通往 AGI 的必经之路:Agent 自进化到底是在“进化”什么?
AI AMA首期聚焦"Agent自进化"主题,由魔搭社区等机构联合发起,汇集阿里通义实验室研究员翟云鹏及5位顶会论文作者展开深度探讨。与会专家围绕自进化定义展开多元视角:陈兆润强调在有限监督下自主改进策略并生成环境的能力;张凯提出需突破单一环境限制,建议以编程等复杂场景作为突破口;刘博则认为自进化是智能系统的固有能力,代表高阶认知水平。讨论聚焦三大方向:1)环境自主生成与策略协
原文:https://mp.weixin.qq.com/s/HrkXmbkQOrA_XGE2ZVmd3w
本文为 AI AMA 栏目第一期 Agent自进化 主题全观点转录。
青稞 AMA(AI AMA)是由魔搭社区、青稞社区、机智流与知乎联合发起的 AI 前沿技术圆桌对话栏目。围绕真正值得讨论的AI技术方向,以「多元视角」邀请一线实践者同框深度对谈:拆解原理、还原细节、碰撞观点,直面工程落地的真实挑战,打破信息茧房,建立更立体、更清晰的认知框架。

从2023年以来,我们见证了Agent在工具调用、任务规划上的逐步成熟。但一个根本性瓶颈始终存在:如何让Agent像人类专家一样,在持续实践中积累经验、优化策略,而非每次都从零开始?
Agent的自进化或许正是为破解这一困局而生,当前学界对“自进化”的理解仍未统一,有人聚焦于模型权重的持续更新,有人则关注记忆与上下文层面的进化,多种路径如何选择,是否存在融合可能…
带着这些问题,我们找到本期话题的联合发起人——阿里巴巴通义实验室研究员、AgentEvolver 项目负责人翟云鹏作为本期Agent自进化主题的圆桌主持人,并荣幸地邀请到 5 位一线的顶会论文作者同框,从最新顶会研究与真实工程实践出发,系统拆解“Agent 自进化”的技术路径、分歧观点与落地边界。
嘉宾信息
翟云鹏(主持人),阿里巴巴通义实验室研究员、魔搭社区AgentEvolver项目负责人,研究兴趣包括自我进化的智能体学习系统、复杂场景下的智能体强化学习、大语言模型后训练技术等。24年于北京大学获得计算机博士学位,在AI领域累计发表Top期刊和会议论文二十余篇。
陈兆润,芝加哥大学计算机科学专业博士二年级,Scaling Agent Learning via Experience Synthesis 一作,研究聚焦于约束条件下的 AI 智能体强化学习与自进化,以及智能体安全问题,包括自主化的 red-teaming 与 guardrail 机制设计。其研究成果曾多次发表于 NeurIPS、ICML、ICLR、NAACL、EMNLP 等计算机领域顶级会议,并获得 Oral 与 Spotlight 报告。
黄呈松,圣路易斯华盛顿大学博士三年级,R-Zero: Self-Evolving Reasoning LLM from Zero Data 一作,本科毕业于复旦大学,研究方向集中于模型自提升,代表作包括LoraHub,R-Zero, Benchmark^2。
刘博,新加坡国立大学计算机科学系博士生,SPICE : Self-Play In Corpus Environments Improves Reasoning 一作,研究兴趣主要集中在强化学习、推理与机器学习系统及其在复杂真实环境中的应用。近期在Meta FAIR担任Research Scientist Intern,研究大语言模型的可扩展自我改进与自博弈方法,发表了SPIRAL和SPICE系列工作。此前,在DeepSeek担任Student Researcher,参与了DeepSeek-LLM、DeepSeek-V2、DeepSeek-VL和DeepSeek-Prover等基础模型的研发工作。研究目标是探索可扩展的自我改进方法,构建能够在任何未知环境中智能行动的自主决策系统。
孙泽一,上海交通大学博士三年级,SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience 一作,研究方向为多模态LLM强化学习,Agent后训练。以第一/共同第一作者身份在NeurIPS, CVPR, ICCV等学术会议上发表7篇论文。Google scholar citation 700多次,github项目3k+ star。其中SEAgent作为Computer Use Agent的早期自主进化的探索得到学术界较高关注。
张凯,美国俄亥俄州立大学博士四年级,Agent Learning via Early Experience一作,研究方向聚焦于数据在基础模型与智能体中的作用。已在顶级NLP/CV/ML会议发表多篇论文,其中多篇论文获得或入围Best Paper Award(3篇),或被选为Oral(8次)和Spotlight(3次)。代表作包括MMMU, MagicLens, MagicBrush, Early Experience等。曾在Microsoft Research、Meta Superintelligence Labs以及Google DeepMind 实习。
以下进入完整圆桌观点转录&整理 👇
问题1:如何定义"自进化"?其核心判据与理解框架应如何建立?
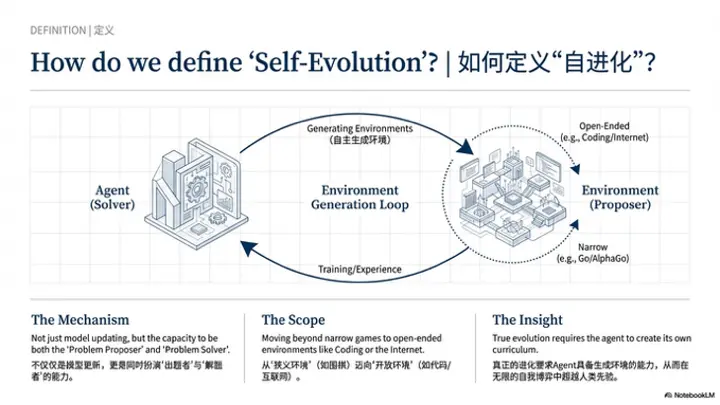
云鹏(主持人)
今天第一个问题是想请教一下大家。大家各自心目中的自进化大概是一个什么样的形式,是一个框架,还是一种模型的基础能力?大家心目中怎么定义和理解。
陈兆润
我个人对自进化的定义是,在给定有限的人类监督(human supervision)以及有限的初始训练数据(finite initial training data)的情况下,agent能够自主改进其策略(policy),从而解决越来越复杂的问题。理想情况下,它能够产生超越人类最初提供的先验知识(prior)的信息或能力。我认为这就是自进化(self-improving)的本质。
从我个人角度来看,自进化目前必须要解决的核心问题是:agent或policy model需要能够自主生成环境或任务。因为在人类提供的监督有限的情况下,为了解决更复杂的问题,agent需要在更复杂的环境中探索(explore),收集数据,进行自我训练(self-training)。因此,要达到这一目标,agent必须能够自主生成环境,或者与环境共同进化(co-evolving)。也就是说,环境和agent的策略本身需要同时变得更强,我认为这是自进化的必经之路。
张凯
我刚才一直在思考兆润提到的观点,我先来补充一下。兆润刚才提出了一个非常好的point,即他希望agent能够生成环境。这个观点其实很少有人会谈到。正如我之前所说,我是一个比较坚定的Data Believer,包括现在硅谷的数据公司,他们出售的数据实际上就是整个环境。在self-play框架下,大家通常的做法是agent既是出题者,也是解题者,这一点刚才也有提到。
无论是出题还是解题,大家有一个基本假设,就是所有事情都发生在一个限定的环境内,比如下围棋。如果要向前推进一步,就需要agent能够直接生成环境。然后在这个生成的环境中进行出题和解题。这样一来,我们就拥有了无限的环境,并且在每个环境中都可以进行self-play。在固定环境中进行self-play这件事,从2016年AlphaGo出现时就已经得到证明。包括刘博的一系列工作也证明了,self-play在语言模型上同样可行。
现在的问题是环境不够丰富。一种方法是不断让环境变得更加复杂,比如将一个外部网站或多个外部网站作为环境,或者将整个互联网作为环境——那样你就获得了数字通用人工智能(digital AGI)。但这个环境过于庞大,模型无法生成。另一个办法是逐个添加环境,比如同时用十个网站对模型进行训练,但这样环境仍然是有限的。因此,正如兆润刚才所说——这是我的理解——如果模型能够逐步生成更加复杂、更加真实的环境。
更加接近真实世界的环境,并且在这个环境中,它既可以作为出题者也可以作为解题者,那么这就相当于在一个更接近语言agent的设定下实现self-evolving。这与传统的在单一环境(如围棋)下的self-play完全不同。围棋中的self-play本质上也是一种self-evolving,最终超越了人类水平。但这个设定放在语言模型上显然过于狭窄。所以,我非常认同自主生成环境这个概念。
回到这个话题本身,即心目中的自进化是什么、如何定义和理解。我认为自进化最重要的一点是,它必须能够自动产生任务和数据。当然,我们刚才也提到,环境是数据的一部分——环境也是某种类型的数据。我最看重的标准是,这个环境不能过于狭窄,不能只是几个购物网站的组合。即使你把它定义为一个通用的购物环境(general shopping environment),解决了这个环境只能让你成为shopping expert,能够超越人类在各个网站上购物、退货、注册账号等操作,但我认为这还不够通用。
