“多选几个大模型”真的会变强吗?RouterEval 给了一个残酷前提:先把 router 练到够靠谱
你可能也遇到过:同一个输入,换个 LLM 结果就像开盲盒——有的秒懂,有的胡编。直觉上,“那我就多接几个模型,总能撞上会的那个”似乎很合理。
EMNLP 2025 《RouterEval》这篇论文把这个直觉推到极限后,给了一个更尖锐的结论:候选模型变多,确实可能触发一种“模型层面(model-level)的 scaling up”——但前提是 router 足够强;否则,更大的候选池并不一定带来提升,甚至可能只是更高的部署复杂度。 特别是:论文在 Limitations 里指出,从他们的实验观察看,约 3–10 个候选模型时 cost-effectiveness 最高(性能增长最快);候选太多可能带来部署挑战。
这形成了一个很现实的张力:Routing LLMs 被讲成“规模化”的新范式,但可落地的甜点区,反而可能要求你别把规模化做成“模型动物园”。
1|Routing LLMs:它省的不是“推理”,而是“把推理权交给谁”
论文把 Routing LLMs 描述成一种“分诊台”:给定输入 s s s,先由 router 决定把请求交给候选池里的哪一个 LLM,而不是让所有模型都跑一遍再做 ensemble 聚合。目标可以很多:更高准确率、更低成本、更少 hallucination……但本文为了把问题说清,在本文实验设置里优先只对齐“各基准上的性能表现”,暂不考虑计算成本、幻觉率等目标。
这个范式天然有两个吸引人的工程属性:
- 兼容异构候选:不同结构的 LLM 都可以进入同一个 pool;
- 兼容模型增强手段:fine-tuning 等方法不冲突,因为 routing 本质是“输入分配”(论文也提到与大多数模型增强方法兼容,并举了 fine-tuning 作为例子)。
但理想与现实之间卡着一个硬问题:你要研究 router,就得有系统、可复现、可迭代的 benchmark。论文也明确指出:当前缺少“全面且开源、专为 router 设计”的基准,这会阻碍 router 的发展;并举例说部分既有基准存在候选 LLM 不足等问题。
RouterEval 的目标很直接:先把地基铺平,再谈方法学。
