MySQL索引优化:百万数据秒变0.01秒
摘要 本文详细介绍了MySQL索引的创建与管理方法。首先通过百万级数据表的查询测试,展示了索引对查询效率的重要影响(无索引查询耗时1.93秒)。文章详细讲解了三种创建主键索引和唯一索引的方法,并介绍了使用CONSTRAINT指定索引名称的技巧。同时说明了普通索引的创建时机和注意事项,建议在高频查询列上创建索引,但需考虑数据量大小对性能的影响。最后讲解了索引删除方法,特别指出删除自增主键时需要先取消
前言❤️❤️
hello hello💕,这里是洋不写bug~😄,欢迎大家点赞👍👍,关注😍😍,收藏🌹🌹
上篇数据库博客提到了索引能提升数据库中数据的查询效率,并且分析了内部数据是使用B+树存储的,还有一些索引的分类,这篇博客就会从具体操作上解析如何创建索引来查询效率,以及如何分析索引的使用情况
🎇个人主页:洋不写bug的博客
🎇所属专栏:数据库
🎇mysql8.0和navicate的安装:mysql安装教程
🎇铁汁们对于MySQL数据库的各种常用核心语法,都可以在上面的数据库专栏学习,专栏正在持续更新中🐵🐵,有问题可以写在评论区或者私信我哦~

1,创建索引重要性
有这样一个学生表,里面有100万条数据,这里id跟sno是相同的,只是id数据类型是bigint,sn数据类型是varchar,这篇博客就会用这个数据量比较多的表来进行一些测试,来看下使用索引带来的效率提升有多少🐵
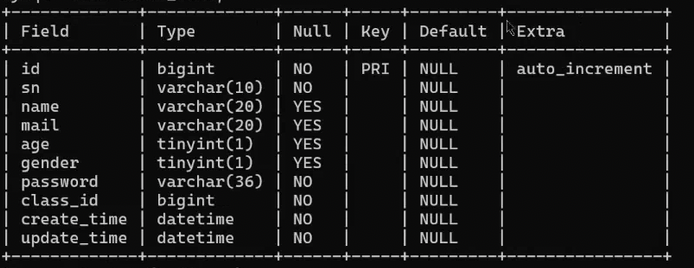
如果用主键id去查询第100万条数据,速度是很快的(下面标注的查询时间是0.00sec,这表示在0.01s内就查询好了)