我认为coding是一个非常好的切入点(sweet spot)。首先,这个环境非常复杂,有众多编程语言和接口,甚至可以自己创造工具,拥有无限多的可能性。其次,它具有非常大的商业价值。而且在这个环境中,你相对容易获得明确的reward,比如通过算法题或NYP类问题。你可以很自然地从简单题目开始,逐渐提升难度,最终解决真实世界的问题,成为一个强大的编程agent。这就是我对环境的期望——它不能是一个简单的购物场景,比如仅仅是Amazon。我们不能将这种情况称为自进化。正如我刚才所说,即使在围棋上,不用语言模型也可以实现自进化,但这是一个非常狭窄的设定。我们已经到了2026年,十年过去了,我们需要对下一代agent有新的期望。新期望的最大难点在于,环境一定要比围棋或Atari这种非常狭窄、单一的环境更加真实和复杂。
环境可以是多个小环境的集成,这没有问题。比如你认为Amazon是一个环境,eBay也是一个环境,将它们整合在一起,我们也可以认为这是一个狭窄的购物环境。关于环境的定义,我无法给出一个完美的标准,但我应该能够判断出什么是过于狭窄的环境,什么是过于宽泛以至于无法训练模型的环境。这大概是我的一些想法。
刘博
我觉得从兆润开始,大家实际上已经聚焦到一个非常具体的框架,即自进化就是自己产生training problem,然后自己解决问题——也就是problem proposer和problem solver这样一个框架。但实际上这只是自进化的一部分。
回到之前提出的问题,即如何看待self-evolving或self-improving,也就是自进化。我认为它可能是intelligent system的一种固有能力。因为我们现在已经有了RLHF和RLVR,在这个范式下,我们已经能够训练出能力非常强的agent,或者说智能水平很高的系统。那么什么标志着更高的智能水平?比如DeepMind的CEO Demis Hassabis对general intelligence的定义,就是具备人类所有的认知能力。
self-improving象征着一种更高阶智力水平的能力。这是我对自进化的看法——一个系统必须具备持续自进化的能力。至于如何拥有这种能力,或者用什么手段让它自进化,我认为首先是兆润所说的那部分,比如RLVR中的出题。现在environment scaling的做法是由human-curated environments,然后在上面进行RL。
下一步必然是让agent或者LM、foundation model自己创造环境,然后在上面进行RL。但这可能只是其中一部分,即生成环境和解决环境。从根本上来说,自进化可以改变整个系统中的任意部分——无论是系统中的所有代码、系统架构、loss,还是update rule——通过改变这些来实现general intelligence的提升。
至于如何衡量通用智能或智能水平,后面可能会讲到。只要系统不断对自身进行modify,并且在外部观察者看来智能水平提高了,在我看来都属于self-improving。生成环境和解决环境是其中一种近期来说比较有前景的手段。
云鹏(主持人)
我的理解是,自进化(self-evolving)并不完全局限在训练阶段,对吧?它可能是一个在运行时、在推理阶段也能够进行自我提升的系统。这个系统的自进化不一定局限于模型训练(model training),也可能是其他系统组件的更新,可能是context,可能是其他模块。
刘博
对,从持续学习(continual learning)的角度来看,比如有观点认为不存在training和deploy这两个截然分开的阶段。可能我们定义一个系统,在设计完成(design time)之后就直接deploy,然后在部署状态下与现实世界交互,从而实现自self-improve。
但我们现在做的一些方法,比如我们发表的大部分文章,都是在部署之前的各种方法,在部署之后还没有将这些算法应用起来。所以暂时还是按两阶段来框定这件事。正如你刚才所说,部署之后也需要不断对自身的模块进行modify。
孙泽一
我个人对自进化的判定标准有点类似自动驾驶的分级,即人的介入程度有多少。在模型pretrain完成后应用到具体下游任务时,我们现在的做法实际上是给模型提供人工构造的数据。自进化的角度可能是,先让模型自己出题,然后自己解决。我认为未来更重要的重点是,模型如何在完全不依赖人的状态下,在某个下游任务上实现智力水平的提升。
比如说,最高程度的自进化就是完全不需要算法研究人员的参与,只要给模型足够的算力,它就能在一个新任务上达到人类应有的水平。这就类似于自动驾驶有L1到L10的分级,我觉得自进化也可以通过人的介入程度来进行划分。
云鹏 (主持人)
你认为应该以人介入程度的递减作为标志。如果人在整个模型或agent能力提升的过程中不做任何介入,那就是完全自动化的self-evolving。
孙泽一
刚才大家主要提到的是环境生成。我个人认为,在初步阶段做这个方向时,核心还是应该聚焦在真实环境上。比如code agent,我们会使用编译器作为交互环境;对于GUI和Robotics,我们会将它们放到真实的GUI和机器人场景中,让模型进行自适应。当然,环境生成也是非常必要的,未来肯定是很重要的方向。
但我觉得目前还存在一些gap。以我做的GUI为例,我们可能希望直接生成网页源码,然后让agent在其中交互。但到目前为止,这仍然是一个比较大的瓶颈——模型实际上只能学会在模拟网站上操作,无法真正泛化到真实网站。这可能是因为多模态比较困难,而纯语言任务已经做得比较好了。这是我提出的一个不同观点。
黄呈松
我认为self-evolving实际上有狭义和广义之分。狭义上,包括现在绝大部分工作,强调的是在没有额外数据或监督信号(supervision signal)的情况下进行进化——就像之前提到的出题答题的code evolving,或者让模型自己生成环境(generate environment)进行交互。但严格定义上的狭义self-evolving,更像是对已有模型能力和知识的重组与提升,就像做数学平面几何时,所有定理都基于公理和公设推导出来。模型在预训练阶段具备了一些基础能力,然后在后续的self-evolving过程中将这些能力应用得更加general,可以应对更多问题。
这是狭义上的self-evolving。但我认为更重要的是,正如刘博刚才提到的,是在deploy之后的自我进化能力。想象一个人刚出生,从小到大他不会有明确的信号告诉他应该做什么,更多是在与环境的交互中实现self-evolving。所以我认为,如果真正要实现一个self-evolving的agent system,它应该与完全真实的环境进行交互,而不是研究人员设计的环境。
比如将它放到互联网上,让它与人们聊天,通过这样的方式实现能力上的self-improve。我认为现在绝大多数工作中的code improving更像是一个训练阶段——你拥有预训练阶段已有的一些能力,然后通过一个名为self-improving的阶段让模型更好地应用这些能力、提升能力,但终究没有超出一开始的能力边界。这与我们真正希望实现的superhuman intelligence,即完全超过人类能力的AI,可能还有一些区别。我认为真正的self-evolving应该是在与真实世界、真实环境的交互中达成的系统。
云鹏(主持人)
其实我觉得evolving一方面发生在训练阶段,另一方面evolving本身也是模型的一种能力。如果我们可以定义一种能力叫做模型的evolving能力,那么当我们训练模型具备了这种能力后,它就可以在部署之后,在任何环境或场景中,以某种形式更新自己。这种更新可能发生在不同层面:比如像Linear Attention一样更新发生在cache里,如KV cache中;也可能发生在context的管理中;甚至可能包含一些self-train的逻辑,尽管这可能比较遥远或不太可控。
它可能是一个训练闭环的pipeline——我们在虚拟或真实环境中模拟自我迭代;也可能是模型本身的一种能力,这种能力使其能够在真实环境中交互并更新自己。我认为这可能是一个比较理想的状态。
问题2:自进化系统真正学到的是什么?能力提升更倾向于环境适应性,还是可泛化的通用策略?
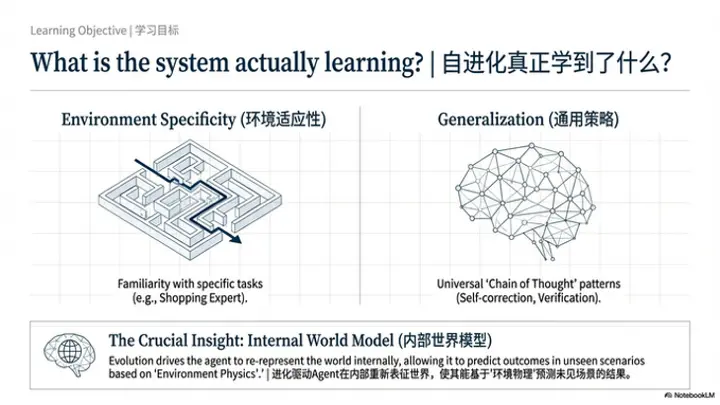
云鹏(主持人)
回到刚才呈松提到的拓展任务边界的问题,我觉得这涉及到我们今天的第二个议题:大家认为自进化——无论是什么形式的自进化——学到的东西到底是什么?它更多是对某一个下游任务或某个环境的适应,还是能够学到一些通用智能?大家在实验中有没有什么发现或观察?