2|把“选模型”写成监督学习:关键不在模型结构,在标签怎么做
论文在 Preliminary 里把 routing 形式化成一个分类学习问题(标签向量可以是 multi-hot):
- 候选集合 { ℓ i } i = 1 m \{\ell_i\}_{i=1}^m {ℓi}i=1m
- 输入集合 { s j } j = 1 n \{s_j\}_{j=1}^n {sj}j=1n
- 用 encoder κ \kappa κ 把输入编码成 κ ( s j ) \kappa(s_j) κ(sj)
- 用历史性能记录构造选择向量 v j ∈ { 0 , 1 } m v_j \in \{0,1\}^m vj∈{0,1}m
其中 m m m 是候选 LLM 数量, n n n 是样本数量。
这里最“反直觉但很关键”的点是:标签不一定是强制 one-hot 的“唯一冠军”。如果指标是对/错,那么多个答对的模型都可以标 1(例如 [ 1 , 1 , 0 ] [1,1,0] [1,1,0] 甚至 [ 1 , 1 , 1 ] [1,1,1] [1,1,1]);如果指标是连续分数,那么落在最优分数 95% 以内的模型也可标 1。
这背后的工程含义可以理解为:router 不必被训练成“永远押同一个最强模型”,而是学到“对这类输入,哪些候选都足够好、可替代”。最终学习目标是:
r θ [ κ ( s j ) ∣ D ] → v j r_\theta[\kappa(s_j)\mid D] \rightarrow v_j rθ[κ(sj)∣D]→vj
其中 D D D 可以是额外数据;同时,论文在 Experiments 部分也说明:为了评测基线方法,他们的实验不考虑 Section 4.3 提到的额外数据(因为其用法高度多样)。
3|先证明“现象”:为什么 router 质量才是 scaling 的真正瓶颈
这篇论文最抓人的实验不在某个 fancy 架构,而在他们构造了一个可控能力的“强 router”族 r o ( p ) r_o(p) ro(p)(论文记为 r o ( p ) ro(p) ro(p)):
