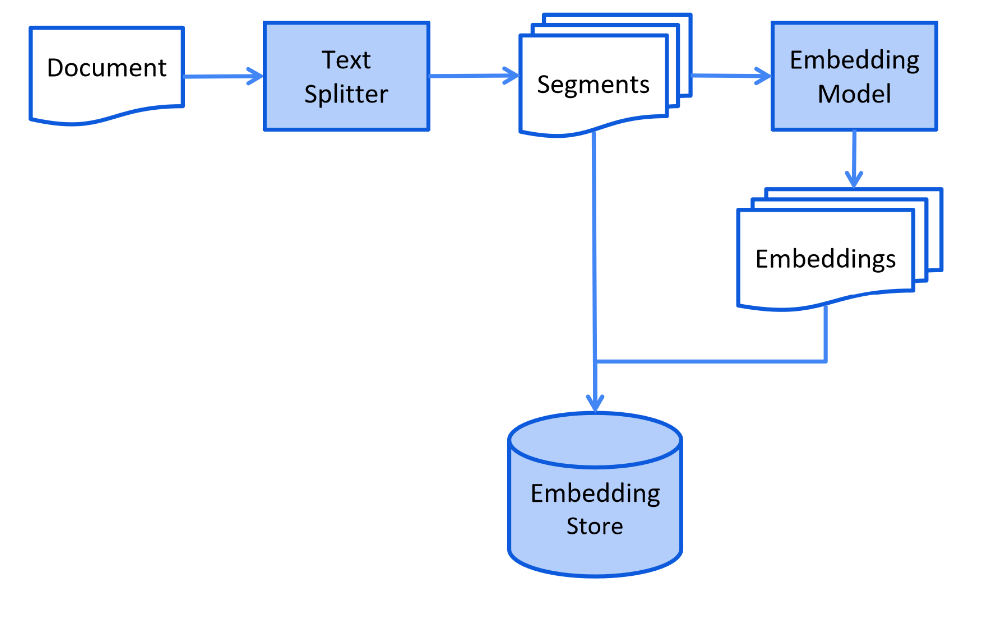
</dependency>大体的流程是这样的,我们先需要对资料进行一个向量化的存储。先对文档进行文本分割,再通过Embedding Model将每个分割完的chunk给一个向量,然后将向量和其原本的chunk都存进向量数据库
再然后是检索的流程,那就是将用户输入的文本也切分成chunk,计算其向量,再在store中进行向量比对,将余弦值最大的几个拿出来就算检索完成,再将检索到的数据拼接到prompt上,发送给LLM
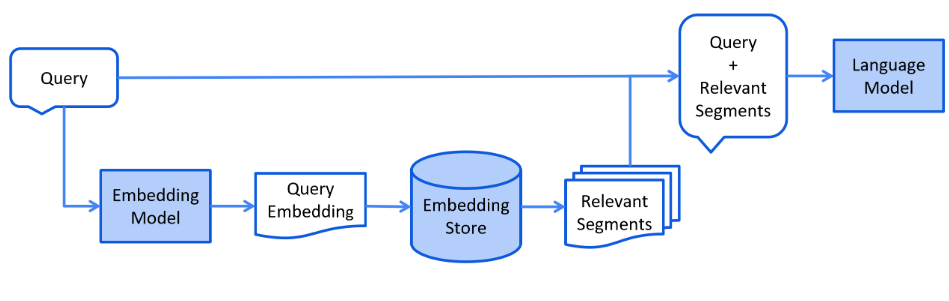 我们再用langchain4j来实现,这里我们选择用milvus向量数据库来存储embedding后的向量数据
我们再用langchain4j来实现,这里我们选择用milvus向量数据库来存储embedding后的向量数据
首先我们用docker部署一下milvus,compose一下就可以了:
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
然后我们在springboot上连接,先引入依赖:
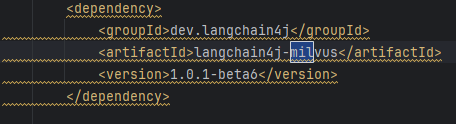
然后在yml里配置一下(虽然没什么用。。)
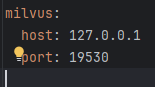
这个需要我们自己config设置一下:
@Configuration
public class MilvusConfig {
@Value("${milvus.host}")
private String host;
@Value("${milvus.port}")
private Integer port;
@Bean
public MilvusEmbeddingStore milvusStore() {
return MilvusEmbeddingStore.builder()
.host(host)
.port(port)
.collectionName("langchain4j_collection") // 自动创建的集合名称
.dimension(1024)
// 如果使用其他模型(如本地模型),请修改对应维度
.build();
}
}接下来我们要做的就是把自己的md文件经过分词,向量化后存储milvus即可,对此我们要创建一个数据库操纵对象(这里的embeddingModel也是我们可以自己选择的大模型,这里我们还是选择qwen的embedding模型),(500是指文本分割,一个chunk最多500个字符,且为了防止于语义确实,上下文可以有100个重复字符)
//创建数据库对象
@Bean
public EmbeddingStore store(){ //构建向量数据库对象,并实现rag的存储(这只是在内存而已)--名字无所谓,只有存在多个同类bean时才需要使用qualifier来查找
//1.读取在common下的Md文档
List<Document> documents= ClassPathDocumentLoader.loadDocuments("common"); //类路径会拼接:src/main/resources/common
List<Document> documents1=ClassPathDocumentLoader.loadDocuments("pdfCommon",new ApachePdfBoxDocumentParser()); //用于解析pdf文档
//2.创建向量数据库
//InMemoryEmbeddingStore store=new InMemoryEmbeddingStore();
//自定义文档分割器
DocumentSplitter documentSplitter= DocumentSplitters.recursive(500,100);
//3.创建ingestor,用来分割并embedding文档,存储到store中