刘博
我先抛砖引玉。我之前做过一篇文章叫SPIRAL,大致是让LM在一系列language game上进行self-play,然后将self-play后的模型在一些OOD的reasoning benchmark上进行评估。我们发现,OOD推理基准的性能也会提升。这里面基于一个核心观点:reasoning model之所以比instruction following model更强,是因为CoT具有泛化性。针对任意输入的prompt,模型都会按照某些CoT模式去思考。
在RLHF和RLVR阶段,目前大家都在讨论RL到底扮演什么作用,存在一些相互矛盾的观点。但我的观点是,针对这个问题,RL主要是在upweight一些基础模型能够采样出来的、比较可泛化的CoT模式——即泛化性较强的CoT pattern,比如self-reflection或者多次尝试、self-verify等,这些我都称之为CoT pattern。它们能够被RL自动筛选出来。相当于说,当你在数学题和编程题上训练时,拥有这些pattern更容易得到正确的结果,所以这些CoT pattern被RL筛选出来。
SPIRAL做的事情是,希望模型能够在一系列双人零和博弈(two-player zero-sum game)中——人类只需要编写一些比较简单的语言游戏,然后在上面进行self-play的scaling——自动筛选出那些可泛化的CoT pattern。这样不仅在这些语言游戏上表现良好,筛选出来的CoT pattern也能泛化到下游的OOD推理基准上。这就是SPIRAL要做的事情。
但这是针对推理模型的。推理agent可能会不一样。我感觉现在推理agent的某些pattern可能是基础模型采样不出来的。这样的话,就可能需要像从指令跟随模型转换到推理模型一样,需要一个中间训练(mid-training)过程。
比如,指令跟随模型要转换成推理模型,就需要一些中间训练的long CoT data,不管是通过自我指令(self-instruct)还是自我蒸馏(self-distillation)产生的数据。我认为到了推理agent阶段,可能也需要一个中间训练阶段来生成类似于推理模型长CoT数据的内容。
回答这个问题,我认为通过这些训练阶段,是能够赋予agent一些可泛化能力的。这是我的想法,也是我们的目标——我们想要达到这样的目的,所以会想出各种方法去实现。这是我目前的一些发现和想法。
张凯
非常感谢刘博这个非常有insights的分享。我之前邀请过刘博到我们组做过talk,我一直是刘博工作的big fan。其实我挺好奇的,因为我刚刚在重新思考Spiral和你的一系列其他工作。我一直很认同你说的可泛化CoT模式(generalizable CoT pattern)这个概念。
但我有一个疑问:你会不会觉得,通过在你论文中的井字棋(Tic-Tac-Toe)或其他toy language game、或者general toy games上训练,就一定能让模型找出可泛化的CoT pattern?我刚才尝试理解和解释这件事时认为,只要有一种比较通用、比较高效的解题策略,并且模型又能采样出来,那么就能自然而然地提高模型解决这道题的准确率,这个pattern就会被奖励。所以它至少是更高概率出现的。但我想问,你能否保证这个可泛化的CoT一定能被挖出来?
刘博
确实,这一点本身是无法被严格保证的。可以通过一定程度的environment scaling,但这些 language game 之间的差异可能依然非常大。这里有一个基本的假设:如果一个 reasoning model 能够在这一系列 game 上都表现良好,那么它就有可能逐步涌现出一些具备泛化能力的 CoT pattern。
此外,如果希望通过人工设计 CoT pattern 并将其注入到 base model 中,也需要非常谨慎地考虑它与预训练数据分布(pretrained data distribution)之间的关系。因为一个有效的 pattern,应该是互联网上本身可能自然存在的表达形式,而不能与真实数据分布偏离过远。否则,如果以一种较为生硬的方式进行注入,模型往往难以很好地将其激发出来,甚至可能在一定程度上产生对抗性的效果。
张凯
我非常认同这一点,尤其是与预训练数据分布(pretraining data distribution)的关系。回到刚才提到的 generalizable CoT pattern,或者在大规模推理(mass reasoning)中常说的 “aha moment”,其实可以很自然地联想到互联网上真实存在的场景。例如在 Stack Overflow 上,有人贴出自己解的一道数学题,请大家帮忙检查是否正确。
随后会有人在评论中指出:“第三行公式推导有误,应该采用某种方法。”原作者再回复“you’re right”。这一过程本身就天然包含了一个逐步推理(sequential reasoning)和自我修正(self-reflection)的轨迹。因此,这类过程数据其实是可以较为自然地被“清洗”或重构为 self-reflect 的推理过程。
所以我一直认为,像math reasoning、coding、以及其他symbolic reasoning相关的数据,在互联网上一定是大量存在的,真正缺乏的是如何将它们有效地挖出来。
但如果转到 agent 场景,情况就非常不同了。agent 的过程数据是极其稀缺的。较早提出这一问题的是秦丽佳,她指出:agent 在探索过程中,包括走弯路、回到初始状态再尝试的完整过程数据,几乎不会被记录和公开。
例如,大多数人制作软件教程时,往往是在自己已经非常熟悉完整流程之后,只展示“正确的操作路径”。比如在苹果手机上开启某项功能,互联网上有大量文档,甚至苹果官方也有说明,但这些内容只会告诉你“正确的操作序列”,有时甚至还是过时的版本。它们并不会记录一个 agent 在探索过程中形成的、可泛化的行为模式(generalizable pattern)。
这也是为什么在我看来,reasoning agent 或 self-evolving agent 想要真正具备 generalizable 能力,其中一个最大的难点就在于:缺乏这类过程数据。
回到刚才的问题——“自进化究竟学到的是什么?进化带来的更像是环境熟悉,还是通用策略?”刚才与刘博讨论时,他提到希望模型能够通过在一系列环境中的scaling逐渐学到通用策略。这一点与我想表达的观点是相通的。
我认为,目前几乎所有的 benchmark,本质上都不是针对 agent 设计的。像 MMLU 这类非常静态的 benchmark 自不必说,甚至 MMMU 也同样如此。即便是所谓的 agent benchmark,例如 WebArena、Mind2Web,它们本质上仍然是在一个特定环境(specific environment)中训练 agent。模型在这些环境中训练,大概率学到的只是对该环境的熟悉。
即便我们通过扩展环境数量(scaling environments),也只是提高模型学到通用策略的概率,而无法对此做出保证。因此,我会把这类方法视为一种手段:通过叠加大量 task-specific 或 environment-specific 的环境,希望模型有机会学到 generalizable strategy——这是人类设计出来的一种路径。
另一种思路是,直接构建专门面向通用策略的 benchmark。例如姚胜宇老师最近提出的 context learning benchmark,其核心方向是:将所有环境信息都放入 context 中,迫使模型必须依赖通用策略来完成任务。这个 benchmark 的目标是非常直接的——它就是要考察模型是否具备通用策略。
但在我看来,这类真正面向通用策略的 benchmark 目前仍然相对较少。这是我的一些个人看法。
陈兆润
我补充两点。刘博提到,在 reasoning task 中,generalizable policy 的来源,本质上是对那些已经被验证有效的 pattern 的插值(interpolation)。我认为这个insight非常合理。
但正如凯刚才所说,当任务转向更具 agent 特征的场景和环境时,例如需要多步决策(multi-step)的任务,本质上虽然仍可以看作是对已有能力(existing capability)和功能(functionality)的插值,但要真正学到这种能力,往往需要极其大量的过程数据,这在现实中是非常困难的。
因此,对于 GUI、CUA 这一类 agent,我认为一种相对更可行的方式,是借鉴早期关于“经验学习”的一些思路:是否可以让模型逐步学习到一个内部世界模型(internal world model)。这也与我相对狭义地理解 self-improving 的定义有关。
也就是说,通过不断暴露于越来越多的环境,模型在内部逐步形成对“世界”的再表征(re-representation)。最终,无论面对怎样的新环境,模型都可以基于已见过的环境进行插值,构造出对新环境的理解,然后依据该环境的“物理规则”(environment physics)进行推理与泛化。
在我看来,对于 agent 类型的任务而言,这种 internal world model 的构建,可能是实现泛化策略的关键所在。
孙泽一
还有一点补充。我非常认同刚才凯提到的观点:所谓“无法泛化”,很多时候并不是模型本身的问题,而是因为我们的 environment 规模还不够大。如果未来能够构建出足够多、可以大规模变形的软件环境,让 agent 在其中进行充分训练,那么它可能就真正具备了泛化能力。
另外,我认为在实际场景中,“环境适应性”和“可泛化的通用策略”这两种能力都非常重要。可泛化的通用策略,可能更多是做base model的人需要重点思考的问题;而环境适应性,则是做垂直领域模型的人需要重点关注的方向。这两种能力都是能力提升的重要组成部分。
至于模型是如何学到这些能力的,实际上也与具体算法有关。例如 SFT 更偏向于对特定环境的“记忆”,而 RL 可能会让策略呈现出更强的分化性和泛化性。这是我的一些补充看法。
黄呈松
我想补充一点关于 self-improving(或 self-evolving)与 pretraining 阶段关系的看法。这一点非常关键。在之前的一些实验中可以看到,所谓的 self-improving,很多时候只是把 pretraining 阶段见过、但未被充分利用的能力重新激活并强化。
因此,self-improving 更像是一轮“复习”,而不是从零开始的“全新学习”。在出题—答题这样的框架下,它更像是把那些曾经见过、但掌握不够好的内容重新拿出来训练。模型原本在不同能力维度上有强有弱,通过这一过程把薄弱环节补齐,最终表现出来的效果就是“各方面能力都更强了”,也就是我们所观察到的“泛化能力提升”。但本质上,这是一个查漏补缺的过程。
所以我认为,self-evolving 更重要的问题在于:如何引入新的能力。例如刘博在 VITA 中提出的 SPICE,就是一个很好的思路——需要在整个 co-evolving system 中引入一些额外的元素。这可以通过文档知识的方式,也可以通过环境反馈信号来实现。
但回到一个更基础的问题:这一切仍然高度依赖于模型本身的训练基础。如果 environment 对模型来说过于困难,始终无法获得正向的 reward,那么 self-evolving 的过程仍然会非常困难。因此在我看来,self-evolving 本质上更像是对 pretraining 成果的一种再利用和再强化。
云鹏(主持人)
关于“自进化究竟带来的是环境熟悉,还是通用策略的提升”,我认为这在很大程度上取决于我们让模型进行 self-evolving 的具体场景。正如刚才张凯所提到的,不同的环境设置,本身就会影响模型最终学到的能力形态。
另外,前面的讨论也多次提到:模型或 agent 在环境中究竟学到什么,一方面取决于环境本身,另一方面则取决于环境能够提供怎样的反馈信号。
问题3:关于反馈系统,自进化应该靠什么信号驱动?