- 先用性能记录构造 oracle router r o r_o ro:对给定输入从 m m m 个候选中选到最优 LLM;
- 再定义:
- 以概率 p p p 用 oracle 做选择;
- 以概率 1 − p 1-p 1−p 退化成均匀随机选择 ω m \omega_m ωm。
当 p → 1 p \to 1 p→1,router 接近神谕;当 p → 0 p \to 0 p→0,就是随机抽模型。
接着他们在 ARC、MMMU-PRO、MATH Lvl 5、TruthfulQA 上,针对不同候选规模 m m m,反复从大池子里均匀采样 m m m 个候选、重复 100 次取平均表现,得到 Fig.2 的趋势:当 router 更强时,随着候选数增加性能会更快提升;论文特别指出在 p ≥ 0.5 p \ge 0.5 p≥0.5 时提升更明显。
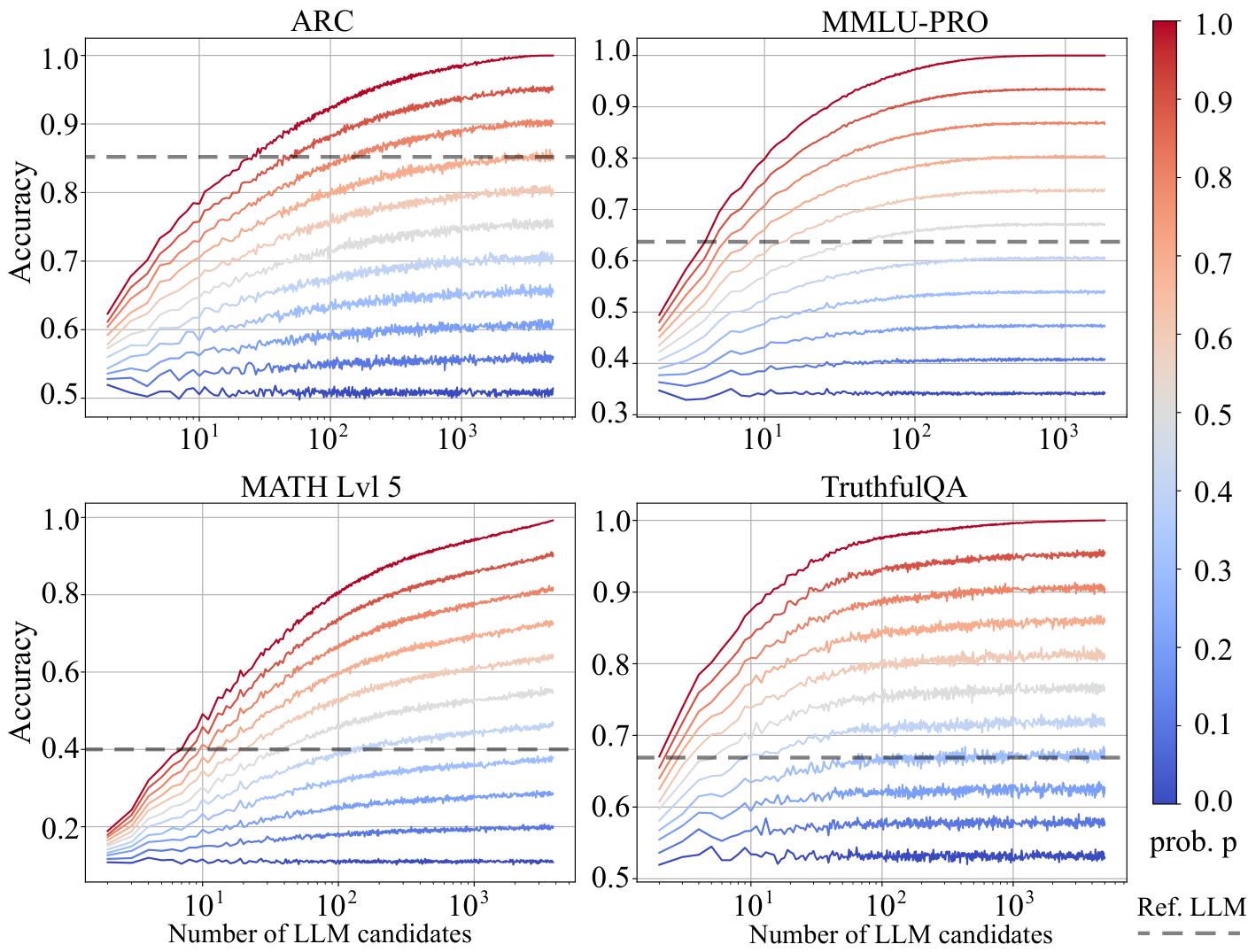
图 2 当 router 足够强时,候选越多性能越涨;router 不够强时,更多候选可能只是负担
更大的候选池并不自动等于更强的系统;router 的能力(更接近 oracle 的程度)才是能否吃到 scaling 红利的关键因素。
4|再证明“缺口”:RouterEval 把“router 还不够强”这件事摊开讲
RouterEval 的体量是它的核心卖点:基于 8,500+ LLM、覆盖 12 个常用评测,整理出 2 亿+ performance records,把 routing 研究从“小样本、小候选、小复现性”拉到一个更接近真实生态的尺度。
12 个评测覆盖知识问答、常识推理、语义理解等(论文列出的 12 个评测为:ARC、HellaSwag、MMLU、TruthfulQA、WinoGrande、GSM8k、IFEval、BBH、GPQA、MUSR、MATH Lvl 5、MMLU-PRO)。
他们还把候选规模分成两档:
- easy:候选 LLM 数量 m ∈ { 3 , 5 } m \in \{3,5\} m∈{3,5}
- hard:候选 LLM 数量 m ∈ { 10 , 100 , 1000 } m \in \{10,100,1000\} m∈{10,100,1000}