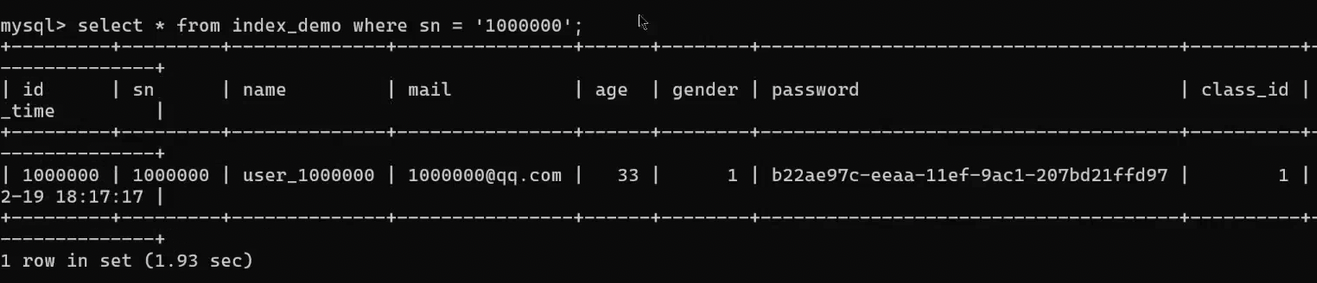
但是如果用sn去查询第100万条数据,就会感到明显查询时间,如下图所示,显示的是1.93s
有的界面是由多条数据组成的,比如要查询几十条数据,而且上一条数据是下一条数据查询的基础,如果不设置索引,直接这样查,那卡个半分钟是没问题的😅
不使用索引进行查询,耗时就会非常久,为了提升效率,就需要我们在经常被做查询条件的列上去创建索引,这个根据工作中的具体情况而定
2,索引的创建
铁汁们对于Mysql语法的学习,可以在mysql server中选择Reference Manual(参考手册),在Statement(声明)中点击Alter Table Statement,就能看到表的各种修改语法(链接如下所示)
mysql官网文档
创建主键索引有三种方法,代码如下所示,第一种就是最常用的,直接创建id的时候在后面加;第二种就是在表创建后面加上主键创建语句;第三种就是在外面分别加上将id改为自增和将id改为主键,modify就是专门用于修改已有列的属性,代码如下所示
CREATE TABLE t_test_pk(
id bigint PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
)
CREATE TABLE t_test_pk1(
id BIGINT AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY id
)
CREATE TABLE t_test_pk1(
id BIGINT,
name VARCHAR(20),
)
ALTER TABLE t_test_pk1 add PRIMARY KEY(id);
ALTER TABLE t_test_pk2 MODIFY id BIGINT AUTO_INCREMENT;
创建唯一索引也是有三种方法,普遍用的是第一种,代码如下所示:
create table t_test_uk (
id bigint primary key auto_increment,
name varchar(20) unique
);
create table t_test_uk1 (
id bigint primary key auto_increment,
name varchar(20),
unique (name)
);
create table t_test_uk2 (
id bigint primary key auto_increment,
name varchar(20)
);
alter table t_test_uk2 add unique (name);
也可以用constraint来指定创建的唯一索引名,代码如下,这两个表的唯一索引名分别是un_name和un_name1,
create table t_test_uk1 (
id bigint primary key auto_increment,
name varchar(20),
CONSTRAINT unique un_name(name)
);
create table t_test_uk2 (
id bigint primary key auto_increment,
name varchar(20)
);
alter table t_test_uk2 add unique un_name1 (name);
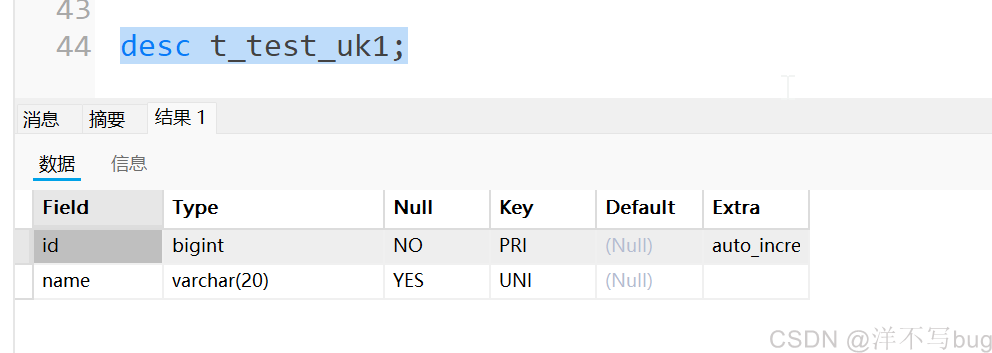
在navicat中右键这个表,点击设计表,再点击索引,就能看到索引名,如下所示:

可以使用desc查看表结构来查看索引
接下来就是普通索引,普通索引并不是我们创建约束,然后自动生成的索引,普通索引需要自己去创建
创建时机:
- 创建表的时候如果可以预测某个列是个频繁查询的列,就直接在这个列上去创建索引
- 对于数据量比较小的系统,一般在数据量达到十几万的时候再去创建索引,这是因为创建索引后还会单独维护一个索引树,当表中数据量比较小的时候,有时候直接使用全表扫描甚至比创建索引要快
- MySQL内部有优化器,会根据具体情况来决定查找时是否使用索引(当在数据量较小的表中创建了索引,查找时可能不会使用索引,直接全表扫描)
- 在版本迭代过程中,如果出现了sql查询语句运行很长时间的情况(慢sql),就要考虑添加索引
-
创建普通索引代码如下,这三个表的索引名分别是idx_sno,idx_sno1和idx_sno2
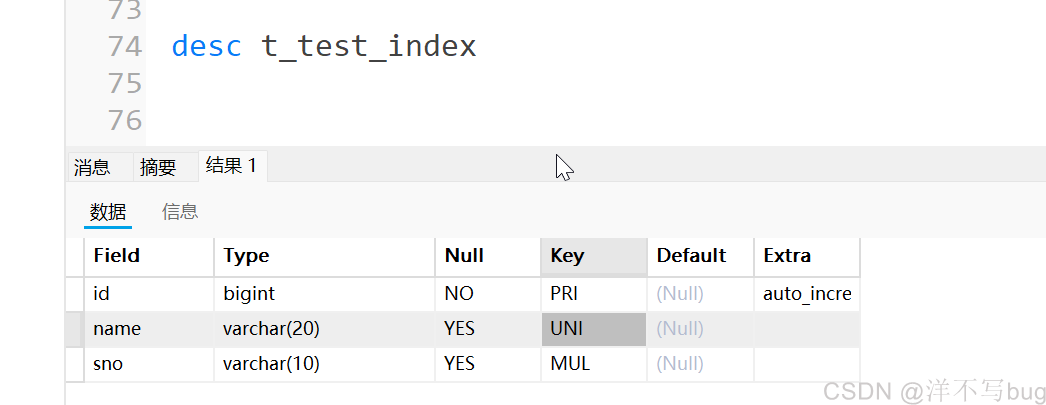
第一种就是直接在表中创建索引,第二种和第三种是创建完表后,添加普通索引,博主这里比较喜欢用第二种(创建复合索引方法类似,后面会提到这里就不再赘述了)create table t_test_index ( id bigint primary key auto_increment, name varchar(20) unique, sno varchar(10), index idx_sno (sno) ); create table t_test_index1 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10) ); alter table t_test_index1 add index idx_sno1 (sno); create table t_test_index2 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10) ); CREATE index idx_sno2 on t_test_index2(sno);查询表结构,就能看到这个普通索引
创建索引的注意事项: - 索引应该创建在高频查询的列上
- 索引需要占用额外的查询空间
- 对表进行查询、插入、更新操作时,同时也会修改索引,可能会影响性能
- 创建过多或者不合理的索引会导致性能下降,需要谨慎规划和选择
-
索引也有命名的规范,能够看到索引名字就知道这是个什么索引,命名规则如下
主键索引:pk_列名
唯一索引:un_列名
普通索引:idx_列名[_列名] 如idx_user_id_status就是包含user_id和status的复合索引3,索引的删除
如果是普通索引的删除,语法:
alter table 表名 drop index 索引名不知道索引名的话,就可以查一下,如下所示,Key_name就是索引名
show index from t_test_index1
这里注意一点,如果删除的是主键,就不写index,直接写drop primary key
ALTER table t_test_index drop primary KEY这里尝试删除主键,但是却报错了,看报错信息是跟自增有关的
这是因为如果主键是自增列,就必须把自增属性给取消,再删除主键
取消自增属性代码如下,自增属性取消后,就可以删除主键了
alter table t_test_index MODIFY id BIGINT4,索引分析(复合索引)
这个表里面有100万条数据,在文章开头提到了,直接用sn查询的话,查询时间是1.9s,这个时间是很长的

创建个普通索引,再用sn来查询下,就会发现原先需要查询接近2s,现在在0.01s内就能查询完毕


还有个常见的需求,就是通过班级和学生姓名来查询,查找时间为1.79s,就需要创建复合索引来解决,如下所示,注意,这里复合索引创建有先后的顺序,应该是先按照班级进行查询,再按照学生姓名进行查询