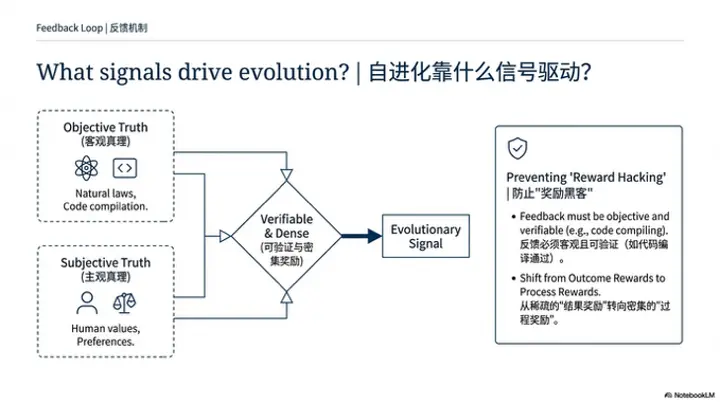
云鹏(主持人)
接下来可以讨论另一个问题是:对于一个 self-evolving 的系统,算法层面更应该关注怎样的反馈信号?这种反馈是一个简单的分数(scalar score),还是更具语义信息的表示?怎样的反馈形式,才能更有效地促进 agent 的持续进化?
刘博
我先抛砖引玉谈一下对“反馈信号”的理解。在我设想的 self-evolving system 中,它最终应当是一个持续学习(continual learning)的系统。这样的系统,其输入本质上只是一个 observation stream,也就是源源不断来自与现实(reality)交互的观测数据。
如果引入类似 RL 的算法框架,那么系统需要做的关键事情,就是从这些 observation 中挖出 reward。这在很大程度上依赖于研究者如何设计机制,让系统学会从 observation 中提取有效信号。
关于 observation,我认为在与 reality 或 experience 的交互中,大致有两类非常重要的信号来源。
第一类来自于与自然和现实世界的交互。现实世界遵循客观的物理定律(physics law)。当系统在某一状态下采取一个 action,转移到 next state 时,这个 next state 必然符合物理规律。在我看来,这是一种客观真理。如果一个 self-improving system 试图预测“接下来会发生什么”,那么它就可以通过比较预测结果与真实发生结果之间的差异,不断逼近那个符合物理规律的真实 outcome。这是一类可以从 observation 中挖掘出的 reward 信号。
第二类则来自系统与人类的交互。作为一个 continual learning 的 agent,它的 action 不仅会影响环境状态,也会影响与人类的互动结果。因此,系统需要从与人类交互的过程中挖掘 reward signal。这里我想强调的是,agent 的 action 需要受到人类价值体系(human value system)的约束,这样 self-improving system 才能沿着符合人类期望的方向提升智能,而不是偏离目标。
因此,我将这两类信号分别理解为:来自自然的客观真理(objective truth),以及来自人类交互的主观真理(subjective truth)。系统需要从 nature 和 human 两个来源中学习“什么是对的,什么是错的”,将这两类“是非”内化进自身系统,从而推动智能的持续提升。
在具体实现上,从 observation 到 reward 的转换往往需要借助所谓的 proxy reward。
例如,一种 proxy reward 可以是 prediction error,即预测的 next state 与真实物理世界中 next state 之间的误差。另一种则是对 human value 的刻画,例如基于 constitution 的原则,从人类反馈中判断哪些行为值得强化,哪些不值得更新。
这些 proxy reward,本质上是 AI 设计者在构建 self-improving system 时人为设计的中介信号,用来帮助系统更有效地从 observation 中吸收来自自然与人类的两类外部信号。这是我对反馈信号问题的整体看法。
黄呈松
我认为,环境提供的信号应当尽可能丰富和具体。举一个简单的类比:小时候考试,如果老师只是打一个叉把试卷发回来,这种 outcome reward 对学习的帮助是非常有限的。更理想的方式是,老师不仅指出错误,还会告诉你正确答案,甚至进一步给出类似情境,引导你举一反三。
同样地,对于 agent 而言,一个好的反馈信号,不应只是简单的结果提示,而应当包含更多上下文信息与解释。
例如,在 Web 环境中执行一个 action,误点击后出现一个 404 页面。这个信号不仅是“404”这个结果本身,更重要的是:它说明该资源不存在,为什么会不存在,以及在什么情况下容易触发类似错误。同时,还应包含如何rollback以及如何避免再次犯错的提示。
因此,反馈信号越详细越好。但更关键的是,除了结果本身,信号还应包含产生该结果的原因以及容易导致类似问题的场景。这样,agent 才能从中抽象出 common pattern,加速其向更具泛化能力的学习过程收敛。
刘博
我可能想讨论一下,就是说这些信号你觉得都是谁给的?人类给的吗?就是比如说他怎么知道404是不好的?
黄呈松
我们肯定希望是这个环境自己给的,但是现在,在我们所谓的 agent 和交互的环境,更大部分都是一些 human design 的环境。
就像人从小到大之所以知道“404”代表资源不存在,是因为在文档中反复见过类似说明。因此,“404”本身之所以成为一个信息量很高的信号,是因为它在既有知识体系中已经被充分解释过。对于模型而言也是类似:这样的信号,要么在 pretraining data 中出现过,要么就需要以模型能够理解的形式,显式地作为反馈提供给模型。
如果是在真实世界中,而没有这类结构化、可解释的反馈,那么相比于在人为设计的系统中进行 self-evolving,难度会显著提高。
刘博
我理解你想表达的是:在 pretraining 阶段可以为模型注入一些 prior,但更关键的问题在于之后如何进行 bootstrap。
也就是说,基于人类已经能够明确给出“对”与“错”的知识,是否可以通过 self-evolving 的方式,让系统逐步学会判断那些人类尚无法直接给出明确对错的问题。
黄呈松
这其实取决于我们希望 agent 最终成为什么样的系统。如果目标是与 human behavior align,那么它就应该做“人类认为对的事情”,避免“人类认为错的事情”。
但如果目标是构建一种 super intelligence,那么它所面对的,必然是人类也无法直接判断对错的问题。此时,即便它给出了答案,我们也难以判定它究竟是“对”还是“错”。
刘博
不过,也许人类虽然无法完成这件事本身,但仍然可以对“判断过程”进行评估。换句话说,判断一件事情是否合理,可能比亲自完成这件事更容易。
因此,问题变成:对于那些在 pretraining data 中并未明确给出对错的情形,如何去构建一种机制,使系统能够逐步形成对“对错”的判断能力。某种程度上,人类的价值观本身也是 self-evolving 的。那些被认为更聪明或更成熟的人,他们的价值观是如何在成长过程中逐步形成的?并没有人持续告诉他们什么是对、什么是错。
黄呈松
可以这样理解:一个人的价值观是由先天因素和后天环境共同决定的。这类似于模型的 pretraining 加上后续训练过程。
人在成长过程中接触到的环境与经验,共同塑造了其对“对”与“错”的理解。这个过程并不存在一个非常明确的 reward signal,人更多是在做自己认为正确、并且符合社会共识的事情。
刘博
如果一定要用 RL 的视角来理解,那么就是人在不断从 observation 中挖掘 reward signal。
但更核心的问题在于:人究竟是如何从环境中挖掘这些 reward signal,并在这一过程中持续提升自己的 intelligence。
孙泽一
我分享一个相对“纯粹”的视角。我认为最理想的反馈场景其实是游戏。例如在 2048 这类游戏中,分数始终是实时可见的。优化目标非常明确——提升最终得分。在这样的设定下,我们就可以训练出一个表现良好的 agent。
因此,我个人的观点是:对于任何复杂过程,我们都需要一种机制,能够判断该过程是否成功执行,而这可以通过一个 reward model 来实现。
以复杂的 GUI 任务为例,人类未必了解 agent 中间每一步是如何执行的,但可以根据最终呈现的结果判断 agent 是否完成了任务。因此,如果引入一个 reward model 来承担这一“判定结果是否正确”的职责,是一个相当合理的思路。
进一步来看,为什么这种方式是可行的?例如在 PPO 等 RL 算法中,本身就包含了 value model。虽然最终的 reward 可能只在序列结尾以 0/1 的形式体现,但 value model 可以将这一信号在 token level 上向前传播,对中间过程进行评估和引导。
从更宏观的角度来看,我们需要类似“游戏打分机制”的 reward model,来为 agent 的行为提供持续的反馈。在真实世界这种反馈极为稀疏的环境中,尤其是 GSP、GUI 等复杂任务场景下,这可能是一条较为可行的路径。