并且很明确地解释为什么主打 easy:论文在 Section 4.2 里说明,他们更关注 easy,是因为结合 Fig.2 与 Section 3 的现象,性能增长在较小候选规模区间(论文表述为 2 ≤ m ≤ 10 2 \le m \le 10 2≤m≤10)更快,且这一区间的部署成本更低、更“cost-effective”。
评估指标也很“面向路由本质”,不只看分数(论文在 5.1 定义):
- μ o ( r θ ) \mu_o(r_\theta) μo(rθ):原始指标(路由选出的 LLM 在该基准上的整体表现)
- V R = μ o ( r θ ) / P e r f . ( r e f . ) V_R = \mu_o(r_\theta)/Perf.(ref.) VR=μo(rθ)/Perf.(ref.):相对强参考模型的比值(参考模型例如 GPT-4)
- V B = μ o ( r θ ) / P e r f . ( B S M ) V_B = \mu_o(r_\theta)/Perf.(BSM) VB=μo(rθ)/Perf.(BSM):相对候选集中最佳单模型的比值
- E p E_p Ep:用熵刻画预测分布多样性,用于诊断“分类偏置/塌缩”(router 总选同一个 LLM 时熵会更低)
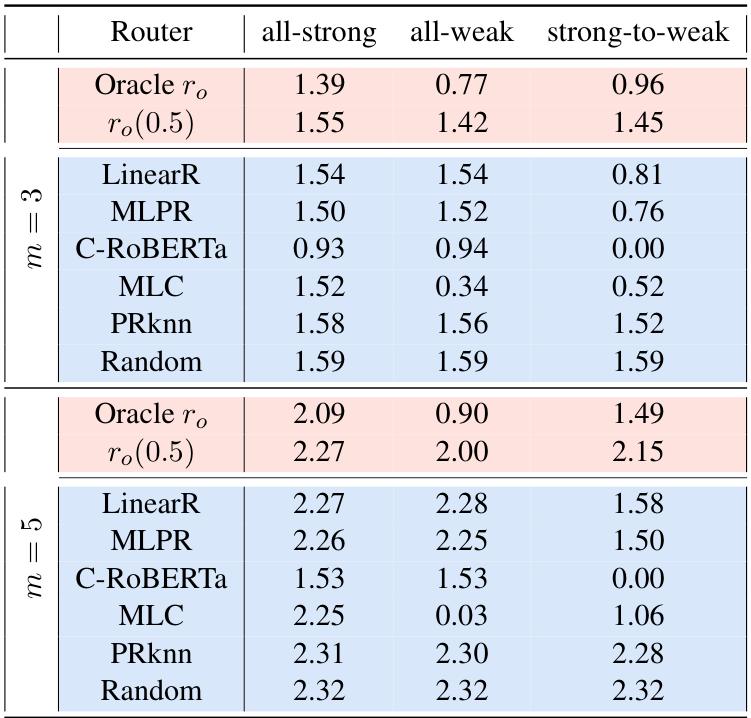
Baselines 包括上限( r o r_o ro、 r o ( 0.5 ) r_o(0.5) ro(0.5))和一批已有 router(LinearR、MLPR、C-RoBERTa、MLC、PRknn 等)。
结果的整体信号很一致:现有 router 多数有一定分类能力,但在大多数设置下,选出来的 LLM 在性能上仍显著落后于候选集中最佳单模型与强参考模型,即论文总结的 V R ≤ 1 V_R \le 1 VR≤1、 V B ≤ 1 V_B \le 1 VB≤1 在多数设置成立;并且没有任何一种 router 能跨所有 benchmark 持续优于其他方法。
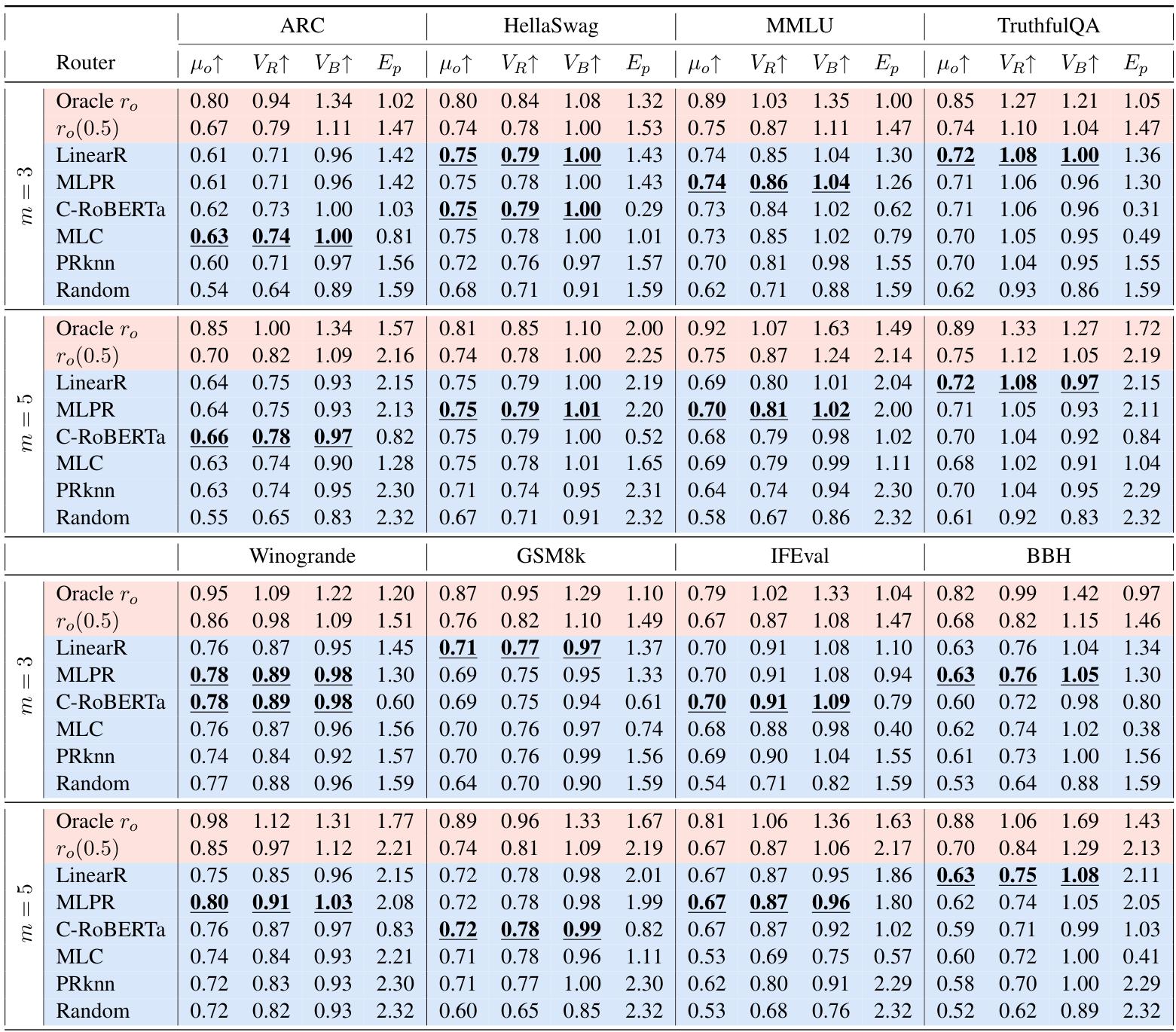
easy 设置下大规模对比(Table 1)