EmbeddingStoreIngestor embeddingStoreIngestor=EmbeddingStoreIngestor.builder()
.embeddingStore(milvusEmbeddingStore)
.documentSplitter(documentSplitter)
.embeddingModel(embeddingModel)
.build();
embeddingStoreIngestor.ingest(documents);
return milvusEmbeddingStore;
} embedding-model:
api-key: ${API-KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
model-name: text-embedding-v3
log-requests: true
log-responses: true
max-segments-per-batch: 10然后设置数据库检索器(minscore是余弦相似度)
//创建数据库检索对象
@Bean
public ContentRetriever contentRetriever(){ //这里的传参是会在Ioc容器中寻找
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(milvusEmbeddingStore)
.embeddingModel(embeddingModel)
.minScore(0.5)
.maxResults(3)
.build();
}最后我们还是在factory内加入这个检索器就可以了:
@Bean
public AiCoderHelperService aiCoderHelperService(){ //这里相当于是生成我们自己创建的类,所以叫factory不叫config了。。。
AiCoderHelperService aiCoderHelperService=AiServices.builder(AiCoderHelperService.class)
.chatModel(qwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemoryProvider(chatMemoryProvider)
.contentRetriever(contentRetriever)
.build();我们可以看到我们的usermessage后面跟着Answer using the following information,后面就是我们的RAG比对后得来的拼接的prompt了:

四.tools以及function calling
function calling的原理其实很简单,就是在将原始prompt发送是,还会拼接一个叫tool的json数据,类似这种:
"tools" : [ {
"type" : "function",
"function" : {
"name" : "insert",
"description" : "此方法用作用户报名信息的插入",
"parameters" : {
"type" : "object",
"properties" : {
"arg0" : {
"type" : "string",
"description" : "用户的姓名"
},
"arg1" : {
"type" : "string",
"description" : "用户的性别"
},
"arg2" : {
"type" : "string",
"description" : "用户的电话号码"
},
"arg3" : {
"type" : "string",
"description" : "用户的预约时间,格式为yyyy-MM-dd'T'HH-mm"
},
"arg4" : {
"type" : "string",
"description" : "用户的省份"
}
},