陈兆润
我补充两点。从更长期、偏向 AGI 的视角来看,正如刘博和呈松刚才讨论的那样,最终会面临一个问题:人类可能已经无法判断 agent 完成的任务究竟是“对”还是“错”,此时从 human 侧提供 reward 将变得非常困难。
但如果回到一个更现实、短期的 self-improving 场景,我的经验是:反馈信号必须是可验证的。因为在 self-improving 的闭环中,尤其是同时存在 environment 和 action policy 时,最大的风险是 reward hacking。如果再引入一个 reward model 参与其中,就可能出现“合谋”(scheming)或“作弊”(cheating)的现象。比如,出题方不断降低题目难度,而 reward model 给出越来越高的分数,系统表面上在进步,实际上却在退化,最终导致整个系统崩溃。
因此,我更倾向于引入一些 自然存在的信号(natural signal)。例如泽一提到的游戏信号,或者 coding 场景中已有的客观验证方式。比如 GitHub 上的 issue,如果 agent 真的能够修复问题,那本身就是一个天然且可信的验证。在这个闭环中,必须始终有一个环节是处于 human control 之下的,例如 verifier。
第二点是关于 verifier 的设计。我也非常认同前面提到的观点:reward 信号应当尽可能详细,最好是 procedural reward。以 coding agent 为例,一个常见的现象是:agent 为了通过测试,会编写一些 fallback 逻辑来“绕过”测试,而不是去真正改进核心逻辑。这其实是一种典型的 reward hacking。如果最终的 outcome reward 仅仅是“测试是否通过”,那么这种行为也会被判定为成功,但实际上任务并未真正完成。
因此,需要设计更完整、更严格的 outcome verifier,甚至对中间过程进行验证,以避免这种“投机取巧”的行为。以上是我基于实践经验,认为在 self-improving 过程中非常关键的两个点。
张凯
听完大家的分享我学到了很多。关于刚才兆润提到的可验证奖励(verifiable reward)这件事,我想补充一些看法。其实这个观点我是从Silver在podcast中听到的——有些可验证奖励实际上需要非常长的时间才能获取。比如ChatGPT给你推荐了一个蛋糕配方,你不把它做出来尝一尝,可能都不知道这个蛋糕好不好吃。所以只有做出来品尝后,你自己满意了,才能获得反馈。但这个时候你也不会回到ChatGPT说"这个真好吃"——我反正不会这么做。所以这就存在一个可验证奖励非常延迟的问题。
同时,即使用户最终真的给ChatGPT这个反馈说"真的很好吃",正如刘博最开始说的,这也是一个非常主观的评价。对某个用户来说好吃的东西,换一个用户可能就不一样。比如有人说"给我做一份蛋糕",但实际上这是给他的宠物狗吃的,这个信息可能隐藏在一个1000字的prompt里面——比如提到"这其实是给我小狗吃的",或者假设小狗的名字叫Cookie。当然我这是在过度复杂化这个案例,但大家可以想象,这种情况下,这个蛋糕大概率就不能给小狗吃了,因为里面有些成分对狗是有害的。
所以我在思考怎样将一个相对主观的奖励转化为相对客观的奖励。这个主观反馈大部分来自真实用户。一个比较好的方案是我最近听到的一句话:最好的AI游乐场就是真实市场。比如你可以让agent做一个APP,让真实用户去使用它,然后看看它能否击败其他竞品。
假设在聊天场景中,比如能否取代微信。如果它的用户流量在稳定增长,那么在整个过程中,你实际上可以比较平稳地收到奖励,因为你的年度经常性收入(ARR)和DAU都是可以监控的。同时,你还能够将一个相对主观的东西转化为比较客观的客观事实(objective truth)。这是我关于这个问题的一些想法。
关于反馈,大家之前一直在讨论分数反馈,呈松也提到可能需要一些比较细节的语义反馈(semantic feedback)。我觉得这两者各有优势。分数反馈有一个特别好的优点,就是它是可微的,所以容易训练。而语义反馈只能像next token prediction一样,注入到模型里面去。
语义反馈有一个比较大的独特优势,就是在测试时它比分数反馈更加有效。因为在编程场景中,你可以很自然地看到,如果环境报错了,目前的编程agent——无论是Claude Code、Codex还是Cursor这些模型——都有能力自己去改进。
但正如兆润刚才的案例所说,假设你的最终反馈是通过或不通过,这换成分数就是1或0。比如你有10个测试用例全部通过了,那就是满分。但实际上中间可能用了特别多的回退(fallback)去逐个攻克测试用例。所以我认为还是要增强反馈的密度(density)。这是我的补充。
云鹏(主持人)
感谢凯。我其实对一件事比较感兴趣,就是前面提到的语义反馈。因为我们今天聊的语境可能更多是RL,而RL天然需要一个分数来促进模型学习。但语义本身不是分数,所以需要一些操作将其转换成分数才能让模型学习,这就带来了一个很强的挑战。
这确实是一个gap。刚才你也提到希望agent去做一些真实的事情,比如开发APP,然后看看有没有用户使用。这里面就存在一个更复杂的跳跃问题:谁来确定如何给agent提供分数信号?如何将语义转换成分数?比如当你把DAU或APP下载量这些指标转化为agent的分数奖励时,实际上也需要一个mapping关系。这个mapping由谁来完成?是由agent自己选择,还是由人来定义?你对这方面有什么想法吗?
张凯
关于你刚才提到的这些问题,首先它们是可量化的分数,其次确实也不够全面。但在我们今天讨论的自进化语境下,我认为这个mapping应该让模型自己来完成。这样相当于模型自己创造了一个东西,然后这个反馈来自一群用户,所以也算是外部奖励(external reward),接着模型自己再将这个反馈映射到可训练的信号(trainable signal)。这样更符合我们今天讨论的主题。
但在现实中,甚至在硅谷,大部分人的做法实际上还是:我打开电脑,让Claude Code运行一天,让它写代码就完事了。但做出来的APP最终还是由人来决定Claude Code下一次如何改进这个feature。所以在现实中,还是有更多人参与其中。他们会尝试将一些客观指标,比如DAU等,转换成具体应该完成哪一个模块或改进哪一个功能的决策,然后直接以instruction的形式告诉模型怎么做。在现实中是由人来完成这件事情的。不知道是否在一定程度上回答了您的问题。
刘博
我基于凯的观点补充一下。他说的现实情况和理论上的做法,在不久的将来应该会结合起来。也就是说,模型首先肯定是自己将DAU转化成训练信号(training signal),但这个模型会具备一定能力去判断"我转化得对吗?"它会就不确定的东西询问人类,得到人类的确认后再进行整体训练。
我们作为AI designer在设计AI时,也需要让AI具备这种能力。尤其是在让self-improving system去设计自己的reward signal时,转化过程一定要让人类确认一下是否正确,然后在人类肯定后再进行转化。这样会让整个系统更加鲁棒。
云鹏(主持人)
会更稳定一些。因为如果模型自己提供奖励,一方面很容易被击hack,另一方面它提供的奖励也不一定满足人类的需求。
刘博
对,一定是协同改进(co-evolving improvement),AI和人类共同进化。
问题4:如何评估自进化的实现程度?是否需要建立新的评价体系与测试场景?
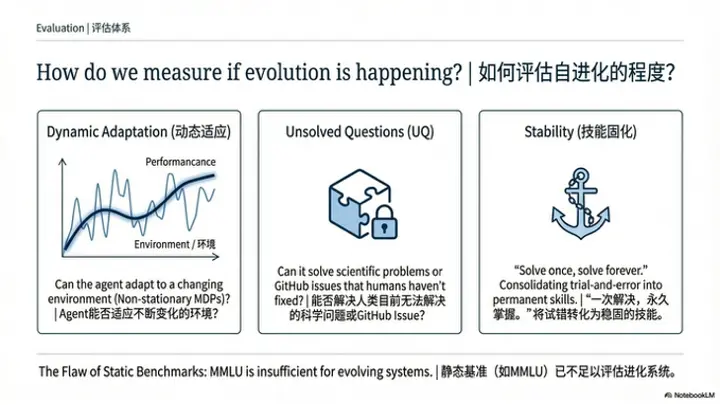
云鹏(主持人)
好,那我们看下一个问题,因为我们刚刚讲的是反馈信号,我们下一个问题是关于评估。反馈和评估之间它天然的有一种比较自然的联系,反馈可能是告诉模型这一轮你做的怎么样,而评估就是我们如果真的有一个 self evolving 的系统也好,或者是算法也好,怎么去评估它做的好还是不好?
我先自己随便抛一个,我觉得如果有一系列任务——不管是一系列环境还是一系列任务——那么可以像元学习(Meta learning)一样,在元训练(Meta training)阶段进行验证和训练,然后看在后面那些没有见过的任务或环境中,模型能否做得更好。这是一种评价方式。那是否还有其他更合理的新方式呢?大家有什么想法?