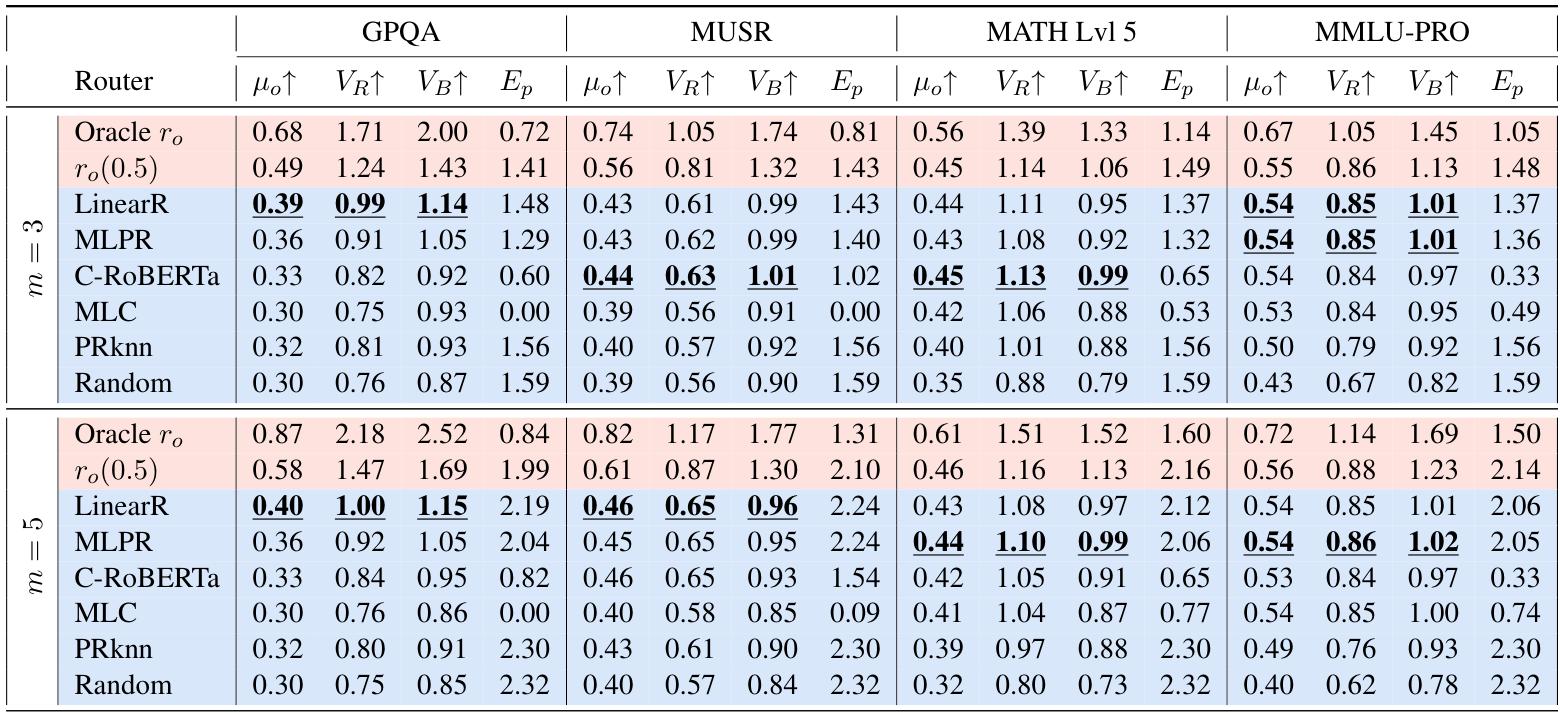
easy 设置下大规模对比(Table 2)
如果你把它翻译成工程语言:你可能已经付出了“多模型接入 + 路由维护 + 观测与回滚”的复杂度,但收益还不稳定,甚至不如“直接永远用候选里最强的那一个”。
5|最危险的失败模式:router 看起来在路由,其实在“装饰性分流”
论文把一个非常真实的现象称为 classification bias:router 的预测分布熵 E p E_p Ep 很低,几乎总把请求发给同一个模型。论文明确指出:当熵很低意味着缺乏多样性,可能暗示过拟合与选择偏置。
文中也指出一种极端情形:当 E p → 0 E_p \to 0 Ep→0,router 会退化成一种“只会选同一个 LLM”的行为(论文表述为若总选同一个 LLM,预测分布熵会很低),这会削弱 Routing LLMs 的优势,因为它没有真正利用多个候选的互补性。
这很致命,因为它会制造一种错觉:
- 平均分数可能不差(毕竟强模型兜底);
- 但 routing 的核心价值——互补性、分工,以及潜在的效率优势——会被明显削弱。
Table 3 专门用 E p E_p Ep 展示这种偏置在不同候选组、不同方法中出现的程度:一些方法在某些设置里 E p E_p Ep 很低(论文用“低熵”来指示潜在偏置/过拟合)。
用选择熵 Ep 抓“塌缩”:Ep 越低越像只会选一个模型(Table 3)
把它和 Fig.2 放一起看,你会发现 RouterEval 暗含的主线冲突是:
- 你想要“候选越多越强”的 model-level scaling;
- 但只要 router 发生强烈偏置(预测分布塌缩),你扩张出来的候选就会更难被有效利用;
- 为了缓解这种问题,你可能需要更有效的训练策略与去偏(debiasing)等能力(论文在分析部分也强调了去偏的重要性)。
6|“落地建议”:甜点区可能真是 3–10 个候选
论文在 Limitations 里说得很直白:大量候选 LLM 可能带来部署挑战;同时他们的实验观察表明,约 3–10 个候选时该范式的 cost-effectiveness 最高(性能增长率最快)。因此论文认为:如果不追求极致表现,小规模候选也能在部署上保持较低计算需求;并补充说,在工业部署中若路由基础设施完善、且输入成批到来,平均计算成本也未必很高。