"required" : [ "arg0", "arg1", "arg2", "arg3", "arg4" ]
}
}
}这样LLM就能知道它能调用我们提供的这些工具(函数),如果它需要调用,就会暂时不返回最终结果,而是说明需要调用什么函数,函数调用完再拼接prompt发送给LLM,LLM再生成最终的结果(当然如果还需要调用function那就一直循环)
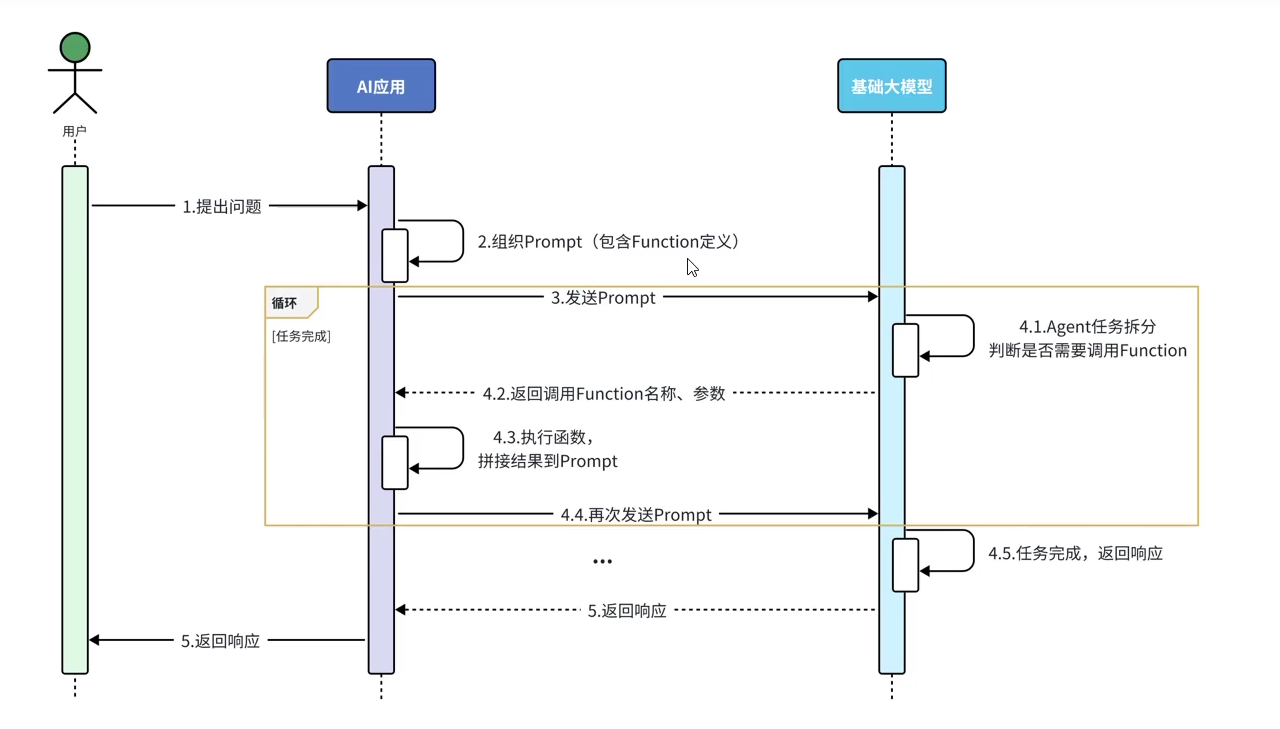
对此我们只需要写一个工具类就可以了(里面service的具体内容我就不写了,也就是增删改查)
@Slf4j
@Component
public class ReservationTools {
@Autowired
private ReservationService reservationService;
@Tool("此方法用作用户报名信息的插入")
public void insert(@P("用户的姓名") String name, @P("用户的性别") String sex, @P("用户的电话号码") String phone,@P("用户的预约时间,格式为yyyy-MM-dd'T'HH-mm") String communication_time, @P("用户的省份") String province){
Reservation reservation=new Reservation(name,sex,phone, LocalDateTime.parse(communication_time),province);
reservationService.insert(reservation);
}
@Tool("若用户提供其手机号想要查询报名信息,可以调用此查询方法")
public String findByPhone(@P("用户电话号码") String phone) { // 建议返回 String
List<Reservation> byPhones = reservationService.findByPhone(phone);
Reservation byPhone= byPhones.get(0);
log.info("开始查询,电弧号码是:"+phone);
// 1. 如果查不到,返回一段明确的文字,不要返回 null
if (byPhone == null) {
return "未查询到该手机号的报名信息,请确认号码是否正确。";
}
// 2. 如果查到了,把对象转成 JSON 字符串或者简单的描述返回
// 这样 AI 就能读懂了
return "查询成功:姓名=" + byPhone.getName() +
", 性别=" + byPhone.getSex() +
", 省份=" + byPhone.getProvince() +
", 预约时间=" + byPhone.getCommunicationTime();
}
}然后还是在factory中加入这个工具类:
@Bean
public AiCoderHelperService aiCoderHelperService(){ //这里相当于是生成我们自己创建的类,所以叫factory不叫config了。。。
AiCoderHelperService aiCoderHelperService=AiServices.builder(AiCoderHelperService.class)
.chatModel(qwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemoryProvider(chatMemoryProvider)
.contentRetriever(contentRetriever)
.tools(reservationTools)
.build();现在如果我们向LLM发送我想要查询号码为xxx的数据,其就会帮我们调用这个查询函数:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)