刘博
在我看来,如果所有基准测试(benchmark)的分数都提升了,就说明实现了自我改进。也就是说,人类设定的所有benchmark都上涨,就是自我改进。
云鹏(主持人)
这实际上是一个持续的评测过程,而不是一个静态的切面。
刘博
对的,假如说有一个衡量general intelligence的基准测试,这个基准测试可能是现存所有人类工作的KPI。我们现在做的实际上都是一个代理指标(proxy)——大家设定一些简单的benchmark是为了方便,可以在10分钟或半小时内完成评测。但理论上,真正的标准可能是:如果一个self-improving system在现存人类所有工作的KPI上都得到了提升,那在我看来就是真正的提升,这是100%能确定它正在自我改进的标准。
但当然,这是一个理论设想,实际上太难评估了——将所有系统部署到各个工作岗位上去衡量它的performance难度太大。虽然现在大家都在分布式地部署各大模型,比如用Claude写代码,用某些工具做法律咨询等,也会有这样的应用,但评估时间太长了。
对于AI designer来说,还是需要设计一些代理基准测试(proxy benchmark)来衡量某些关键能力的提升,比如腾讯最近姚顺雨发布的一些benchmark。
陈兆润
我补充一点。除了现有的benchmark,我认为一个肯定可以用来衡量通用人工智能(AGI)的指标是:它能否解决尚未解决的新问题。比如斯坦福有一个benchmark叫做未解问题(Unsolved Questions, UQ),这些都是人类目前尚未解决的问题。
我认为如果AI能够解决这些问题,因为人类做不到(human cannot do it),那么就证明它能够超越人类现有的知识(existing knowledge),也就是说它能够在人类提供的语料库(corpus)基础上实现改进。我觉得这是一个可以作为比较可靠的评价指标(reliable metric)。但这应该很难实现。
刘博
我稍微补充一下兆润说的,这个可以映射到一个非常简单的实验:给定爱因斯坦发现相对论之前的所有知识,如果一个系统能够发现类似相对论这样的理论,那这个系统可能就具备了非常强的general intelligent能力。
但这是一个0或1的benchmark,不能像云鹏说的那样,随着系统随时间变化,用一个随时间变化的指标去追踪它的进展。这个可能需要再设计一下。
陈兆润
对,我想补充一点。随着时间发展,另一个例子是刚才凯提到的GitHub上的existing issue。理论上来说,随着时间发展,因为现在大家都用coding agent来解决问题,如果某个bug当前的编程agent能够修复,它就不会上升为issue。
所以我认为,如果agent能够持续解决GitHub上的issue——只要是现有的、新的、未解决的问题,如果AI能解决,这应该是一个持续的过程(continuous process),可以作为对刘博刚才评论的补充。
黄呈松
我觉得有一些场景很适合做评估,包括前面提到的开发APP,或者一些更现实的场景,比如让agent去炒股——它能赚多少钱就取决于它的能力。这就是我前面提到的社会共识(social consensus):你认为一个人比较厉害,他就能赚比较多的钱。那么通过炒股赚钱就是一个衡量agent是否比上一个版本更强,或者比大部分人更强的方案。
所以我认为,我们评价人的很多指标和方式都可以用来评价agent。比如可以让它参加高考,看能考多少分,这也类似于一个基准测试——有一个统一的标准,这个标准不停在更新,可以看到agent的能力有没有变得更强。
张凯
我补充一点。我觉得大家说得都特别好,我也非常认同呈松刚才说的观点。如果是在一个单一但非常复杂的任务上——虽然交易是一个单一任务,但实际上非常复杂,动作空间(action space)几乎无穷大——我们确实能够证明模型在交易上可以自我进化。包括兆润提到的coding,也能证明在编程上可以自我进化。
我不可否认,这两个环境和任务都比传统强化学习agent的围棋案例要复杂得多。我一直在反思传统RL agent的围棋这种狭窄环境(narrow environment)与现代agent之间的最大区别和挑战。在我看来,这两者可能确实复杂了很多,但可能还没有那么大的本质区别。不过我承认,编程已经不算是单一环境了。
我想谈谈超出环境之外的一些评价指标。我想强调一点:如果agent完成一次任务后,它应该永远都能做对相关的任务。
它不需要泛化到未见过的任务,而是说自己试错(trial and error)成功一次之后,永远都能做对类似的任务。比如最近比较火的Claude Bot,它自己setup之后,对你的memory都是hard coded的,你能做什么事情它也不太清楚。假设我们让它去监控股票,定期帮我买大盘指数,一旦它写了一段代码后,之后每次都能非常可靠地完成这个任务。当然这个任务也会越来越难,因为人在知道了它的一些底层逻辑后,就会想要更多——因为人是有惰性的,总是会让它为自己做更多事情,比如转养老基金等。
所以我的评价指标(metric)是:它不需要第一次零样本(zero-shot)就能解决未见过场景的未见过任务,但一定要做到的是,给它一个任务,解决之后永远都能解决这个任务。我觉得这比较符合自我进化的特征。这跟训练不训练没有关系。比如我们做完一个任务后可以将它封装成skill或MCP。做完这件事后之后都应该能做对。这实际上比想象的难很多,因为如果你的技能堆叠到10万个、100万个、1000万个之后,你是没办法管理这些上下文的,甚至无从下手。因为有时候那些技能没有那么通用。虽然短期来看这非常符合我刚才说的自我进化,但这样做是有上限的——它被模型的上下文能力(context capability)和记忆系统(memory system)所限制。这是我的一些想法。
云鹏(主持人)
我很同意凯的观点。我觉得如果以不断堆叠和scale的形式,相当于一个没有记忆的人在不停地记笔记。每做完一件事情就忘掉它,然后把它记在笔记本上。以后要做什么新事情,就要把笔记本翻开。无论你有什么高效的记笔记或检索笔记的方式,但这不是智能。你还是一个空空的大脑,只是写了很多工作流去做这件事情,但并没有真正解决问题。聊到这里,刘博你还有补充吗?
刘博
我想补充一点。针对我刚才说的,其实我刚才定义的基准测试都是在定义什么是通用general。但对于自我进化来说,还有一点就是适应性(adaptation)——它必须能够适应新环境。所以如果今后要建立一些基准测试的话,我可能会倾向于建立一些变化环境(changing environment)的基准。
它可能不光是任务会有变化,从马尔可夫决策过程(MDP)的角度来讲,它的状态转移也希望能有变化,并且随着时间变化。然后将这些作为一个组合系统去衡量自我进化系统的适应能力——即适应不同环境的能力。这可能是一个continual RL的设定来衡量。这是我想补充的。
问题5:不同学习范式(如SFT、RL与训练之外的进化机制)之间应如何协同与定位?
云鹏(主持人)
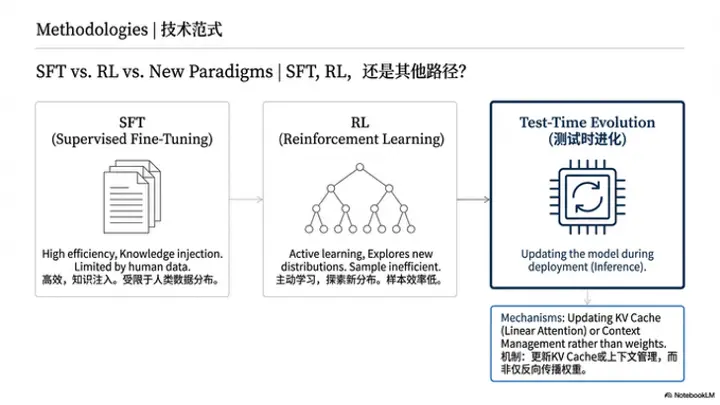
聊到这里,我们接着下一个问题。刚才大家讲到的,不管是RL、SFT,还是其他训练之外的进化方式,我们发现现在做自我进化有很多种手段。我们的目的是一样的,就是希望agent在一个环境里的运行过程中,能够不管以训练的方式还是非训练的方式去迭代更新agent系统本身,使得它在这个环境里可以越来越好用,或者越来越智能。但方法上其实存在一些不同的选择。大家觉得从各自的视角来看,SFT、RL,甚至一些其他训练之外的进化模式,各自会有什么样的特点和取舍呢?
以之前Early Experience的文章为例,那篇文章其实并没有提到RL的逻辑,而是在与环境主动发起探索之后,把一些信息以SFT的形式注入到模型里面去。在我理解,它实际上是学了一个内在的世界模型(world model),但更多是把这个世界的运行模式记录下来。它不是一个做题的过程,而是记录了一些环境切换的过程。凯觉得这与后面大家发表的一些关于RL的工作相比,有什么侧重点的不同呢?
张凯
感谢感谢!这个工作只是我对agent学习数据的一些比较粗浅的探索。我稍微展开一下。其实我觉得RL这个东西没什么特别神奇的——先讲理由。我不是一个非常坚定的RL信仰者(RL believer),我是一个非常坚定的数据信仰者(data believer)。我和刘博讨论过很多次,我们互相认同。
比如说,SFT比较好的地方是,现在Infra非常成熟,训练非常快,也很容易注入知识。而RL的优势在于,比如我们拿最简单的RLHF来说,如果不加过程奖励(process reward),那么它就避免了模型从探索的中间过程中学偏——即过拟合(overfit)到某一个模式(pattern)。它只是学习如何最大化最好的结果(outcome),所以训练当然会慢一些。但它防止了模型拟合到人给定的任何模式。这是在环境比较好的情况下。所以它的优势是可能具有超越人类(over-human)的潜力,劣势当然是训练比较慢。
还有就是,如果你的采样概率为0,该如何启动等问题。我在Early Experience里面做过一些比较有意思的实验,但最后没有放在论文中。比如我把探索的替代动作(alternative action)——每一个state探索的替代动作——作为负奖励(negative reward)。
我拿一个最优的字符(optimal character),它有一个完整求解器(complete solver)。我把这个多步骤(multi-turn)的东西打散成多个单步骤(multiple single-turn),也就是说在每一步时,它要像做数学题一样去选择这个状态的action。无论你怎么推理,我只奖励给你这个最优字符的最优动作。这听起来已经非常接近完美了,对吧?但它训练出来的效果跟SFT差不多。
所以那一刻我感觉,不管是RL还是SFT,它们核心的区别就是监督来源(source of supervision)的区别。我比较喜欢用数据去解释问题,就是监督数据来源的区别,以及RL和SFT在监督方式上的区别。如果你的监督来源不变,比如按照刚才那个设定,我这样去建模RL可能别人觉得很蠢,但它本质上做的事情跟SFT是一样的——就是说你在这个状态就要做一个动作,其他的全是负的。
那这样训练出来就不如RL的情况。不知道我有没有讲明白我的观点。所以我当时想的是,在一些RL基础设施就绪之前,如何尽可能地利用环境——因为环境也在提升,大家在慢慢构建能够提供奖励(reward)的环境。比如现在的外部环境,它可以交互,你也可以获得很多有用的信息,但可能很难获得奖励。也许我们后面会有这种奖励的情况,或者像一些多轮工具使用(multi-turn tool use)的设定,在基础设施成熟之后,它也能够提供奖励。
但在这之前,我们的模型训练也不能停下。我们就先让它去探索,探索之后我们再做RL。模型训练这块——做数据、做模型训练——和构建环境、构建基础设施这块,是可以并行的。我觉得对我来说,这是我对这篇工作的理解。不知道有没有回答刚才提的问题。
陈兆润
我也比较同意刚才说的。我觉得RL其实没什么大不了的。但我觉得RL最大的优势是它是一个主动学习(active learning)——我觉得RL对数据分布(data distribution)的影响是最大的。它可以主动去改变这个分布,而在SFT中,分布实际上是由人类控制的。
但我非常同意凯刚才说的,RL不容易过拟合(overfit),前提是任务的reward设计得好。我觉得如果奖励设计不好,它仍然会过拟合——这是所有训练范式(training paradigm)都无法避免的。同时,RL仍然有一些问题,比如刚才提到的采样效率(sample efficiency)问题也非常严重。所以可能比较认同的是,SFT和RL需要结合。