这对平台方是个微妙但重要的信号:
- Routing LLMs 不是鼓励“无限堆模型”;
- 更像是在逼你把注意力从“更大的单体”转向“更好的组织与分工”;
- 并且在可部署区间内,把 router 练得“不偏、能泛化”,可能比扩候选更关键。
7|关键:先别急着 multi-objective(cost / hallucination),因为单目标都还没做好
很多人谈 routing,会直接把叙事拉到“又便宜又准又少幻觉”的 multi-objective 优化。论文的态度更偏现实主义:他们指出 RouterEval 可以扩展到计算成本、幻觉率等目标(通过多目标优化),但从 Section 5 的实验结果看,即使只关注各基准上的性能指标,当前 router 方法仍有很大提升空间;在这种情况下,论文建议暂缓加入更多目标,因为在数据有限时,更多学习目标可能进一步影响性能。
这句话对研究路线的启发是:RouterEval 不是来“宣布 routing 已经 ready”,而是来明确告诉你——router 能力本身仍是关键瓶颈之一,而不是你缺一个更花哨的目标函数。
8|我们是在训练“分诊台”,还是在训练“新的单点权力”?
RouterEval 把 routing 的公共地基做大了:海量候选、海量记录、系统化指标,并在分析中把 Routing LLMs 类比为 recommender system,讨论了表示学习、cold-start、debiasing、因果推断等可能方向。但它也把一个更深的风险摆到台面上(至少从论文揭示的“偏置/塌缩”现象出发,很容易引出这样的追问):
当 router 变强、候选变多,系统的控制权会不会从“模型能力”转移到“router 的偏置、可解释性与可控性”?当低 E p E_p Ep 式的偏置随时可能发生时,我们构建的到底是多专家协作,还是一个更难审计的黑盒决策中心?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)