create index idx_classId_name on index_demo(class_id,name);这时候进行查询,查询的时间是0,01s,查询效率得到了大幅度提升
select * from index_demo where class_id = 2 and name = 'user_1000001';
前面用class_id和name创建了一个复合索引,那单独用class_id或者name查询,查询能被复合查询加速吗,可以分别测试一下,如下所示:
select * from index_demo where class_id = 2 limit 3;
select * from index_demo where name = 'user_1000001';
这里很明显,使用class_id来查询速度很快,用name查询速度还是比较慢,这是为什么呢
这就要提到复合索引的特征了,复合索引是哪个写在前面,先按照哪个来查询(也就是最左原则)
这就类似于字典中的拼音索引(如下图),class_id就相当于是声母,name就相当于是韵母(知道声母是A当然能够加速查询,但是知道韵母是a,是很难加速查询的)
mysql内部有优化器,会根据具体情况判断到底有没有使用索引,铁汁们有没有想过这样一个问题:
这里根据姓名来进行查询,时间是1.8s,那这是使用复合查询后面列效率低,还是说就没有使用查询?
单看执行时间恐怕是没法确定的,这时候就可以在sql语句前加上个explain关键字,得到sql语句执行的分析结果,同时使用id和name查询如下所示:EXPLAIN select * from index_demo where class_id = 2 and name = 'user_1000001';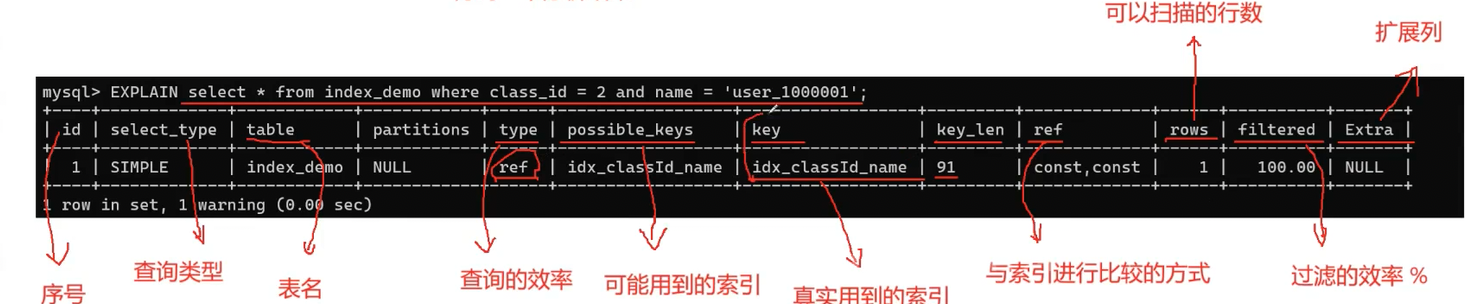
- select_type表示查询类型,这里是一个简单查询(simple),如果用复合查询这里就显示union,用子查询这里就是null
- table就表示查询的是哪个表,partition 表示区域的分区,现在可以不用管
- type表示连接类型,通过连接类型可以看出查询的效率,ref基本上就表示使用了普通索引,效率还是比较高的(具体的连接类型效率排序下面会提到)
- possible_keys表示优化器可能会用到的索引,key表示实际上用到的索引
- key_len表示实际使用索引的字节数
- ref表示与索引进行的比较方式,这里是两个const,表示使用两个常量(class_id = 2 and name = 'user_1000001')与索引字段进行匹配
- rows表示扫描的行数,是一个估计值,估计值越小效率越高,这里优化器直接匹配复合索引,只需要扫描一行
- filtered表示按表条件过滤后,剩余结果行的估算百分比。这里是 100.00,表示扫描的行全部符合条件(只扫描了一行)
- Extra表示执行的额外信息,也就是特殊说明,这里没有,就是NULL
-
select_type有以下几个常见的类型(性能从高到低):
- system:最优,表只有 1 行(系统表),几乎遇不到;
- const:表中最多 1 行匹配,通过主键 / 唯一索引等值查询,比如WHERE id = 1(主键);
- eq_ref:多表连接时,被连接表用主键 / 唯一索引等值匹配,每行只匹配 1 行,比 ref 稍优;
- ref:你案例中的值,非唯一索引 / 索引前缀等值匹配,可匹配多行(但效率仍很高);
- range:索引范围查询,比如WHERE id BETWEEN 1 AND 10;
- index:扫描整个索引(索引全扫描),比全表扫描快(索引比数据小);
- ALL:最差,全表扫描(没用到索引),要尽量避免;
在查询时,尽量不要进行ALL类型的查询,对于经常进行的查询,一定使用索引,提升效率
下面就可以看下name查询到底有没有使用到索引,如下所示,看一下type,发现是All,这里确实使用的是全表查询
EXPLAIN SELECT * FROM index_demo WHERE name = 'user_1000001';
子查询进行explain,分析就会有两行,子查询那一行的extra还标明了查询的结果使用在哪里(这里是使用在where中)
EXPLAIN SELECT * FROM student WHERE id = (SELECT id FROM student1 WHERE name = '唐三藏');
这里按照class_id的升序排序,Extra里面有个Using filesort,表示MySQL 先进行了全表扫描(type=ALL),然后对结果集进行手动排序,这是一种低效的操作。
EXPLAIN SELECT * FROM index_demo ORDER BY class_id;
还有之前提到的索引覆盖,就是创建查询列表中的列刚好是创建普通索引时的所有部分列,这时候就可以直接返回数据,explain这条sql语句,显示Using index就表示索引覆盖
EXPLAIN SELECT class_id, name FROM index_demo WHERE class_id = 2 AND name = 'user_1000001';
结语💕💕
创建索引部分并不复杂,最多用到的也就是给经常使用的查询项创建索引,索引的分析部分铁汁们大概了解下即可🐵
以上就是今天的所有内容啦~完结撒花~🥳🎉🎉


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)