可能需要一些中间训练(mid-training),最后到最终阶段后,我们再用RL把它部署到真实世界(real world),然后去收集真实世界的反馈(feedback)。但前期从代码的热启动(warm start)来说,可能还是用一些SFT和中间训练比较符合生产环境(production),比较合理。
黄呈松
我认为无论是 SFT、RL 还是关于 Memory 的技术,其本质都是在更新策略模型(policy model),只是实现方式不同,最终结果是一致的。在这一点上我与凯的观点相同,即最核心的始终是数据和信号(signal),无论采用何种方式来更新策略(policy)。
所以目前来看,无论是 SFT,还是刚才提到的reward hacking 的问题。除非奖励信号来自真实世界,否则绝大部分由人工设计的奖励(human-designed reward)——除了像 RLVR 这种基于规则(rule-based)、能够绝对保证正确率的奖励外——都很容易发生 reward hacking,尤其是在设计一些较为复合的 reward 的情况下。
因此,与其关注哪种训练方式更适合模型scaling,我认为如何从现实环境中无监督地获取这些训练信号(training signal)会更加重要。
刘博
我非常赞同呈松的观点,即从经验中挖掘信号或奖励信号(reward signal)。关于此前讨论的 SFT、RL 及 self-play,RL 的一个核心点在于它具有负梯度(negative gradient)机制,即通过试错(trial and error)来降低产生错误动作(error action)的概率。
此外,RL 会计算当前state下所有动作的value,并根据 value 的大小来选择 action。凯之前观察到的实验现象,可能是因为未能将次优(sub-optimal)动作进行有效区分,导致在某些 state 上针对不同 sub-optimal action 的价值估计(value estimation)出现偏差。如果能在每个 state 下对所有 action 的 value 评估准确,RL 的表现理应优于 SFT。
诚如兆润刚才所言,对于一个环境或马尔可夫决策过程(MDP)来说,当前的状态-动作分布(state-action distribution)是由当前策略(policy)决定的。同时,RL 的更新机制能保证模型逐渐学到未来奖励之和(cumulative reward)最大的 policy。这印证了我刚才的观点,即 RL 通过不断试错来排除错误选项,使正确选项脱颖而出。这是 RL 相对于 SFT 的优势所在。
我再补充一种训练范式(training paradigm)。最近讨论的自我演化(self-evolving),其可选的训练范式之一就是自我博弈(self-play),而 self-play 也有多种形式化(formulation)表达。这里列举一些现有的形式:
第一种如 SPIRAL 所示,在零和博弈(zero-sum game)中进行 self-play(涉及 player 0 和 player 1),以此筛选出可泛化的 CoT pattern;
第二种是 Proposer-Solver 架构,其动机是通过对抗式学习,让 Proposer 提出的问题能够覆盖人类未来可能涉及的所有问题空间(problem space),从而训练出通用的解题器(general problem solver);
第三种是将 self-play 用于“证明者-验证者”(Prover-Verifier)架构,即 Solver 和 Verifier。这种模式类似于 GAN 的形式,旨在训练出更具鲁棒性(robust)的 Verifier。对于整个自我演化系统而言,Verifier 的角色至关重要。
通过这种 self-play 的用法,Verifier 会变得更加鲁棒,这也是现有研究中的一种典型 formulation。以上介绍了几种 self-play 的新形式,我认为这可能是继 RLVR 之后一个非常有前景(promising)的训练范式。以上是我的观点。
我也补充一点:刚才大家提到的主要是通过特定的训练方式或优化算法来优化模型参数本身。我想提出的是,如果从我们最初讨论的部署阶段实现self-evolving,KV cache 中的 embedding 本质上也是参数化的一种形式。如果我们能在部署阶段针对 KV cache 进行更新,那么在testing阶段,模型自然可以实现边执行任务边优化输出action概率分布的效果。
但这种方式存在一个问题:如果纯粹以累积(cumulative)的形式积攒所有的历史行为,数据量会不断膨胀。因此,我构想的一种方案是,未来如果能采用类似线性注意力(linear attention)或者更自然的 KV cache 管理机制,就可以在交互过程中持续更新 KV cache。
如果 KV cache 能够支持这种“边做边学”的模式,就可以摆脱每次都要更新模型主干参数的局限,转而以另一种参数模式来影响模型行为。而且这种更新是不需要反向传播(backpropagation/BP)的,过程会更加自然。我认为这也是一种可行的途径。
问题6:具备规划、调用子智能体、文件系统与长程状态等能力的Deep Agent,是否显著增加了自进化的实现难度?
云鹏(主持人)
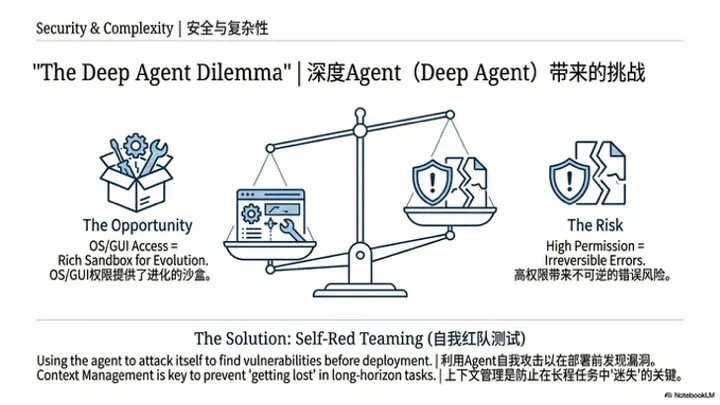
好的,接下来我们进入下一个议题。最近 OpenClaw比较热门,我也部署了一个然后自己玩了玩。OpenClaw 本质上属于DeepAgent的一种,DeepAgent是LangChain 提出的一个概念,就是一个具备plan、子Agent、一些系统和复杂的工具条件下的一个Agent。那么大家认为,在这样一种更为复杂的 Agent 场景下,它的自进化会和我们之前讨论的简单场景,比如解决数学问题或基础搜索任务相比,存在哪些更大的挑战和机会呢?
张凯
对于OpenClaw从环境复杂度来看,它确实比纯coding或特定任务的自进化要困难一个量级。但它之所以受到关注,是因为它拥有极高的操作权限。这种环境对它而言反而是一种优势,因为它能调用计算机上的所有command以及GUI的观测。只要用户信任并提供必要的凭证(credential),它就拥有了一个极其丰富的沙盒(playground)。这与以往不同,过去我们需要顾虑各种安全性问题,特别是 Web Agent 的安全性问题非常严重。
尤其是对于拥有算力的大公司而言,法律风险不容忽视。例如在爬取Amazon数据时,虽然行为本身可能合法,但如果 Agent 自动执行了“加入购物车”的操作,就可能引发法律纠纷。
因此,开发者往往不敢轻易部署,更不用说在真实世界中应用像树搜索(Tree of Search)这类在理论上能极大提升性能、但落地难度极大的算法。过去训练模型多以公司或单位为形式,一旦模型在外部产生安全问题,责任归属很难界定。目前像 Claude 插件或coworker在执行动作前,通常会频繁请求访问权限。这种过程其实不利于自我演化,因为系统过于担心产生不可控的后果。
虽然目前公众对 OpenClaw 的安全性仍然有顾虑,但由于它的用户基数庞大,甚至许多非技术背景的用户也愿意通过 Mac mini 这些设备进行配置和尝试。这类用户往往会直接授予全部权限,这为 Agent 提供了极大的操作空间,使其从部署Day1起就能获取完整权限。这种在部署阶段实现的test-time improvement是前所未有的。所以说,这是一个独特的机会。我认为,这反而为模型在test-time self-evolving提供了一个绝佳的playground。
陈兆润
好的,我接凯的观点补充一下。我认为凯的看法非常make sense。结合我目前的研究方向,我想针对刚才提到的安全性与防御性(security)问题展开讨论。对于自我进化而言,效用(utility)或性能(performance)仅是其中一个维度,安全性问题同样不可忽视。
目前网络上关于 OpenClaw讨论最多的议题正是其安全性。对于这种包含多个组件的复杂智能体,正如刚才云鹏提到的,我们需要分析其可能存在的失败模式。我认为安全性应当作为一个核心维度,纳入评估智能体的benchmark中。例如,我们可以让智能体充当红队智能体(red-teaming agent),对自己进行风险评估(risk assessment),并尝试fix自身存在的漏洞。
我本质想表达的是,自我进化不能只关注效用(utility),必须同时将安全性(security)纳入考量。只有兼顾这两者,才能称之为一个真正work且完善的self-improving agent。
云鹏(主持人)
关于这一点我再做一些补充。其实随着Agent变得日益复杂,它需要处理long context、大量文件、解决复杂任务并调用多种工具。这导致 Agent 的执行逻辑和任务轨迹变得越来越长。
刚才刘博提到,如果value function能够估计准确, RL就能取得很好的效果。但在这种复杂场景下,价值函数的训练与收敛面临着巨大挑战。在长上下文的场景中,试图让模型准确预估未来的value expectation,其本身就极难收敛。这给复杂 Agent 的训练带来了显著的困难。
所以我认为,一方面,即使 Agent 本身的上下文管理能力足够出色,value function也需要配套的上下文管理机制,或者采用更高效的adaptation学习方法。如果仍需使用value function,则必须确保它能更快速地适应policy的变化。这在算法层面提出了更为严峻的挑战。
刘博
是的,关于deploy来说,目前像 OpenClaw 这种系统主要依赖于LLM inference。虽然实现方式谈不上多么fancy,但目前主要依靠context management能力来构建memory,保证具备一定的self-improving和self-evolving能力。
我想抛一些关于test-time training(TTT)的探讨尝试。刚才提到的value function在实际应用中更多表现为价值模型value model。目前在 Agent RL 领域,这类模型的使用还不普遍,但对于长程决策(long-horizon decision making)而言,价值模型是至关重要的。价值模型同样需要进行test-time training,或者说需要具备持续学习(continual learning)的能力。
无论采取哪种test-time training方式,核心都在于如何adapt当前任务。因为每个任务都对应特定的reward function,如果一个general的或generative的value model能够快速adapt到特定任务中,将对test some training也会产生巨大帮助。
这样回到问题本身,现在的 OpenClaw 相当于大家将inference作为一种最economical的方式,也是self evolving的方式部署在了一个非常复杂的系统上。比如,它已经被部署到了一个 OS level 的环境里面,可调用的工具量量已经陡增了。现在大家就处于探索阶段,在仅依靠test-time inference的方式,看他的上限在哪,然后用一些context management 方式,看一下他的 self evolving 的方式在哪 。这个平台对于test-time training而言,会是一个非常有挑战的问题。以上是我对这个场景的大致看法。
问题7:在工业实践中,自进化如何被可控地转化为业务价值?


云鹏(主持人)
好的,接下来我们进入最后一个议题,这是一个非常现实的问题。刚才我们深入探讨了许多research层面的involving方法和关键的问题,那未来我们还是希望这类involving的系统能在工业场景中真正落地应用。考虑到大家都有在各个企业实习的经历,想请教各位:从工业界的实际视角出发,在生产环境中应用这些involving 的系统,还面临哪些阻力和风险?
刘博
我觉得现在大家一直在做problem solver,对吧?从RLHF到RLVR到environment scaling,重要的是所谓大家可能称之为RL data,就是prompt——比如数学题、编程题的提示词。这是单轮环境(single-turn environment),然后到了多轮环境(multi-turn environment)就是编程、搜索等环境和tool use环境任务。
我觉得对于工业界来说,这些提示词肯定是先靠人类研究者去现实中挖掘一些可验证的环境,比如从GitHub、从编程的预训练语料里面去挖掘一些软件工程(SWE)的环境。这个已经被做了,而且已经被扩展了。
我觉得下一步紧接着就是让合成提示词(synthetic prompt)——这是工业界可能会或者可能已经大规模做的,但据我所知现在可能有效的并不多。首先,合成的数学提示词(synthetic math prompt)在大规模上应该是不太有效的,呈松可能可以评论这一点。我的观点是,现在大规模的合成数学提示词应该不太有效,可能code improving有效。
但我觉得合成提示词这么一个非常具体的东西,在大规模上有效,对于self-improving来说是迈出巨大一步的一个非常切实的方向。就是如何让大规模合成提示词能够有效,或者合成环境(synthetic environment)能够有效。其实DeepSeek尝试过合成环境,但可能更多是一些合成的任务(synthetic task),而不是一个具体的合成环境——它的一些合成转移函数(synthesize transition function)之类的。
这是我想表达的:如何先让合成提示词大规模地有效,然后再考虑去生成自适应难度(adaptive difficulty)的提示词——也就是现在self-play正在触及的一些东西——然后让它大规模地有效。这可能是我想抛出来讨论的一个问题。
黄呈松
我想说一点。其实对于真正的SOTA model,比如GPT、Gemini这种级别的模型,它有一个很大的成本在于部署成本。这意味着它很多时候不能像小模型一样,针对每一个下游任务(downstream task)都有一个对应的self-evolving版本。所以对于这些模型来说,它的自我进化大概就是整个模型的更新。
但又回到这个问题,这个模型本身的训练成本很高,所以它也不支持一个很高频率的更新。所以业界的自我进化,相比于我们在研究阶段做的,它是一个频率更慢的动作,也就是说它是收集了一系列的数据。
然后做一次training,然后improve。当然也像刘博说的,它肯定有data这一步,还需要synthetic data。但这个合成数据肯定需要来自一些human feedback。因为语言模型是一个飞轮流程——当你有了一些流量后,你就有一些真实的问题,即用户提出的这些问题。你需要的是从这些用户问题中找到一些signal。
现在正在进行的一些项目,就是研究如何从原始对话(raw dialog)里面,通过一些用户的上下文来提供一些训练信号(training signal)。所以我觉得对于业界来说,利用流量带来的标注是一个非常重要的事情。它不是一个纯粹的self-improving过程,它更像是一个从无标注数据(unlabeled data)中去寻找模式pattern、寻找reward的过程。
张凯
我接着刘博和呈松的观点说一点自己的想法。刚才呈松也提到,私有企业的模型自我进化成本是非常高的。刘博也提到,在coding agent上,大规模合成提示词(large-scale synthetic prompt)是有效的。其实我一直很喜欢——因为大家都是程序员,肯定天天用编程agent——你可以仔细想一想,我们可以一起来反思:为什么coding agent这么成功?答案其实很明显。
首先,它的环境太好了,环境是可以回溯的。你在Git上的很多环境,即使做错了也可以回溯,而且中间的所有过程都需要人授权。它从补全一行代码、补全一个function,到写一个Python文件、写整个repo,都有一个非常平滑的曲线。最重要的一点是它可以回溯,这在真实世界(real world)的环境里是非常非常难得的一个条件。比如在购物场景中,在亚马逊上买了一个错误的产品——而且编程里面还有一点,就是你运行错了,总是有编译器,你立马就能得到test time的semantic feedback。
假设我现在在亚马逊上,有一个web agent,我想买东西,跟它说要一个15美元以内的iPhone 16 Pro手机壳,不要干扰无线充电等特性。这个query搜索出去后,模型不小心加错了一个——假设模型看错了价格,或者有时候没注意到这个手机壳的无线充电接触可能不太良好,这个信息在review里有,但它直接就先加到购物车了。这件事情的回溯是相当难的,因为你不是说回到上一个网页就行了,你要进入购物车,找到这个产品,点删除,再点确定,再回到亚马逊主页,再搜索同样的查询才能回到这个状态。
所以这也就是为什么其他真实世界的agent,大家不太敢大规模部署到有非常多用户的地方。像web agent,大家就是做一个demo发布,或者OpenAI给你开一个agent模式——比如Atlas,如果大家玩过的话。对于任何敏感的环境,比如金融或者政府文件填写个人信息这种,它一般都很谨慎,直接拒绝说不支持这种操作。它做完一个动作action又特别慢,时时刻刻你要担心它,它永远都处于一个自动驾驶FSD(Full Self-Driving)的状态。但FSD其实已经非常好用了,而网页agent到目前为止,大家很愿意去试,但要真正让大家掏钱,我持怀疑态度。
所以一旦大家不愿意提供很多有效的feedback,这个环境又有这么多限制,我觉得这件事走起来会很慢。像特斯拉,作为普通轿车你也能开,也能收集data,但web agent你不用的话,我强烈怀疑它怎么收集到比较好的反馈。这是我关于coding agent的成功和其他真实世界中具有巨大商业价值的agent的一些反思。
所以可以观察到,所有厂家的agent都做了一个非常好的抽象,就是用tool use。因为工具使用太general了——我不做具体的agent场景,我做一种通用的agent能力,我就增强这个能力。这总没问题吧?用错了,部署到你本地,用错了是你的问题。这是我对现状的一种自我理解。
陈兆润
我接着凯最后那个观点补充一小点。我觉得凯说的在实际生产或工程中,确实存在security问题,或者说你是否真的敢将agent部署到这个环境里。一方面是你不敢让agent触及这些环境,另一方面是customer feedback的成本很高。所以我觉得在工程中一个比较重要的点是自动沙盒化(automatic sandboxing)。
一方面如凯所说,对于代码来说,它天然就是一个sandbox——你很容易可以在Docker中沙盒化一个terminal。但同时,对于其他场景,比如与业务相关的、与客户交互的一些个性化内容,可能需要一些其他方法。这里顺便推广一下我们的DreamGym论文——我们可以训练一个模型来模拟任何环境。
比如给定一个业务场景,我可以模拟这个用户群体或模拟这个环境。你先在这个沙盒里评估这个agent,最后没有什么大问题后再部署到真实环境。我觉得这个self-sandboxing是工程应用中一个比较重要的环节。
云鹏(主持人)
我觉得sandbox和之前兆润提到的environment synthesis其实有非常强烈的联系。但是在工业场景上,相当于你要对它的业务场景做一个数字镜像(digital twin),整套云资源都要重新备份一遍,然后去复现一个可能模拟真实环境的场景,在那个场景上去做测试。这可能也是走向工业化的一个卡点,因为这套系统的成本也有一些。总的来说,这还是有意义的,需要用一些方法把成本降下来。
(结束)
云鹏(主持人)
今天其实也不早了,很多同学都在海外,目前应该已经凌晨两三点了。所以今天首先非常感谢大家的参与。我们一起对self-evolving这个话题做了非常深入的讨论,针对一些问题也都发表了各自的观点,产生了碰撞。
今天非常感谢大家的参与,也感谢幕后各位的支持,包括魔搭社区、青稞社区、机智流、知乎各个平台的支持。感谢大家!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)